⊹ CCIE ⊹
SDWAN LM Notes
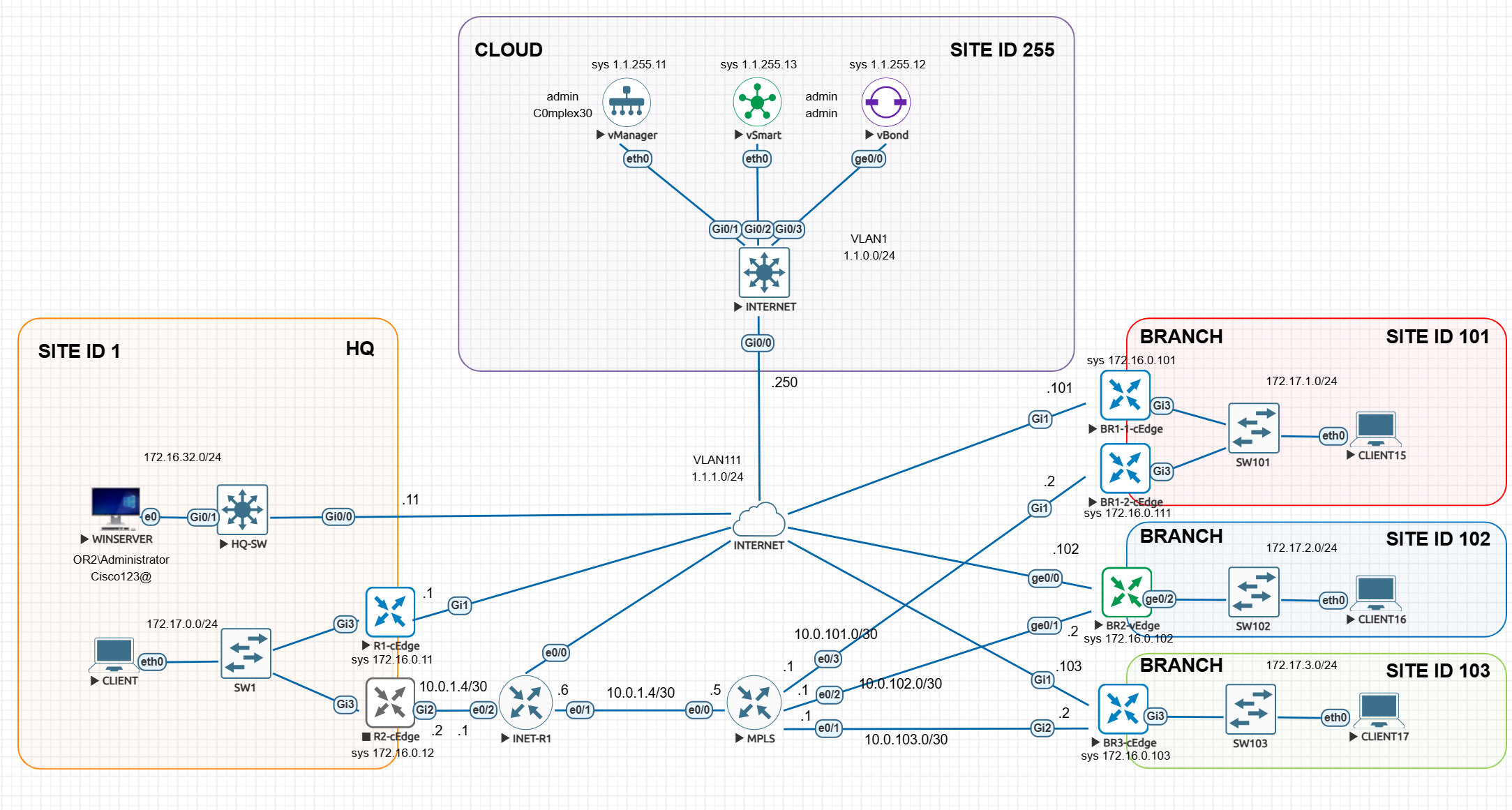
SDWAN Basics & LAB Controllers / Edge Standup

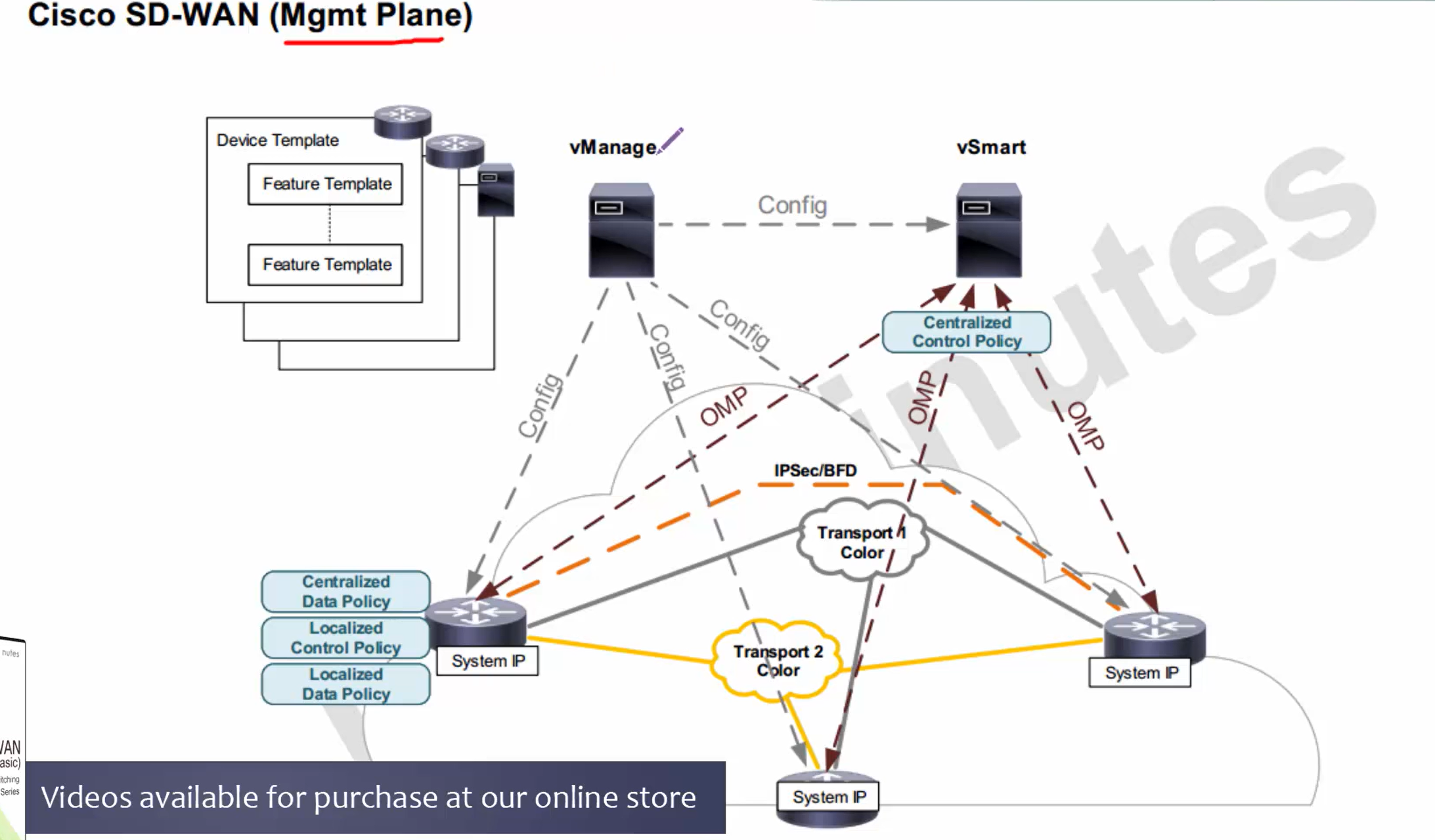
in above, only vbond authenticates to the vmanage, every thing else authenticates to the vbond including vsmart and all wan edges
All are assigned certificate from vmanage but they all authenticate to vbond except vbond itself which has to authenticate with vmanage as there is nothing else
Step 1. First we install vmanage and add vbond to vmanage
vmanage then issues certificate to vbond
vmanage and vbond then perform mutual certificate based authentication and establish a management channel indicated by the grey arrow
Step 2. Then we add vsmart to vmanage and vmanage then issues certificate to the vsmart
you will see after step 2 vsmart information is uploaded to vbond (so vsmart can first authenticate to vbond)
vsmart then contacts and authenticates with vbond
after authentication vsmart will have management channel with vbond and vmanage
At this stage, if we have more vsmarts, they will learn about other vsmarts from vbond
Step 3. Either vmanage can sync with your smart account and download the list of devices
or we can use the serial file method which is offline method of importing devices
once device list has been uploaded to vmanage, it uploads this device list to all controllers (vbond and vsmart)
at this point all the controllers are aware of all the wan edge devices which will join
Step 4 When the wan edge device comes up it gets DHCP ip and contacts ZTP on a pre-defined URL
ZTP in this case is cisco’s online server that will have all the licenses generated will redirect the wan edge to organisation’s vbond
wan edge will authenticate with vbond
vbond will inform the wan edge about how to get to vmanage and vsmart
Step 5. wan edge will go and authenticate with vmanage and establish the management channel
Step 6. wan edge will go and authenticate with vsmart and establish the OMP channel
Step 7. wan edge will establish the IPSec tunnel with other wan edge routers
TLOC = System IP + Color + Encapsulation protocol
There are 3 kinds of routes
OMP routes
TLOC routes
Service routes
TLOC is maintained using BFD, if a TLOC goes down then all routes associated to that TLOC are removed just like next hop interface
BFD does more than reachability check, it checks for Loss (completely no response) , delay (delayed response) , jitter (variation in delay) as well also called path quality, these path quality metrics are then used in application aware routing
If there is a second vsmart, wan edge will have another omp peering with that vsmart
VPN number is tagged in the IPSec header so other router can land that traffic in same VPN
Configuration is not only pushed to wan edge devices but also to the vsmart
vsmart is also considered a managed device like wan edge router since it needs to be added to vmanage and applied configuration through the template etc just like wan edge device
once template is applied, devices go in something called vmanage mode and then we cannot configure devices from CLI (initially you can configure devices from CLI but once managed by vmanage you cannot)
Device template > feature template
As can be seen above
Centralized control policy (vsmart)
Centralized data policy (wan edge)
Localized control policy (wan edge)
Localized data policy (wan edge)
Centralized control policy is used to create different types of topologies
Centralized data policy is like route-map that is applied on interface effects the data packet directly, we can match packets based on packet header or application based matching which relies on deep packet inspection and take actions such as dropping packets, QoS classification, policing, change next hop and so on – but this is pushed by vsmart and lives in wan edge memory and does not really get added to the device local configuration, remember that from central keyword, anything that is centralized, its policies are in wan edge’s memory and not in the wan edge config
Localized control policy – this is effective or configured on the service side only, so if OSPF and BGP is running on LAN of the wan edge, localized control policy is needed
Localized Data policy is very similar to the Centralized Data policy, only difference is that is configuration is pushed and becomes part of wan edge configuration and is per interface
make sure when connecting vbond device to switch, it is connected using ge0/0 instead of eth0
this will save you a lot of troubleshooting time when standing up vBond

WINSERVER configuration
Setup same as https://learn.anasather.uk/masters/eveng/eveng-ccie-lab-and-megalinks/
Assign IP address as to Win server as below

Deploy NTP on Windows Server
https://www.domat-int.com/en/how-to-configure-a-local-ntp-server
https://docs.litmus.io/litmusedge/product-features/system/network/configure-dns-ntp-servers/configure-local-ntp-server
Configure the Windows Time Service
In the File Explorer, navigate to: Control Panel\System and Security\Administrative Tools
Double-click Services. This same task can be completed by entering services.msc in the Windows Run dialog (Windows Key + R).
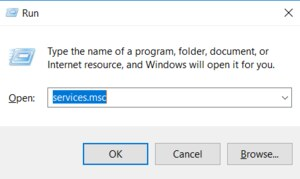
In the Services list, right-click on Windows Time and click Stop.
Note: The Windows Time service may already be stopped. In this case, skip this step and go to the next step to Update the Windows Registry
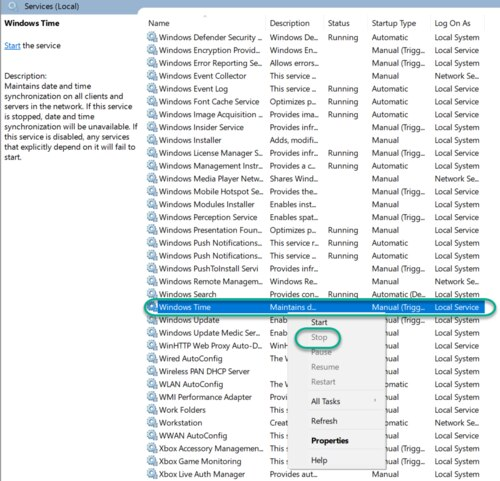
Update the Windows Registry to Create a Local NTP Service
Launch Windows Run (Windows Key + R).
Enter regedit and click OK.
Navigate to the registry key: Computer\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Parameters
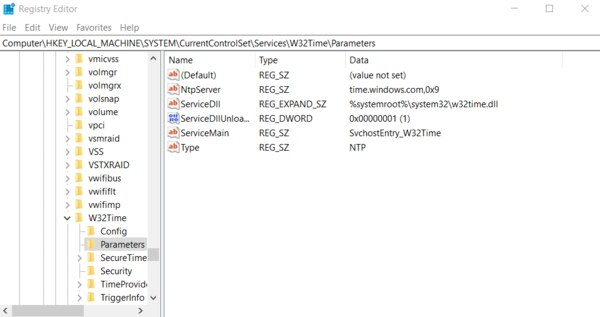
If you do not see LocalNTP REG_DWORD in the list, create it using the following steps.
Right-click in the Registry Editor, select New, select DWORD and enter LocalNTP (note that this name is case sensitive).
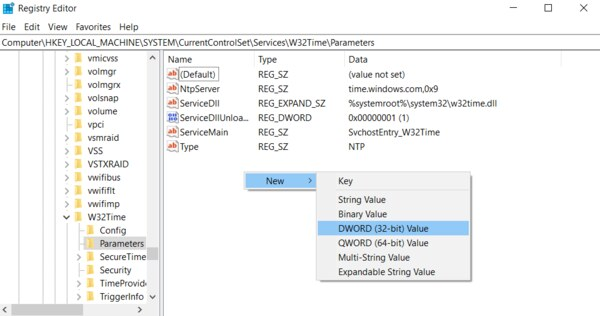
Double-click LocalNTP, change the Value data to 1, select a Base of Hexadecimal , and click OK.
Do not close the Registry Editor because it is used in the following steps.
Update the Windows Registry to Configure the Time Provider
Navigate to the registry key: Computer\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\TimeProviders
Select NtpServer, double-click Enabled, change the Value Data to 1, select a Base of Hexadecimal and click OK.
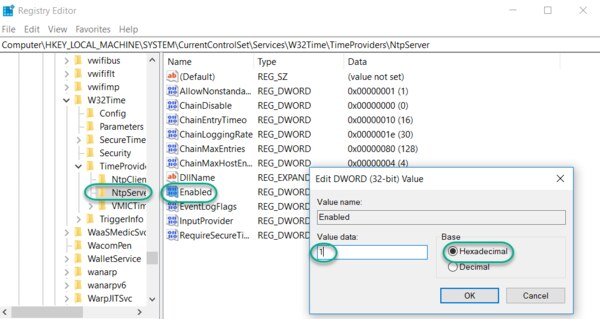
Do not close the Registry Editor because it is used in the following steps.
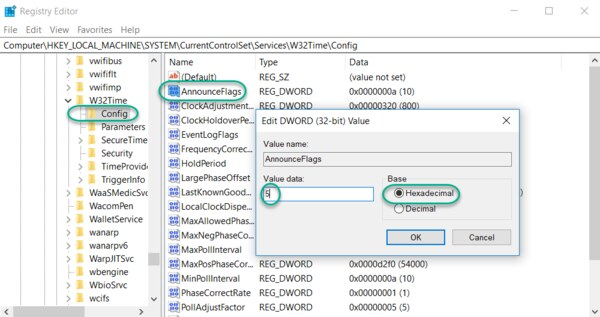
Update the Windows Registry to Configure the Announce Flags
Navigate to the registry key: Computer\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Config
Double-click AnnounceFlags, change the Value data to 5, select a Base of Hexadecimal, and click OK.
Close the Registry Editor.
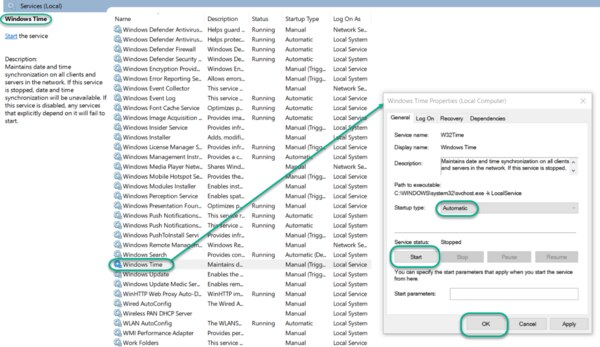
Start the Local Windows NTP Time Service
In the File Explorer, navigate to: Control Panel\System and Security\Administrative Tools
Double-click Services.
In the Services list, right-click on Windows Time and configure the following settings:
Startup type: Automatic
Service Status: Start
OK
Finally, enable UDP port 123 on the Windows firewall for incoming connections.
In Search find Firewall in Windows Defender…
Go to Incoming rules
In the right column, select New rule…
Select the rule Port
Enter UDP port 123 and click Next
Select Allow connection and click Next
Select all domains
Enter the rule name, e.g. Local NTP server, and click Finish.
The local NTP Time Server configuration is now complete. You now can synchronize the time of other computers and devices on your local network.
To test the server functionality from another PC (e.g. a service notebook) use for example the NTP Server Test Tool:
https://www.ntp-time-server.com/ntp-software/ntp-server-tool.html
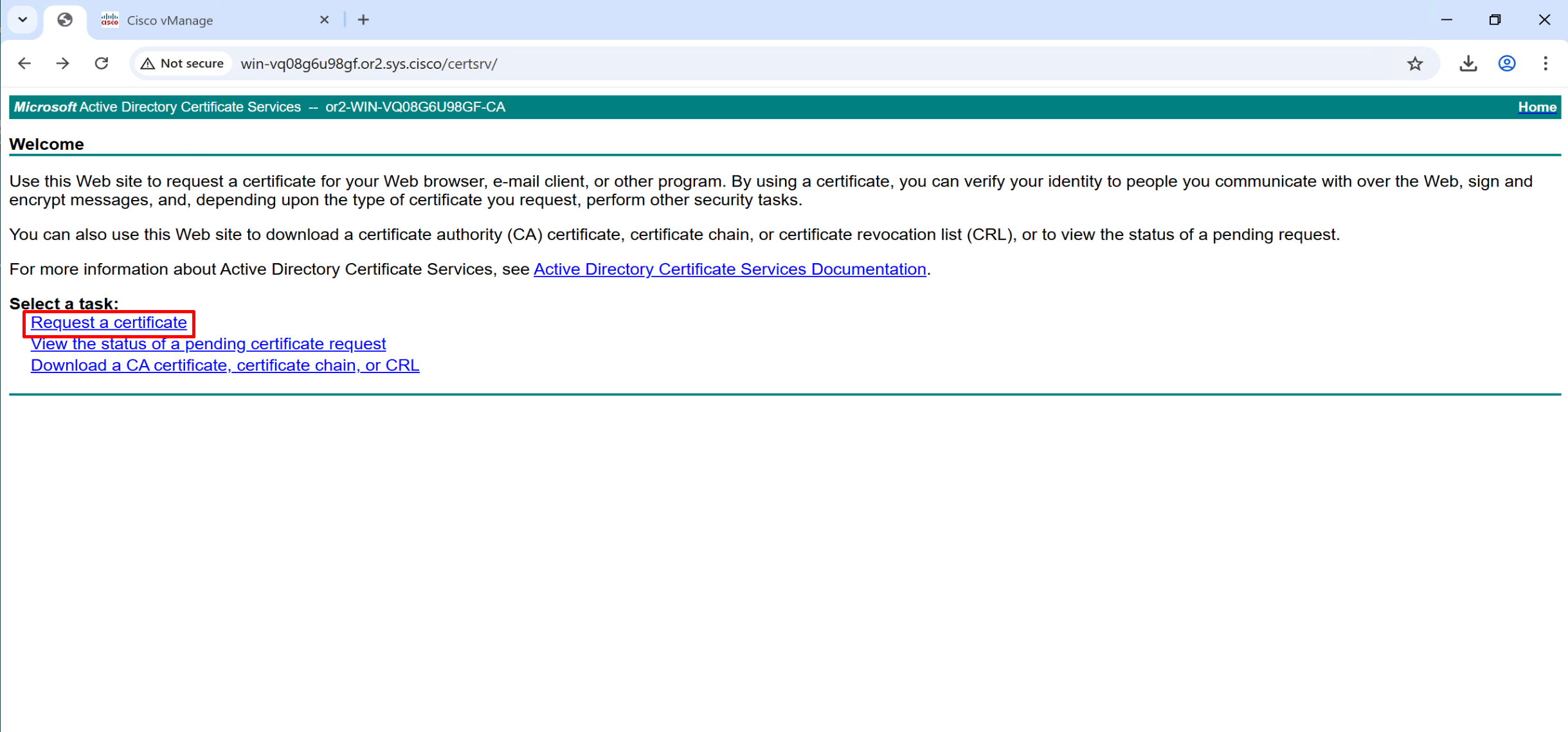
Configure CA Server
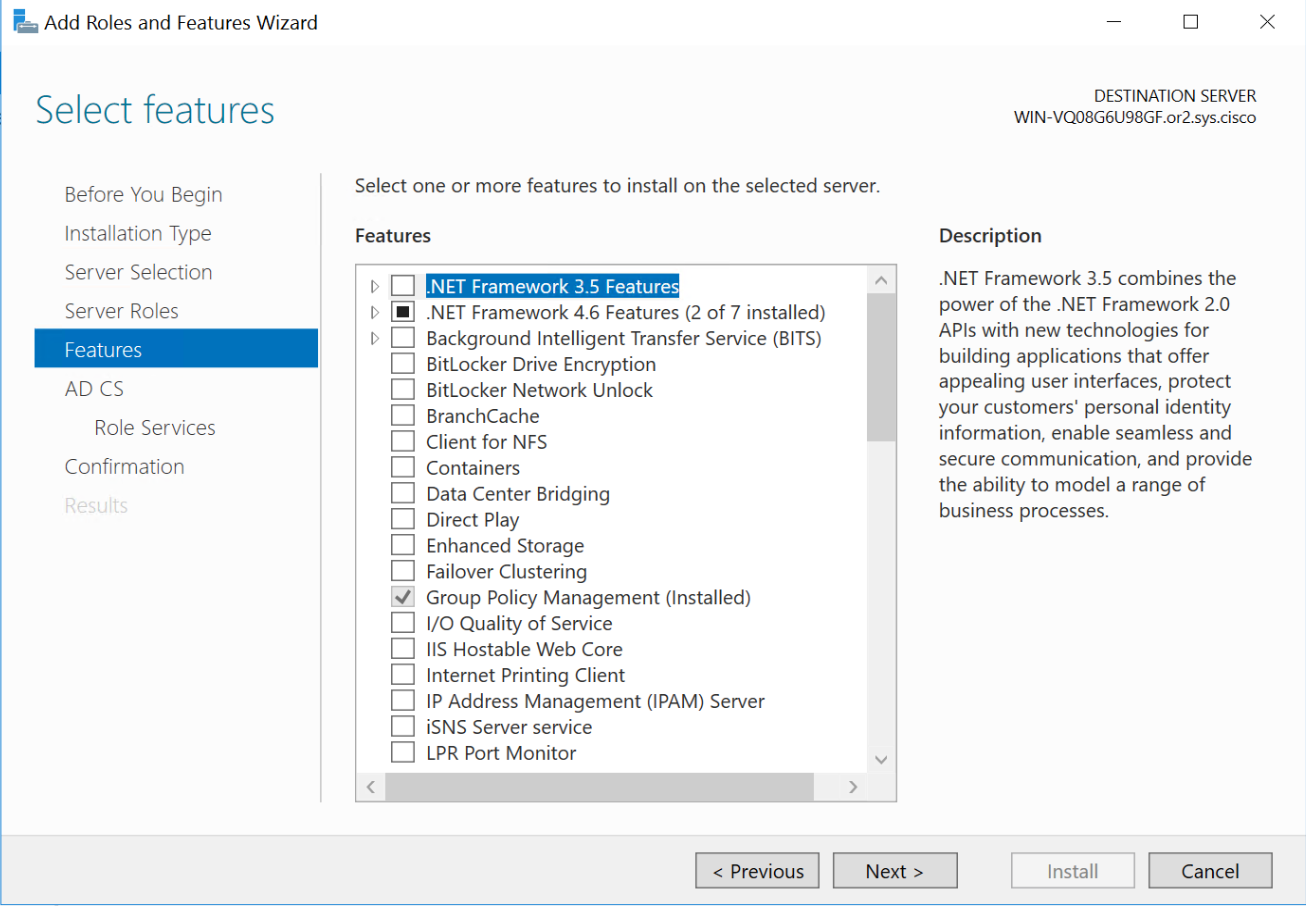


now visit http://[serverFQDN]/certsrv
http://win-vq08g6u98gf.or2.sys.cisco/certsrv/
SDWAN Standup
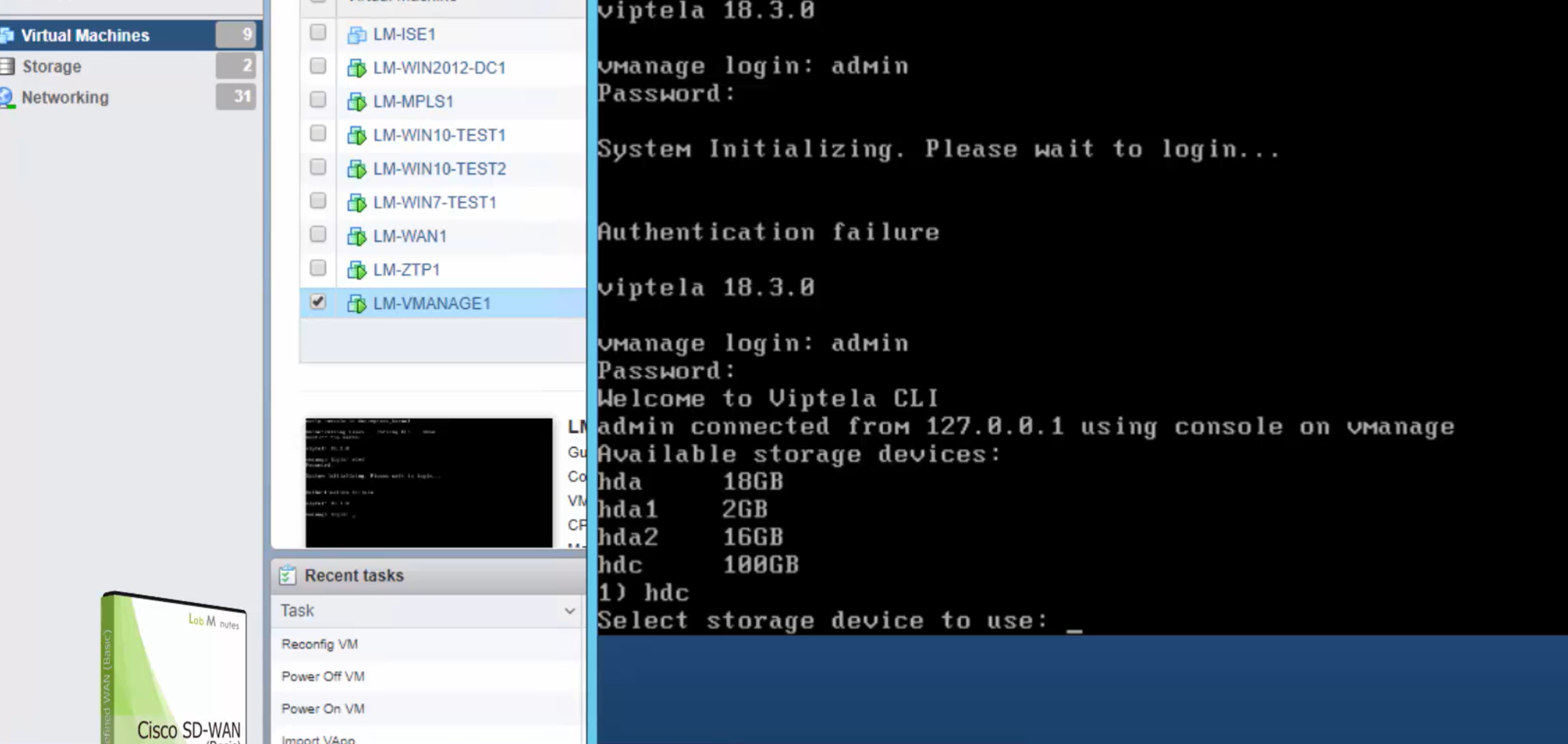
default username and password for vbond is admin/adminvManage requires second hard disk in vCenter
We should know this if we are deploying for onprem environment

it needs to be 100G minimum
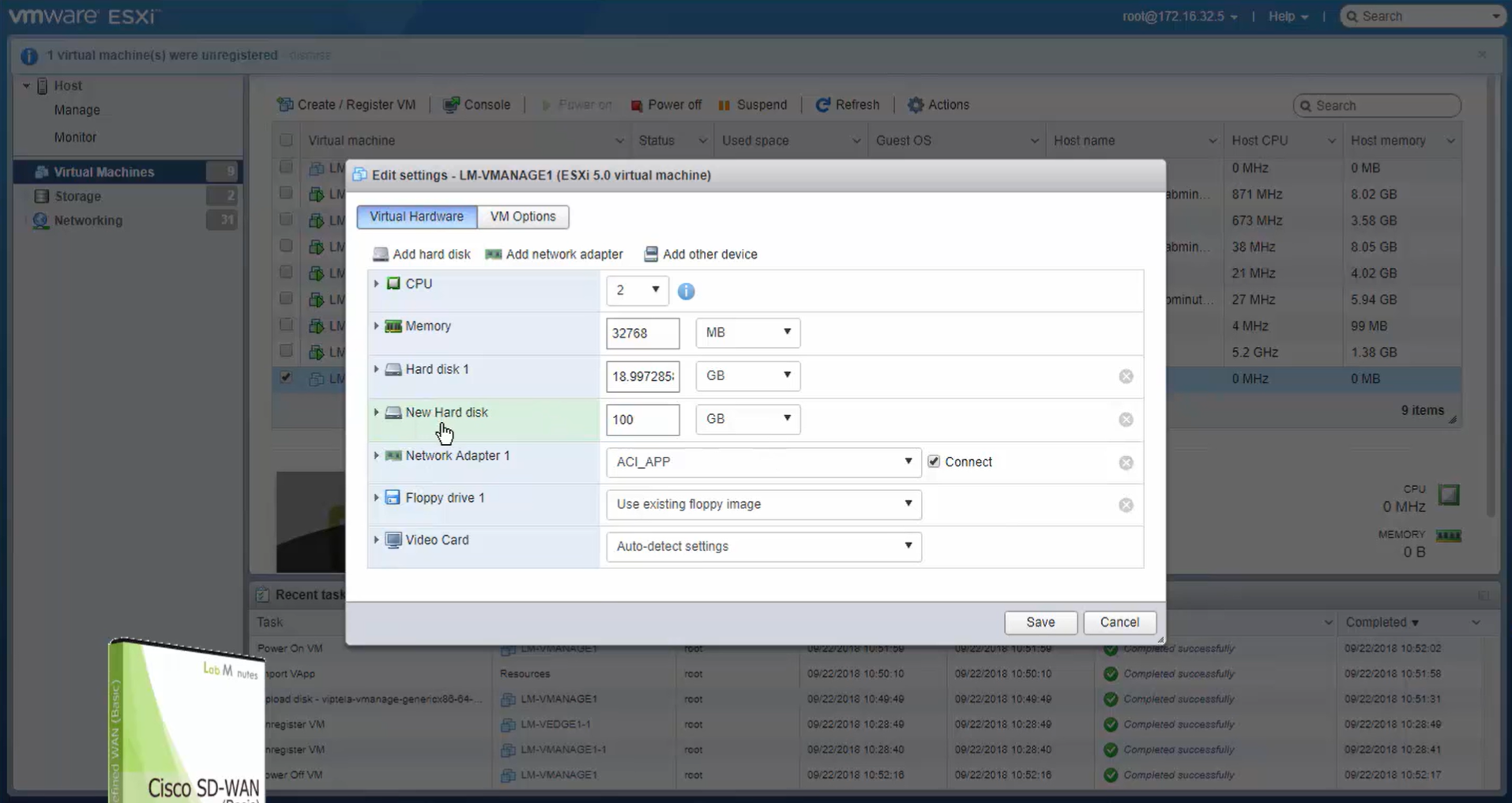
Make sure it is the master
During setup we can see the additional disk we added
vManage system configuration
Assign vmanage second hard drive , if this has not been done already
cd /opt/unetlab/addons/qemu/vtmgmt-20.9.1
/opt/qemu/bin/qemu-img create -f qcow2 virtiob.qcow2 100G
/opt/unetlab/wrappers/unl_wrapper -a fixpermissionsshow version
conf t
system
host-name vManage
system-ip 1.1.255.11
clock timezone Europe/London
site-id 255
organization-name or2.sys.cisco
vbond vbond.or.sys.cisco
ntp server ntp.or2.sys.cisco
! it is important to have ntp server and
! have all controllers and devices with same
! time because we are doing a lot of certificate
! based authentication
! vbond IP is the only controller that you
! define on each all SDWAN devices whether
! controllers or vedge if you have 2 vBond
! then it is good to add FQDN otherwise IP
! address is ok, reason is that on controllers
! we cannot define two different vbond IP addresses
! always commit the configuration
commitshow running-configvmanage(config-ntp)# do show running-config ! to see the commmitted configuration
system
host-name vmanage
admin-tech-on-failure
no vrrp-advt-with-phymac
aaa
auth-order local radius tacacs
usergroup basic
task system read
task interface read
!
usergroup global
!
usergroup netadmin
!
usergroup operator
task system read
task interface read
task policy read
task routing read
task security read
!
usergroup resource_group_admin
task system read
task interface read
!
usergroup resource_group_basic
task system read
task interface read
!
usergroup resource_group_operator! check configuration of a section while in that section
vmanage(config)# system
vmanage(config-system)# show configuration ! t show uncommitted configuration but only under system section
system
host-name vManage
system-ip 1.1.255.11
site-id 255
organization-name or2.sys.cisco
clock timezone Europe/London
vbond vbond.or.sys.cisco
ntp
server ntp.or2.sys.cisco
version 4
exit
!vSmart system configuration
conf t
system
host-name vSmart
system-ip 1.1.255.13
clock timezone Europe/London
site-id 255
organization-name or2.sys.cisco
vbond vbond.or.sys.cisco
ntp server ntp.or2.sys.ciscovBond system configuration
conf t
system
host-name vBond
system-ip 1.1.255.12
clock timezone Europe/London
site-id 255
organization-name or2.sys.cisco
vbond vbond.or.sys.cisco local
! this local keyword converts the vedge to vbond role
ntp server ntp.or2.sys.cisco
DNS server on Windows Server
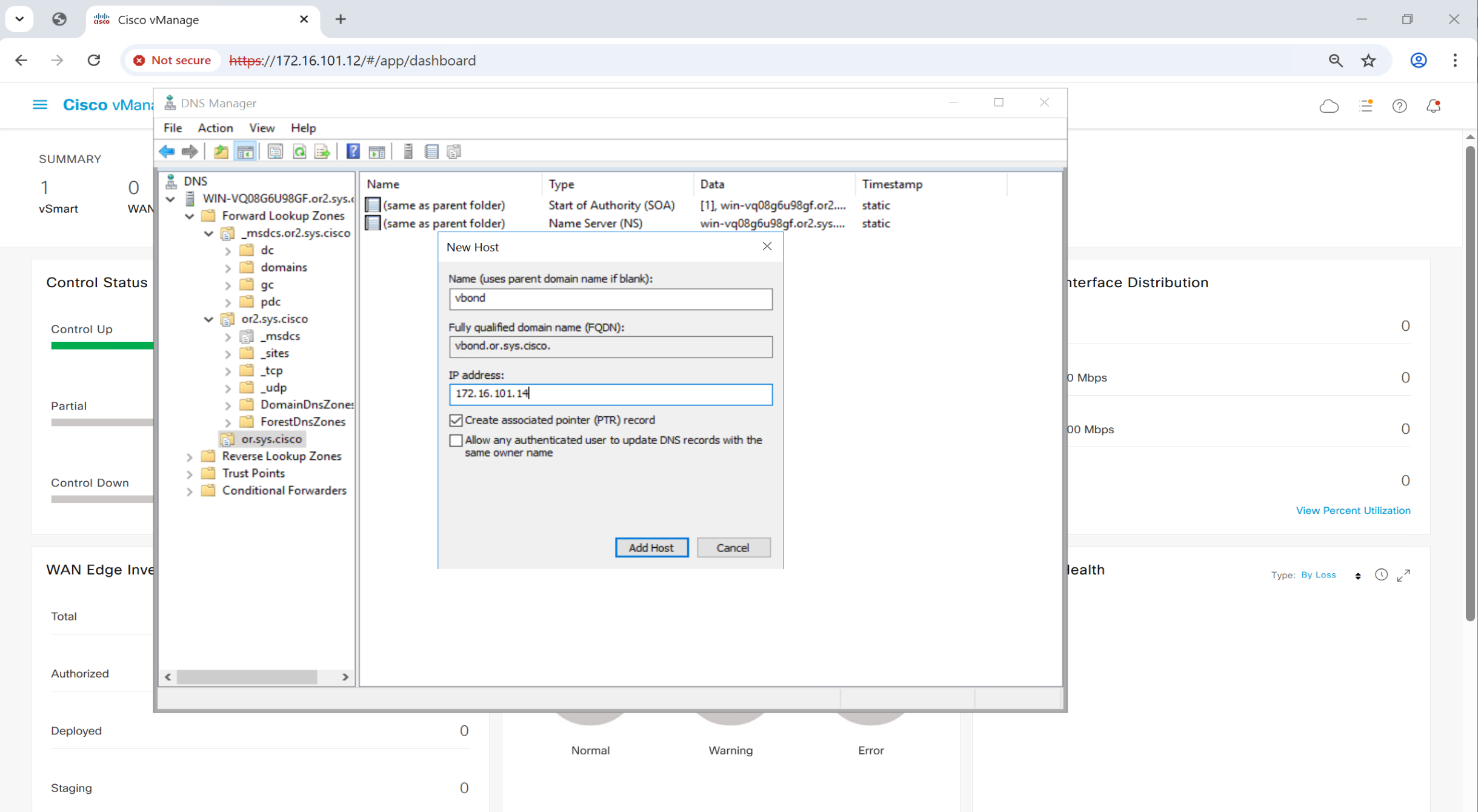
Then create DNS A records
Add A record for vbond in or.sys.cisco domain
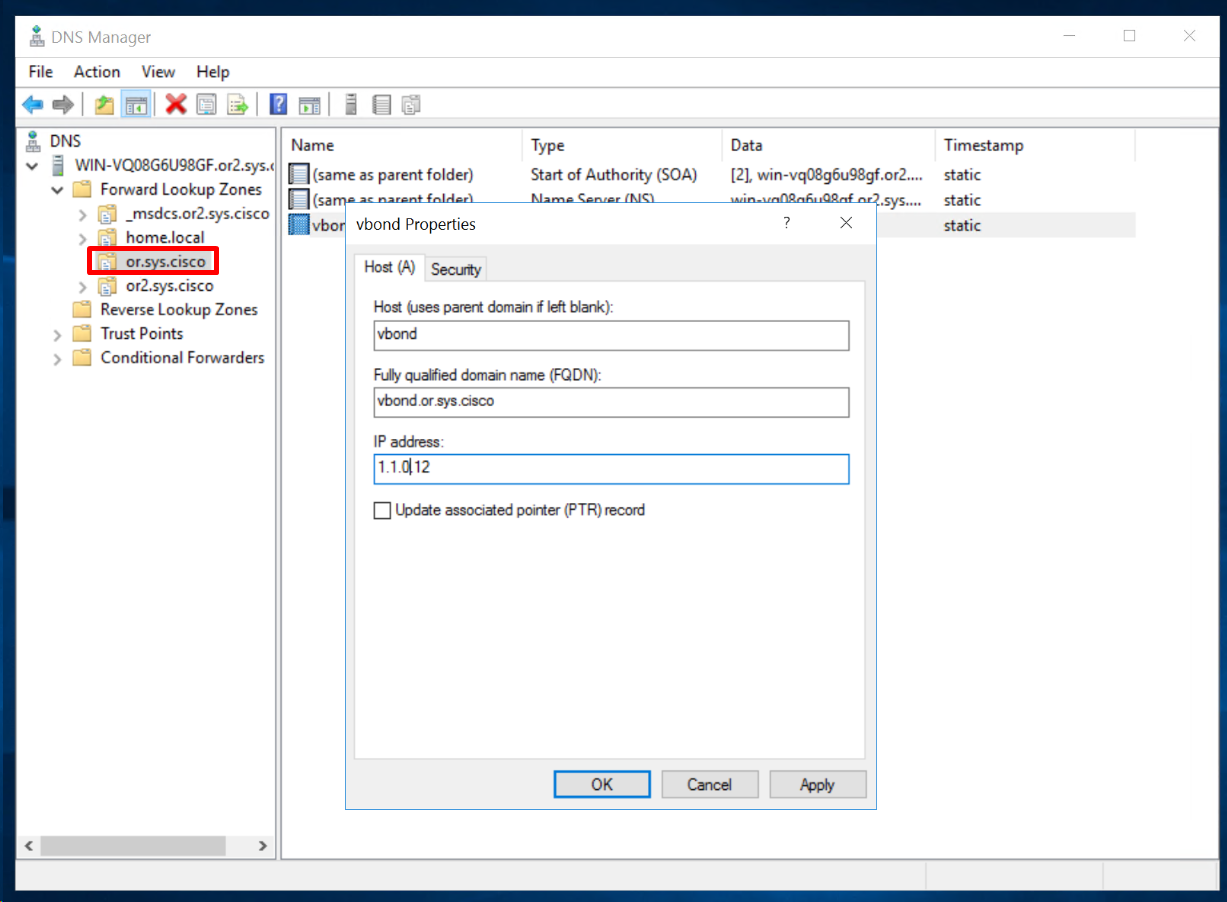
If we have a second vbond and it needs to be added then add another entry for “vbond” same as above but with different IP, multiple vbonds or vbond redundancy is supported by DNS roundrobin (default)
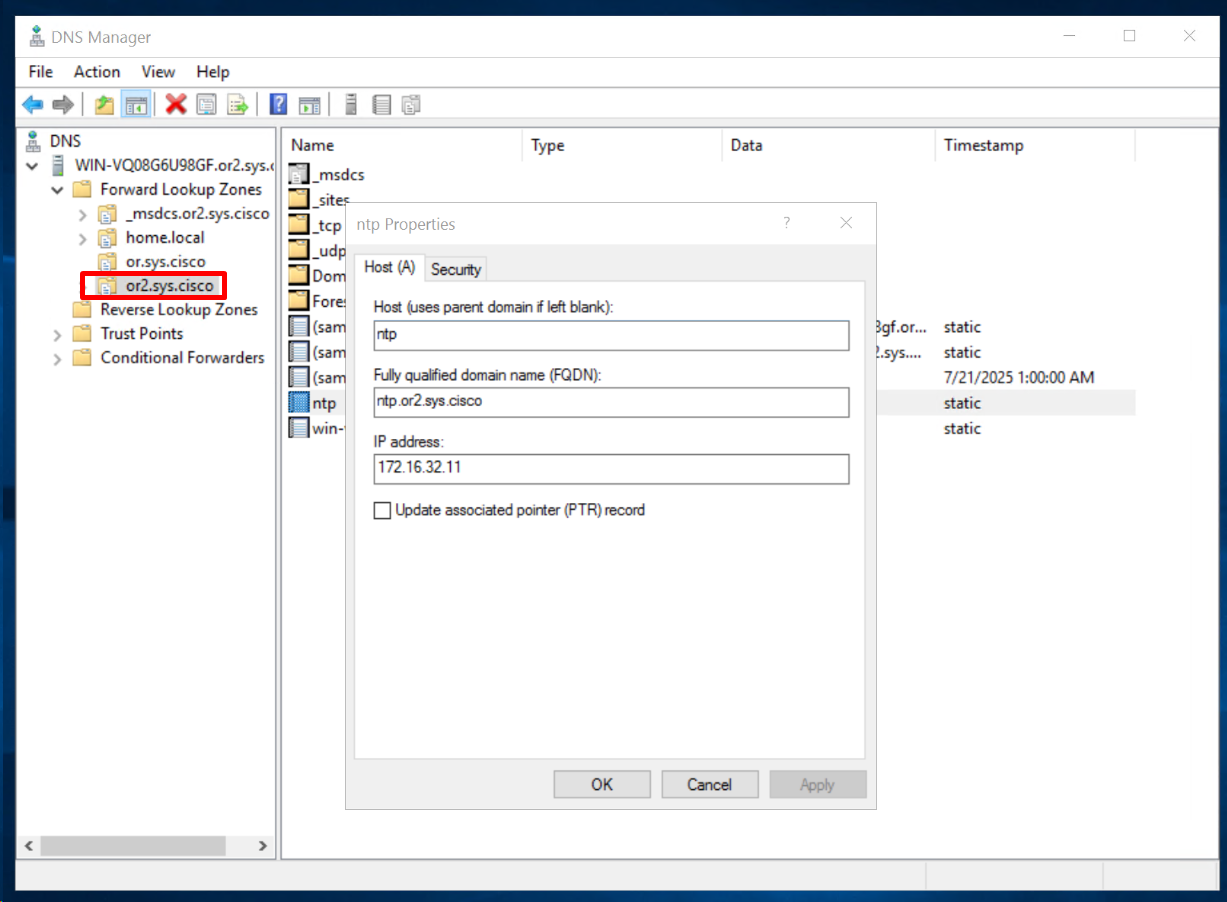
Add A record for ntp in or”2″.sys.cisco
Configure the (WAN , Transport) interface of SDWAN controllers
These interfaces are configured under VPN 0 and they are used to access the GUI by admins and outbound to edge routers communication using NETCONF (vmanage), for OMP peering (vsmart) and onboarding (vbond)
There is no such thing as LAN interface for these controllers
In Cisco cedge devices we do not have VPN0 instead transport uses Global routing table or default non vrf routing table
Configure vmanage vpn0 Transport Interface (vpn0)
conf t
vpn 0
interface eth0
ip address 1.1.0.11/24
no shutdown
no tunn
! we keep the tunnel interface down for now as it is used to deal with overlay or fabric till we have basic connectivity up
! while within the vpn0 configure default route
ip route 0.0.0.0/0 1.1.0.1
dns 172.16.32.11 ! configure this DNS if your vmanage has reachability to internet for automatic sync of device serial numbers from internet rather than offline import of serial number file, "Sync Smart Account" button rather than "Upload WAN Edge List" buttonYou cannot have interface ip same as system ip so they both need to be different
vManage(config)# commit
Aborted: ‘vpn 0 interface eth0 ip address’: Interface eth0 with address 1.1.0.11/24 & System IP 1.1.0.11 cannot be same in vpn 0
Configure vsmart Transport Interface (vpn0)
conf t
vpn 0
interface eth0
ip address 1.1.0.13/24
no shutdown
no tunn
! we keep the tunnel interface down for now as it is used to deal with overlay or fabric
! while within the vpn0 configure default route
ip route 0.0.0.0/0 1.1.0.1
dns 172.16.32.11Configure vbond Transport Interface (vpn0)
conf t
vpn 0
interface ge0/0
! Option 1: we need to keep this tunnel interface down for vbond's own onboarding to work
no tunnel-interface
! or
! Option 2: bring up tunnel interface but allow some services on it
vpn 0
interface ge0/0
tunnel-interface
allow-service sshd
allow-service dns
allow-service ntp
Allowed service are both inbound and outbound
such as NTP will be outbound but SSH will be inbound
!--------------------------------
vpn 0
interface ge0/0
no tunnel-interface
ip address 1.1.0.12/24
no shutdown
! while within the vpn0 router, configure default route
ip route 0.0.0.0/0 1.1.0.1
dns 172.16.32.11
ping vbond.or.sys.ciscoDownload CA Certificate

Download in Base64 format
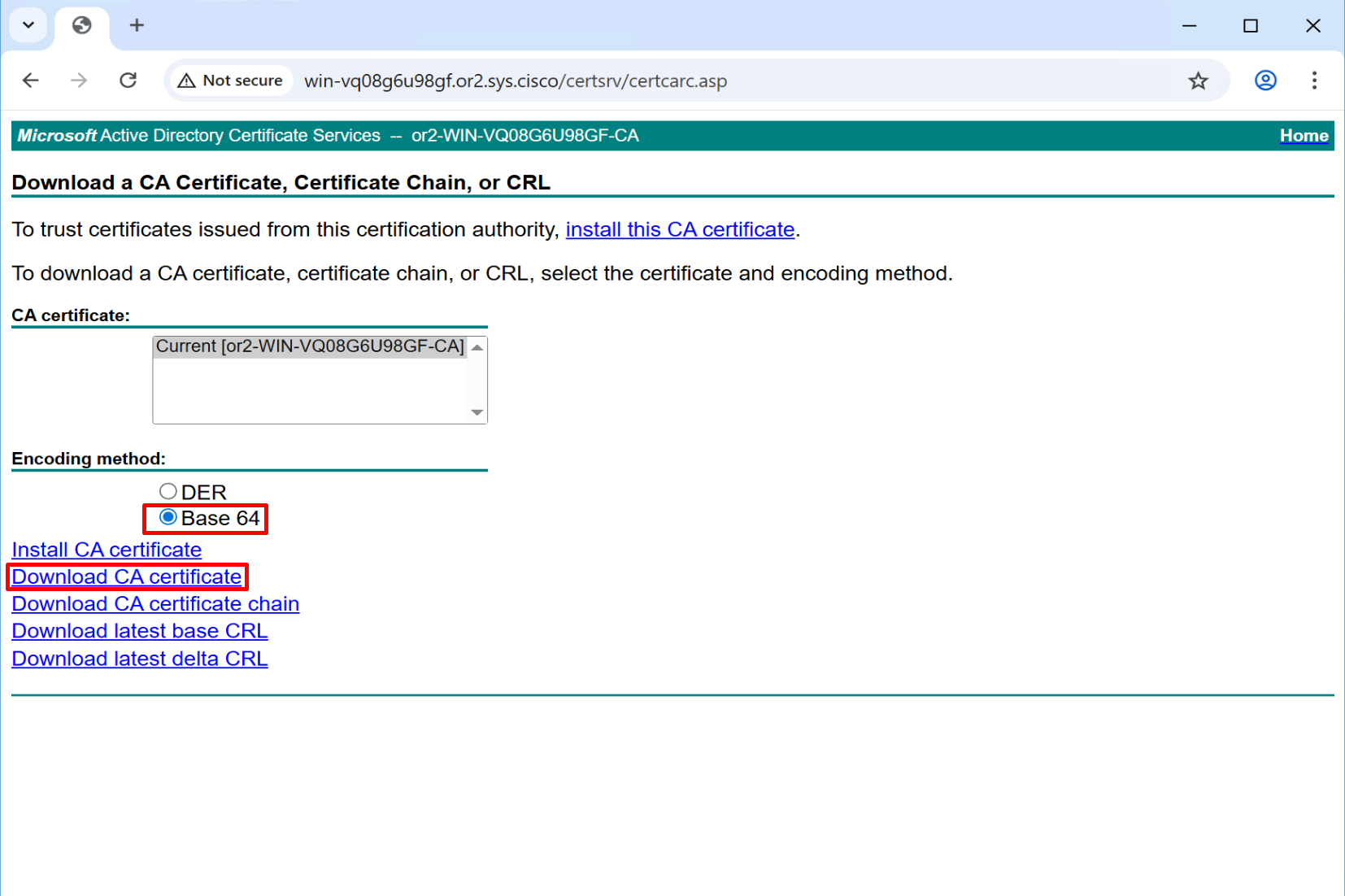
Rename this to root_ca
Access vmanage GUI but make sure you do using IP address and not FQDN, using FQDN it does not work and simply spins and comes back to login screen

Login as admin/Cisco123@
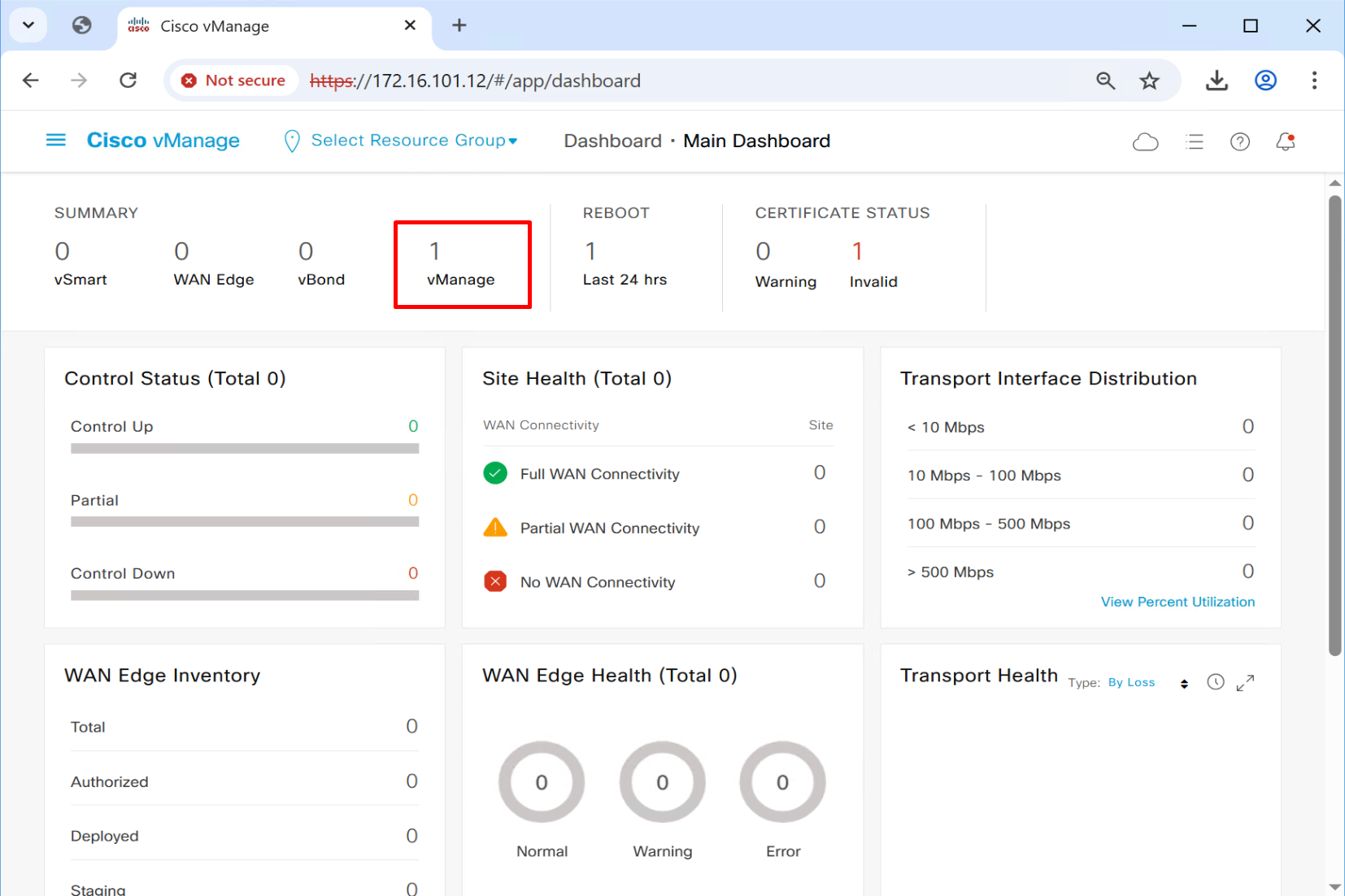
There is only one vmanage that is why we only see one on top summary
Upload root CA to all controllers’ trust store
WinSCP SFTP to the vManage
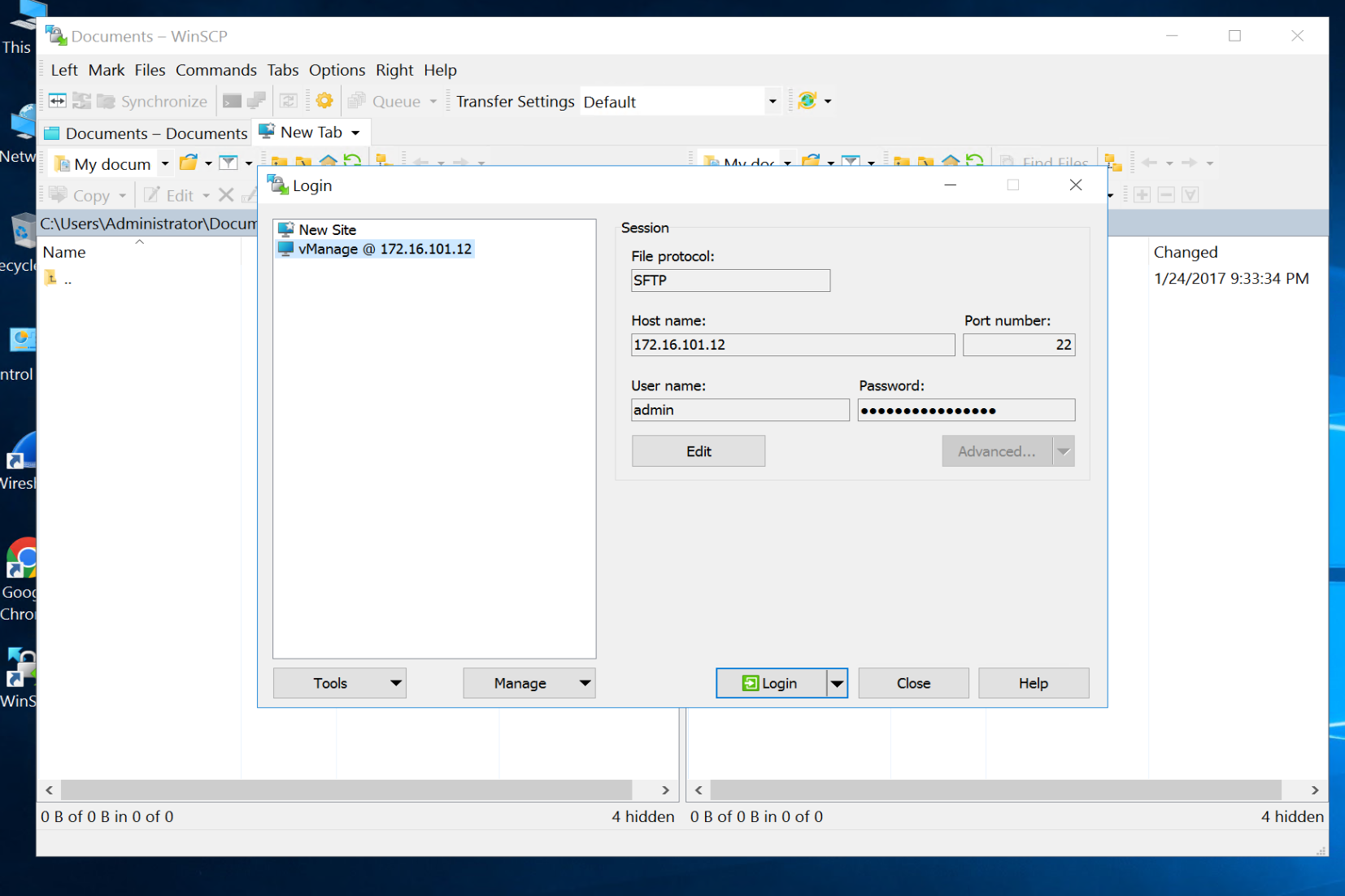
drag root.ca file to /home/admin folder
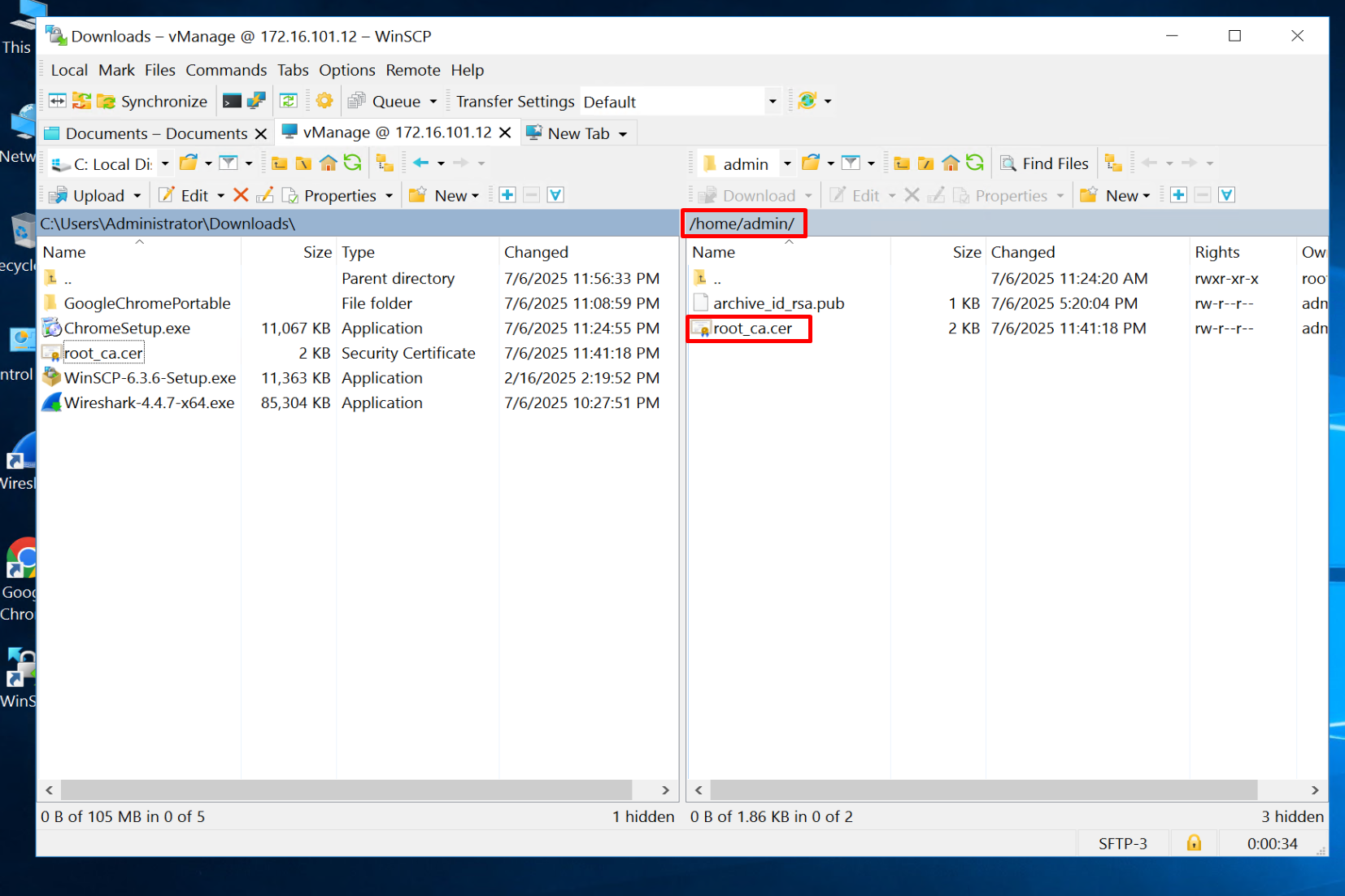
Do same for vSmart and vBond
Before adding certificate, make sure that basic system config is in place
the configuration that we configured earlier
Install root CA certificate chain in Trust store of Controllers
request root-cert-chain install /home/admin/root_ca.cervManage# request root-cert-chain install /home/admin/root_ca.cer
Uploading root-ca-cert-chain via VPN 0
Copying ... /home/admin/root_ca.cer via VPN 0
Updating the root certificate chain..
Successfully installed the root certificate chainvSmart# request root-cert-chain install /home/admin/root_ca.cer
Uploading root-ca-cert-chain via VPN 0
Copying ... /home/admin/root_ca.cer via VPN 0
Updating the root certificate chain..
Successfully installed the root certificate chainvBond# request root-cert-chain install /home/admin/root_ca.cer
Uploading root-ca-cert-chain via VPN 0
Copying ... /home/admin/root_ca.cer via VPN 0
Updating the root certificate chain..
Successfully installed the root certificate chainSync the root cert chain database on vmanage
https://1.1.0.11/dataservice/system/device/sync/rootcertchain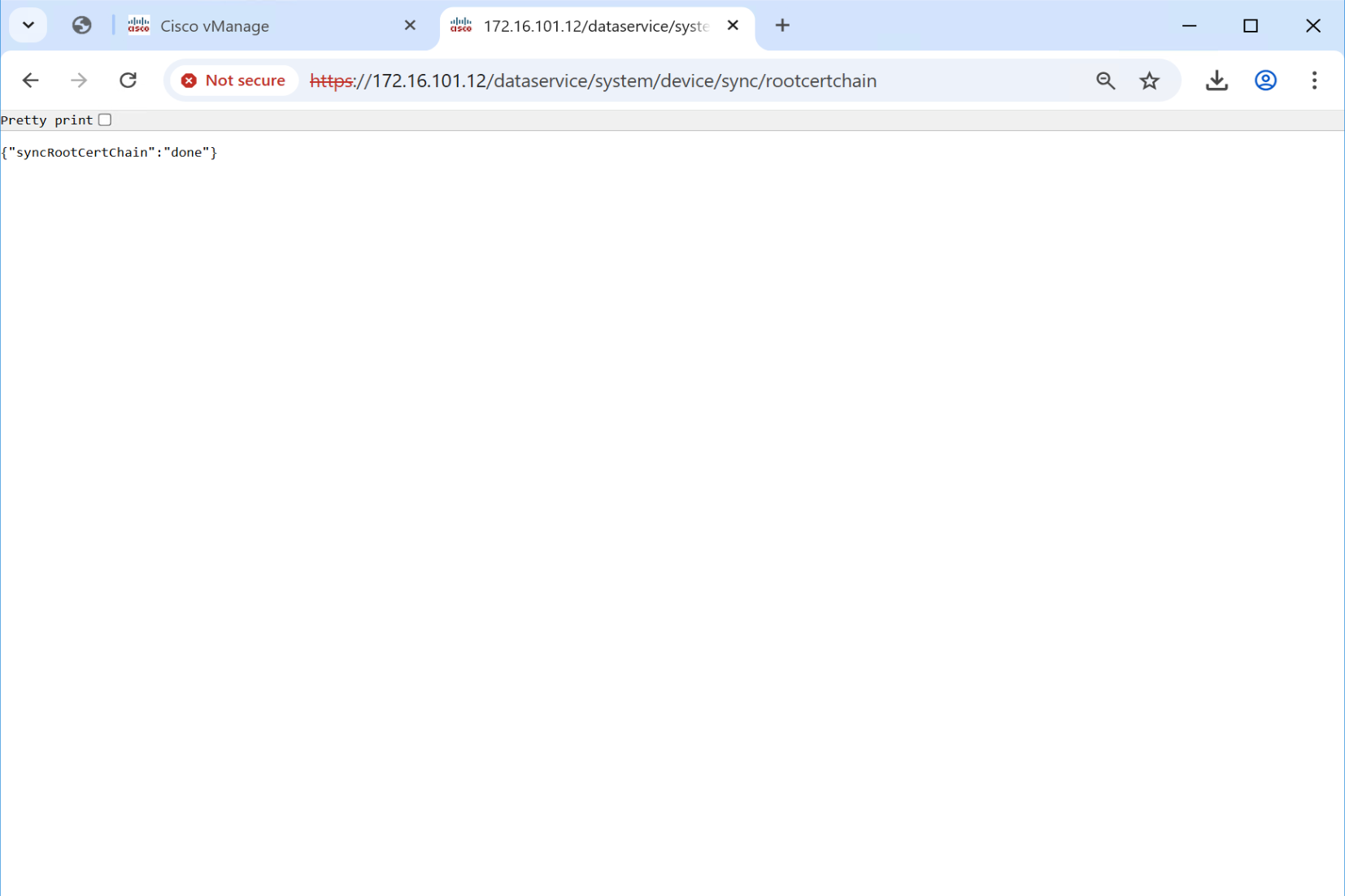
Add controllers to vManage
Add vsmart (credential managed)
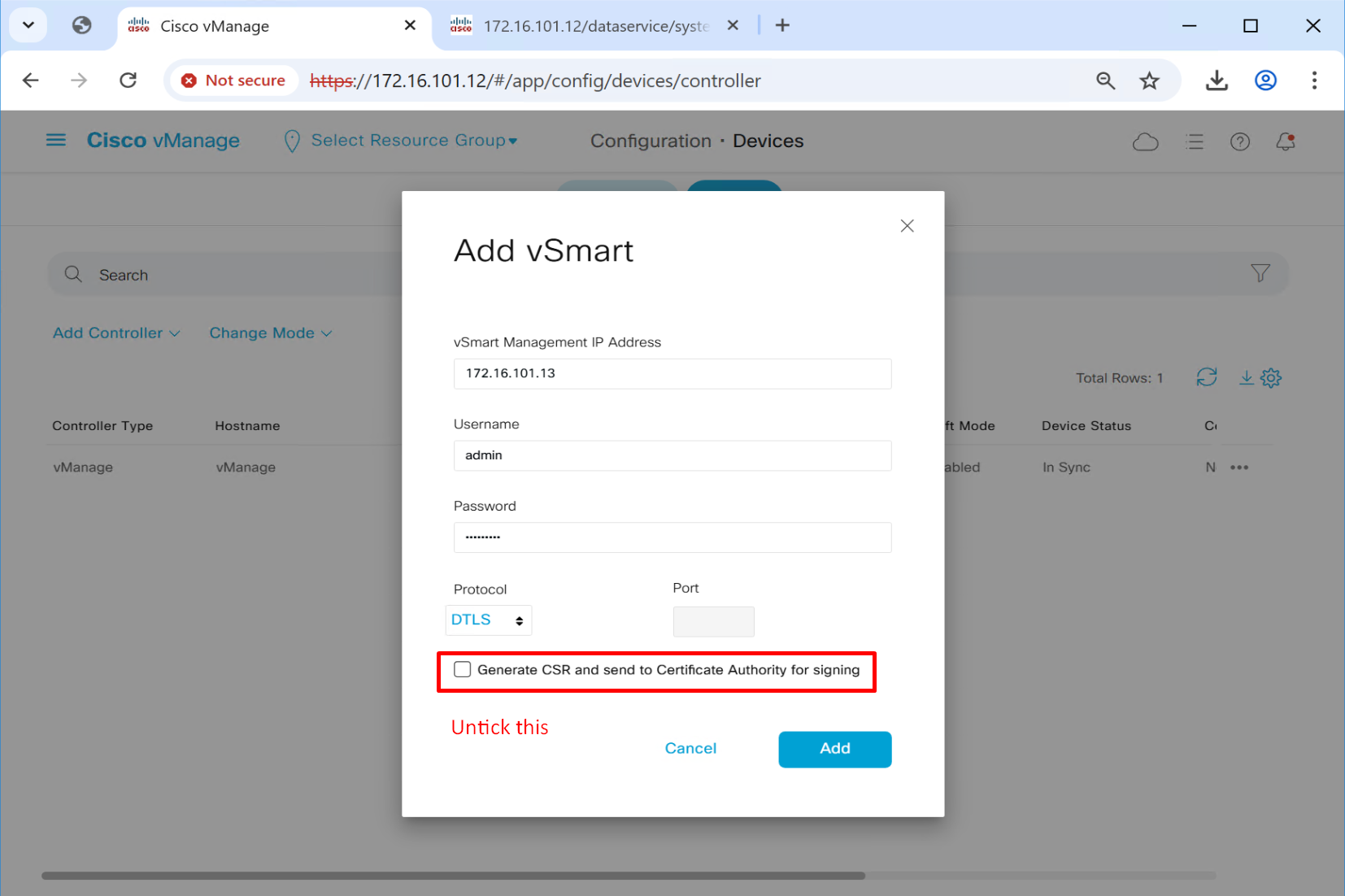
Add vbond (credential managed)
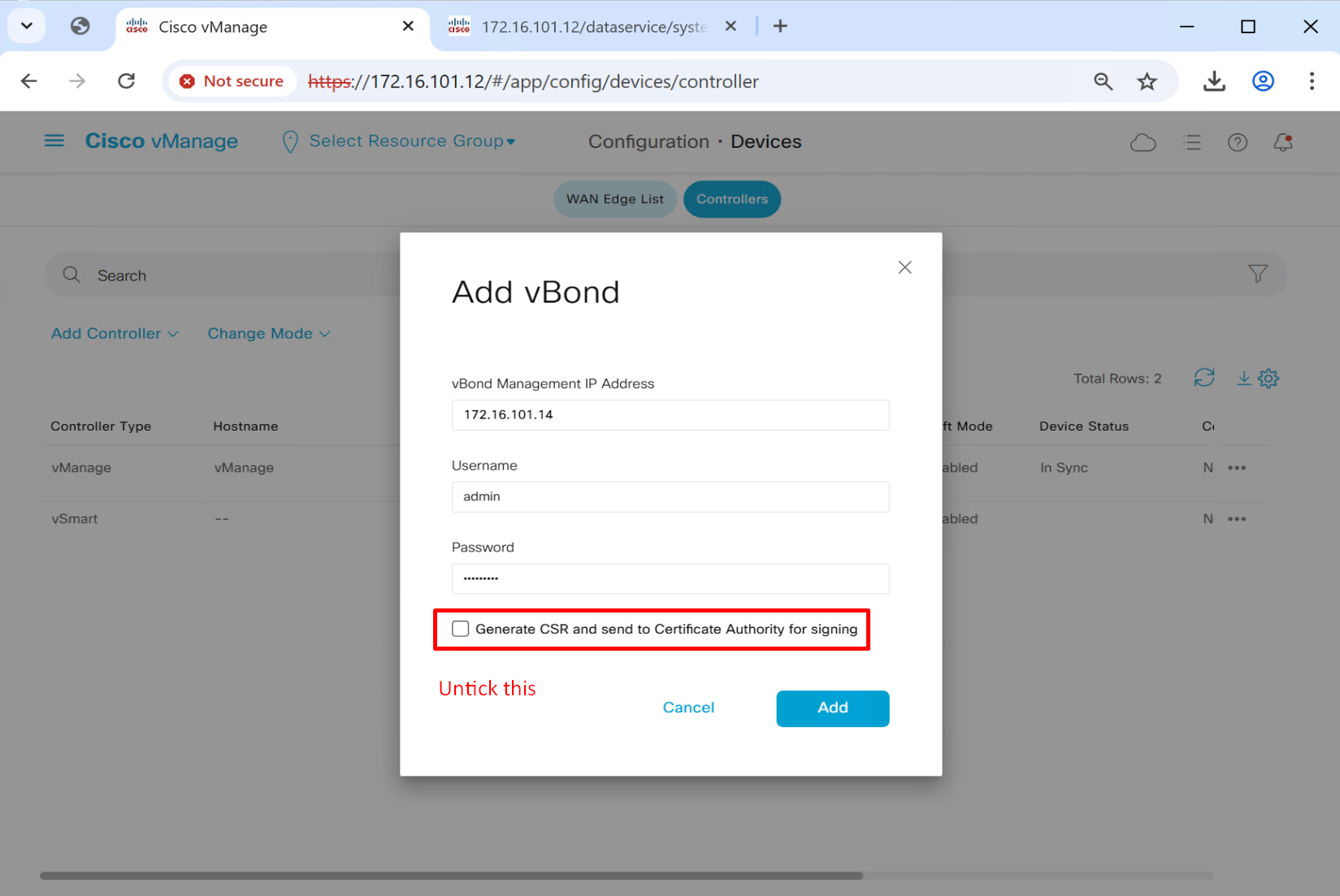
so controllers are configured but we are missing very important bit
even though we configured Org name in command line, it does not get picked up automatically, so click edit to configure it


Add Organisation Name
or2.sys.cisco

Add vBond FQDN
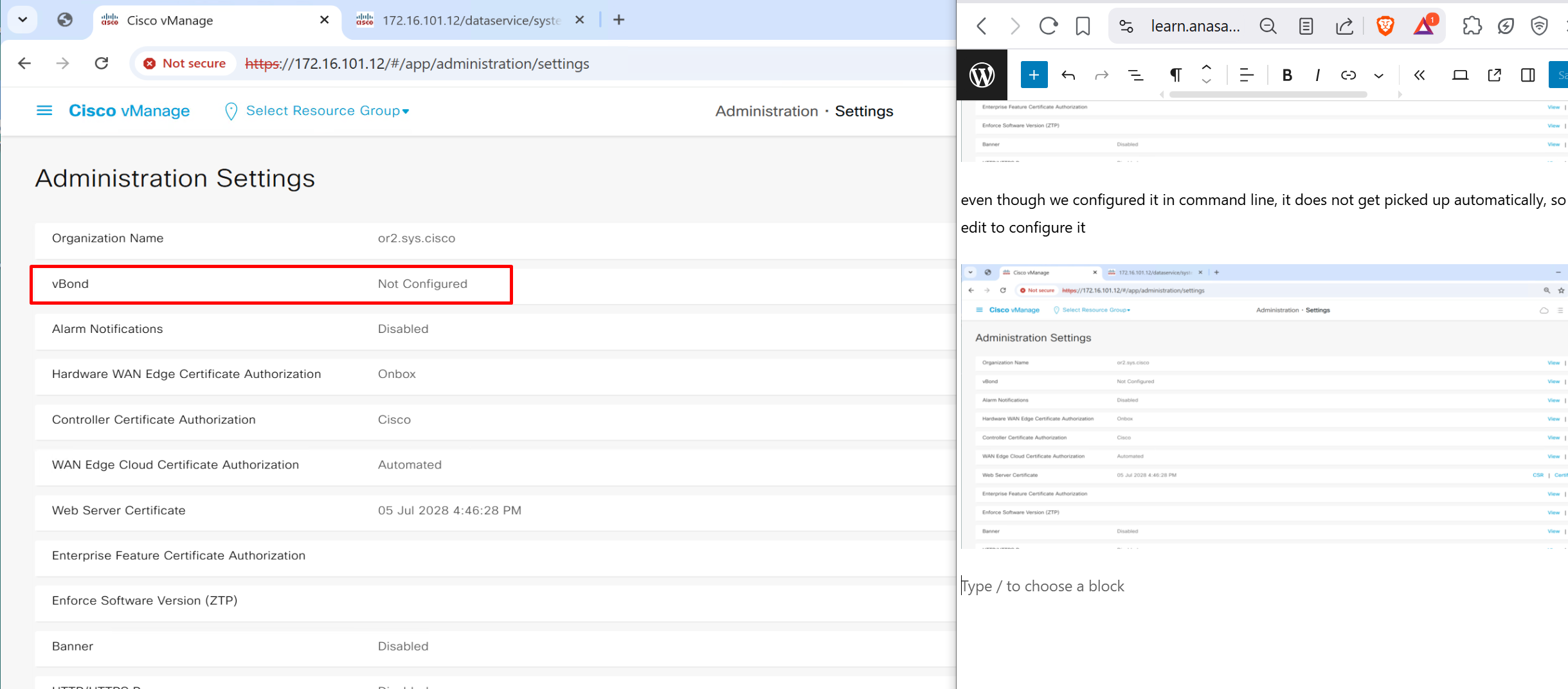
vbond.or.sys.cisco
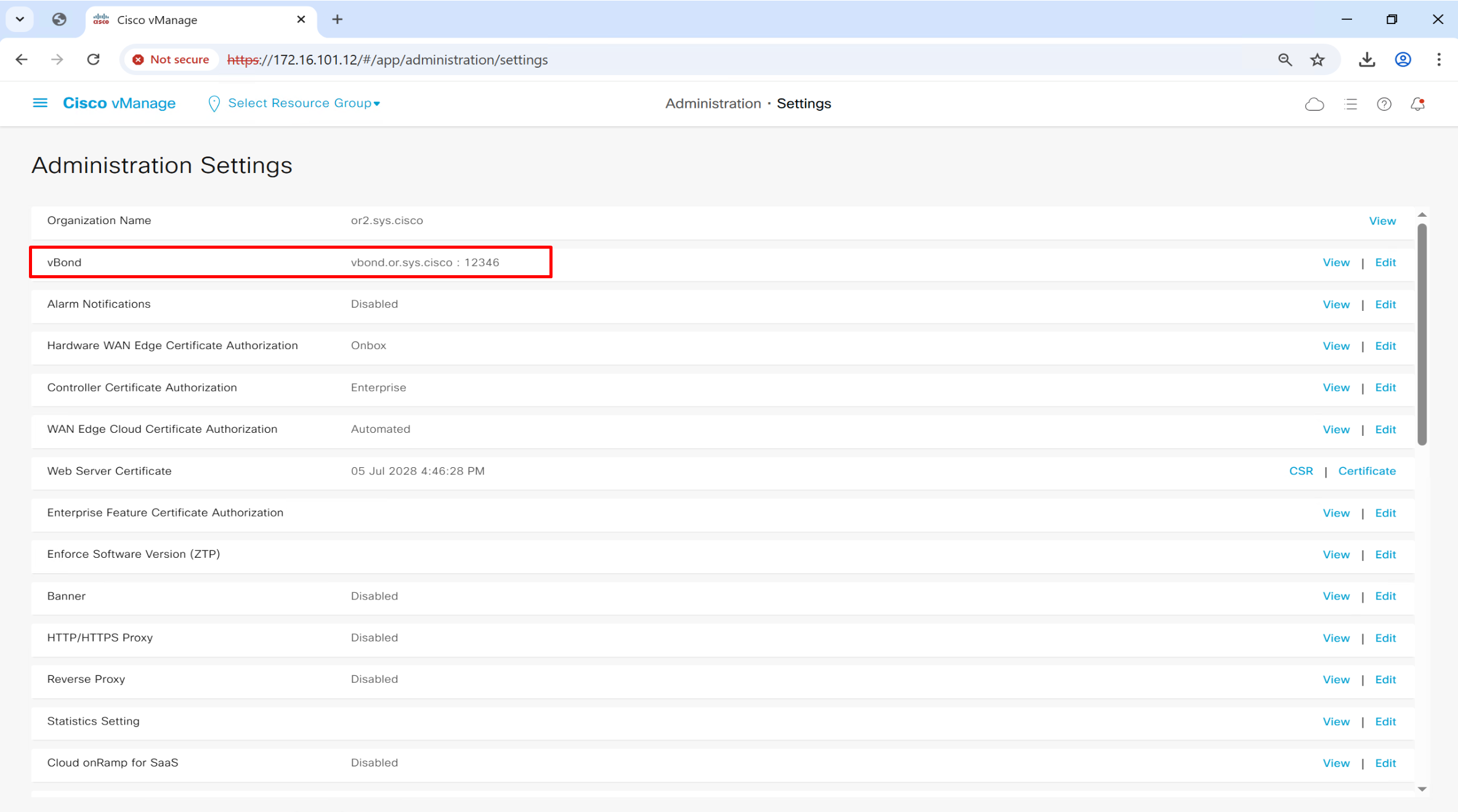
Controller Certificate Authorization mode
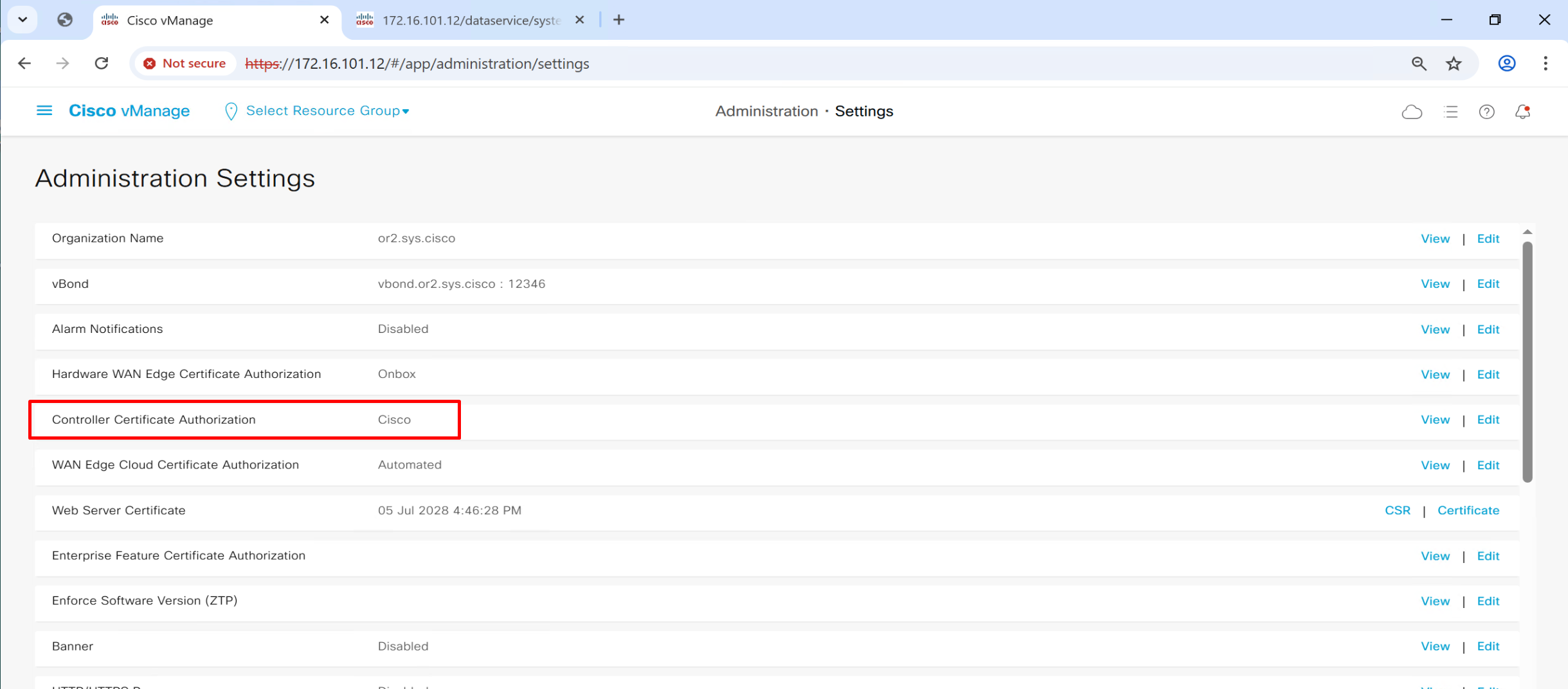
This is much simpler method as it uses Cisco’s Pre-installed Certificates

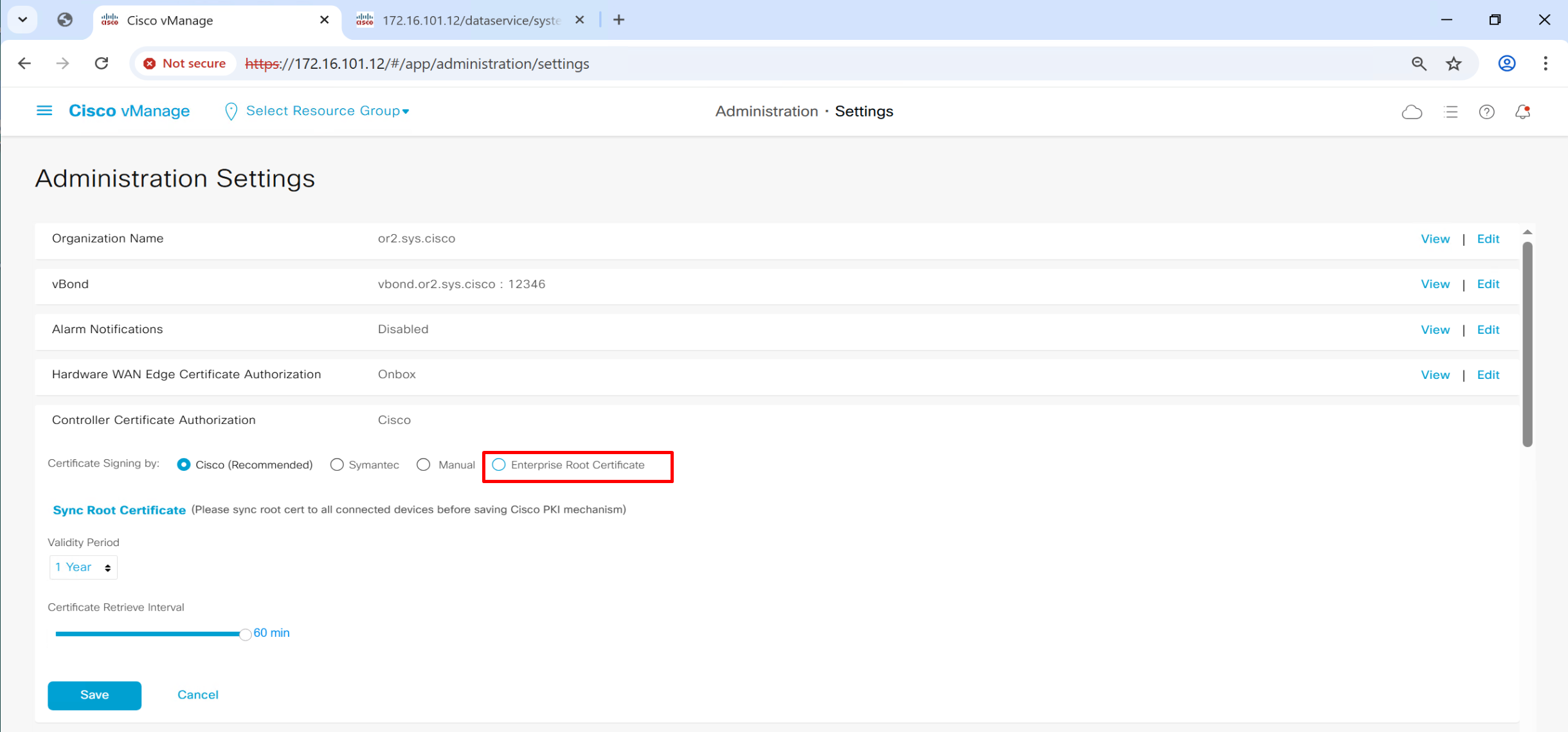
This root certificate can be same as the one added in the “trust store” earlier as this option is asking us to provide a root CA which will be used for “Authentication” for devices
this will tell other controllers vbond and vsmart to authenticate using this certificate

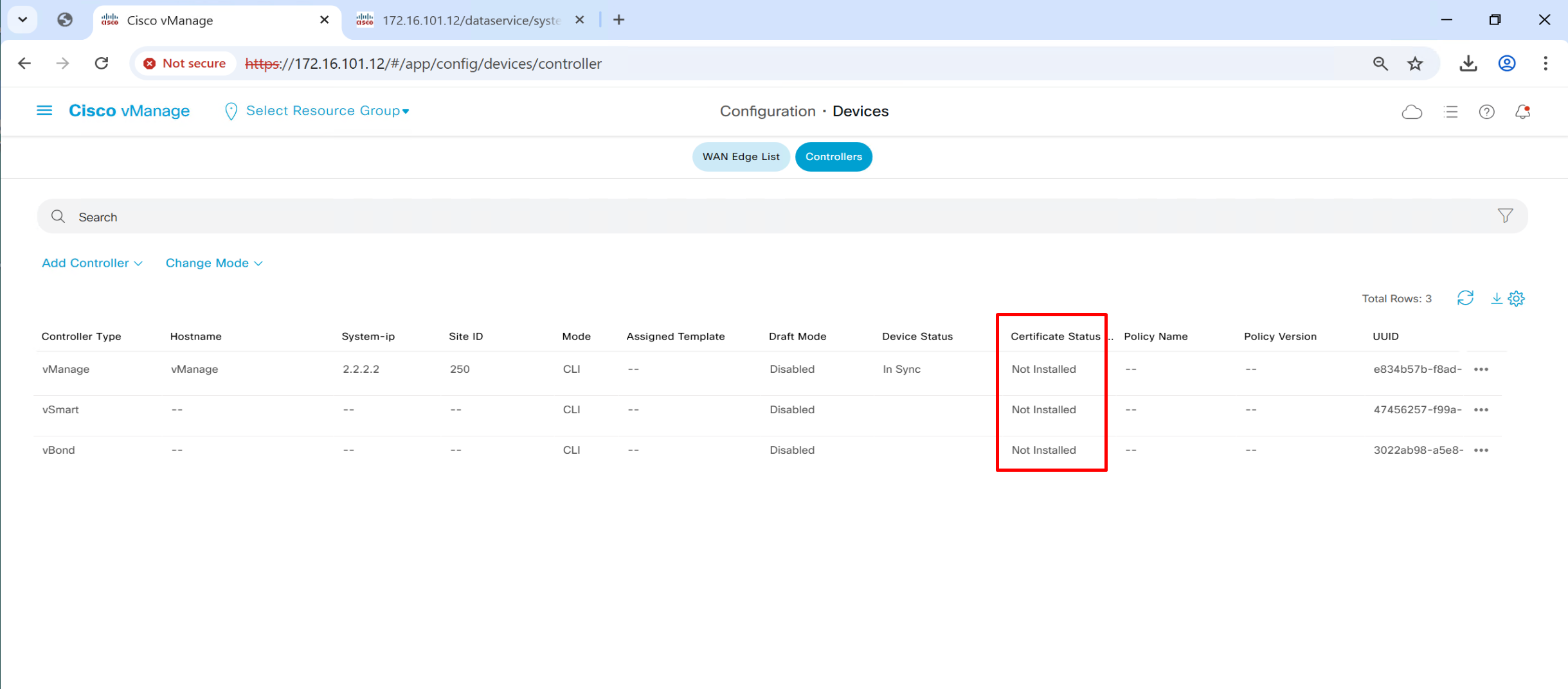
Now vmanage knows about the IP addresses of the controllers like authorization or whitelisting but they are not onboarded yet, before they can be onboarded on to fabric they need certificate that is signed by CA and this will be done using each controller CSR
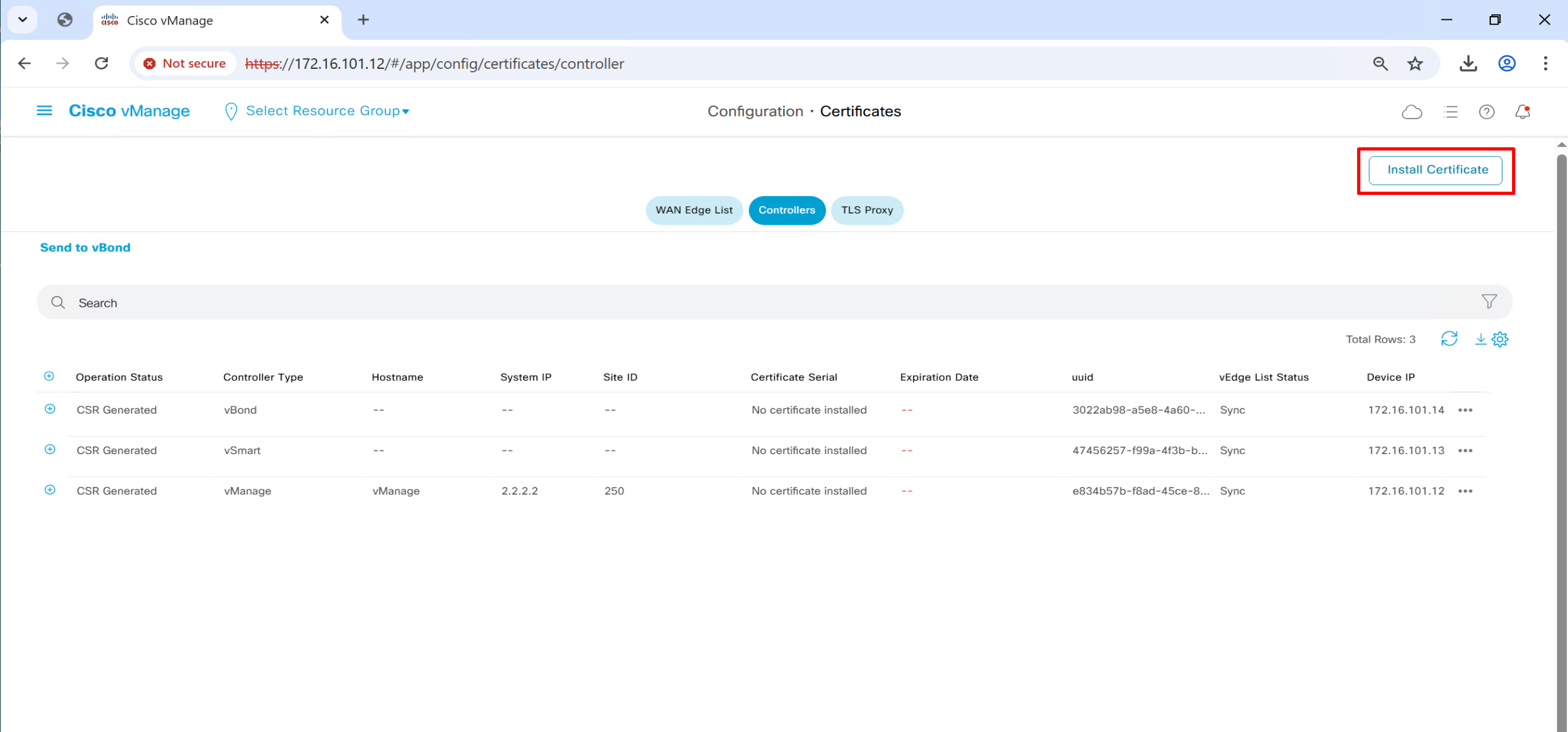
Install certificates on vSmart and vBond through vManage
Generate CSR per controller from vmanage

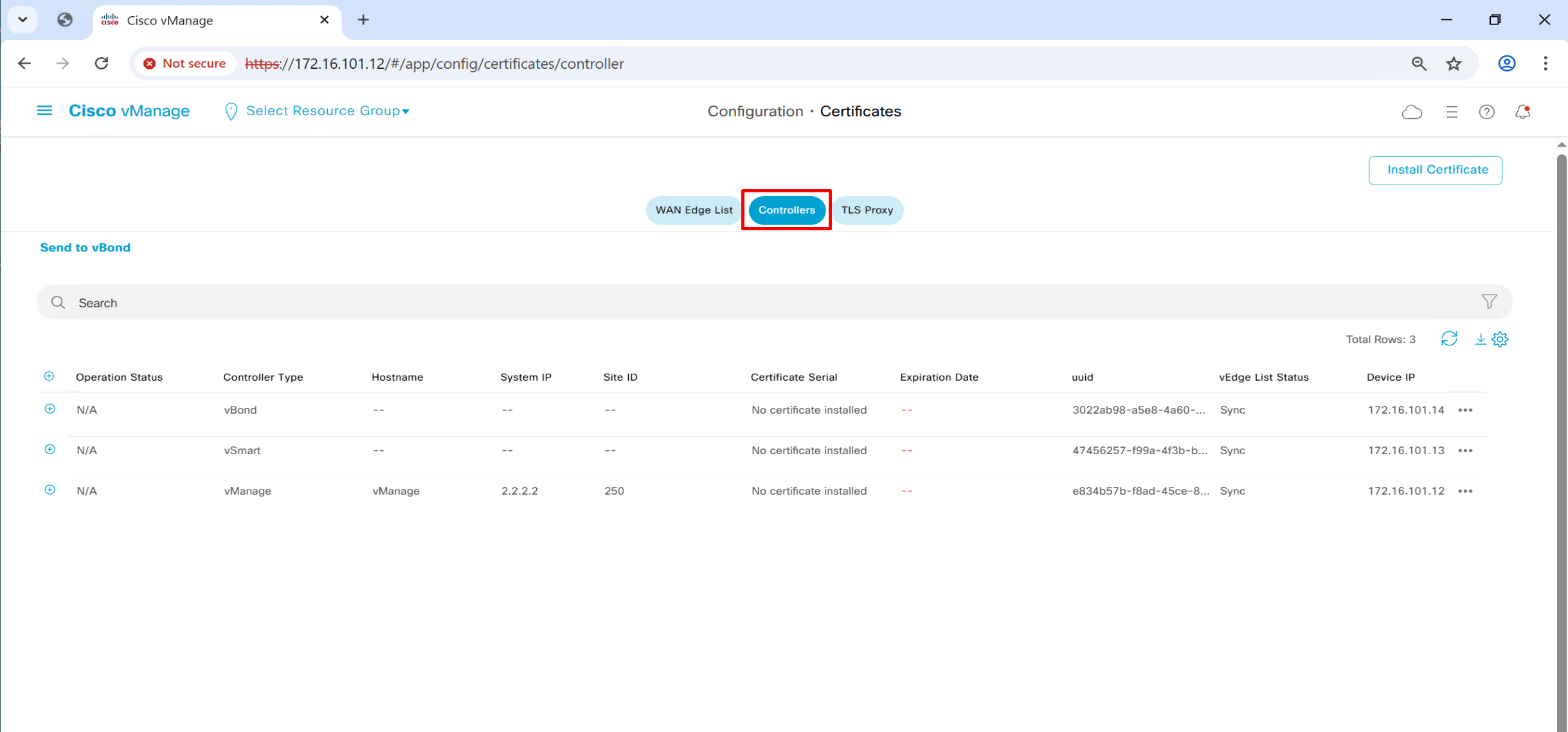
Click on vManage three dots > generate CSR
even vManage itself needs a certificate
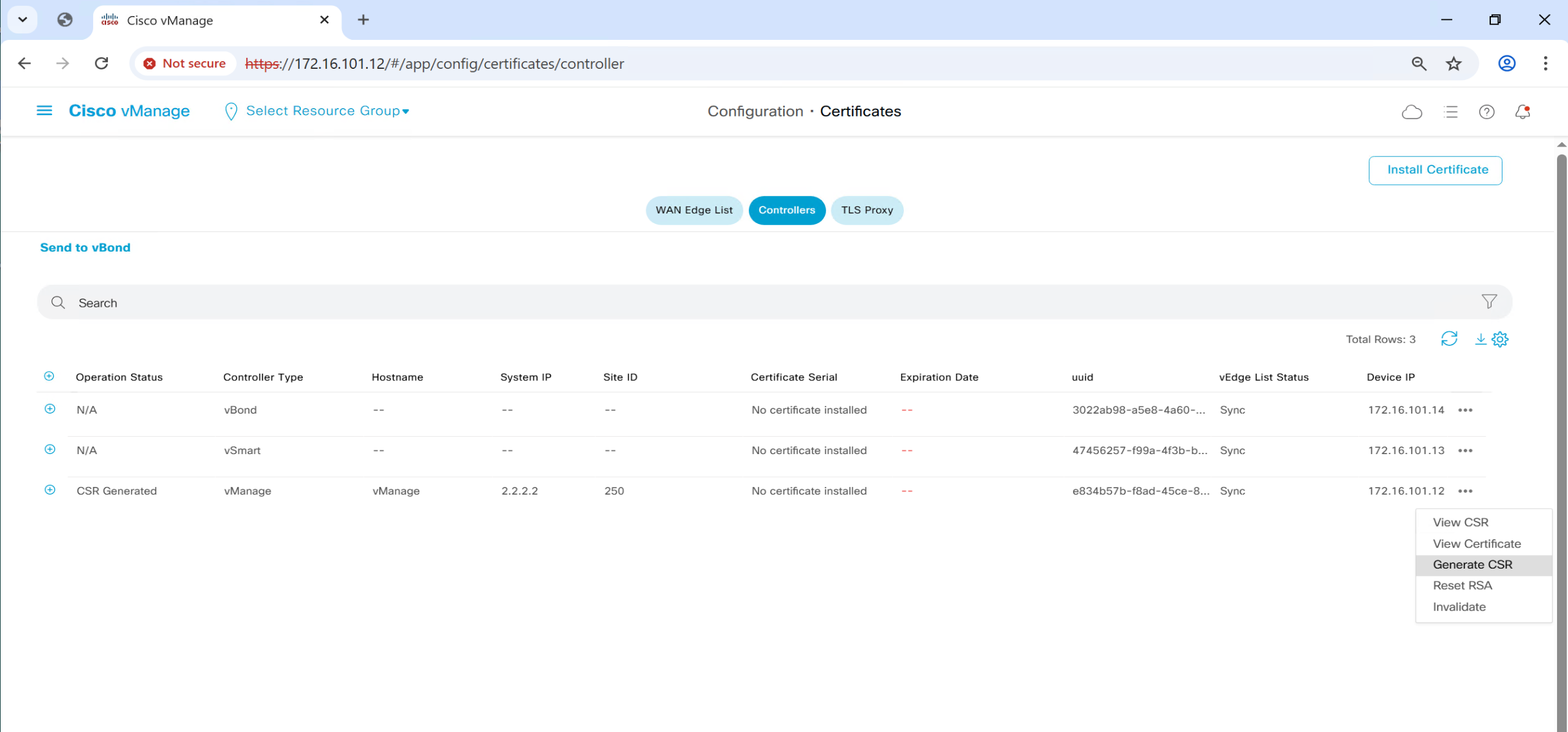
CSR for vSmart and vBond is generated and installed on vSmart and vBond
and it is then signed by our windows server CA, so when this cert is presented to vmanage, it can trust the presented cert
and once certificates are “issued” by vmanage to vbond and vsmart,
a certificate based mutual authentication will take place before controllers are added to fabric in vmanage

Click on download
same process is required for vmanage as well because vmanage also needs to issue certificate to itself
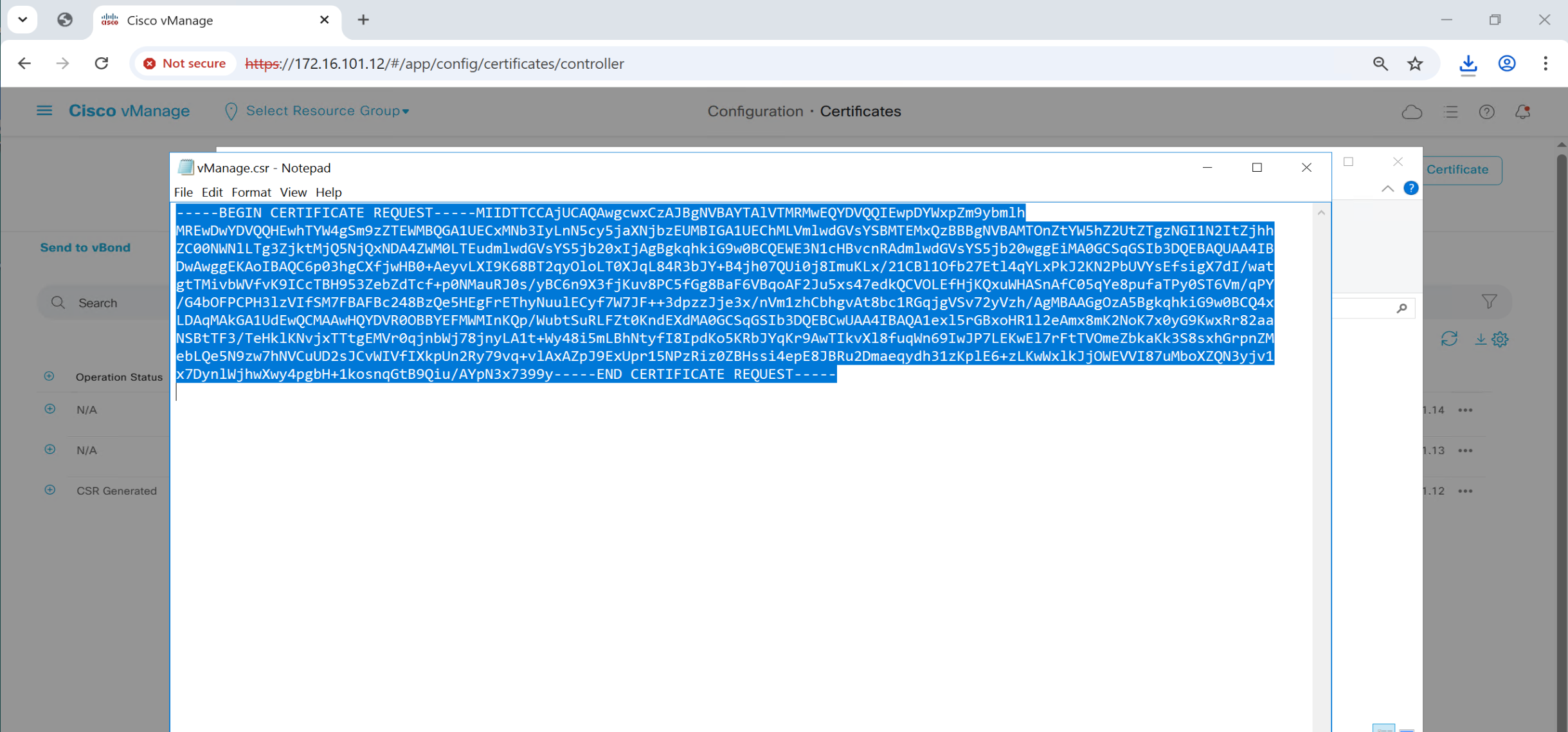
Copy and paste it to certsrv
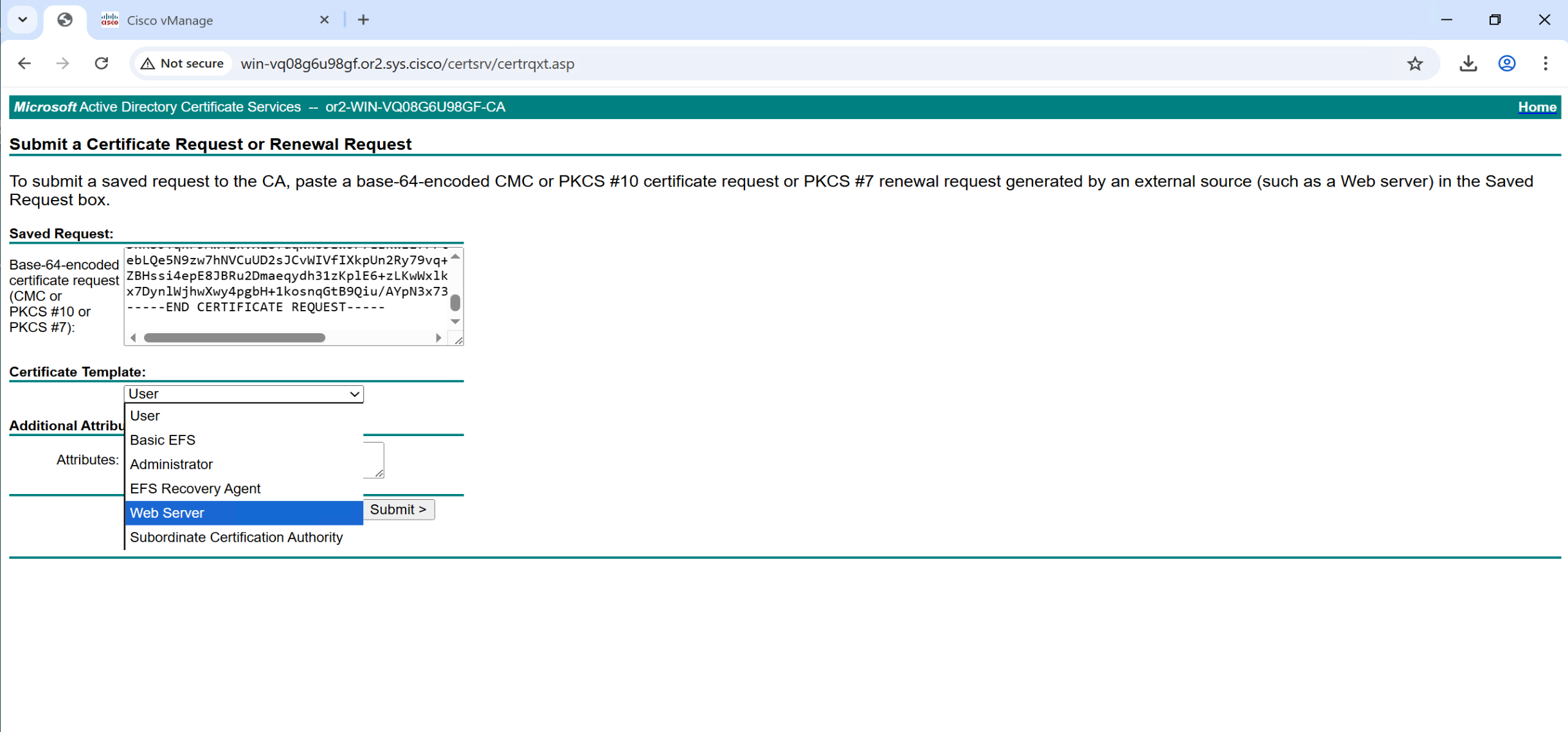

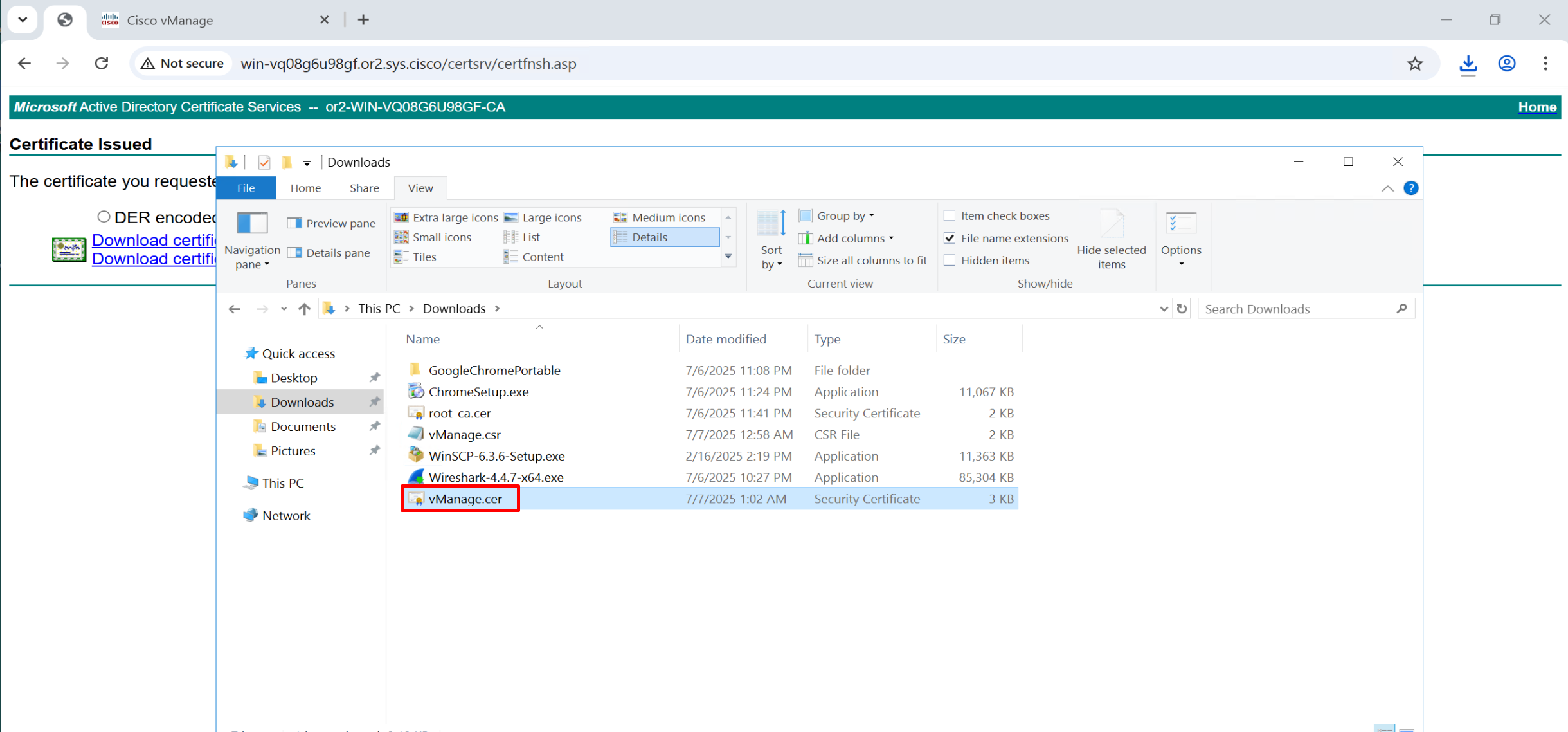
Repeat same process of CSR generate for vsmart and vbond as well
Install Certificates
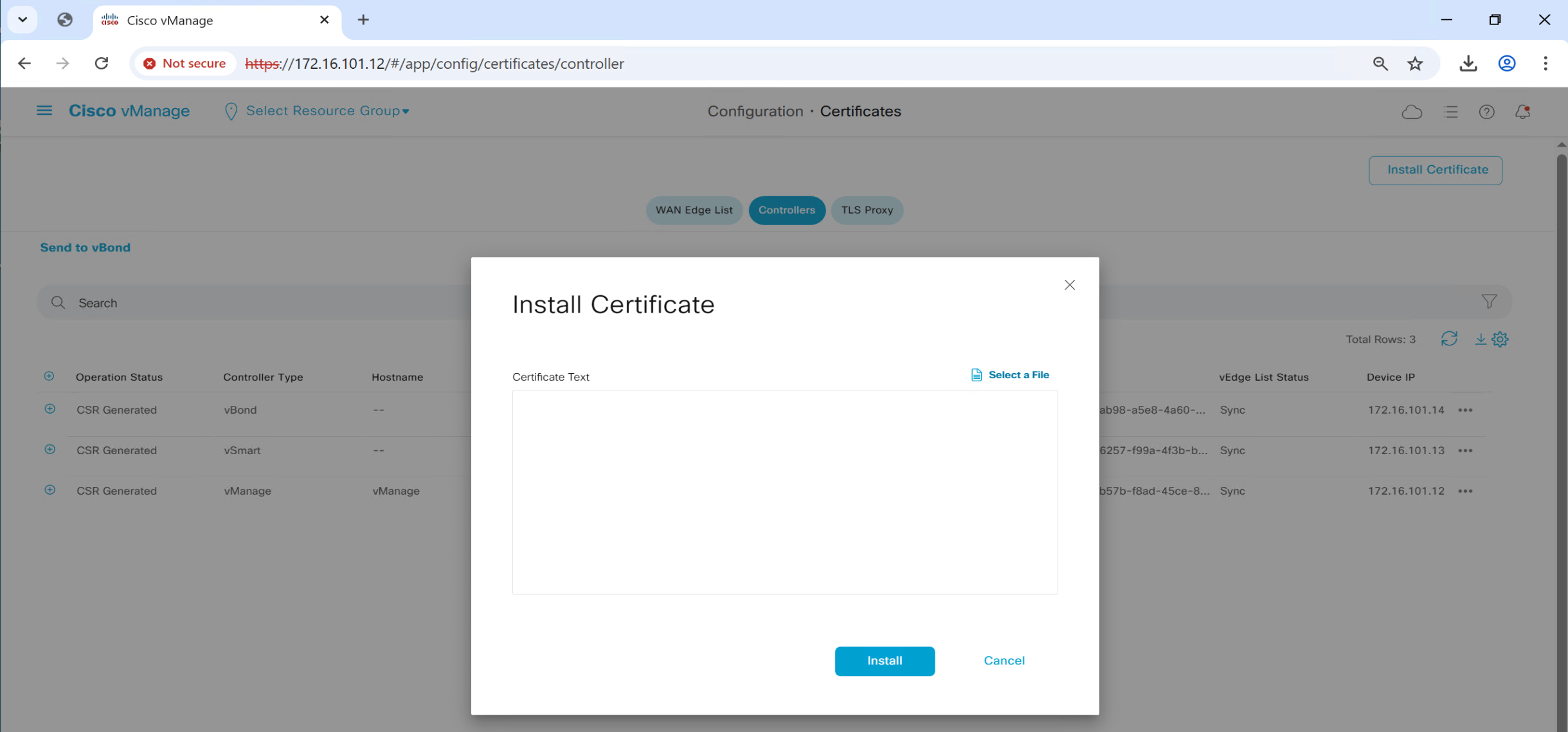
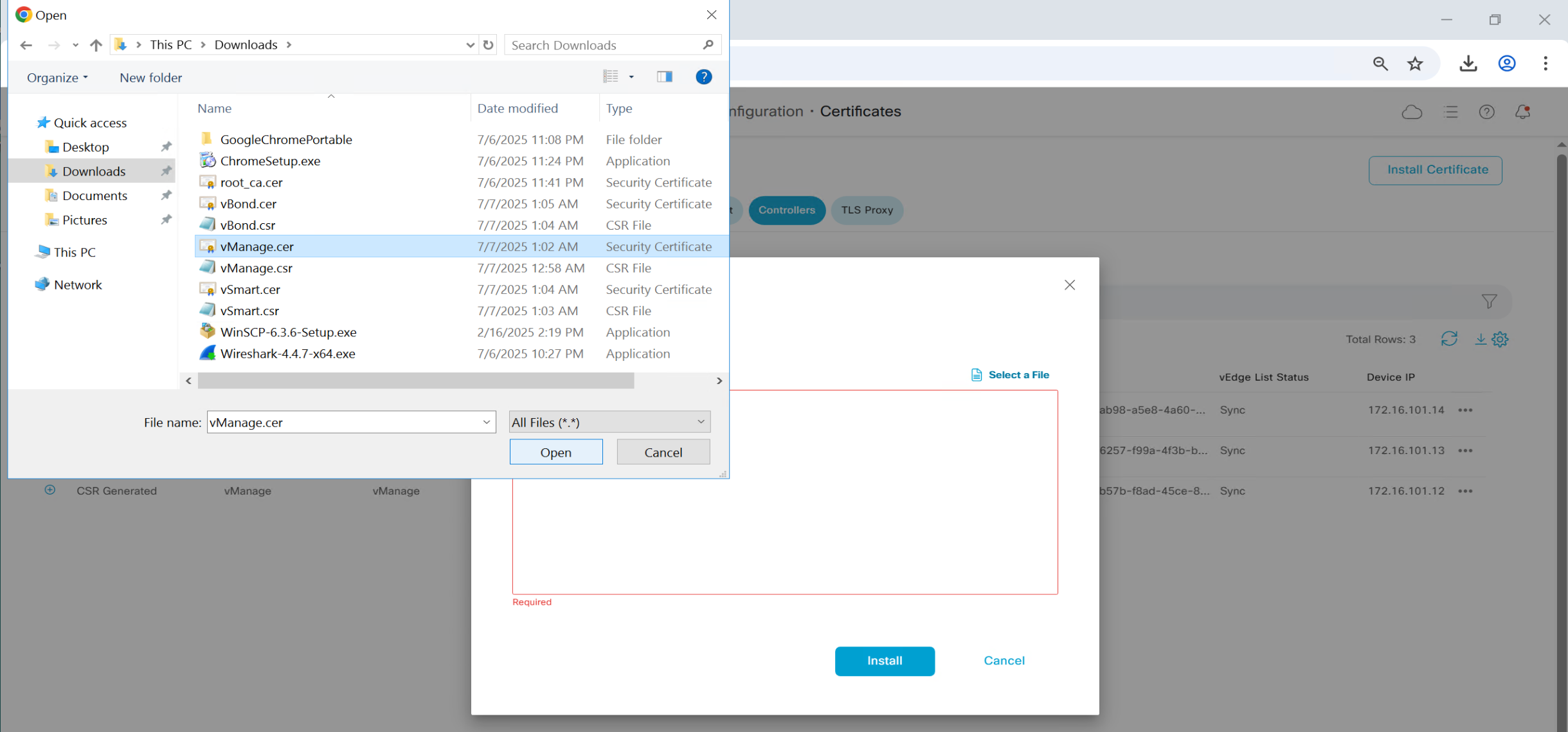



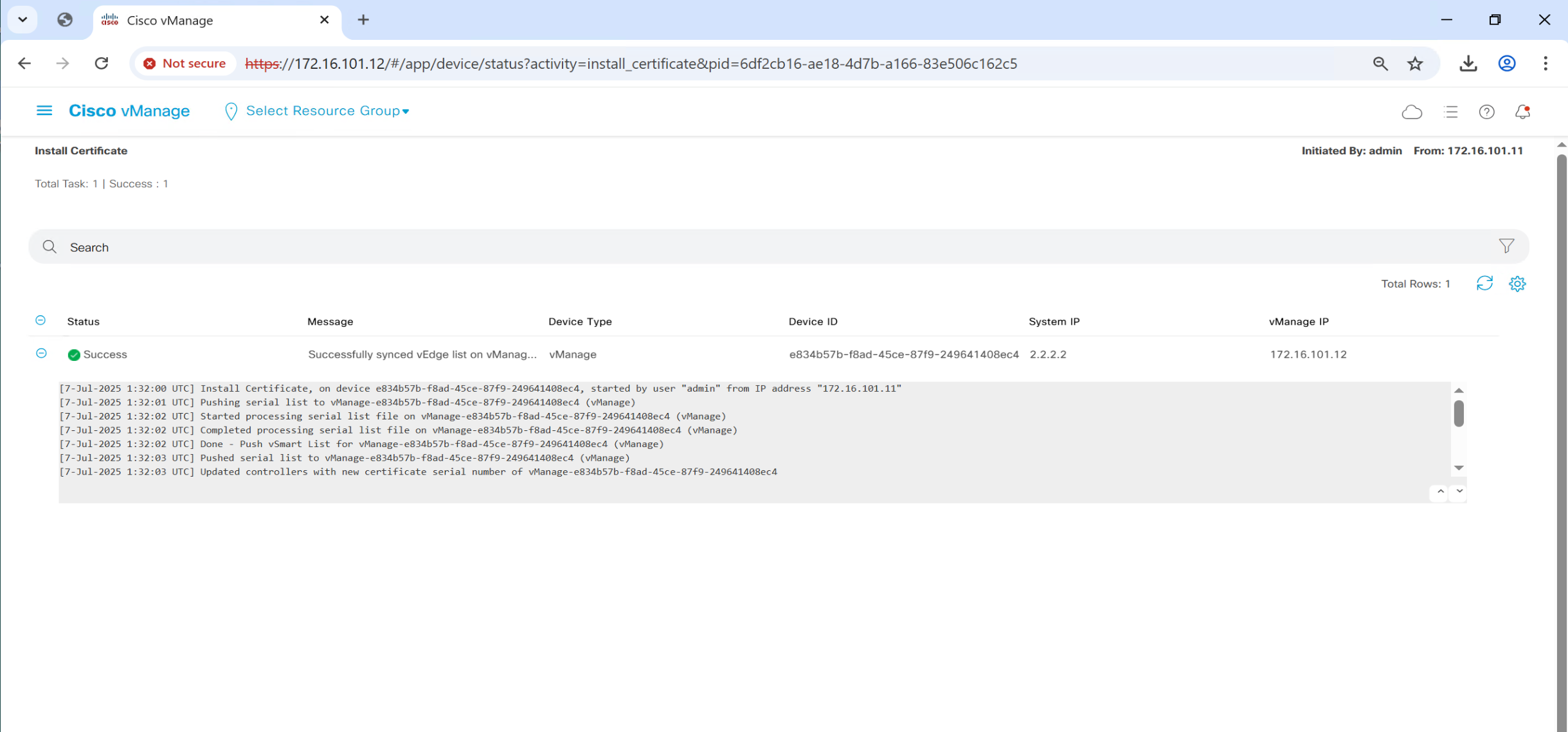

Follow same steps to install certificates on other controllers

in above screenshot we can see that “site ID” is still missing and “System IP” also
This has to do with tunnel interface, as the “site ID and System IP” are exchanged over fabric
so we need to bring up the tunnel interface with allowed services which are safe over WAN or internet such as HTTP and icmp etc, Allowed service are both inbound and outbound
such as NTP will be outbound but SSH will be inbound
vManage tunnel interface
vpn 0
interface eth0
tunnel-interface ! DTLS tunnel
allow-service all ! only use all in lab for prod restrict services
allow-service sshd
allow-service ntp
allow-service dns
allow-service httpsvSmart tunnel interface
vpn 0
interface eth0
tunnel-interface ! DTLS tunnel
allow-service all ! only use all in lab for prod restrict services
allow-service sshd
allow-service ntp
allow-service dns
allow-service httpsvBond tunnel interface
vpn 0
interface ge0/0
tunnel-interface ! DTLS tunnel
encapsulation ipsec ! this is also required in case of vbond
allow-service allafter bringing up the tunnel interface we can see that system IP, hostname and site ID are present
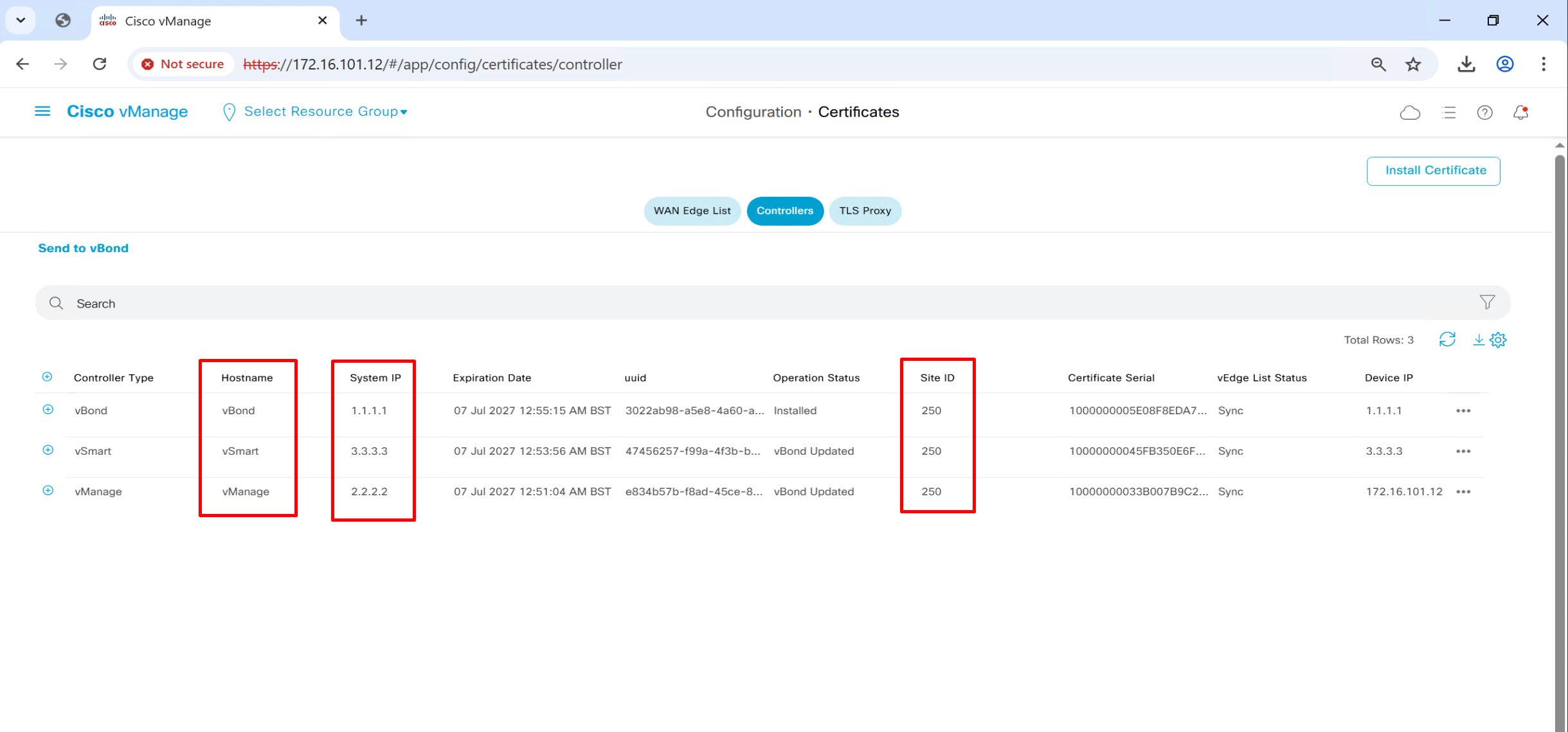
we have successfully onboarded the controllers
vManage commands
show runn
conf t
system
show configuration
commit
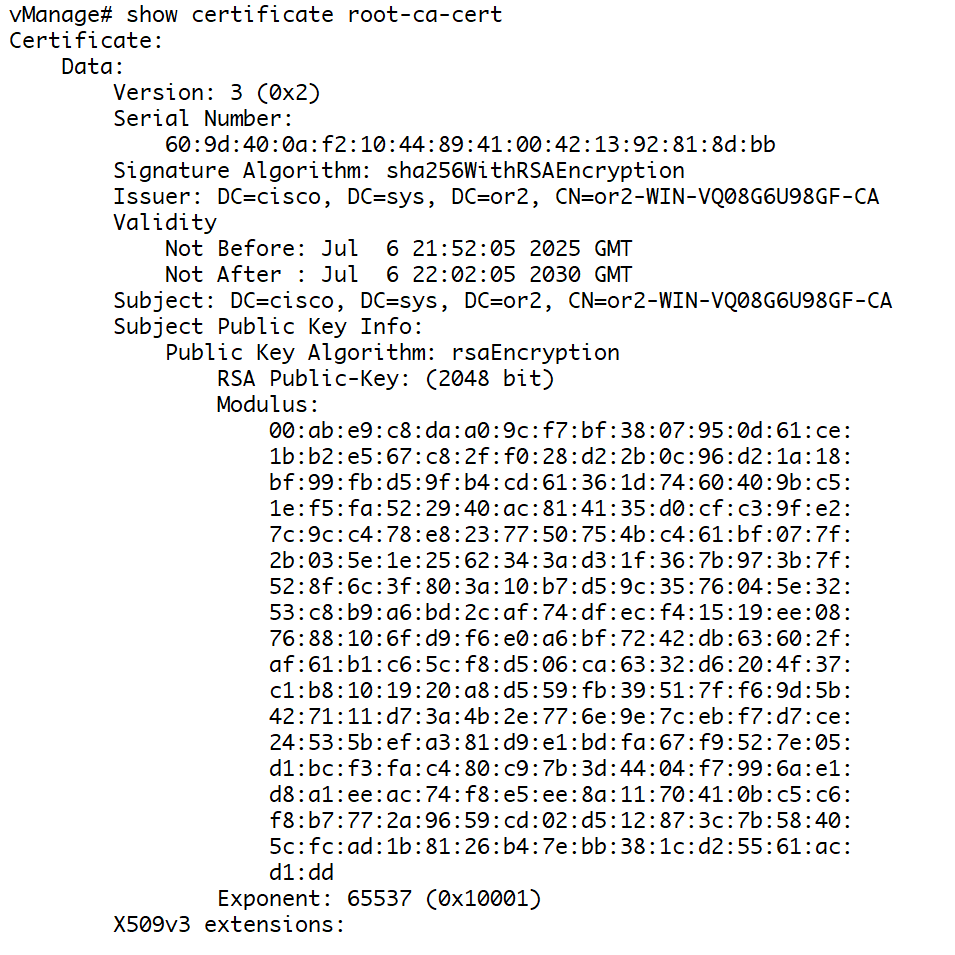
show certificate root-ca-cert ! to see installed root-ca cert
show ntp associations
show run vpn 0
show control local-properties
vbond commands
show orchestrator connections
one DTLS connection per vmanage CPU core with vmanage
show orchestrator valid-vsmarts
first one is vmanage and other one is vsmart
vsmart commands
show control connections 
Web certificate for vmanage
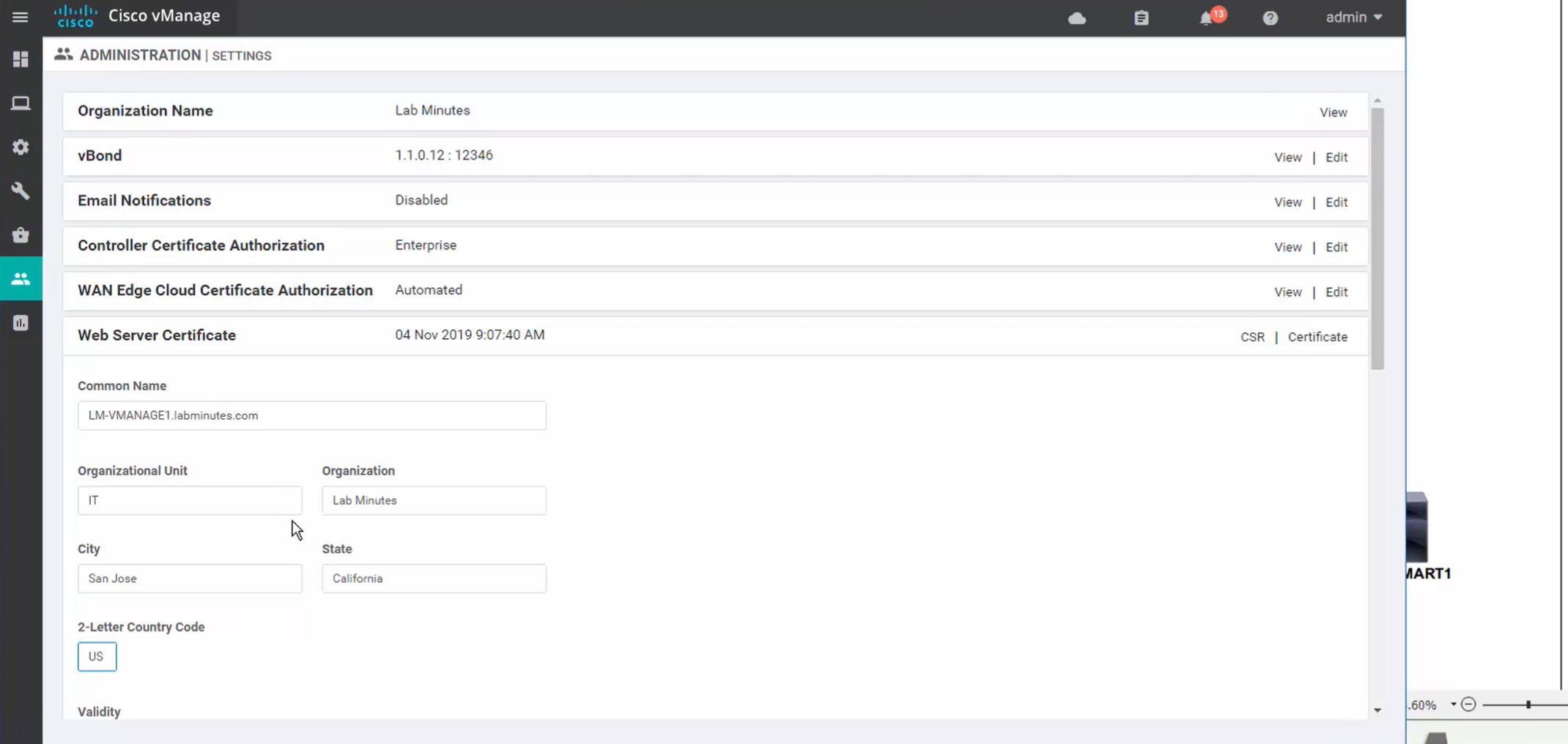
We will get the CSR

it needs to be signed by CA


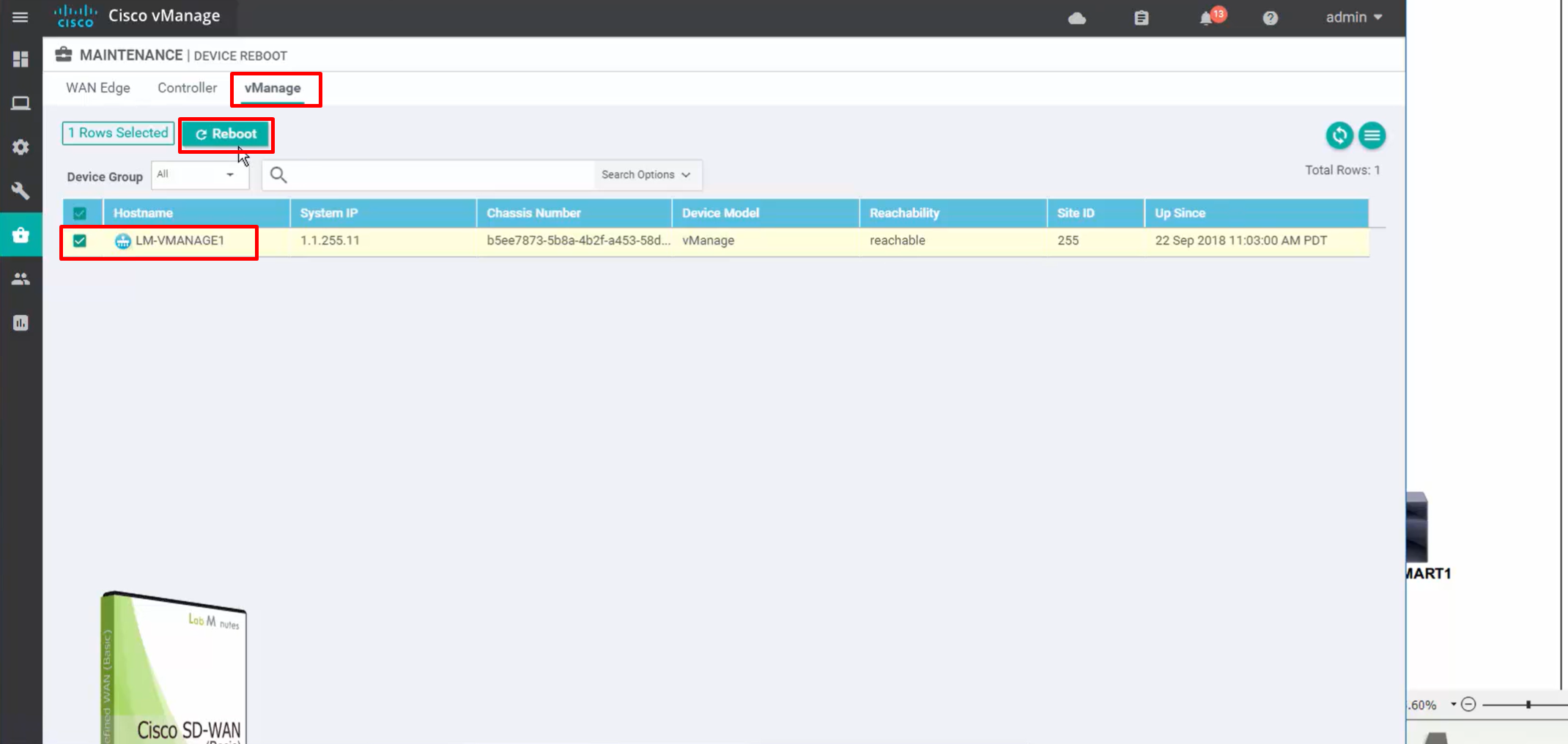
for certificate to take effect, we need to reboot the vmanage
under maintenance, device reboot

Edge device onboarding
Virtual cEdge devices themselves do not have any chassis numbers,
in order to get those chassis number we need to go to software.cisco.com, on the portal we need to define the vbond IP (best to define FQDN for flexibility in serial file) and Org name.
There is a different process for hardware edge devices,
For Virtual devices we specify how many virtual devices we want to generate chassis numbers for.
If we have hardware routers then we have to enter the serial numbers, PID and certificate serial number from routers into the portal
Extracted serialFile_new.viptela
The file appears to be in a compressed binary format, starting with the byte sequence \x1f\x8b\x08, which is the standard signature for a GZIP-compressed file.
I’ll attempt to decompress the file and then read its contents. Let’s proceed.
The decompressed file starts with the text viptela_serial_file, which suggests it is a Viptela serial file (used in SD-WAN deployments). However, the rest of the content contains what looks like binary padding and possibly a tar archive header, indicated by terms like ustar.
This means the GZIP file likely contains a tar archive, not a plain text file. Let me try extracting the tar contents and see what files it contains.
The archive contains the following files:
viptela_serial_file– likely the main serial/license file.viptela_serial_file.sig– likely a digital signature file to verify authenticity.cisco_cert.cer– a Cisco certificate, probably used for validation.
I’ll extract and display the contents of the main viptela_serial_file first.
The viptela_serial_file contains JSON data representing serial information for Cisco SD-WAN devices. Here’s a summary of what’s inside:
✅ Key Information Extracted:
- Version: 1.1
- Organization:
or2.sys.cisco
- Organization:
- Overlay Network:
SD-WAN-3 - 388033 - vBond Controller:
vbond.or.sys.cisco(DTLS port 12346) - Timestamp: 2022-02-25 00:06:49
✅ Chassis & Serial Numbers:
The file lists multiple devices, each with:
- Chassis ID (example:
4567A82E-54D1-FA17-E1A4-302781B96194) - SKU: (e.g.,
VEDGE-CLOUD-DNA,C8000V,CSR1KV) - HWPID: Hardware Product ID
- Serial Number: matches the chassis ID in each case
- No SUDI (Secure Unique Device Identifier) certificates included (fields are empty).
Create new DNS zone
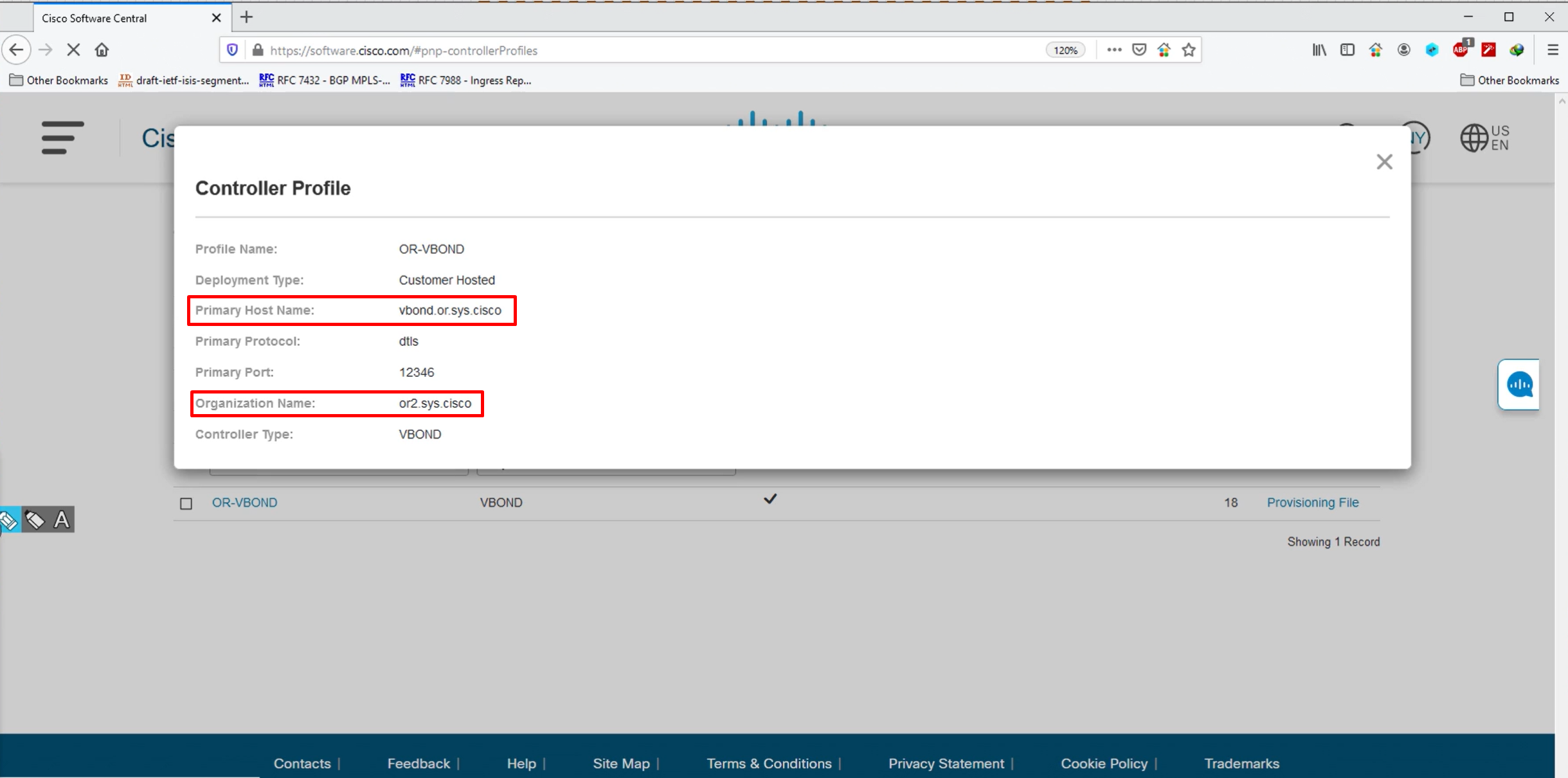
Since the .viptella serial file contains org name as or2.sys.cisco but it vbond profile has vbond FQDN as vbond.or.sys.cisco, we will create another DNS zone
Right-click on “Forward Lookup Zones” (or Reverse Lookup Zones if needed) ➔ New Zone…
In the New Zone Wizard:
- Select Primary zone (if this is the main copy).
- Choose whether to store the zone in Active Directory (recommended).
- Select the replication scope – all DNS servers in the forest.
- Enter your zone name or.sys.cisco
- Choose how to handle dynamic updates – secure and non-secure.
- Complete the wizard.

Generate .viptela serial file
These devices PID and serial numbers will be empty when you first create Smart account and virtual account, once have been assigned chassis numbers and associated to the org show up as green and “provisioned”
This section is where we define the vBond info with FQDN or IP and Org info

You define the PID of the device, quantity of devices and the vbond profile – this allowance will be added to our .viptela serial file


After submitting this wait for devices to be provisioned status

once all devices are provisioned, click on Controller profiles

Select the controller version

Upload .viptela serial file
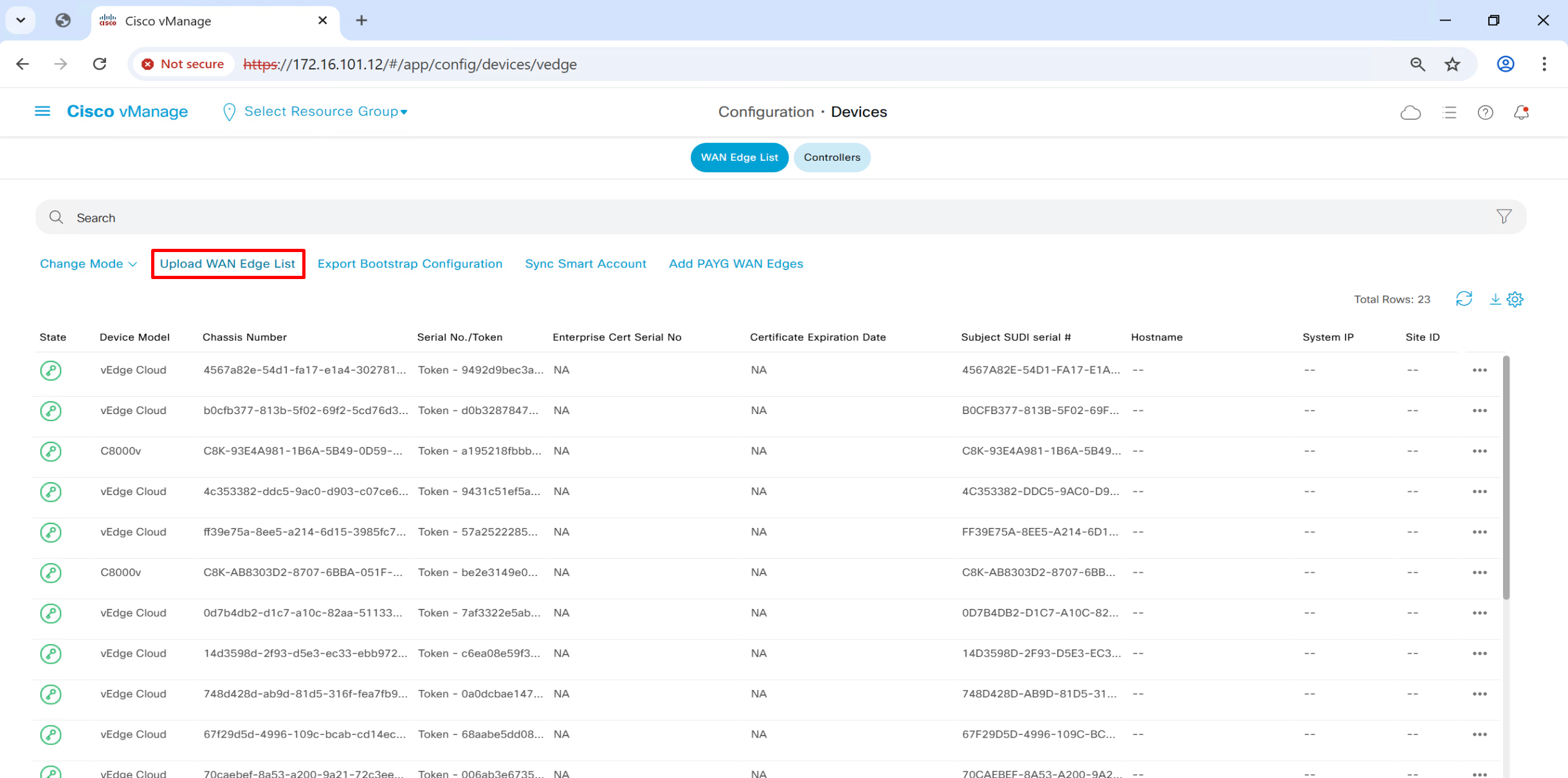

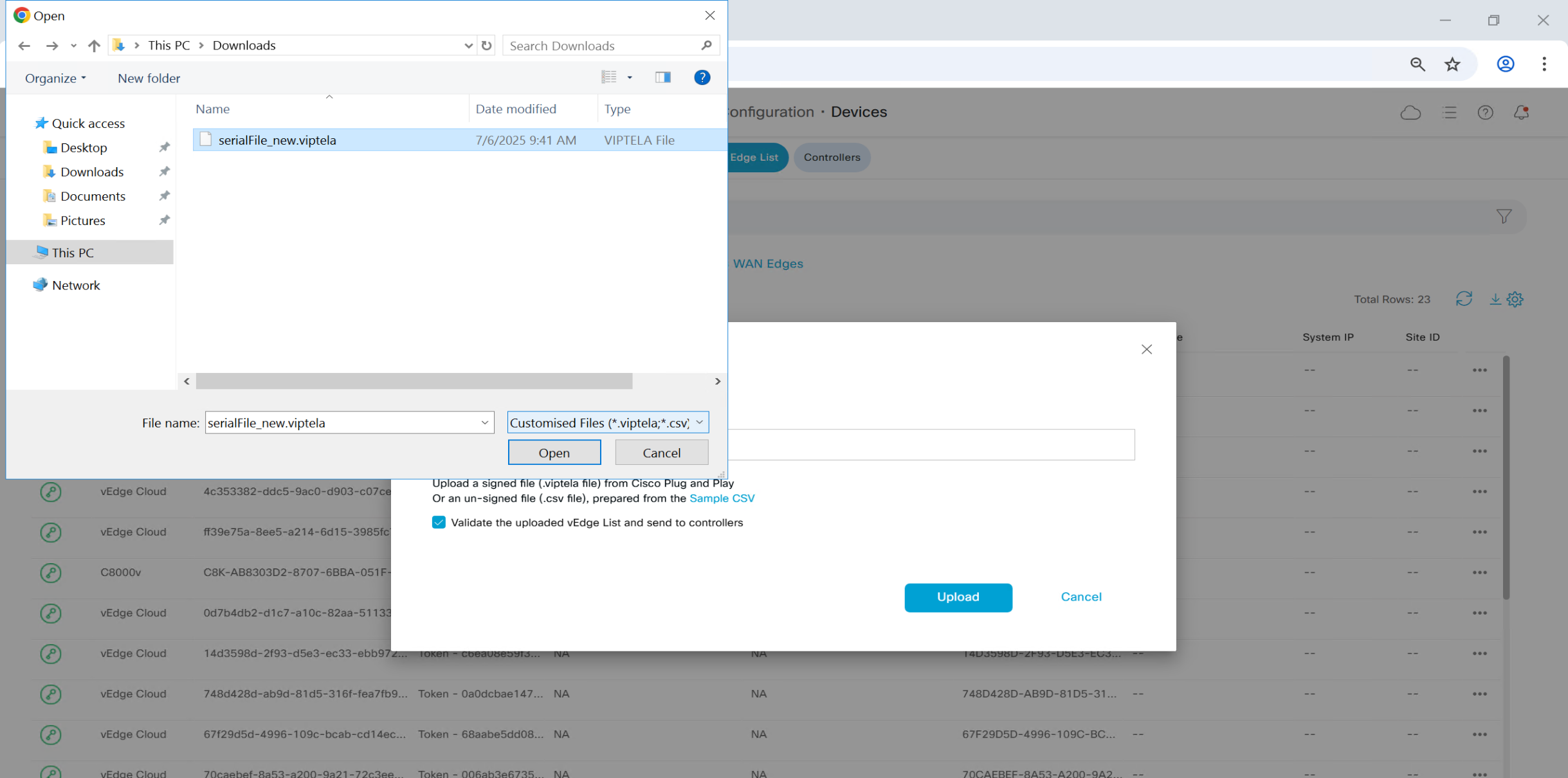
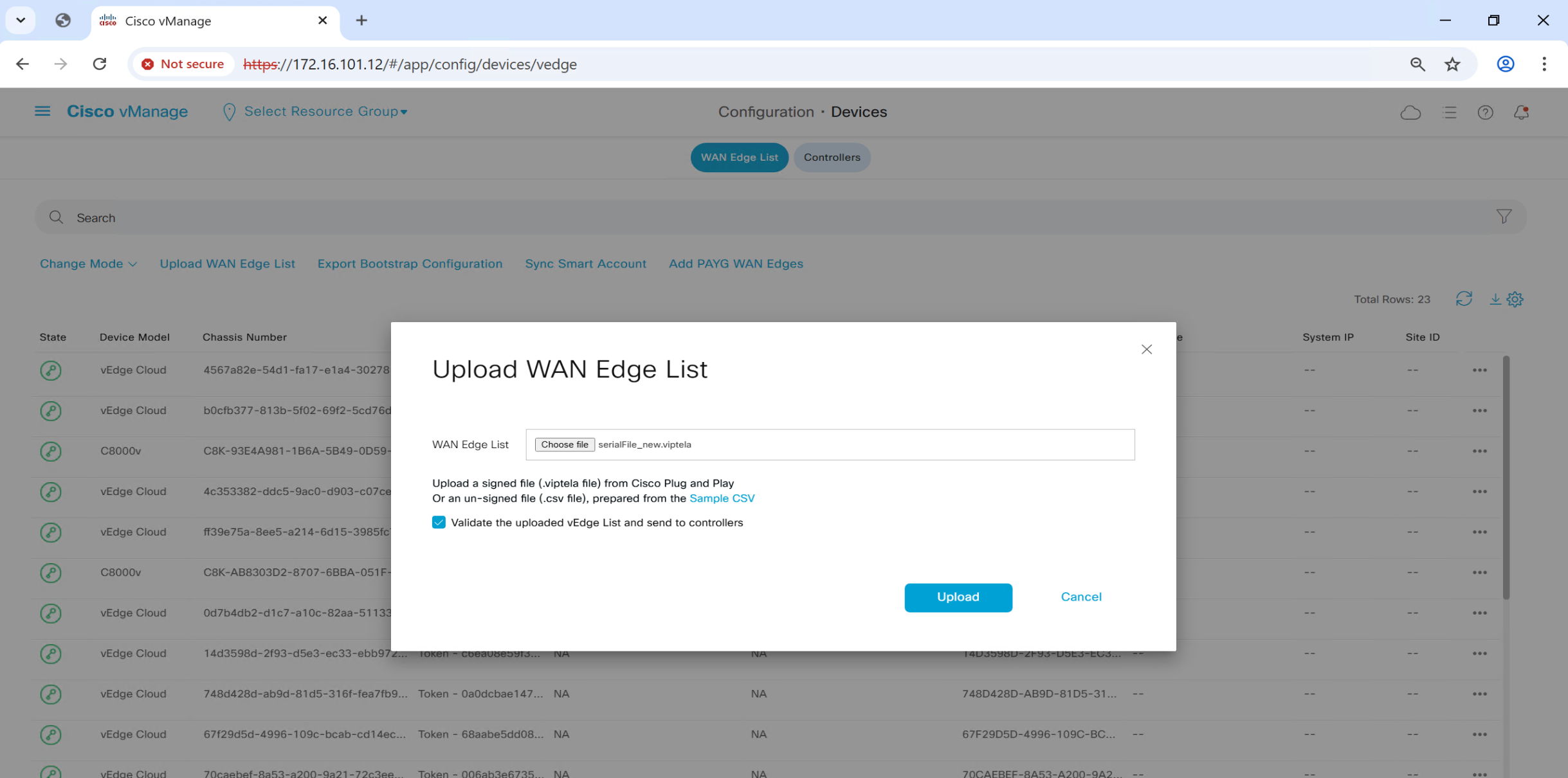
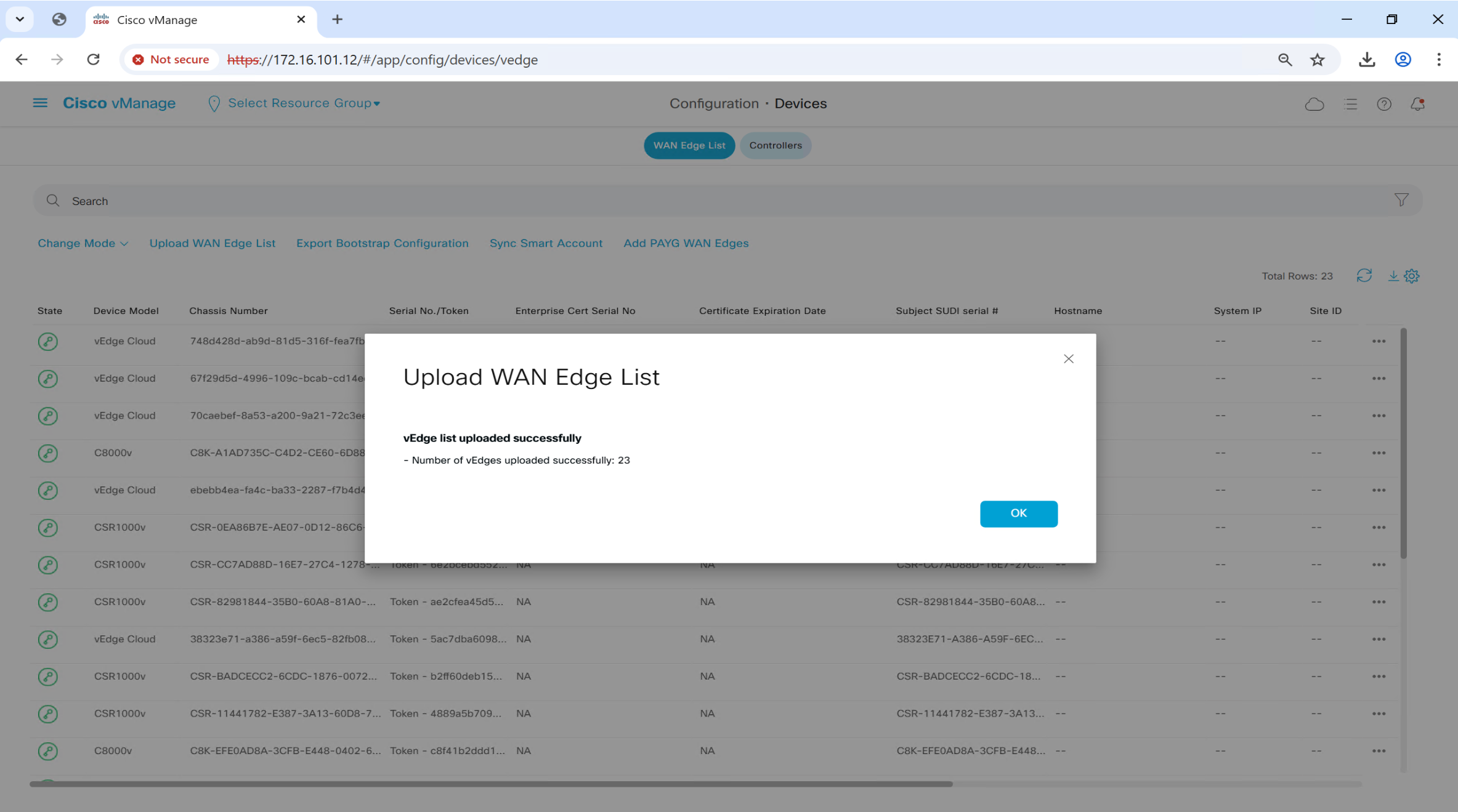
once file is uploaded, it will be pushed by vmanage to all other controllers
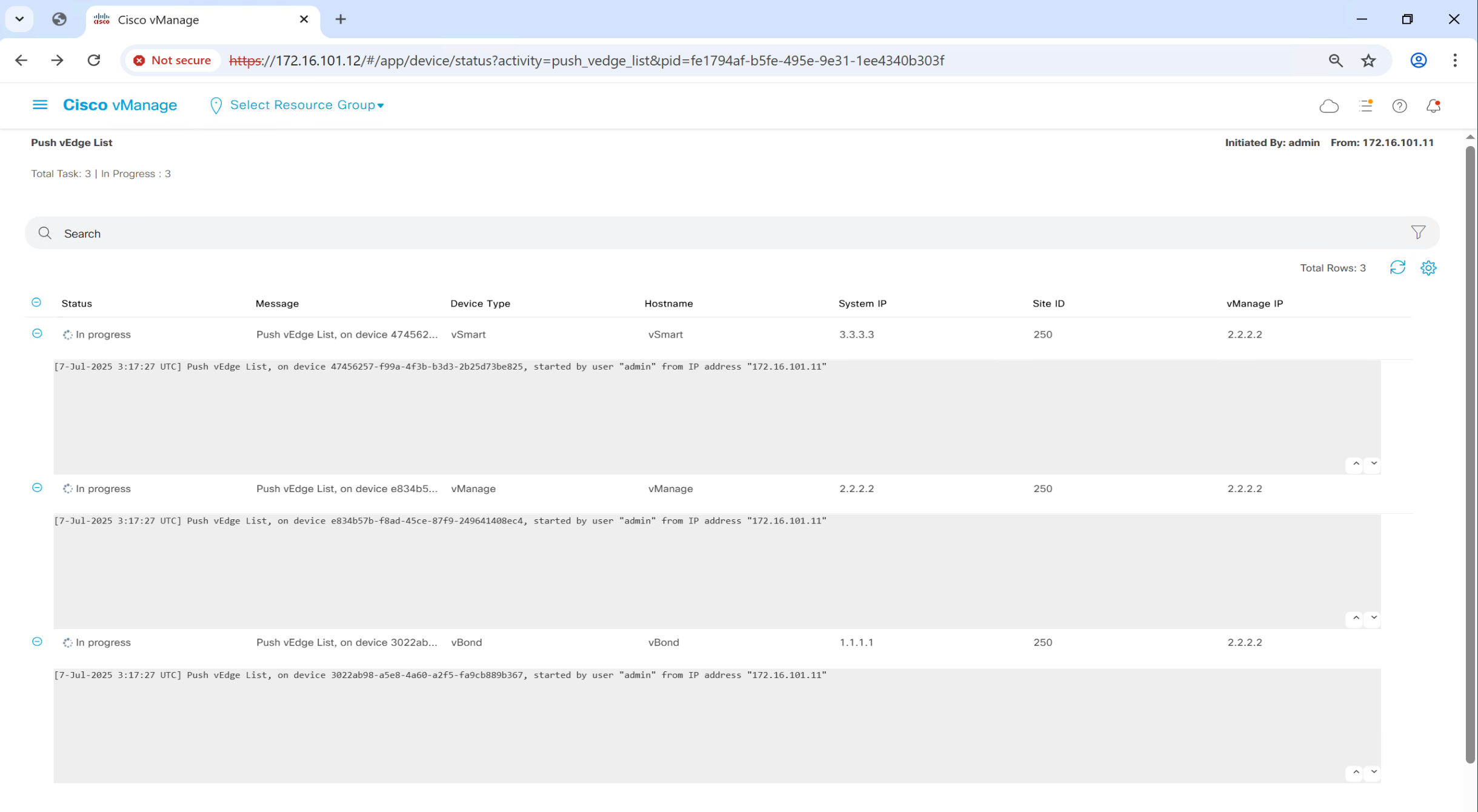
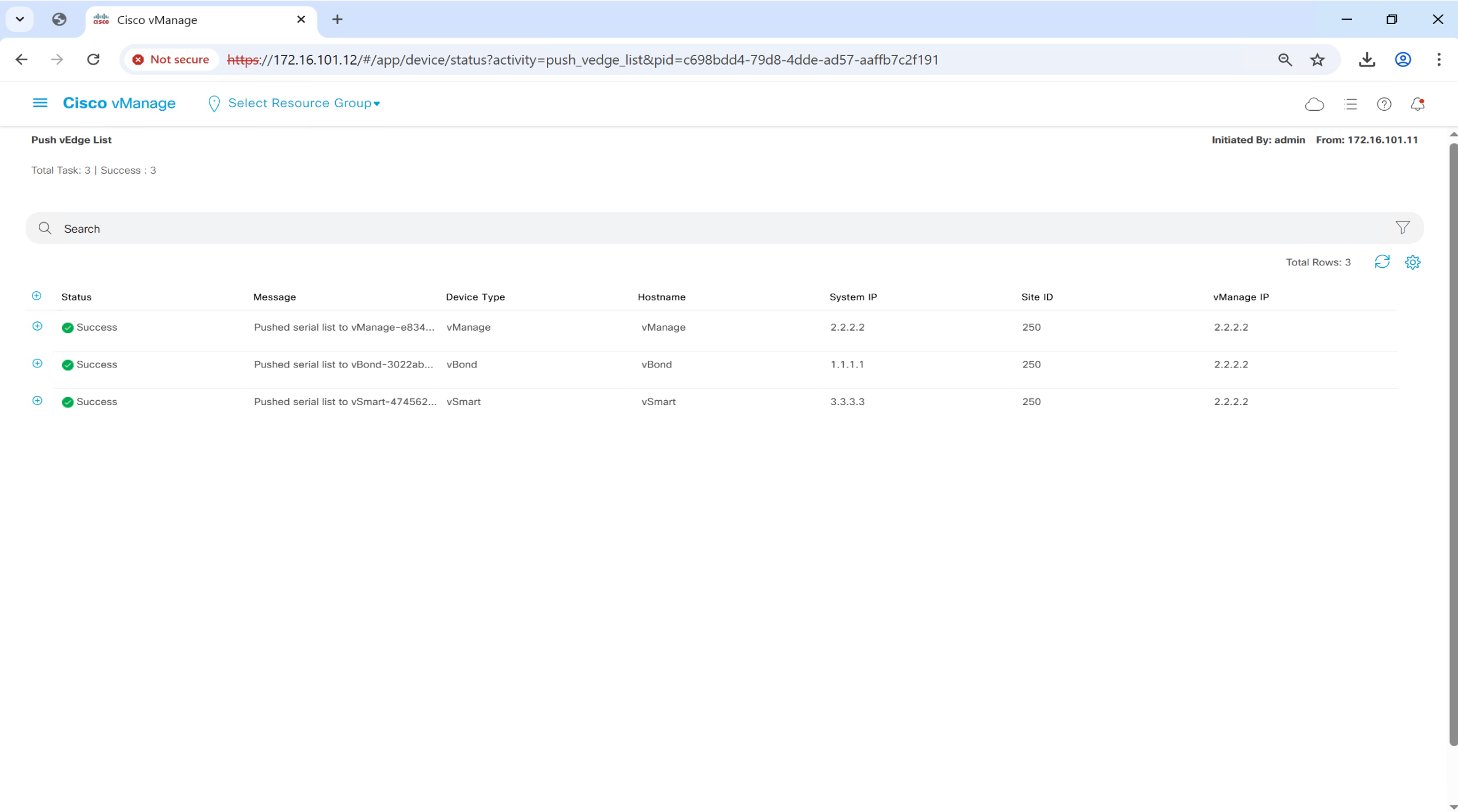
If we go to devices now
you will see available devices, this serial file has some C8000v and vEdge devices
Get rid of this annoying error message

Login to vmanage CLI
vManage# request nms configuration-db update-admin-user
Enter current user name:neo4j
Enter current user password:password
Enter new user name:admin
Enter new user password:C0mplex30
configuration-db
WARNING: sun.reflect.Reflection.getCallerClass is not supported. This will impact performance.
Successfully updated configuration database admin user
Successfully restarted NMS application server
Successfully restarted NMS data collection agent
vManage# Setting up watches.
Watches established.This will restart the vmanage
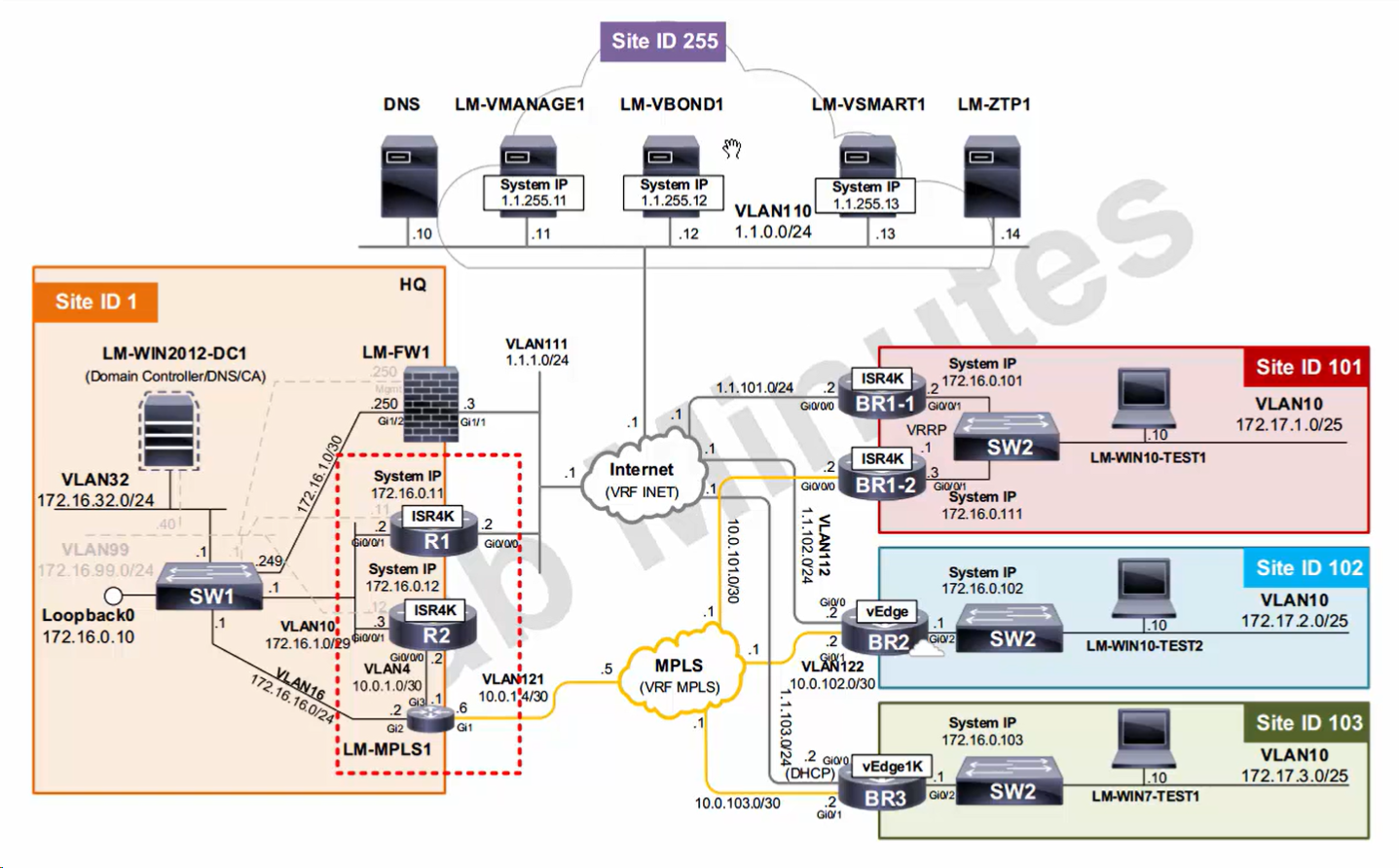
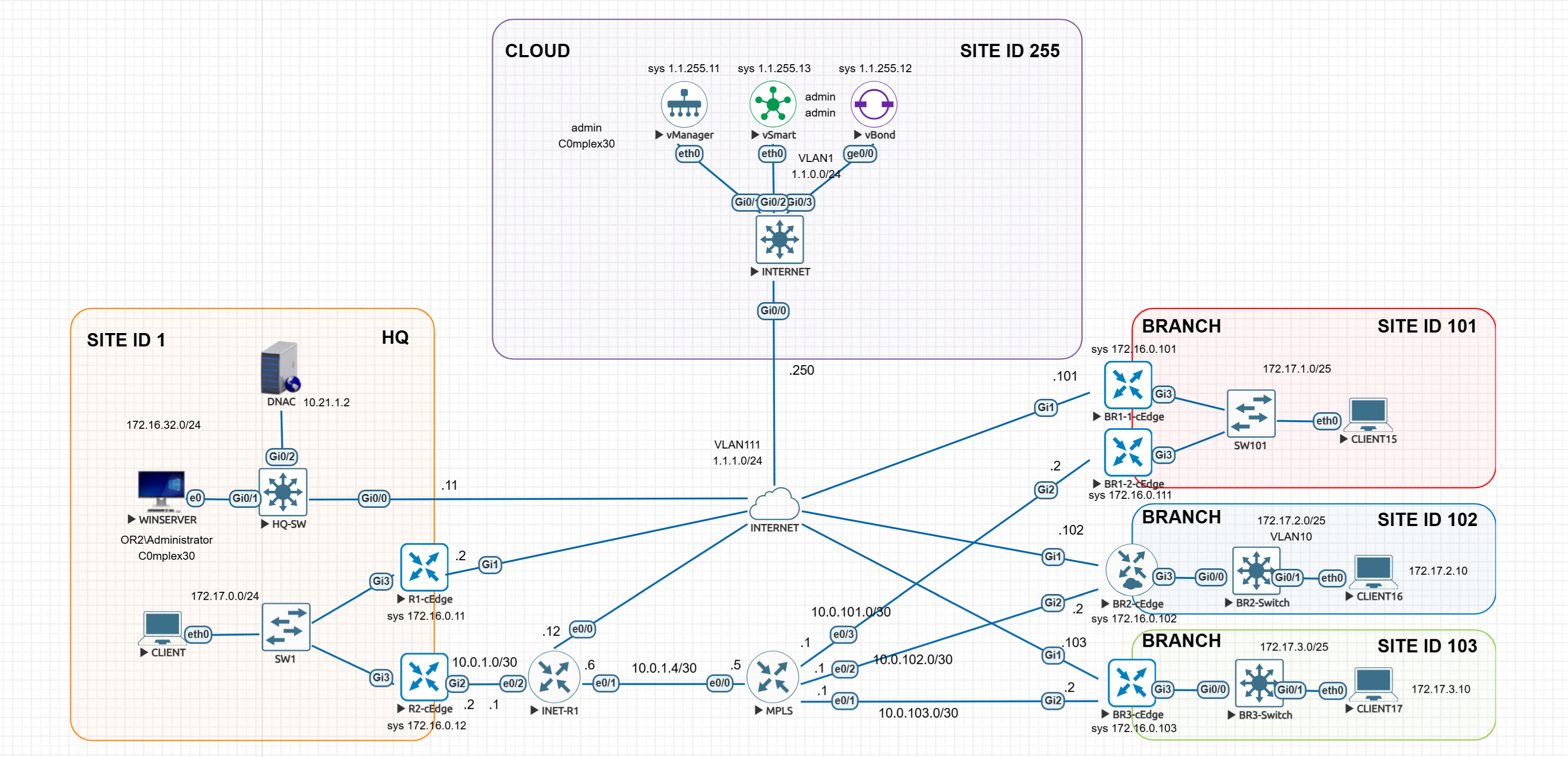
LM Topology with Wan Edge devices
Onboard cEdge devices
https://www.networkacademy.io/ccie-enterprise/sdwan/onboarding-cedge-c8000v
Prepare the software image
When a Catalyst 8000V router is powered on for the first time, it boots up in AUTONOMOUS mode, as seen in the output below.
%BOOT-5-OPMODE_LOG: R0/0: binos: System booted in AUTONOMOUS modeThe router asks if you would like to enter the initial config dialog. We answer no. Just provide enable password and save configuration to NVRAM
% Please answer 'yes' or 'no'.
Would you like to enter the initial configuration dialog? [yes/no]: no
The enable secret is a password used to protect
access to privileged EXEC and configuration modes.
This password, after entered, becomes encrypted in
the configuration.
-------------------------------------------------
secret should be of minimum 10 characters and maximum 32 characters with
at least 1 upper case, 1 lower case, 1 digit and
should not contain [cisco]
-------------------------------------------------
Enter enable secret: ************
Confirm enable secret: ************
The following configuration command script was created:
enable secret 9 $9$uYATfwi9sBtruU$A4/FPncLMnru9Oo4oQjaF89yHqrCXDJBp**********
!
end
[0] Go to the IOS command prompt without saving this config.
[1] Return back to the setup without saving this config.
[2] Save this configuration to nvram and exit.
Enter your selection [2]: 2
Building configuration...
Guestshell destroyed successfully ommand to modify this configuration.
Press RETURN to get started!Install root ca cert on edge just like controllers – so it can mutually authenticate the certificate that is presented by remote device
You should have the Root CA certificate on vBond named root_ca.cer
The easiest way to install the root certificate on a Catalyst 8000v router is by creating a local file directly on the router using TCLSH, as shown in the following example.
In the highlighted section, you should paste the root_ca.cer using the “cat root_ca.cer” command in vshell mode from vBond.
cEdge# tclsh
cEdge(tcl)# puts [open "bootflash:root_ca.cer" w+] {
+> paste root-cert-here
+> }
cEdge-1(tcl)# exitIn the end, you should have the root certificate in the cEdge router’s bootflash, as shown below.
Router# dir bootflash:
Directory of bootflash:/
31 -rw- 1315 Sep 3 2022 08:19:25 +00:00 ROOTCA.pem
131078 drwx 4096 Sep 3 2022 08:18:48 +00:00 tracelogs
131073 drwx 4096 Sep 3 2022 08:16:36 +00:00 .installer
28 -rw- 618 Sep 3 2022 08:16:25 +00:00 cvac.log
131112 drwx 4096 Sep 3 2022 08:16:24 +00:00 license_evlog
29 -rw- 157 Sep 3 2022 08:16:23 +00:00 csrlxc-cfg.log
...
...
5183766528 bytes total (3968655360 bytes free)Now, it is time to reboot the router in CONTROLLER mode, which is required for SD-WAN. The router will notify you that a bootstrap configuration isn’t available, but we will continue anyway.
Router# controller-mode enable
Enabling controller mode will erase the nvram filesystem, remove all configuration files, and reload the box!
Ensure the BOOT variable points to a valid image
Continue? [confirm]
% Warning: Bootstrap config file needed for Day-0 boot is missing
Do you want to abort? (yes/[no]): no
Mode change successAfter the reboot, the router will boot up in CONTROLLER mode, as shown in the output below.
Oct 22 16:30:59.812: %BOOT-5-OPMODE_LOG: R0/0: binos: System booted in CONTROLLER modeThe last step is to install the root certificate using the following command.
cEdge# request platform software sdwan root-cert-chain install bootflash:root_ca.cer
Uploading root-ca-cert-chain via VPN 0
Copying ... /bootflash/ROOTCA.pem via VPN 0
Updating the root certificate chain..
Successfully installed the root certificate chainIf everything has gone smoothly, you should see our Enterprise CA Root certificate installed on the router.
cEdge# show sdwan certificate root-ca-cert | in network
Issuer: C=US, ST=NY, L=NY, O=networkacademy-io, CN=root.certificate
Subject: C=US, ST=NY, L=NY, O=networkacademy-io, CN=root.certificateNow we need vManage to issue certificate to vEdge
Pick on C8000v device from the devices, click on three dots and click on “Generate Bootstrap Configuration”

#cloud-config
vinitparam:
- uuid : C8K-A1AD735C-C4D2-CE60-6D88-01686AD4ED52
- rcc : true
- otp : 4a3a1eb353fc4b3b9a9c94baf06fd1f5
- org : or2.sys.cisco
- vbond : vbond.or.sys.cisco
ca-certs:
remove-defaults: false
trusted:
- |
-----BEGIN CERTIFICATE-----
MIIDnzCCAoegAwIBAgIQYJ1ACvIQRIlBAEITkoGNuzANBgkqhkiG9w0BAQsFADBi
MRUwEwYKCZImiZPyLGQBGRYFY2lzY28xEzARBgoJkiaJk/IsZAEZFgNzeXMxEzAR
BgoJkiaJk/IsZAEZFgNvcjIxHzAdBgNVBAMTFm9yMi1XSU4tVlEwOEc2VTk4R0Yt
Q0EwHhcNMjUwNzA2MjE1MjA1WhcNMzAwNzA2MjIwMjA1WjBiMRUwEwYKCZImiZPy
LGQBGRYFY2lzY28xEzARBgoJkiaJk/IsZAEZFgNzeXMxEzARBgoJkiaJk/IsZAEZ
FgNvcjIxHzAdBgNVBAMTFm9yMi1XSU4tVlEwOEc2VTk4R0YtQ0EwggEiMA0GCSqG
SIb3DQEBAQUAA4IBDwAwggEKAoIBAQCr6cjaoJz3vzgHlQ1hzhuy5WfIL/Ao0isM
ltIaGL+Z+9WftM1hNh10YECbxR71+lIpQKyBQTXQz8Of4nycxHjoI3dQdUvEYb8H
fysDXh4lYjQ60x82e5c7f1KPbD+AOhC31Zw1dgReMlPIuaa9LK903+z0FRnuCHaI
EG/Z9uCmv3JC22NgL69hscZc+NUGymMy1iBPN8G4EBkgqNVZ+zlRf/adW0JxEdc6
Sy53bp586/fXziRTW++jgdnhvfpn+VJ+BdG88/rEgMl7PUQE95lq4dih7qx0+OXu
ihFwQQvFxvi3dyqWWc0C1RKHPHtYQFz8rRuBJrR+uzgc0lVhrNHdAgMBAAGjUTBP
MAsGA1UdDwQEAwIBhjAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQWBBQ/bI8yZeKD
fgjmmeWorjGo25t5hzAQBgkrBgEEAYI3FQEEAwIBADANBgkqhkiG9w0BAQsFAAOC
AQEAdtt6aiABkDDg/mAlcZfFPHcqmEEvQaMPeBaUqvfZKNrFVO8GMb9kingZJ62n
K05x5wE3tHy3jBmAl6eHZ/nUjXS11C06NwZMHpcDhty5BcDN08oEYdLF24upisNA
aRLOBhyEtKI9VKLAWfMkpWYEd/dqgVWs67GjAFT0Osgva9QHbz24iT6/c09jbZMt
41opmxacw8FFZcHMH9Afv1fIW9PwscrdlgjSSHR4XQLyDbyuDGsolzeh9PUVyPOd
f+/LYkLwH9jVcHlxl4Oy7MHRPtcbG9T3+vQGLjSAXu3Ybrl2R9Tn/sz5lYs44EEB
mqCxT00LxB3et6jAxJlEyE5vCw==
-----END CERTIFICATE-----We have to configure basic IP addressesing and default route and system configuration
we will also configure a DNS name for vBond, as recommended by Cisco.
config-transaction
hostname R1-cEdge
!
int GigabitEthernet1
ip address 1.1.1.1 255.255.255.0
no shut
!
ip route 0.0.0.0 0.0.0.0 1.1.1.250
!
system
system-ip 172.16.0.11
site-id 1
ip host vbond.or.sys.cisco 1.1.0.12 ! cisco recommends adding this host entry
organization-name or2.sys.cisco
vbond vbond.or.sys.cisco
commitYou should be able to ping the controllers at this point, If there is no IP connectivity between the WAN edge router and the controllers, there is no point in continuing further. You should troubleshoot the problem first.
sdwan
int GigabitEthernet1
tunnel-interface
color biz-internet
encapsulation ipsec
!
interface Tunnel 1 !----> this tunnel interface number should be same as physical interface
ip unnumbered GigabitEthernet1
tunnel source GigabitEthernet1
tunnel mode sdwan
!
int GigabitEthernet2
tunnel-interface
color mpls restrict
encapsulation ipsec
!
interface Tunnel 2
ip unnumbered GigabitEthernet2
tunnel source GigabitEthernet2
tunnel mode sdwanRouter is now ready to join overlay fabric
Before the cEdge router can be able to join the SD-WAN fabric, it must have a device certificate signed and installed by vManage
this is the common rule for both controllers and edge devices, anything that needs to join fabric, requires a certificate issued from vmanage and mutual authentication
request platform software sdwan vedge_cloud activate chassis-number C8K-A1AD735C-C4D2-CE60-6D88-01686AD4ED52 token 4a3a1eb353fc4b3b9a9c94baf06fd1f5Once you’ve done, you should see in the logs that vManage logs into the cEdge using NETCONF over SSH, generates a CSR, then signs it and install a device certificate. Then the cEdge router should establish an OMP peering with vSmart and start receiving TLOCs and OMP routes.
R1-cEdge#
*Jul 21 20:27:09.257: %SYS-5-CONFIG_P: Configured programmatically by process iosp_dmiauthd_conn_100001_vty_100001 from consol6
*Jul 21 20:27:09.523: %SYS-5-CONFIG_P: Configured programmatically by process iosp_dmiauthd_conn_100001_vty_100001 from console as admin on vty42946
*Jul 21 20:27:09.503: %DMI-5-CONFIG_I: R0/0: dmiauthd: Configured from NETCONF/RESTCONF by admin, transaction-id 558pong
*Jul 21 20:27:17.068: %SYS-5-CONFIG_P: Configured programmatically by process iosp_dmiauthd_conn_100001_vty_100001 from console as admin on vty4294l
*Jul 21 20:28:03.534: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:36606 for netconf over s:
*Jul 21 20:28:29.847: %Cisco-SDWAN-R1-cEdge-action_notifier-6-INFO-1400002: Notification: 7/21/2025 20:28:29 security-install-rcc severity-level:mi1
*Jul 21 20:28:30.030: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:36688 for netconf over s:
*Jul 21 20:28:43.152: %Cisco-SDWAN-R1-cEdge-action_notifier-6-INFO-1400002: Notification: 7/21/2025 20:28:43 security-install-certificate severity-1
*Jul 21 20:29:25.117: %Cisco-SDWAN-Router-OMPD-3-ERRO-400002: vSmart peer 1.1.255.13 state changed to Init
*Jul 21 20:29:25.343: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:36822 for netconf over ss
*Jul 21 20:29:27.205: %Cisco-SDWAN-Router-OMPD-6-INFO-400002: vSmart peer 1.1.255.13 state changed to Handshake
*Jul 21 20:29:27.218: %Cisco-SDWAN-Router-OMPD-5-NTCE-400002: vSmart peer 1.1.255.13 state changed to Up
*Jul 21 20:29:27.218: %Cisco-SDWAN-Router-OMPD-6-INFO-400005: Number of vSmarts connected : 1
*Jul 21 20:29:41.535: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:36882 for netconf over s:
*Jul 21 20:30:01.736: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:36928 for netconf over s:
*Jul 21 20:30:23.576: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:37006 for netconf over s:
*Jul 21 20:30:33.557: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:37052 for netconf over s:
*Jul 21 20:30:43.535: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:37078 for netconf over s:
*Jul 21 20:30:48.611: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:37108 for netconf over s:
R1-cEdge#show sdwan control connections
PEER PEER
PEER PEER PEER SITE DOMAIN PEER PRIV PEER PUB
TYPE PROT SYSTEM IP ID ID PRIVATE IP PORT PUBLIC IP PORT ORGANIZA
----------------------------------------------------------------------------------------------------------------------------------------------------
vsmart dtls 1.1.255.13 255 1 1.1.0.13 12446 1.1.0.13 12446 or2.sys.
vbond dtls 0.0.0.0 0 0 1.1.0.12 12346 1.1.0.12 12346 or2.sys.
vmanage dtls 1.1.255.11 255 0 1.1.0.11 12846 1.1.0.11 12846 or2.sys.

R1-cEdge#
*Jul 21 20:27:09.257: %SYS-5-CONFIG_P: Configured programmatically by process iosp_dmiauthd_conn_100001_vty_100001 from consol6
*Jul 21 20:27:09.523: %SYS-5-CONFIG_P: Configured programmatically by process iosp_dmiauthd_conn_100001_vty_100001 from console as admin on vty42946
*Jul 21 20:27:09.503: %DMI-5-CONFIG_I: R0/0: dmiauthd: Configured from NETCONF/RESTCONF by admin, transaction-id 558pong
*Jul 21 20:27:17.068: %SYS-5-CONFIG_P: Configured programmatically by process iosp_dmiauthd_conn_100001_vty_100001 from console as admin on vty4294l
*Jul 21 20:28:03.534: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:36606 for netconf over s:
*Jul 21 20:28:29.847: %Cisco-SDWAN-R1-cEdge-action_notifier-6-INFO-1400002: Notification: 7/21/2025 20:28:29 security-install-rcc severity-level:mi1
*Jul 21 20:28:30.030: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:36688 for netconf over s:
*Jul 21 20:28:43.152: %Cisco-SDWAN-R1-cEdge-action_notifier-6-INFO-1400002: Notification: 7/21/2025 20:28:43 security-install-certificate severity-1
*Jul 21 20:29:25.117: %Cisco-SDWAN-Router-OMPD-3-ERRO-400002: vSmart peer 1.1.255.13 state changed to Init
*Jul 21 20:29:25.343: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:36822 for netconf over ss
*Jul 21 20:29:27.205: %Cisco-SDWAN-Router-OMPD-6-INFO-400002: vSmart peer 1.1.255.13 state changed to Handshake
*Jul 21 20:29:27.218: %Cisco-SDWAN-Router-OMPD-5-NTCE-400002: vSmart peer 1.1.255.13 state changed to Up
*Jul 21 20:29:27.218: %Cisco-SDWAN-Router-OMPD-6-INFO-400005: Number of vSmarts connected : 1
*Jul 21 20:29:41.535: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:36882 for netconf over s:
*Jul 21 20:30:01.736: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:36928 for netconf over s:
*Jul 21 20:30:23.576: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:37006 for netconf over s:
*Jul 21 20:30:33.557: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:37052 for netconf over s:
*Jul 21 20:30:43.535: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:37078 for netconf over s:
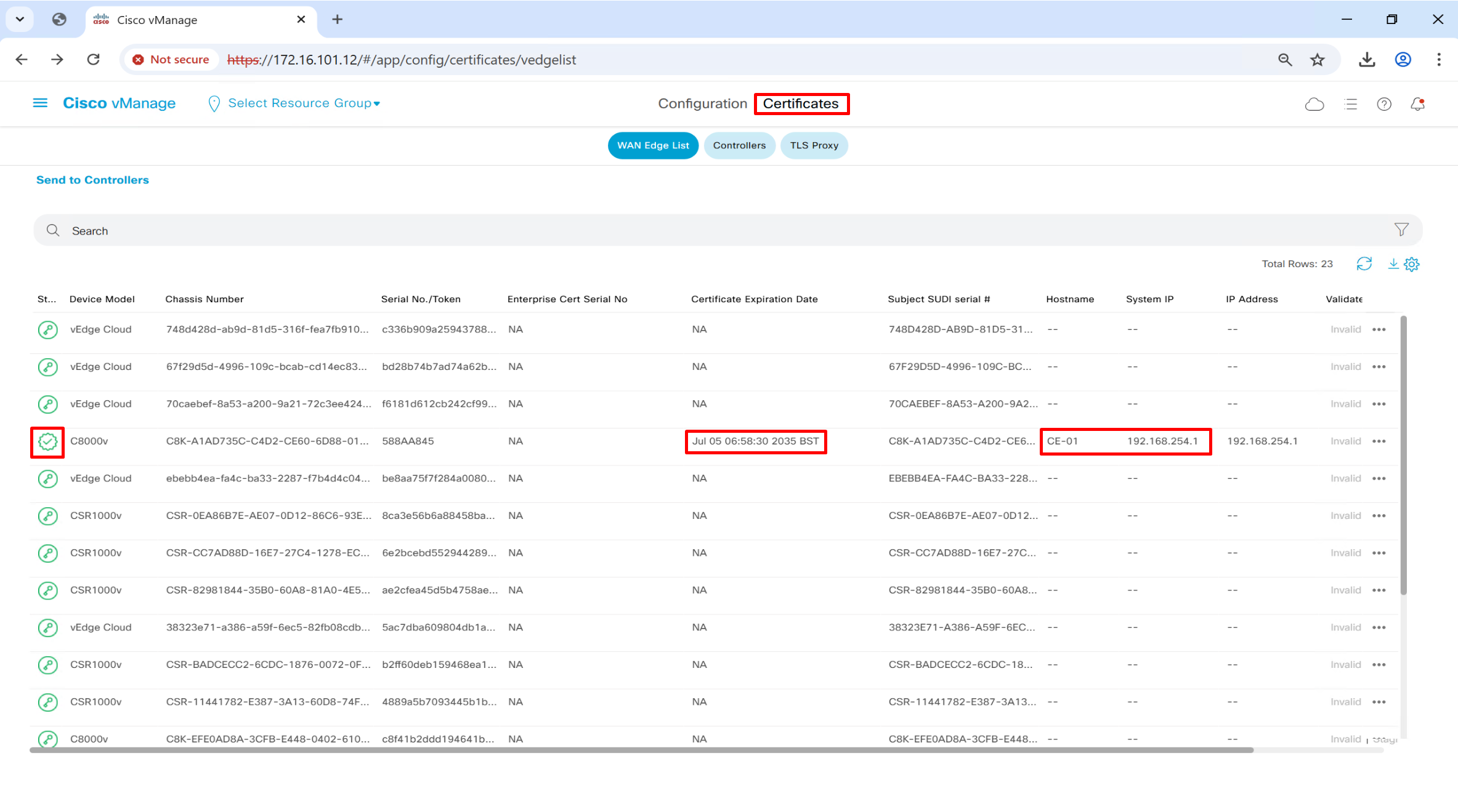
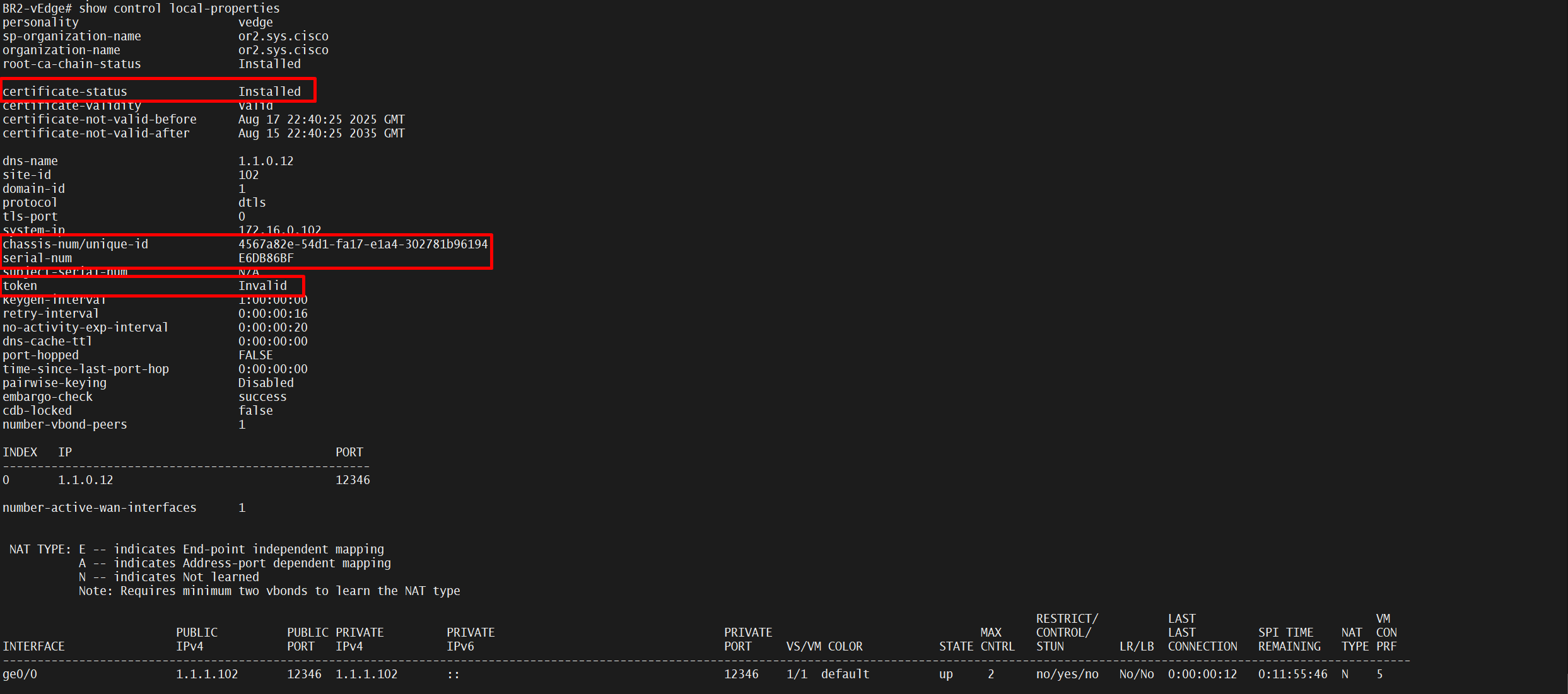
*Jul 21 20:30:48.611: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:37108 for netconf over s:CE-01#show sdwan control local-properties
personality vedge
sp-organization-name or2.sys.cisco
organization-name or2.sys.cisco
root-ca-chain-status Installed
certificate-status Installed
certificate-validity Valid
certificate-not-valid-before Jul 7 05:58:30 2025 GMT
certificate-not-valid-after Jul 5 05:58:30 2035 GMT
enterprise-cert-status Not-Applicable
enterprise-cert-validity Not Applicable
enterprise-cert-not-valid-before Not Applicable
enterprise-cert-not-valid-after Not Applicable
dns-name vbond.or.sys.cisco
site-id 250
domain-id 1
protocol dtls
tls-port 0
system-ip 192.168.254.1
chassis-num/unique-id C8K-A1AD735C-C4D2-CE60-6D88-01686AD4ED52
serial-num 588AA845
subject-serial-num N/A
enterprise-serial-num No certificate installed
token Invalid
keygen-interval 1:00:00:00
retry-interval 0:00:00:16
no-activity-exp-interval 0:00:00:20
dns-cache-ttl 0:00:02:00
port-hopped TRUE
time-since-last-port-hop 0:00:30:51
embargo-check success
number-vbond-peers 1
INDEX IP PORT
-----------------------------------------------------
0 172.16.101.14 12346
number-active-wan-interfaces 1
NAT TYPE: E -- indicates End-point independent mapping
A -- indicates Address-port dependent mapping
N -- indicates Not learned
Note: Requires minimum two vbonds to learn the NAT type
PUBLIC PUBLIC PRIVATE PRIVATE PRIVATE MAX RESTRICT/ LAM
INTERFACE IPv4 PORT IPv4 IPv6 PORT VS/VM COLOR STATE CNTRL CONTROL/ LR/LB CON
STUN F
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------
GigabitEthernet1 172.16.101.200 12366 172.16.101.200 :: 12366 1/1 biz-internet up 2 no/yes/no No/R1-cEdge#show sdwan control connections
PEER PEER
PEER PEER PEER SITE DOMAIN PEER PRIV PEER PUB
TYPE PROT SYSTEM IP ID ID PRIVATE IP PORT PUBLIC IP PORT ORGANIZA
----------------------------------------------------------------------------------------------------------------------------------------------------
vsmart dtls 1.1.255.13 255 1 1.1.0.13 12446 1.1.0.13 12446 or2.sys.
vbond dtls 0.0.0.0 0 0 1.1.0.12 12346 1.1.0.12 12346 or2.sys.
vmanage dtls 1.1.255.11 255 0 1.1.0.11 12846 1.1.0.11 12846 or2.sys.show run ! still works
show sdwan running-config
vbond command: show orchestrator valid-vedges
Platform Console
The last thing in running Catalyst 8000V in a virtual EVE-NG environment is to change the console method after attaching a device template.
Depending on your lab, you will most likely end up attaching a device template to the 8000V edge routers. What typically happens is that you lose access to the device via the console. This happens because, by default, the device boot up configured with the following command.
platform console serialHowever, after you attach a template, vManage changes the console method to
platform console virtualThe “virtual” option defines that the 8000V router is accessed through the virtual VGA console of the hypervisor. To change the console method back to “serial,” you must configure a CLI add-on feature template and add it to the respective device template the router is attached to.
Changing IP address on WAN side of the edge device
I changed IP address on R1-cEdge on its WAN transport interface and it re-established connections to controllers and all control connections came up, I did not have to edit or change addresses in any of the controllers, that is good. I changed IP address from 1.1.1.1 to 1.1.1.2
ISR 4000 Conversion and Standup as SDWAN router for CCIE Hardware router provisioning exam topic
Do all below videos in their accordion sections
RS0138 – SD-WAN ISR 4K Installation (Part 1)
RS0138 – SD-WAN ISR 4K Installation (Part 2)
RS0138 – SD-WAN ISR 4K Installation (Part 3)
RS0138 – SD-WAN ISR 4K Installation (Part 4)
ZTP and PnP videos
RS0140 – SD-WAN ZTP and PnP (Part 1)
RS0140 – SD-WAN ZTP and PnP (Part 2)
RS0140 – SD-WAN ZTP and PnP (Part 3)
RS0140 – SD-WAN ZTP and PnP (Part 4)
R2-cEdge standup over MPLS (apparent no reachability to controllers)
Most MPLS setup do not have the internet access unless you pay for it and then provider can provide default route from MPLS, it will have an INET-R1 router that will route traffic for 0.0.0.0/0 towards internet cloud and allow connectivity to controllers on internet to be reached via MPLS network
Traffic for MPLS prefixes will be routed towards MPLS router and for internet connectivity will be routed to internet
Add basic configuration on R2-cEdge
system
system-ip 172.16.0.12
site-id 1
organization-name or2.sys.cisco
vbond vbond.or.sys.cisco
hostname R2-cEdge
username admin privilege 15 secret 5 $1$dYK8$TukpN4hzNpia/JRlBkEjG.
ip host vbond.or.sys.cisco 1.1.0.12
ip route 0.0.0.0 0.0.0.0 10.0.1.1
interface GigabitEthernet2
ip address 10.0.1.2 255.255.255.252
no shutdown
no mop enabled
no mop sysid
negotiation auto
exit
interface Tunnel2
no shutdown
ip unnumbered GigabitEthernet2
tunnel source GigabitEthernet2
tunnel mode sdwan
exit
sdwan
interface GigabitEthernet2
tunnel-interface
encapsulation ipsec
color mpls
allow-service all
exit
exit
commit
Untick validate – this validate option will make device status as valid directly skipping invalid and staging state, if you dont want to bring device in production straight away then untick validate
#cloud-config
vinitparam:
- vbond : vbond.or.sys.cisco
- rcc : true
- uuid : C8K-AB8303D2-8707-6BBA-051F-8BB318E56660
- org : or2.sys.cisco
- otp : 5505e0f36e3e45e181c862471c35f18d
ca-certs:
remove-defaults: false
trusted:
- |
-----BEGIN CERTIFICATE-----
MIIDnzCCAoegAwIBAgIQYJ1ACvIQRIlBAEITkoGNuzANBgkqhkiG9w0BAQsFADBi
MRUwEwYKCZImiZPyLGQBGRYFY2lzY28xEzARBgoJkiaJk/IsZAEZFgNzeXMxEzAR
BgoJkiaJk/IsZAEZFgNvcjIxHzAdBgNVBAMTFm9yMi1XSU4tVlEwOEc2VTk4R0Yt
Q0EwHhcNMjUwNzA2MjE1MjA1WhcNMzAwNzA2MjIwMjA1WjBiMRUwEwYKCZImiZPy
LGQBGRYFY2lzY28xEzARBgoJkiaJk/IsZAEZFgNzeXMxEzARBgoJkiaJk/IsZAEZ
FgNvcjIxHzAdBgNVBAMTFm9yMi1XSU4tVlEwOEc2VTk4R0YtQ0EwggEiMA0GCSqG
SIb3DQEBAQUAA4IBDwAwggEKAoIBAQCr6cjaoJz3vzgHlQ1hzhuy5WfIL/Ao0isM
ltIaGL+Z+9WftM1hNh10YECbxR71+lIpQKyBQTXQz8Of4nycxHjoI3dQdUvEYb8H
fysDXh4lYjQ60x82e5c7f1KPbD+AOhC31Zw1dgReMlPIuaa9LK903+z0FRnuCHaI
EG/Z9uCmv3JC22NgL69hscZc+NUGymMy1iBPN8G4EBkgqNVZ+zlRf/adW0JxEdc6
Sy53bp586/fXziRTW++jgdnhvfpn+VJ+BdG88/rEgMl7PUQE95lq4dih7qx0+OXu
ihFwQQvFxvi3dyqWWc0C1RKHPHtYQFz8rRuBJrR+uzgc0lVhrNHdAgMBAAGjUTBP
MAsGA1UdDwQEAwIBhjAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQWBBQ/bI8yZeKD
fgjmmeWorjGo25t5hzAQBgkrBgEEAYI3FQEEAwIBADANBgkqhkiG9w0BAQsFAAOC
AQEAdtt6aiABkDDg/mAlcZfFPHcqmEEvQaMPeBaUqvfZKNrFVO8GMb9kingZJ62n
K05x5wE3tHy3jBmAl6eHZ/nUjXS11C06NwZMHpcDhty5BcDN08oEYdLF24upisNA
aRLOBhyEtKI9VKLAWfMkpWYEd/dqgVWs67GjAFT0Osgva9QHbz24iT6/c09jbZMt
41opmxacw8FFZcHMH9Afv1fIW9PwscrdlgjSSHR4XQLyDbyuDGsolzeh9PUVyPOd
f+/LYkLwH9jVcHlxl4Oy7MHRPtcbG9T3+vQGLjSAXu3Ybrl2R9Tn/sz5lYs44EEB
mqCxT00LxB3et6jAxJlEyE5vCw==
-----END CERTIFICATE-----on R2-cEdge
request platform software sdwan vedge_cloud activate chassis-number C8K-AB8303D2-8707-6BBA-051F-8BB318E56660 token 5505e0f36e3e45e181c862471c35f18d

vEdge onboarding and configuration
Every time a new device is added to the WAN edge list, either via syncing from smart account or viptella serial file, we need to “send to controllers”, verify on vbond that new device is added to it
vBond# show orchestrator valid-vedges | tab
HARDWARE
INSTALLED SUBJECT
SERIAL SERIAL
CHASSIS NUMBER SERIAL NUMBER VALIDITY ORG NUMBER NUMBER
-----------------------------------------------------------------------------------------------------------------------------
0d7b4db2-d1c7-a10c-82aa-51133e50a3ad 56831d0a459a4d11adbebfb844115fe0 valid or2.sys.cisco N/A 0D7B4DB2-D1
14d3598d-2f93-d5e3-ec33-ebb972a54a96 07b454f7f0694a1a8fdc3f59915d8e97 valid or2.sys.cisco N/A 14D3598D-2F
38323e71-a386-a59f-6ec5-82fb08cdbc0c 6b81257104424bdc928e4c2fabfc0967 valid or2.sys.cisco N/A 38323E71-A3
4567a82e-54d1-fa17-e1a4-302781b96194 eca16978e13744e2ac2edda6e33c9373 valid or2.sys.cisco N/A 4567A82E-54
4c353382-ddc5-9ac0-d903-c07ce6fc19ac e56d759ca369422c842d5ff98b370293 valid or2.sys.cisco N/A 4C353382-DD
67f29d5d-4996-109c-bcab-cd14ec837a33 6950d355072b452bb0c3c6ee348e684d valid or2.sys.cisco N/A 67F29D5D-49
70caebef-8a53-a200-9a21-72c3ee424737 25936ef5caa74cff8a30118cba2e5595 valid or2.sys.cisco N/A 70CAEBEF-8A
748d428d-ab9d-81d5-316f-fea7fb910d6d 2b31d2d21dc141b0b0b31cf87a028ddf valid or2.sys.cisco N/A 748D428D-AB
aafa211d-aee9-6dc7-ce14-829e5a025225 cc51993a8cfb46b588def2f923e09e66 valid or2.sys.cisco N/A AAFA211D-AE
b0cfb377-813b-5f02-69f2-5cd76d3c261f 930d0e37929f49f2ad1fbe3d23cc7c5a valid or2.sys.cisco N/A B0CFB377-81
C8K-93E4A981-1B6A-5B49-0D59-4818588CA46A 9B10218D valid or2.sys.cisco N/A N/A
C8K-A1AD735C-C4D2-CE60-6D88-01686AD4ED52 aac6851892a546edbc6c6b50b182ae96 valid or2.sys.cisco N/A C8K-A1AD735
C8K-AB8303D2-8707-6BBA-051F-8BB318E56660 1250E1E5 valid or2.sys.cisco N/A C8K-AB8303D
C8K-EFE0AD8A-3CFB-E448-0402-6108A06678C2 88c4c032d1d1413cbf66c72166e4b070 valid or2.sys.cisco N/A C8K-EFE0AD8
C8K-FF74B9C0-47EC-6B46-6F06-B63A33303C0F 3d4817593d9e42d19092a8a7804051aa valid or2.sys.cisco N/A C8K-FF74B9C
CSR-0EA86B7E-AE07-0D12-86C6-93E64EA24C46 d843a0b45dbf4b7982c930e6c5c120c6 valid or2.sys.cisco N/A CSR-0EA86B7
CSR-11441782-E387-3A13-60D8-74FFCE54D959 7b5690b9065e44e1943c3e74e336625e valid or2.sys.cisco N/A CSR-1144178
CSR-82981844-35B0-60A8-81A0-4E511A9FF6FA 08086272a4174295b0ec03095b39492e valid or2.sys.cisco N/A CSR-8298184
CSR-BADCECC2-6CDC-1876-0072-0F9EAE28D879 fb7abe09c58e48daab91c73fe59a1bc1 valid or2.sys.cisco N/A CSR-BADCECC
CSR-CC7AD88D-16E7-27C4-1278-EC9520C8CCD4 d58d1b454b0f45a2a16bfbeeca1b1f28 valid or2.sys.cisco N/A CSR-CC7AD88
CSR-ED63ADBC-750F-E08A-5C4D-0DDEE109E9D1 46a30397d6b04e43a2b8d5cfa370126e valid or2.sys.cisco N/A CSR-ED63ADB
ebebb4ea-fa4c-ba33-2287-f7b4d4c04b74 f6a307a61d4d4fceac7e2d45a45dc528 valid or2.sys.cisco N/A EBEBB4EA-FA
ff39e75a-8ee5-a214-6d15-3985fc7a9273 5718fec846484ba0b9fb0243c90fc62e valid or2.sys.cisco N/A FF39E75A-8EFor non cisco viptella based vedge onboarding this section works, this settings allows vManage to issue the cert or vedge to use the vManage as the CA and we will keep it to default setting vManage signed

configure BR2-vEdge
conf t
system
system-ip 172.16.0.102
site-id 102
organization-name or2.sys.cisco
vbond 1.1.0.12
host-name BR2-vEdge
commit
vpn 0
int ge0/0
ip address 1.1.1.102/24
no shut
tunnel-interface
allow-service all
no shut
exit
ip route 0.0.0.0/0 1.1.1.250
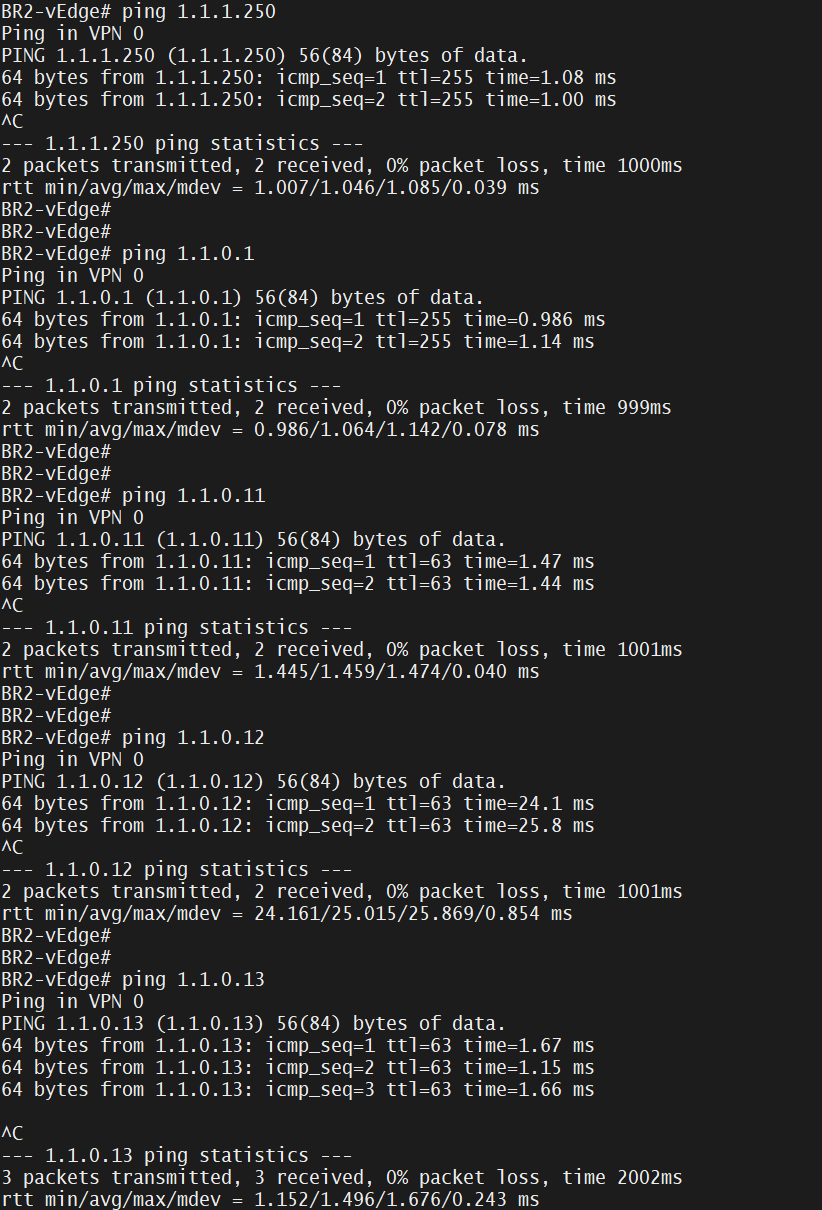
commit Make sure that we can ping hops and controllers
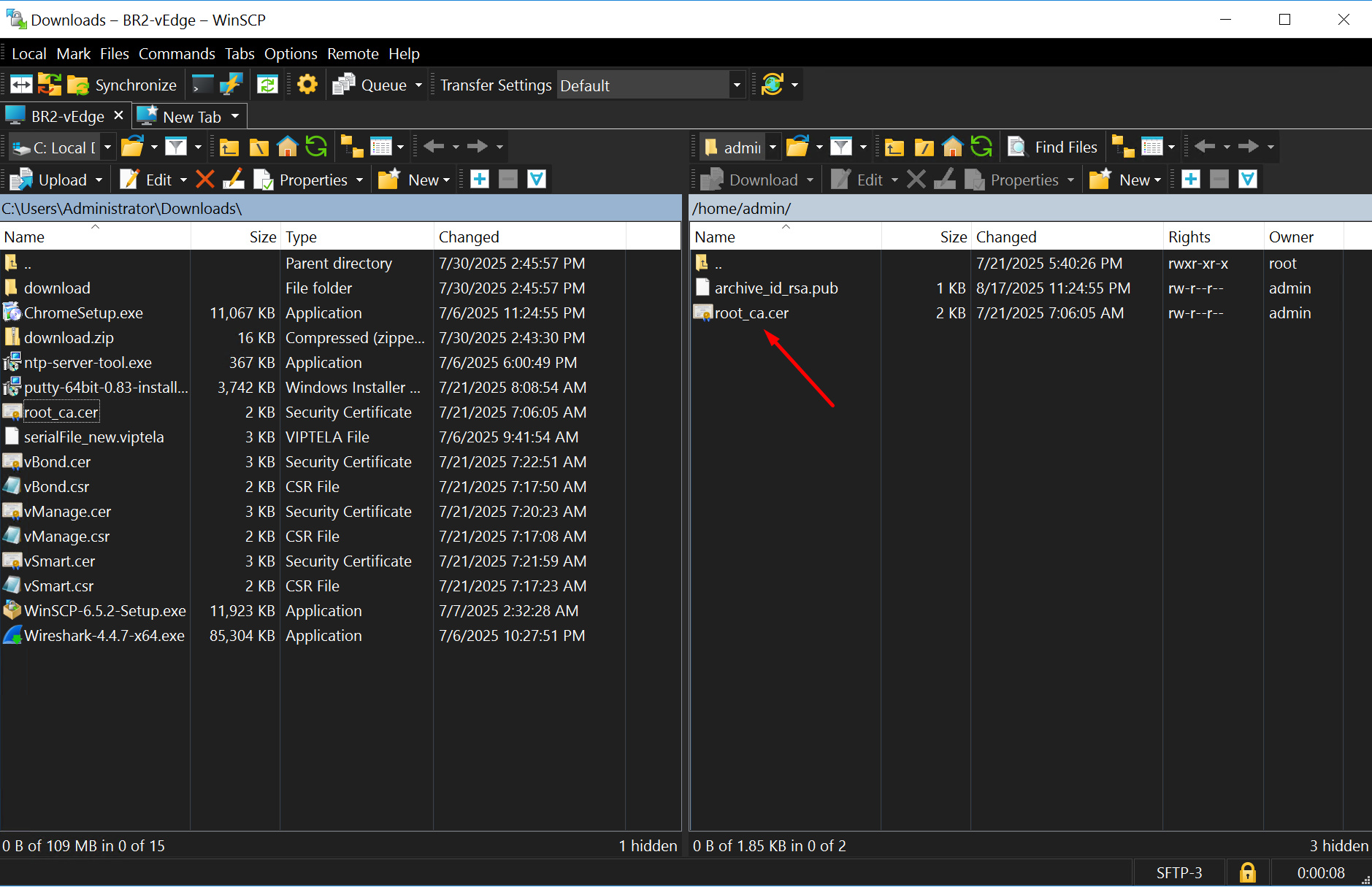
SFTP to vedge router and drag root.cer into it
because with SFTP you dont have to worry about the CLI prompt to be linux


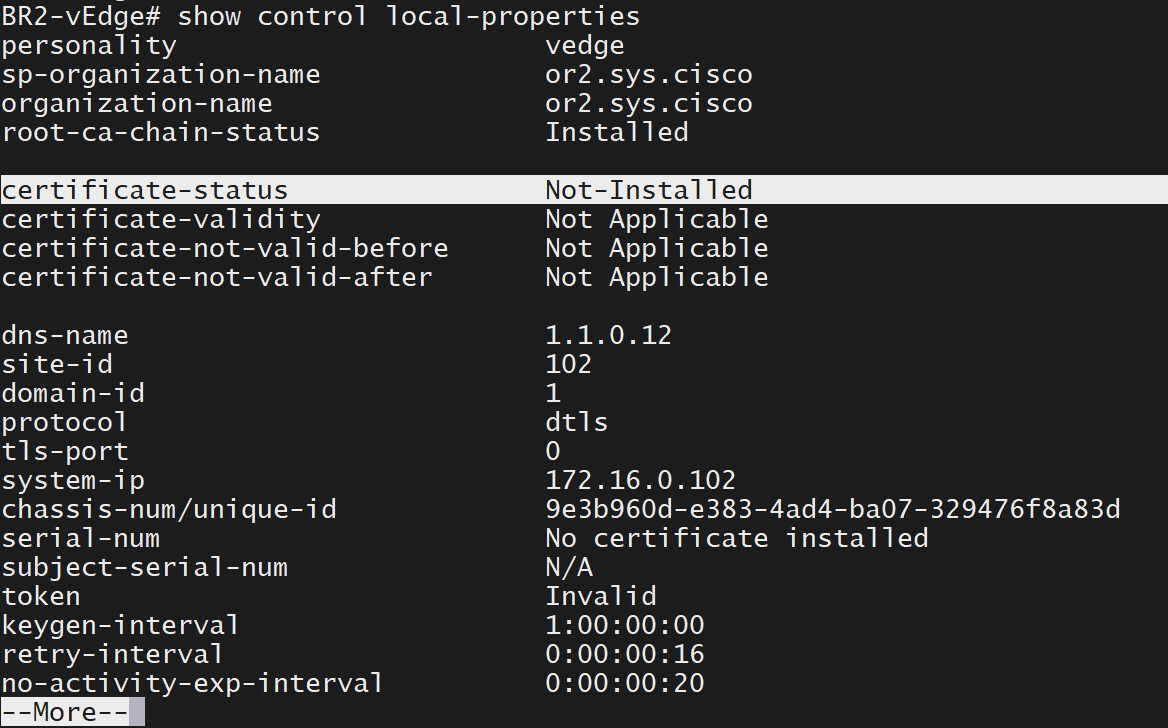
Enter vshell and make sure that root ca cert is present as a result of the previous transfer
BR2-vEdge#
BR2-vEdge# vshell
BR2-vEdge:~$ ls -lapsh
total 32K
4.0K drwxr-x--- 3 admin admin 4.0K Aug 17 22:31 ./
4.0K drwxr-xr-x 14 root root 4.0K Jul 21 16:40 ../
4.0K -rw------- 1 admin admin 5 Aug 17 22:31 .bash_history
4.0K -rwxr-xr-x 1 admin admin 476 Aug 17 22:24 .bashrc
4.0K -rwxr-xr-x 1 admin admin 241 Aug 24 2021 .profile
4.0K drwx------ 2 admin admin 4.0K Jul 21 16:40 .ssh/
4.0K -rw-r--r-- 1 admin admin 564 Aug 17 22:24 archive_id_rsa.pub
4.0K -rw-r--r-- 1 admin admin 1.4K Jul 21 06:06 root_ca.cerInstall root ca cert on vedge
BR2-vEdge# request root-cert-chain install /home/admin/root_ca.cer
Uploading root-ca-cert-chain via VPN 0
Copying ... /home/admin/root_ca.cer via VPN 0
Updating the root certificate chain..
Successfully installed the root certificate chainVerify the root ca cert installation
BR2-vEdge# show certificate root-ca-cert | inc Subject
Subject: DC=cisco, DC=sys, DC=or2, CN=or2-WIN-VQ08G6U98GF-CA
Subject Public Key Info:
X509v3 Subject Key Identifier:We want vManage to install the certificate as it is not installed
now we need to obtain the chassis number and token from vManage for one of the devices of type vEdge
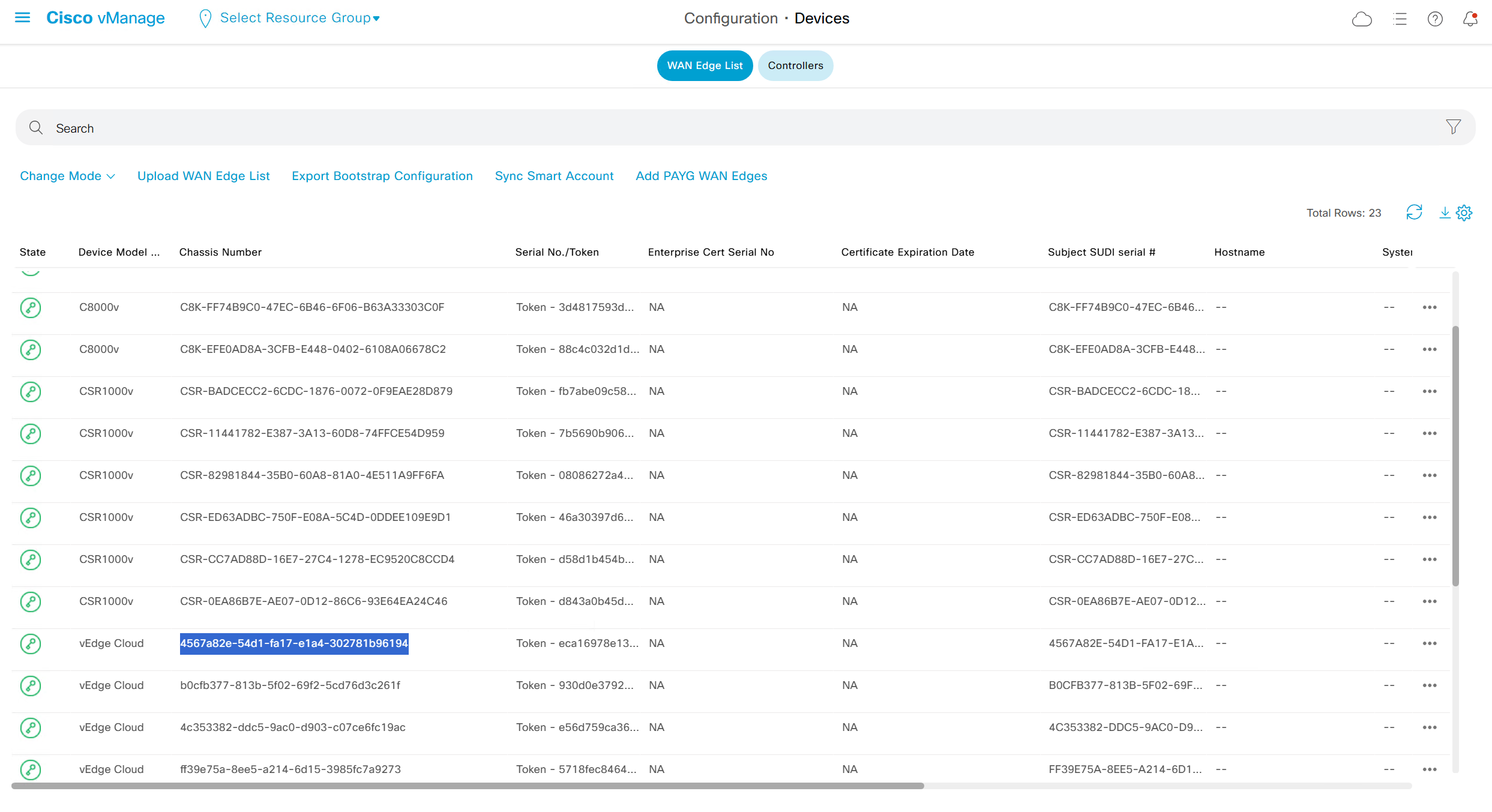
request vedge-cloud activate chassis-number 4567a82e-54d1-fa17-e1a4-302781b96194 token eca16978e13744e2ac2edda6e33c9373
show certificate installed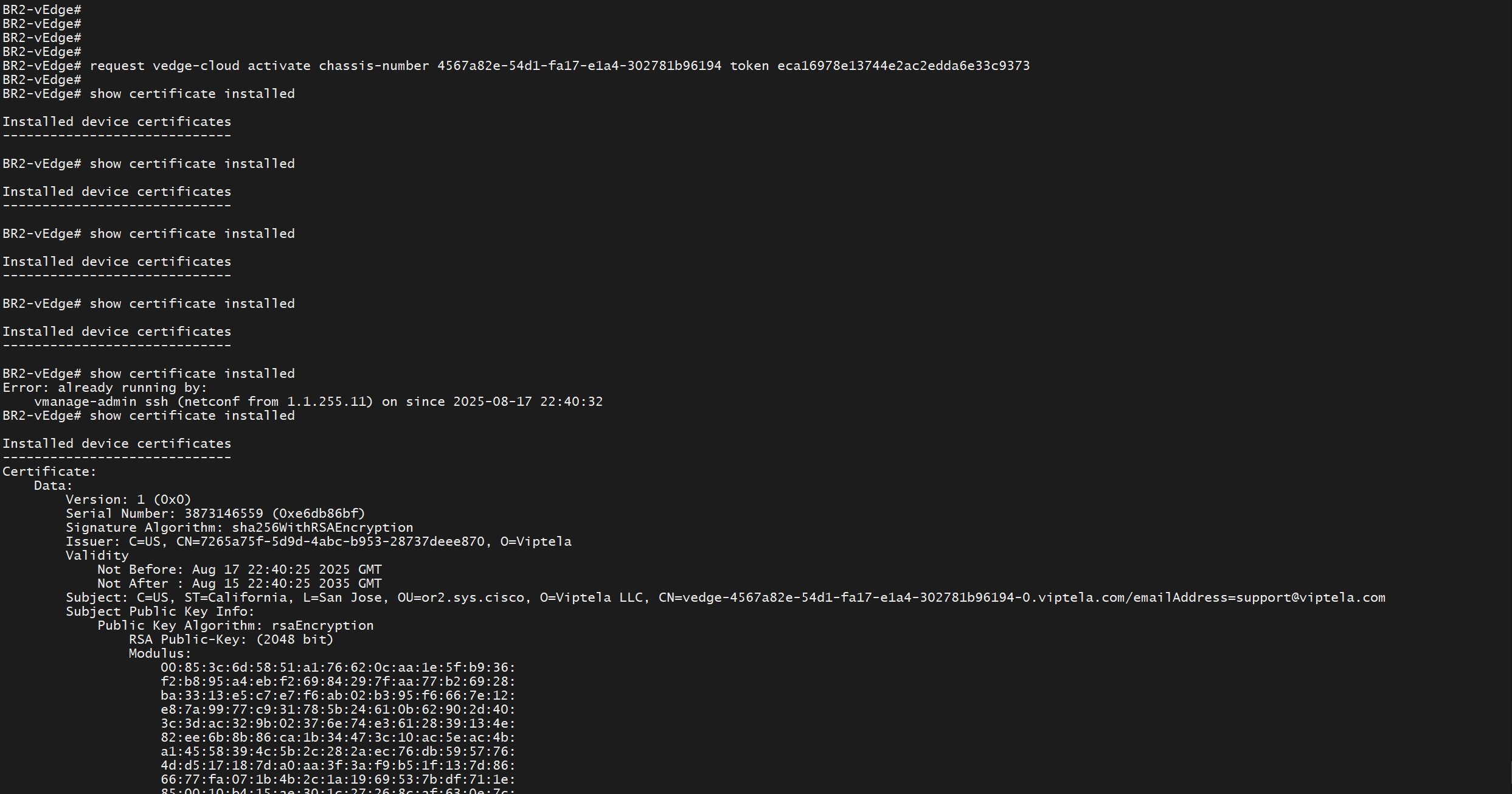
show control connections 
sort by state to see the installed edges and we will see latest vedge in there
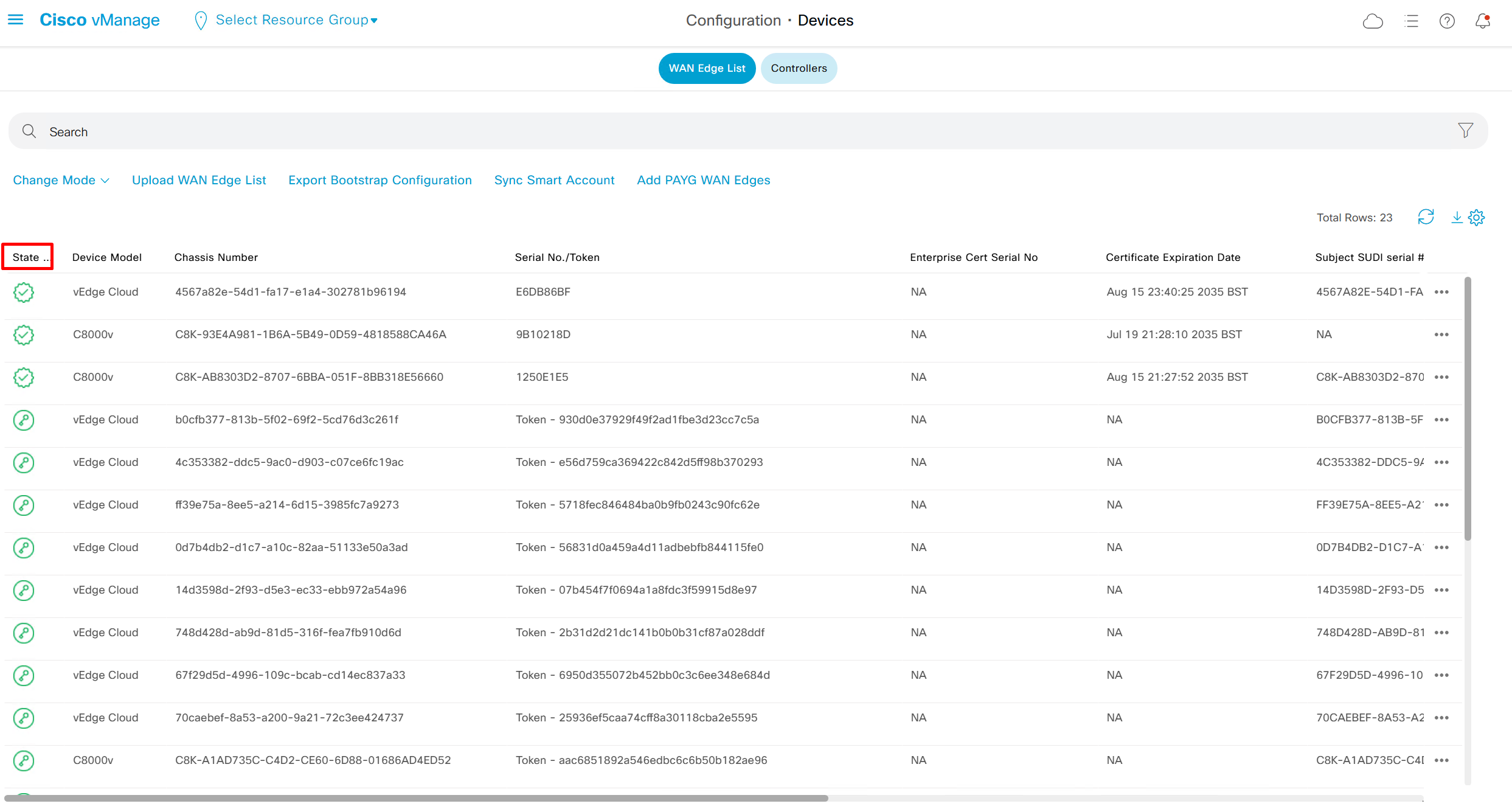
color is set to default so we will set it to biz-internet


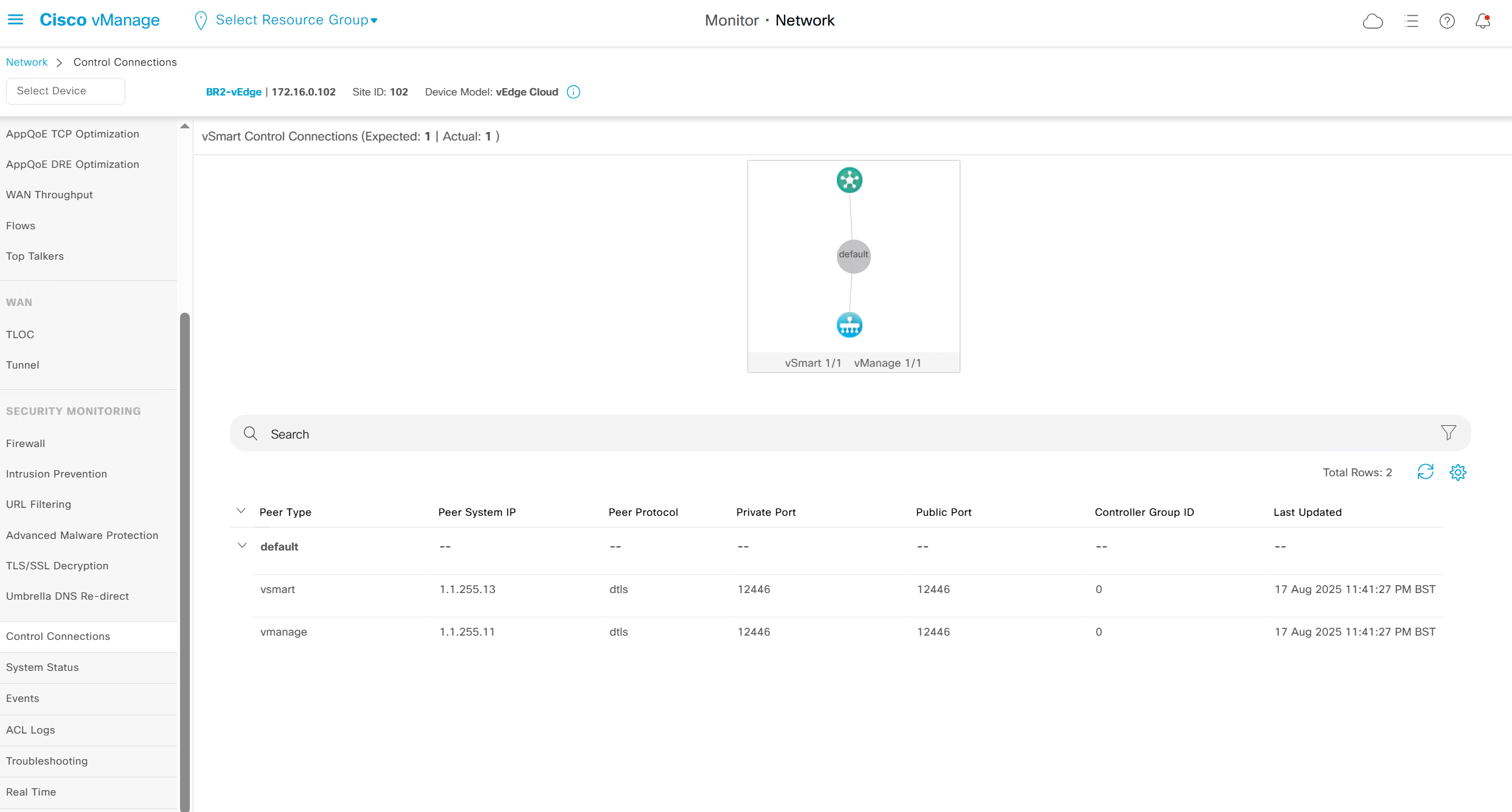
Control connections to vsmart and vmanage
BR3-cEdge
tclsh
puts [open "bootflash:root_ca.cer" w+] {
-----BEGIN CERTIFICATE-----
MIIDnzCCAoegAwIBAgIQYJ1ACvIQRIlBAEITkoGNuzANBgkqhkiG9w0BAQsFADBi
MRUwEwYKCZImiZPyLGQBGRYFY2lzY28xEzARBgoJkiaJk/IsZAEZFgNzeXMxEzAR
BgoJkiaJk/IsZAEZFgNvcjIxHzAdBgNVBAMTFm9yMi1XSU4tVlEwOEc2VTk4R0Yt
Q0EwHhcNMjUwNzA2MjE1MjA1WhcNMzAwNzA2MjIwMjA1WjBiMRUwEwYKCZImiZPy
LGQBGRYFY2lzY28xEzARBgoJkiaJk/IsZAEZFgNzeXMxEzARBgoJkiaJk/IsZAEZ
FgNvcjIxHzAdBgNVBAMTFm9yMi1XSU4tVlEwOEc2VTk4R0YtQ0EwggEiMA0GCSqG
SIb3DQEBAQUAA4IBDwAwggEKAoIBAQCr6cjaoJz3vzgHlQ1hzhuy5WfIL/Ao0isM
ltIaGL+Z+9WftM1hNh10YECbxR71+lIpQKyBQTXQz8Of4nycxHjoI3dQdUvEYb8H
fysDXh4lYjQ60x82e5c7f1KPbD+AOhC31Zw1dgReMlPIuaa9LK903+z0FRnuCHaI
EG/Z9uCmv3JC22NgL69hscZc+NUGymMy1iBPN8G4EBkgqNVZ+zlRf/adW0JxEdc6
Sy53bp586/fXziRTW++jgdnhvfpn+VJ+BdG88/rEgMl7PUQE95lq4dih7qx0+OXu
ihFwQQvFxvi3dyqWWc0C1RKHPHtYQFz8rRuBJrR+uzgc0lVhrNHdAgMBAAGjUTBP
MAsGA1UdDwQEAwIBhjAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQWBBQ/bI8yZeKD
fgjmmeWorjGo25t5hzAQBgkrBgEEAYI3FQEEAwIBADANBgkqhkiG9w0BAQsFAAOC
AQEAdtt6aiABkDDg/mAlcZfFPHcqmEEvQaMPeBaUqvfZKNrFVO8GMb9kingZJ62n
K05x5wE3tHy3jBmAl6eHZ/nUjXS11C06NwZMHpcDhty5BcDN08oEYdLF24upisNA
aRLOBhyEtKI9VKLAWfMkpWYEd/dqgVWs67GjAFT0Osgva9QHbz24iT6/c09jbZMt
41opmxacw8FFZcHMH9Afv1fIW9PwscrdlgjSSHR4XQLyDbyuDGsolzeh9PUVyPOd
f+/LYkLwH9jVcHlxl4Oy7MHRPtcbG9T3+vQGLjSAXu3Ybrl2R9Tn/sz5lYs44EEB
mqCxT00LxB3et6jAxJlEyE5vCw==
-----END CERTIFICATE-----
}
exit
controller-mode enable
request platform software sdwan root-cert-chain install bootflash:root_ca.cer
hostname BR3-cEdge
system
system-ip 172.16.0.103
site-id 103
organization-name or2.sys.cisco
vbond vbond.or.sys.cisco
ip host vbond.or.sys.cisco 1.1.0.12
ip route 0.0.0.0 0.0.0.0 1.1.1.250
interface GigabitEthernet1
ip address 1.1.1.103 255.255.255.0
no shutdown
no mop enabled
no mop sysid
negotiation auto
interface Tunnel1
no shutdown
ip unnumbered GigabitEthernet1
tunnel source GigabitEthernet1
tunnel mode sdwan
exit
sdwan
interface GigabitEthernet1
tunnel-interface
encapsulation ipsec
color biz-internet
allow-service all
exit
exit
commit
request platform software sdwan vedge_cloud activate chassis-number C8K-FF74B9C0-47EC-6B46-6F06-B63A33303C0F token 3d4817593d9e42d19092a8a7804051aaFilter Onboarded Nodes
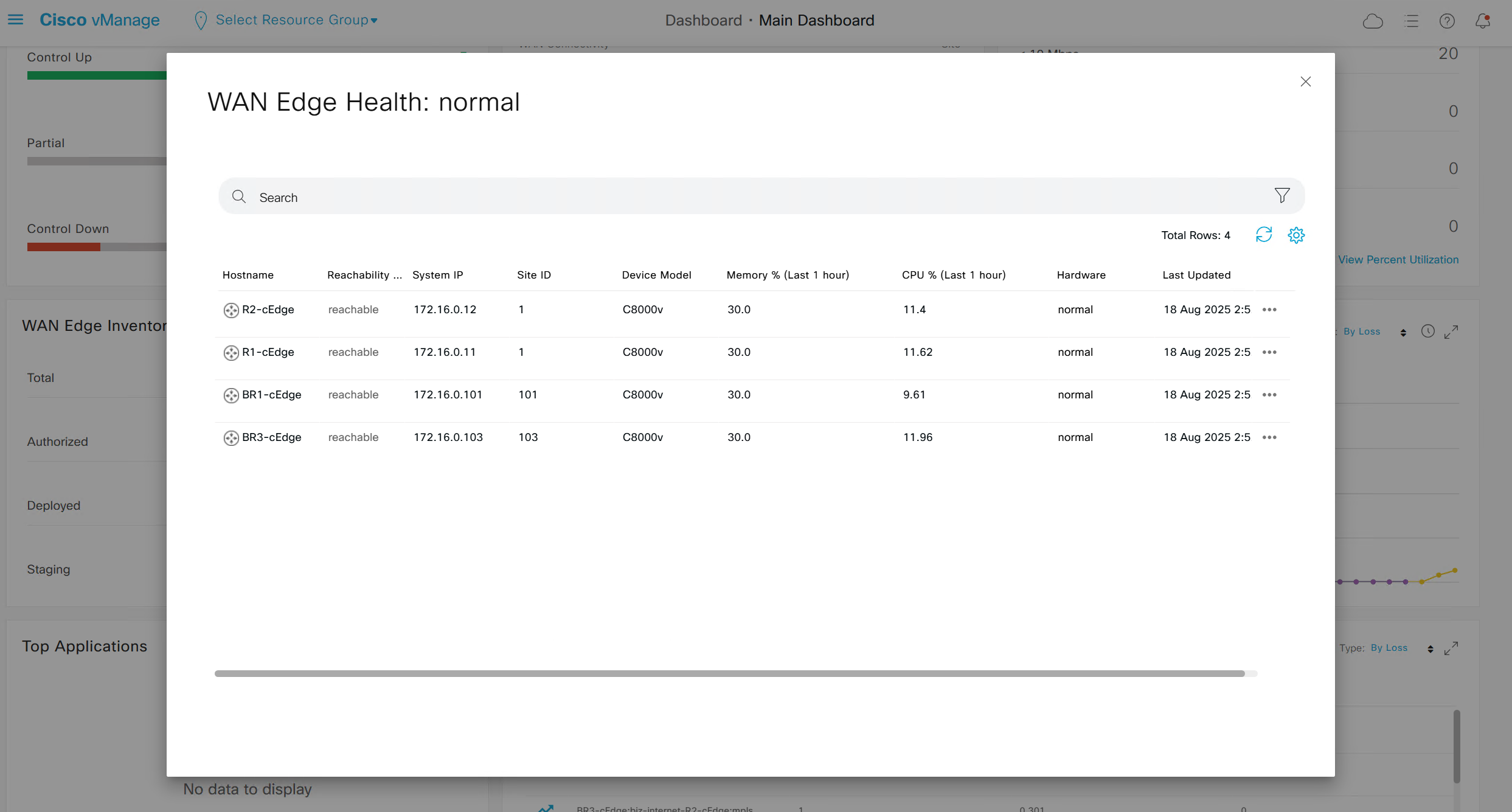
Type “In Sync” in filter on top however it is typed such as “in ync” and onboarded nodes will show
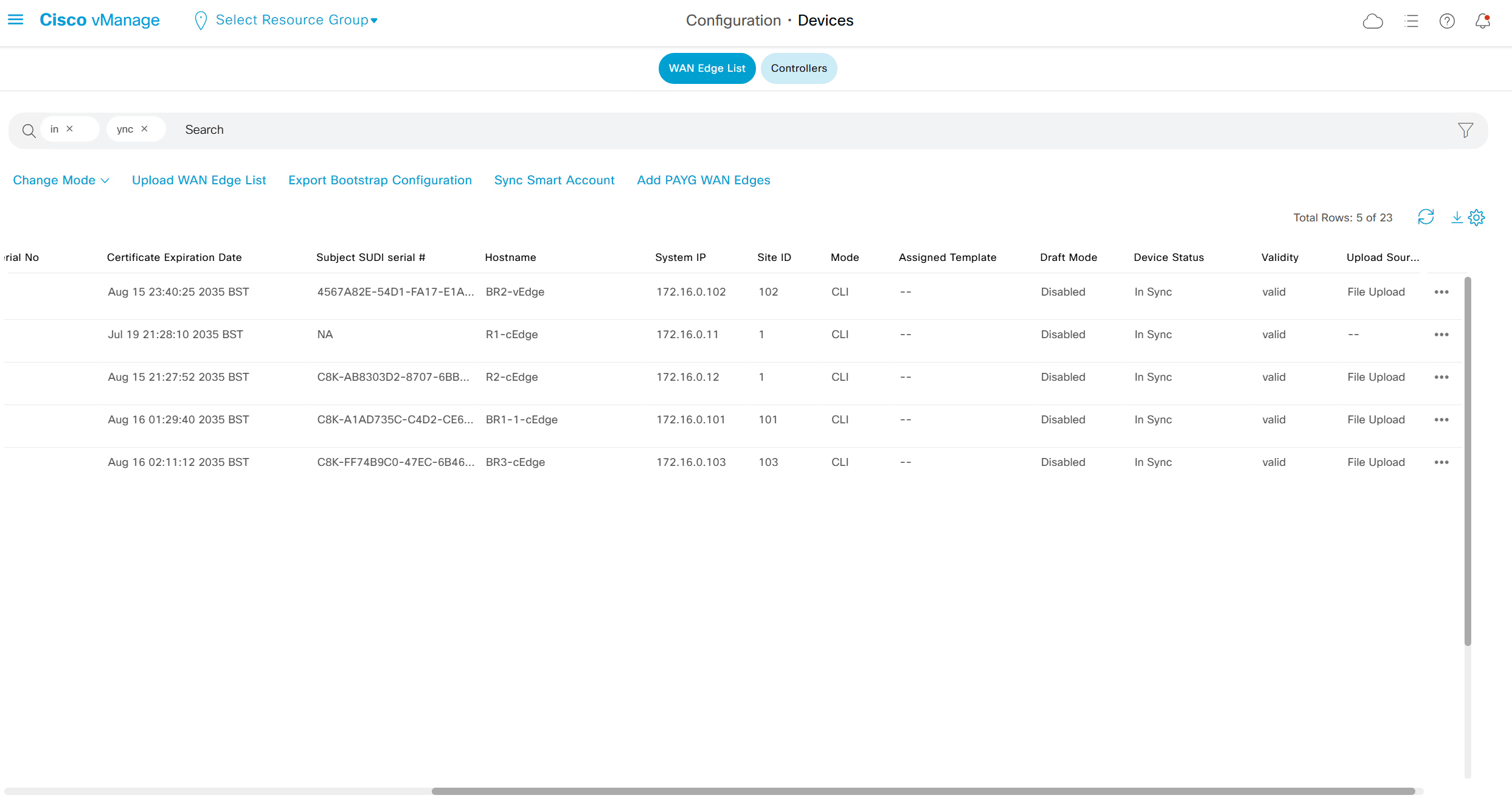
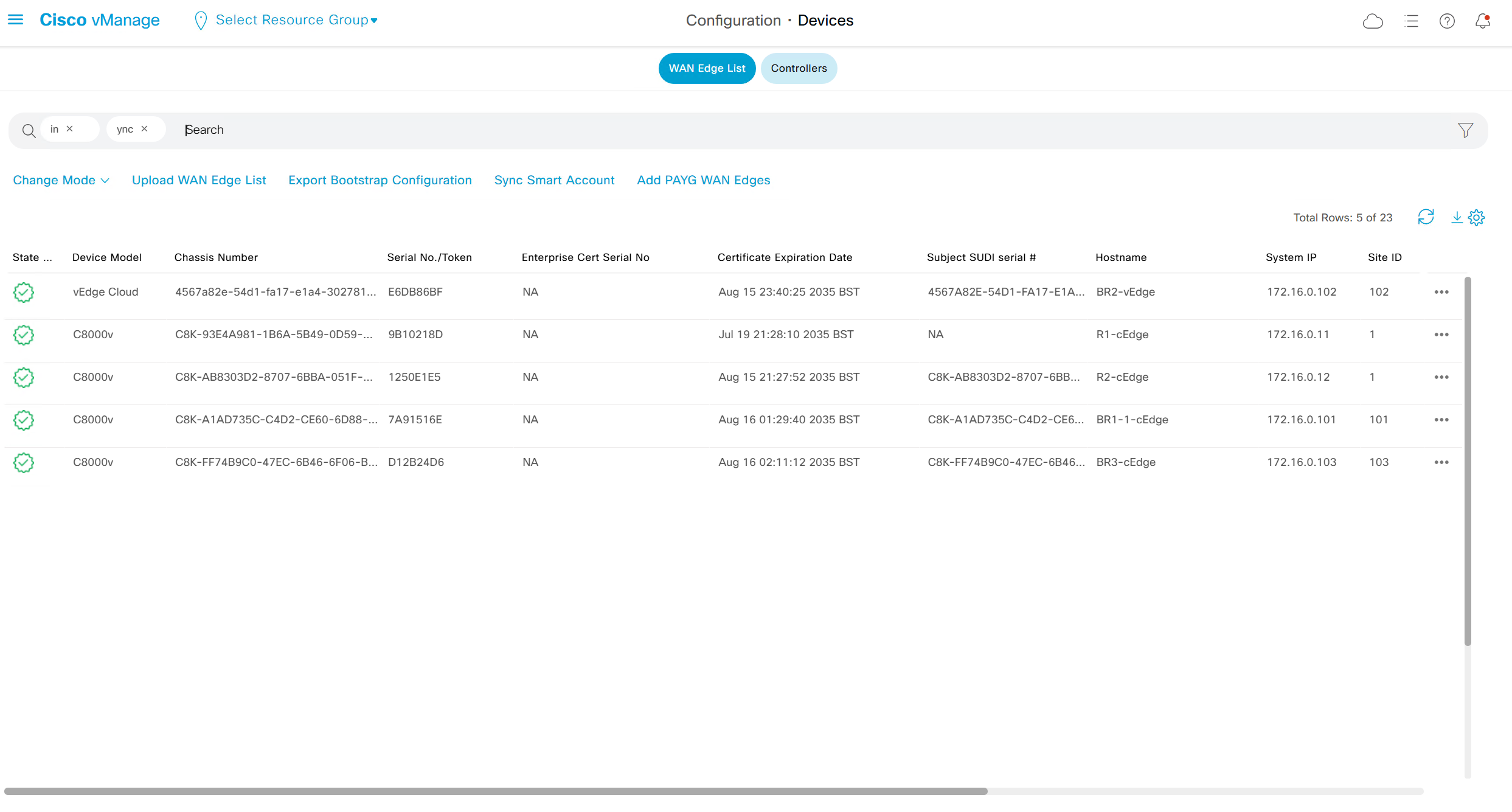
Web Interface

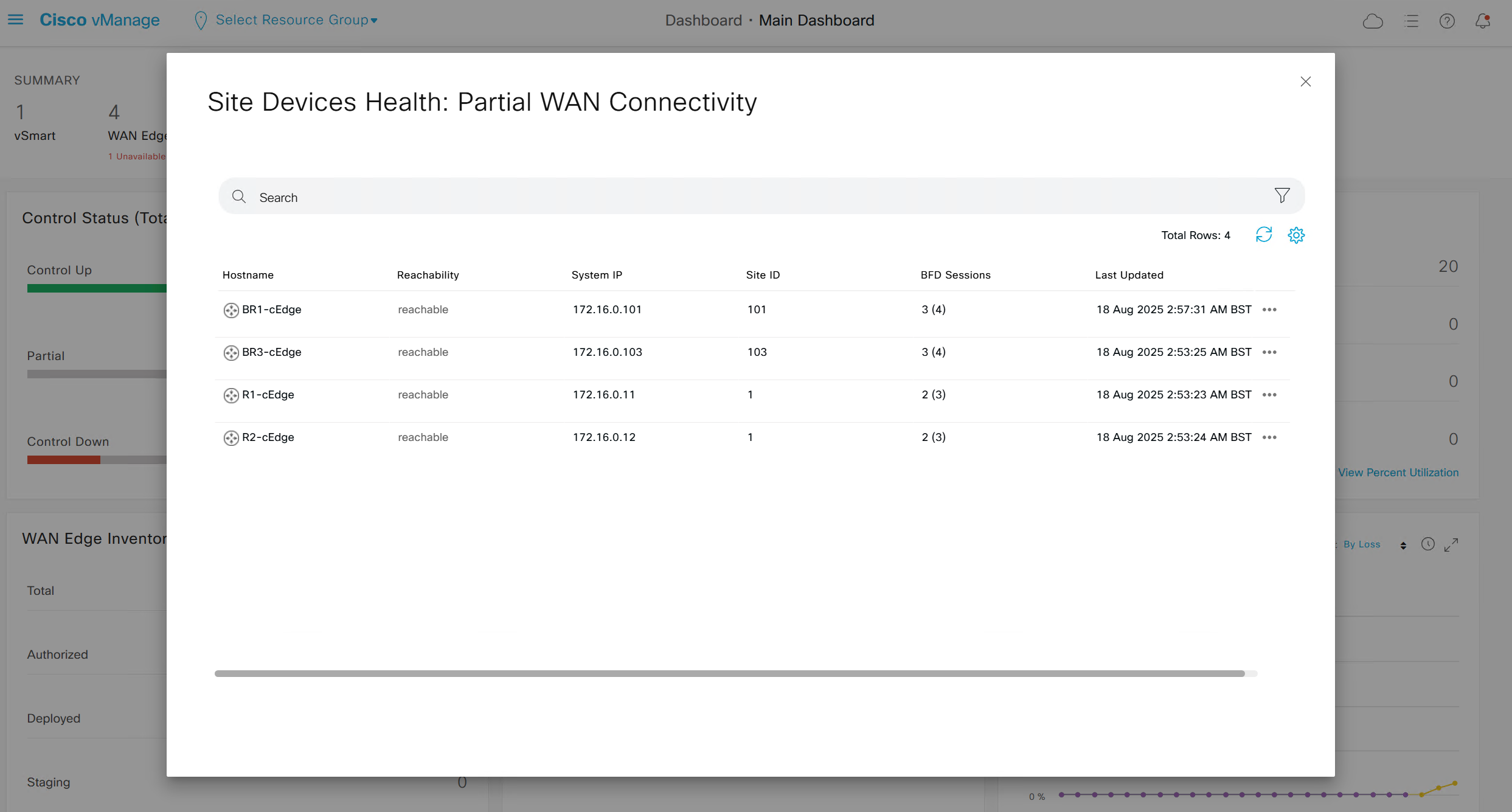
Control Status tells us about the down control connections
Site health shows us status of all the IPSec VPN tunnels between sites
This tells us that BR1-cEdge has 3 tunnels up out of 4, one is down due to BR2-vEdge being down
R1-cEdge and R2-cEdge has 2 tunnels since both are part of same site and they have tunnels to internet based 2 branch sites (out of 3 as site 102 is down)
If we click on number 4 we see
then navigate to “Tunnels” and you will see all the tunnels from one router to remote routers

Navigate to “Real Time” > Device Options: Tunnel BFD Statistics

Inventory and CPU, memory and hardware health
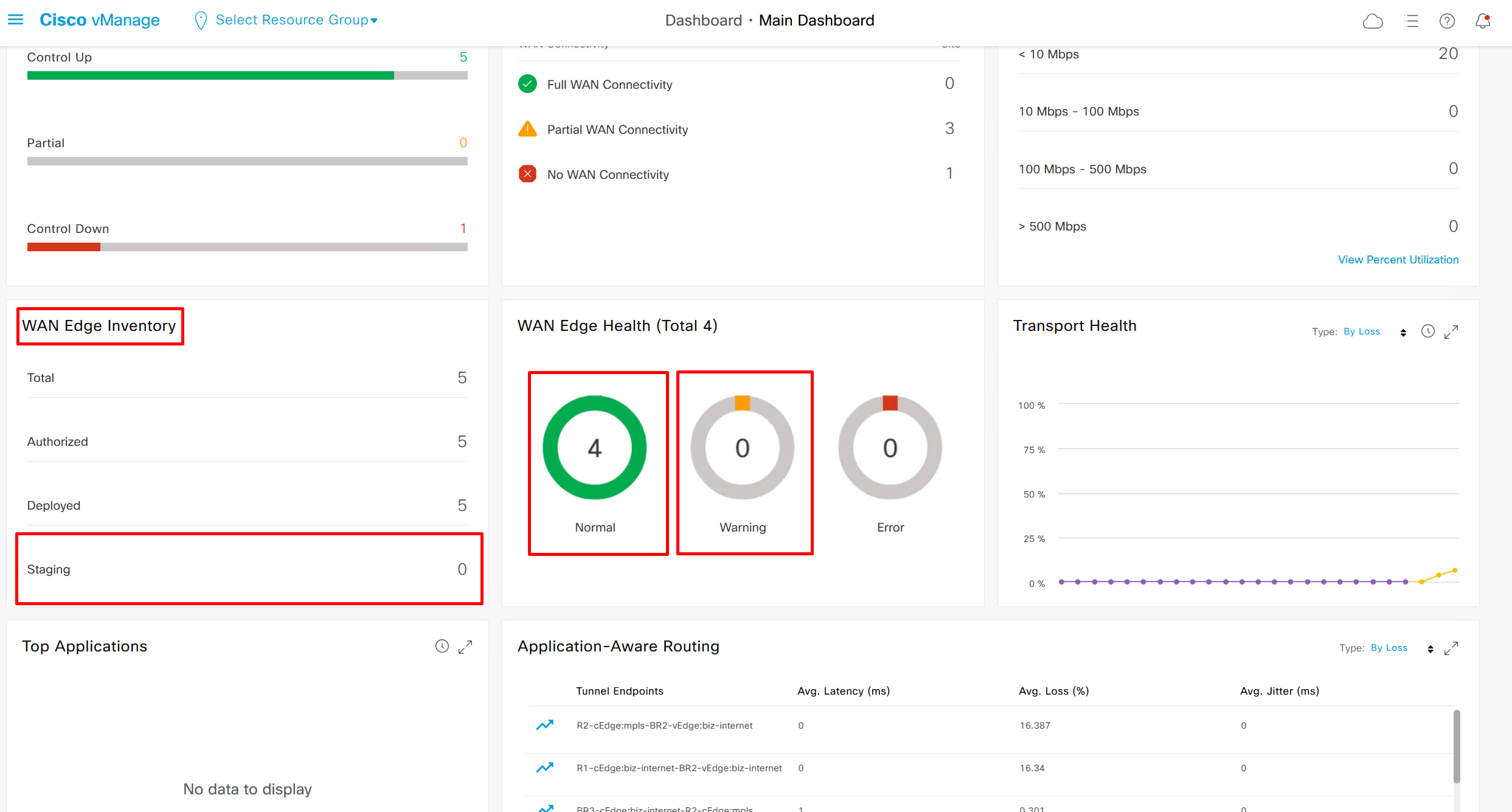
If we click on 4 we see this
Onboarding cEdge “CSR1K” because vEdge is crashing, may be because of version 20.6.1, download new version
Router(tcl)#puts [open "bootflash:root_ca.cer" w+] {
+>-----BEGIN CERTIFICATE-----
+>MIIDnzCCAoegAwIBAgIQYJ1ACvIQRIlBAEITkoGNuzANBgkqhkiG9w0BAQsFADBi
+>MRUwEwYKCZImiZPyLGQBGRYFY2lzY28xEzARBgoJkiaJk/IsZAEZFgNzeXMxEzAR
+>BgoJkiaJk/IsZAEZFgNvcjIxHzAdBgNVBAMTFm9yMi1XSU4tVlEwOEc2VTk4R0Yt
+>Q0EwHhcNMjUwNzA2MjE1MjA1WhcNMzAwNzA2MjIwMjA1WjBiMRUwEwYKCZImiZPy
+>LGQBGRYFY2lzY28xEzARBgoJkiaJk/IsZAEZFgNzeXMxEzARBgoJkiaJk/IsZAEZ
+>FgNvcjIxHzAdBgNVBAMTFm9yMi1XSU4tVlEwOEc2VTk4R0YtQ0EwggEiMA0GCSqG
+>SIb3DQEBAQUAA4IBDwAwggEKAoIBAQCr6cjaoJz3vzgHlQ1hzhuy5WfIL/Ao0isM
+>ltIaGL+Z+9WftM1hNh10YECbxR71+lIpQKyBQTXQz8Of4nycxHjoI3dQdUvEYb8H
+>fysDXh4lYjQ60x82e5c7f1KPbD+AOhC31Zw1dgReMlPIuaa9LK903+z0FRnuCHaI
+>EG/Z9uCmv3JC22NgL69hscZc+NUGymMy1iBPN8G4EBkgqNVZ+zlRf/adW0JxEdc6
+>Sy53bp586/fXziRTW++jgdnhvfpn+VJ+BdG88/rEgMl7PUQE95lq4dih7qx0+OXu
+>ihFwQQvFxvi3dyqWWc0C1RKHPHtYQFz8rRuBJrR+uzgc0lVhrNHdAgMBAAGjUTBP
+>MAsGA1UdDwQEAwIBhjAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQWBBQ/bI8yZeKD
+>fgjmmeWorjGo25t5hzAQBgkrBgEEAYI3FQEEAwIBADANBgkqhkiG9w0BAQsFAAOC
+>AQEAdtt6aiABkDDg/mAlcZfFPHcqmEEvQaMPeBaUqvfZKNrFVO8GMb9kingZJ62n
+>K05x5wE3tHy3jBmAl6eHZ/nUjXS11C06NwZMHpcDhty5BcDN08oEYdLF24upisNA
+>aRLOBhyEtKI9VKLAWfMkpWYEd/dqgVWs67GjAFT0Osgva9QHbz24iT6/c09jbZMt
+>41opmxacw8FFZcHMH9Afv1fIW9PwscrdlgjSSHR4XQLyDbyuDGsolzeh9PUVyPOd
+>f+/LYkLwH9jVcHlxl4Oy7MHRPtcbG9T3+vQGLjSAXu3Ybrl2R9Tn/sz5lYs44EEB
+>mqCxT00LxB3et6jAxJlEyE5vCw==
+>-----END CERTIFICATE-----
+>}
Router(tcl)#exitFirst stop the PnP service so that the SD-WAN software packages can install
pnpa service discovery stopOnce the PnP service has been stopped, we tell the router to install all underlying SD-WAN packages if necessary. Depending on the CSR1k software image, this may not be necessary.
request platform software sdwan software resetThe last step is to verify the software image using the following command
request platform software sdwan software upgrade-confirmsee that the sdwan software is ACTIVE and CONFIRMED as highlighted below.
show sdwan soft
VERSION ACTIVE DEFAULT PREVIOUS CONFIRMED TIMESTAMP
---------------------------------------------------------------------------------
16.12.4.0.4480 true true false user 2022-04-03T08:20:13-00:00
Total Space:388M Used Space:87M Available Space:297Min newer CSR1000v versions we dont have to do above and we can directly do
controller-mode enableOnce the router loads up with the SD-WAN software, we can go ahead and configure the minimal configuration required to join the SD-WAN overlay fabric. Notice that when the cEdge router runs in Controller mode (basically SD-WAN mode), we enter the configuration mode using the “config-transaction” command instead of the well-known “configure terminal” or simply “conf t”.
Notice something very important – the Tunnel keyword in the “interface Tunnel” command should always be with a capital T. It is not like in a regular Cisco IOS where you can create a new tunnel using the “interface tunnel 1” command.
config-transaction
hostname cEdge
!
int GigabitEthernet1
ip address 39.3.1.1 255.255.255.0
no shut
!
int GigabitEthernet2
ip address 10.10.1.1 255.255.255.0
no shut
!
ip route 0.0.0.0 0.0.0.0 39.3.1.254
ip route 0.0.0.0 0.0.0.0 10.10.1.254
ip host vbond.networkacademy.io 10.1.1.10
!
system
system-ip 1.1.1.1
site-id 1
organization-name "networkacademy-io"
vbond vbond.networkacademy.io
commitsdwan
int GigabitEthernet1
tunnel-interface
color biz-internet
encapsulation ipsec
!
int GigabitEthernet2
tunnel-interface
color mpls restrict
encapsulation ipsec
!
interface Tunnel 1
ip unnumbered GigabitEthernet1
tunnel source GigabitEthernet1
tunnel mode sdwan
!
interface Tunnel 2
ip unnumbered GigabitEthernet2
tunnel source GigabitEthernet2
tunnel mode sdwan
commitInstall root ca cert through tclsh and same steps can be followed as C8000v
Template Configuration on Edges and Controllers
Highlighted config is the one we need to configure the template
Each “section” will need a “feature template”
Remember that we need to configure system, vpn 0 (routing table for transport) and interface feature templates
BR1-1-cEdge#show sdwan running-config
system
system-ip 172.16.0.101
site-id 101
admin-tech-on-failure
organization-name or2.sys.cisco
vbond vbond.or.sys.cisco
!
memory free low-watermark processor 68484
no service tcp-small-servers
no service udp-small-servers
platform console serial
platform qfp utilization monitor load 80
platform punt-keepalive disable-kernel-core
hostname BR1-1-cEdge
username admin privilege 15 secret 5 $1$3/FD$EA4V.gZeQ6hMyUG2ct/ax.
no ip finger
no ip rcmd rcp-enable
no ip rcmd rsh-enable
no ip dhcp use class
ip host vbond.or.sys.cisco 1.1.0.12
ip route 0.0.0.0 0.0.0.0 1.1.1.250
ip ssh version 2
no ip http server
ip http secure-server
ip nat settings central-policy
ip nat settings gatekeeper-size 1024
interface GigabitEthernet1
no shutdown
ip address 1.1.1.101 255.255.255.0
no mop enabled
no mop sysid
negotiation auto
exit
interface GigabitEthernet2
no shutdown
no mop enabled
no mop sysid
negotiation auto
exit
interface GigabitEthernet3
no shutdown
no mop enabled
no mop sysid
negotiation auto
exit
interface GigabitEthernet4
no shutdown
no mop enabled
no mop sysid
negotiation auto
exit
interface Tunnel1
no shutdown
ip unnumbered GigabitEthernet1
tunnel source GigabitEthernet1
tunnel mode sdwan
exit
aaa authentication enable default enable
aaa authentication login default local
aaa authorization console
aaa authorization exec default local
login on-success log
line aux 0
!
line con 0
stopbits 1
!
line vty 0 4
!
line vty 5 80
!
sdwan
interface GigabitEthernet1
tunnel-interface
encapsulation ipsec
color biz-internet
allow-service all
no allow-service bgp
allow-service dhcp
allow-service dns
allow-service icmp
no allow-service sshd
no allow-service netconf
no allow-service ntp
no allow-service ospf
no allow-service stun
allow-service https
no allow-service snmp
no allow-service bfd
exit
exit
appqoe
no tcpopt enable
no dreopt enable
!
omp
no shutdown
graceful-restart
no as-dot-notation
address-family ipv4
advertise connected
advertise static
!
address-family ipv6
advertise connected
advertise static
!
!
!
licensing config enable false
licensing config privacy hostname false
licensing config privacy version false
licensing config utility utility-enable false
security
ipsec
integrity-type ip-udp-esp esp
!
!
sslproxy
no enable
rsa-key-modulus 2048
certificate-lifetime 730
eckey-type P256
ca-tp-label PROXY-SIGNING-CA
settings expired-certificate drop
settings untrusted-certificate drop
settings unknown-status drop
settings certificate-revocation-check none
settings unsupported-protocol-versions drop
settings unsupported-cipher-suites drop
settings failure-mode close
settings minimum-tls-ver TLSv1
dual-side optimization enable
!

Device Specific variables mean that value will be taken from us at the time when we attach the template to device
Global means that all the devices that are attached to this template will inherit same static value
Each section of the running-config will require a feature template

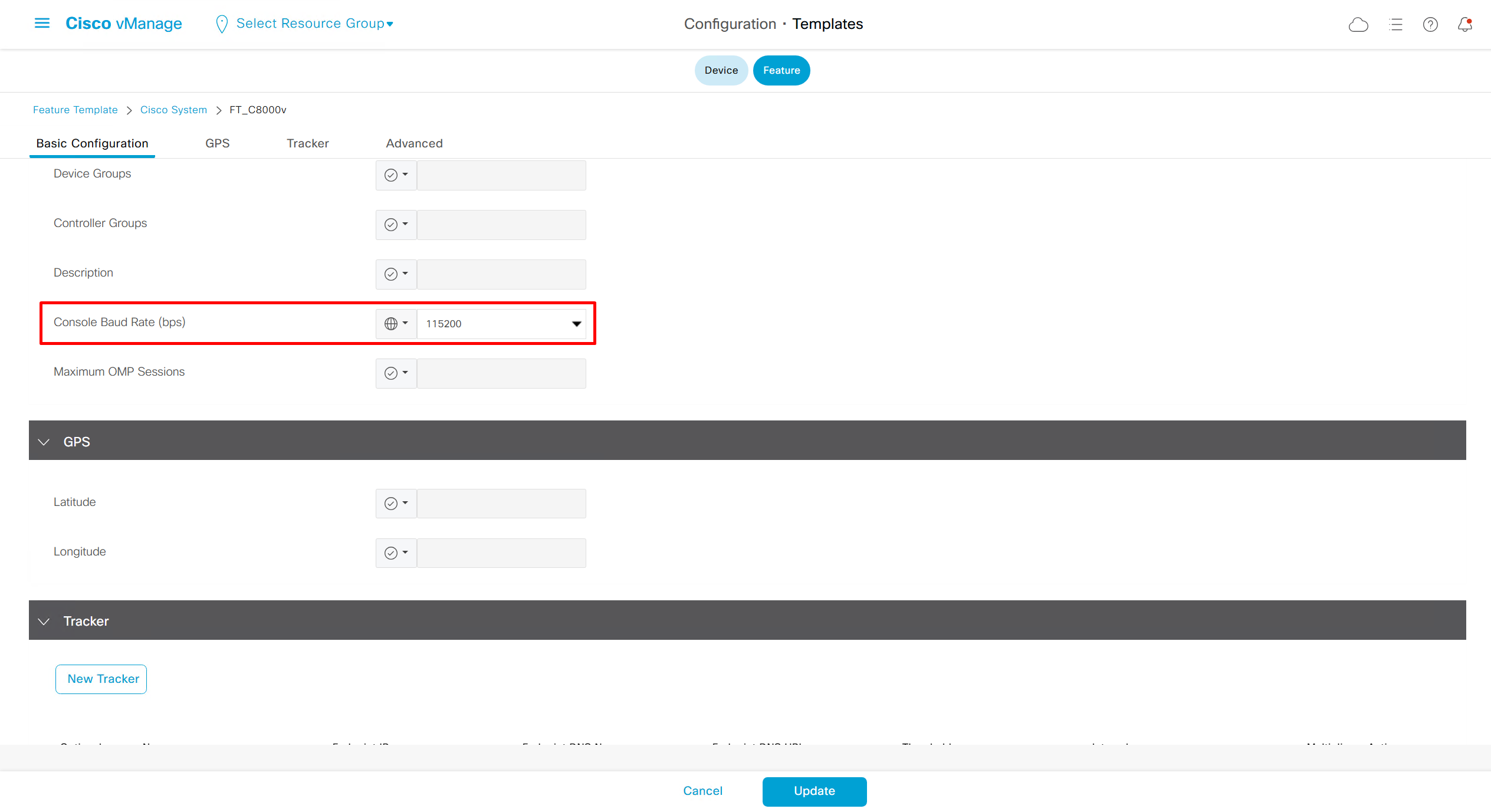
Enhance ECMP Keyring when turned on, also considers the source and destination port to calculate the ECMP
DNS and Static IPv4 routes will come under the GRT
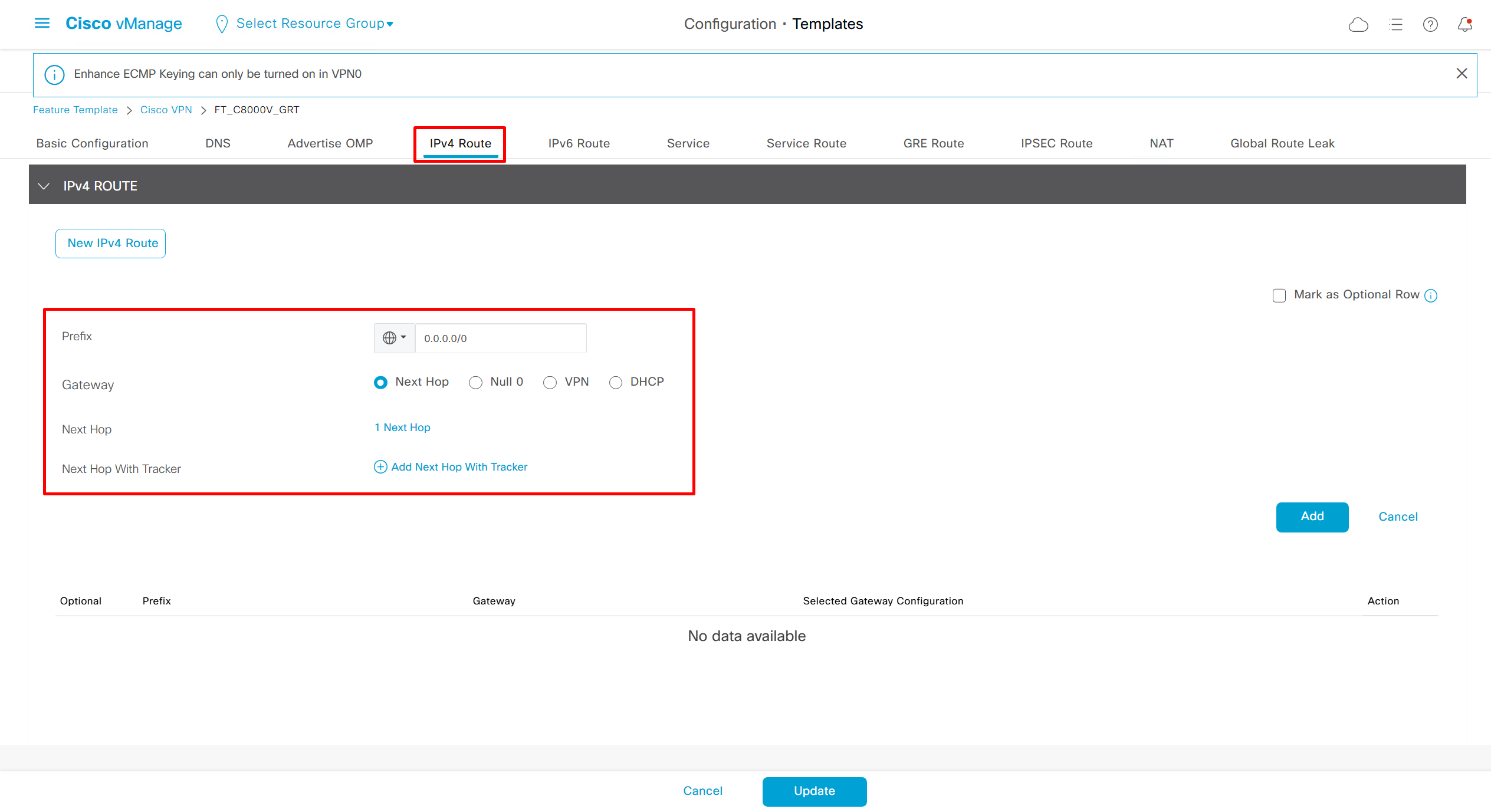
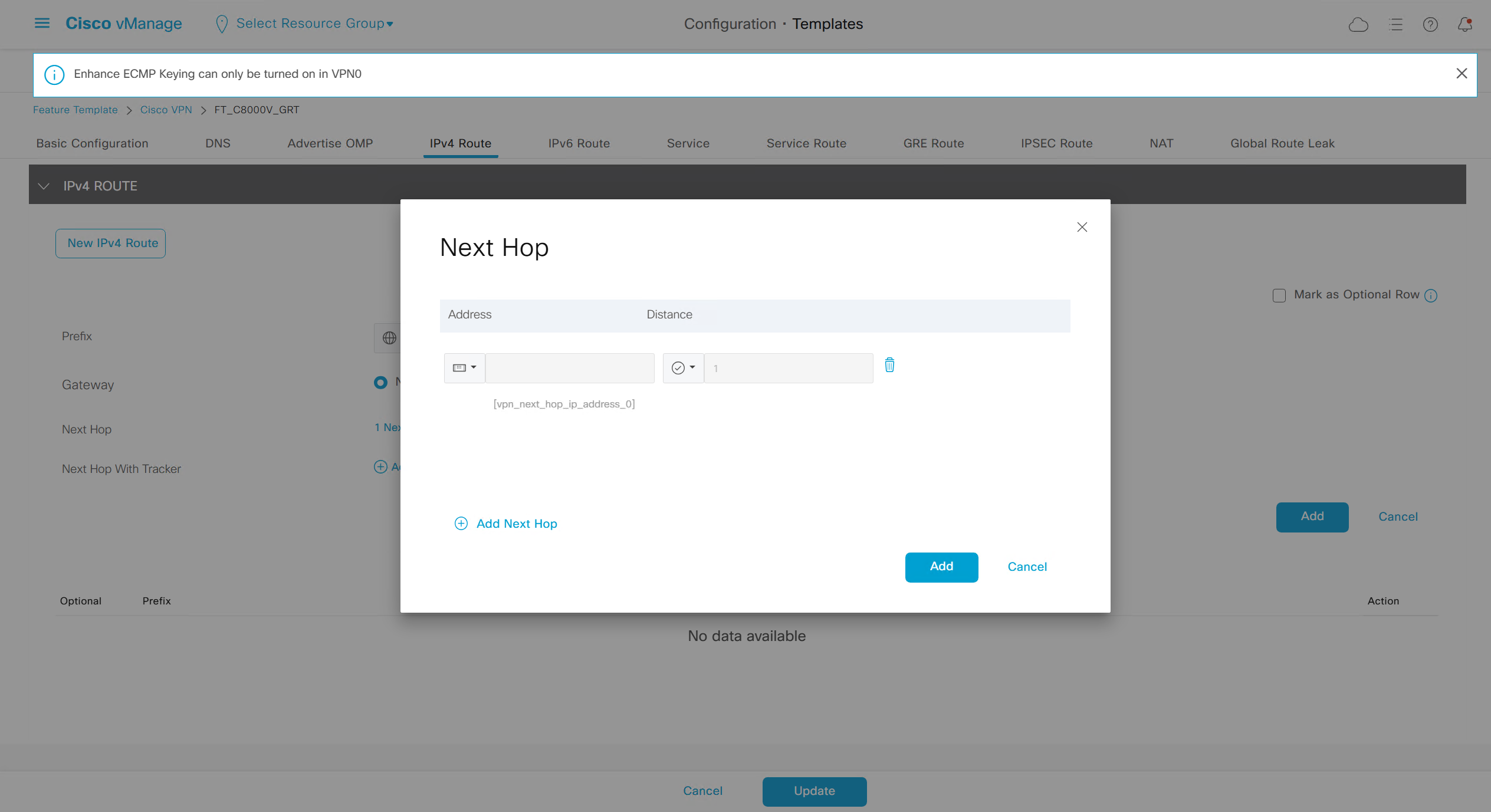
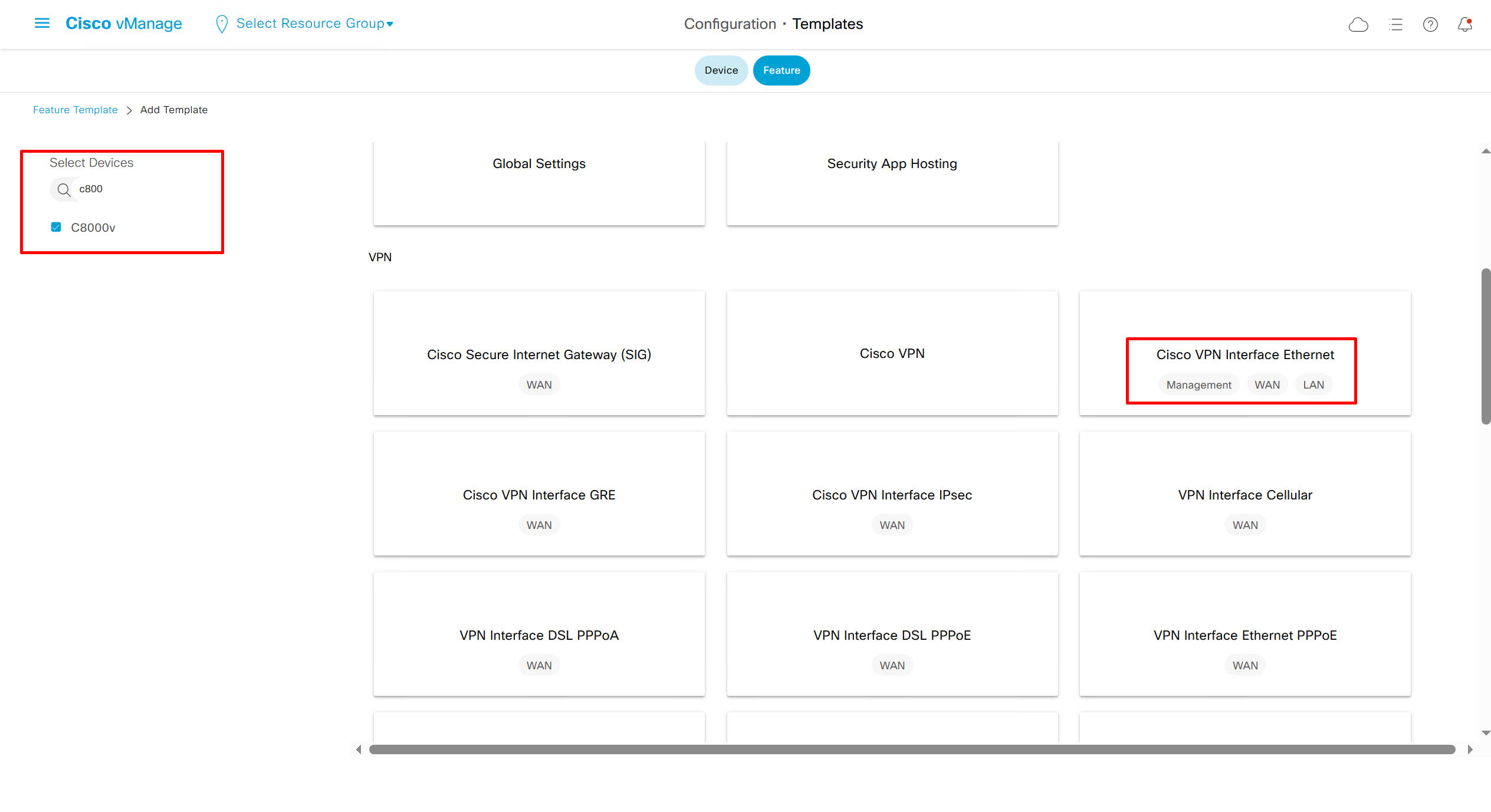
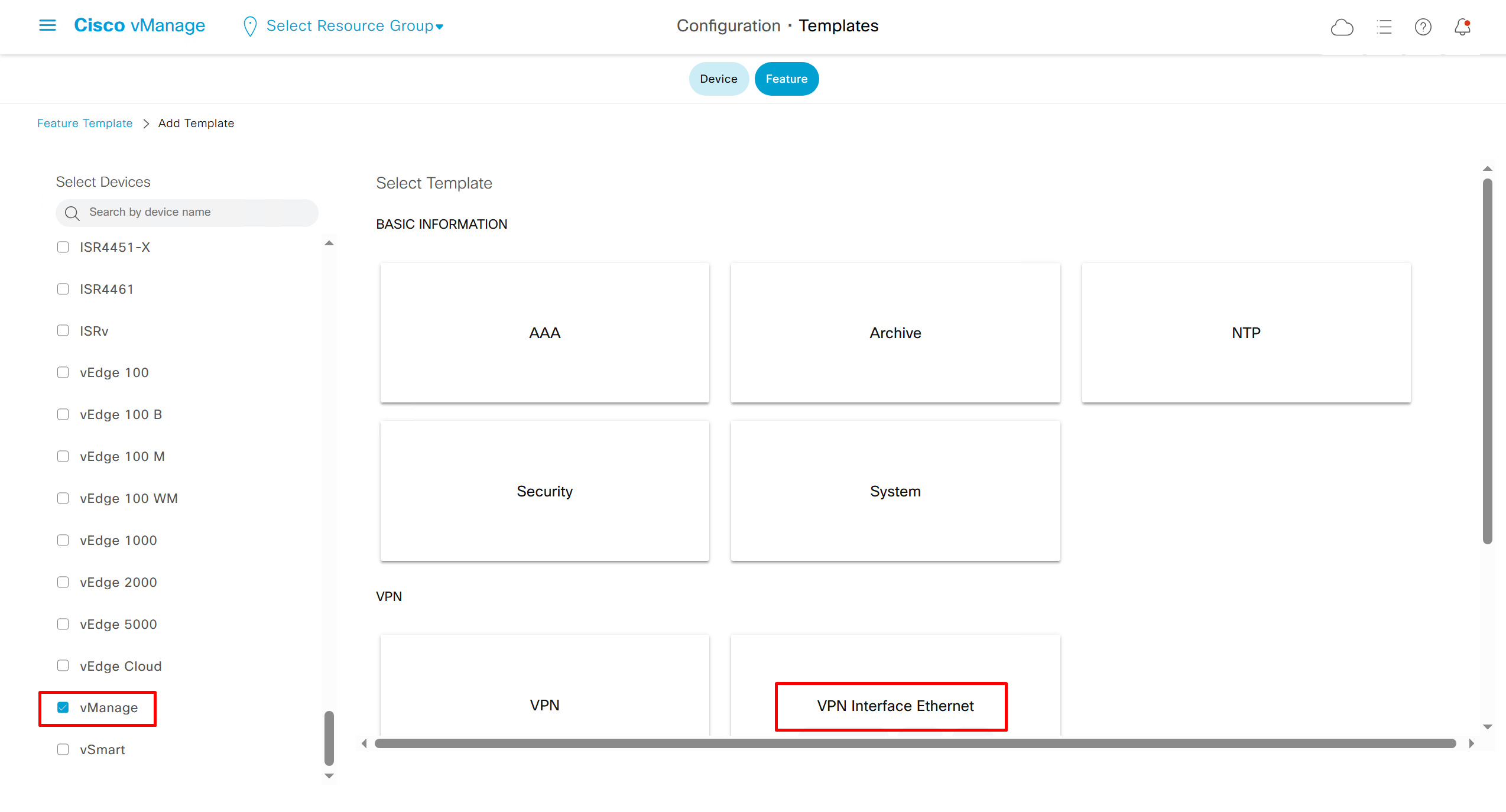
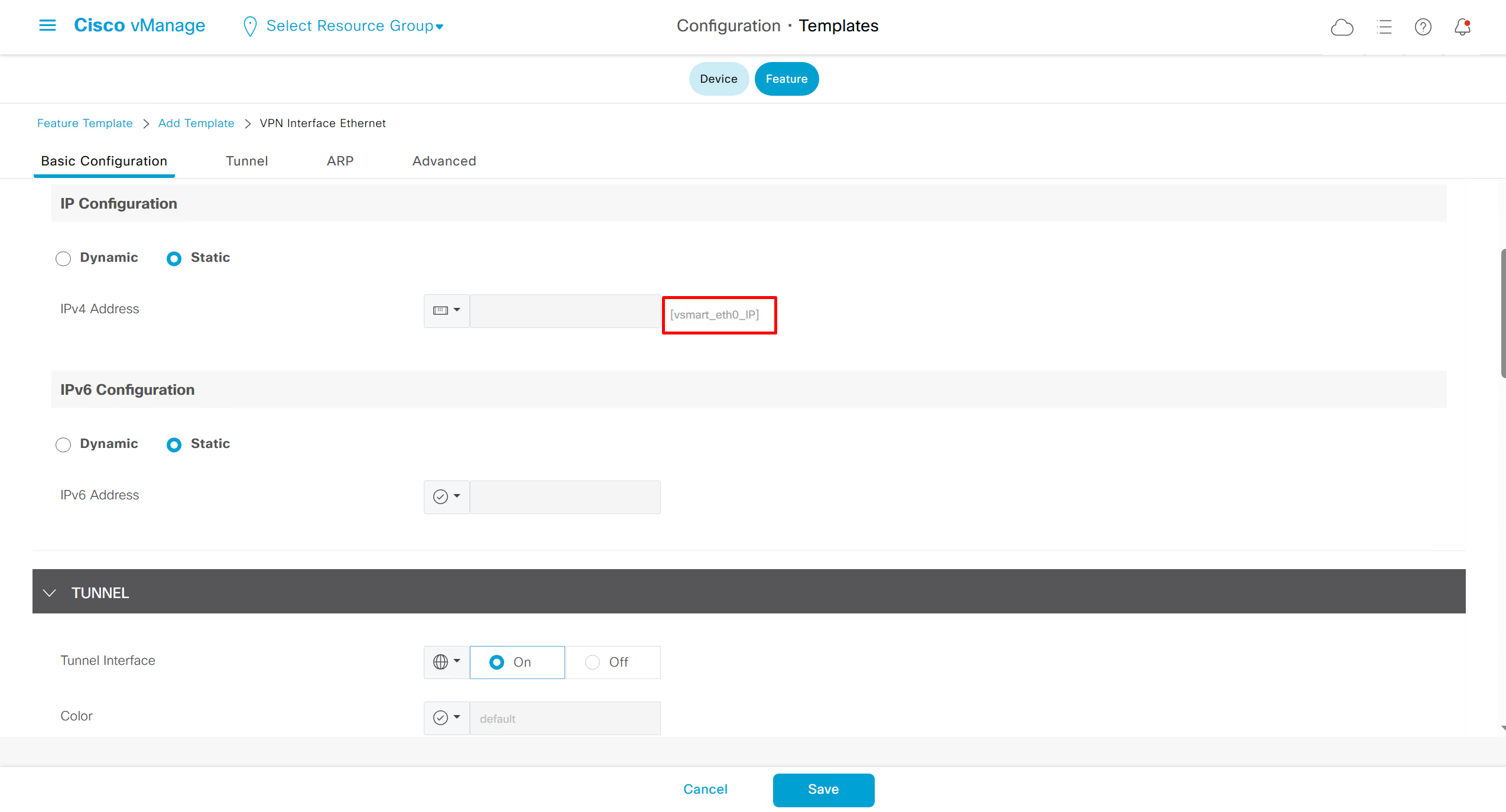
If devices models are different then each device model will need its own feature due to difference in interface names > Cisco VPN interface ethernet template
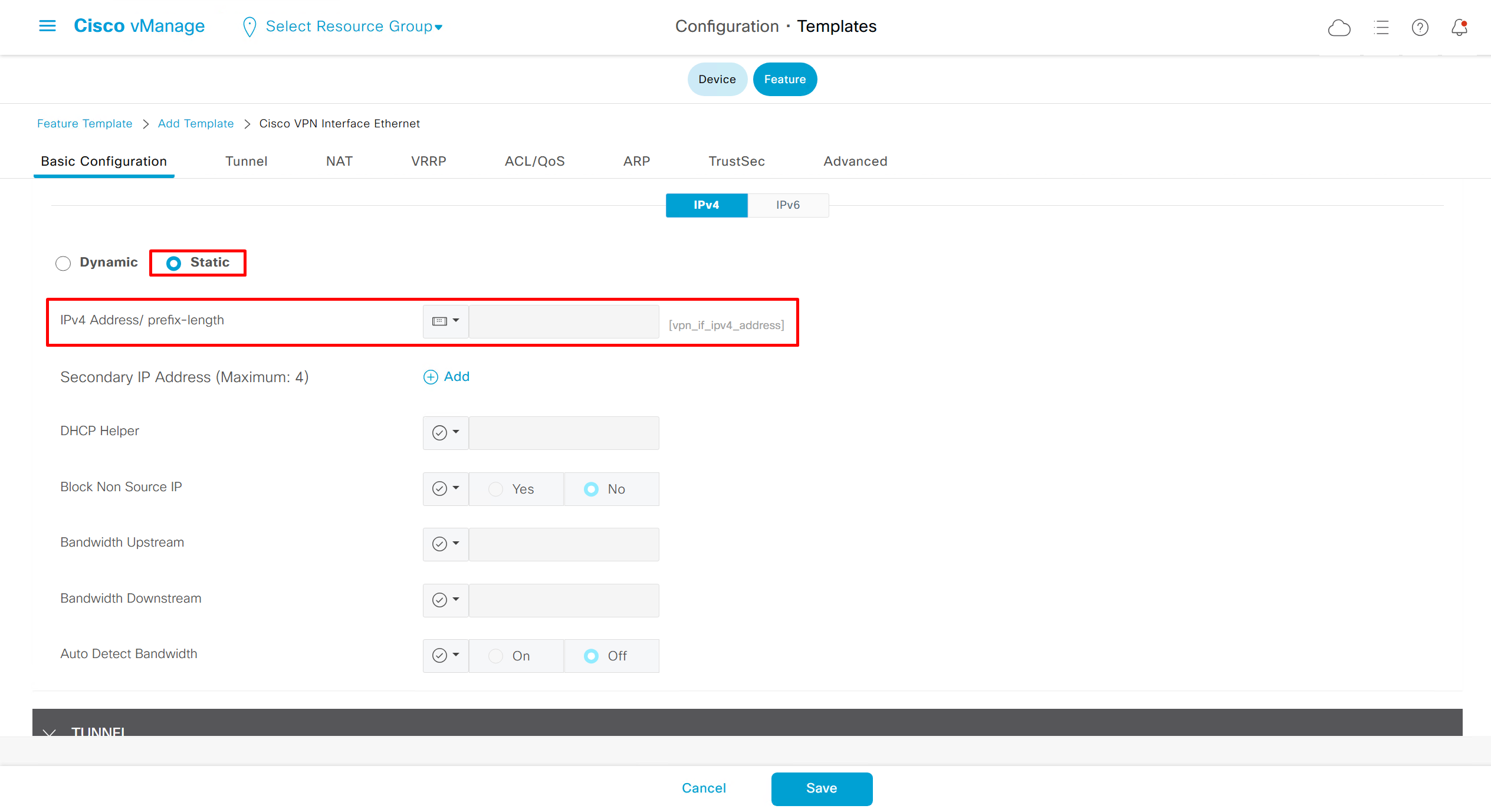

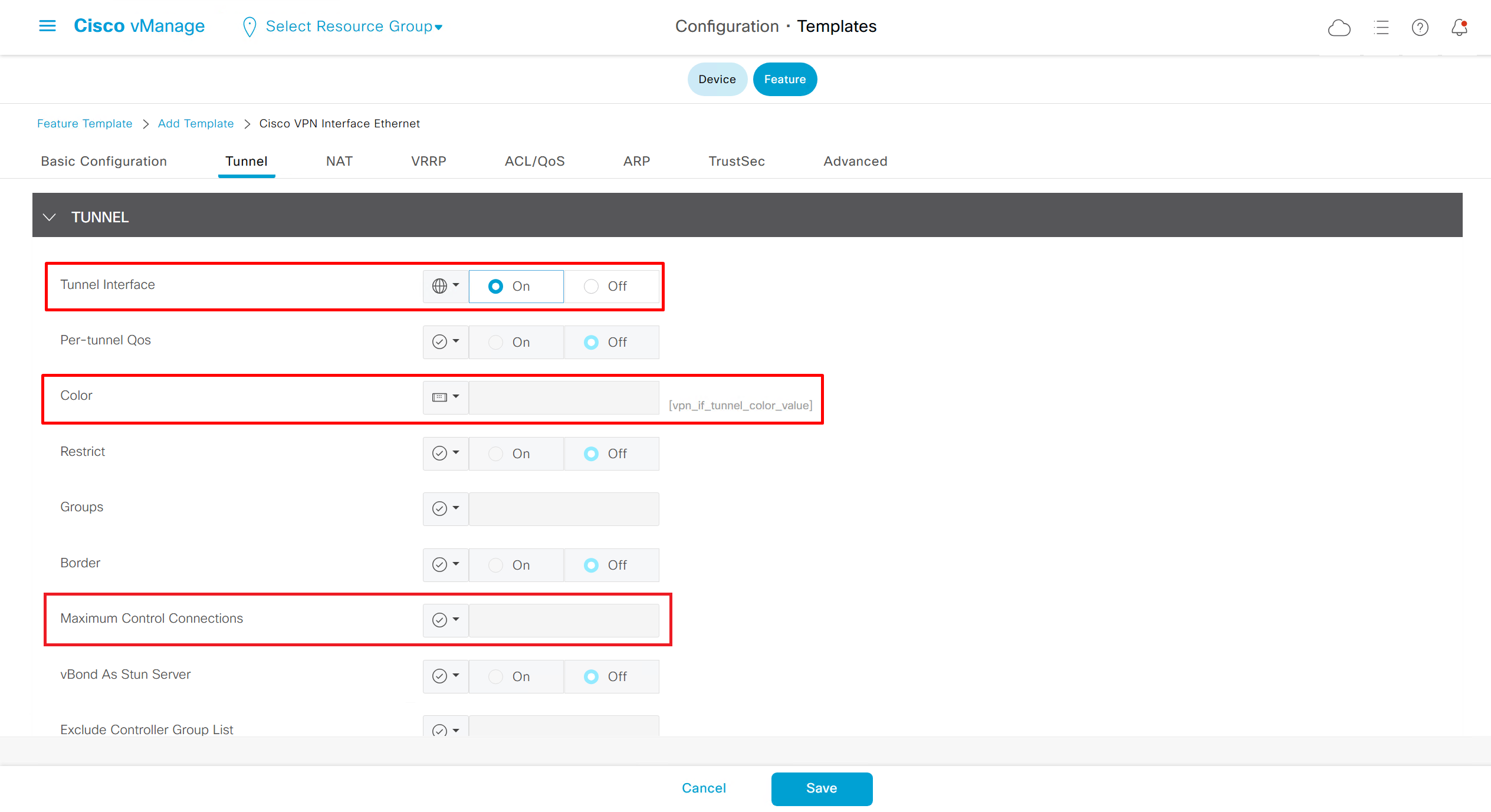
if this color does not have reachability to controllers such as MPLS connection then make Maximum Control Connections to 0
Setting Maximum Control Connections to 0 on MPLS only sites caused loss of control connections to all controllers and because of loss of connections caused rollback because MPLS was only connection to site
Maximum control connections allow sites to have no connection to controllers (not just vmanage, but vsmart and vbond also) from that color, but still have “data tunnels” from that color
Exclude Controller Group List: This is group of controllers that you dont want the edge to connect to, this is important when we dont want edge to connect to vsmart in far regions.

vManage Connection Preference: by default is 5, a link with higher preference is used to connect to vmanage in case we have 2x transports because only one vmanage connection is established
Port hop
By default, WAN Edge devices (vEdge, C8000V) form control connections with controllers (vBond, vSmart, vManage) using:
DTLS (UDP 12346)
TLS (TCP 443)
So normally, traffic will keep using those fixed ports.
When Port Hop is enabled, the “WAN Edge” will not stick to just a single fixed port. Instead, it will cycle through a range of ports if a connection attempt fails.
- DTLS (UDP):
- Starts with UDP/12346.
- If blocked, it will try other ports in the UDP range 12346–12846.
- It keeps retrying until it finds an open port.
- TLS (TCP):
- Starts with TCP/443.
- If blocked, it will try other ports in the TCP range 443–12443.
- Again, hops until success.
This makes control connections much more resilient in restrictive or dynamic network environments where firewalls are doing inspections and rate limiting traffic
Sometimes port hop can be issue
Control connections on the router, you see it is up from last 4 mins and 12 seconds. It will again retrigger after completing 5 mins
NDNA_c8000v#sh sdwan control connections
PEER PEER CONTROLLER
PEER PEER PEER SITE DOMAIN PEER PRIV PEER PUB GROUP
TYPE PROT SYSTEM IP ID ID PRIVATE IP PORT PUBLIC IP PORT ORGANIZATION LOCAL COLOR PROXY STATE UPTIME ID
------------------------------------------------------------------------------------------------------------------------------------------------------------
vsmart dtls 10.10.10.11 1 1 10.10.3.5 12646 17.23.12.11 12646 NDNA-111 gold No up 0:00:04:12 0
vsmart dtls 10.10.10.12 2 1 10.10.3.15 12646 17.23.12.25 12646 NDNA-111 gold No up 0:00:04:12 0
vmanage dtls 10.10.10.10 1 0 10.10.3.12 13046 17.23.12.88 13046 NDNA-111 gold No up 0:00:04:12 0 checked again after like a minute now and you will notice, it is showing 8 seconds now which means it is bounced again.
NDNA_c8000v#sh sdwan control connections
PEER PEER CONTROLLER
PEER PEER PEER SITE DOMAIN PEER PRIV PEER PUB GROUP
TYPE PROT SYSTEM IP ID ID PRIVATE IP PORT PUBLIC IP PORT ORGANIZATION LOCAL COLOR PROXY STATE UPTIME ID
------------------------------------------------------------------------------------------------------------------------------------------------------------
vsmart dtls 10.10.10.11 1 1 10.10.3.5 12646 17.23.12.11 12646 NDNA-111 gold No up 0:00:00:08 0
vsmart dtls 10.10.10.12 2 1 10.10.3.15 12646 17.23.12.25 12646 NDNA-111 gold No up 0:00:00:08 0
vmanage dtls 10.10.10.10 1 0 10.10.3.12 13046 17.23.12.88 13046 NDNA-111 gold No up 0:00:00:08 0For troubleshooting, move the router to CLI mode
First check the mode in which router is working, if we see below in red, the template is attached to the router which means the router is in controller mode.
Personality: vEdge
Model name: C8000V
Device role: cEdge-SDWAN
Services: None
vManaged: true
Commit pending: false
Configuration template: AZURE-NDNA-V01
Chassis serial number: XXXXXXXXXXXXXXMove the router from controller mode to CLI mode in order to do packet captures on the router. Although it is recommended to capture using vmanage datastream mode
Once you moved, run the below script in order to capture the packets on the interface with the source and the destination IPs as shown below :
!
ip access-list extended CAP-Filter
10 permit ip host 10.10.1.23 host 17.23.12.88
20 permit ip host 17.23.12.88 host 10.10.1.23
exit
monitor capture CAP access-list CAP-Filter interface GigabitEthernet1 both buffer circular size 25
monitor capture CAP limit pps 1000000
monitor capture CAP access-list CAP-Filter both buffer circular size 25
monitor capture CAP start
monitor capture CAP stop
!Now run below commands to get debugs
NDNA_c8000v# debug platform software sdwan vdaemon all high
NDNA_c8000v# monitor logging process vdaemon internalOnce you run the above commands, you will see logs related to the interfaces
You will see that in debug logs , TLOC Disable … Why ?
2024/04/19 17:47:59.779970993 {vdaemon_R0-0}{255}: [event] [18342]: (debug): Disabling tloc GigabitEthernet1.
2024/04/19 17:47:59.780001093 {vdaemon_R0-0}{255}: [misc] [18342]: (ERR): Delta preference value added to TLOC pref.
2024/04/19 17:47:59.780003193 {vdaemon_R0-0}{255}: [misc] [18342]: (ERR): Sending TLOC: ifname:GigabitEthernet3 color:gold spi:18915 smarts:2 manages:1 state:DOWN LR encap:0 LR hold time:7000 bw:0, down-bw 0 range: 0-0,adapt period 0 up-bw range 0-0 up_fia 0 capability:0x3fCheck the interface for port-hop and you will see port-hop is enabled. Now disable the port hop and you will see the control connections will be stable
interface GigabitEthernet1
tunnel-interface
encapsulation ipsec weight 1
no border
color gold restrict
no last-resort-circuit
no low-bandwidth-link
no vbond-as-stun-server
vmanage-connection-preference 5
port-hopCheck the control connection after disabling port-hop on the interface , you will see it is up from last 19 min. and stable.
NDNA_c8000v#sh sdwan control connections
PEER PEER CONTROLLER
PEER PEER PEER SITE DOMAIN PEER PRIV PEER PUB GROUP
TYPE PROT SYSTEM IP ID ID PRIVATE IP PORT PUBLIC IP PORT ORGANIZATION LOCAL COLOR PROXY STATE UPTIME ID
------------------------------------------------------------------------------------------------------------------------------------------------------------
vsmart dtls 10.10.10.11 1 1 10.10.3.5 12646 17.23.12.11 12646 NDNA-111 gold No up 0:00:19:02 0
vsmart dtls 10.10.10.12 2 1 10.10.3.15 12646 17.23.12.25 12646 NDNA-111 gold No up 0:00:19:02 0
vmanage dtls 10.10.10.10 1 0 10.10.3.12 13046 17.23.12.88 13046 NDNA-111 gold No up 0:00:19:02 0 
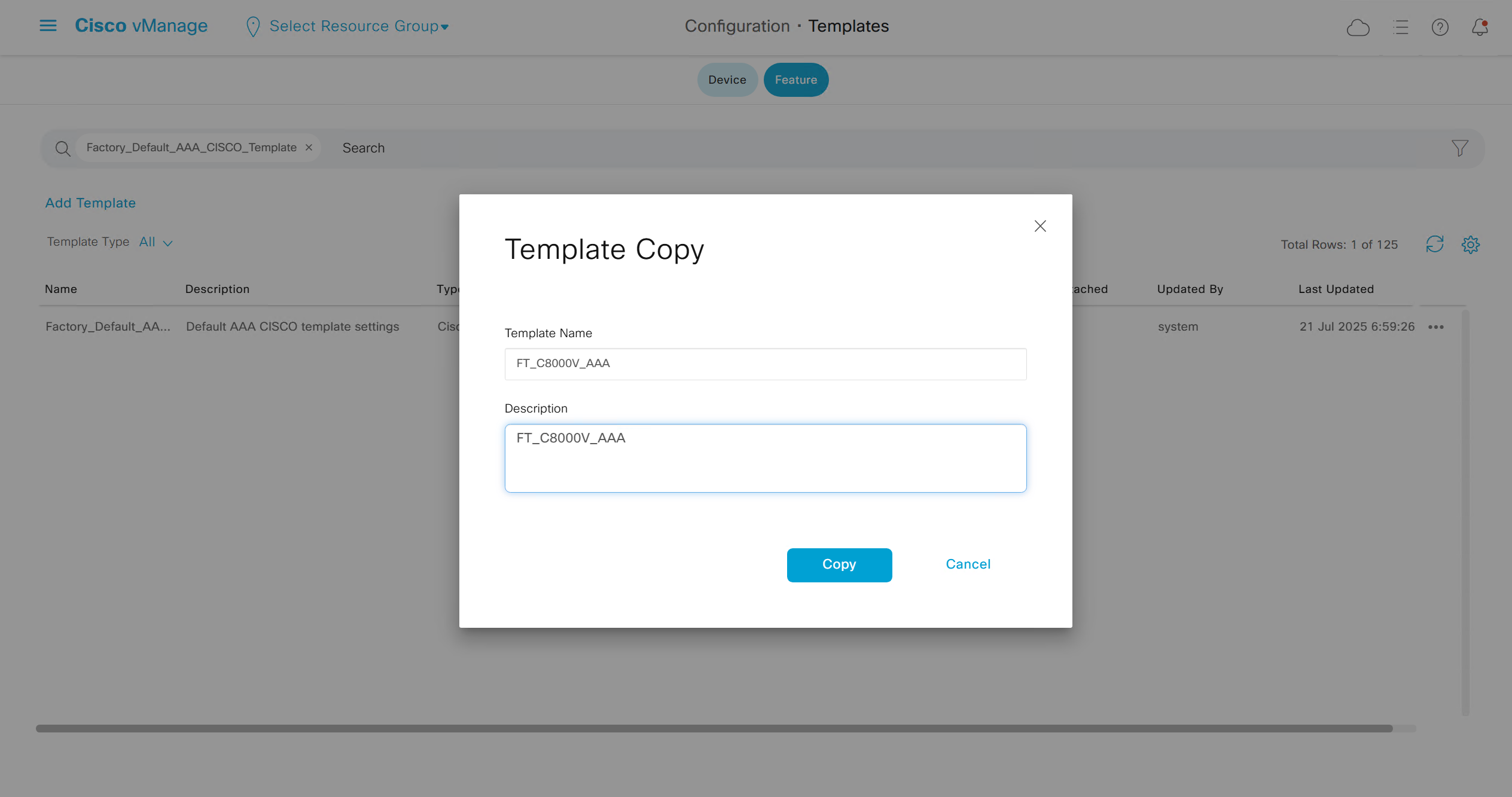
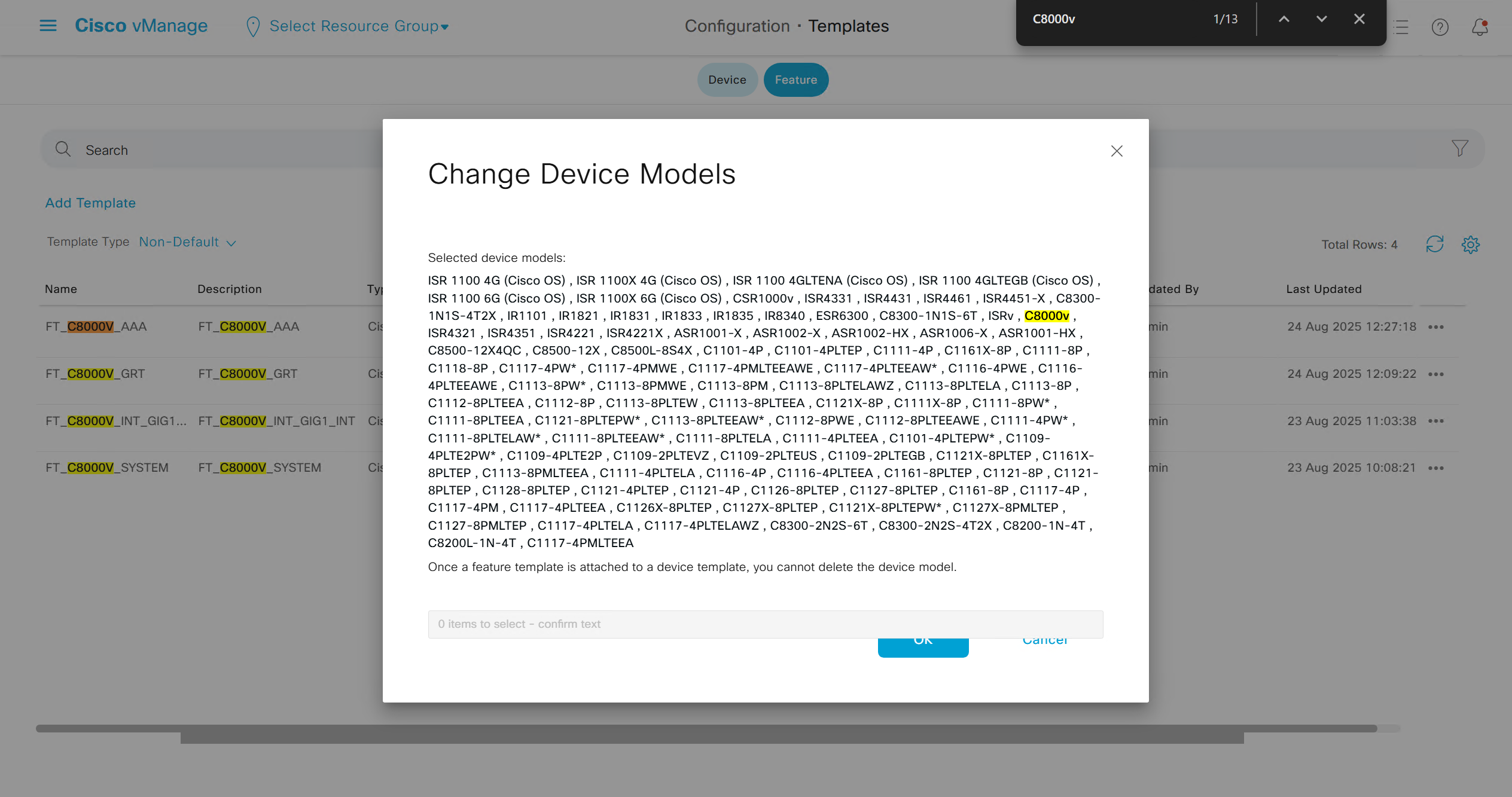
Now we can copy the template and also change its device model as well
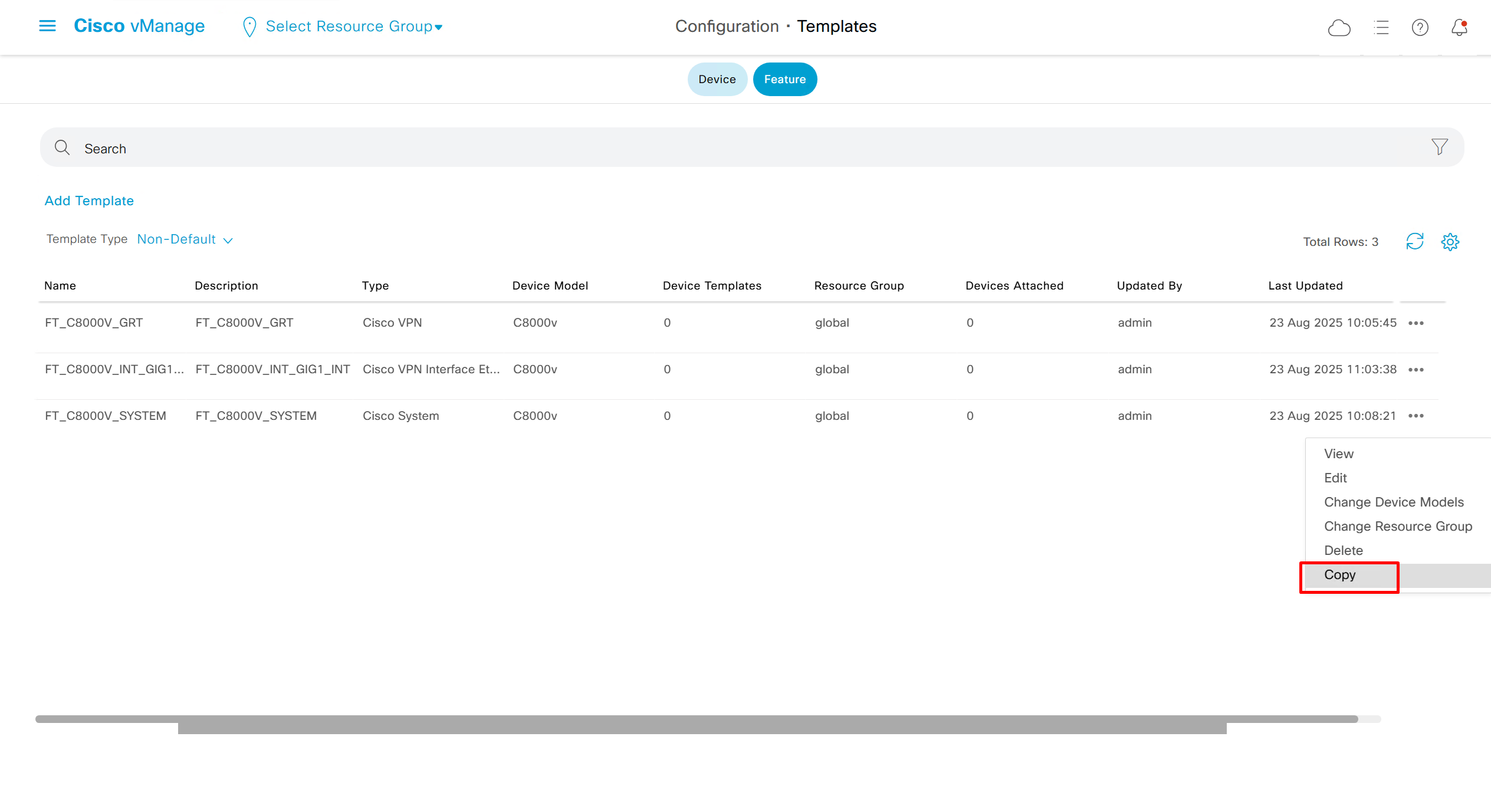
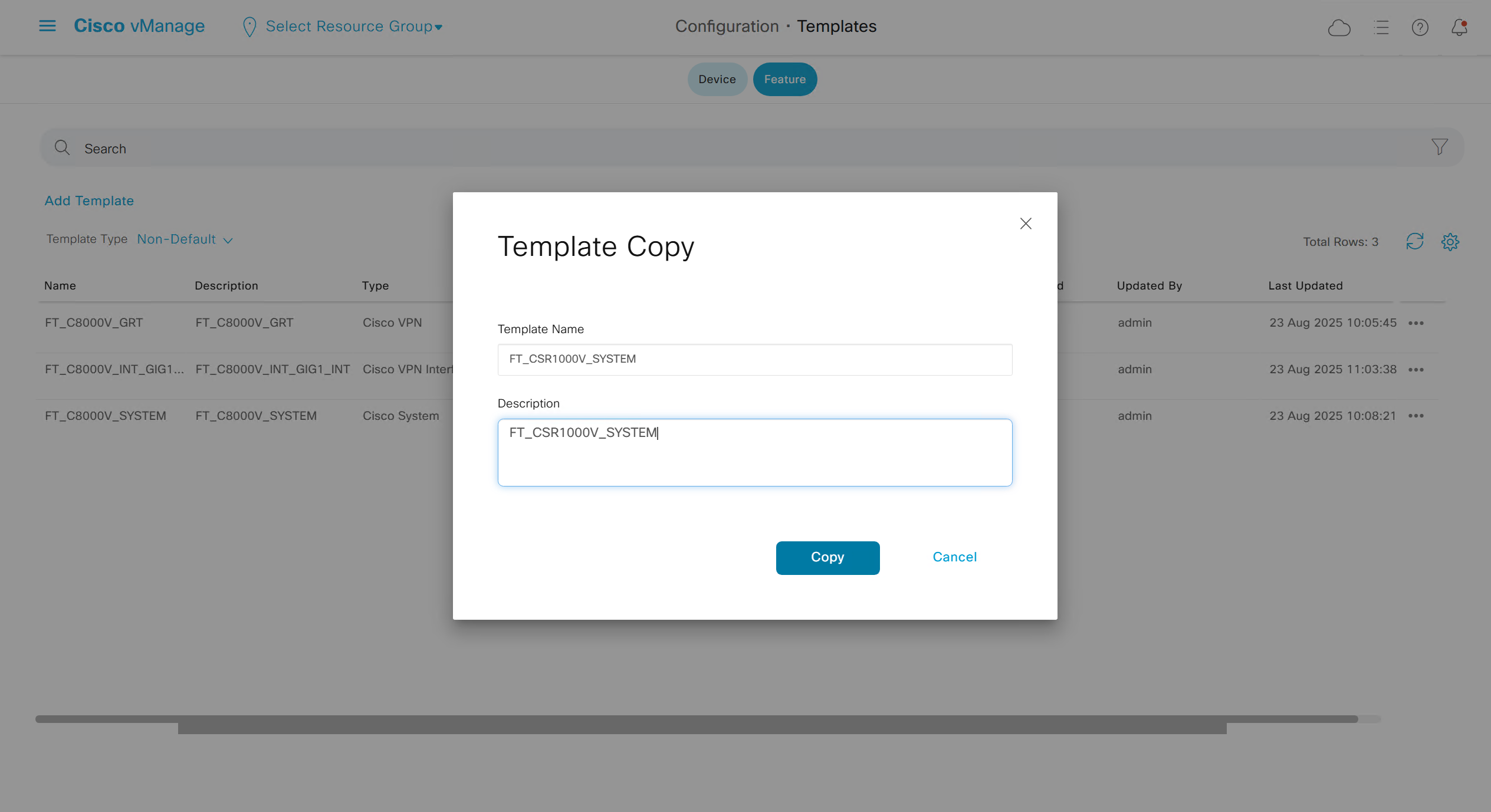
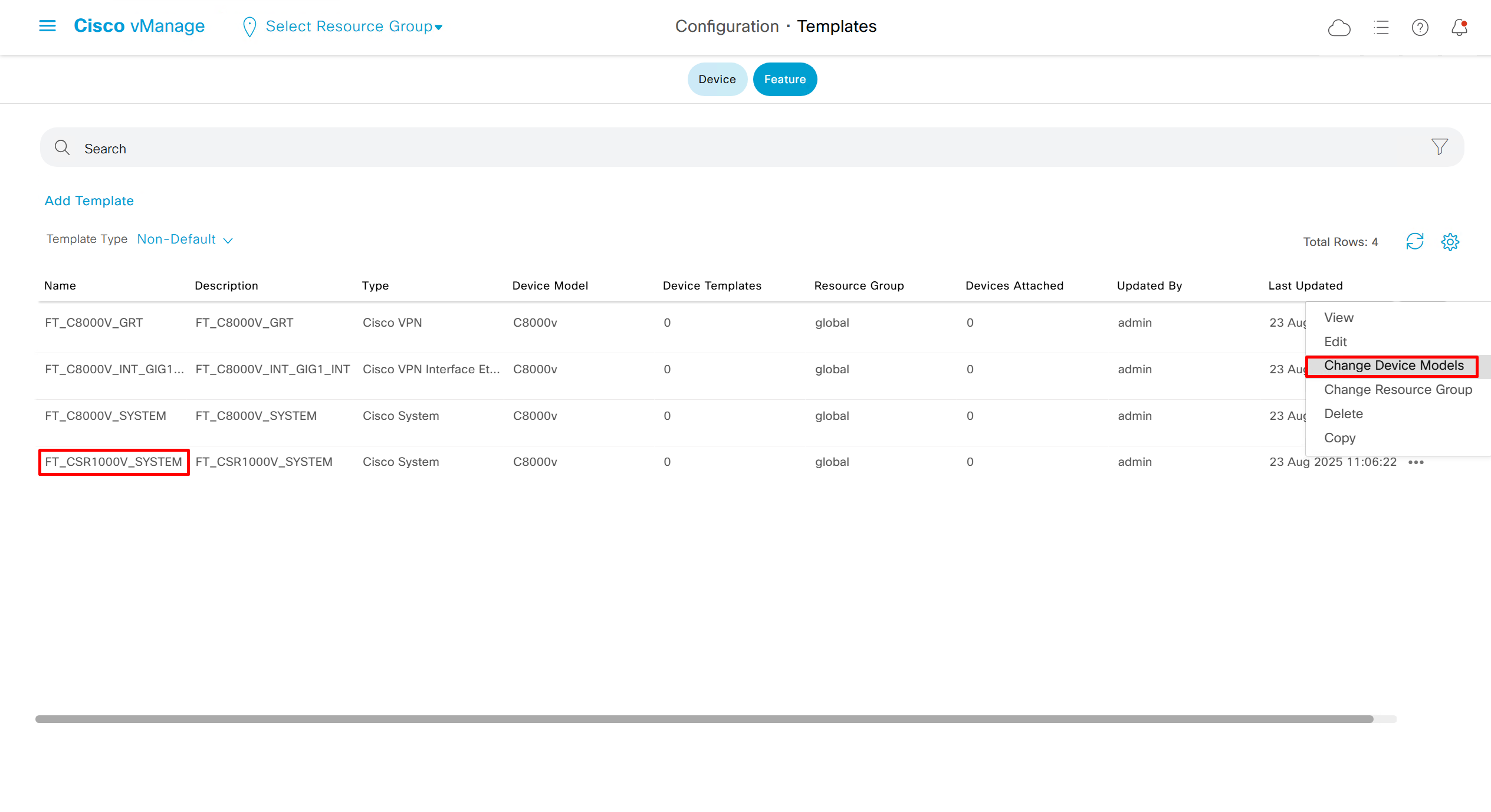
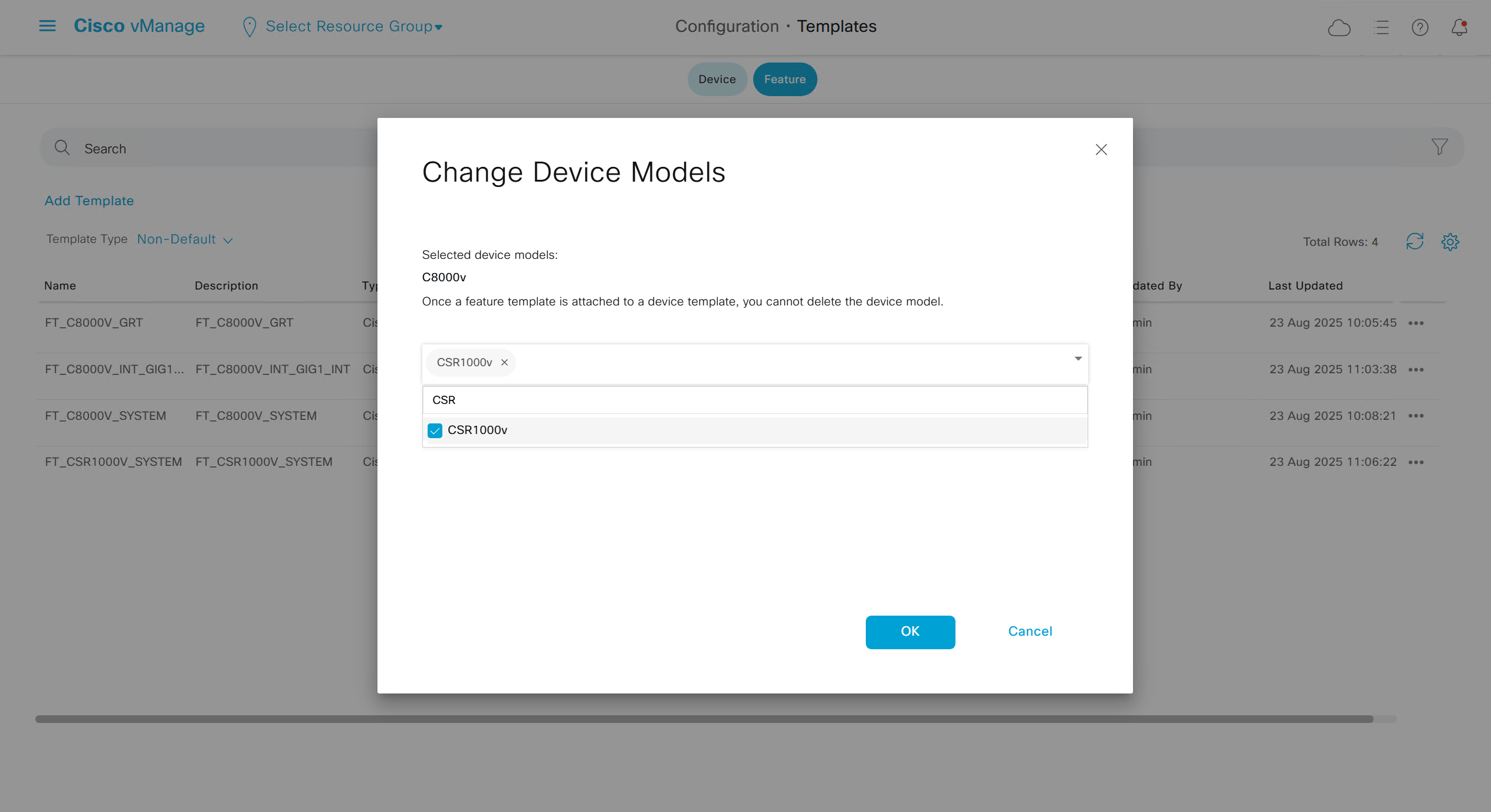
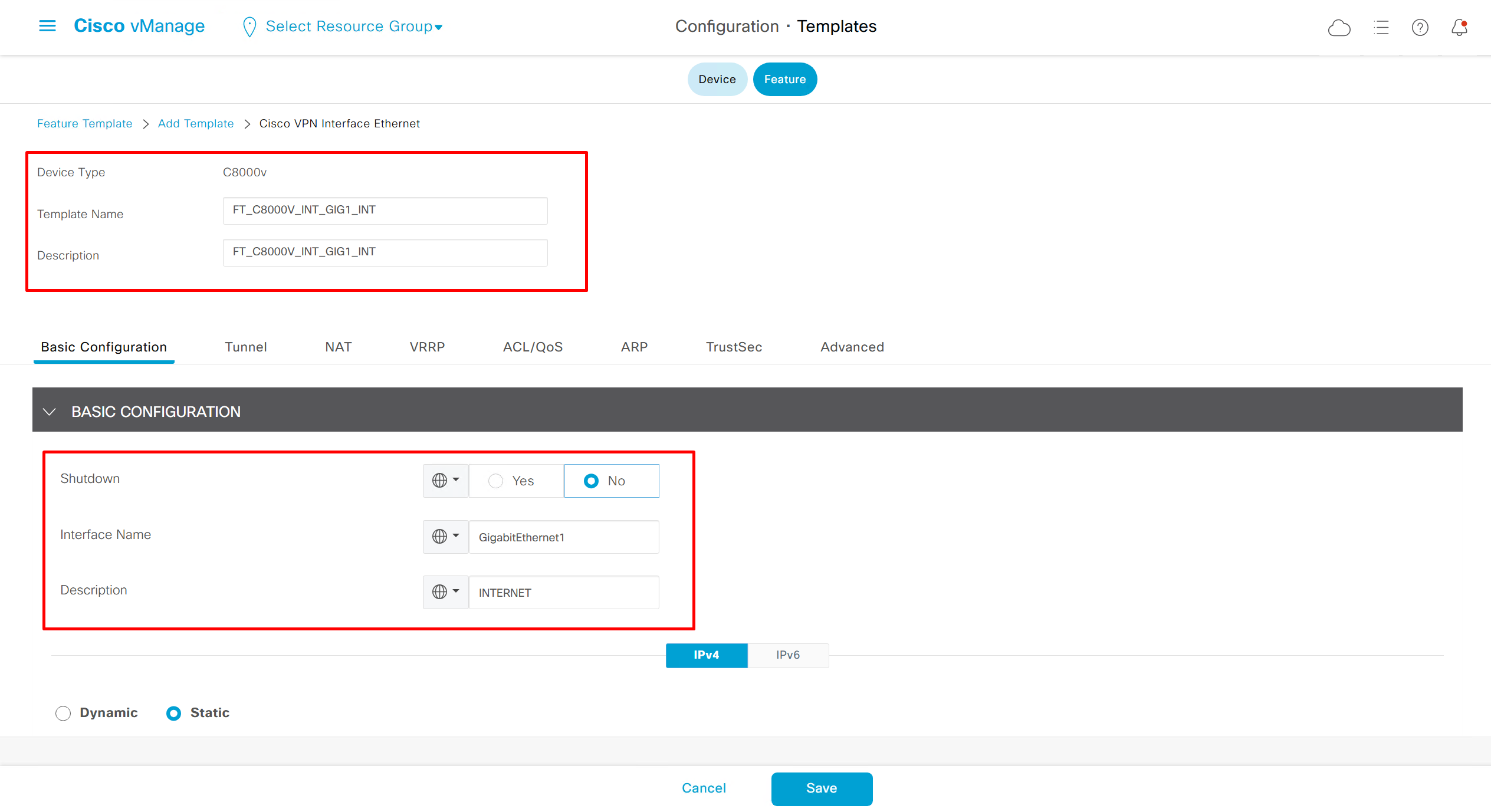
Once you have changed the device model, make sure that interface names match, such as make sure that interface name is not GigabitEthernet0/0/0 and GigabitEthernet1, if it is different then change it inside template as well
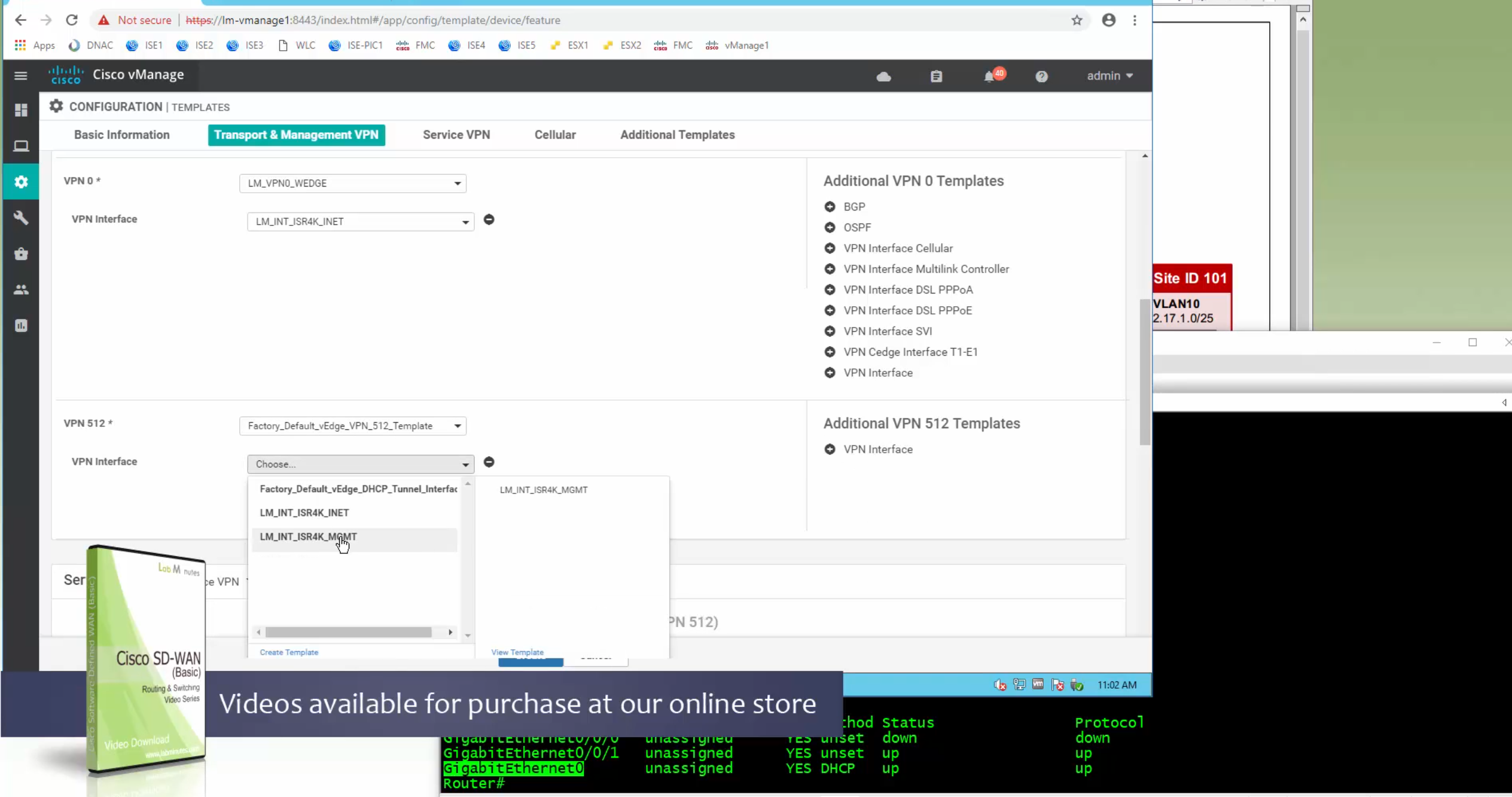
on hardware models we also need to make sure that we have template for management gig0 interface to satisfy the requirement for device template on hardware platforms otherwise deployment fails, for managemet gig0 interface same template “Cisco VPN Interface Ethernet” is used and input its name from “show ip int brief”
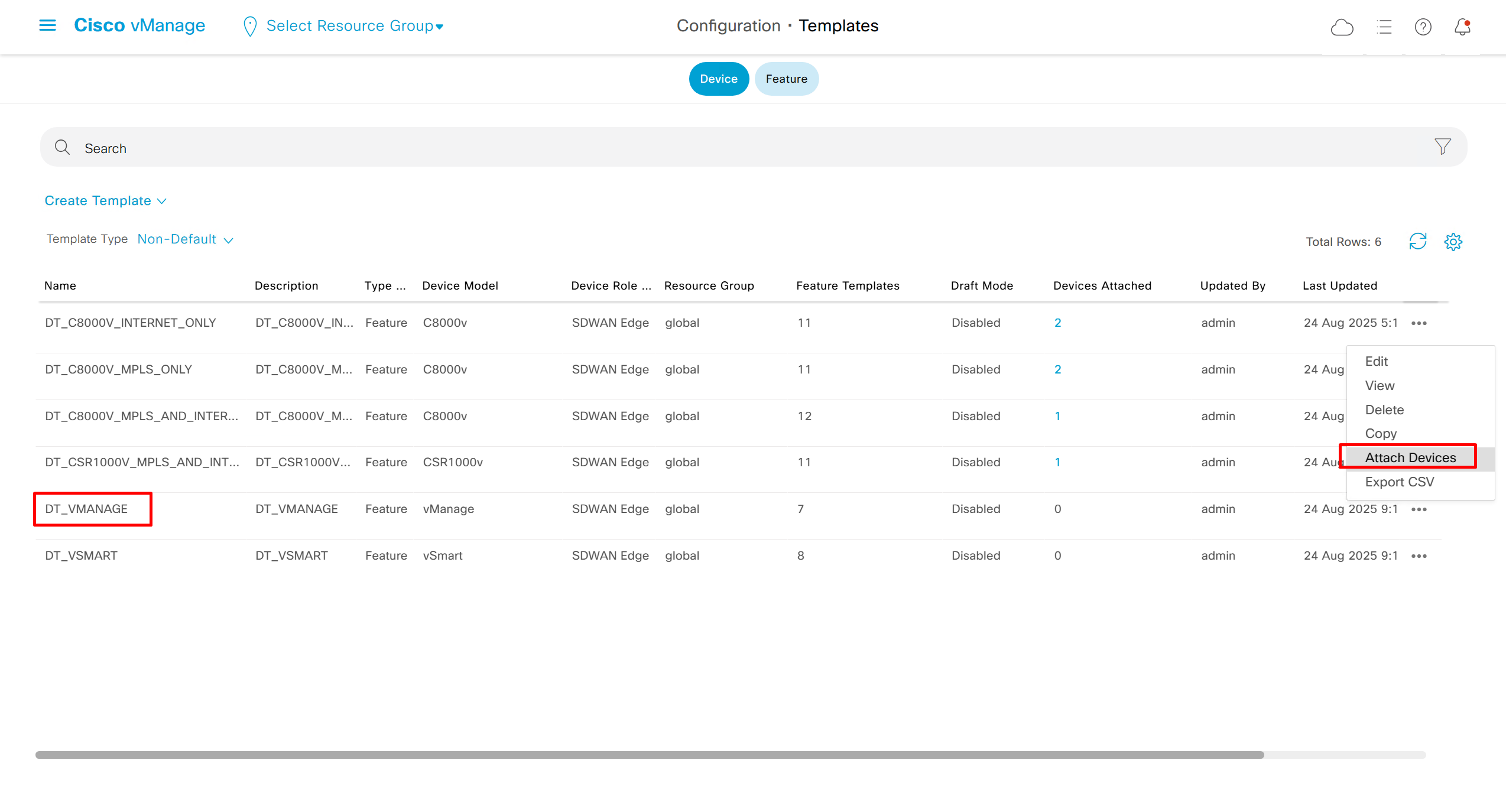
Now create device template
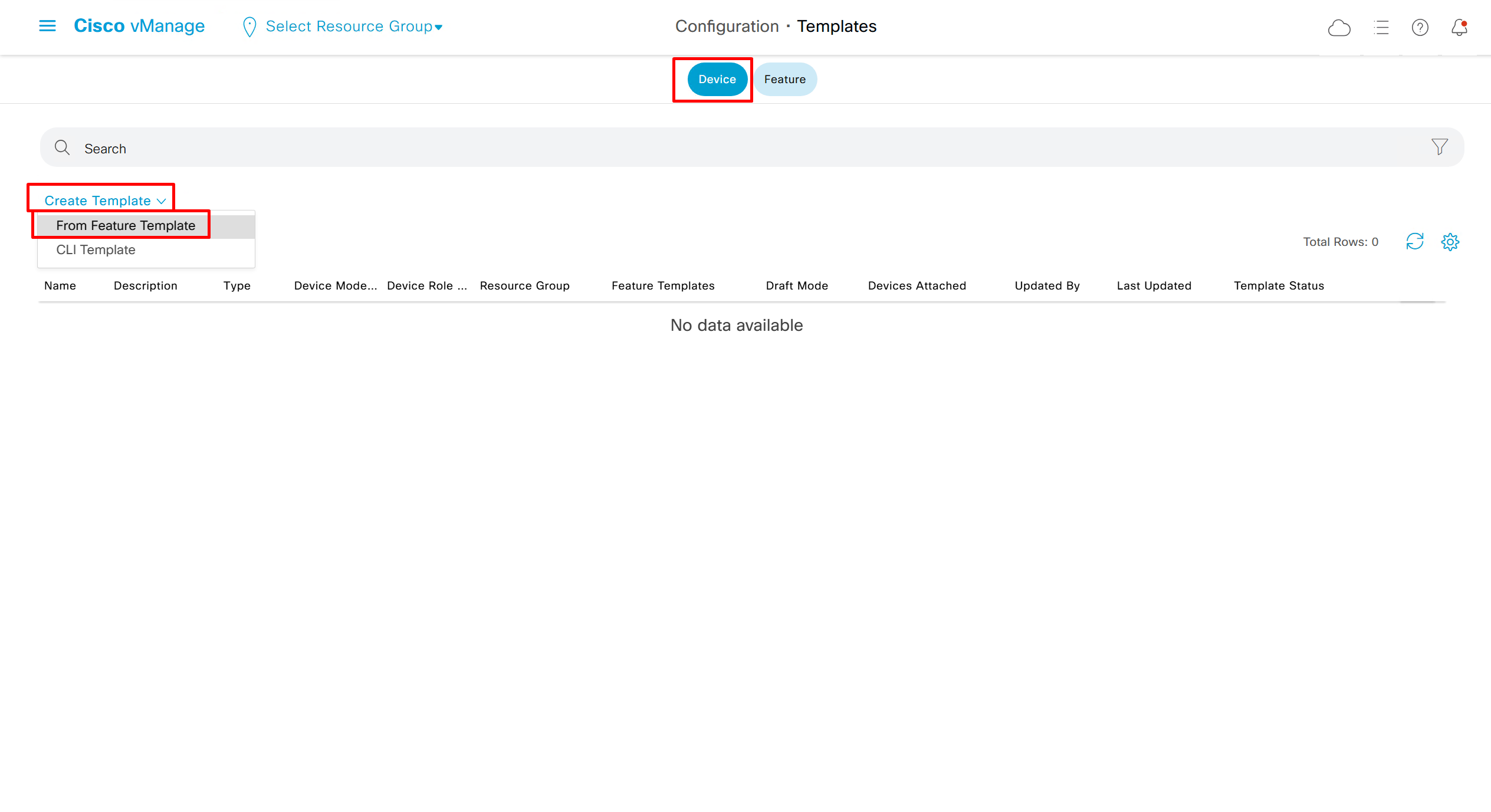
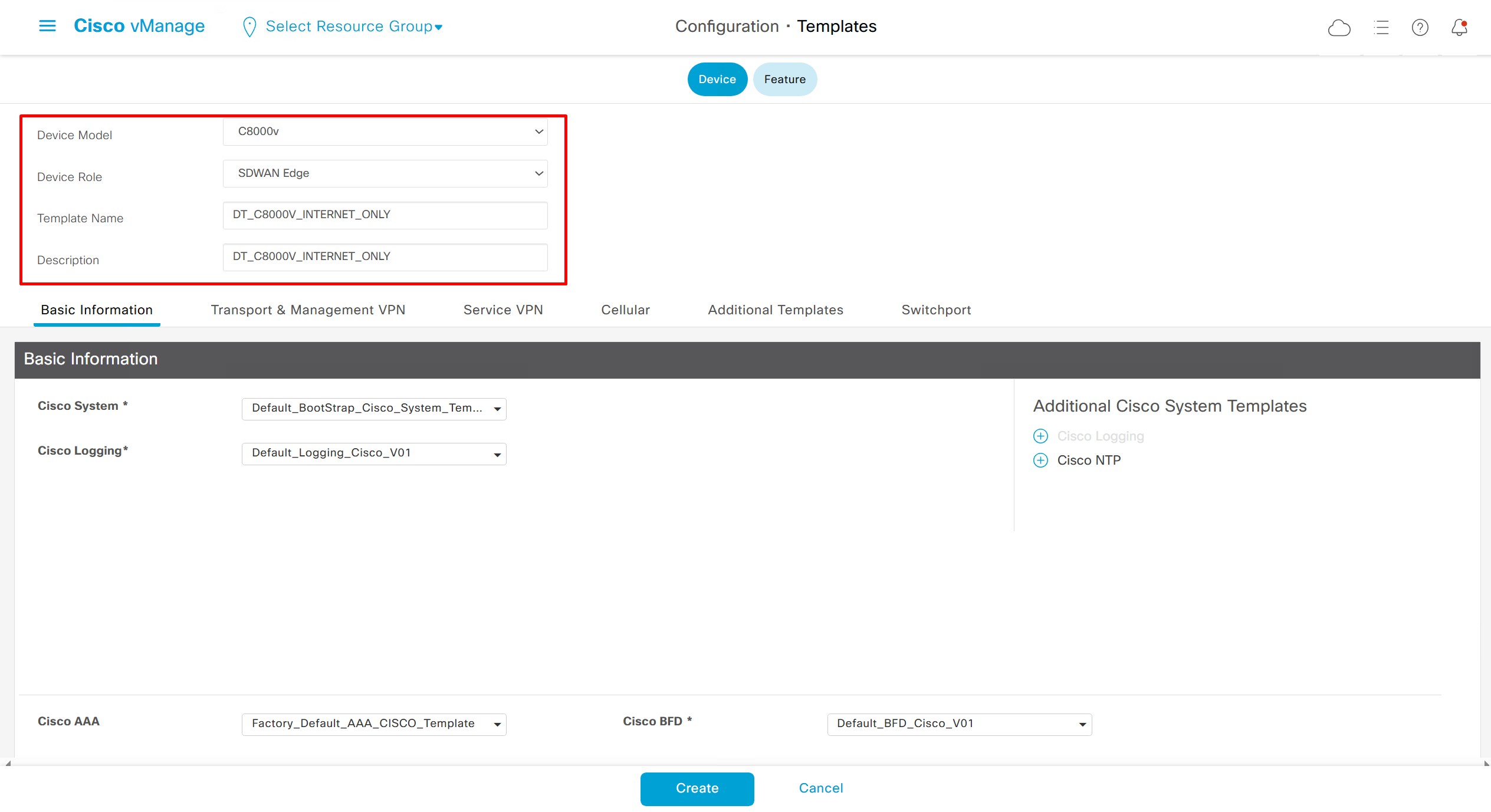
This template is device specific + transport connectivity types specific
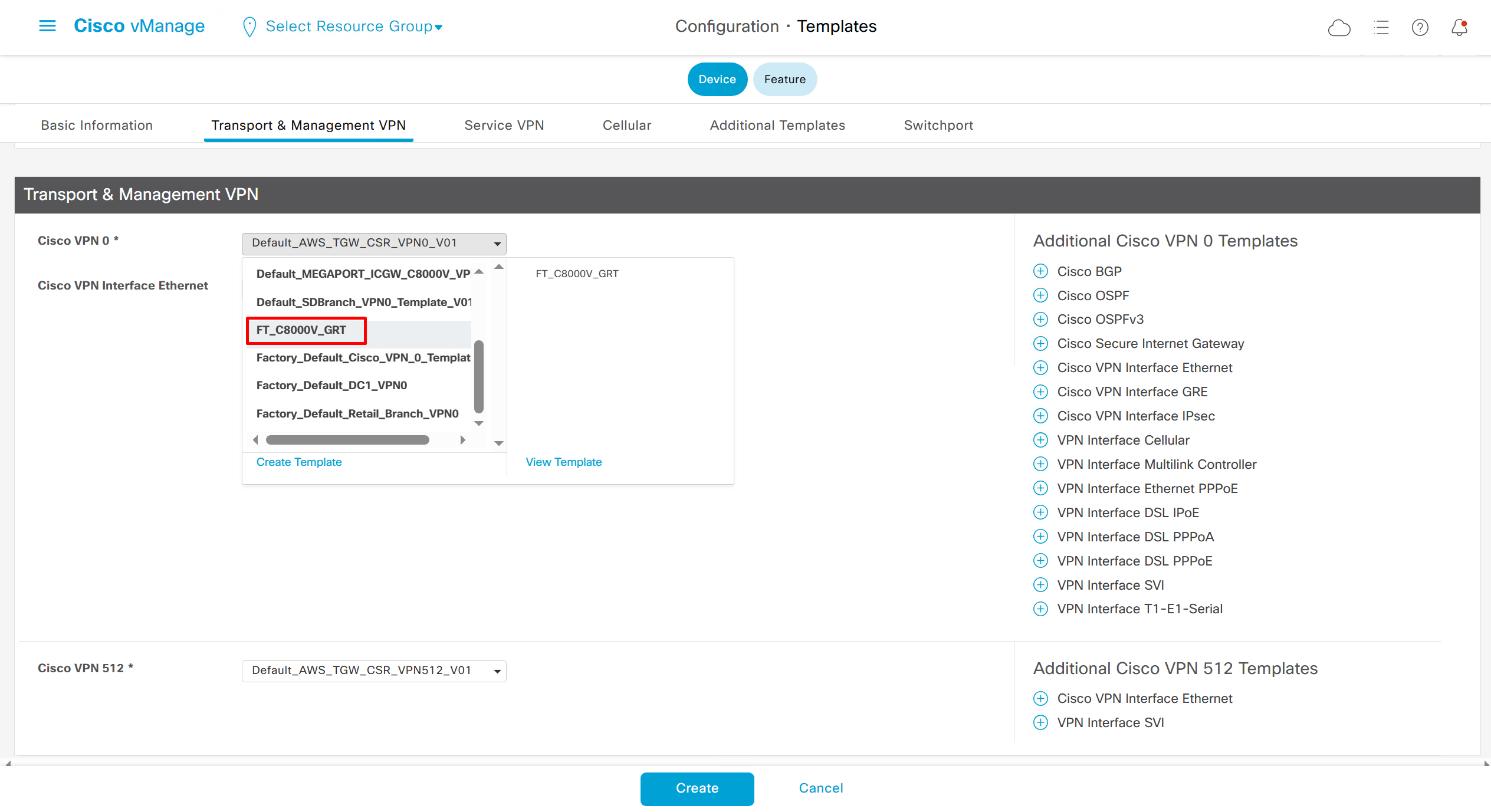
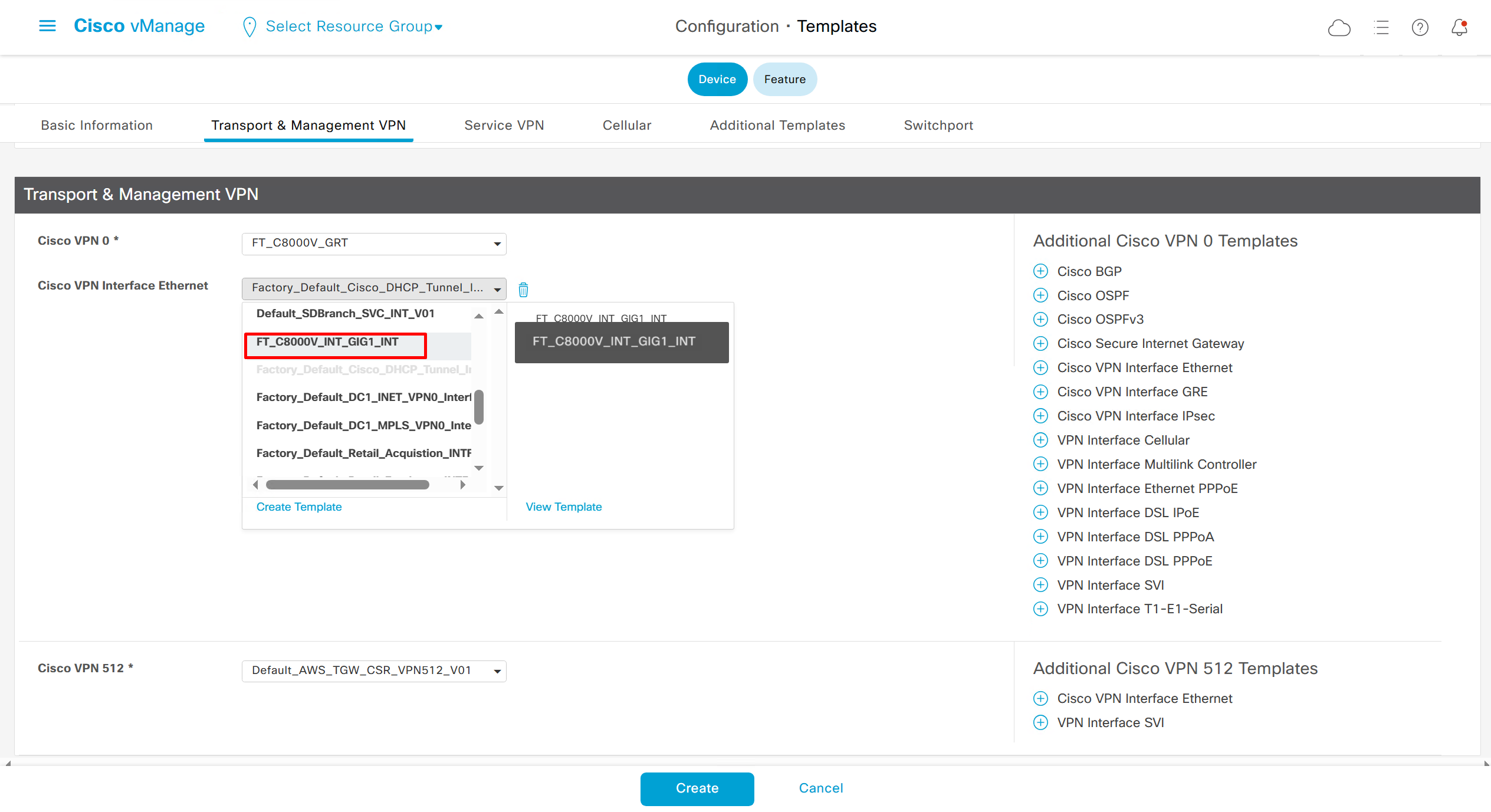
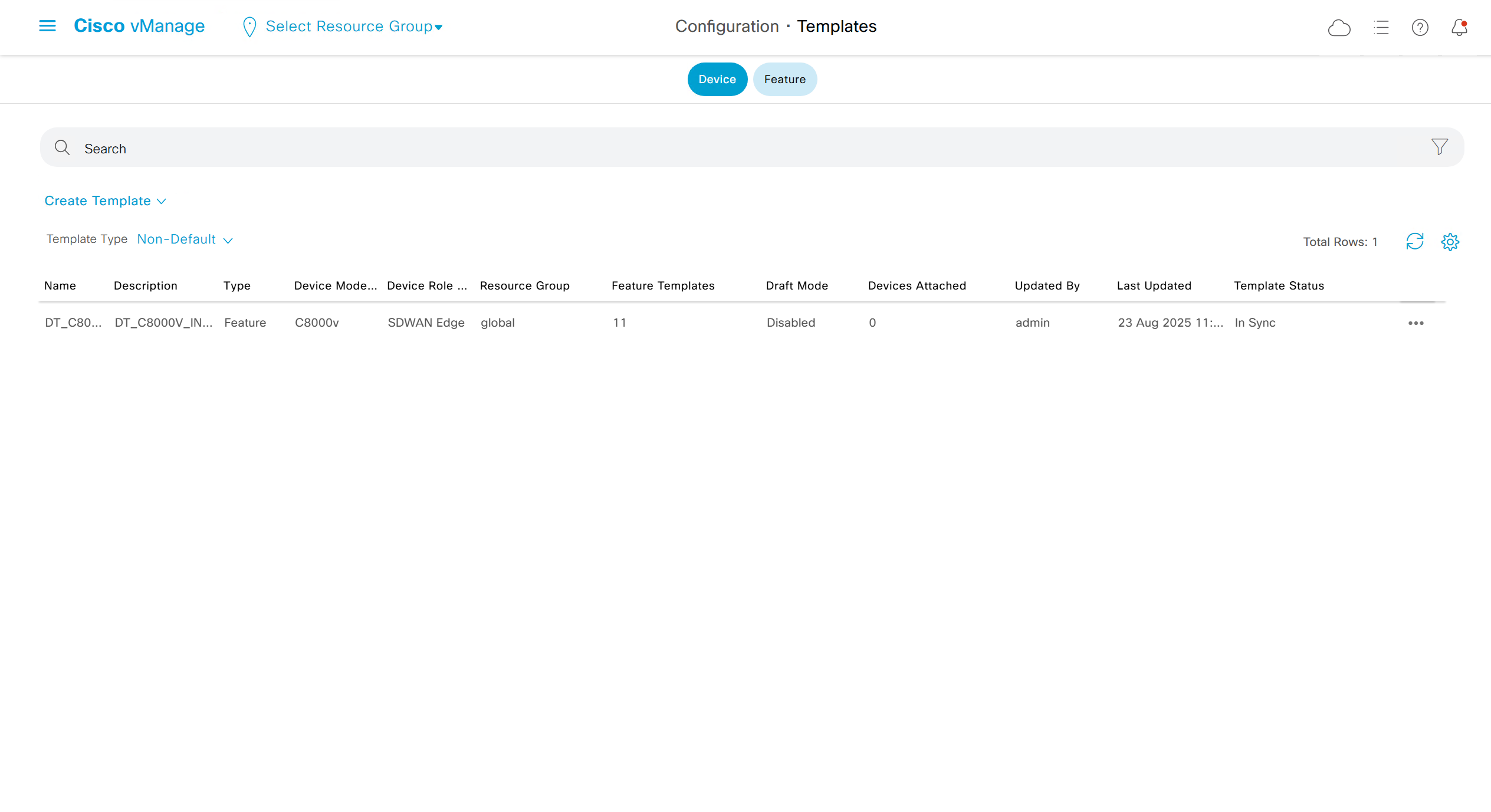
In case we have another transport interface, we can add another from plus icon next to the type of interface

In case we have to attach mgmt interface to avoid deployment errors on hardware device
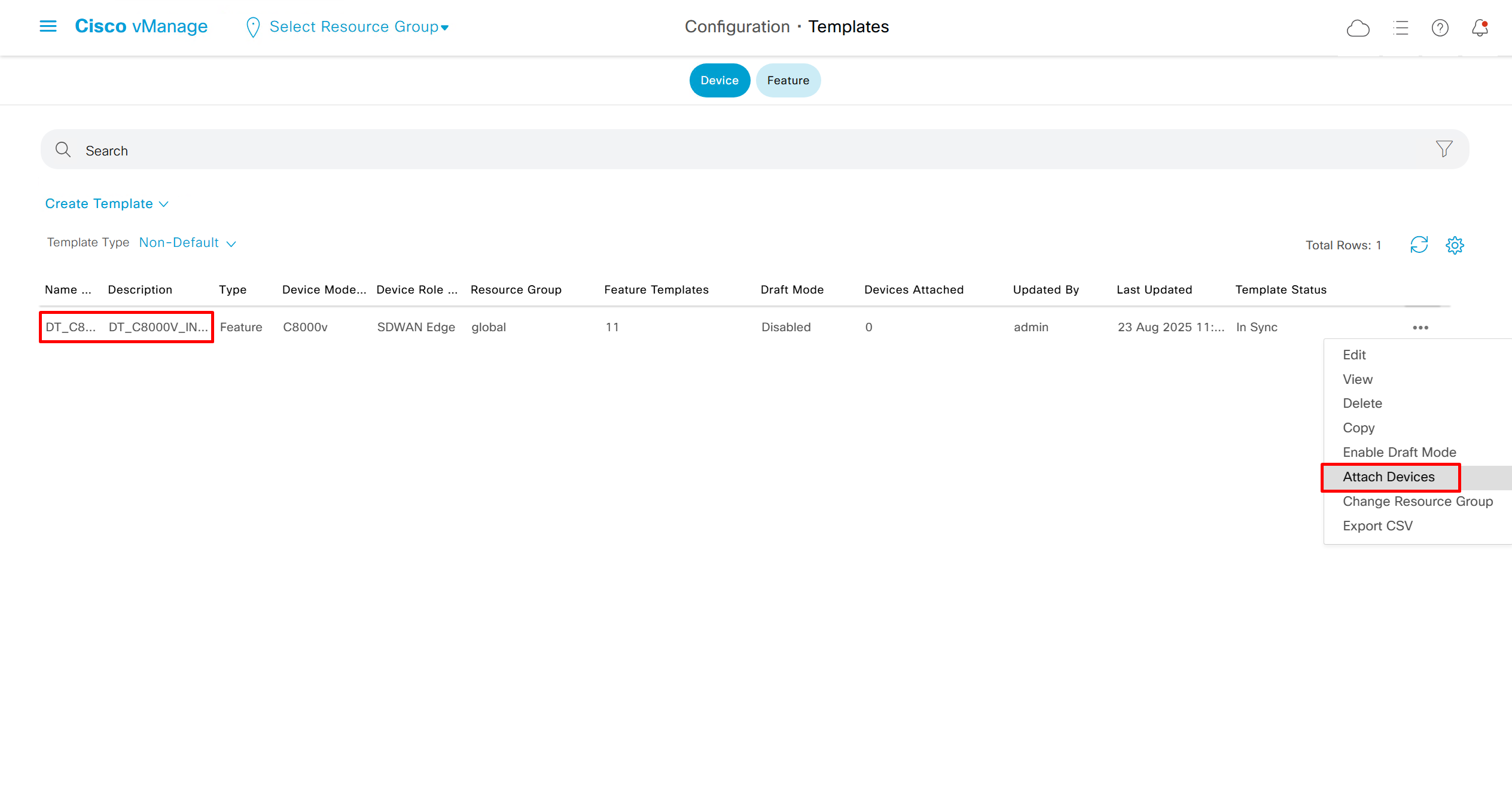
Now we need to attach the device template to a device – C8000v that has internet only connectivity
And you do that from the template itself
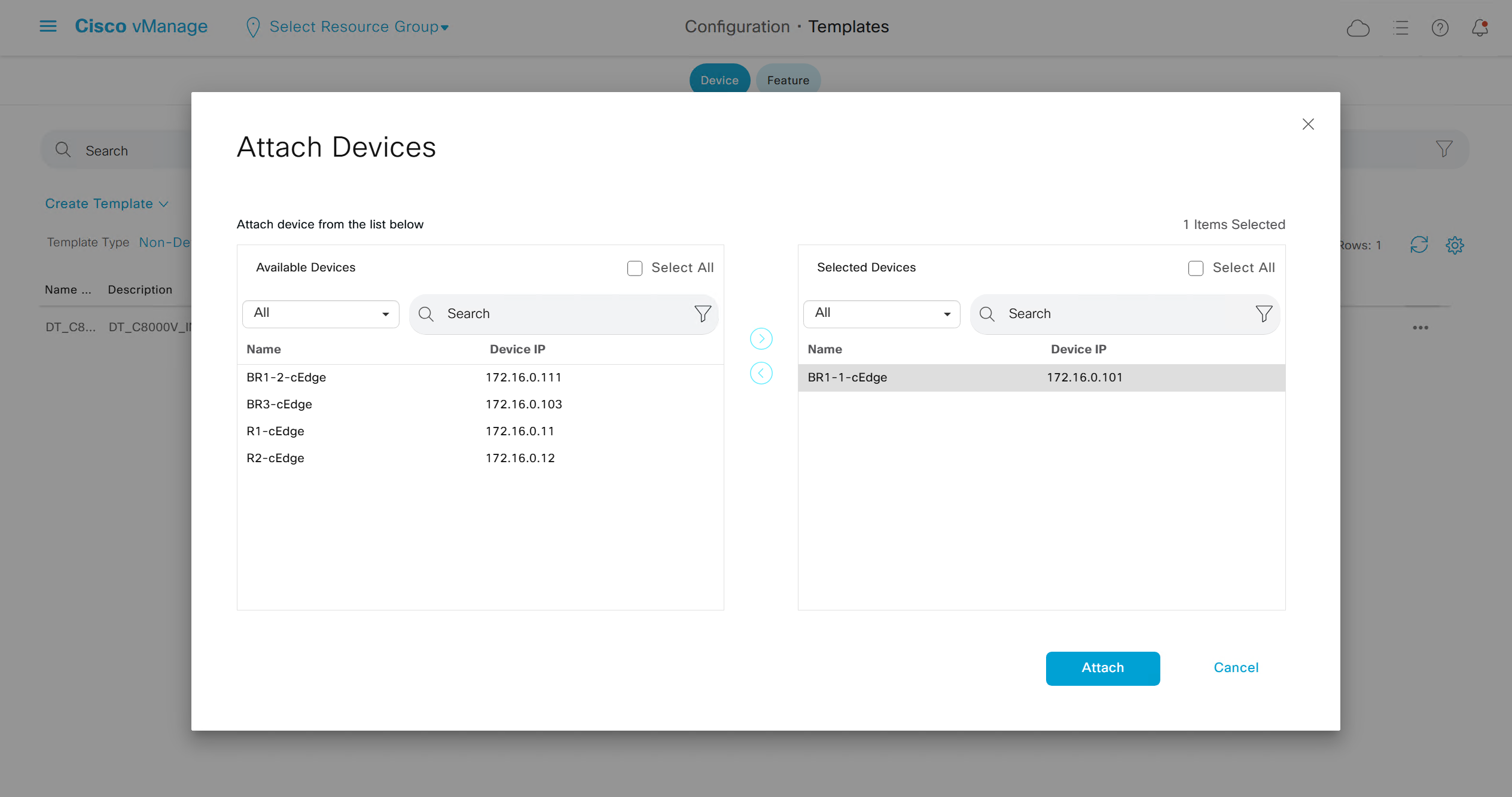
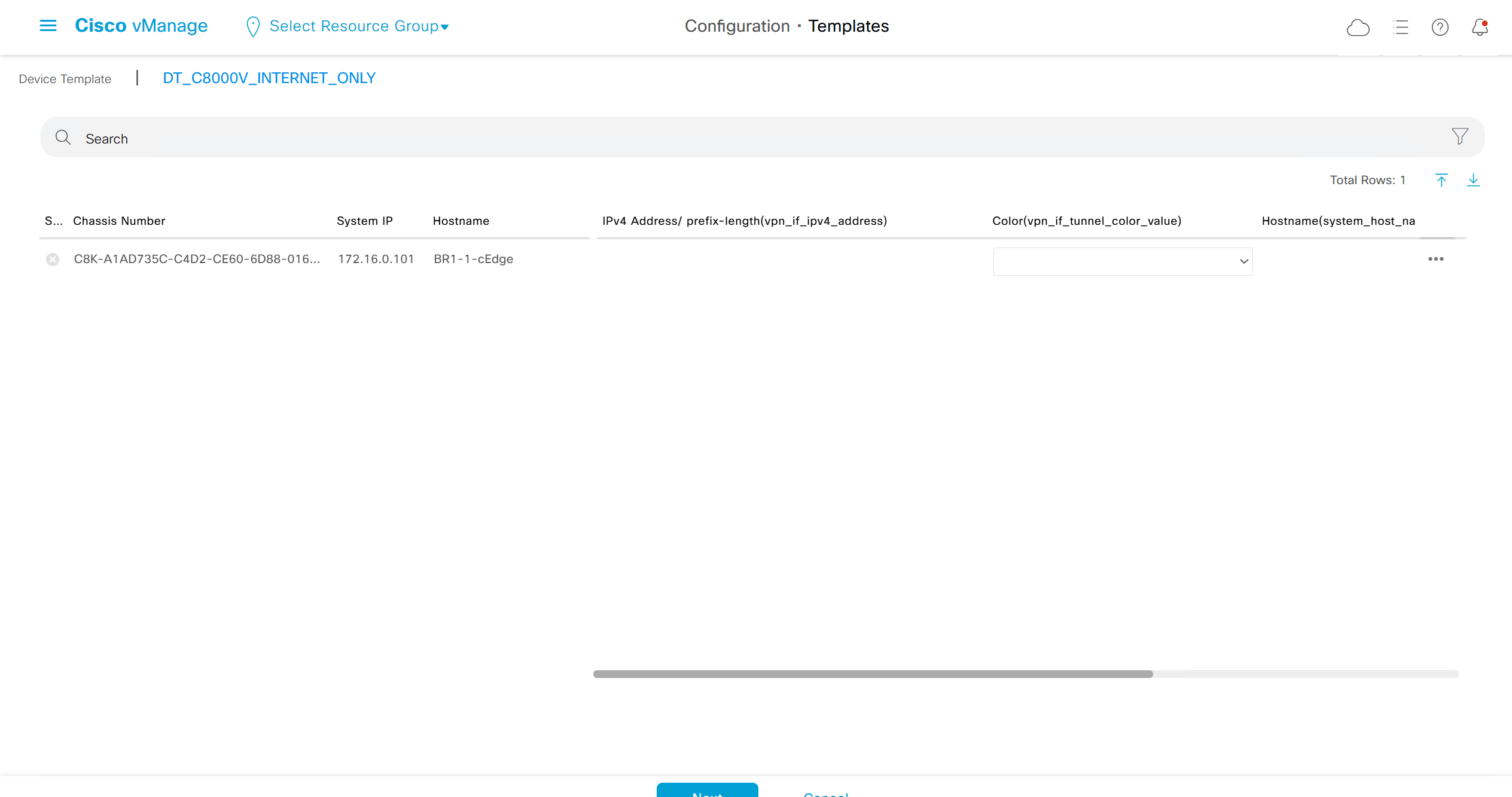
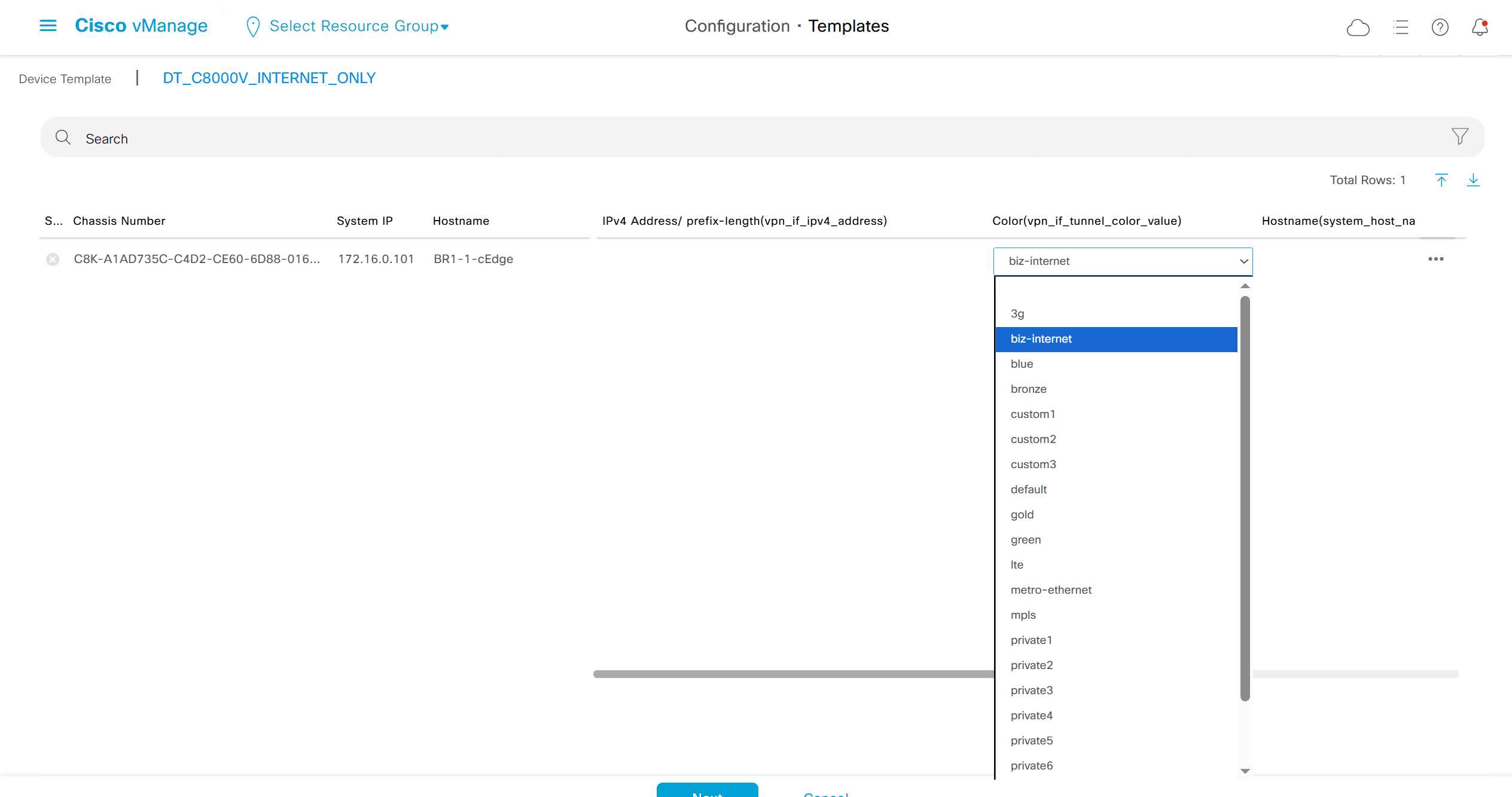

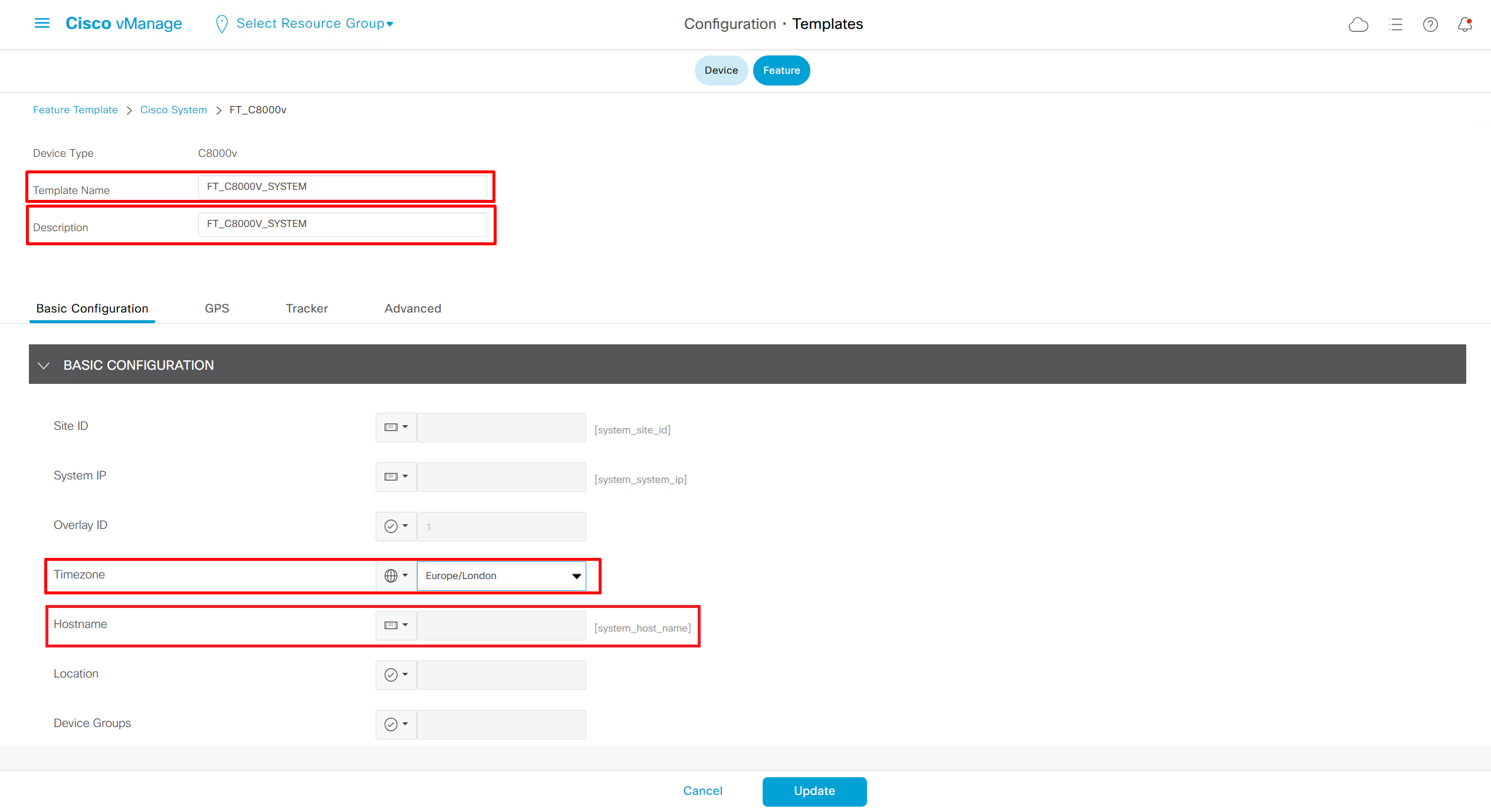
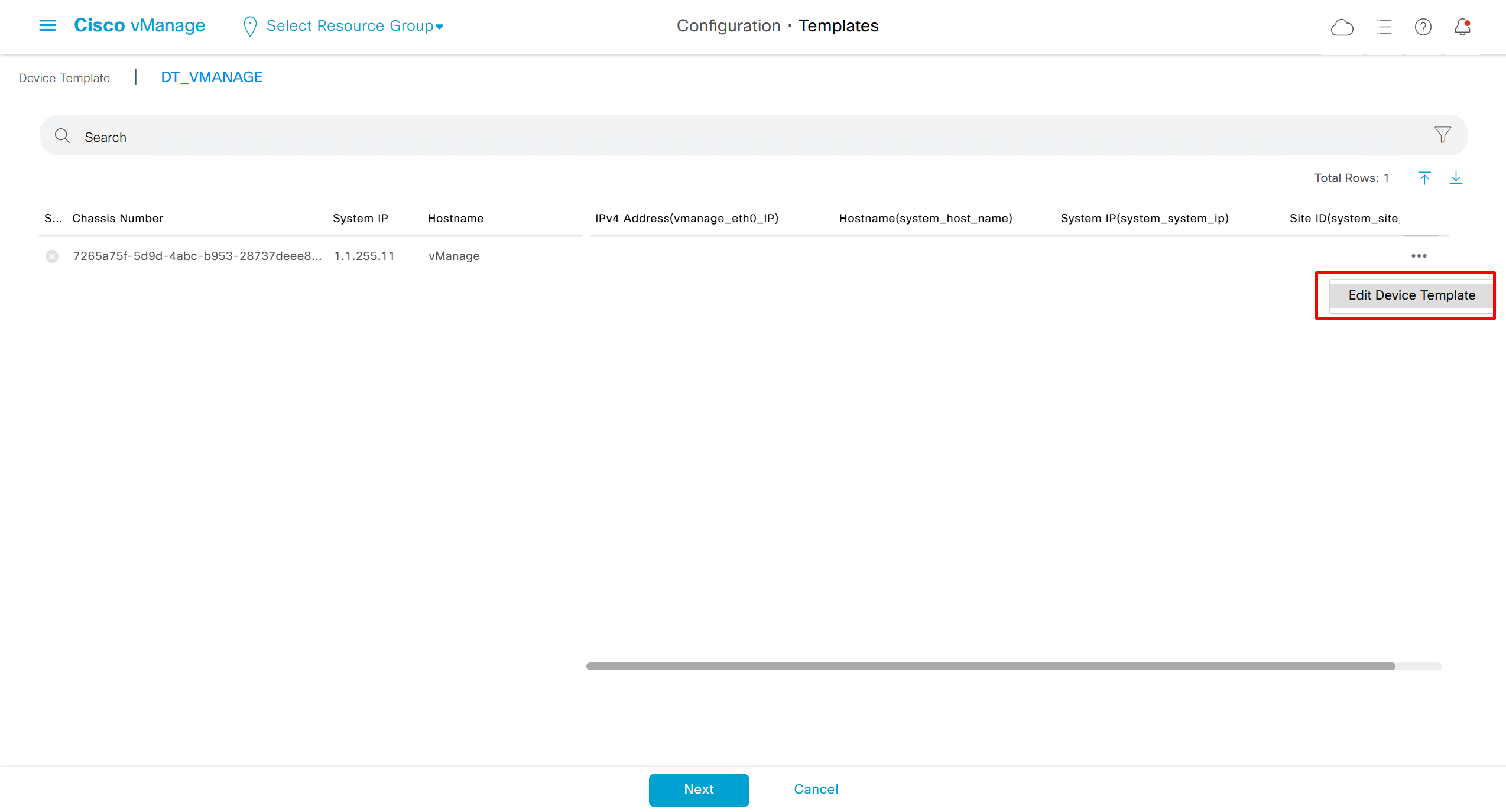
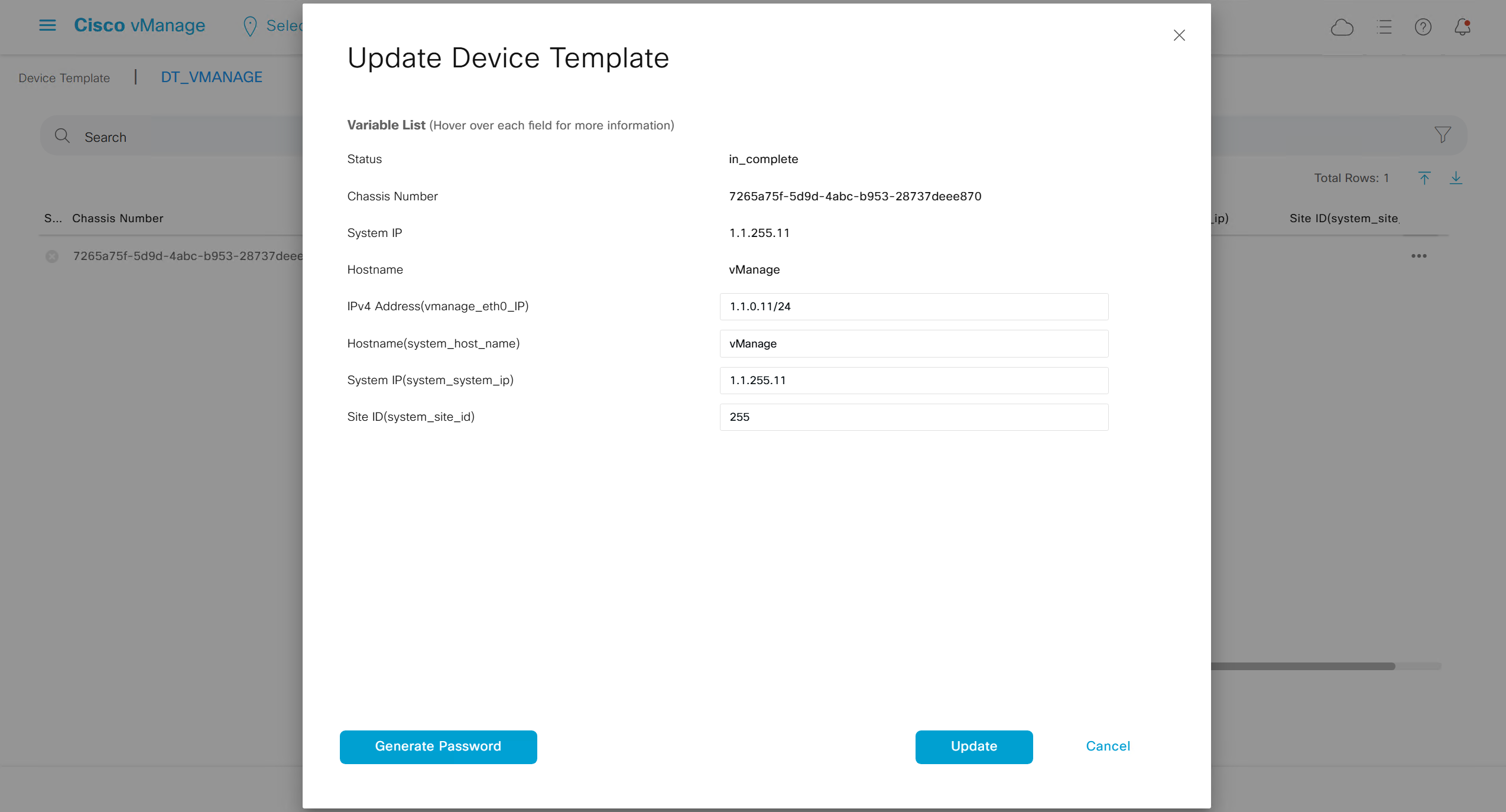
fill the variables with following information from the running-config of edge device


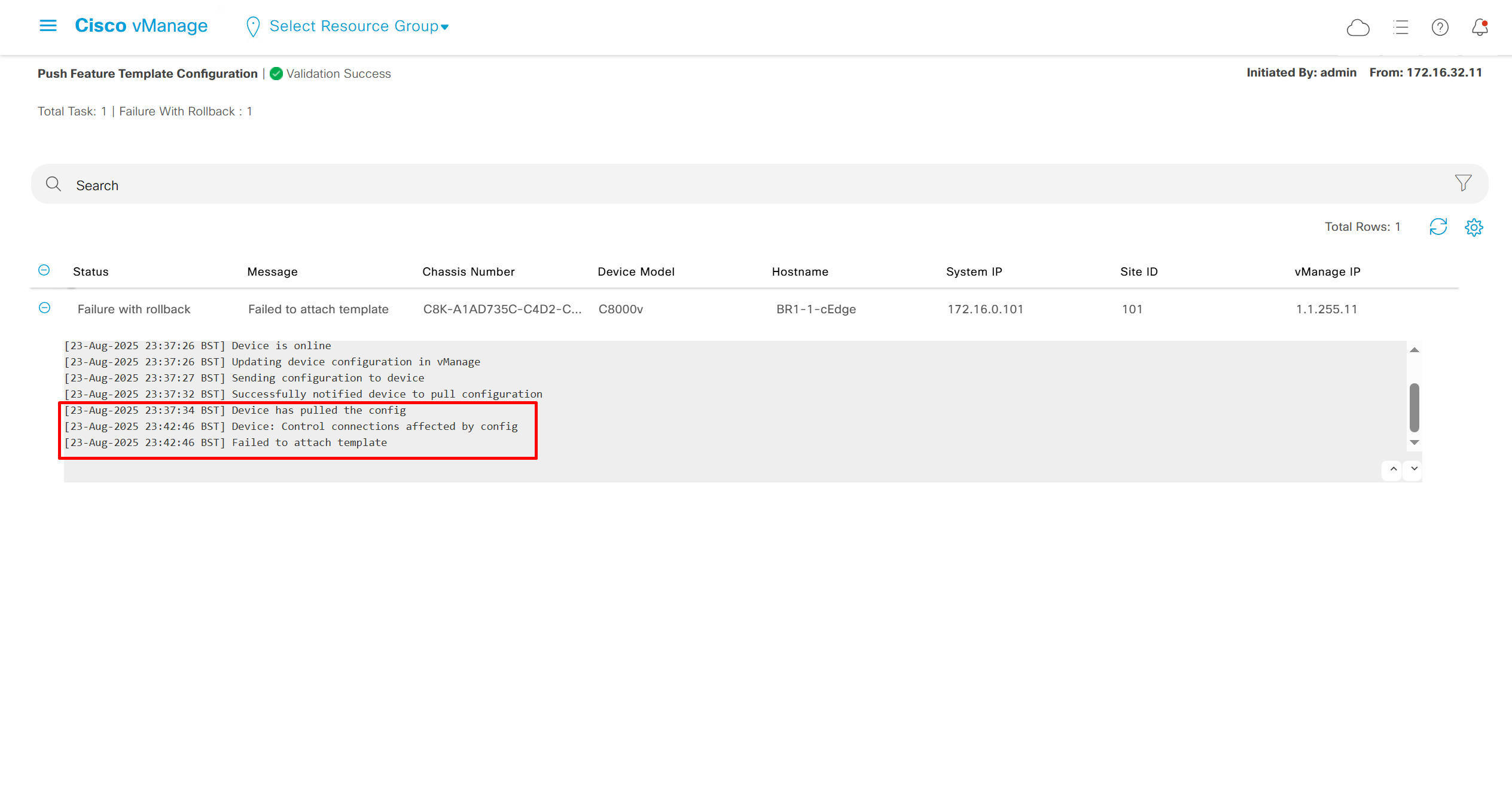
deployment failed and it rolled back to restore connectivity to vmanage as edge lost connectivity to vmanage and also other controllers
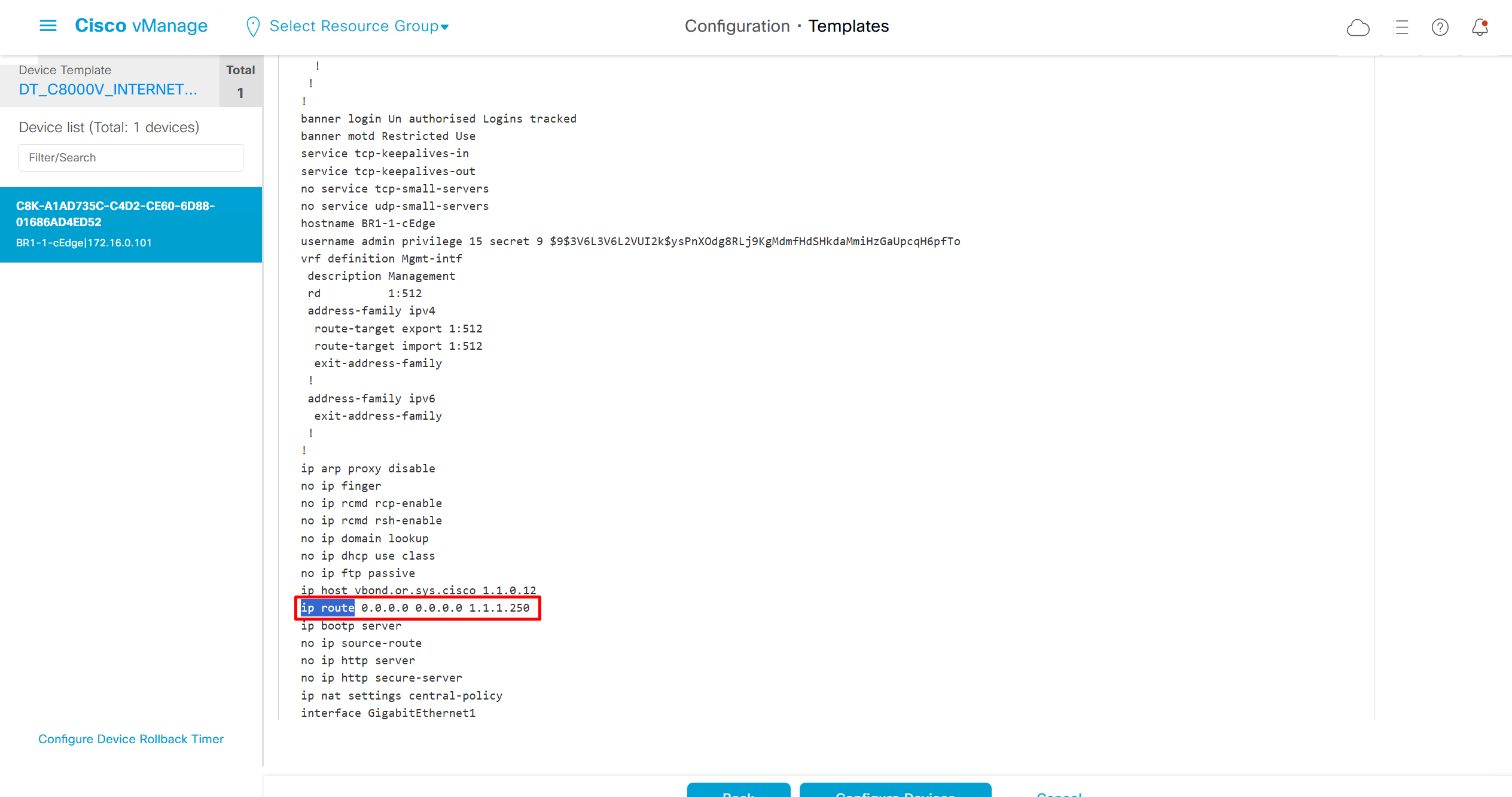
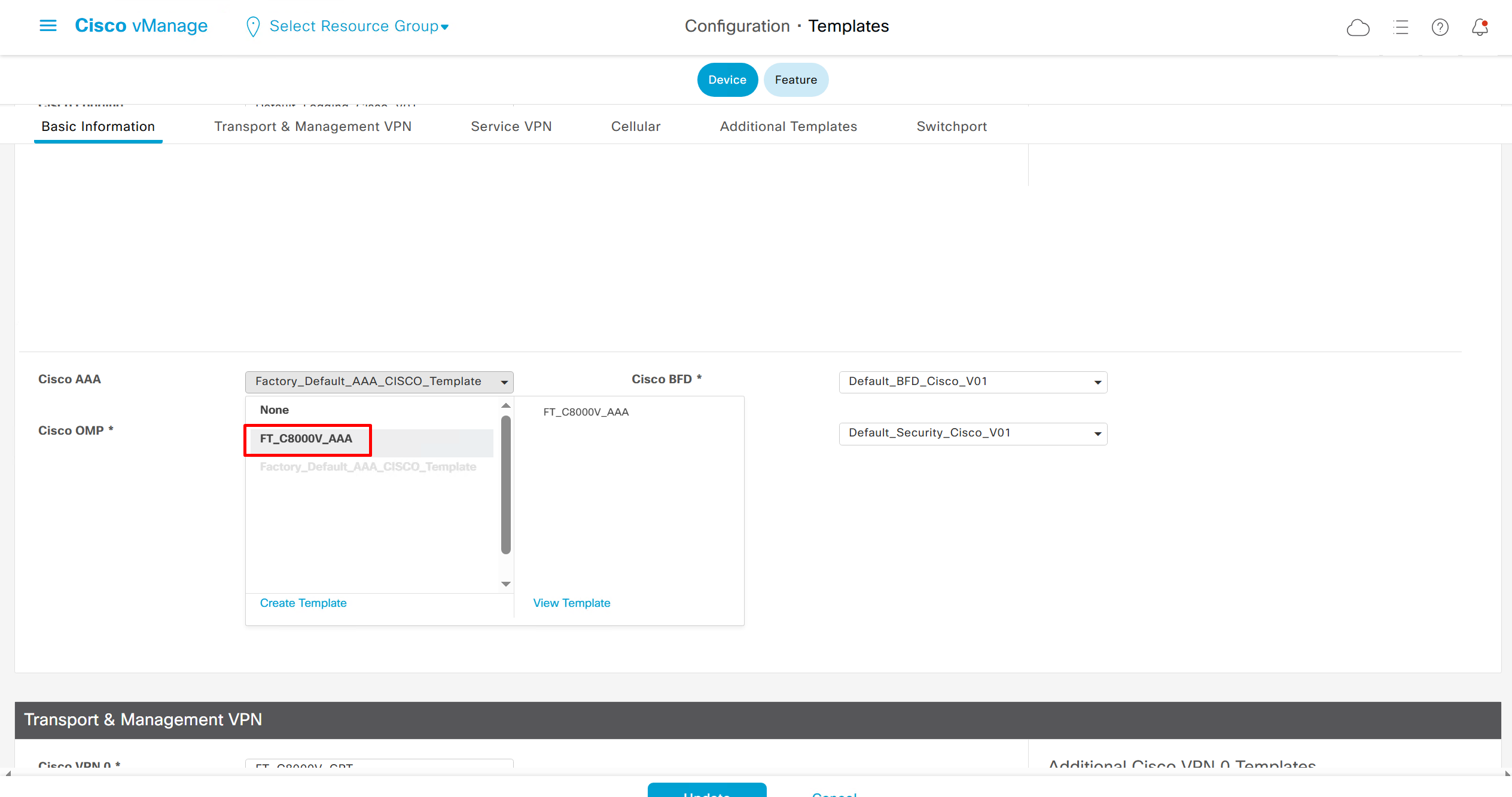
As I checked the template, the default route was missing from feature template FT_C8000V_GRT
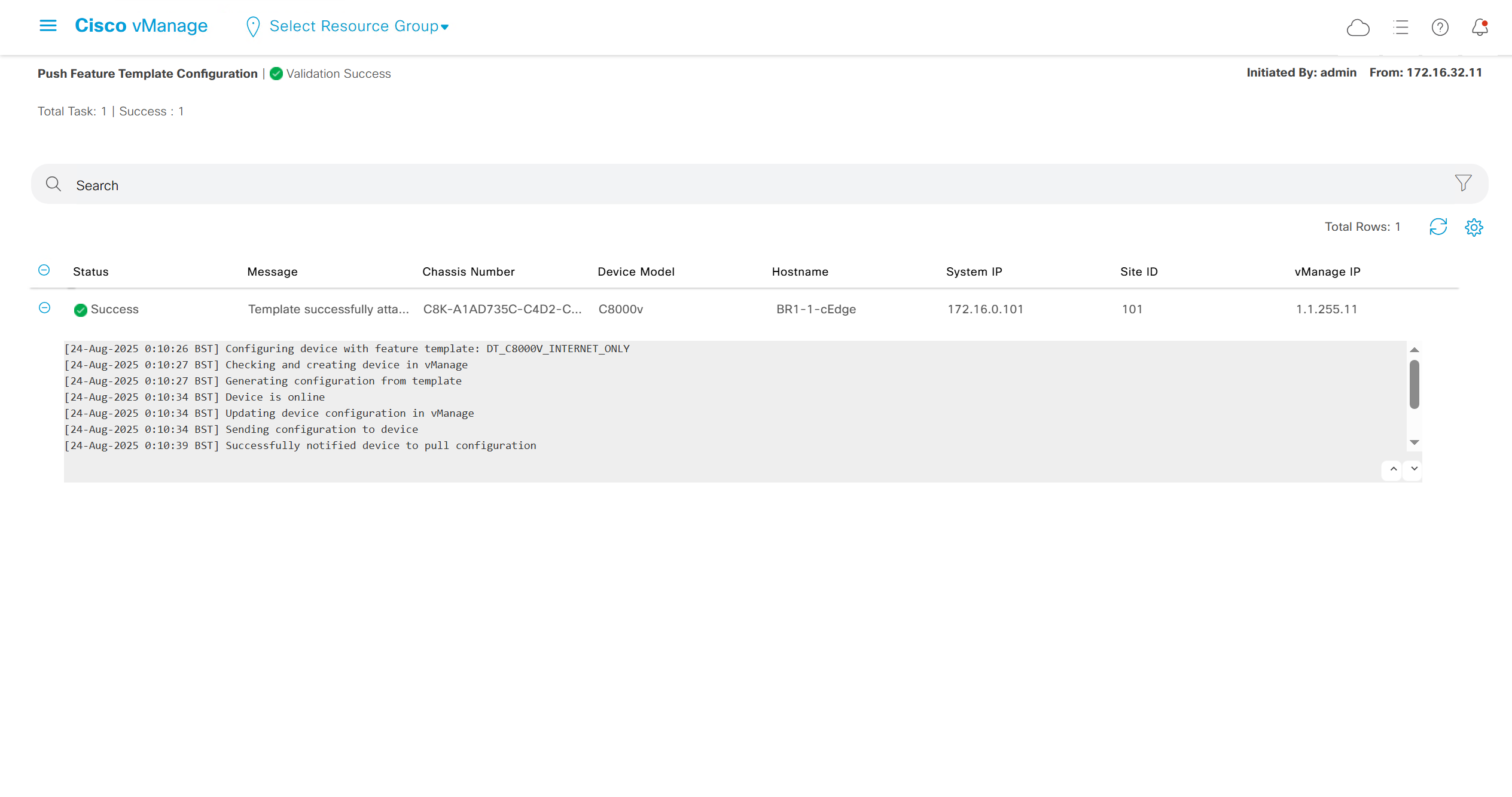
after successful deployment I was not able to login, so new AAA policy was attached
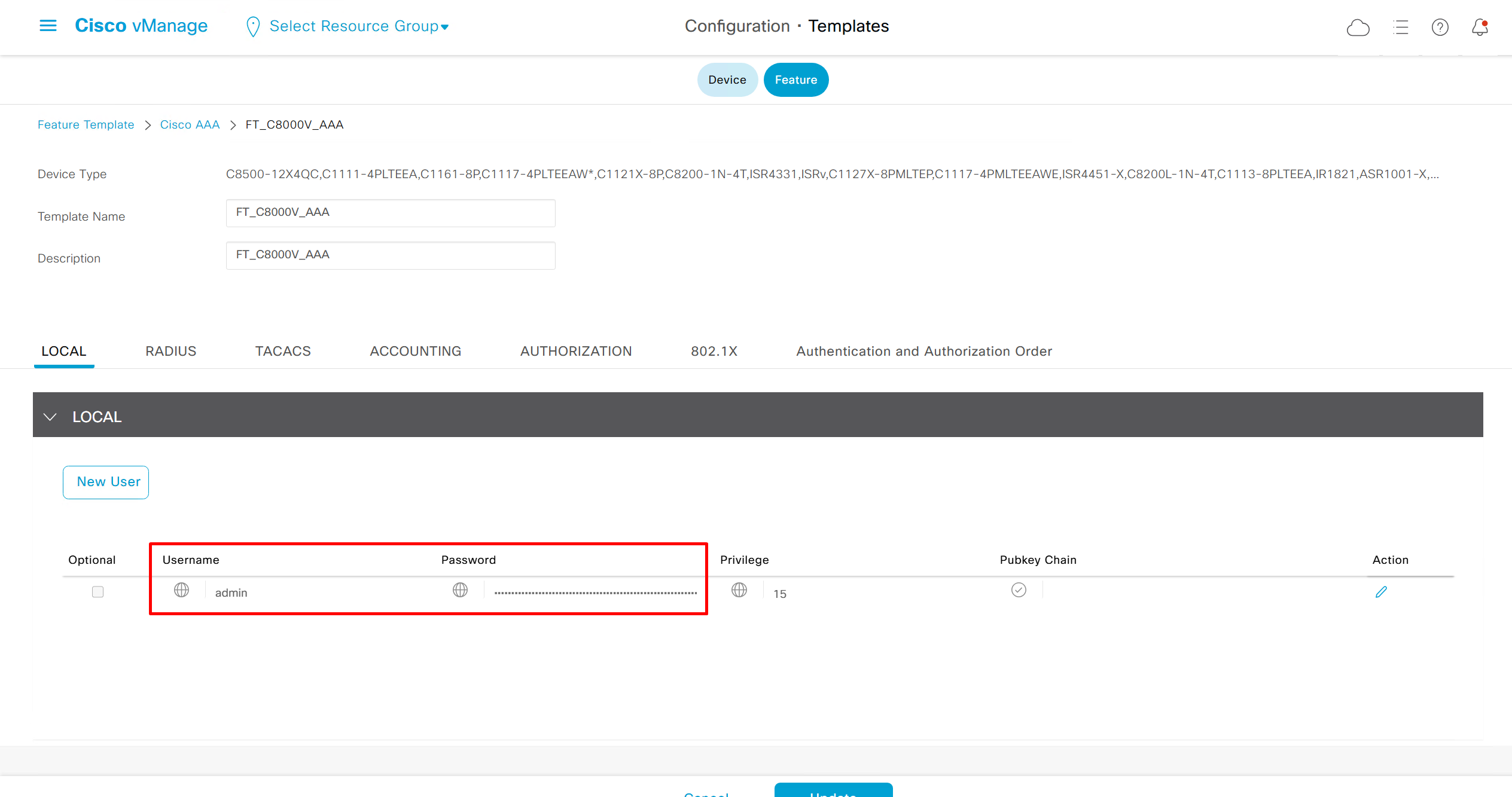

now I can login
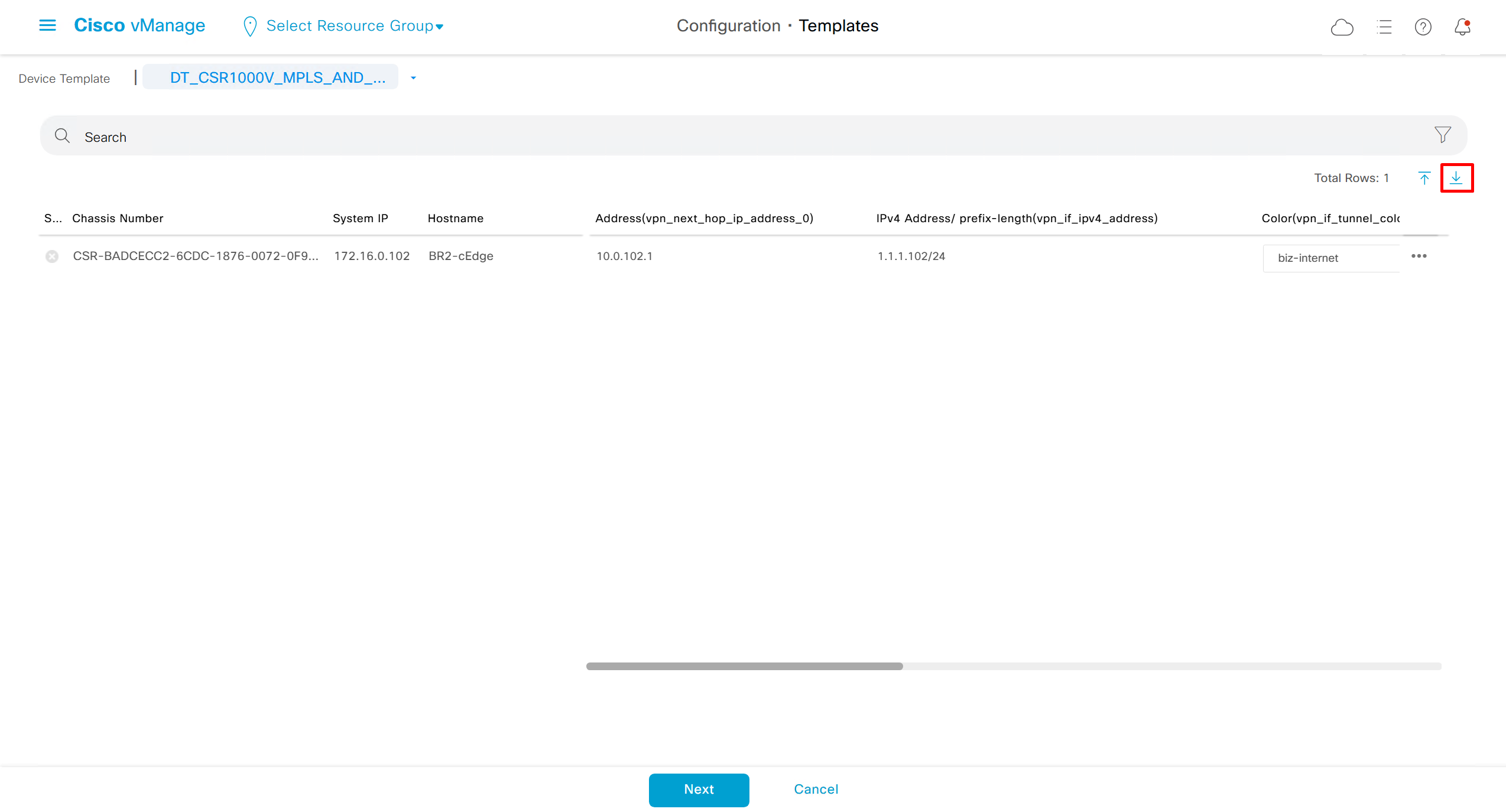
Whenever there is a change made on templates, these changes need to be pushed to the devices
While making those changes there is an option to download the CSV and make bulk changes and then upload the CSV back
This is very useful when you have large number of devices
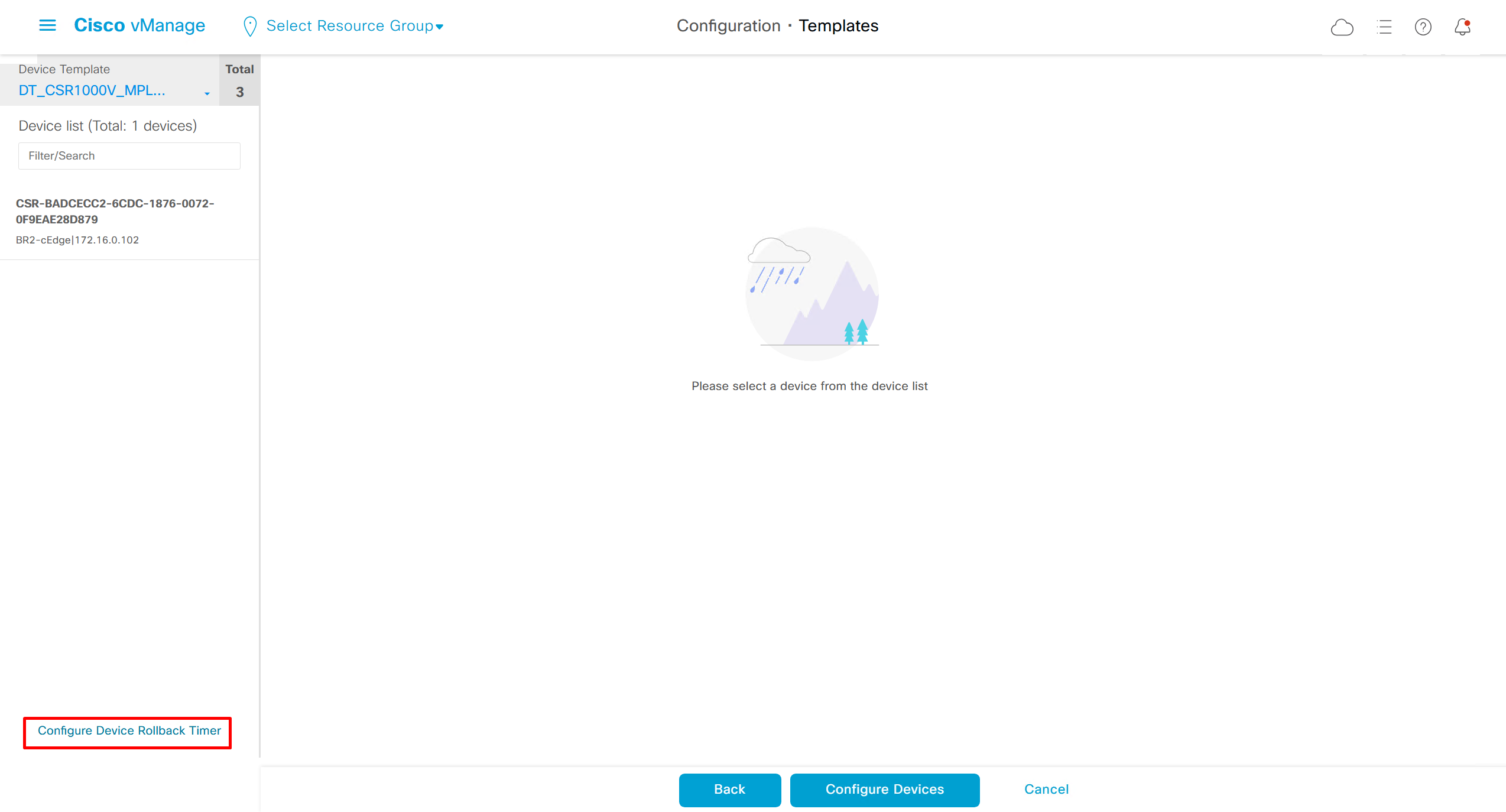
When making changes there is an option on the bottom left corner
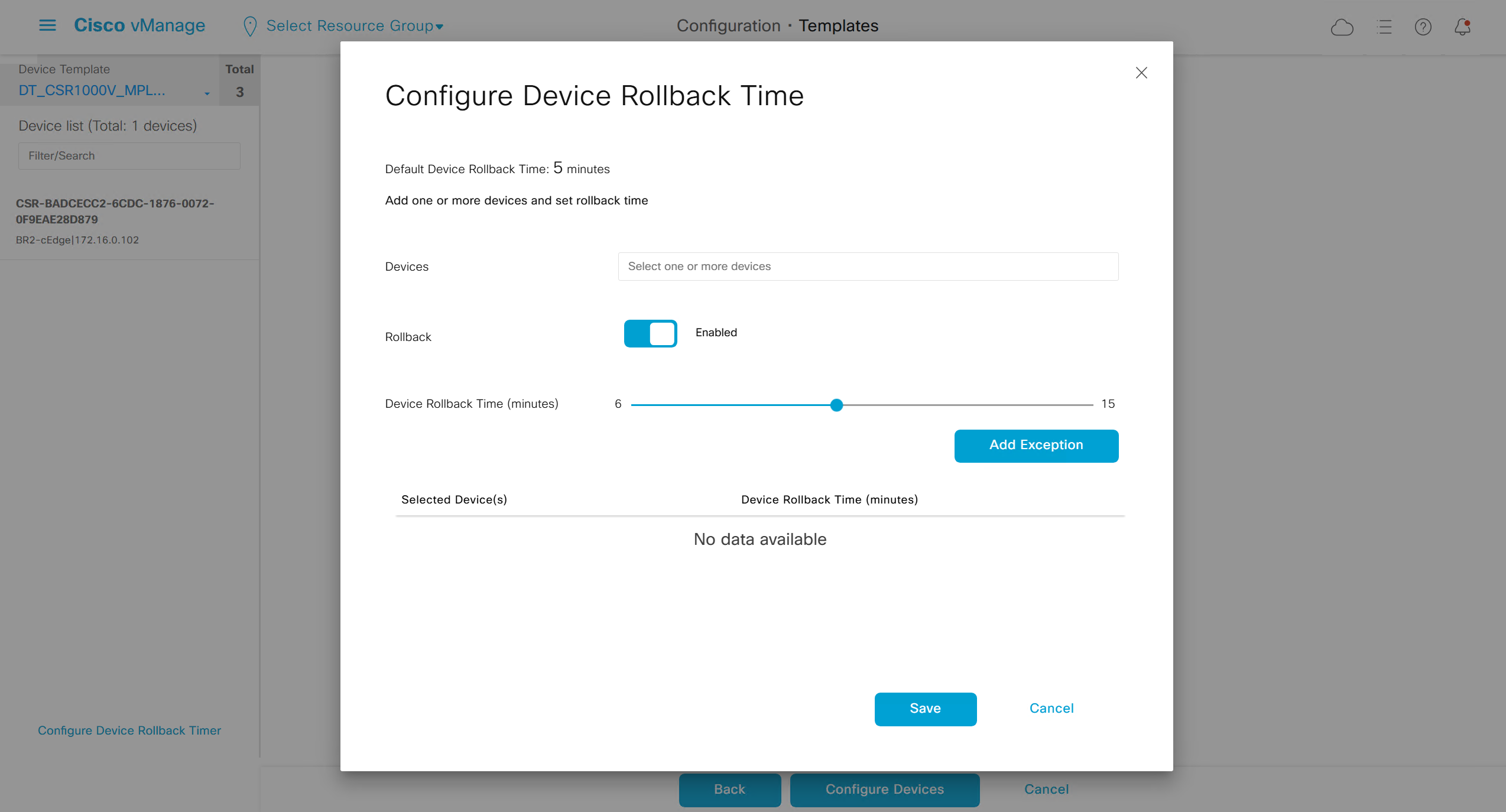
Configure Device Rollback Timer
NTP Feature Template common for all edges
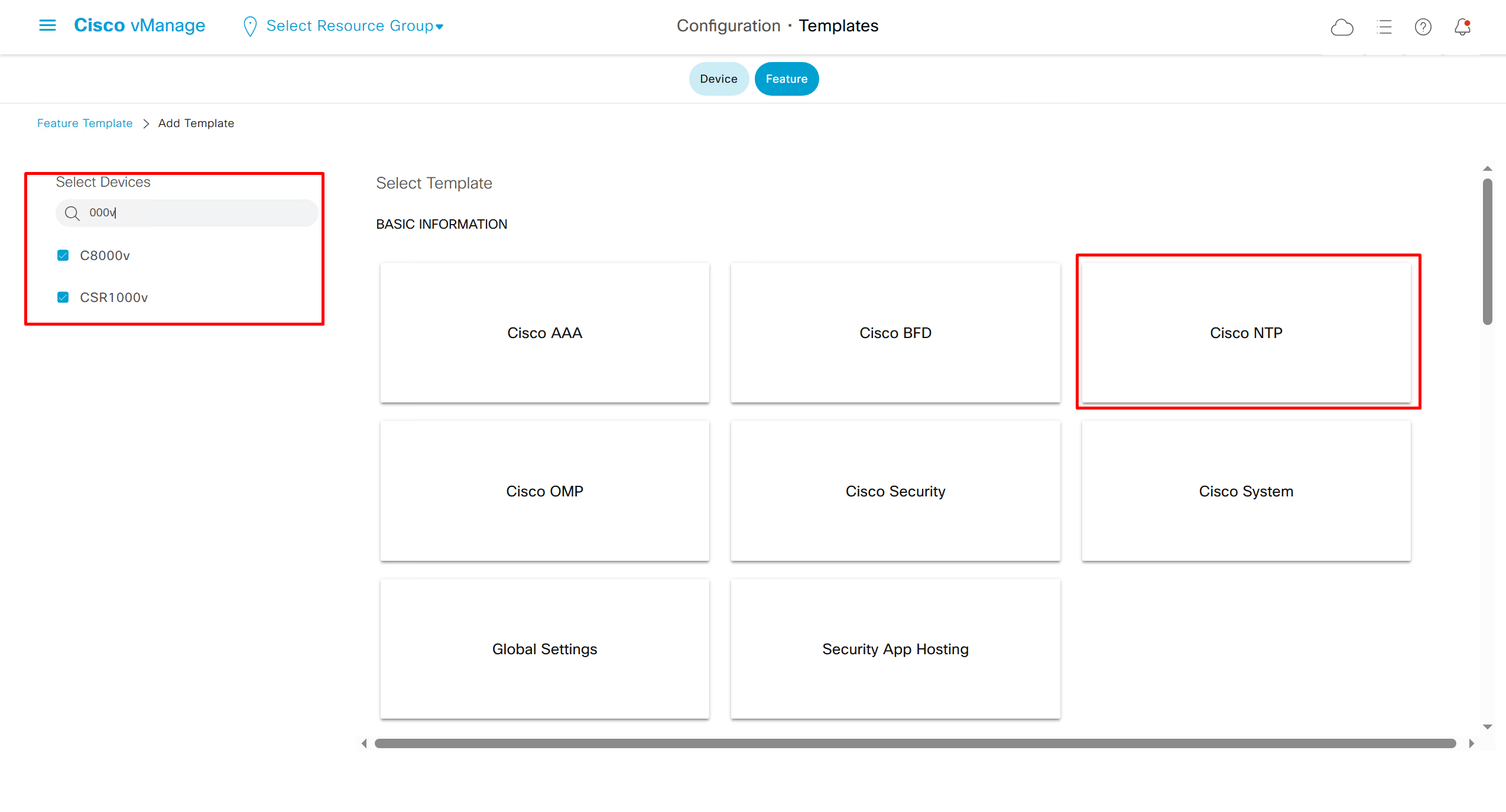
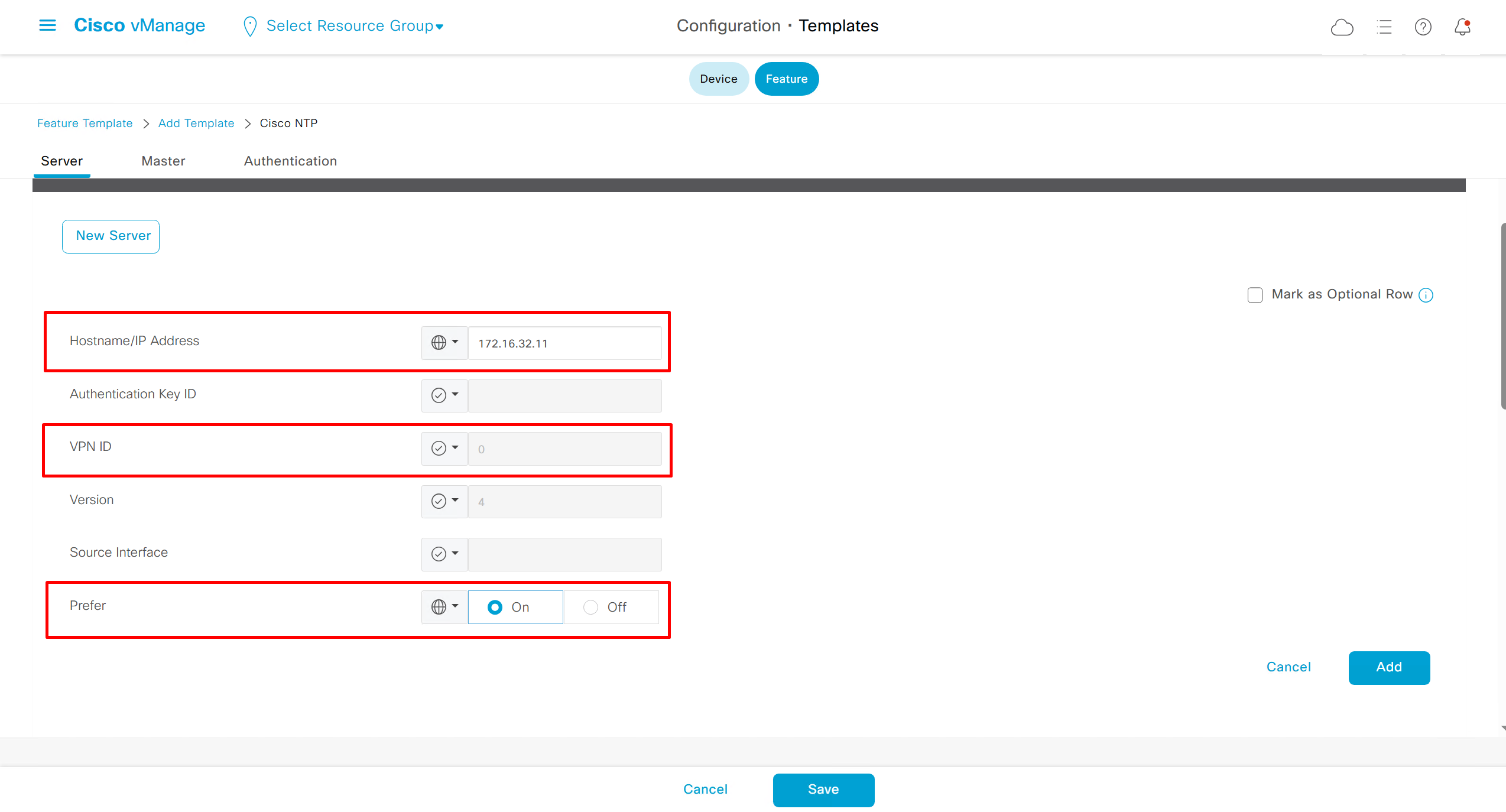

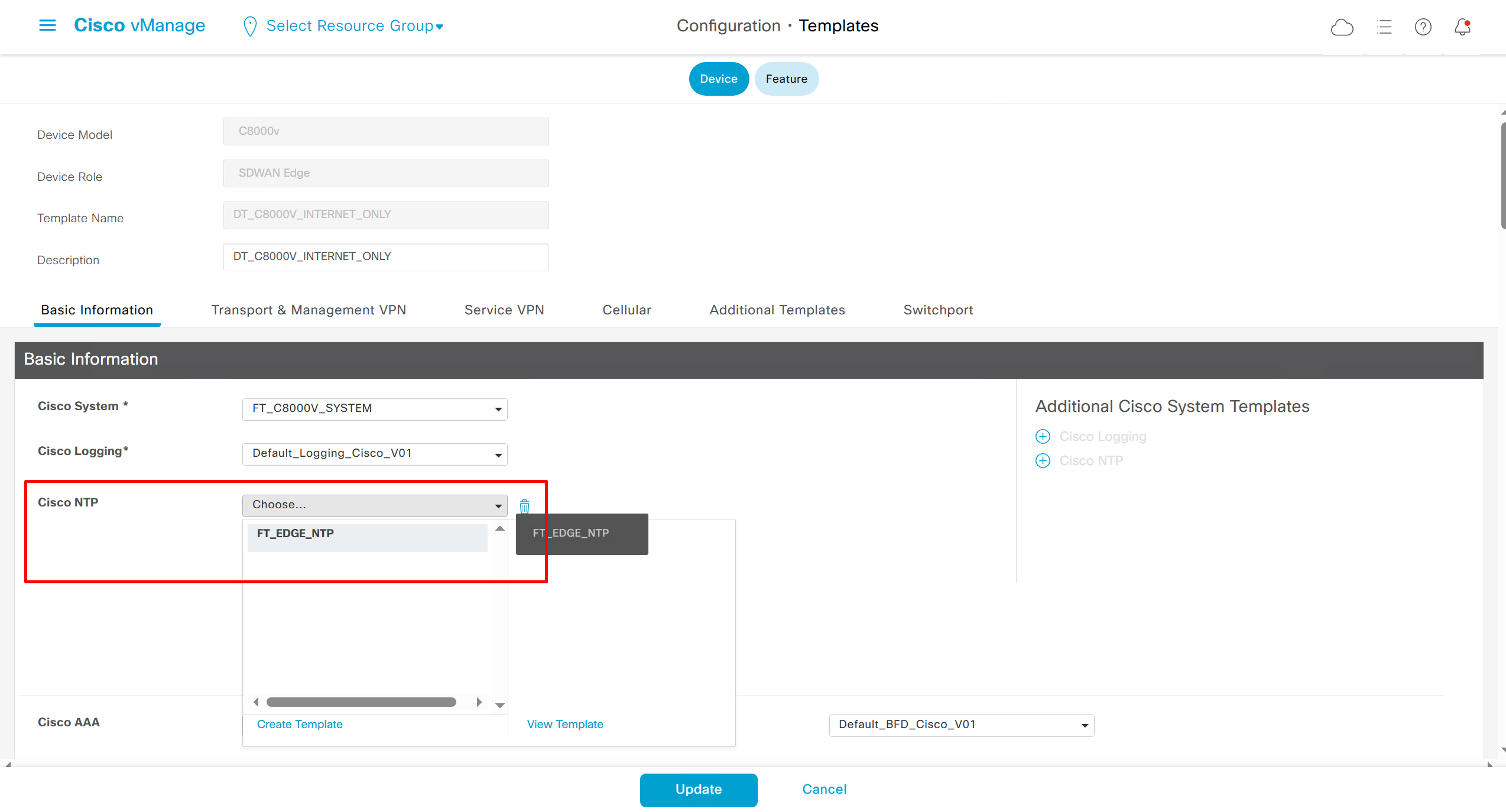
Login Banner Feature Template
Banner text new lines should be replaced with \n so it can be pasted in this box
************************************************************\n* *\n* WARNING: Authorized Access Only! *\n* *\n* This system is for the use of authorized users only. *\n* Any unauthorized access or use is prohibited and *\n* may be subject to criminal and civil penalties. *\n* *\n* All activities on this system are monitored. *\n* *\n************************************************************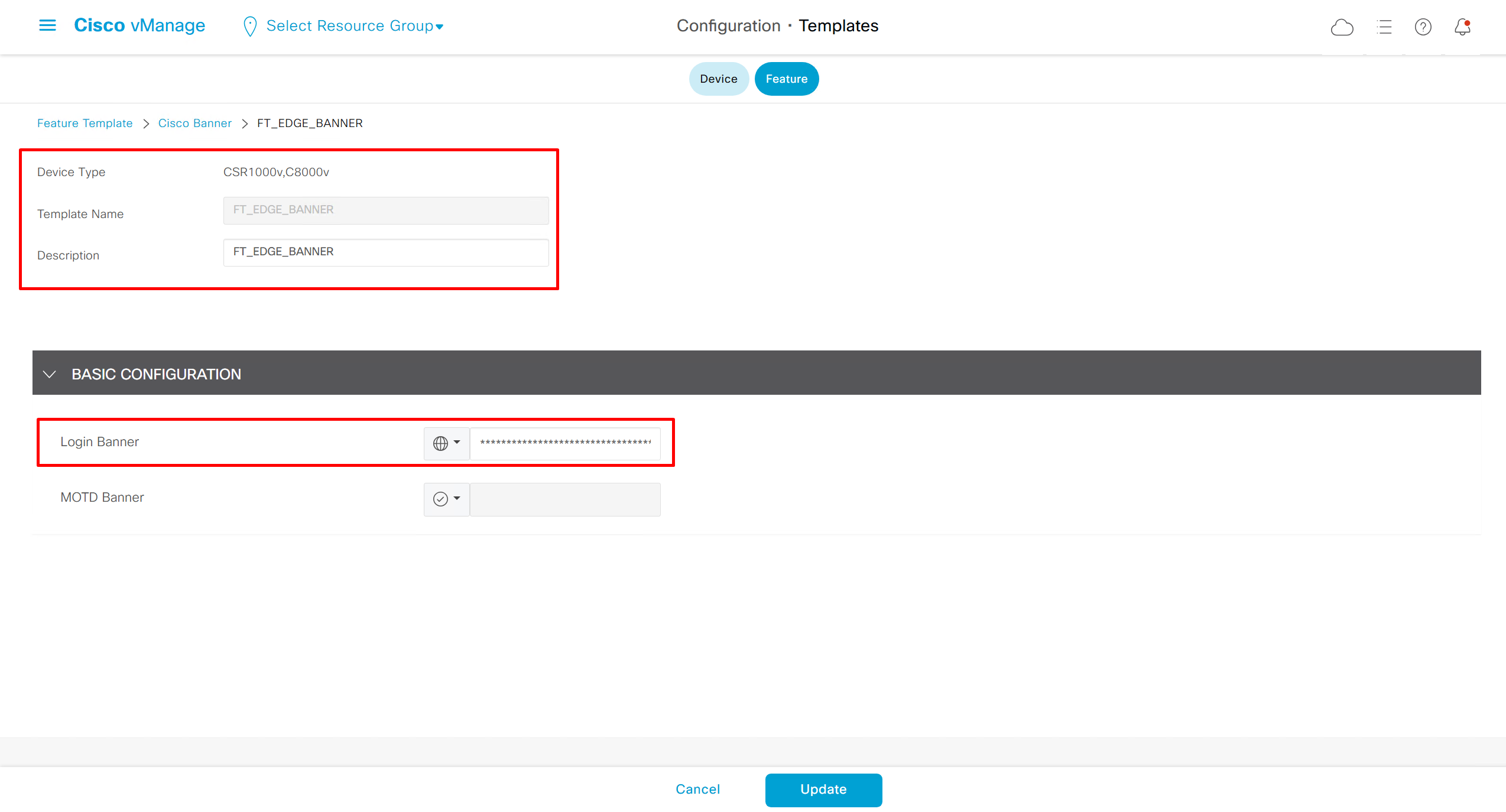
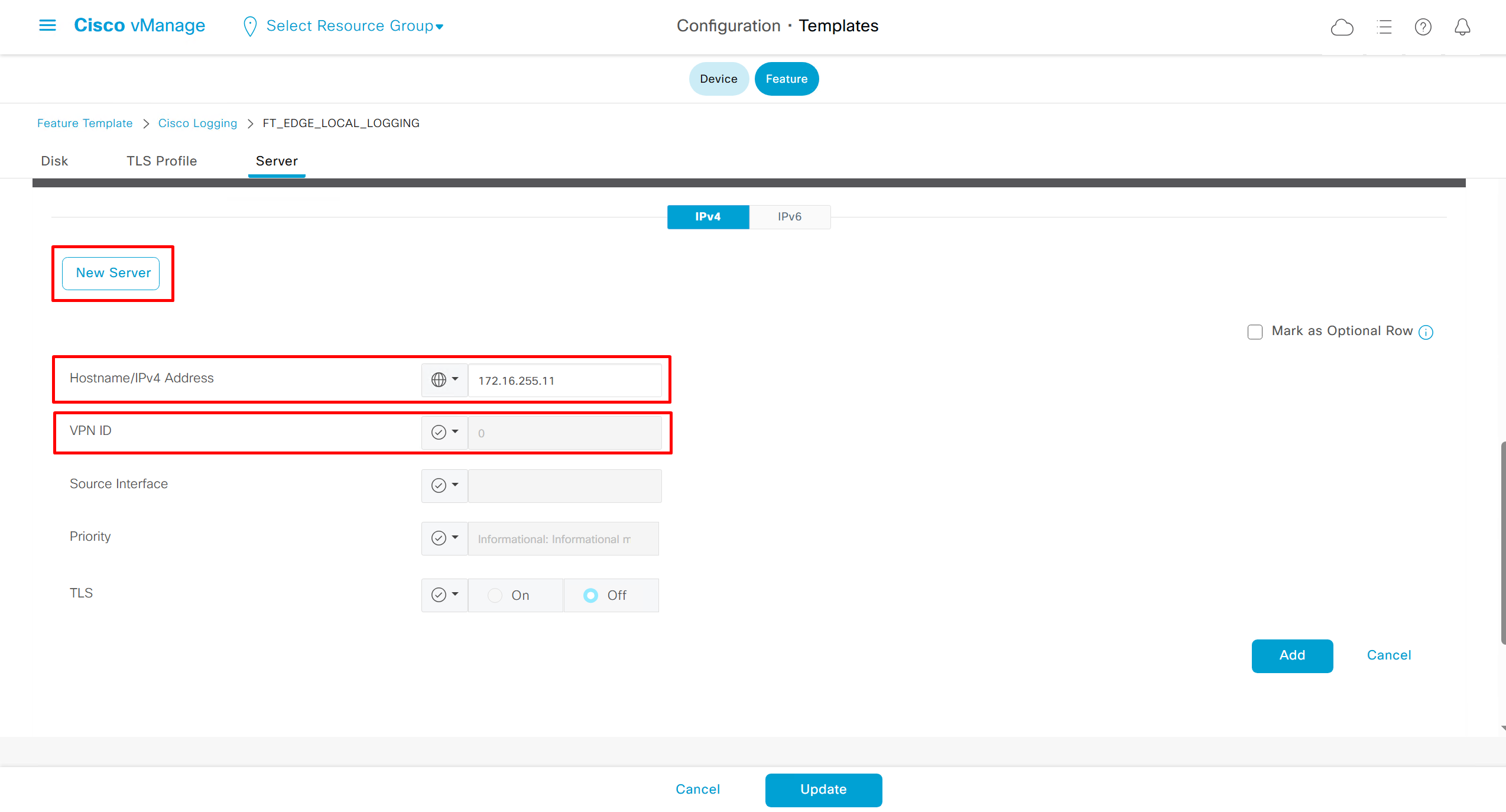
Local Disk Logging Feature Template
As log messages are in /var/log for troubleshooting
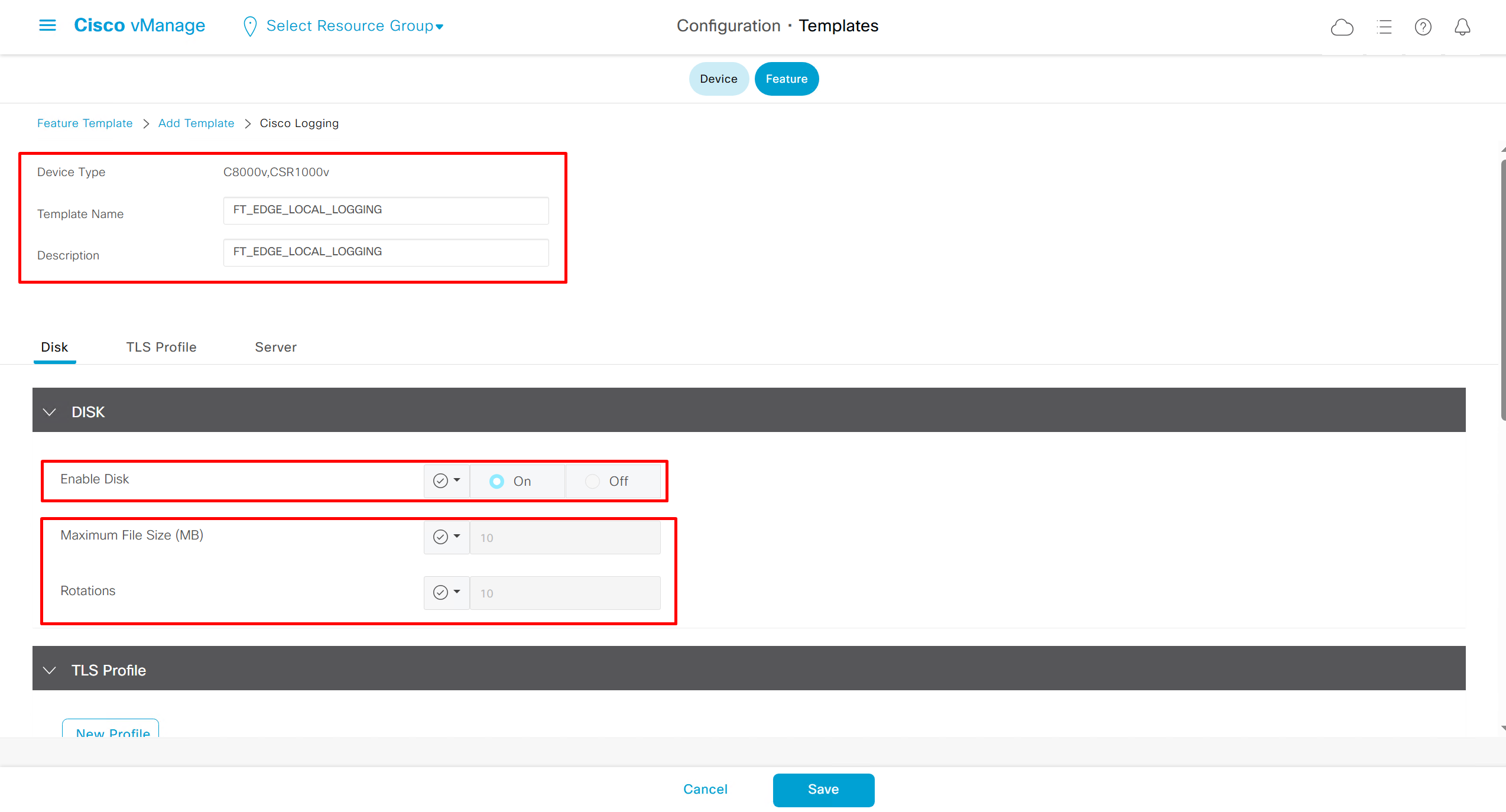
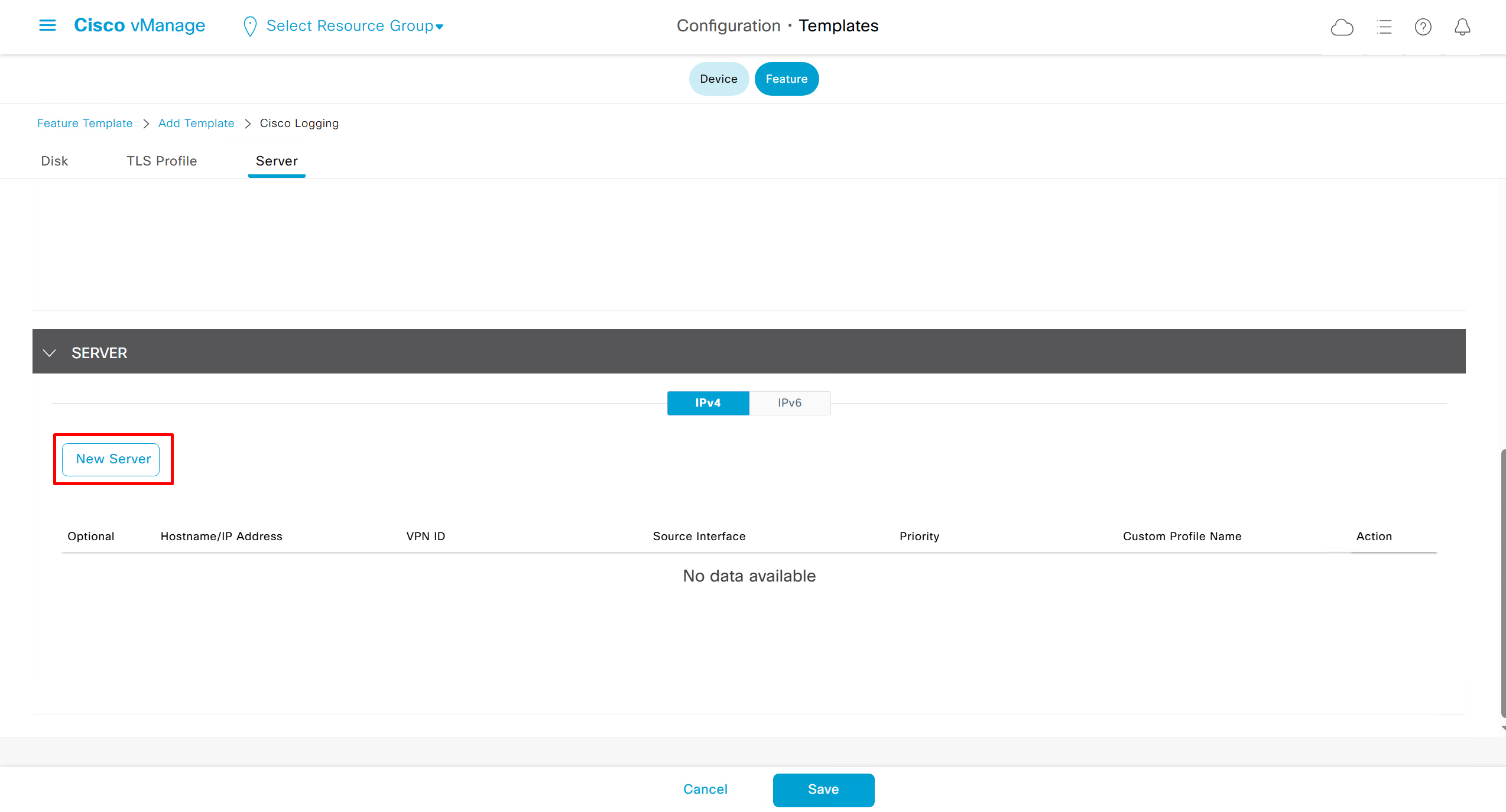
In case Syslog server is inside Datacenter and not over the WAN transport then we have to change the below VPN number and change it from 0 to service side VPN / VRF number of local site / datacenter in which Syslog server lives
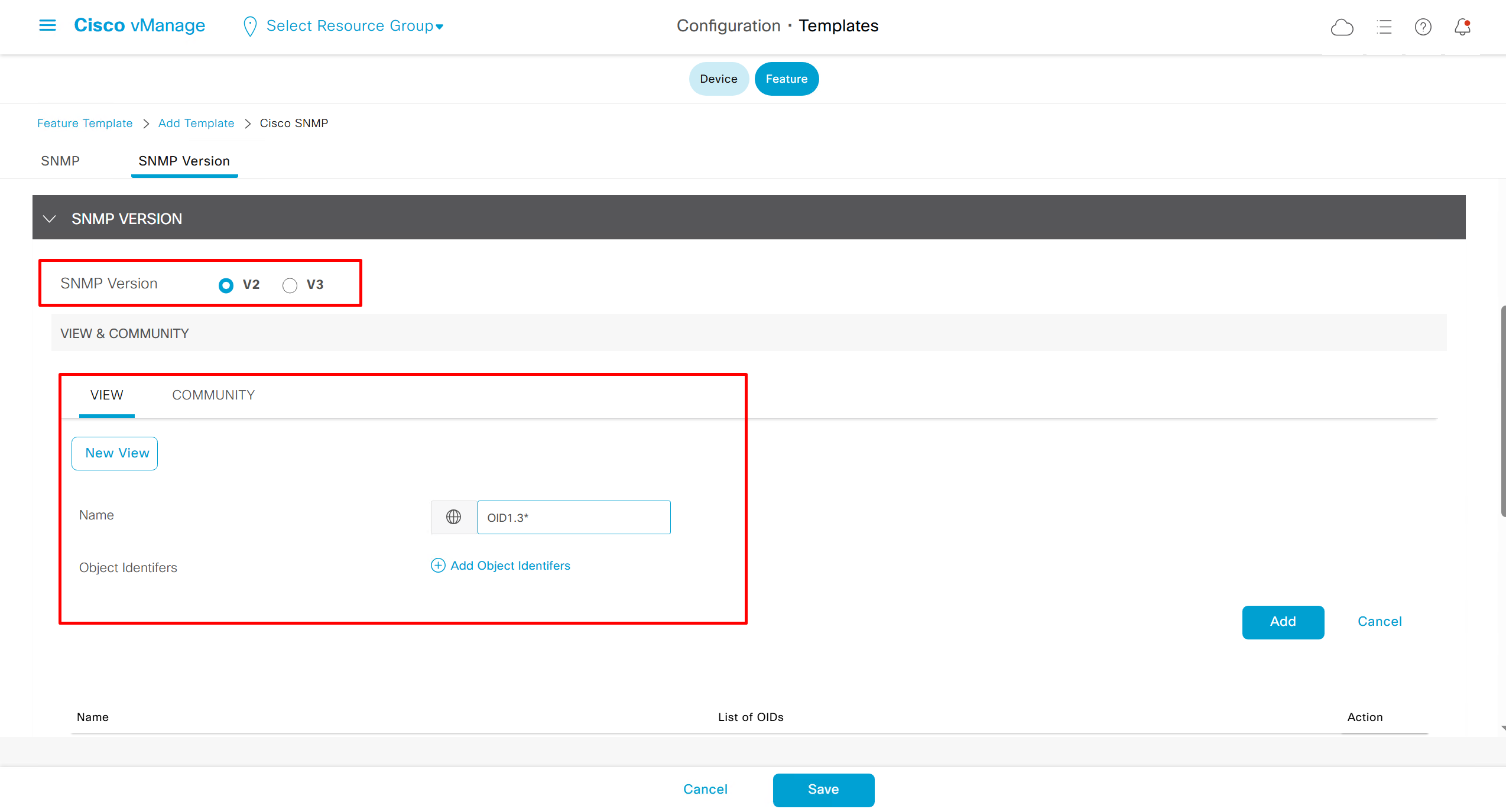
SNMP Feature Template

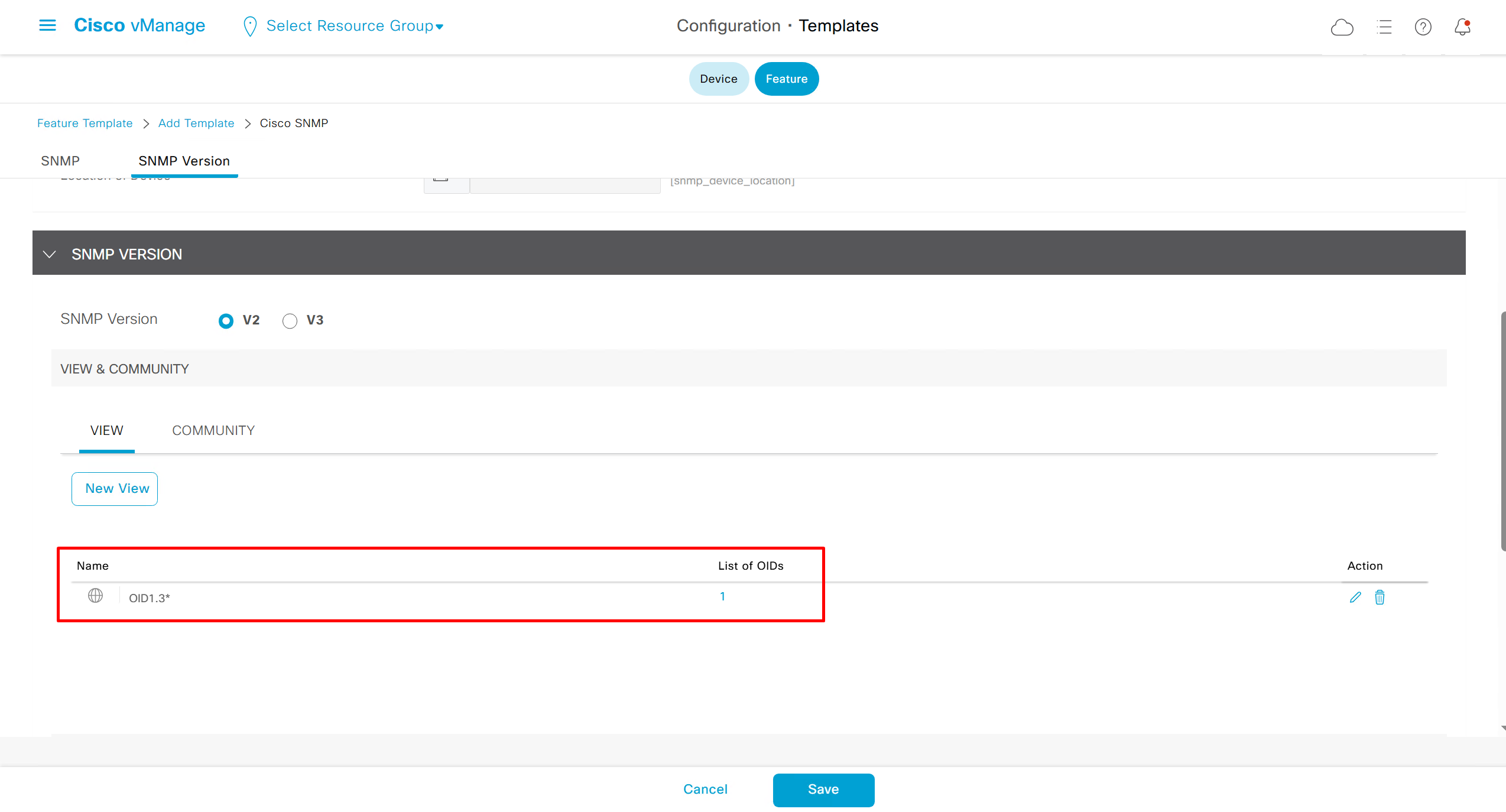
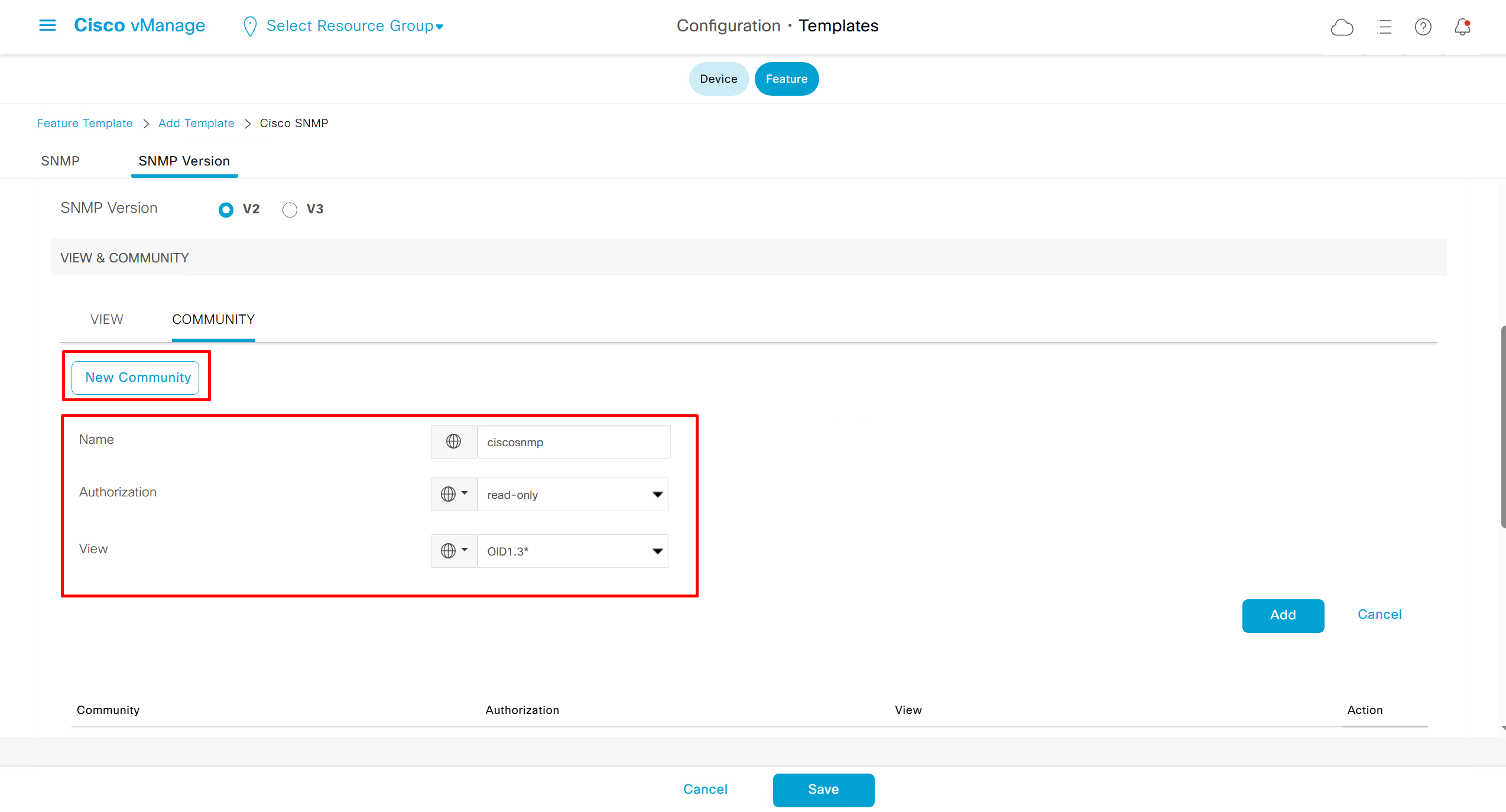

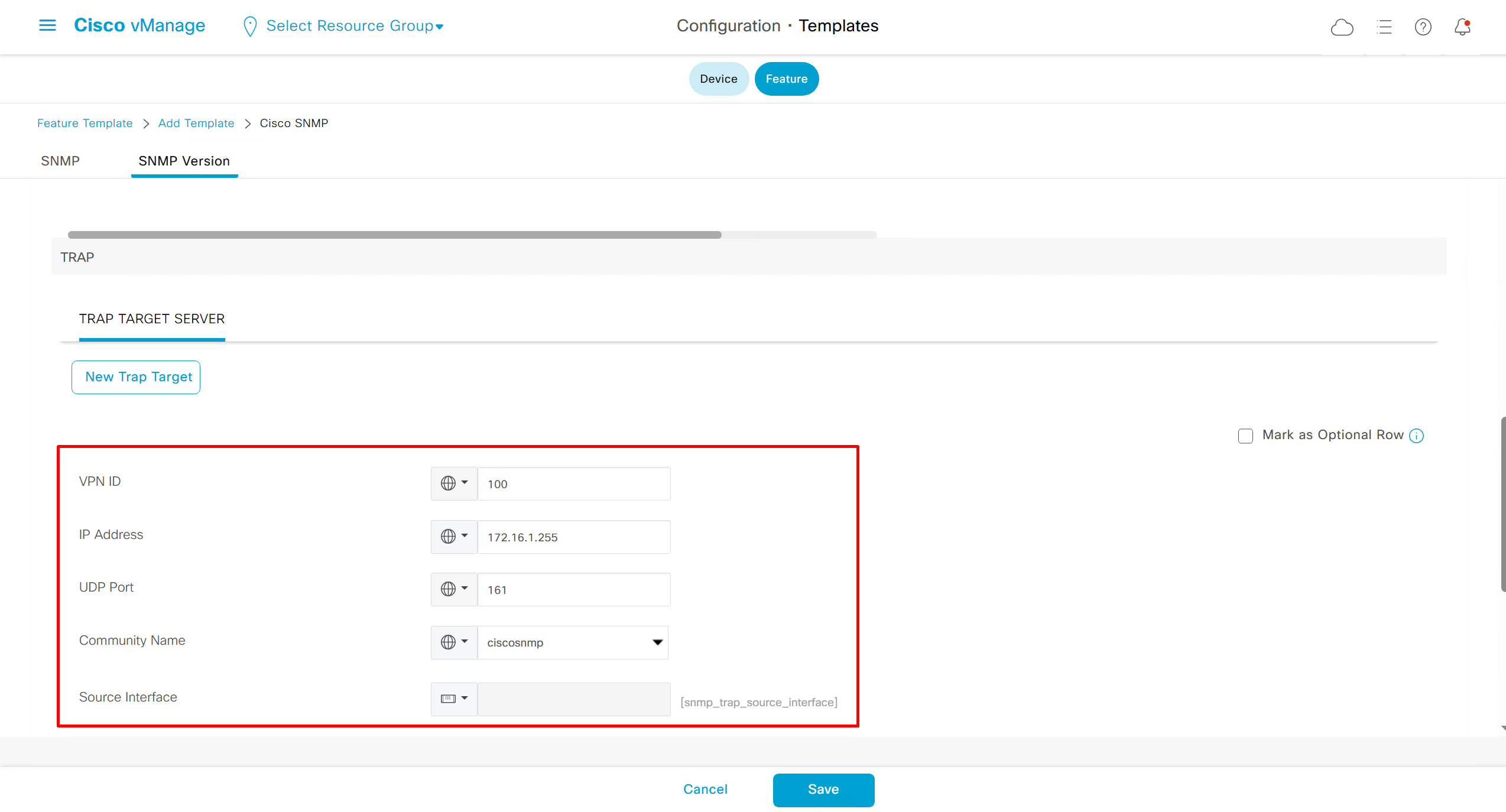
Templates on Controllers
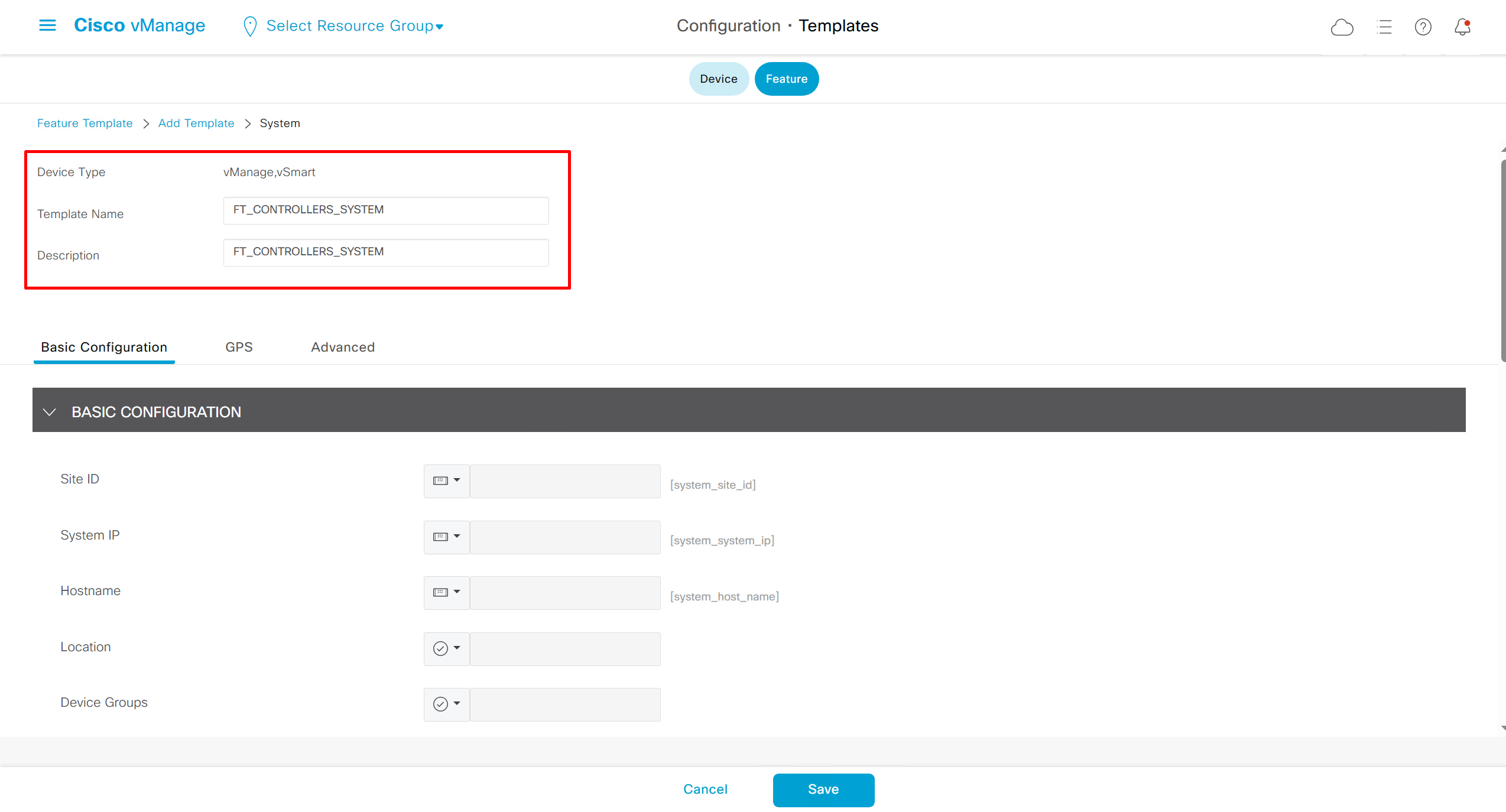
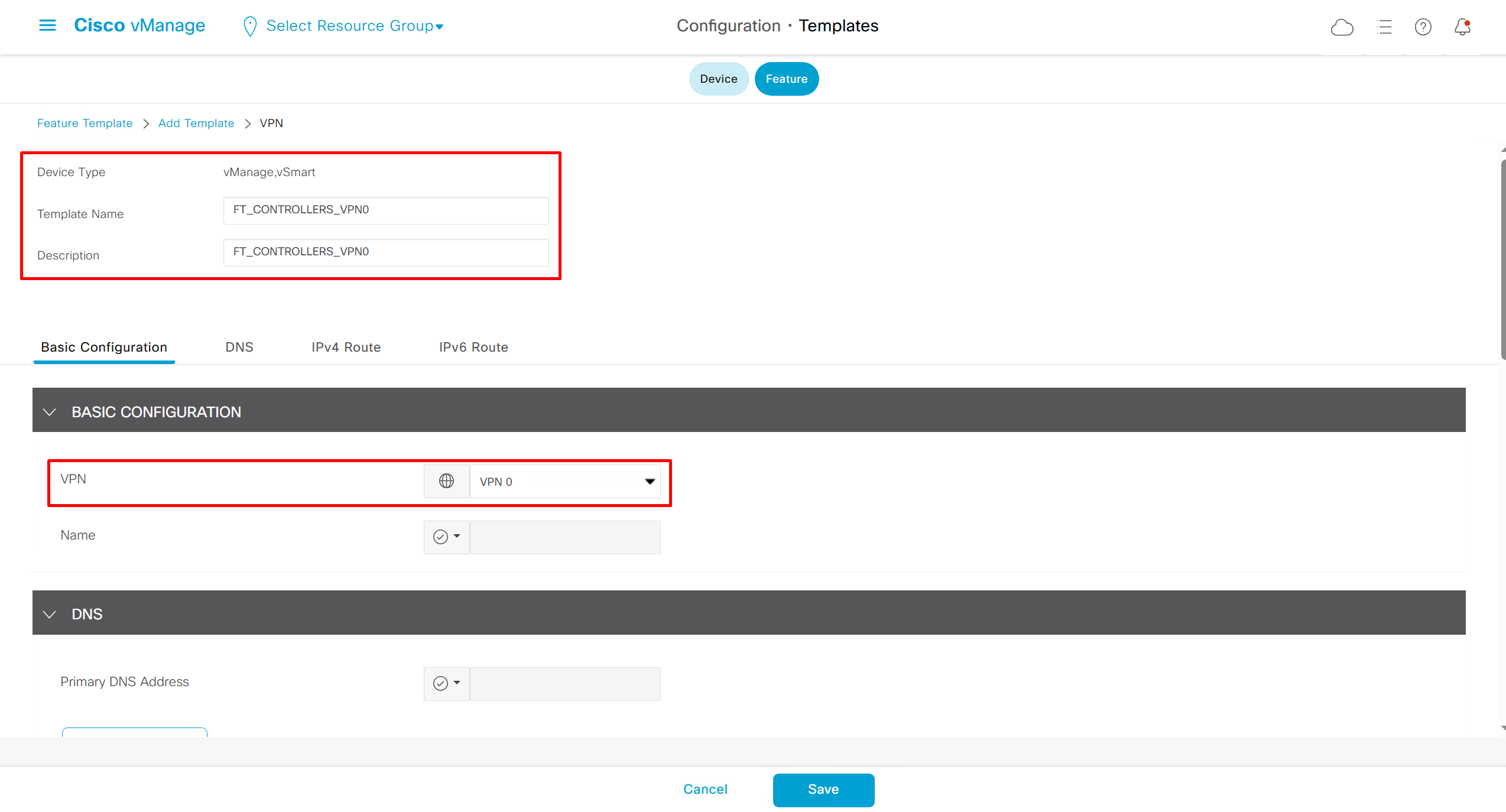
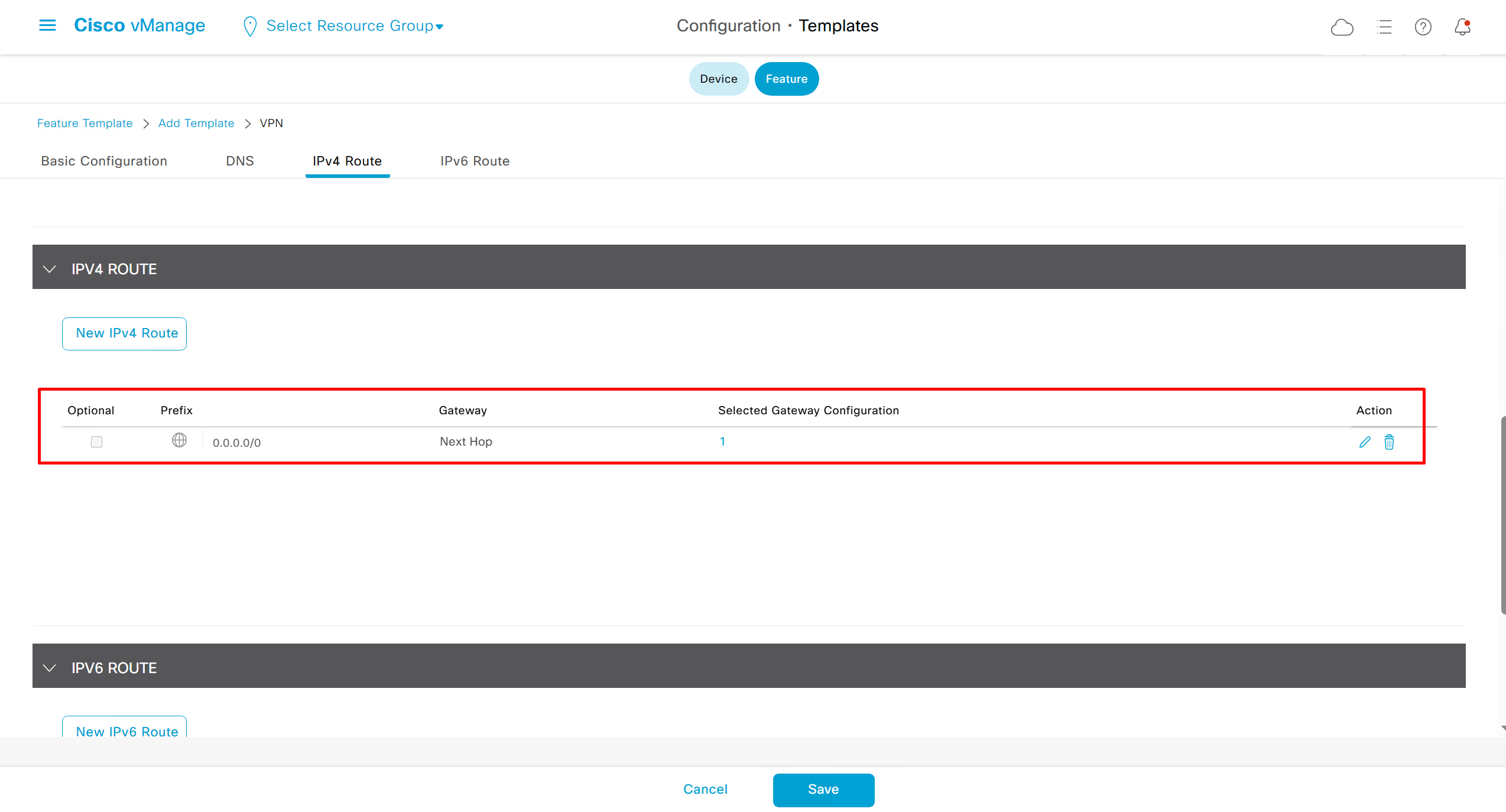
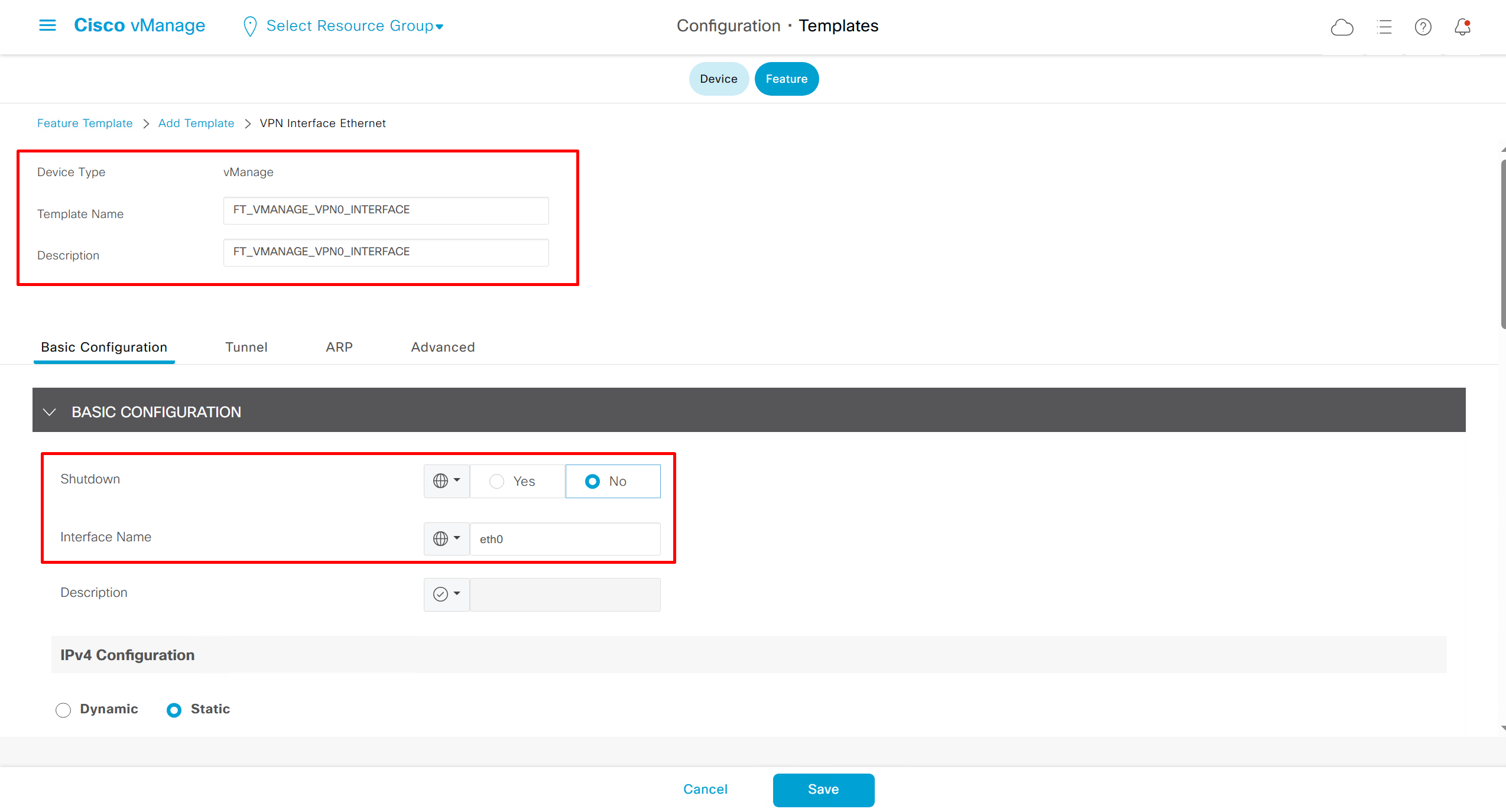
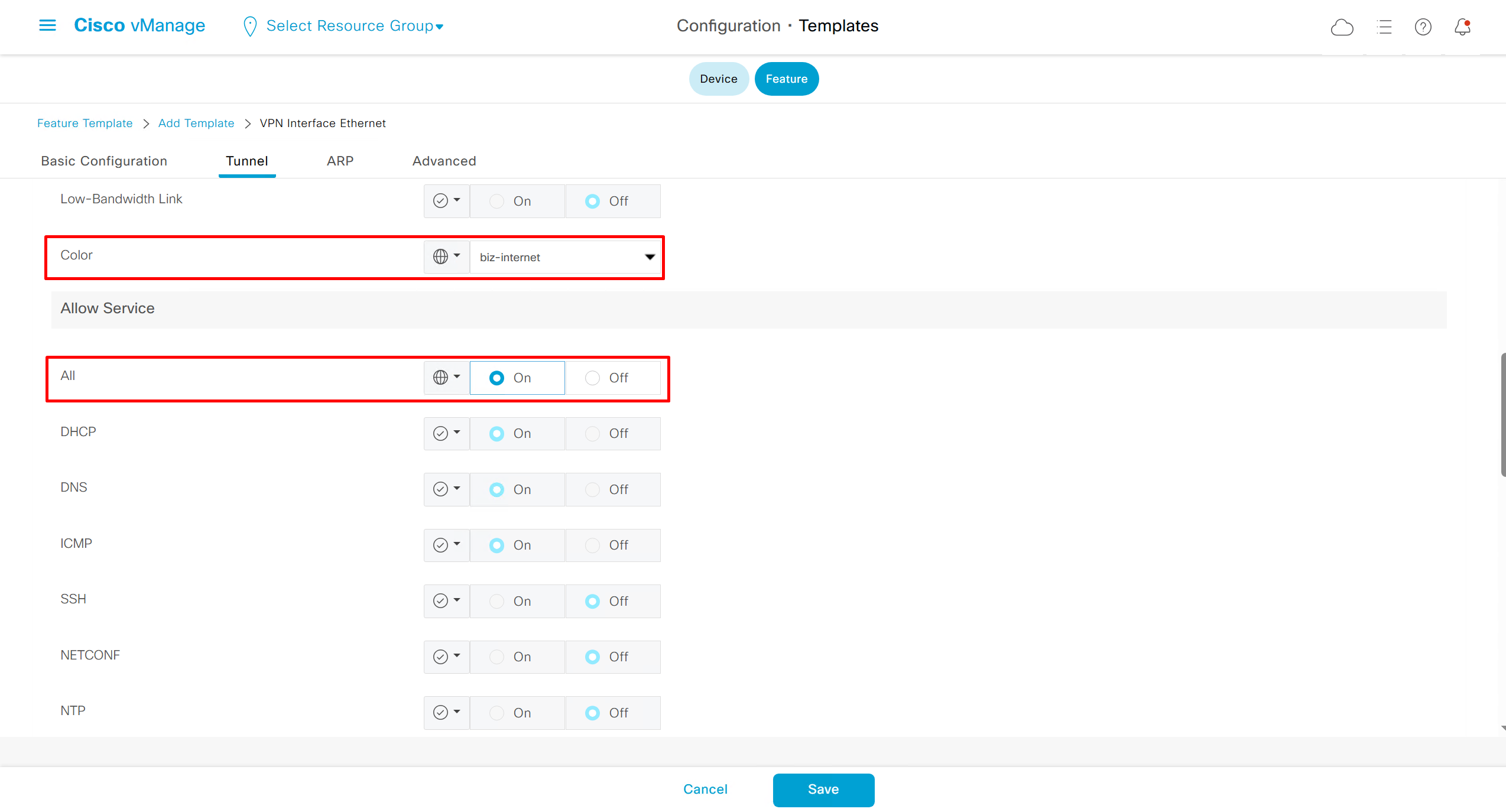
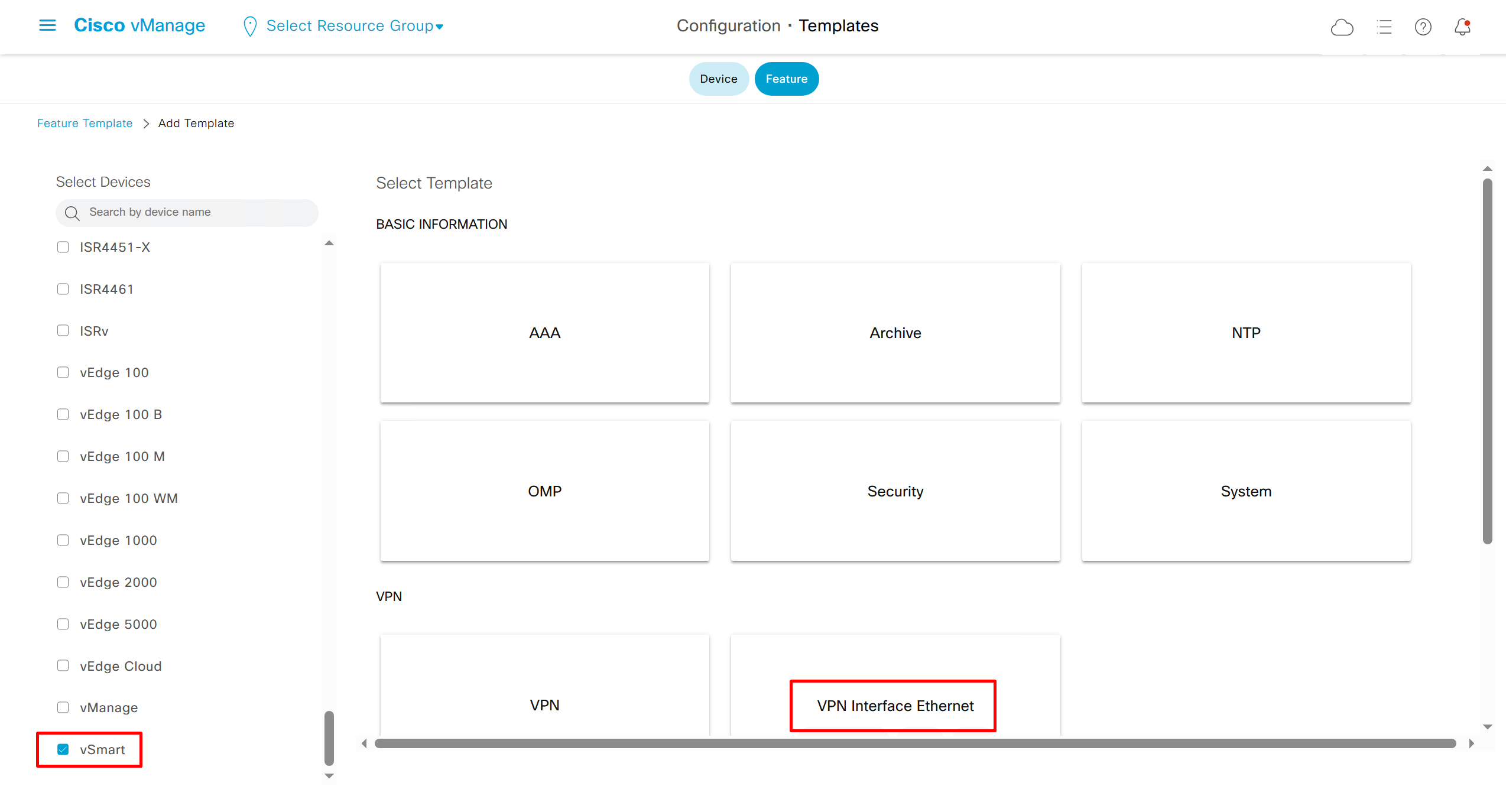
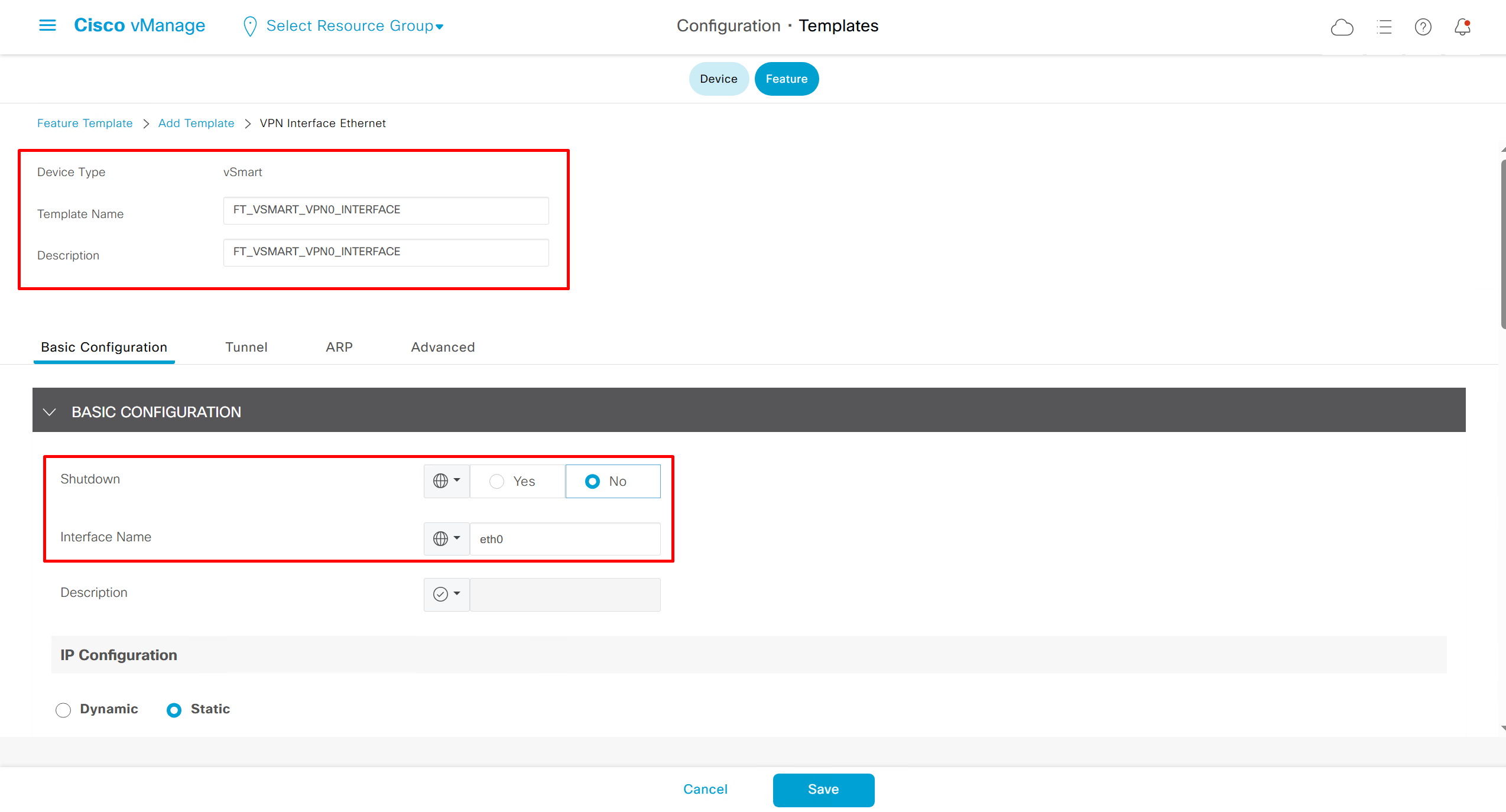
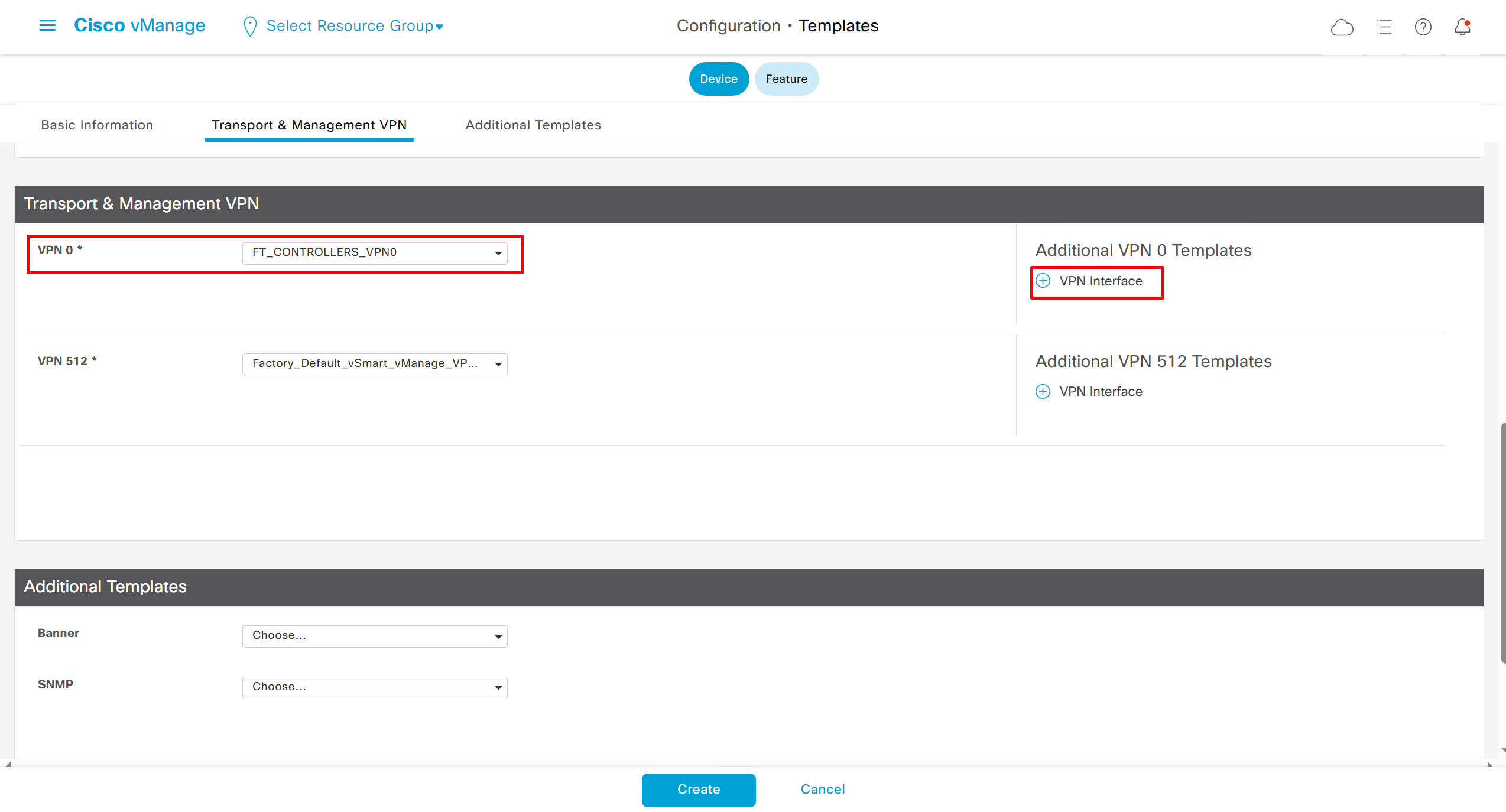
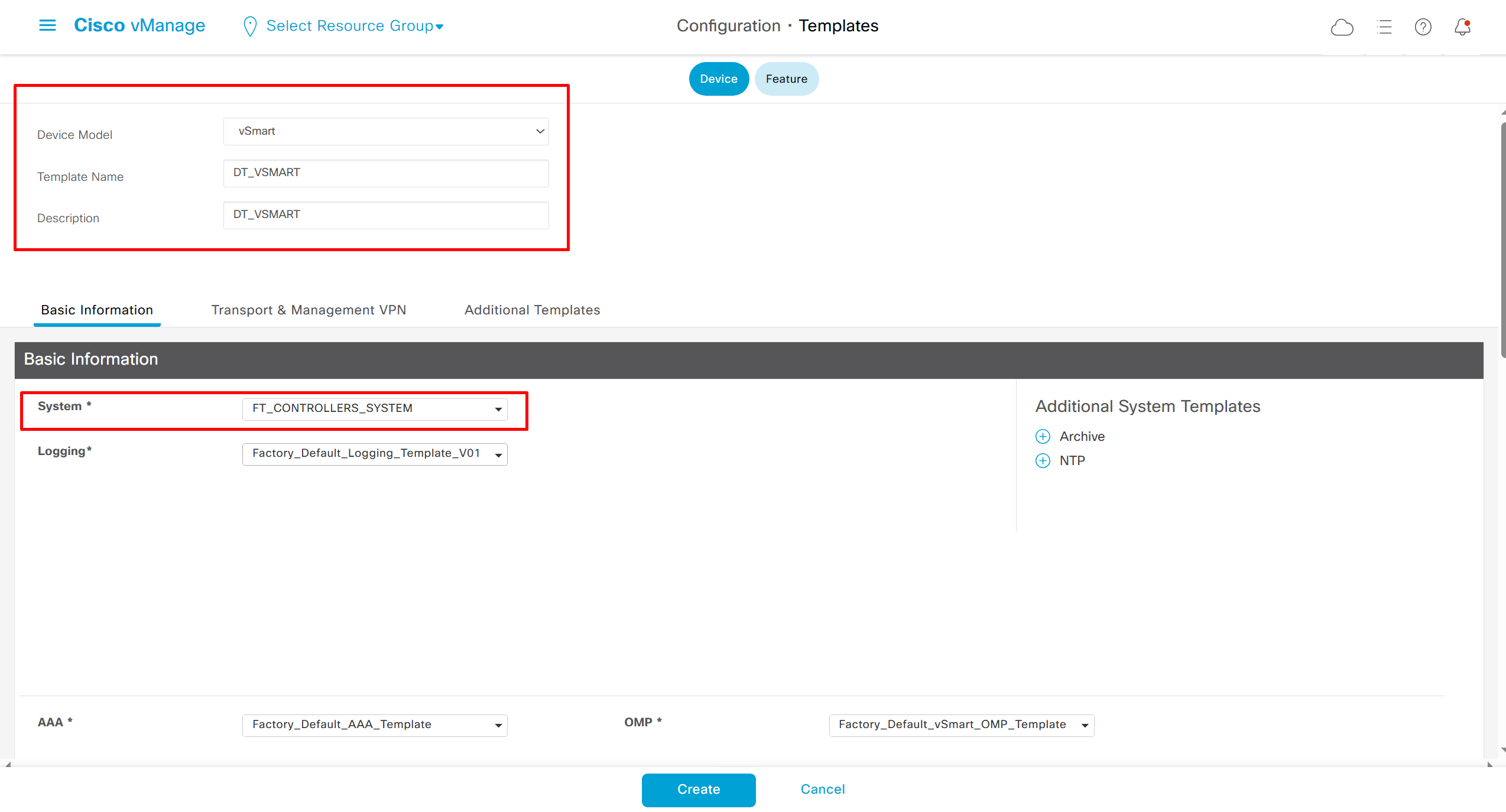
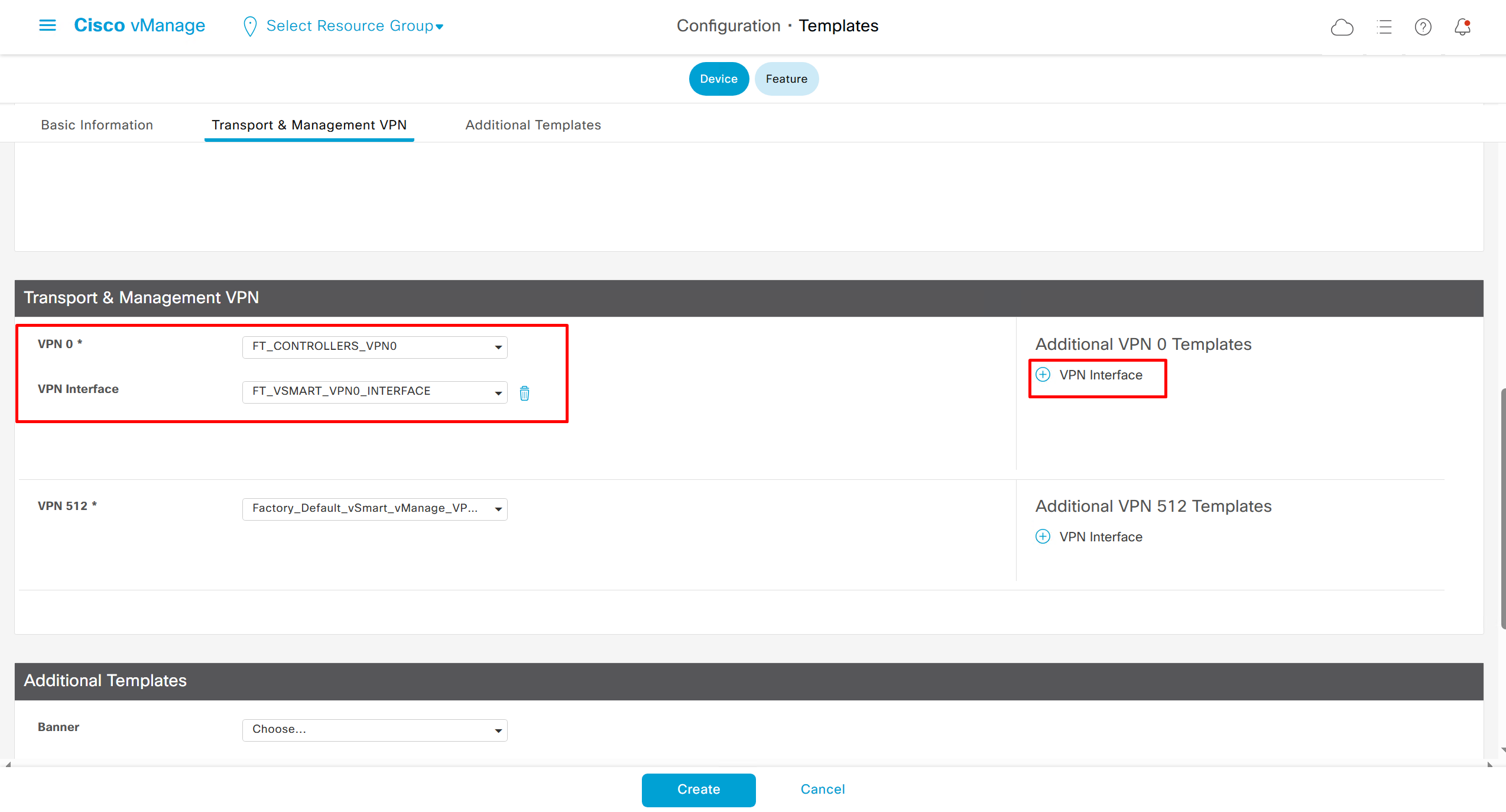
Remember that we need to configure system, vpn 0 (routing table for transport) and interface feature templates
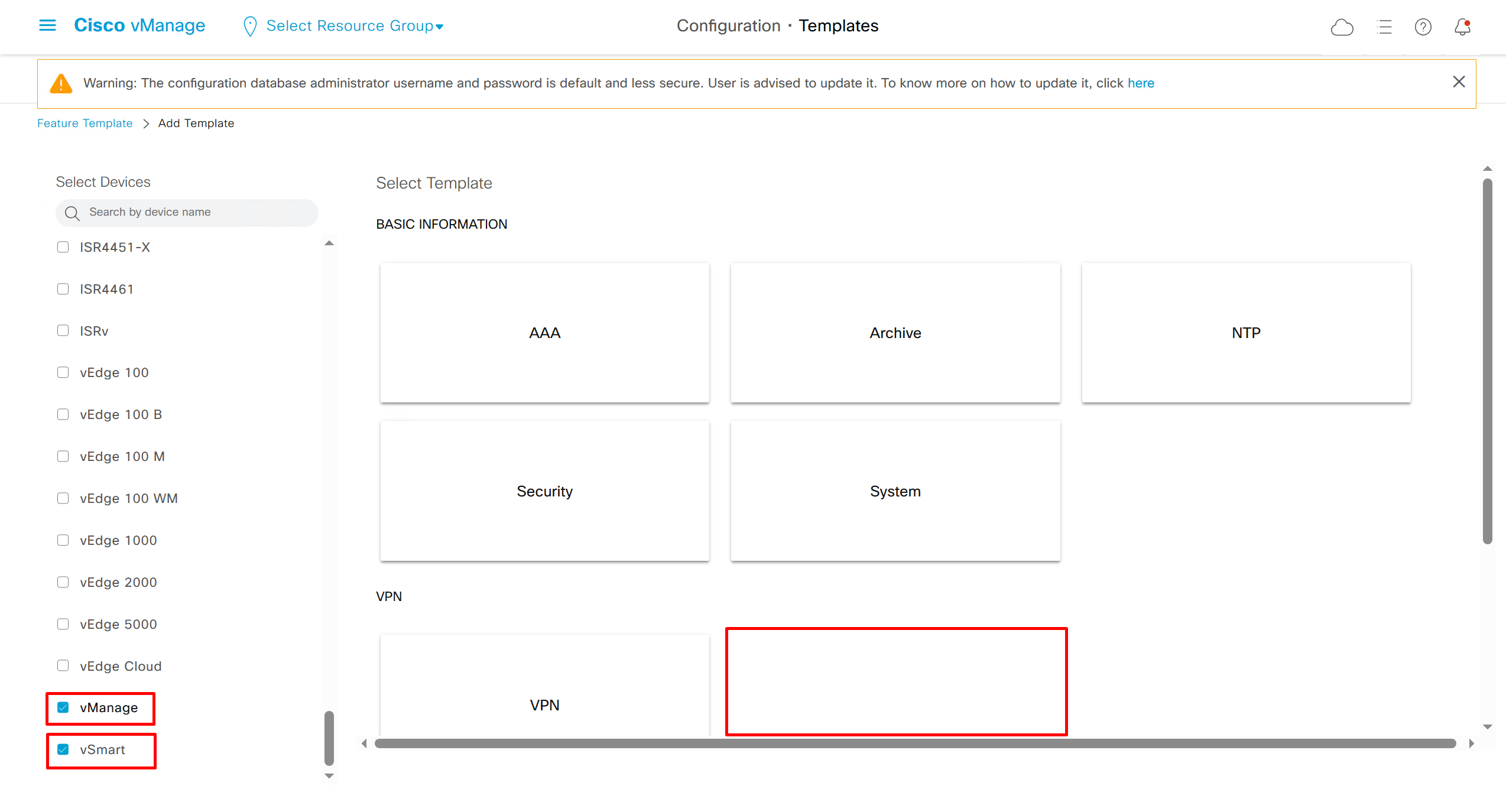
but when device type vManage and vSmart, template types are reduced

with vmanage and vsmart selected we can have common feature template for system and vpn
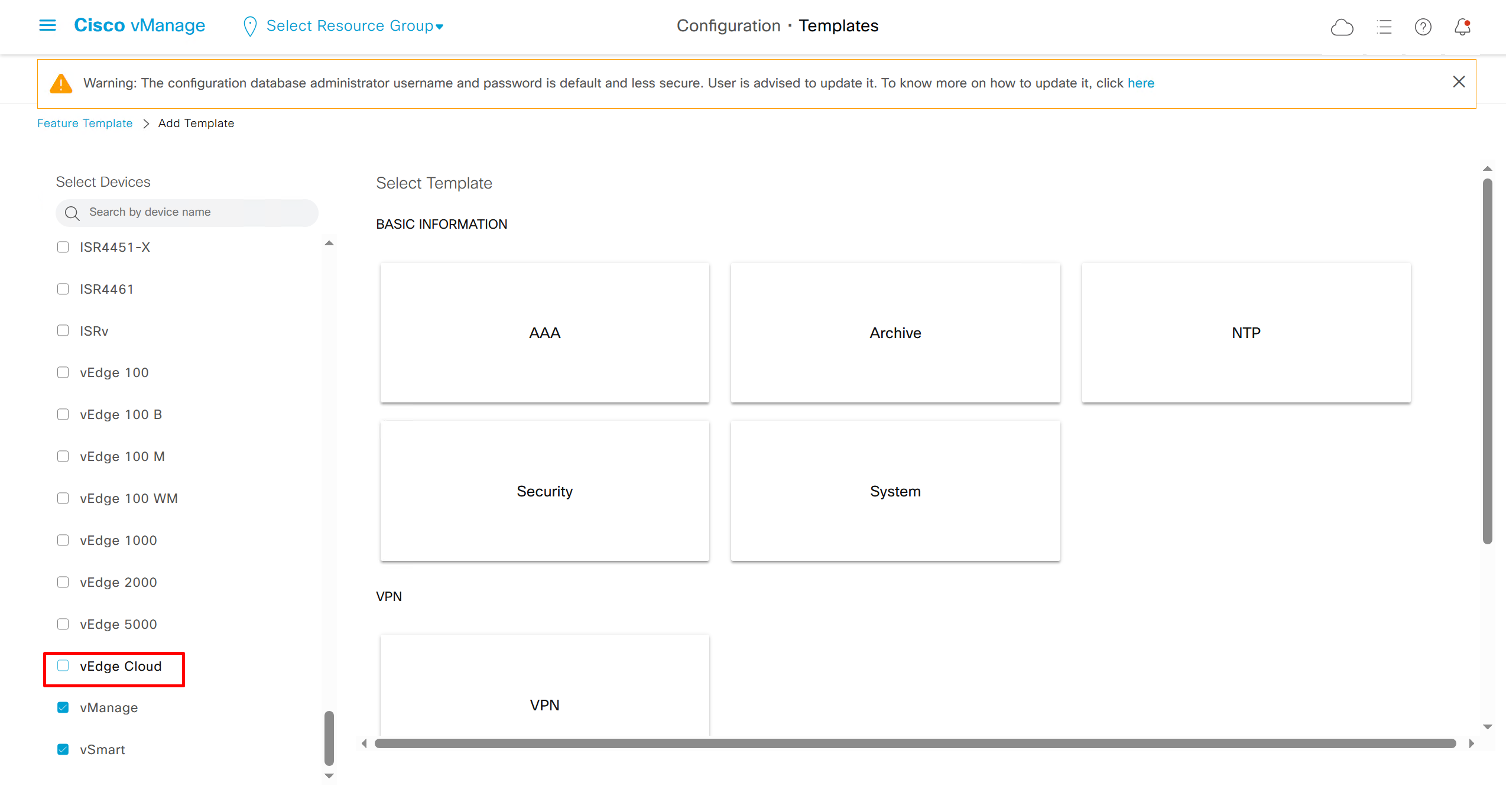
vedge cloud is applied on vbond
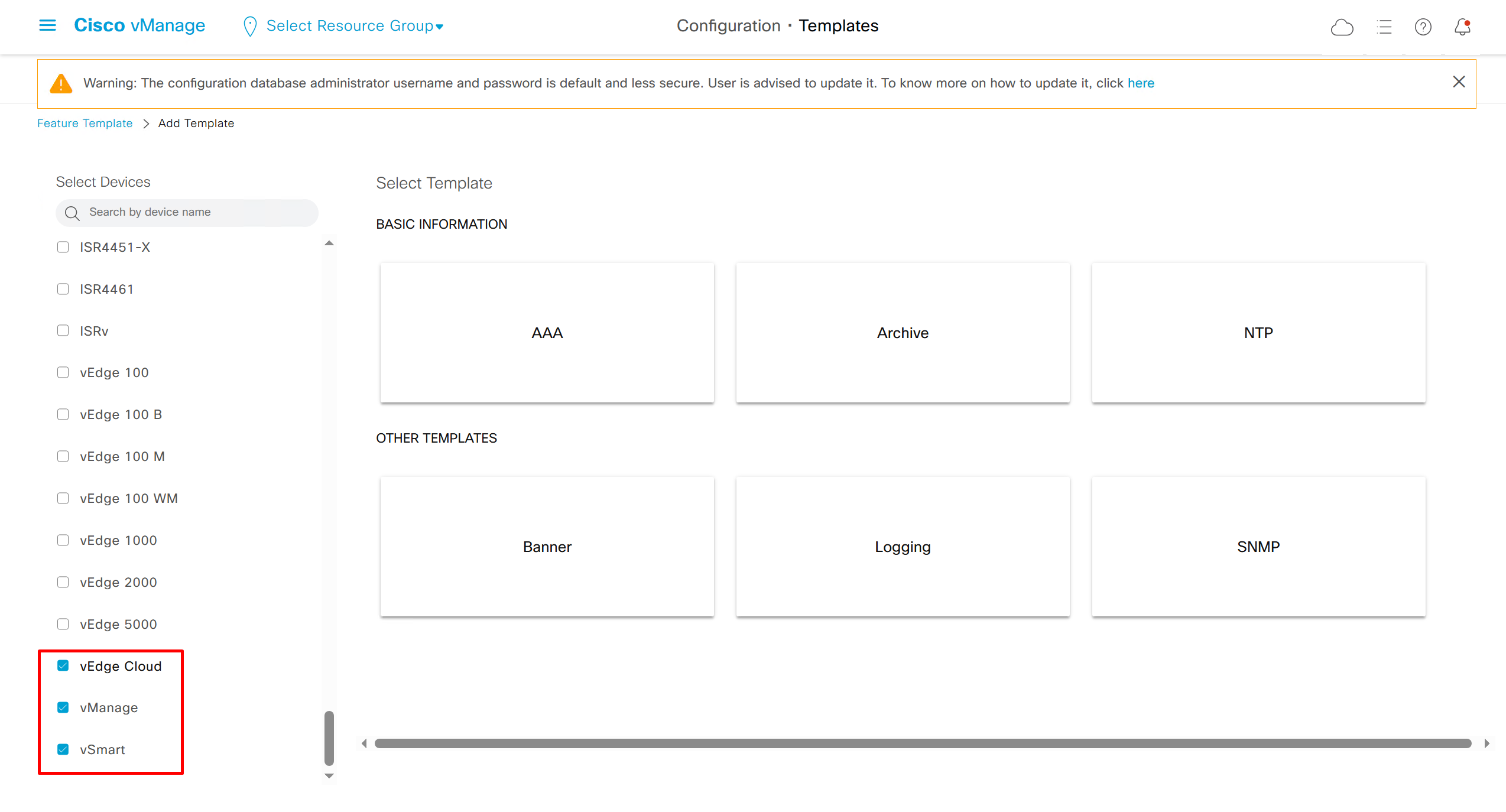
we are more limited in terms of template when we select vedge cloud, vmanage and vsmart
Lets configure template for vmanage





SDWAN – GUI
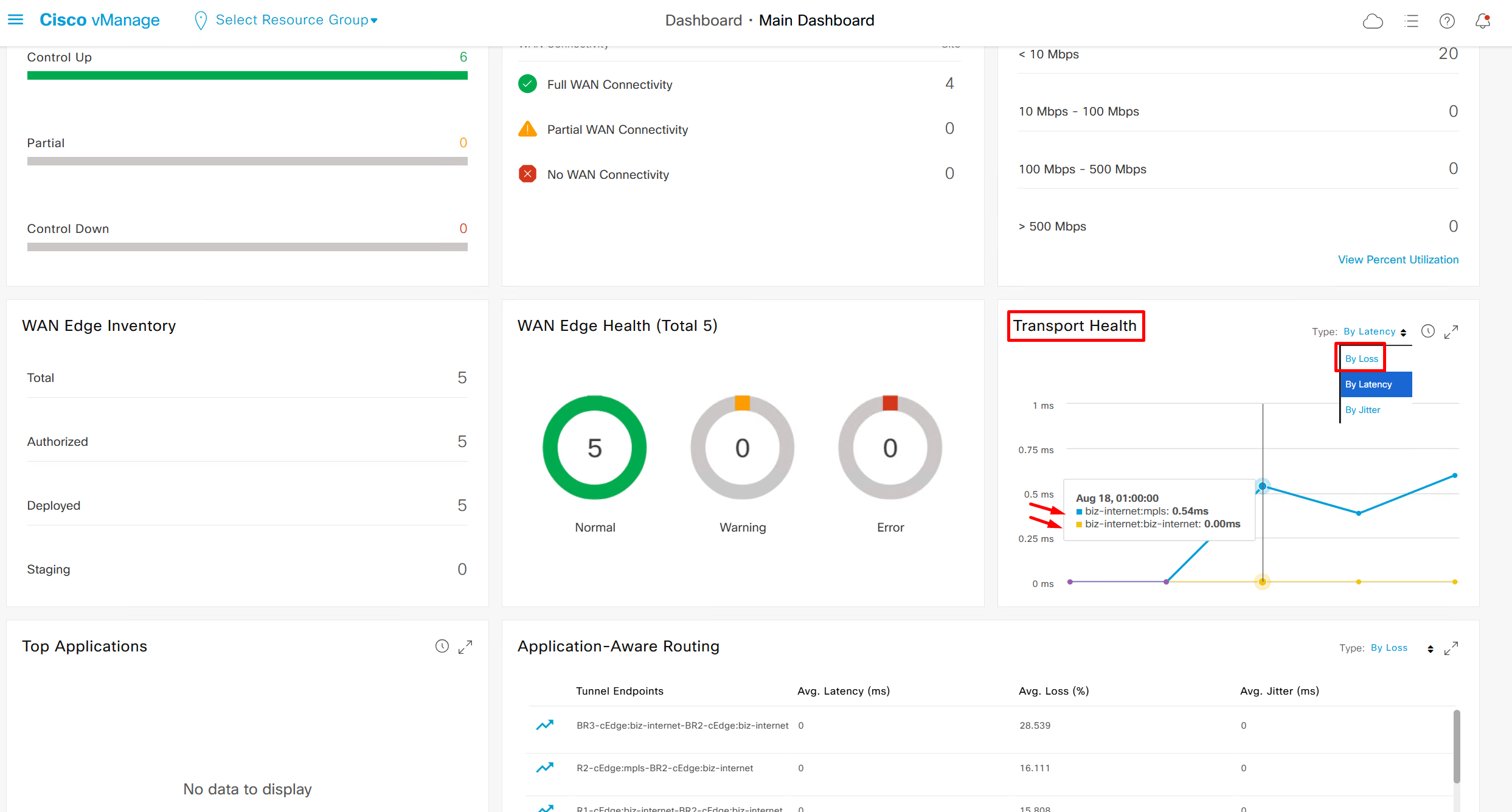
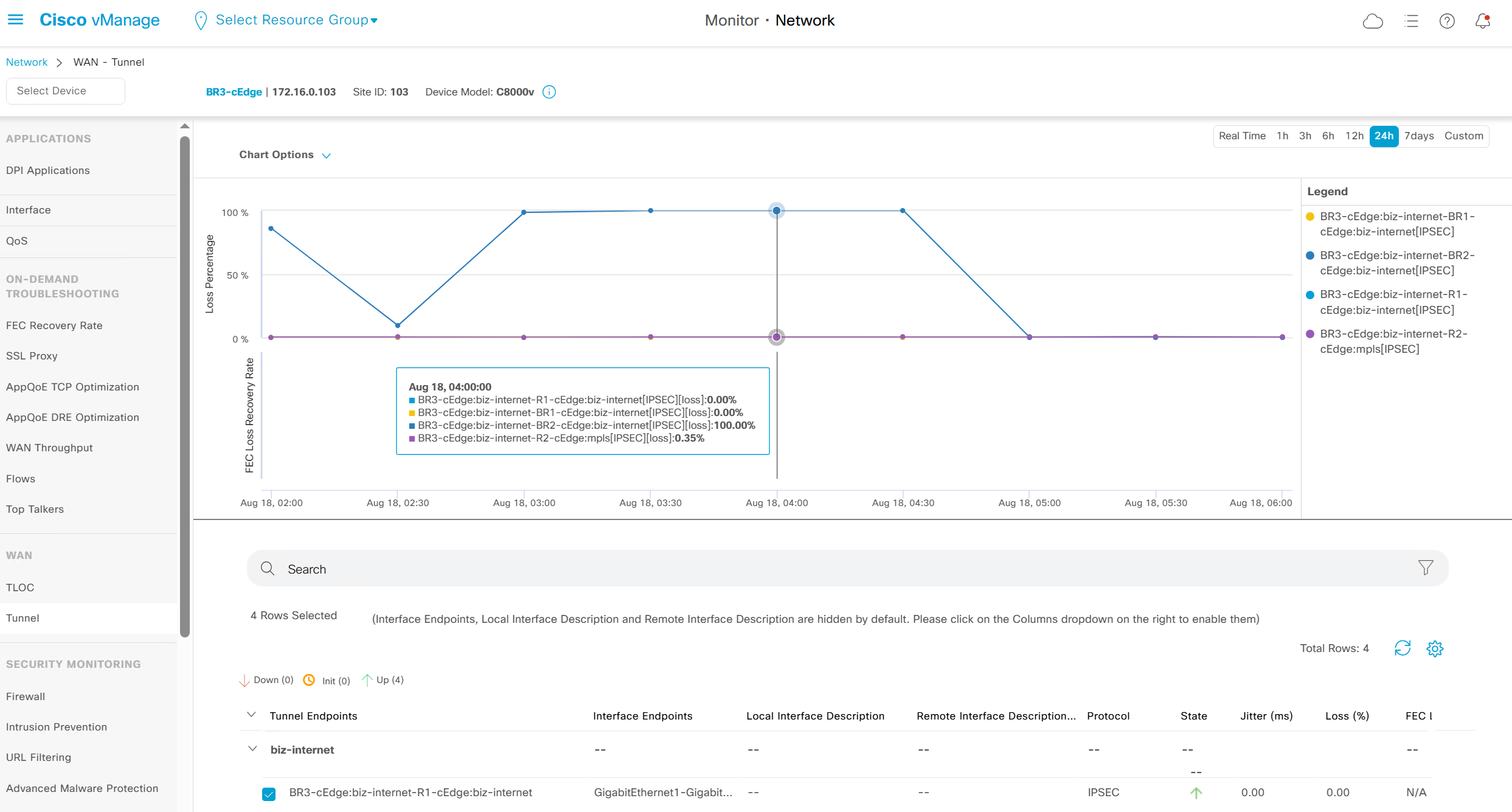
This transport health is of different transports to transports and by loss by default

We can see that these are BFD stats telling us that BR3-cEdge (branch 3) to BR2-cEdge (branch 2) there is Avg Loss of 28.539 %, this is per connection as compared to color to color stats shown in “Transport Health”
It is displayed by loss by default
Monitor > Geography shows geographical location of our sites / edges
for now because we have not assigned any coordinates, it shows as blank
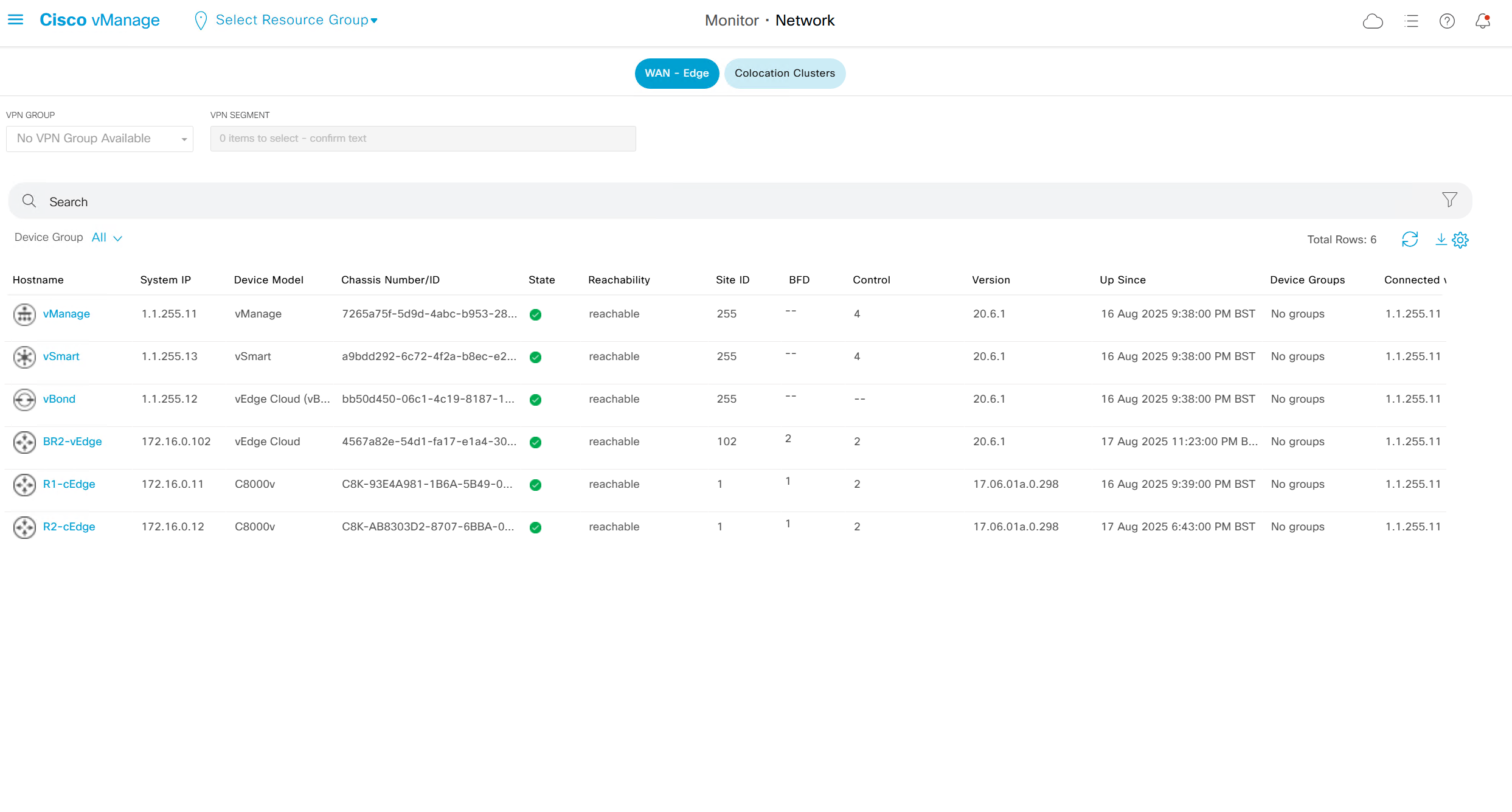
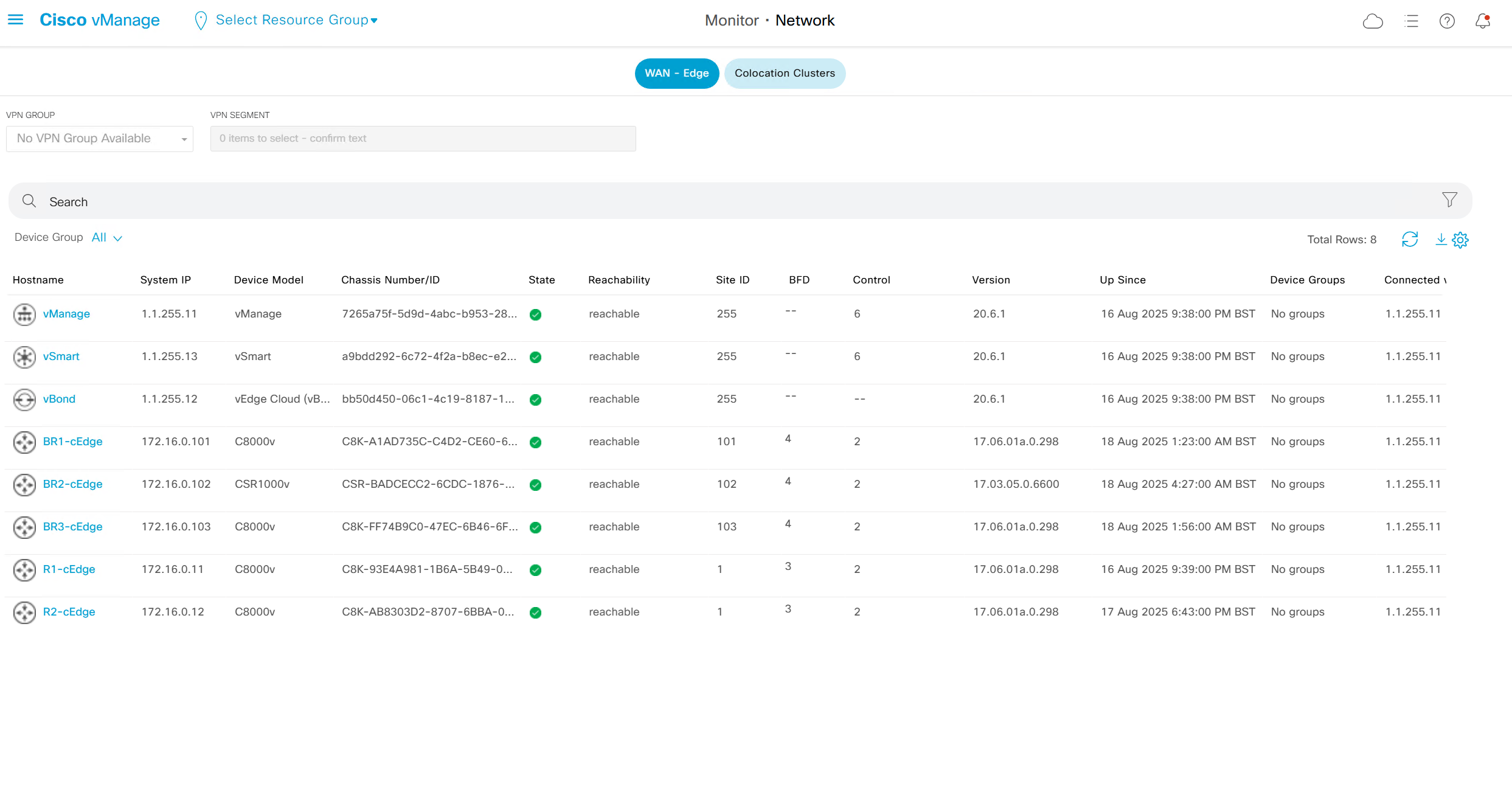
Monitor > Network
shows all network devices and all of their information such as names, states, system ip, reachability, site id, bfd tunnels, control DTLS sessions, version, up since, device groups etc
Clicking on one of the devices takes us into the device
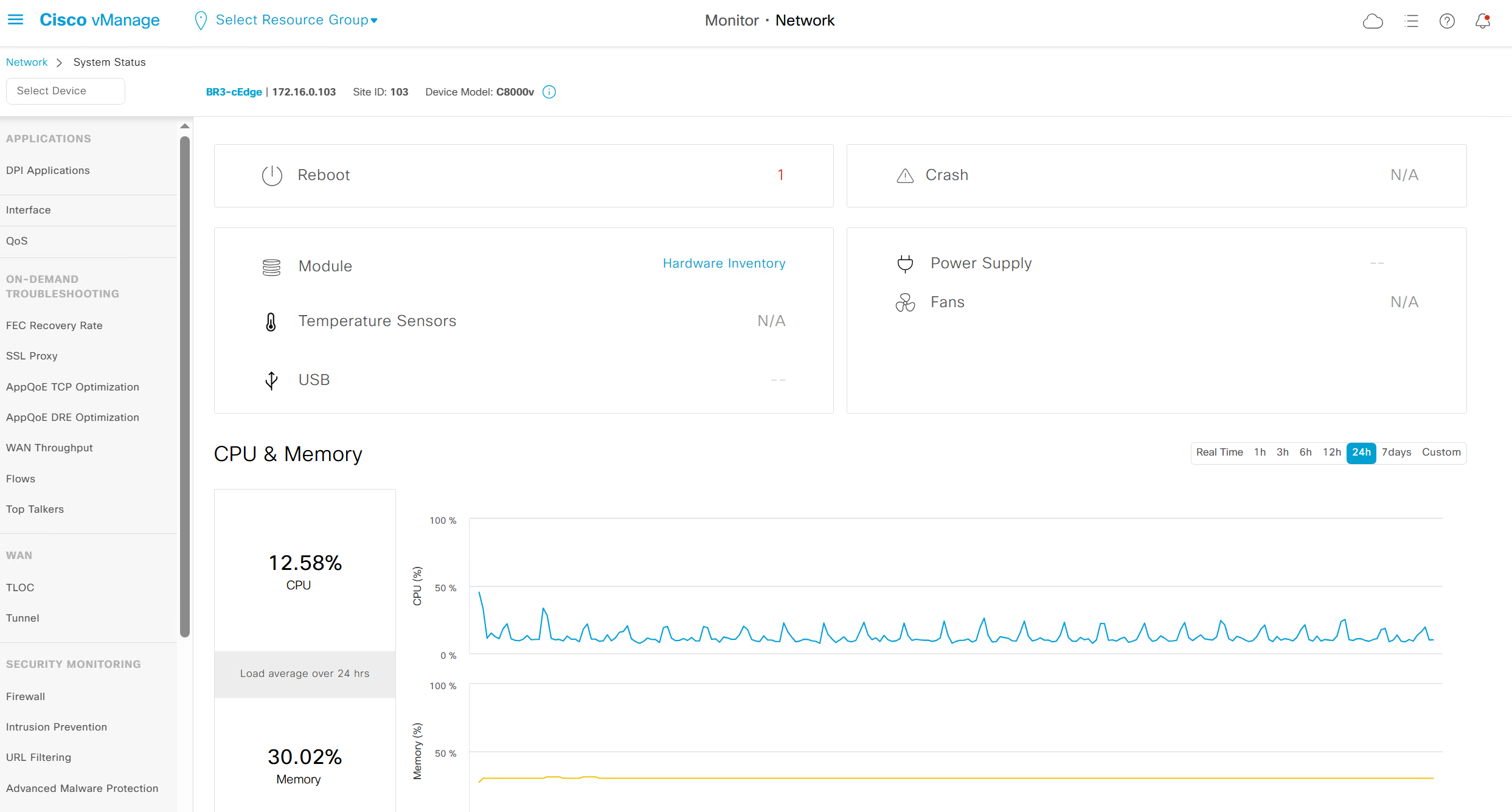
we can see hardware inventory, power supply and fan info – reboot menu – CPU and memory
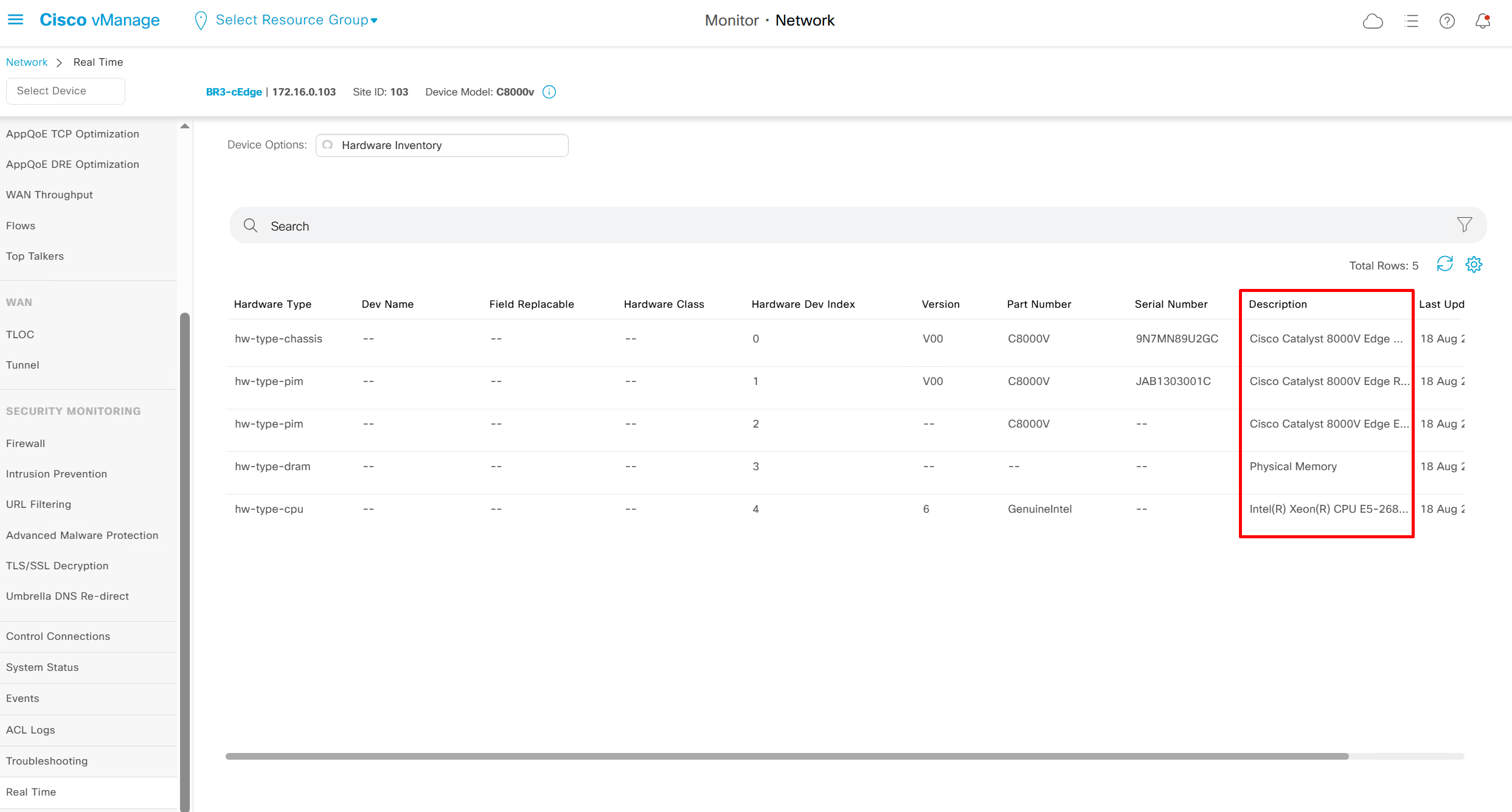
Hardware Inventory
DPI Applications – when traffic passes through router, traffic discovered applications show here
it is not showing as no traffic is passing through router
Interface shows all stats on interfaces

This is good place to check the admin / operational status of the interfaces
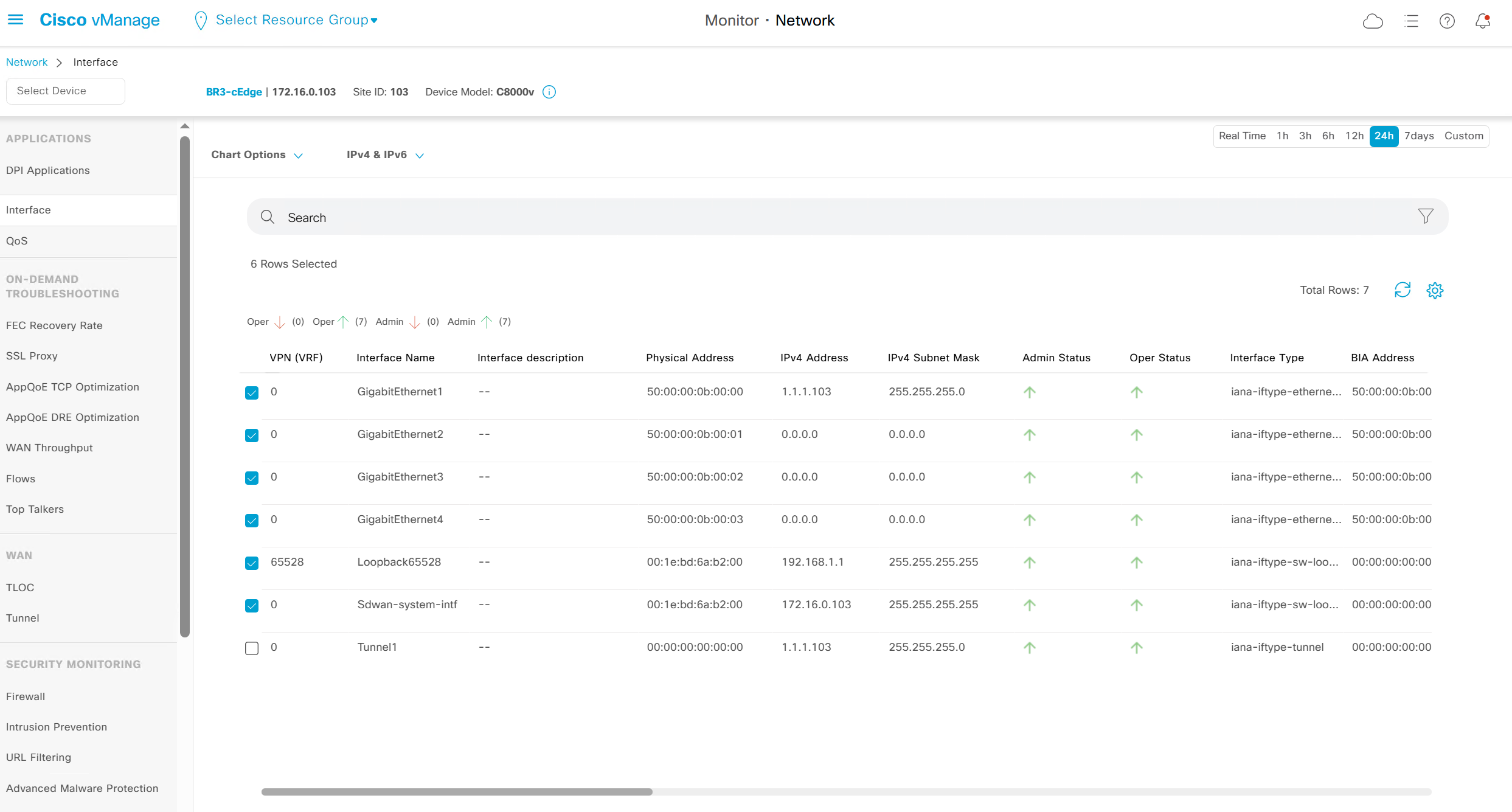
WAN throughput, Flows and Top Talkers as there are TCP optimisation features and are only available on hardware routers
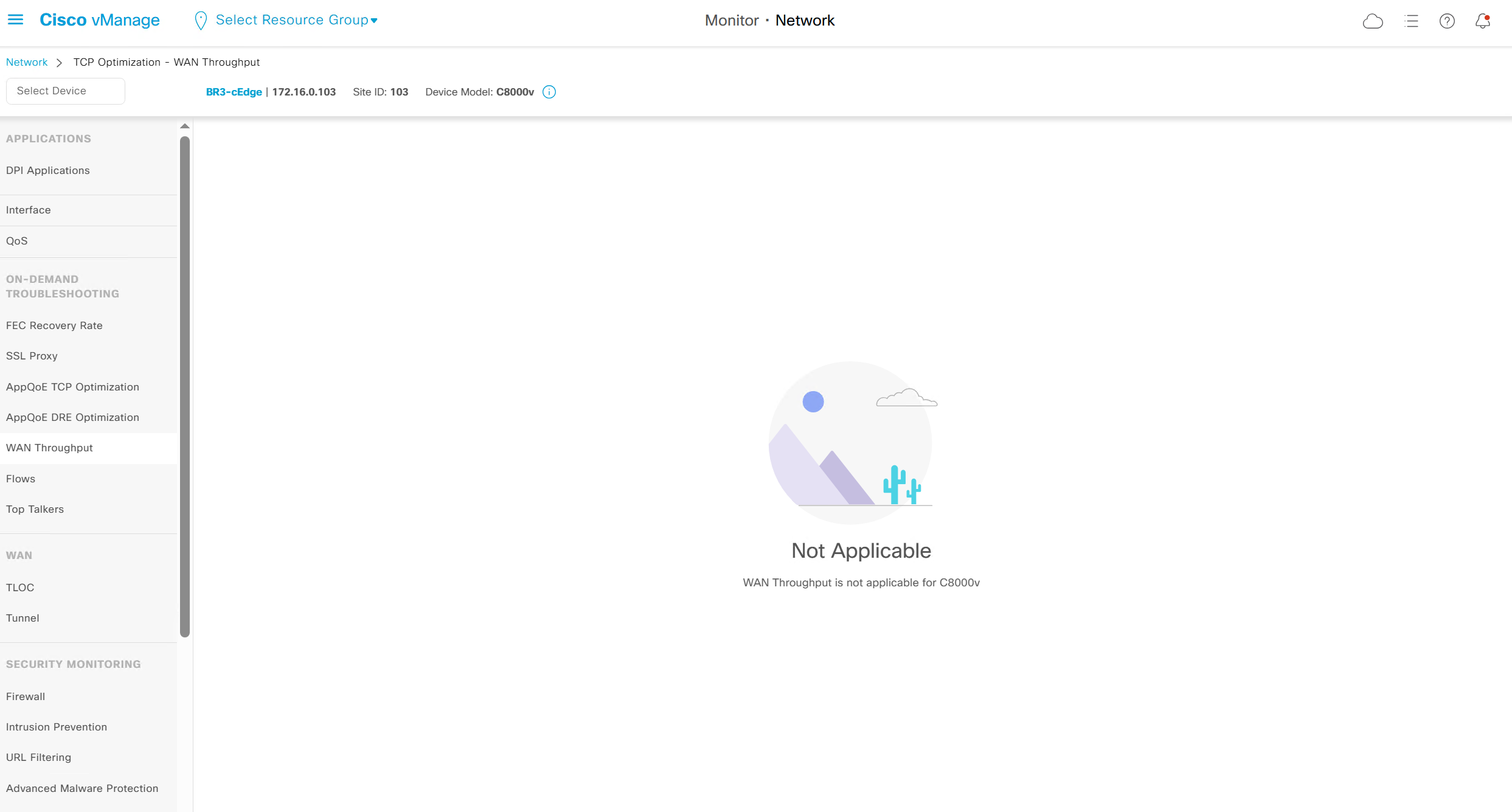
It says “WAN Throughput is not applicable for C8000v”
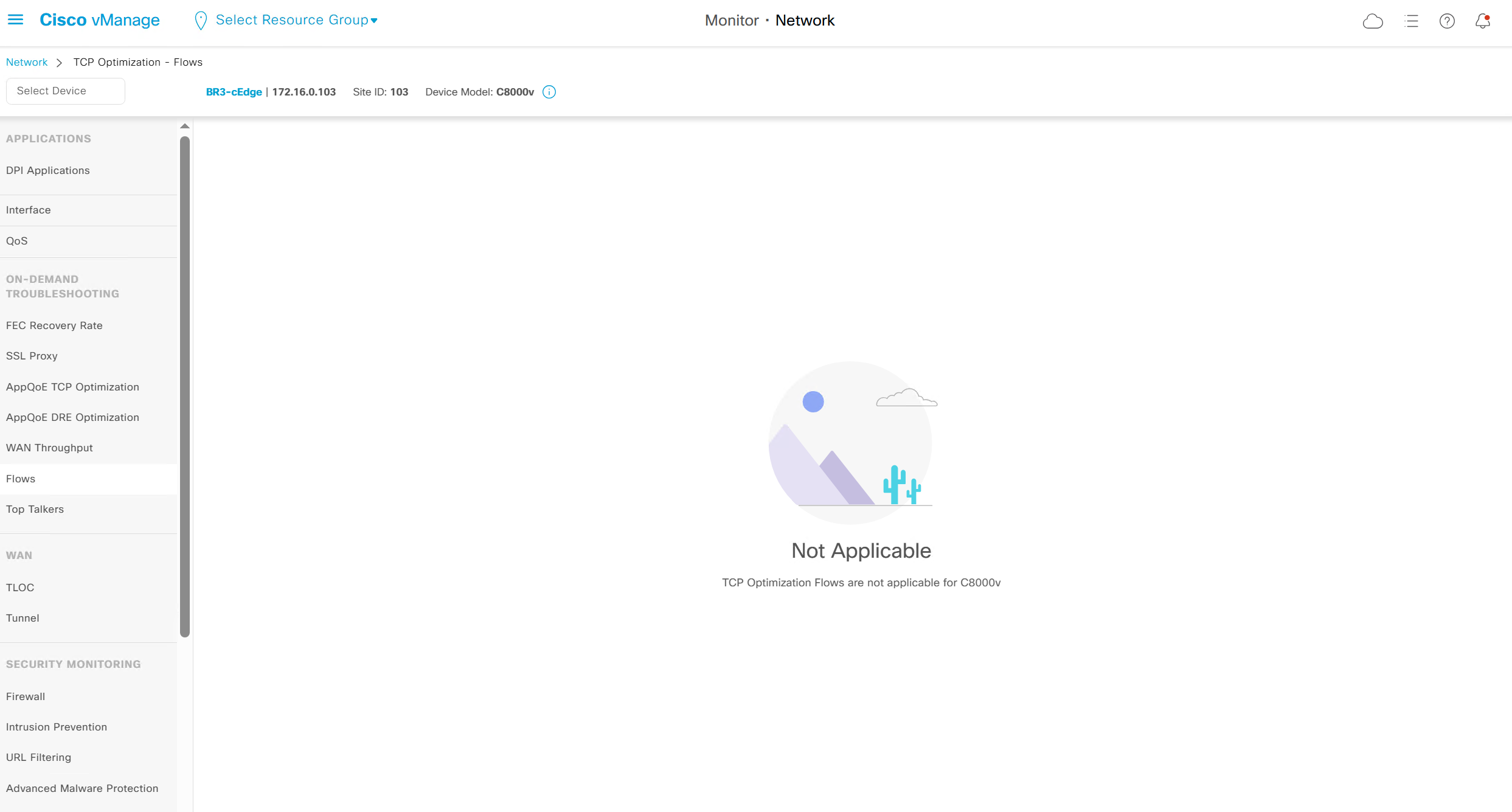
It says “TCP Optimization Flows are not applicable for C8000v”
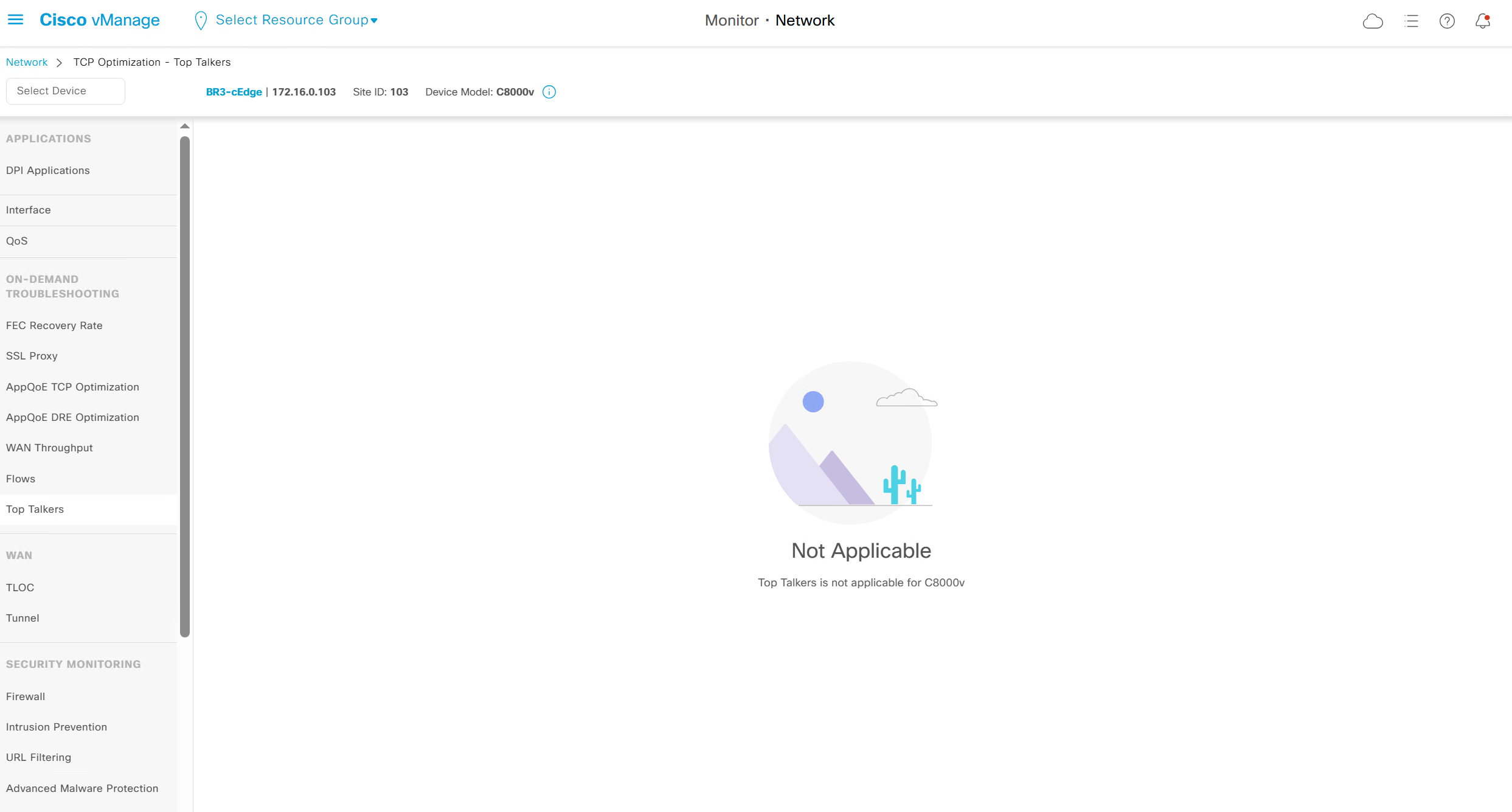
It says “Top Talkers is not applicable for C8000v”
WAN > TLOC

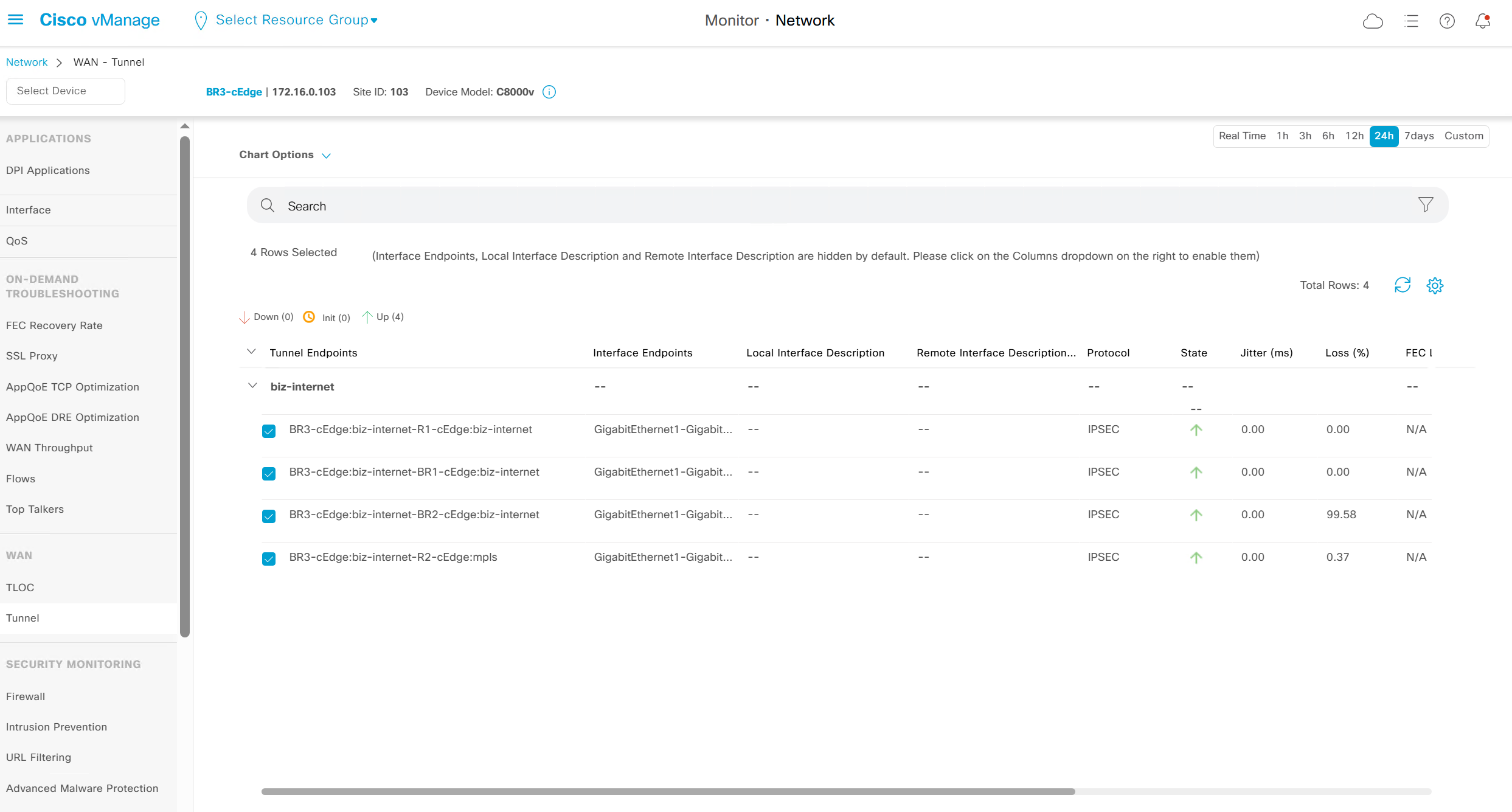
WAN > Tunnels
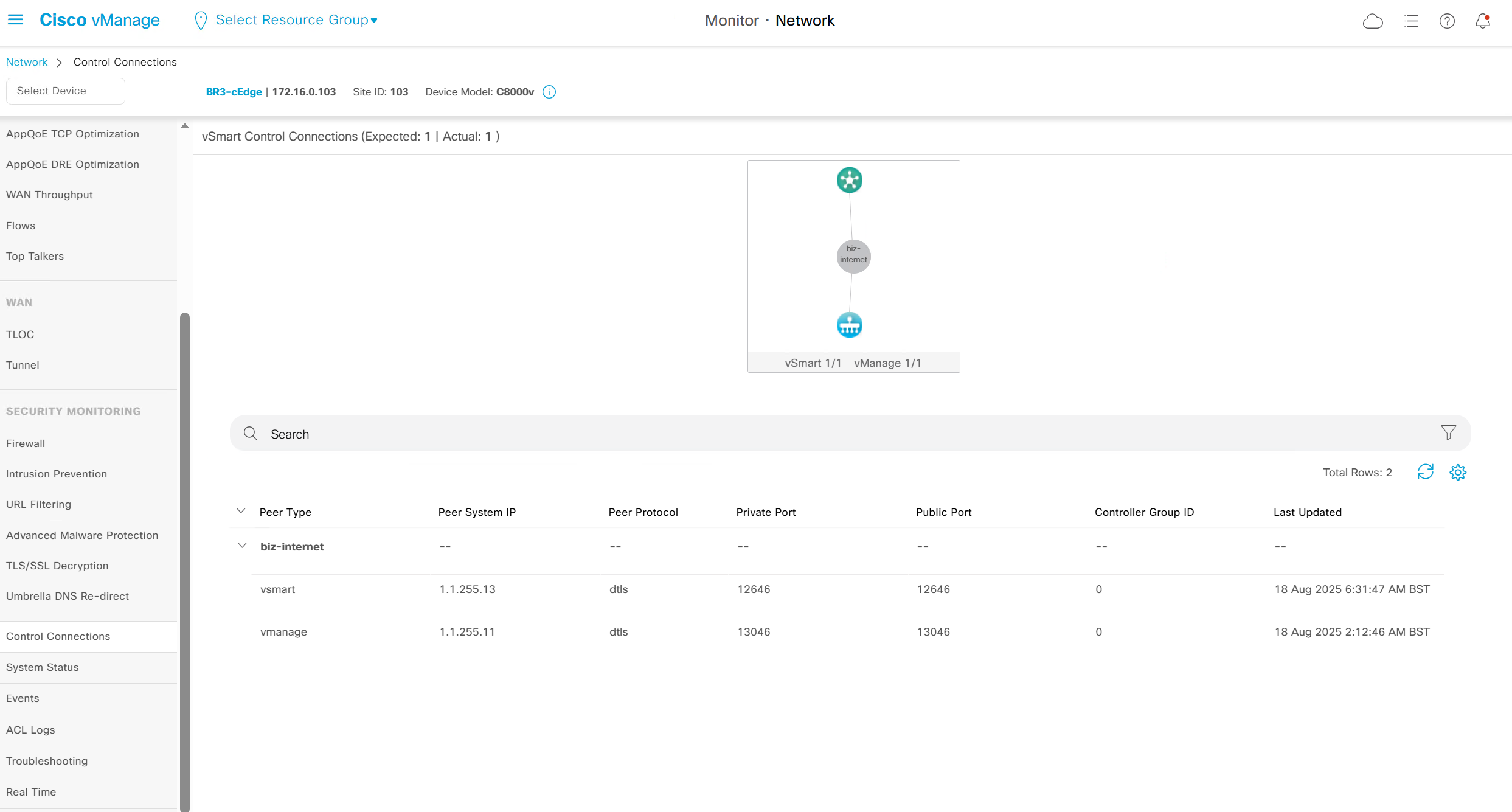
Control Connections
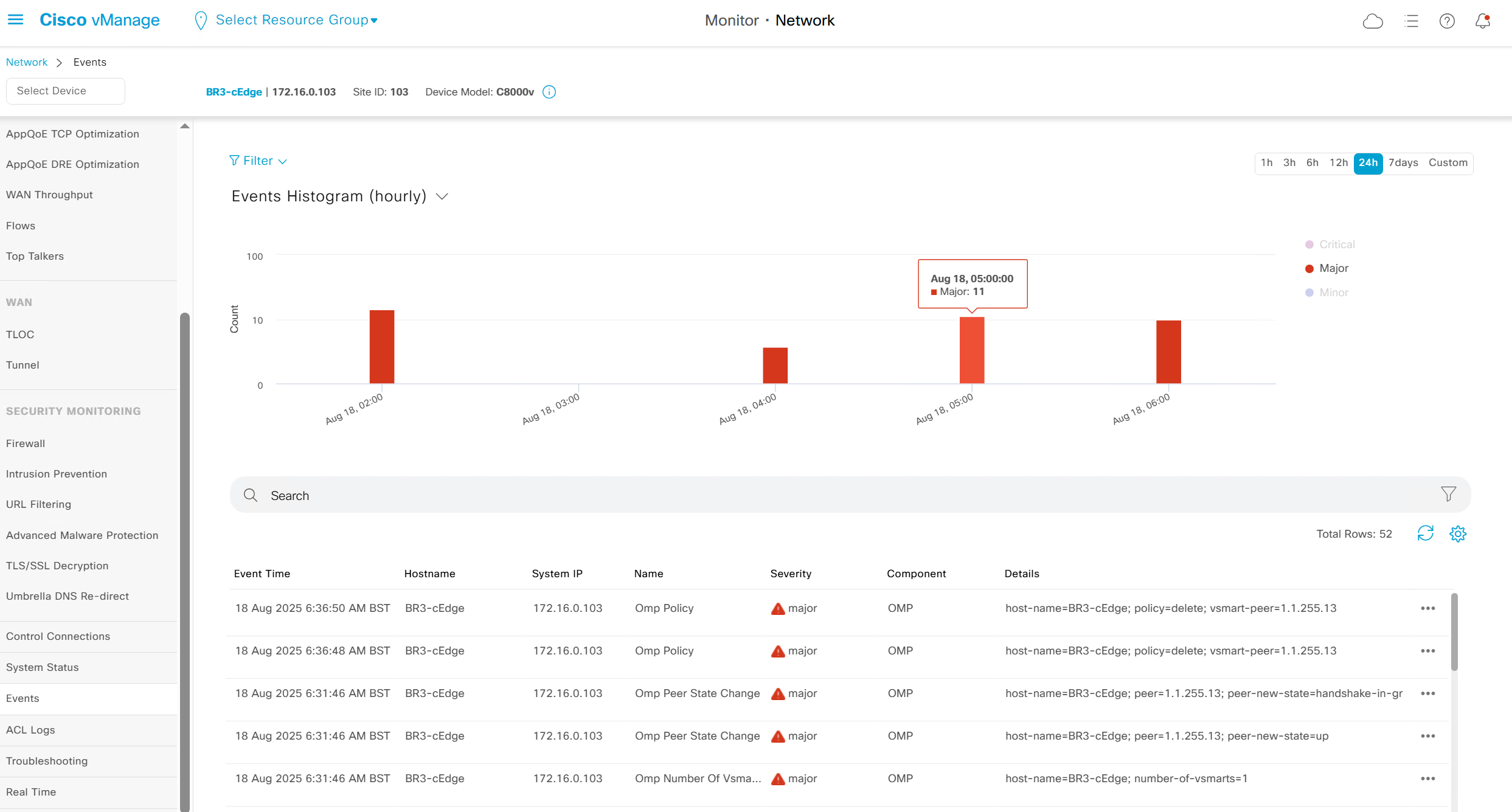
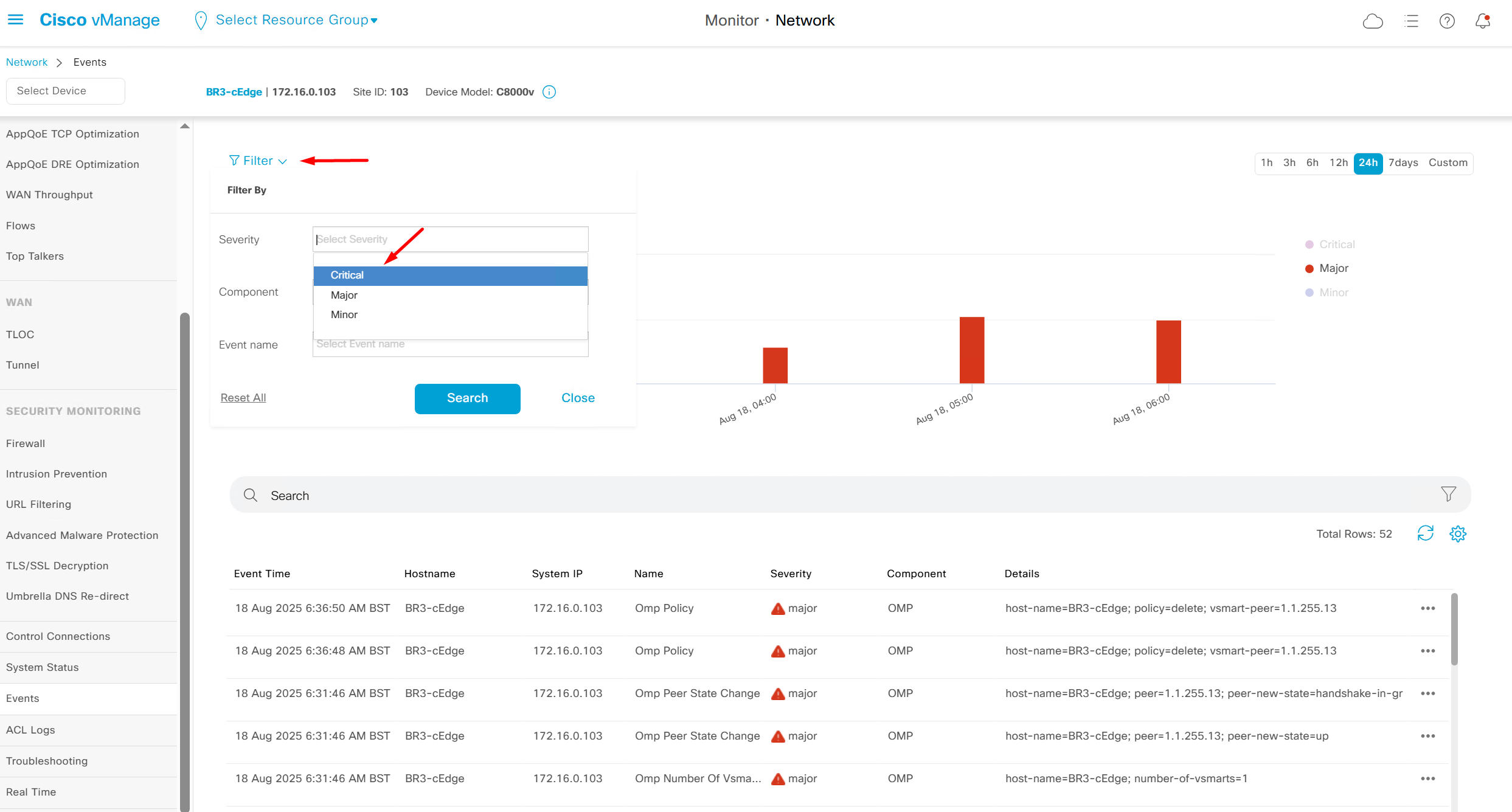
Events
Troubleshooting
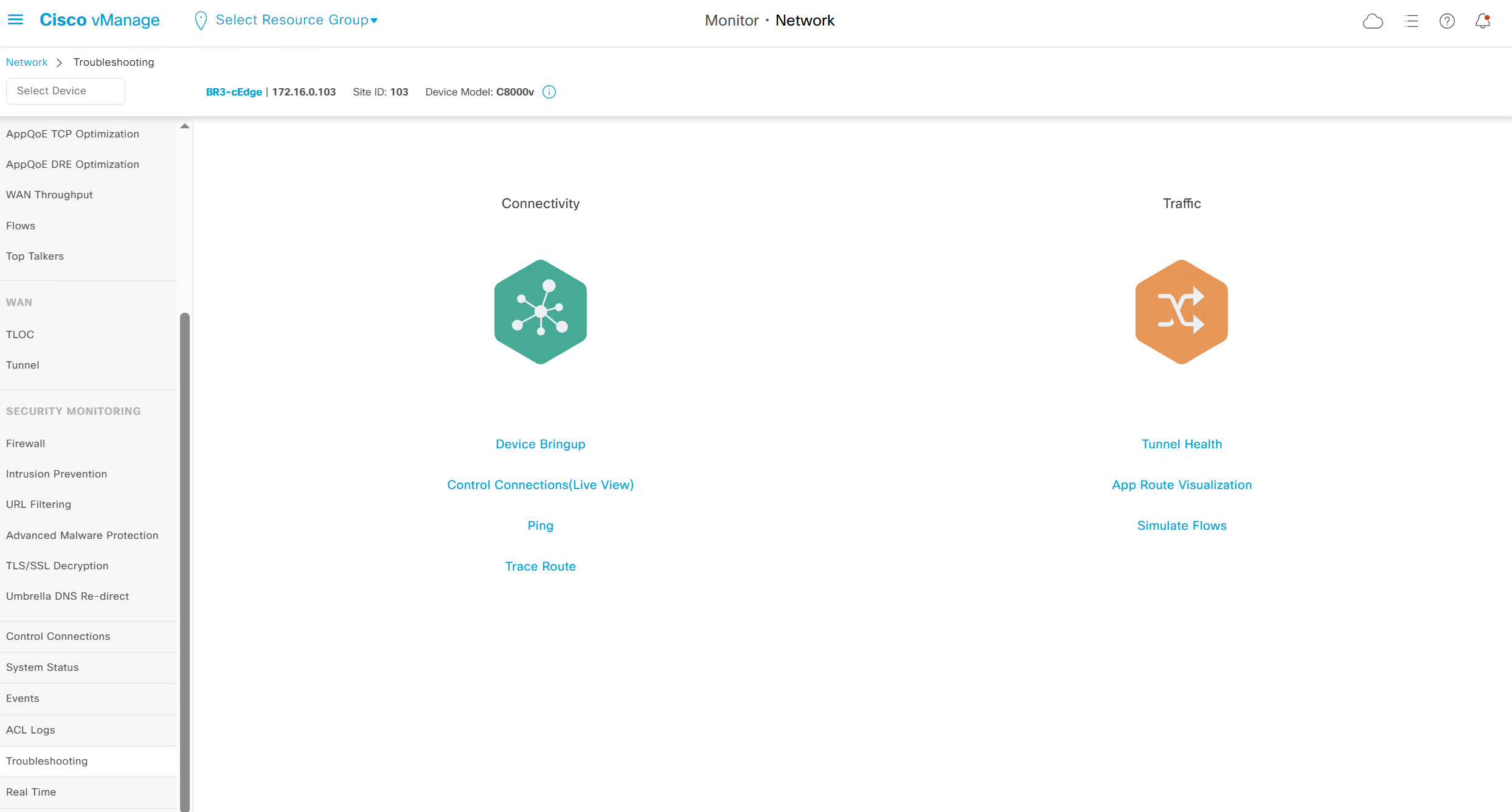
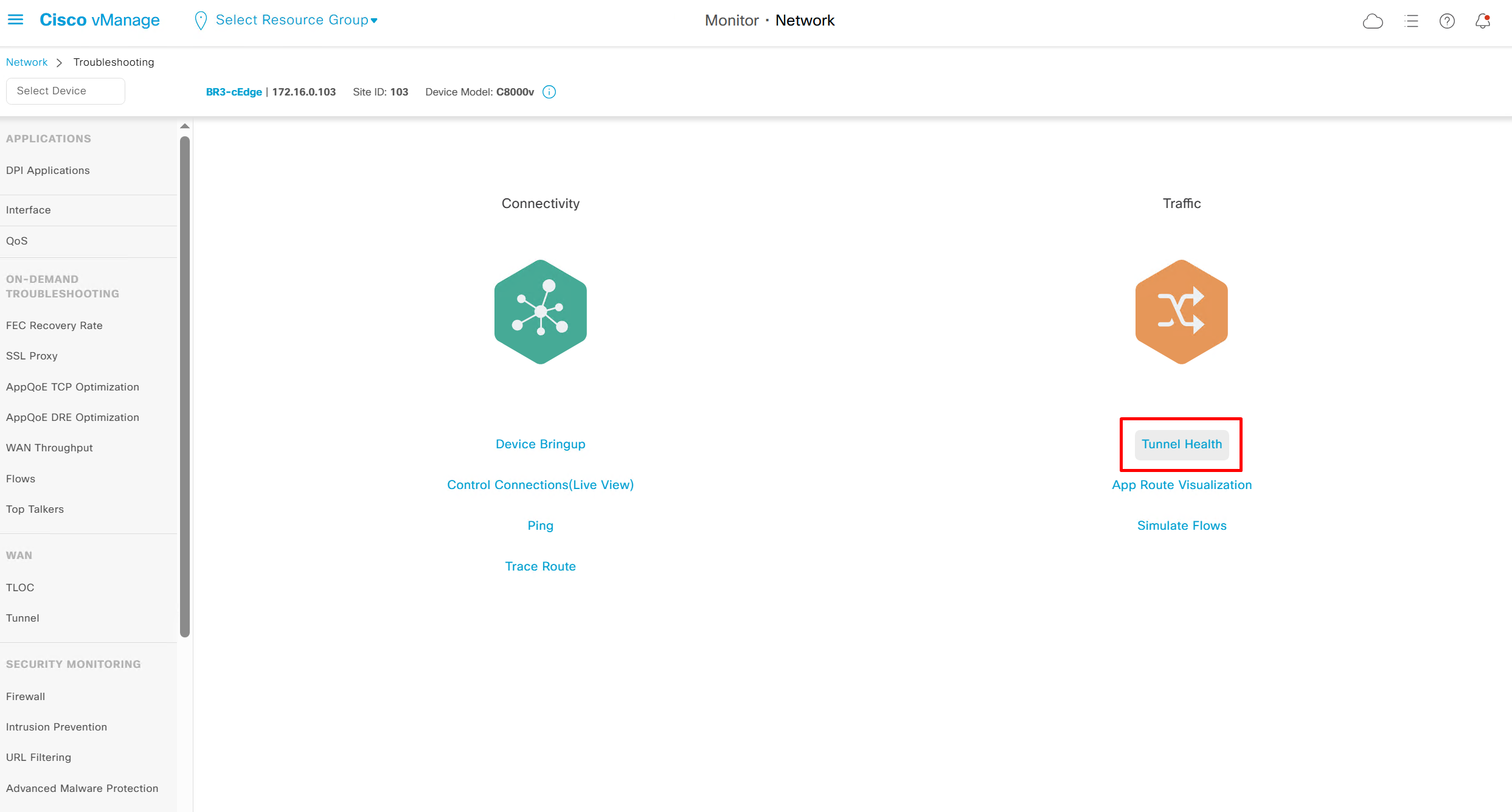
Tunnel Health
Good for troubleshooting per tunnel health
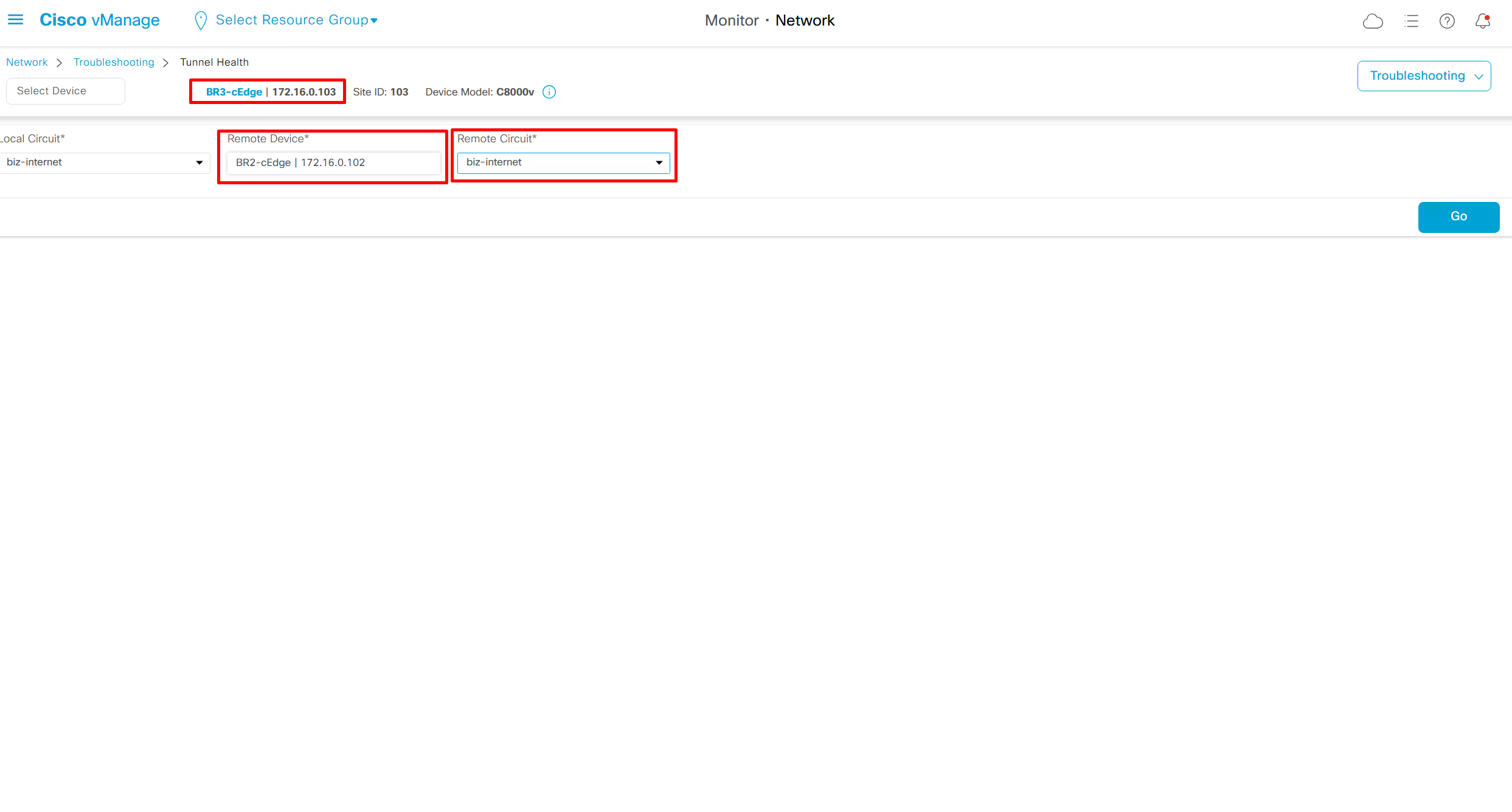
Per tunnel health check for loss, latency and octets or bytes

App route visualisation
DPI is Deep Packet Inspection
This shows applications stats from site to site as previously we say per tunnel health, this options allows us to check beyond tunnels and applications stats after the tunnel
No filter option will show us stats for all traffic
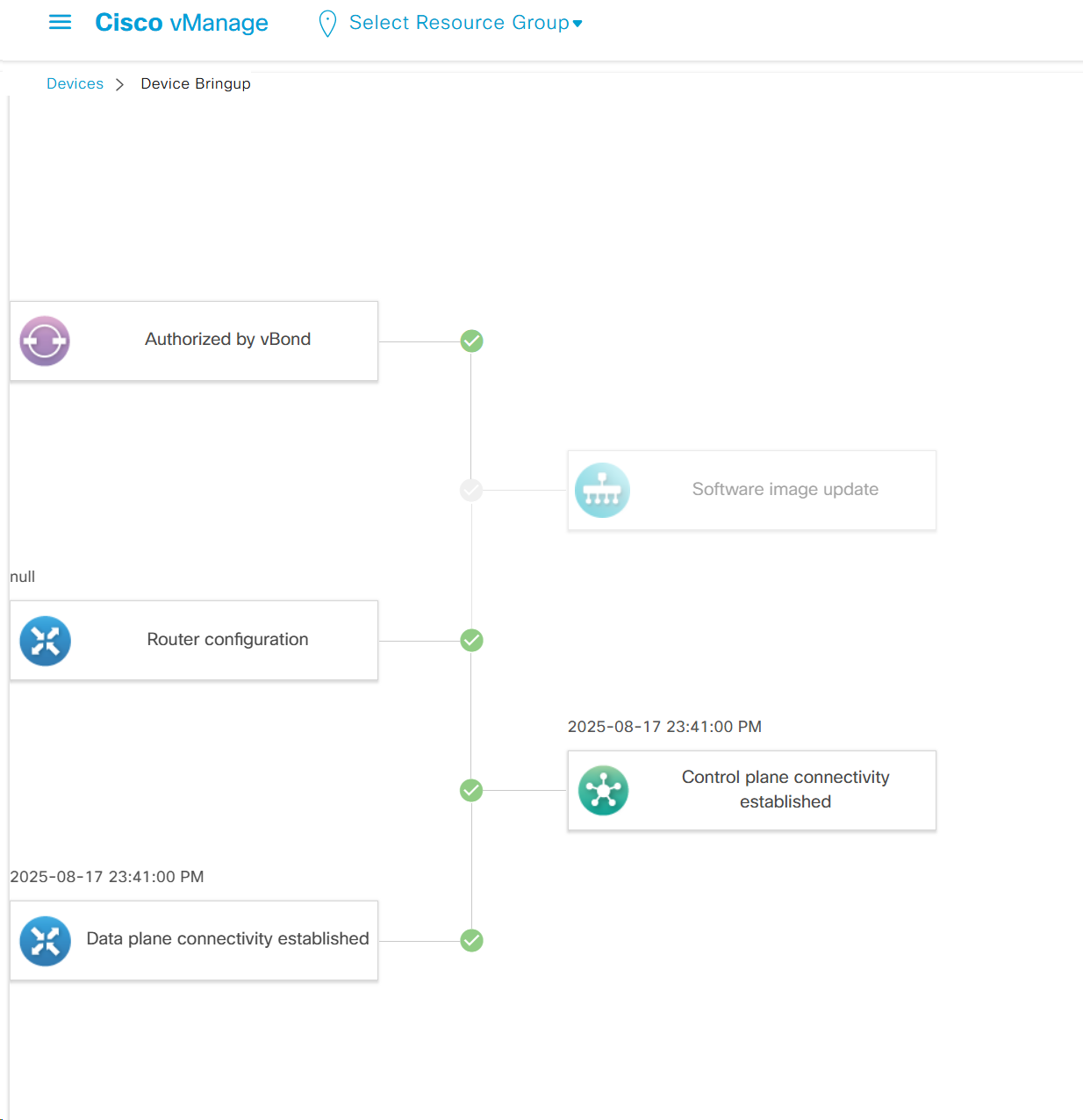
Troubleshooting

It shows us that
1. edge was authorized by vbond
2. Software image update
3. Router configuration
4. Control plane connectivity established
5. Data plane connectivity established
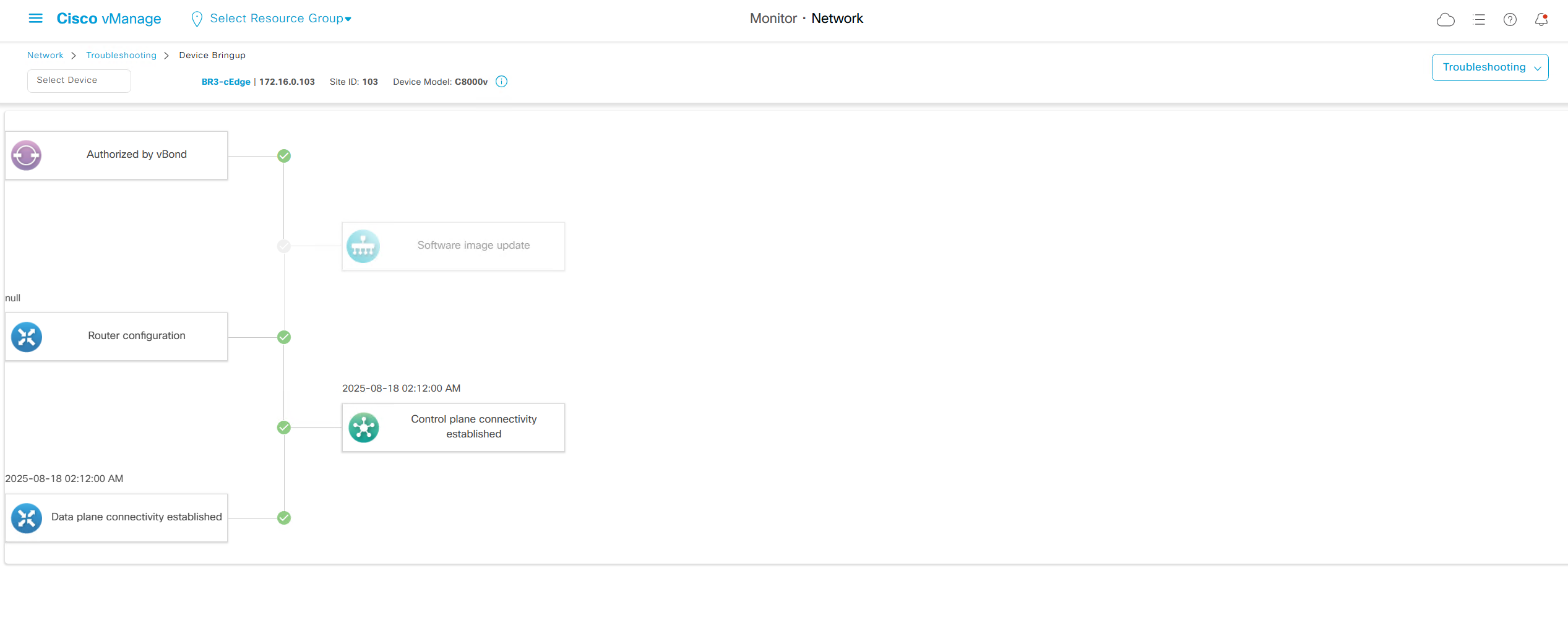
in case edge is behind the firewall and firewall is blocking control plane connectivity

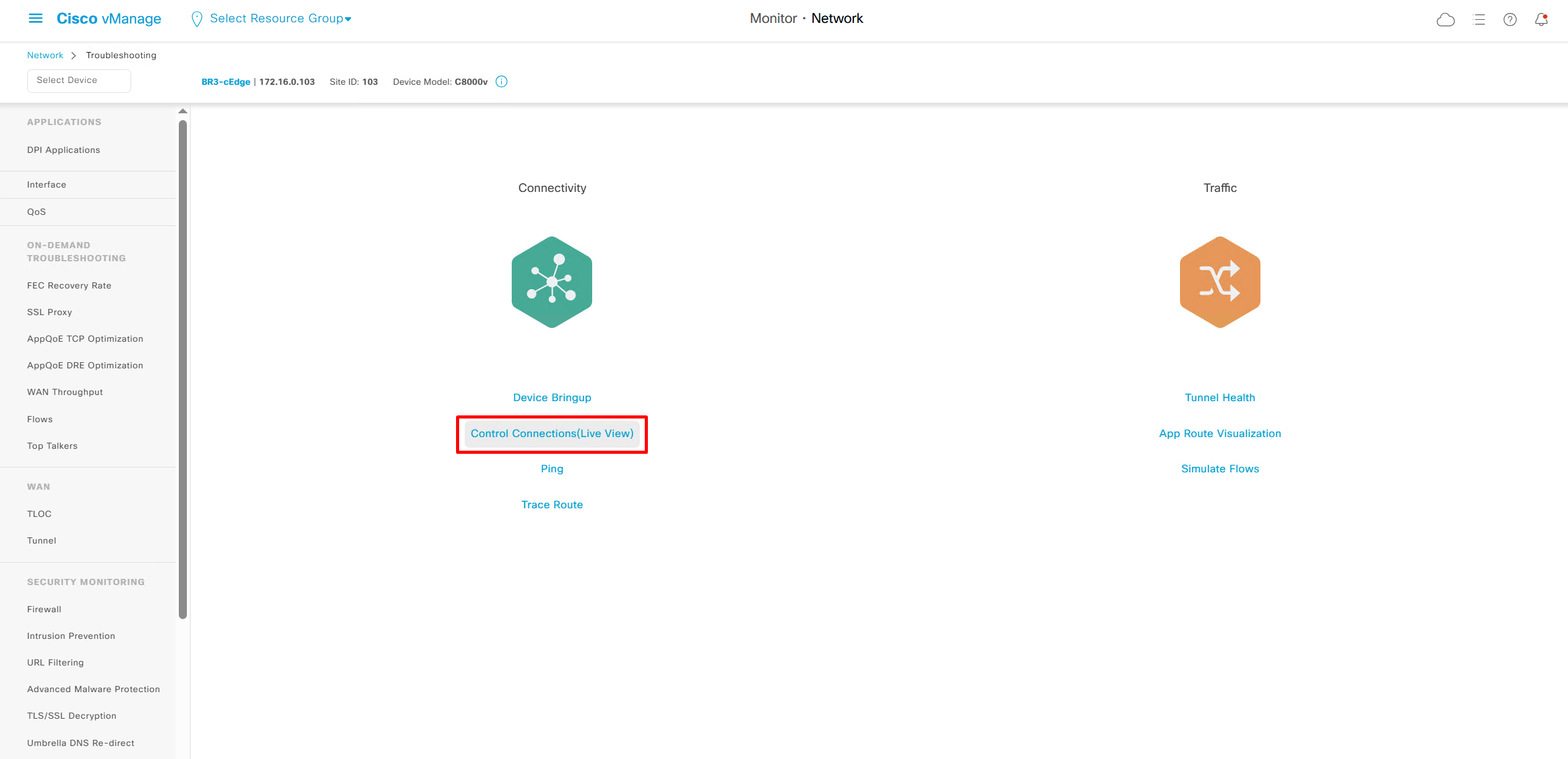
We also have option for ping and traceroute
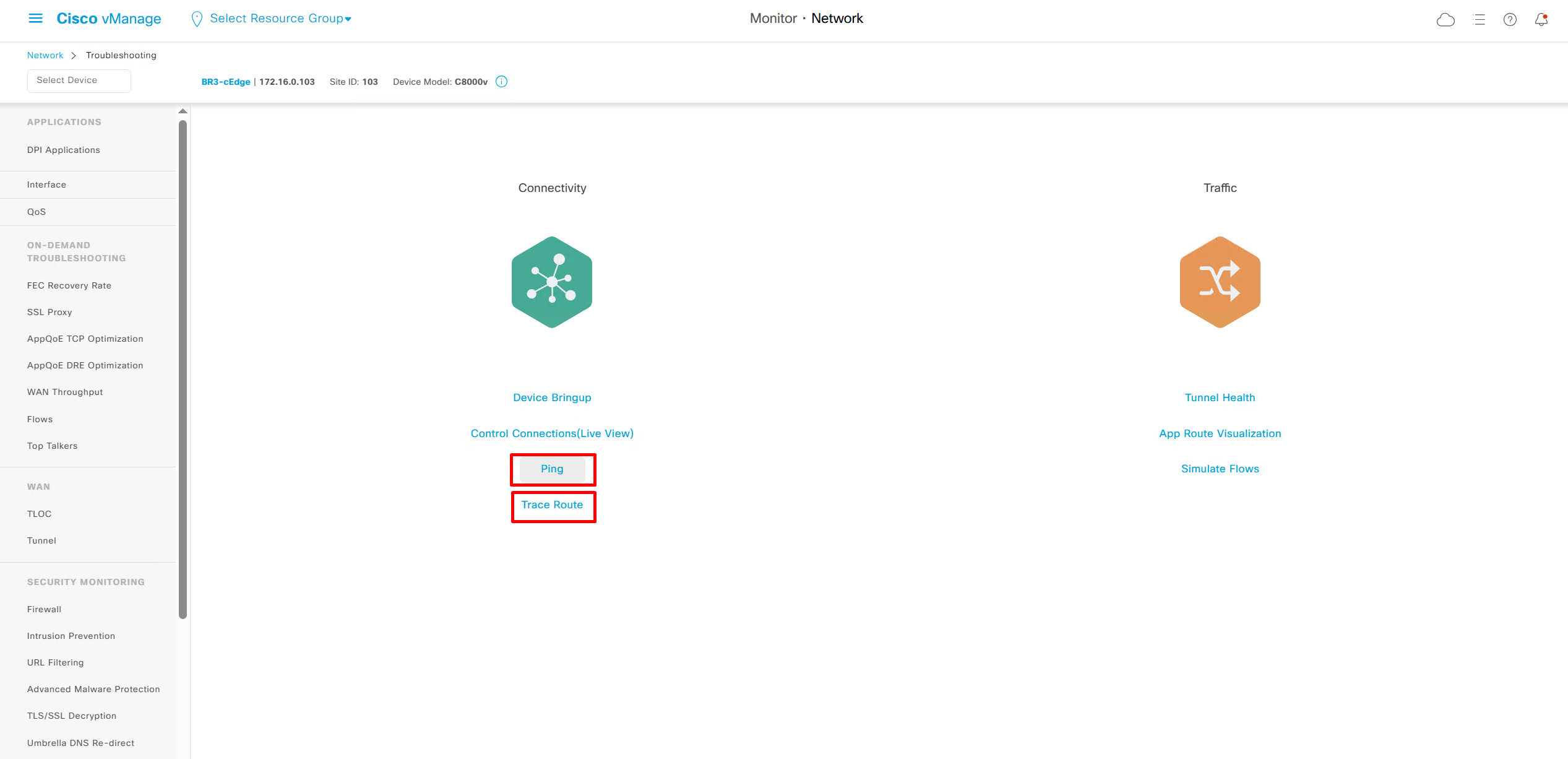
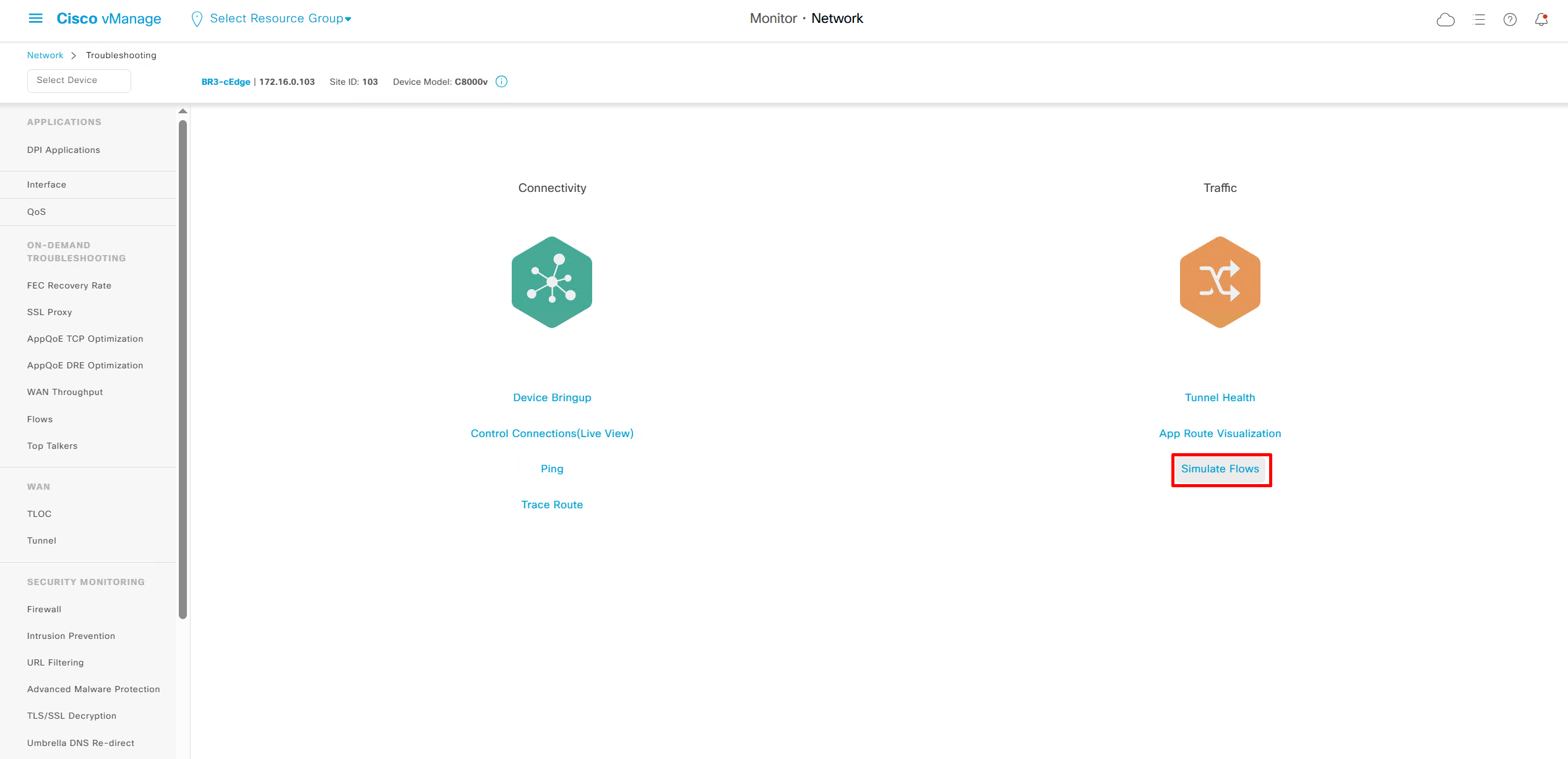
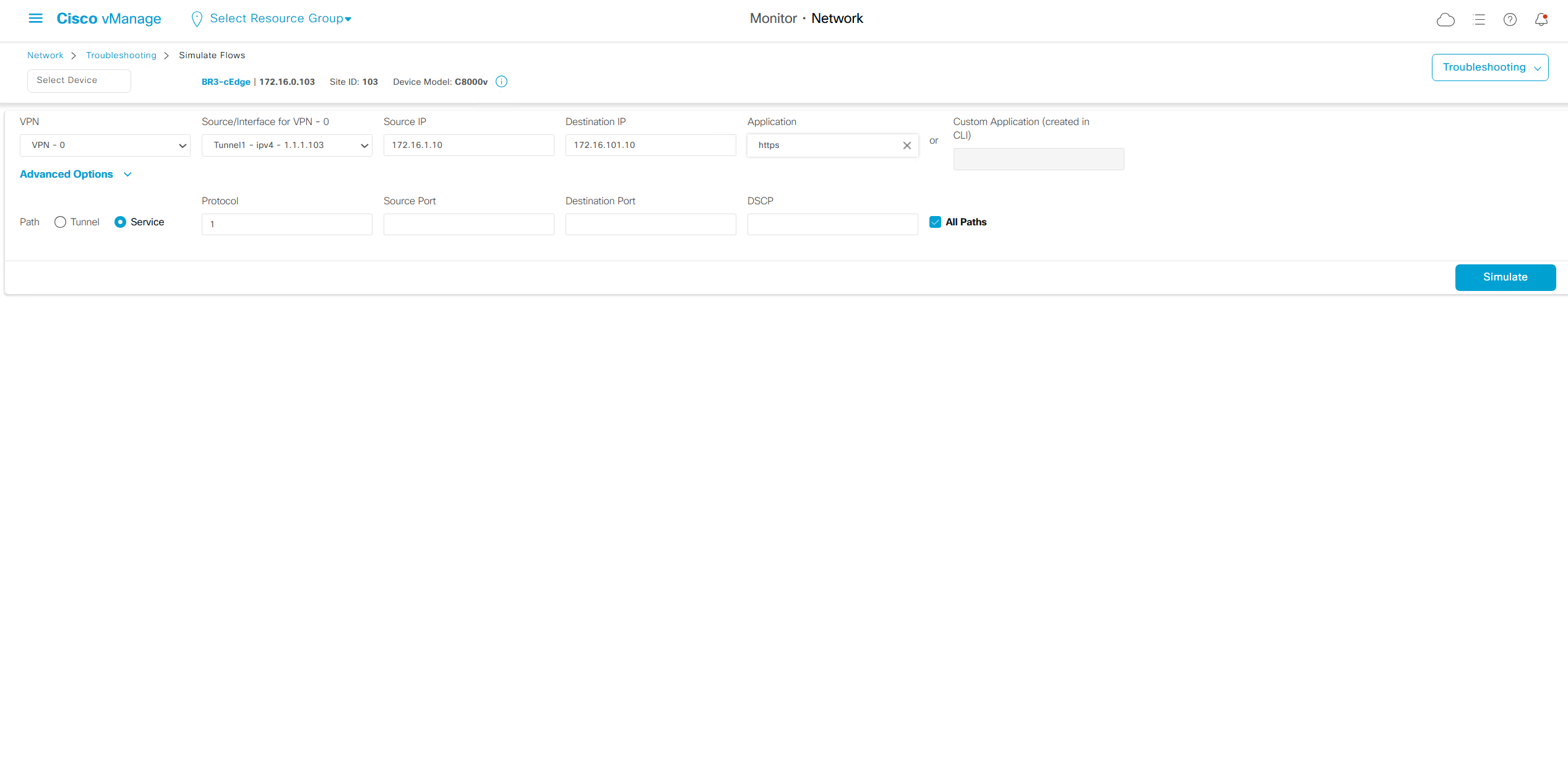
Simulate flow allows us to see how our applications will route and which TLOCs it will pass through
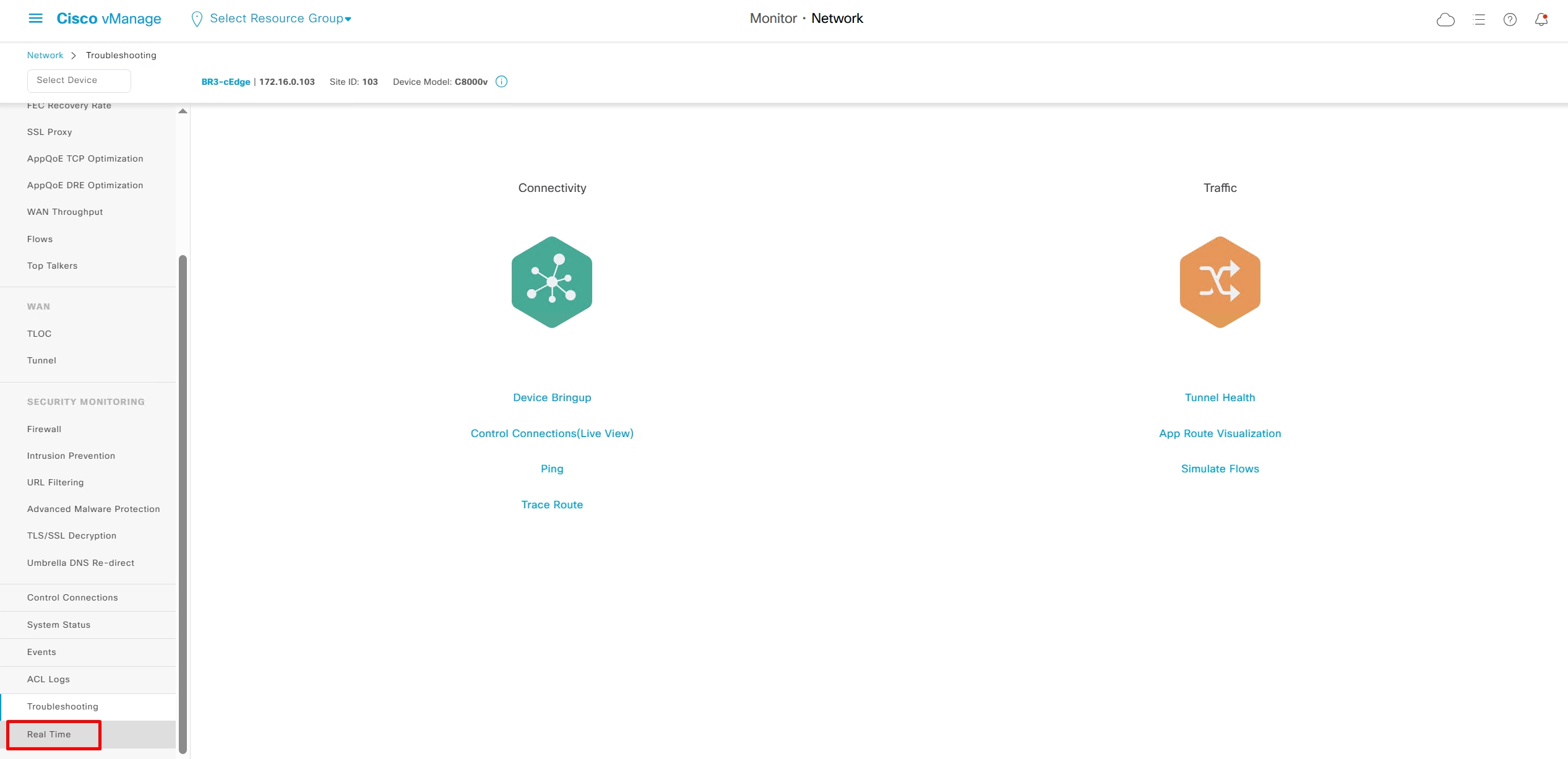
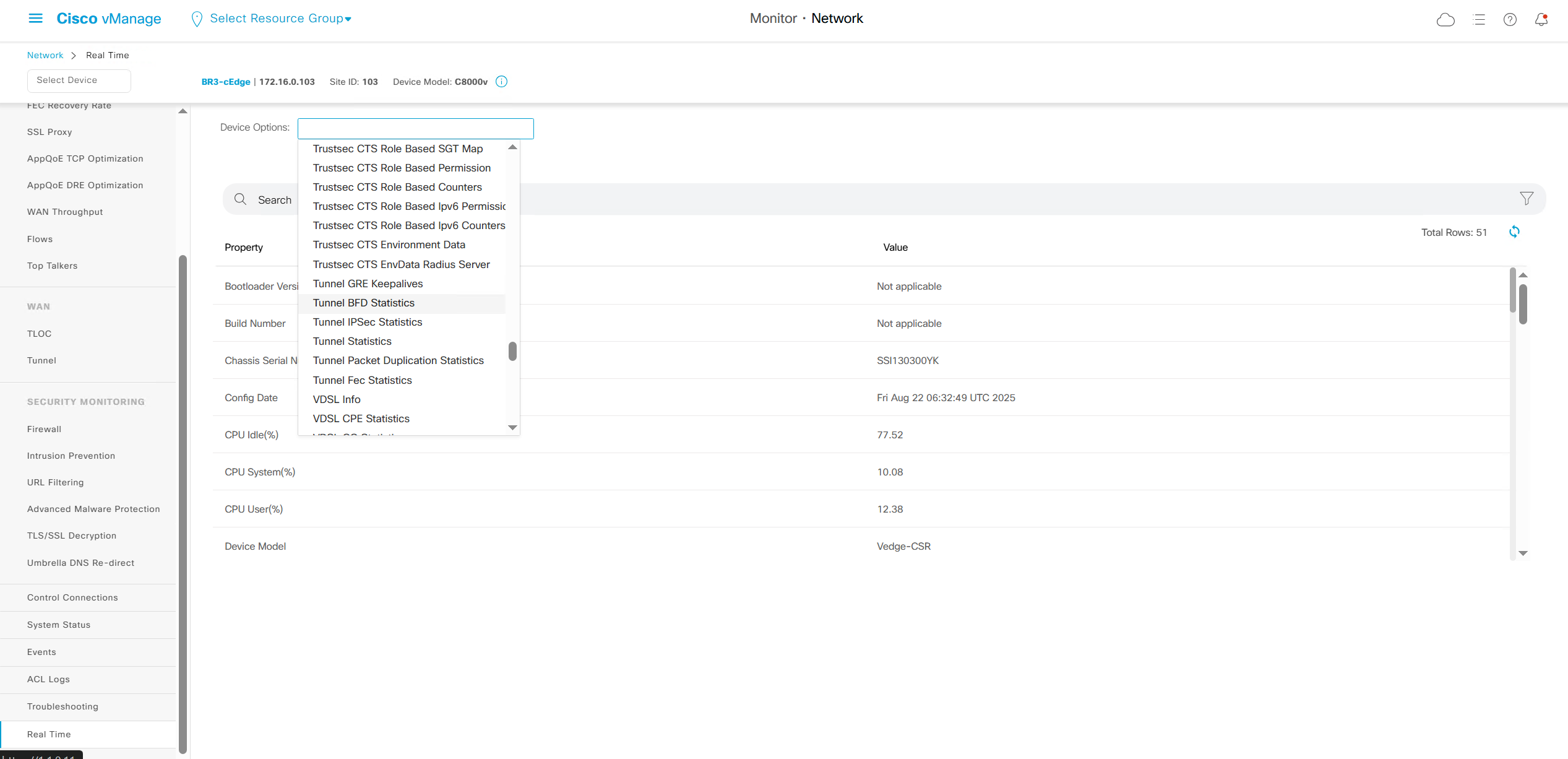
Real time shows us any information that we can see on command line also
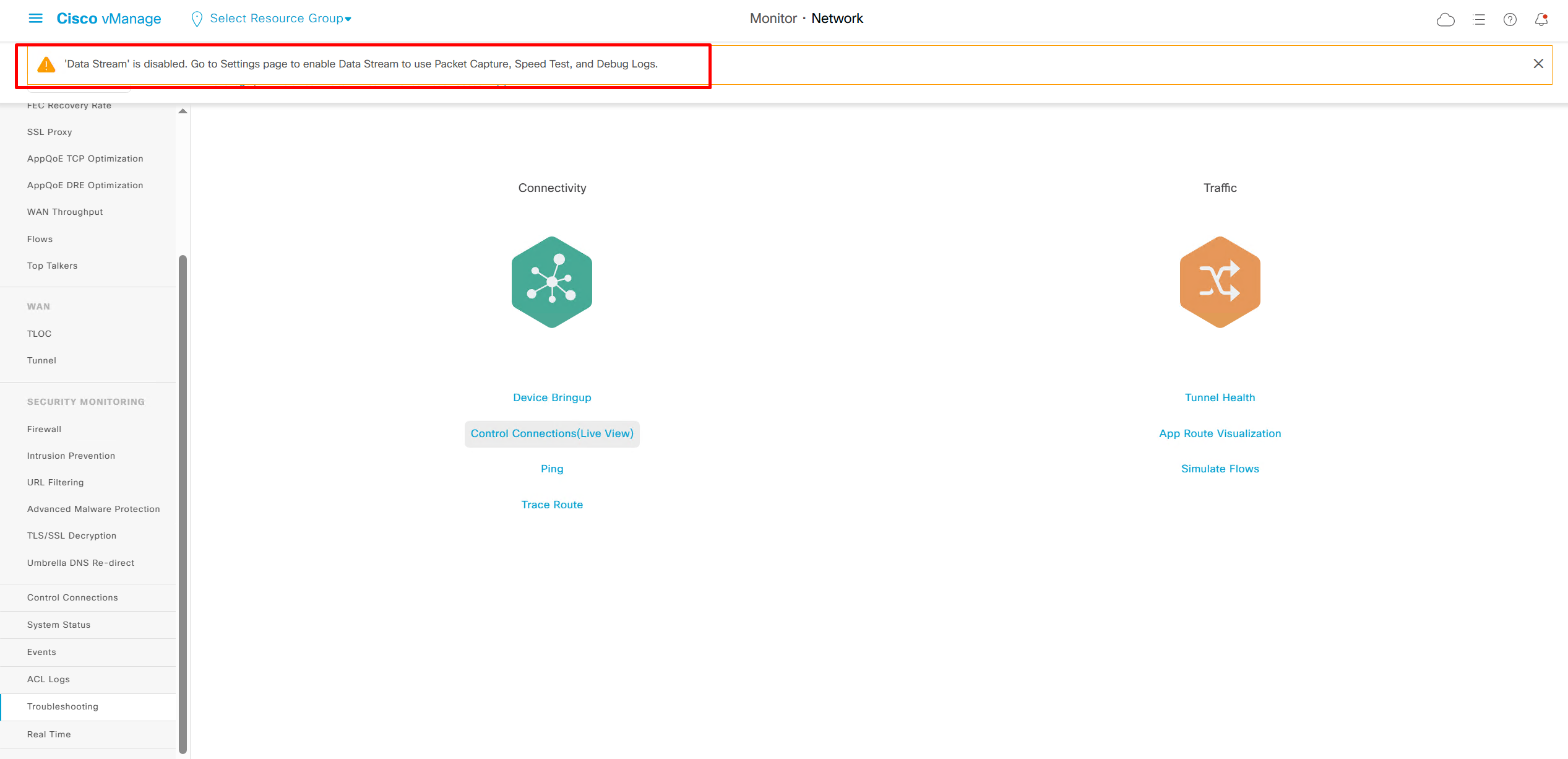
Some troubleshooting options are not available as we dont have Data stream enabled such as Packet Capture, Speed Test, and Debug Logs
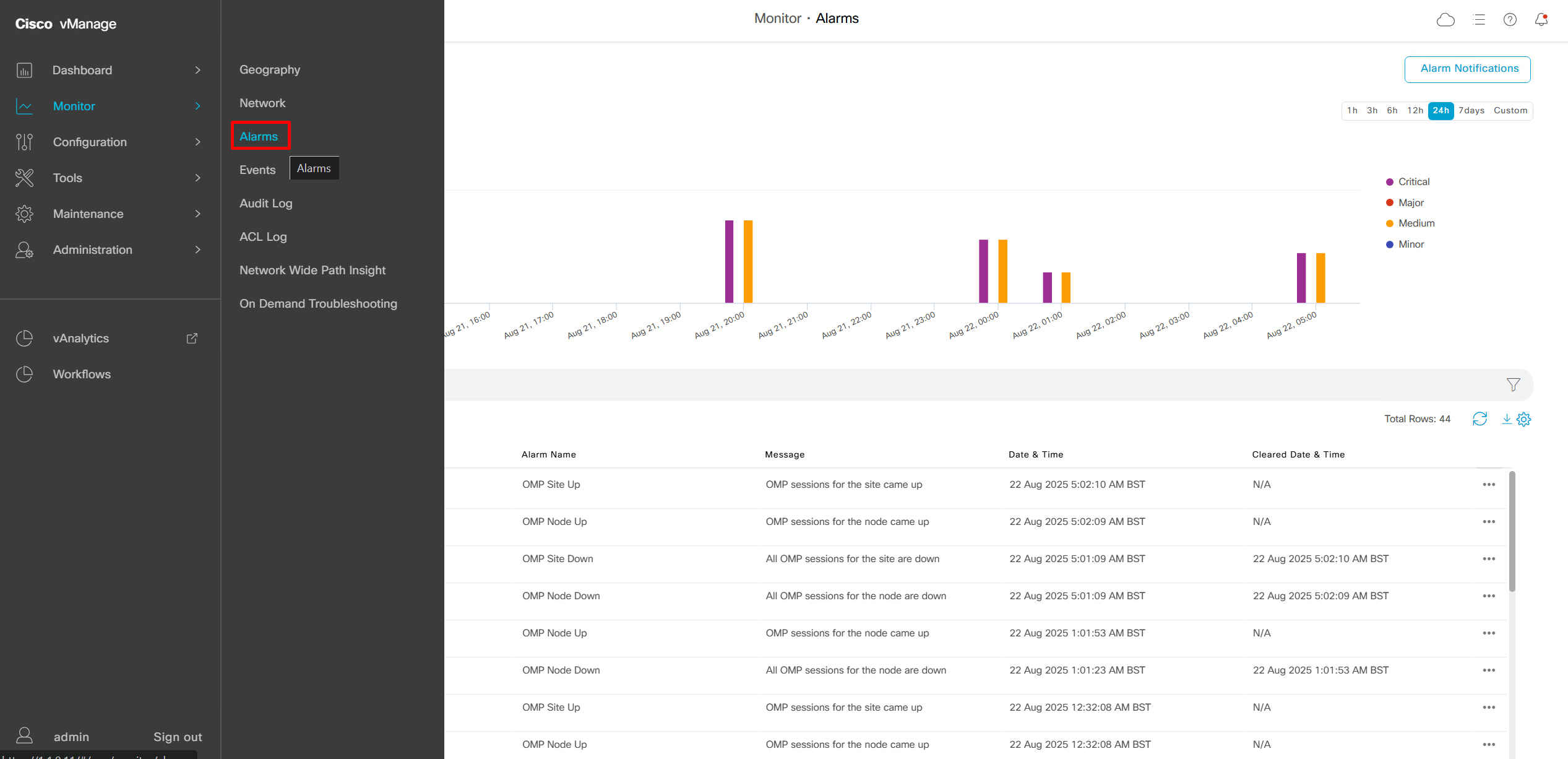
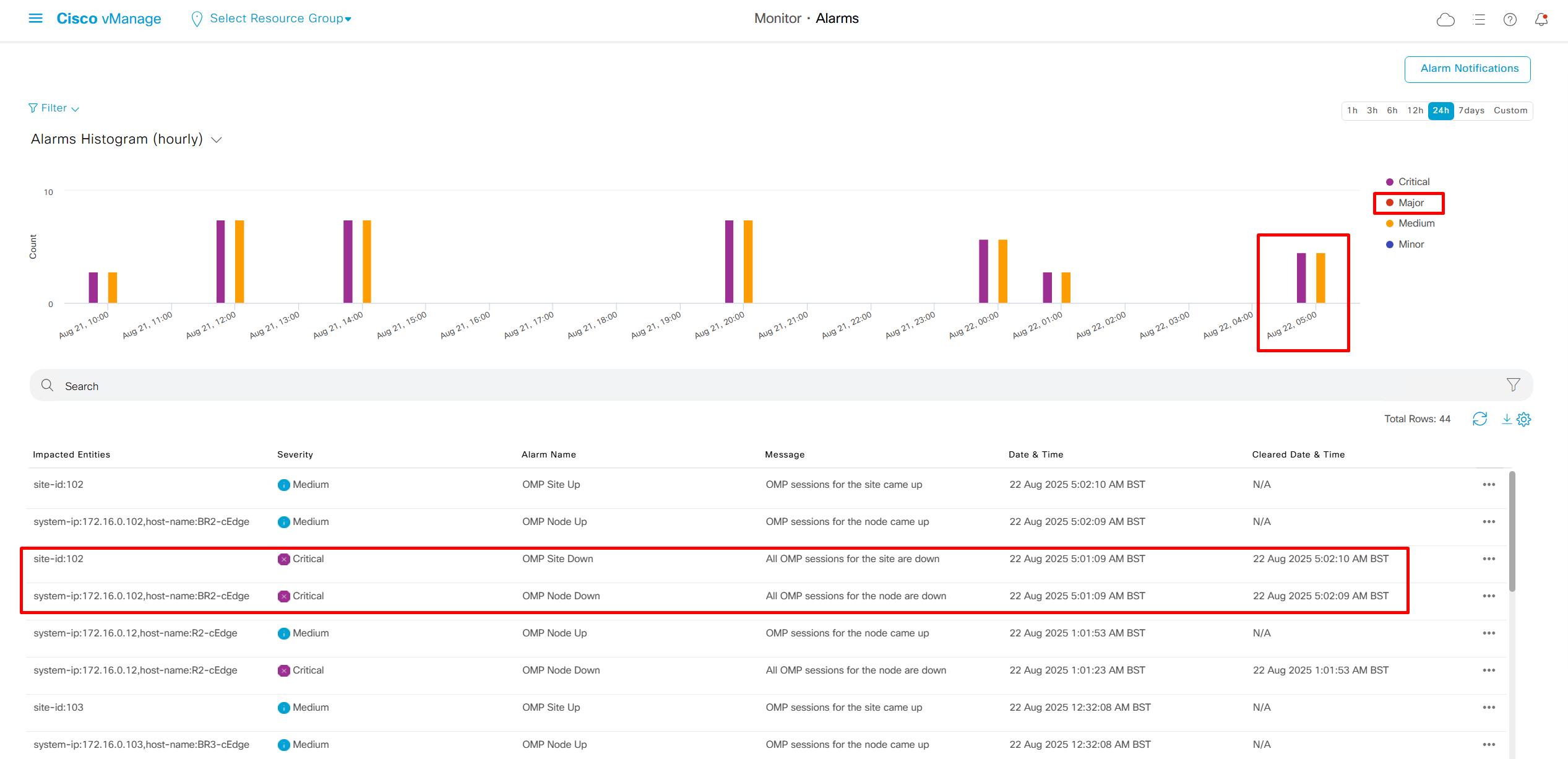
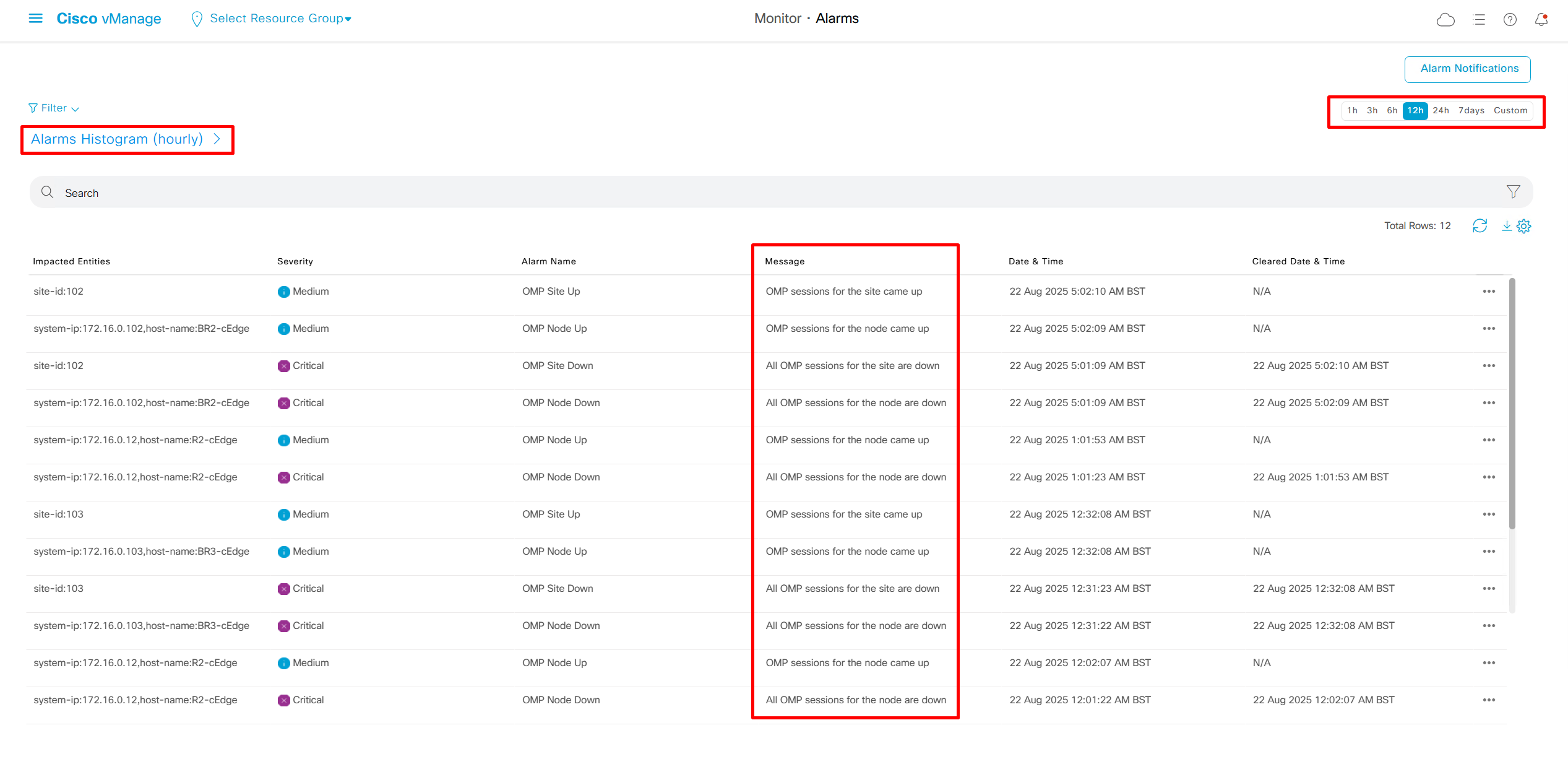
We can add Alarm notification email as well
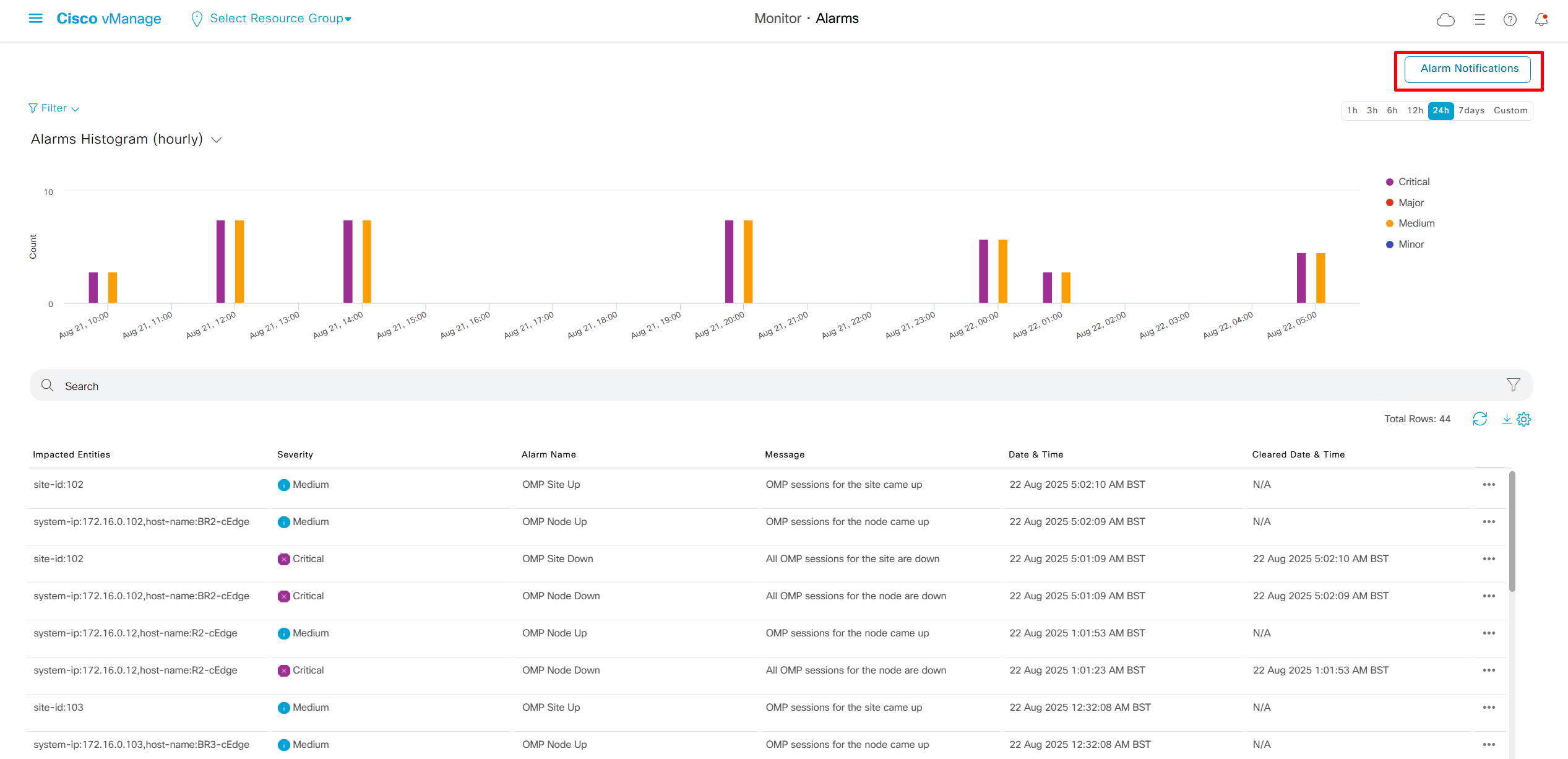
Now we move to events, Alarms are like syslogs generated and events are more detailed events
Audit log
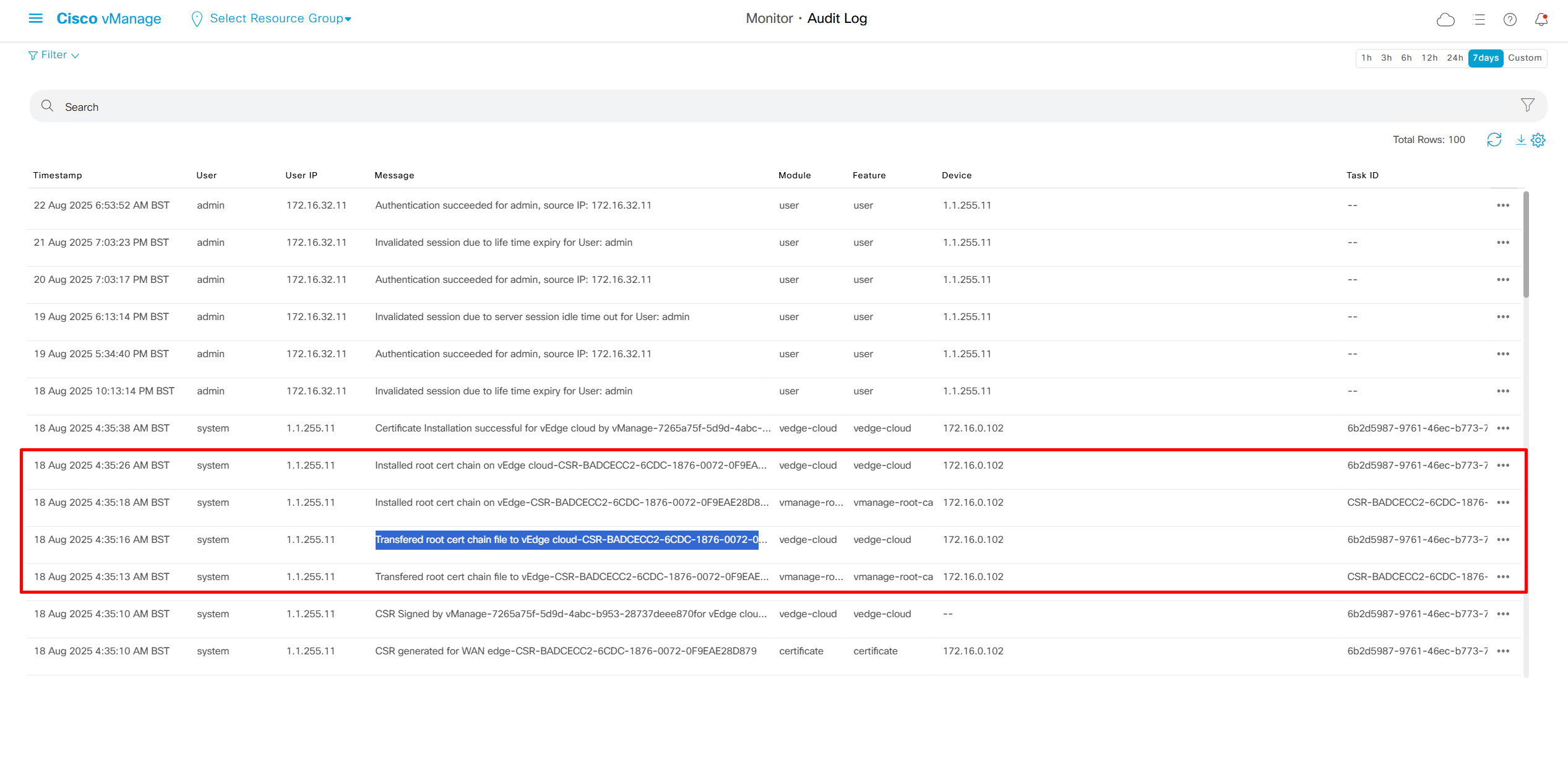
We can see all the audit trail for who did what and what was pushed to which device
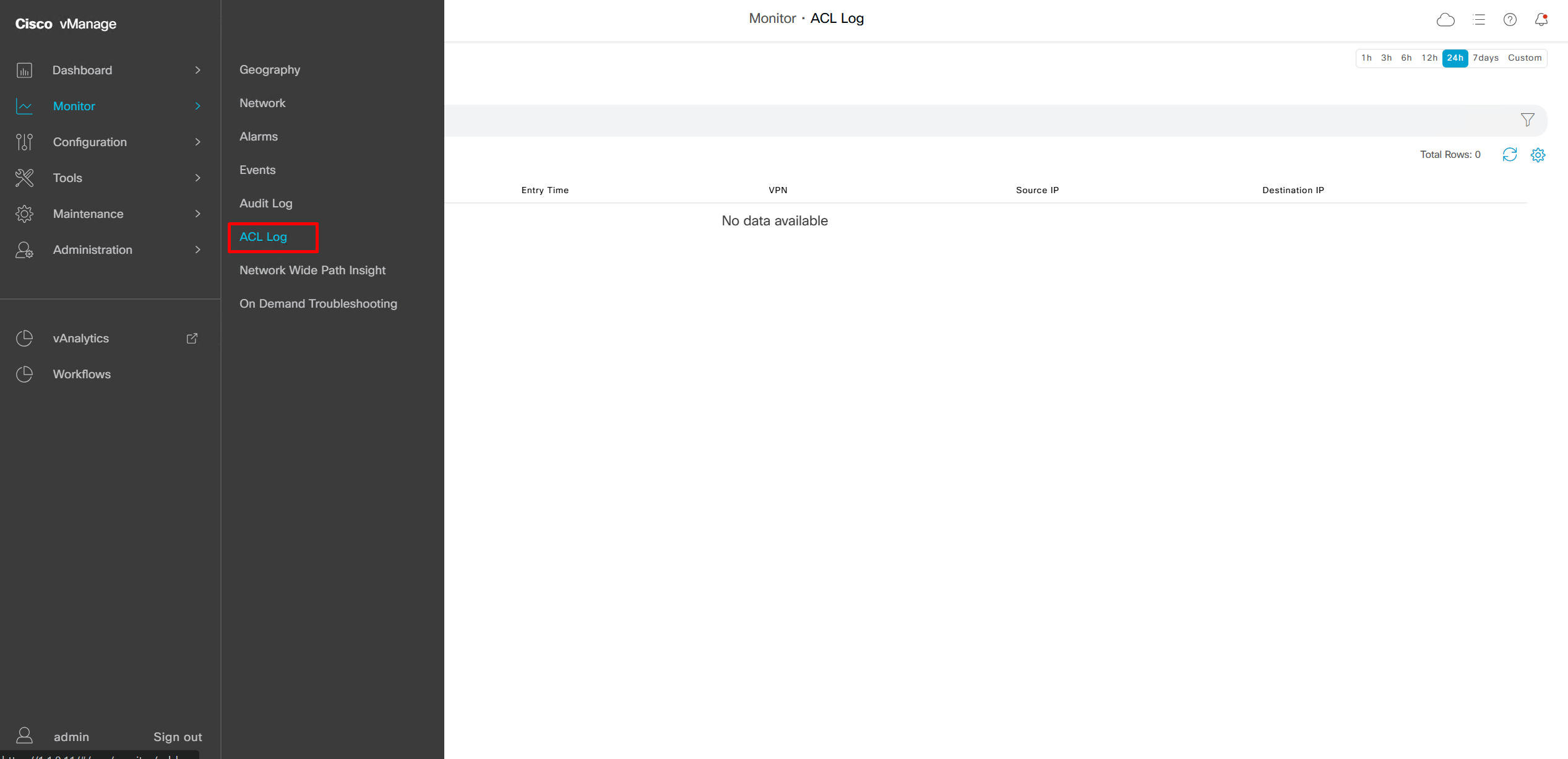
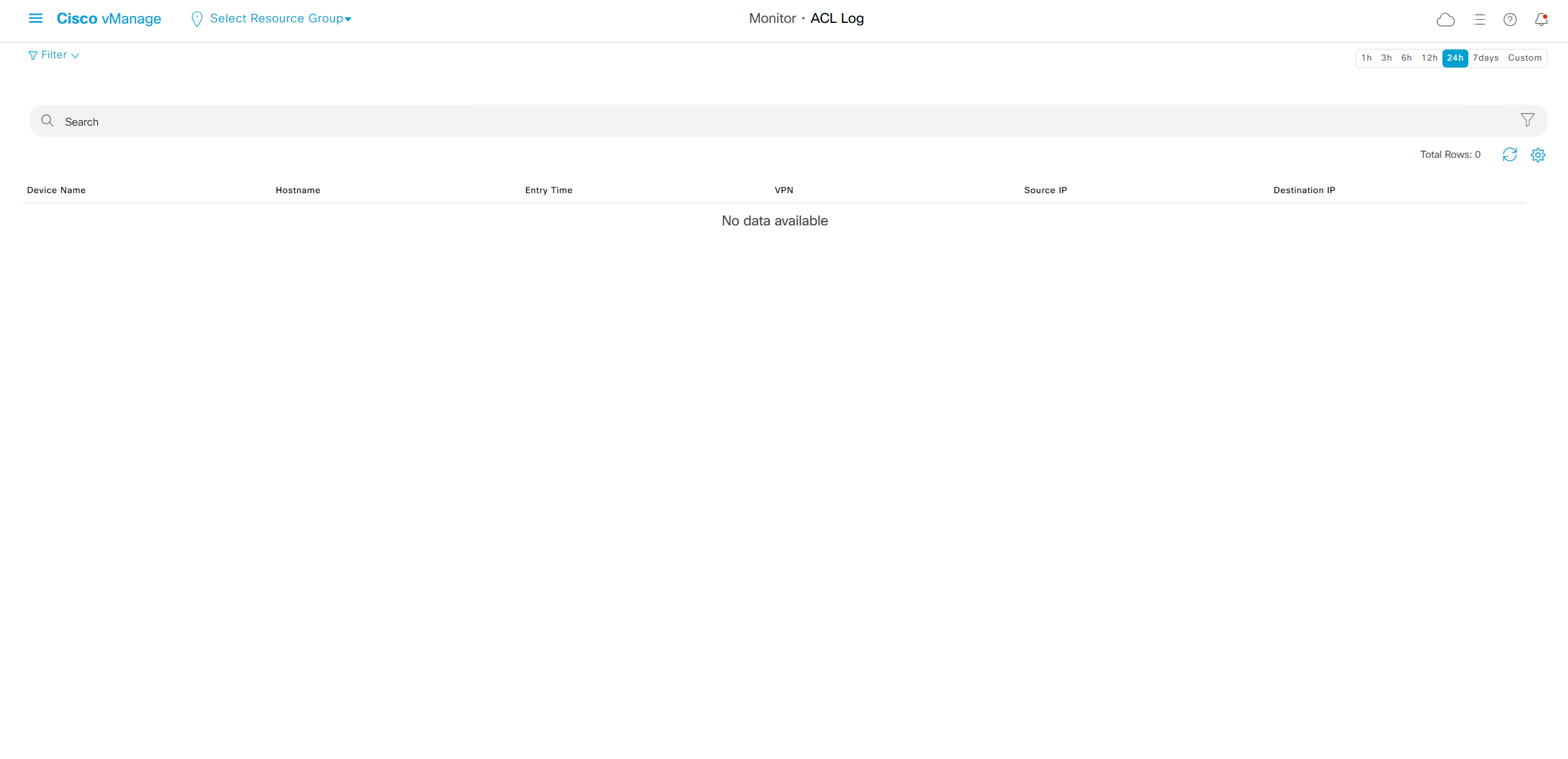
This comes in very handy as we can see ACL logs not just for one device but for the whole system
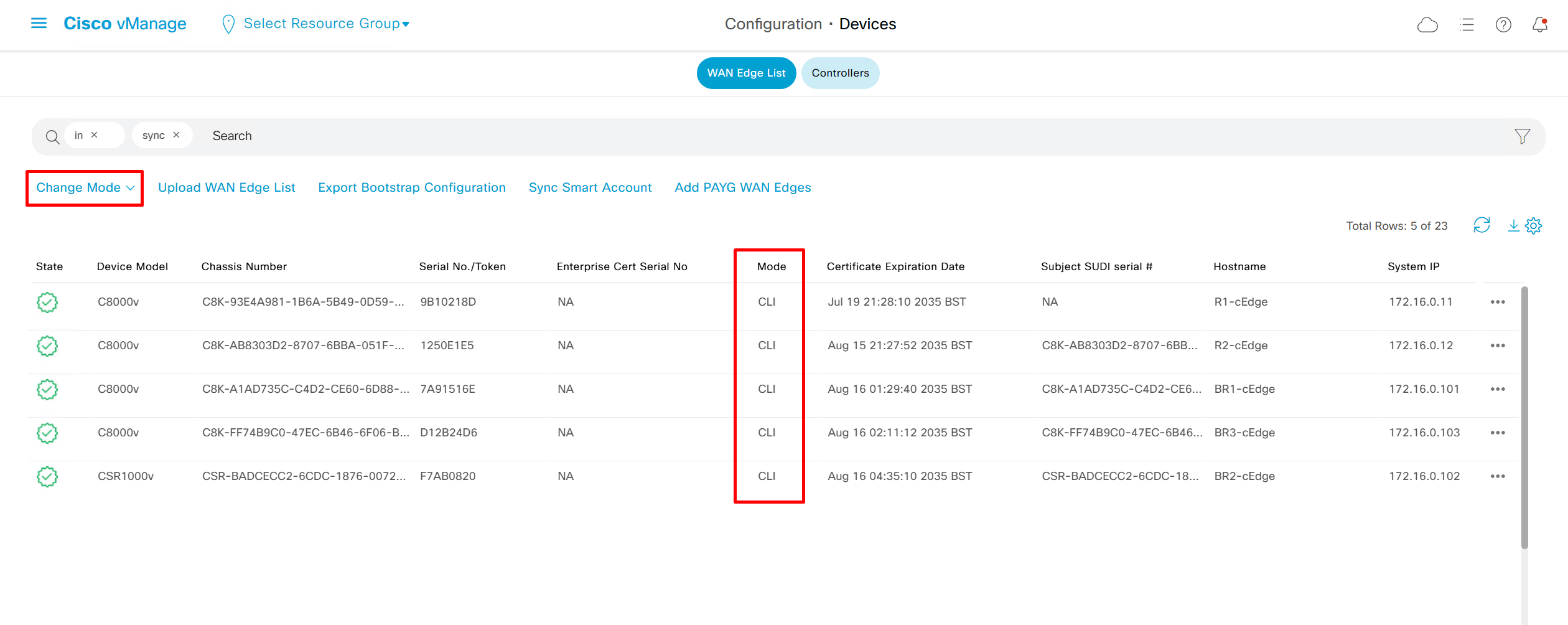
once a device is managed by vmanage, local CLI changes cannot be made on device
nodes which are PNP or ZTP enrolled are already in vmanage mode as at time of enrolment a template is applied and devices are vmanage managed
device manually enrolled are CLI managed as they are manually enrolled
one reason to convert from vmanage mode to CLI is to quickly test a command and then return device to vmanage mode, you dont even have to revert the changes made in CLI as we change back to vmanage mode, the changes made in CLI will disappear because configuration from template will be applied, if change test was successful then make that change part of the template
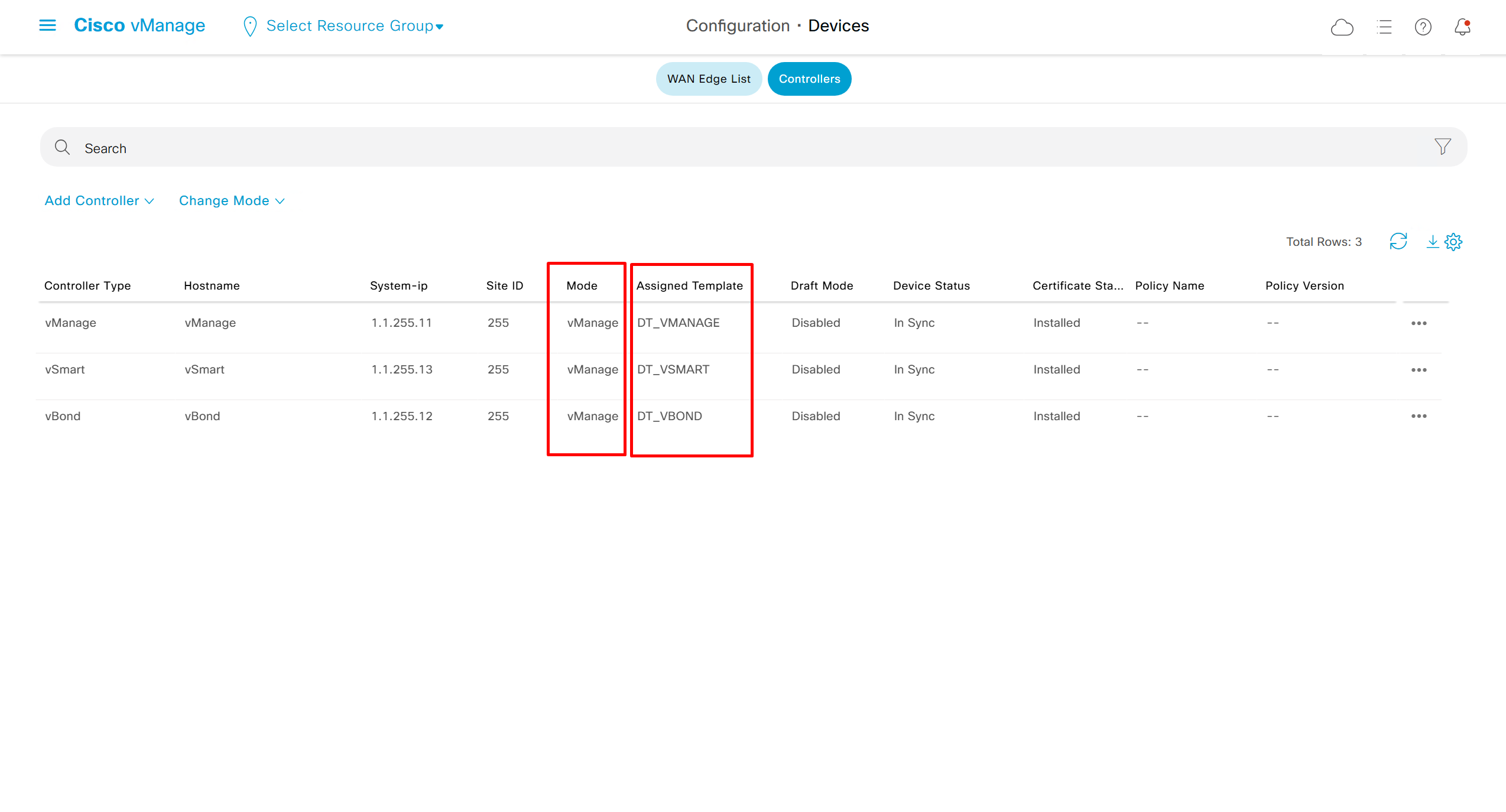
Device status must always be “In Sync”
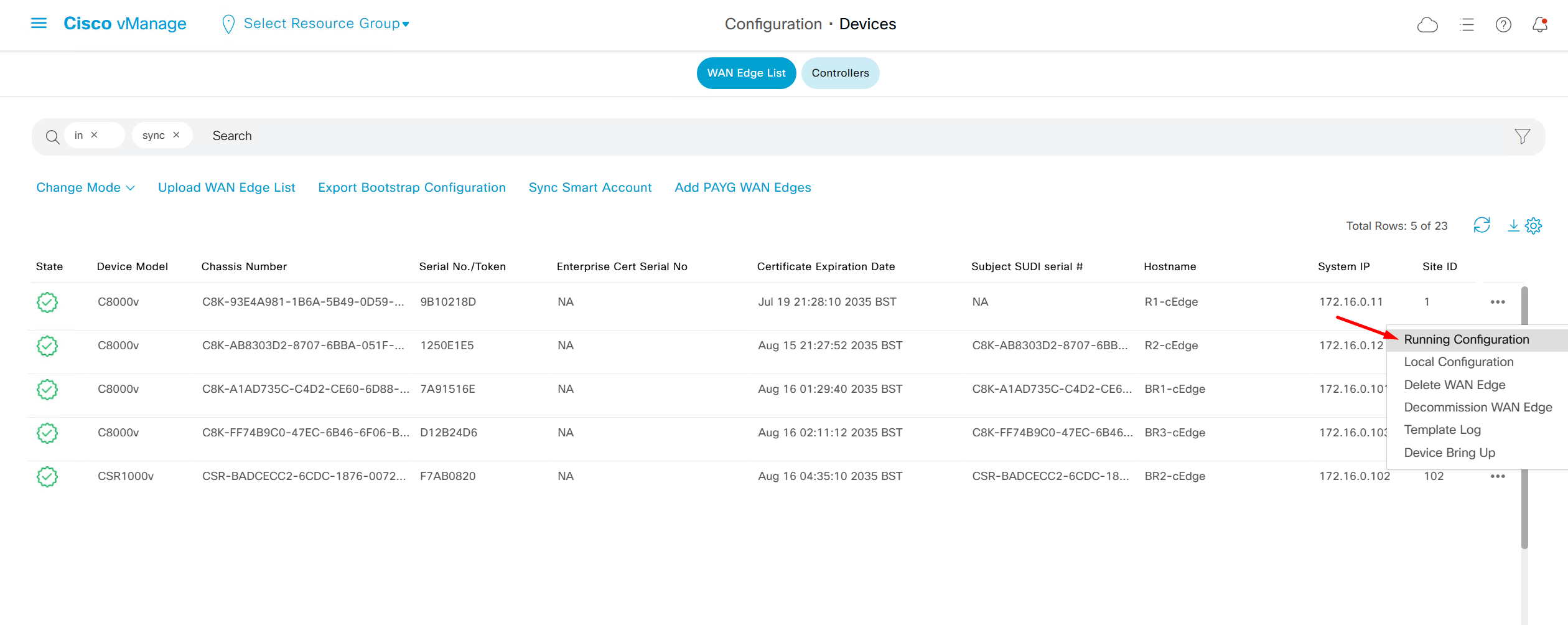
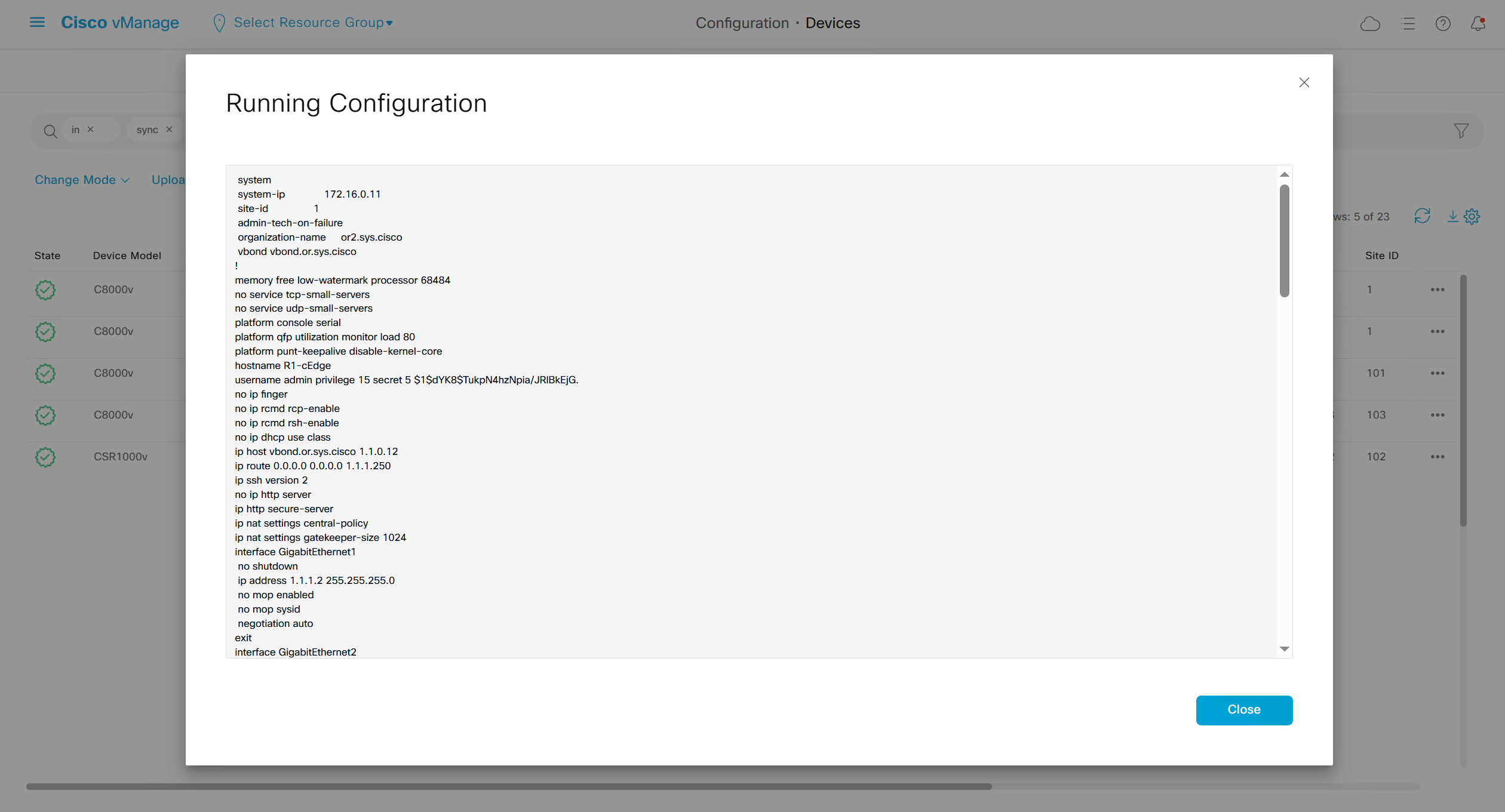
To see if device communication is working with vmanage, pull its running configuration, if it works then we know that netconf over DTLS (control connection) is working between vmanage and edge
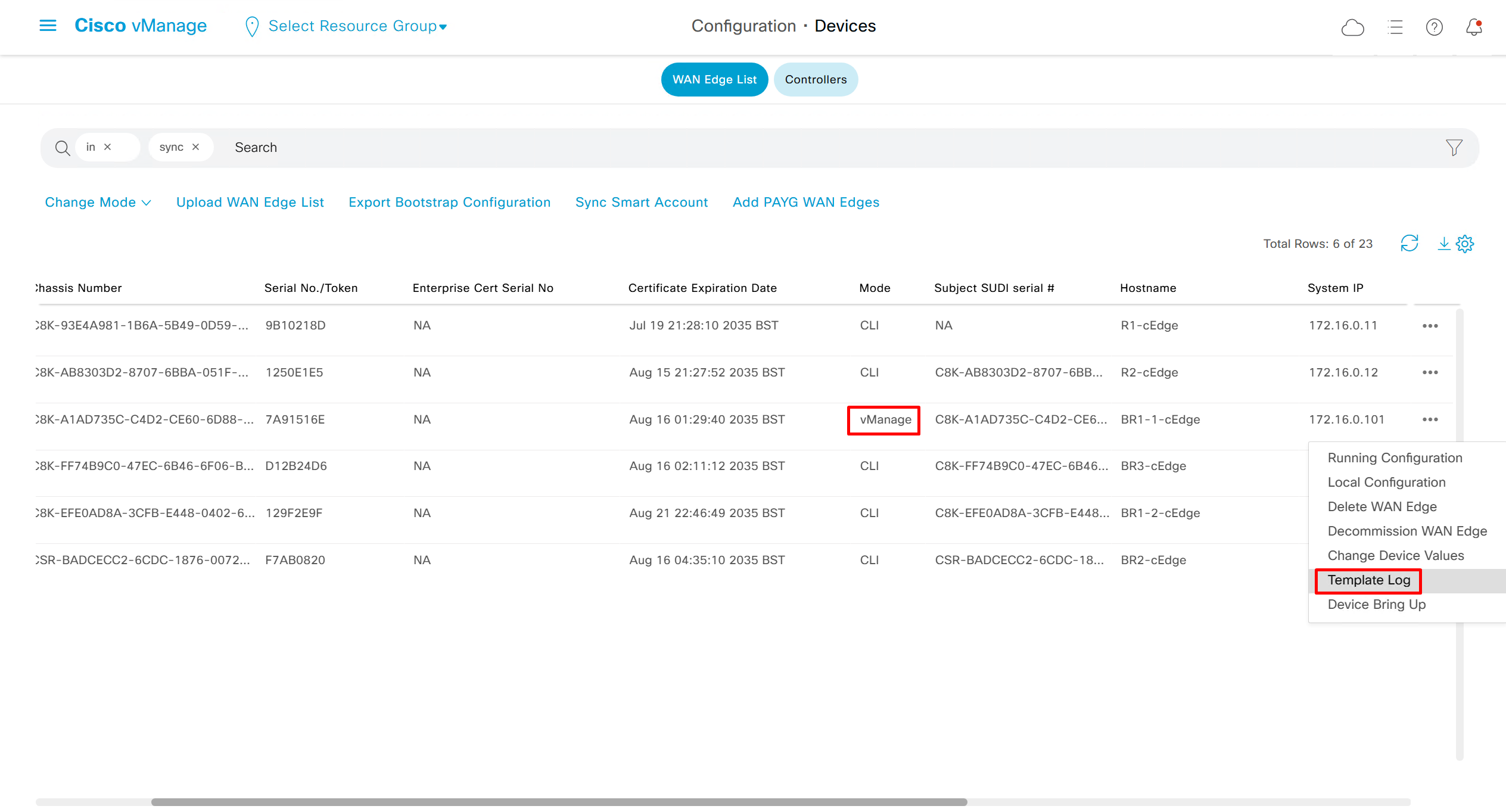
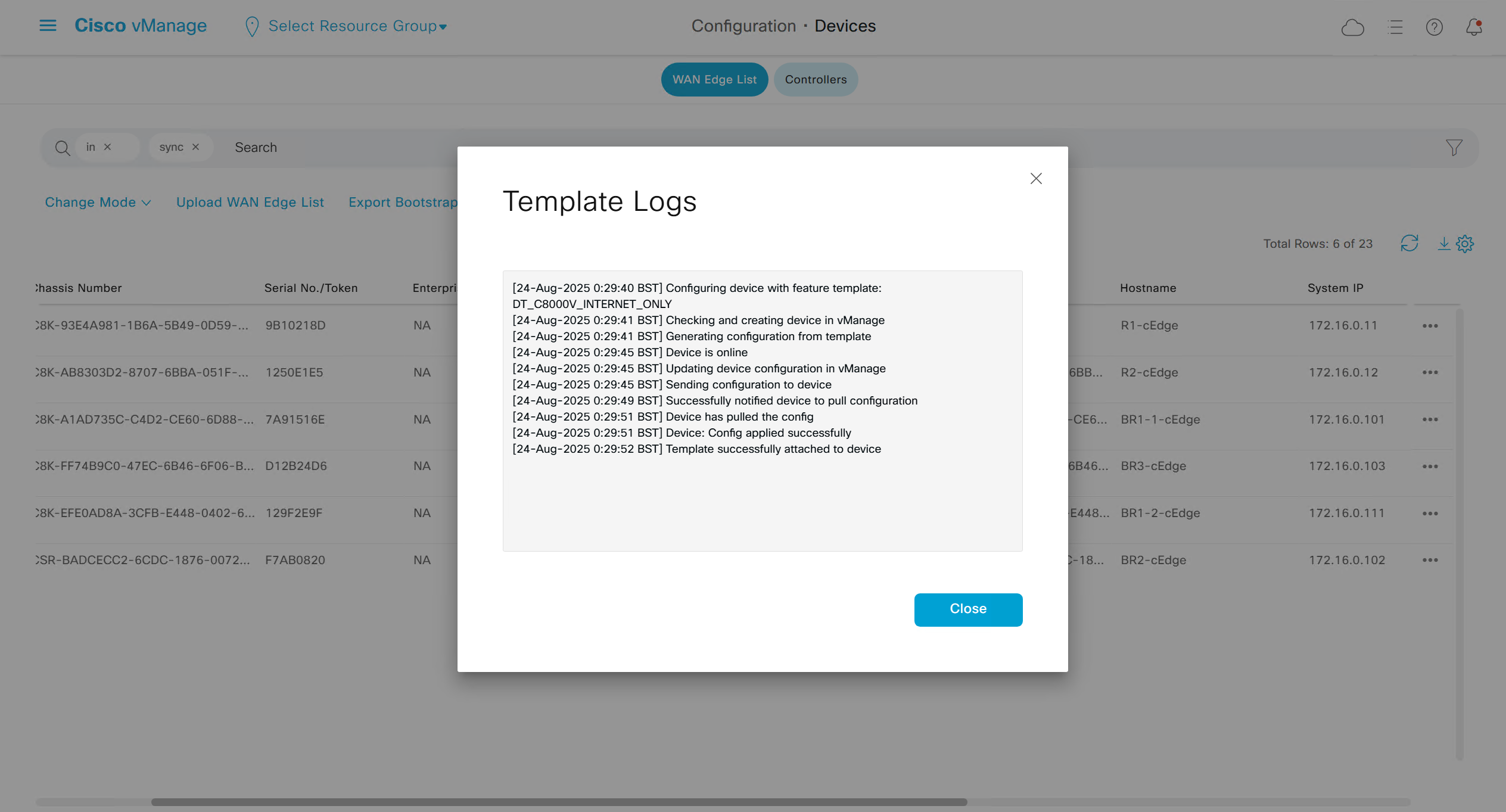
Template log is where we can see the changes
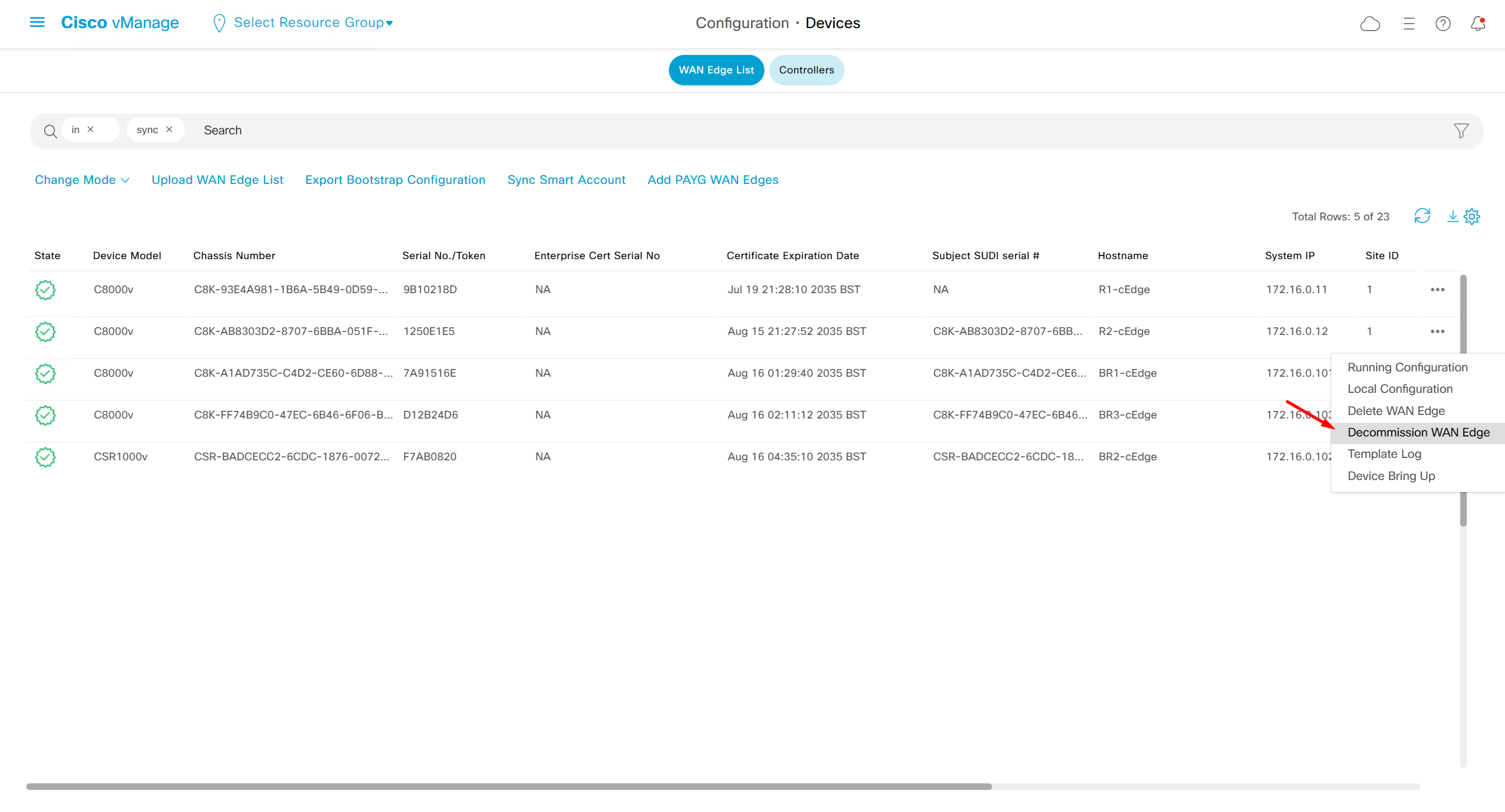
Decommission WAN edge – removes the edge device and puts chassis number back in the controllers so new virtual device can be assigned that chassis / token
Similar options for controllers
Templates
Device Templates
Feature Templates
Centralized Policy

Localized Policy
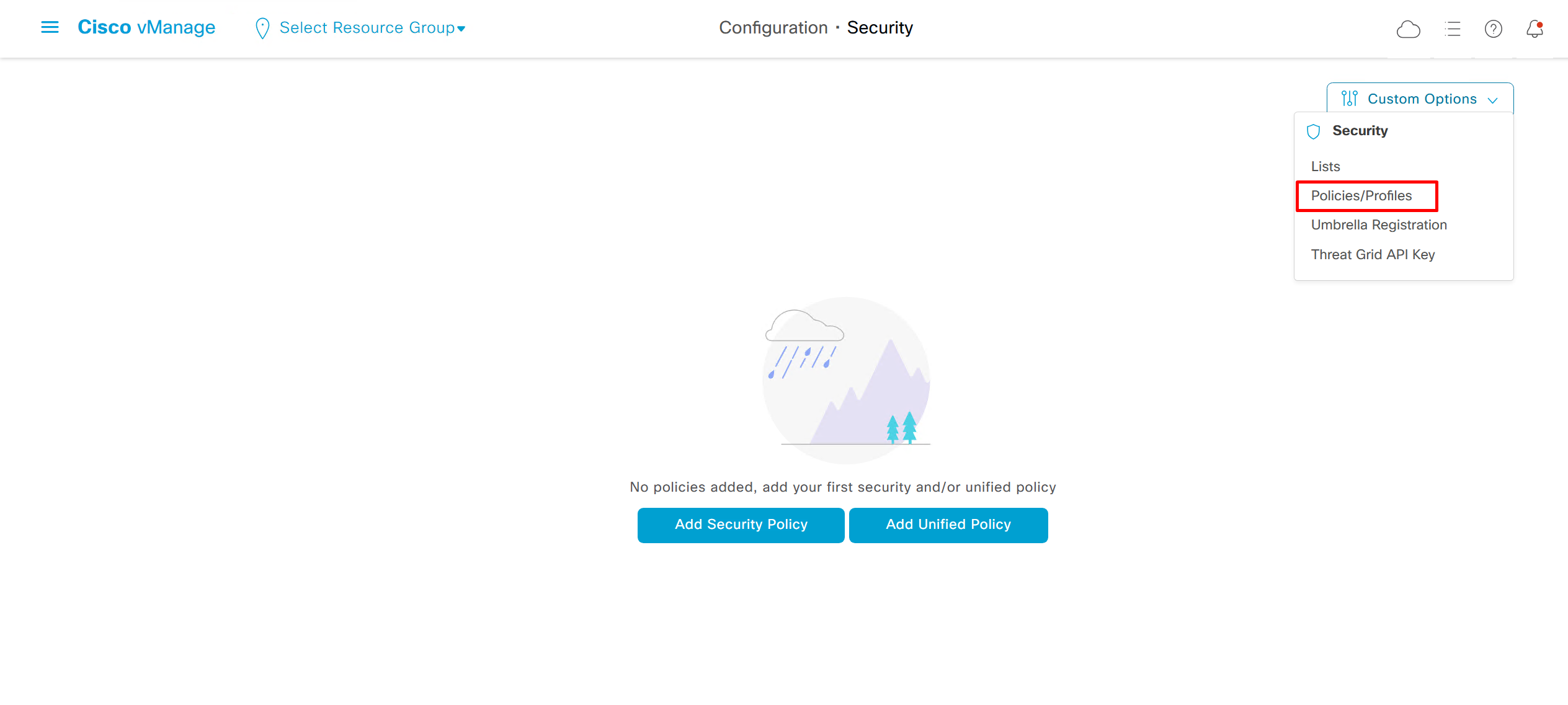
Security section where we can configure Zone Based Firewall etc


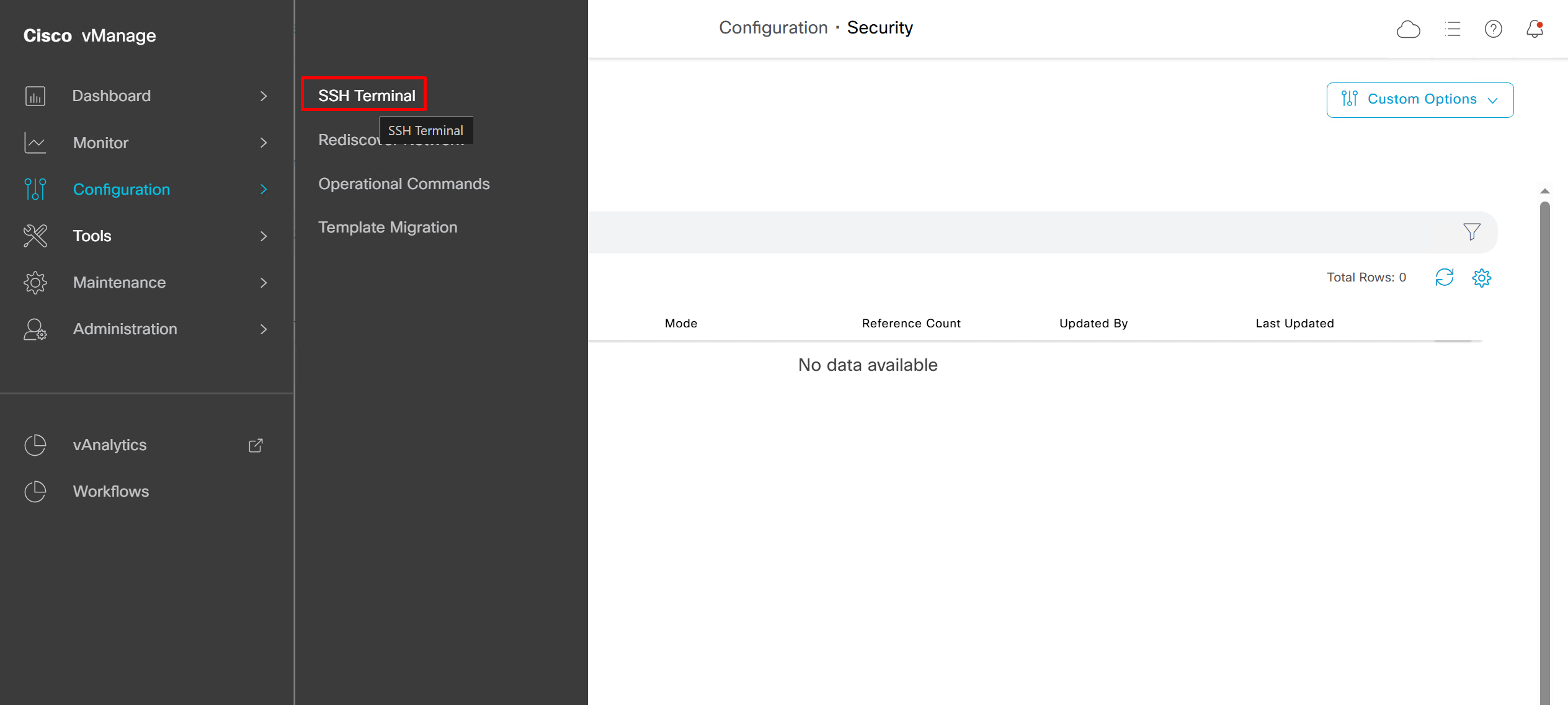
This is great when you want to quickly check something in SSH
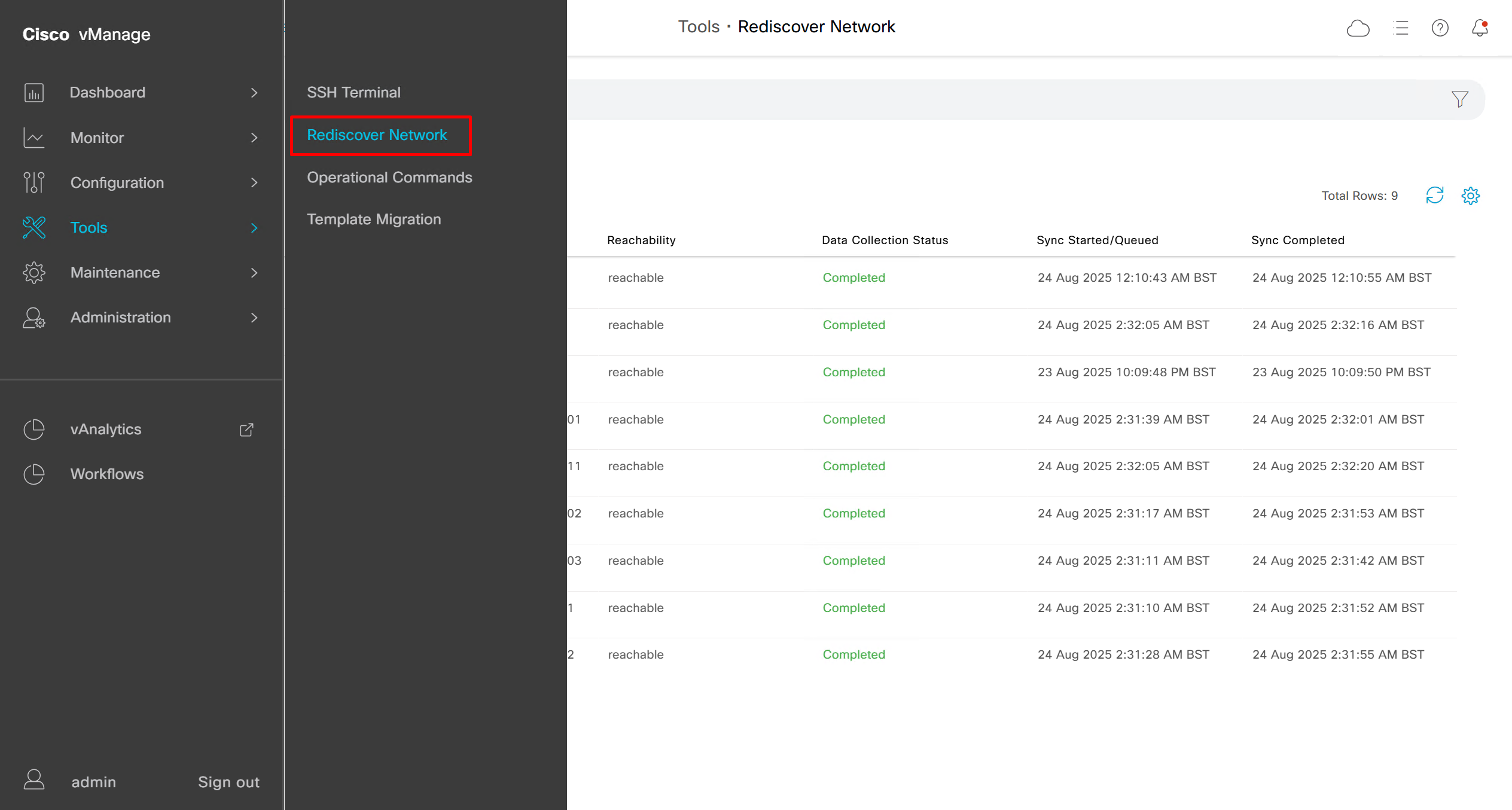
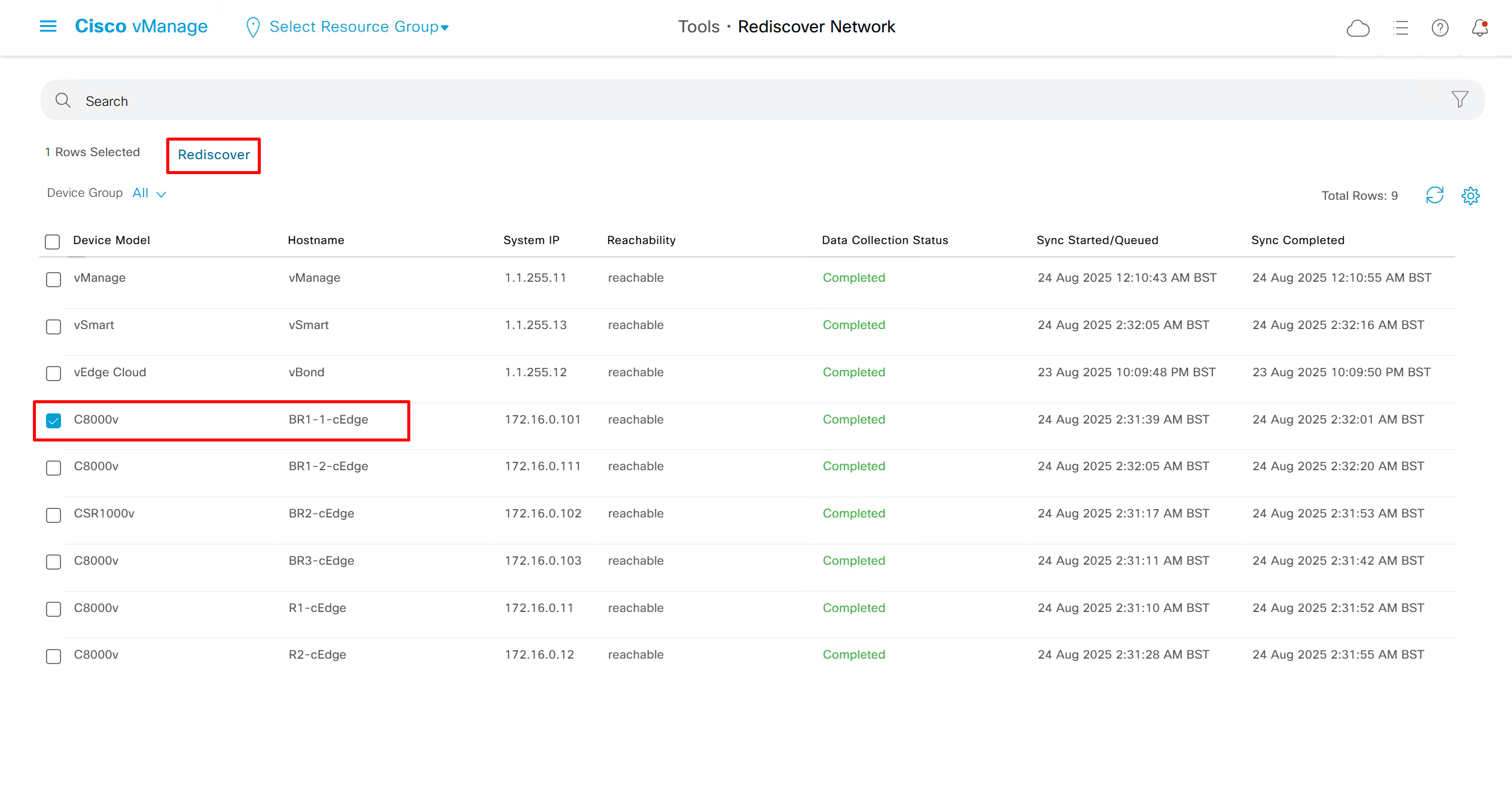
Rediscover network if there is a difference in configuration between vmanage and edge device
Rediscover edge device to sync all those changes
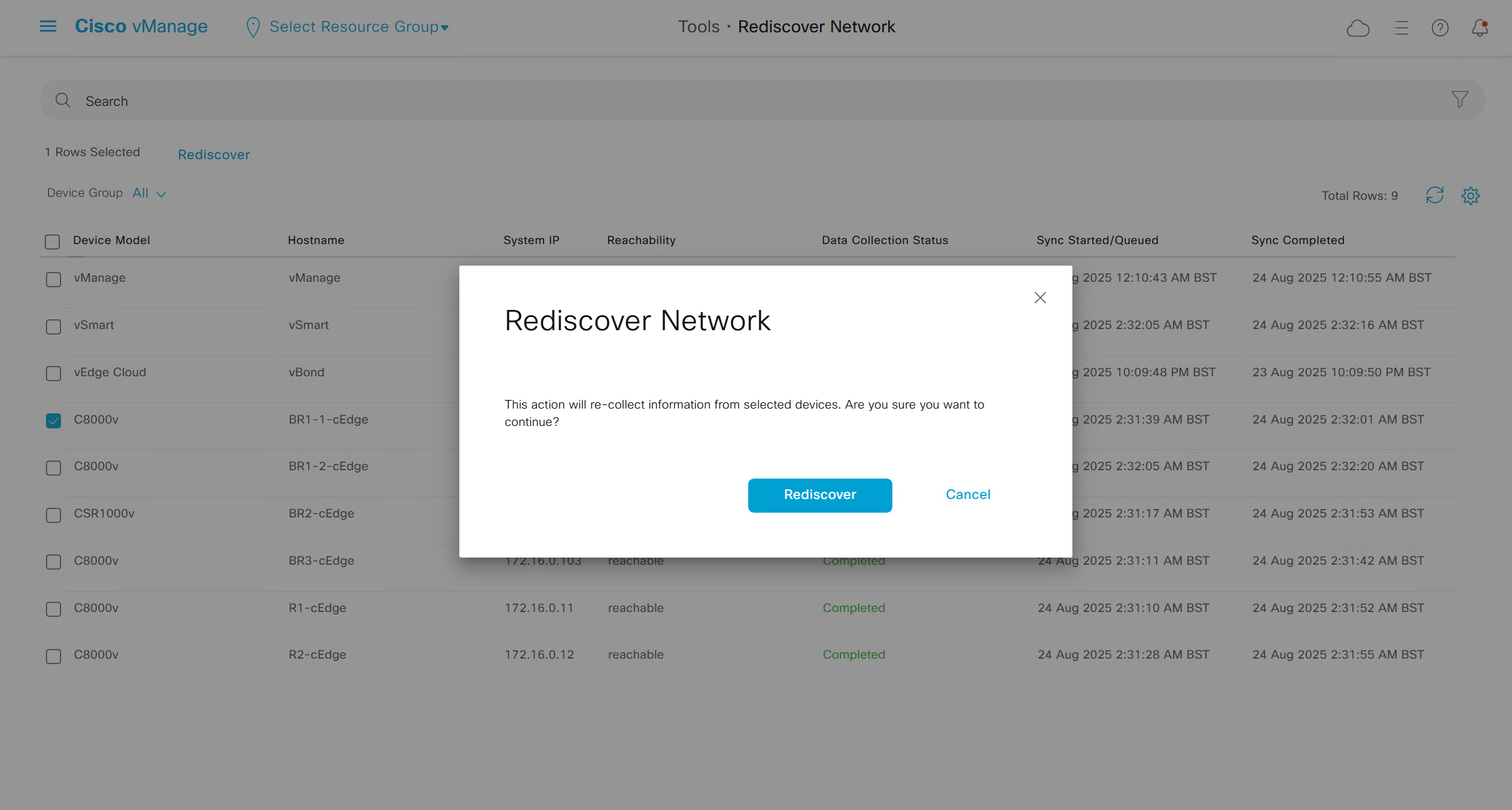
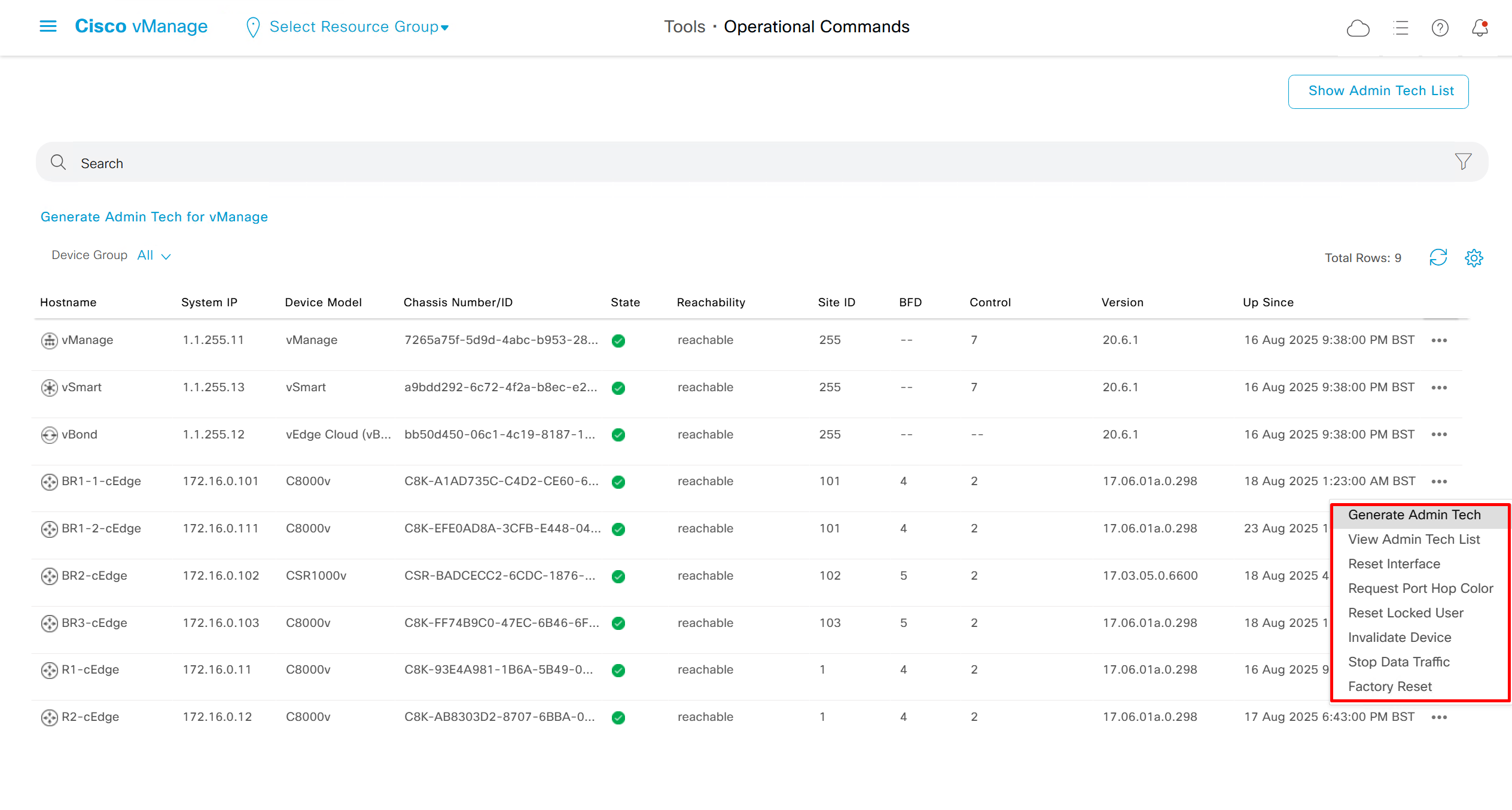
Generate Admin Tech for support
Reset interface is to bounce the port
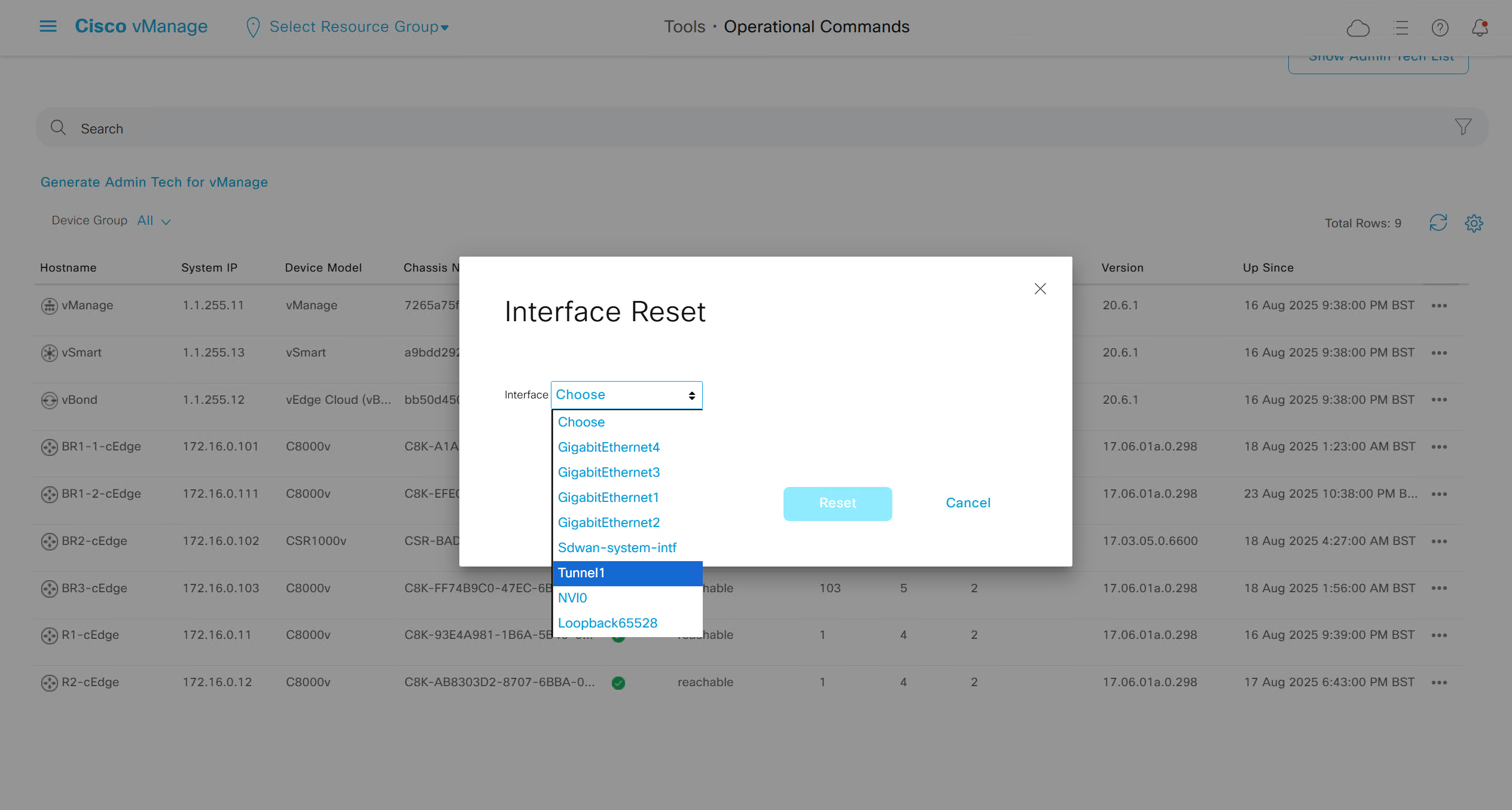
BR1-1-cEdge#
*Aug 24 02:18:57.042: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:47394 for netconf over ssh. External groups:
BR1-1-cEdge#
*Aug 24 02:19:00.560: %Cisco-SDWAN-RP_0-VDAEMON-3-ERRO-500012: Device does not have an active connection to a vSmart controller
*Aug 24 02:19:04.058: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:47412 for netconf over ssh. External groups:
BR1-1-cEdge#
*Aug 24 02:19:13.388: %DMI-5-AUTH_PASSED: R0/0: dmiauthd: User 'vmanage-admin' authenticated successfully from 1.1.255.11:47468 for netconf over ssh. External groups:
BR1-1-cEdge#Request port hop color – Essentially, it forces a TLOC (Transport Locator) color hop so the device re-initiates connections using another WAN interface/color (for example: from biz-internet → public-internet, or mpls → lte).
This is mostly used for troubleshooting and validating policies (e.g., checking failover between MPLS and Internet links).
Reset locked user is used to unlock admin


once a vmanage is switched from single tenant to multitenant then it cannot go back to single tenant


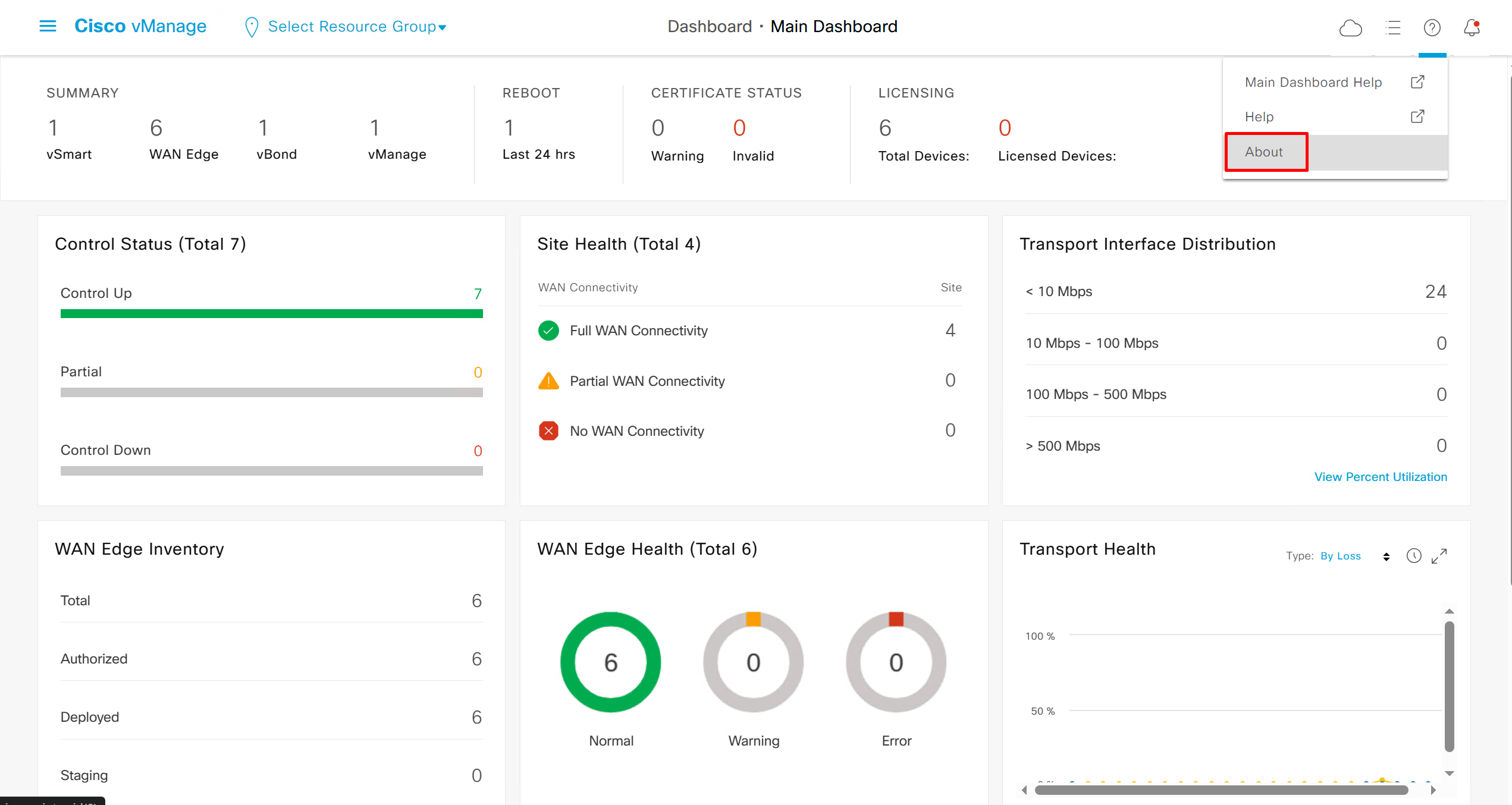



OMP , TLOCs and IPSec VPN
vSmart# show omp peers
R -> routes received
I -> routes installed
S -> routes sent
DOMAIN OVERLAY SITE
PEER TYPE ID ID ID STATE UPTIME R/I/S
------------------------------------------------------------------------------------------
172.16.0.11 vedge 1 1 1 up 0:04:15:03 0/0/0
172.16.0.12 vedge 1 1 1 up 0:03:16:13 0/0/0
172.16.0.101 vedge 1 1 101 up 0:02:45:09 0/0/0
172.16.0.102 vedge 1 1 102 up 0:04:15:21 0/0/0
172.16.0.103 vedge 1 1 103 up 0:04:14:59 0/0/0
172.16.0.111 vedge 1 1 101 up 0:02:45:31 0/0/0R1-cEdge#show sdwan omp peers
R -> routes received
I -> routes installed
S -> routes sent
DOMAIN OVERLAY SITE
PEER TYPE ID ID ID STATE UPTIME R/I/S
------------------------------------------------------------------------------------------
1.1.255.13 vsmart 1 1 255 up 0:04:17:40 0/0/0All the TLOCs known by router, two repeating system IPs means router has transports / colors
R1-cEdge#show sdwan omp tloc-paths
tloc-paths entries 172.16.0.11 biz-internet ipsec
tloc-paths entries 172.16.0.12 mpls ipsec
tloc-paths entries 172.16.0.101 biz-internet ipsec
tloc-paths entries 172.16.0.102 mpls ipsec
tloc-paths entries 172.16.0.102 biz-internet ipsec
tloc-paths entries 172.16.0.103 mpls ipsec
tloc-paths entries 172.16.0.103 biz-internet ipsec
tloc-paths entries 172.16.0.111 mpls ipsecFull TLOC details
R1-cEdge#show sdwan omp tlocs
---------------------------------------------------
tloc entries for 172.16.0.11
biz-internet
ipsec
---------------------------------------------------
RECEIVED FROM:
peer 0.0.0.0
status C,Red,R
loss-reason not set
lost-to-peer not set
lost-to-path-id not set
Attributes:
attribute-type installed
encap-key not set
encap-proto 0
encap-spi 284
encap-auth sha1-hmac,ah-sha1-hmac
encap-encrypt aes256
public-ip 1.1.1.2
public-port 12366
private-ip 1.1.1.2
private-port 12366
public-ip ::
public-port 0
private-ip ::
private-port 0
bfd-status up << BFD status should be up
domain-id not set
site-id 1
overlay-id not set
preference 0
tag not set
stale not set
weight 1
version 3
gen-id 0x80000001
carrier default
restrict 0
on-demand 0
groups [ 0 ]
bandwidth 0
bandwidth-dmin 0
bandwidth-down 0
bandwidth-dmax 0
adapt-qos-period 0
adapt-qos-up 0
qos-group default-group
border not set
extended-ipsec-anti-replay not set
unknown-attr-len not set
---------------------------------------------------
tloc entries for 172.16.0.12
mpls
ipsec
---------------------------------------------------
RECEIVED FROM:
peer 1.1.255.13
status C,I,R
loss-reason not set
lost-to-peer not set
lost-to-path-id not set
Attributes:
attribute-type installed
encap-key not set
encap-proto 0
encap-spi 287
encap-auth sha1-hmac,ah-sha1-hmac
encap-encrypt aes256
public-ip 10.0.1.2
public-port 12406
private-ip 10.0.1.2
private-port 12406
public-ip ::
public-port 0
private-ip ::
private-port 0
bfd-status down
domain-id not set
site-id 1
overlay-id not set
preference 0
tag not set
stale not set
weight 1
version 3
gen-id 0x80000000
carrier default
restrict 0
on-demand 0
groups [ 0 ]
bandwidth 0
bandwidth-dmin 0
bandwidth-down 0
bandwidth-dmax 0
adapt-qos-period 0
adapt-qos-up 0
qos-group default-group
border not set
extended-ipsec-anti-replay not set
unknown-attr-len not set
---------------------------------------------------
tloc entries for 172.16.0.101
biz-internet
ipsec
---------------------------------------------------
RECEIVED FROM:
peer 1.1.255.13
status C,I,R
loss-reason not set
lost-to-peer not set
lost-to-path-id not set
Attributes:
attribute-type installed
encap-key not set
encap-proto 0
encap-spi 285
encap-auth sha1-hmac,ah-sha1-hmac
encap-encrypt aes256
public-ip 1.1.1.101
public-port 12386
private-ip 1.1.1.101
private-port 12386
public-ip ::
public-port 0
private-ip ::
private-port 0
bfd-status up
domain-id not set
site-id 101
overlay-id not set
preference 0
tag not set
stale not set
weight 1
version 3
gen-id 0x80000000
carrier default
restrict 0
on-demand 0
groups [ 0 ]
bandwidth 0
bandwidth-dmin 0
bandwidth-down 0
bandwidth-dmax 0
adapt-qos-period 0
adapt-qos-up 0
qos-group default-group
border not set
extended-ipsec-anti-replay not set
unknown-attr-len not set
---------------------------------------------------
tloc entries for 172.16.0.102
mpls
ipsec
---------------------------------------------------
RECEIVED FROM:
peer 1.1.255.13
status C,I,R
loss-reason not set
lost-to-peer not set
lost-to-path-id not set
Attributes:
attribute-type installed
encap-key not set
encap-proto 0
encap-spi 262
encap-auth sha1-hmac,ah-sha1-hmac
encap-encrypt aes256
public-ip 10.0.102.2
public-port 12426
private-ip 10.0.102.2
private-port 12426
public-ip ::
public-port 0
private-ip ::
private-port 0
bfd-status up
domain-id not set
site-id 102
overlay-id not set
preference 0
tag not set
stale not set
weight 1
version 3
gen-id 0x80000000
carrier default
restrict 0
on-demand 0
groups [ 0 ]
bandwidth 0
bandwidth-dmin 0
bandwidth-down 0
bandwidth-dmax 0
adapt-qos-period 0
adapt-qos-up 0
qos-group default-group
border not set
extended-ipsec-anti-replay not set
unknown-attr-len not set
---------------------------------------------------
tloc entries for 172.16.0.102
biz-internet
ipsec
---------------------------------------------------
RECEIVED FROM:
peer 1.1.255.13
status C,I,R
loss-reason not set
lost-to-peer not set
lost-to-path-id not set
Attributes:
attribute-type installed
encap-key not set
encap-proto 0
encap-spi 280
encap-auth sha1-hmac,ah-sha1-hmac
encap-encrypt aes256
public-ip 1.1.1.102
public-port 12366
private-ip 1.1.1.102
private-port 12366
public-ip ::
public-port 0
private-ip ::
private-port 0
bfd-status up
domain-id not set
site-id 102
overlay-id not set
preference 0
tag not set
stale not set
weight 1
version 3
gen-id 0x80000000
carrier default
restrict 0
on-demand 0
groups [ 0 ]
bandwidth 0
bandwidth-dmin 0
bandwidth-down 0
bandwidth-dmax 0
adapt-qos-period 0
adapt-qos-up 0
qos-group default-group
border not set
extended-ipsec-anti-replay not set
unknown-attr-len not set
---------------------------------------------------
tloc entries for 172.16.0.103
mpls
ipsec
---------------------------------------------------
RECEIVED FROM:
peer 1.1.255.13
status C,I,R
loss-reason not set
lost-to-peer not set
lost-to-path-id not set
Attributes:
attribute-type installed
encap-key not set
encap-proto 0
encap-spi 265
encap-auth sha1-hmac,ah-sha1-hmac
encap-encrypt aes256
public-ip 10.0.103.2
public-port 12366
private-ip 10.0.103.2
private-port 12366
public-ip ::
public-port 0
private-ip ::
private-port 0
bfd-status up
domain-id not set
site-id 103
overlay-id not set
preference 0
tag not set
stale not set
weight 1
version 3
gen-id 0x80000000
carrier default
restrict 0
on-demand 0
groups [ 0 ]
bandwidth 0
bandwidth-dmin 0
bandwidth-down 0
bandwidth-dmax 0
adapt-qos-period 0
adapt-qos-up 0
qos-group default-group
border not set
extended-ipsec-anti-replay not set
unknown-attr-len not set
---------------------------------------------------
tloc entries for 172.16.0.103
biz-internet
ipsec
---------------------------------------------------
RECEIVED FROM:
peer 1.1.255.13
status C,I,R
loss-reason not set
lost-to-peer not set
lost-to-path-id not set
Attributes:
attribute-type installed
encap-key not set
encap-proto 0
encap-spi 286
encap-auth sha1-hmac,ah-sha1-hmac
encap-encrypt aes256
public-ip 1.1.1.103
public-port 12426
private-ip 1.1.1.103
private-port 12426
public-ip ::
public-port 0
private-ip ::
private-port 0
bfd-status up
domain-id not set
site-id 103
overlay-id not set
preference 0
tag not set
stale not set
weight 1
version 3
gen-id 0x80000000
carrier default
restrict 0
on-demand 0
groups [ 0 ]
bandwidth 0
bandwidth-dmin 0
bandwidth-down 0
bandwidth-dmax 0
adapt-qos-period 0
adapt-qos-up 0
qos-group default-group
border not set
extended-ipsec-anti-replay not set
unknown-attr-len not set
---------------------------------------------------
tloc entries for 172.16.0.111
mpls
ipsec
---------------------------------------------------
RECEIVED FROM:
peer 1.1.255.13
status C,I,R
loss-reason not set
lost-to-peer not set
lost-to-path-id not set
Attributes:
attribute-type installed
encap-key not set
encap-proto 0
encap-spi 266
encap-auth sha1-hmac,ah-sha1-hmac
encap-encrypt aes256
public-ip 10.0.101.2
public-port 12406
private-ip 10.0.101.2
private-port 12406
public-ip ::
public-port 0
private-ip ::
private-port 0
bfd-status up
domain-id not set
site-id 101
overlay-id not set
preference 0
tag not set
stale not set
weight 1
version 3
gen-id 0x80000000
carrier default
restrict 0
on-demand 0
groups [ 0 ]
bandwidth 0
bandwidth-dmin 0
bandwidth-down 0
bandwidth-dmax 0
adapt-qos-period 0
adapt-qos-up 0
qos-group default-group
border not set
extended-ipsec-anti-replay not set
unknown-attr-len not setInterval for BFD session is 1000 msec
R1-cEdge#show sdwan bfd sessions
SOURCE TLOC REMOTE TLOC DST PUBLIC DST PUBLIC DETECT TX
SYSTEM IP SITE ID STATE COLOR COLOR SOURCE IP IP PORT ENCAP MULTIPLIER INTERVAL(msec UPTIME TRANSITIONS
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
172.16.0.101 101 up biz-internet biz-internet 1.1.1.2 1.1.1.101 12386 ipsec 7 1000 10 0:23:51:18 0
172.16.0.102 102 up biz-internet biz-internet 1.1.1.2 1.1.1.102 12386 ipsec 7 1000 10 0:00:48:47 2
172.16.0.103 103 up biz-internet biz-internet 1.1.1.2 1.1.1.103 12426 ipsec 7 1000 10 0:03:48:08 0
172.16.0.111 101 up biz-internet mpls 1.1.1.2 10.0.101.2 12406 ipsec 7 1000 10 0:23:14:16 1
172.16.0.102 102 up biz-internet mpls 1.1.1.2 10.0.102.2 12426 ipsec 7 1000 10 0:13:47:48 0
172.16.0.103 103 up biz-internet mpls 1.1.1.2 10.0.103.2 12366 ipsec 7 1000 10 0:12:48:23 0
on ipsec outbound connections destination IP will be of remote routers
R1-cEdge#show sdwan ipsec outbound-connections
SOURCE SOURCE DEST DEST REMOTE REMOTE INTEGRITY NEGOTIATED
IP PORT IP PORT SPI TUNNEL MTU TLOC ADDRESS TLOC COLOR USED KEY HASH ENCRYPTION ALGORITHM TC SPIs
----------------------------------------------------------------------------------------------------------------------------------------------------------------
1.1.1.2 12366 1.1.1.101 12386 285 1438 172.16.0.101 biz-internet ip-udp-esp *****346f AES-GCM-256 8
1.1.1.2 12366 1.1.1.102 12386 281 1438 172.16.0.102 biz-internet ip-udp-esp *****60d6 AES-GCM-256 8
1.1.1.2 12366 1.1.1.103 12426 286 1438 172.16.0.103 biz-internet ip-udp-esp *****d535 AES-GCM-256 8
1.1.1.2 12366 10.0.101.2 12406 266 1438 172.16.0.111 mpls ip-udp-esp *****bf3e AES-GCM-256 8
1.1.1.2 12366 10.0.102.2 12426 262 1438 172.16.0.102 mpls ip-udp-esp *****8f3f AES-GCM-256 8
1.1.1.2 12366 10.0.103.2 12366 266 1438 172.16.0.103 mpls ip-udp-esp *****863f AES-GCM-256 8on the ipsec inbound connections, source IP will be of the remote routers
R1-cEdge#show sdwan ipsec inbound-connections
SOURCE SOURCE DEST DEST REMOTE REMOTE LOCAL LOCAL NEGOTIATED
IP PORT IP PORT TLOC ADDRESS TLOC COLOR TLOC ADDRESS TLOC COLOR ENCRYPTION ALGORITHM TC SPIs
--------------------------------------------------------------------------------------------------------------------------------------------------
1.1.1.101 12386 1.1.1.2 12366 172.16.0.101 biz-internet 172.16.0.11 biz-internet AES-GCM-256 8
10.0.102.2 12426 1.1.1.2 12366 172.16.0.102 mpls 172.16.0.11 biz-internet AES-GCM-256 8
1.1.1.102 12386 1.1.1.2 12366 172.16.0.102 biz-internet 172.16.0.11 biz-internet AES-GCM-256 8
10.0.103.2 12366 1.1.1.2 12366 172.16.0.103 mpls 172.16.0.11 biz-internet AES-GCM-256 8
1.1.1.103 12426 1.1.1.2 12366 172.16.0.103 biz-internet 172.16.0.11 biz-internet AES-GCM-256 8
10.0.101.2 12406 1.1.1.2 12366 172.16.0.111 mpls 172.16.0.11 biz-internet AES-GCM-256 Service Side VPN , Site Local LAN
Setup VPN 10 VRF
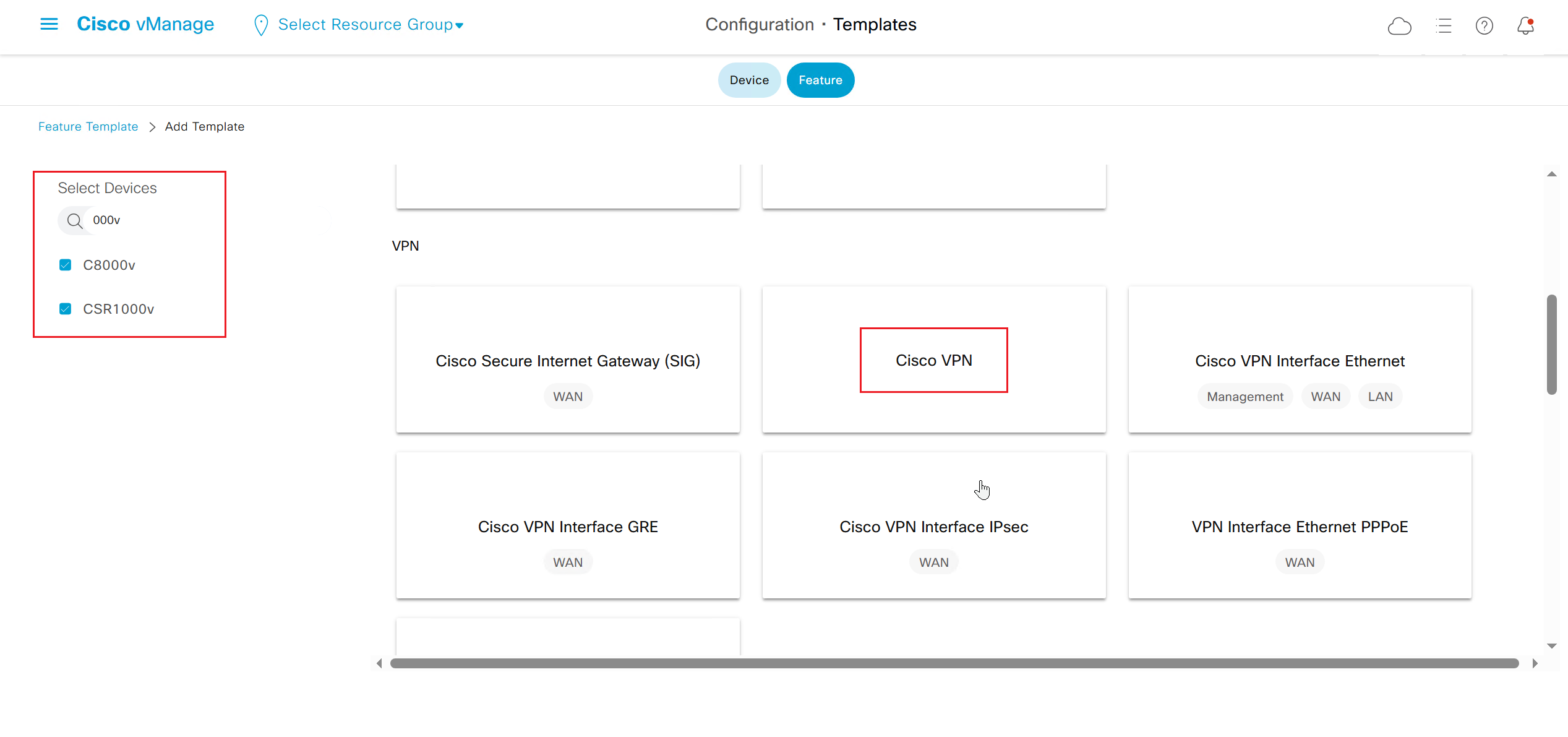
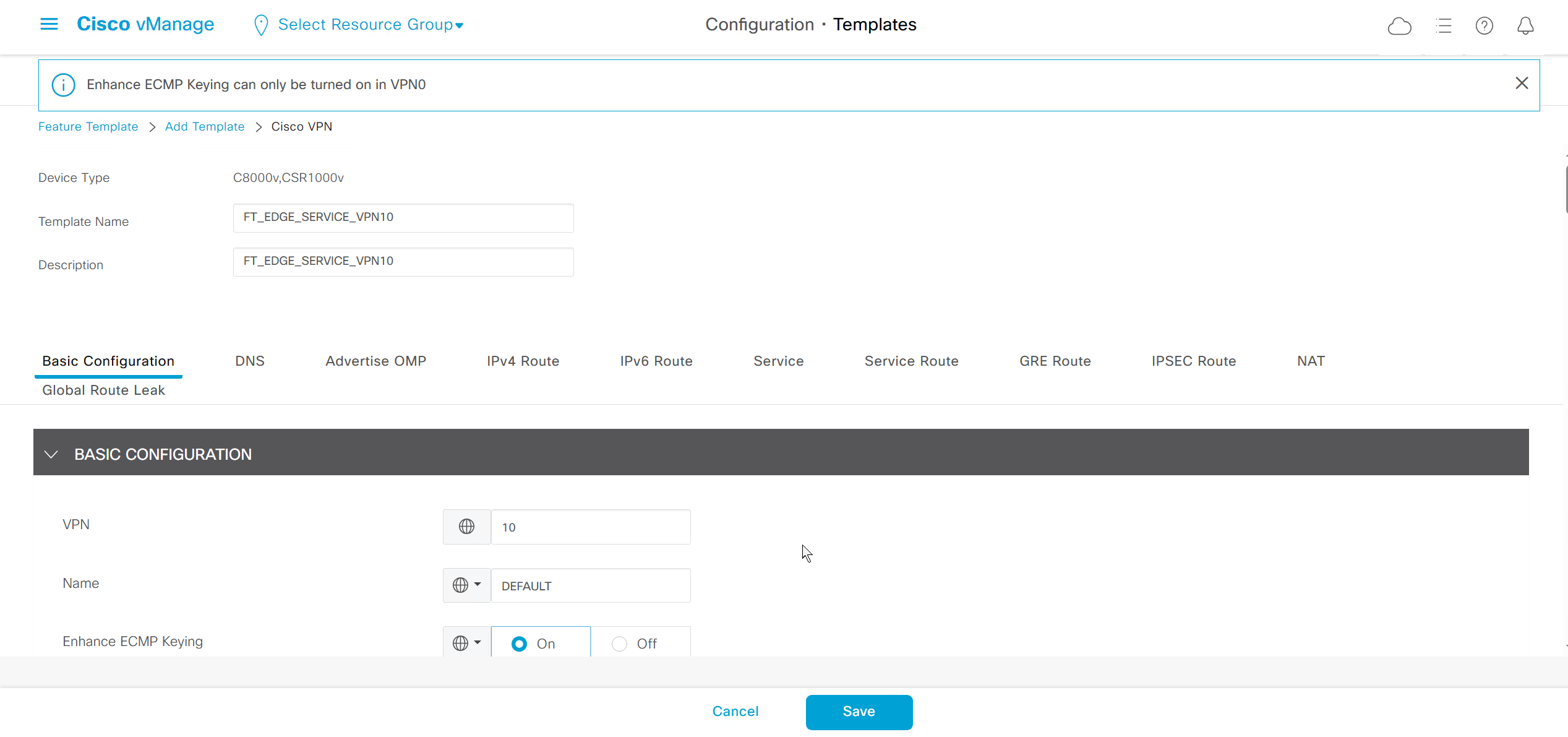
This is to redistribute connected routes in OMP
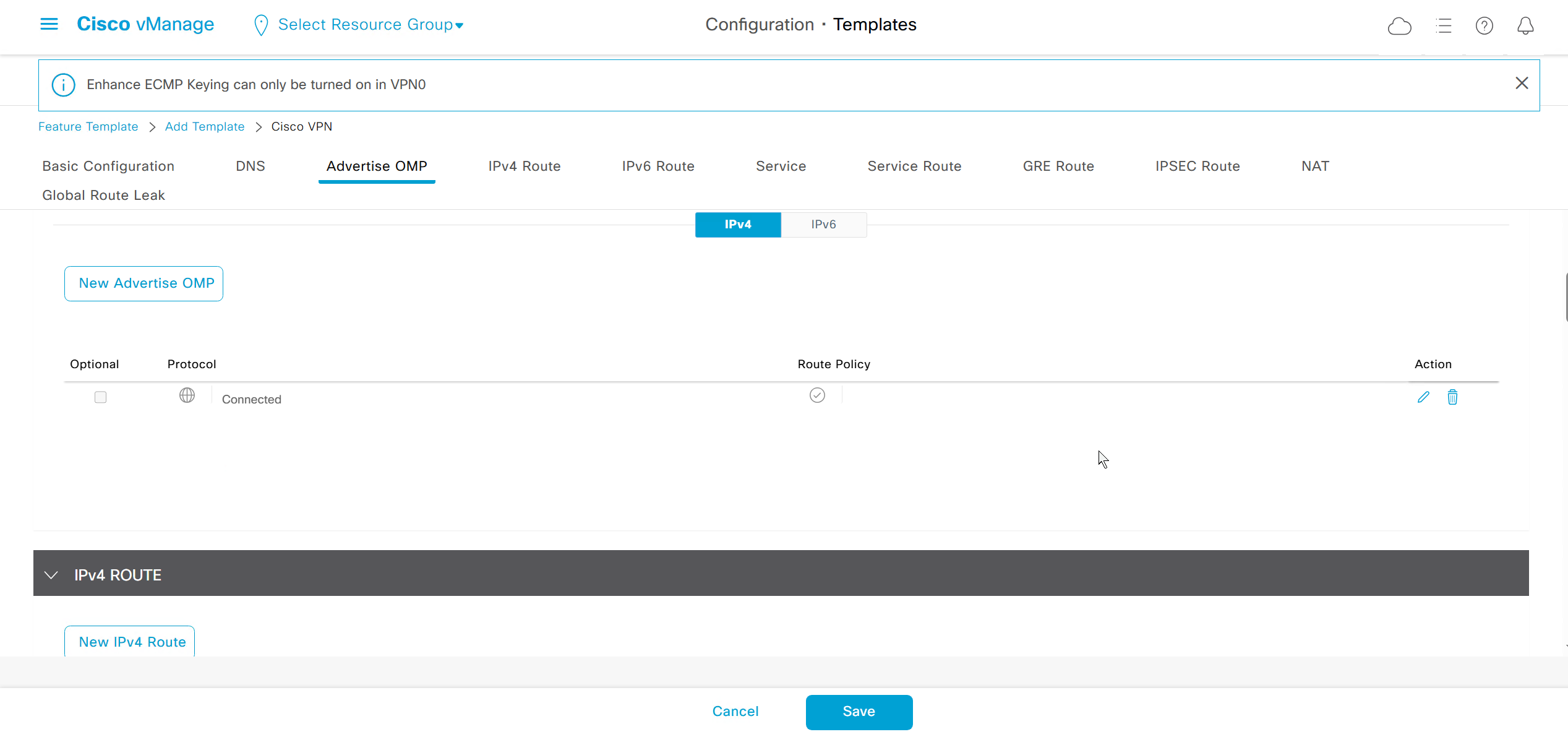
This is to redistribute static routes in OMP
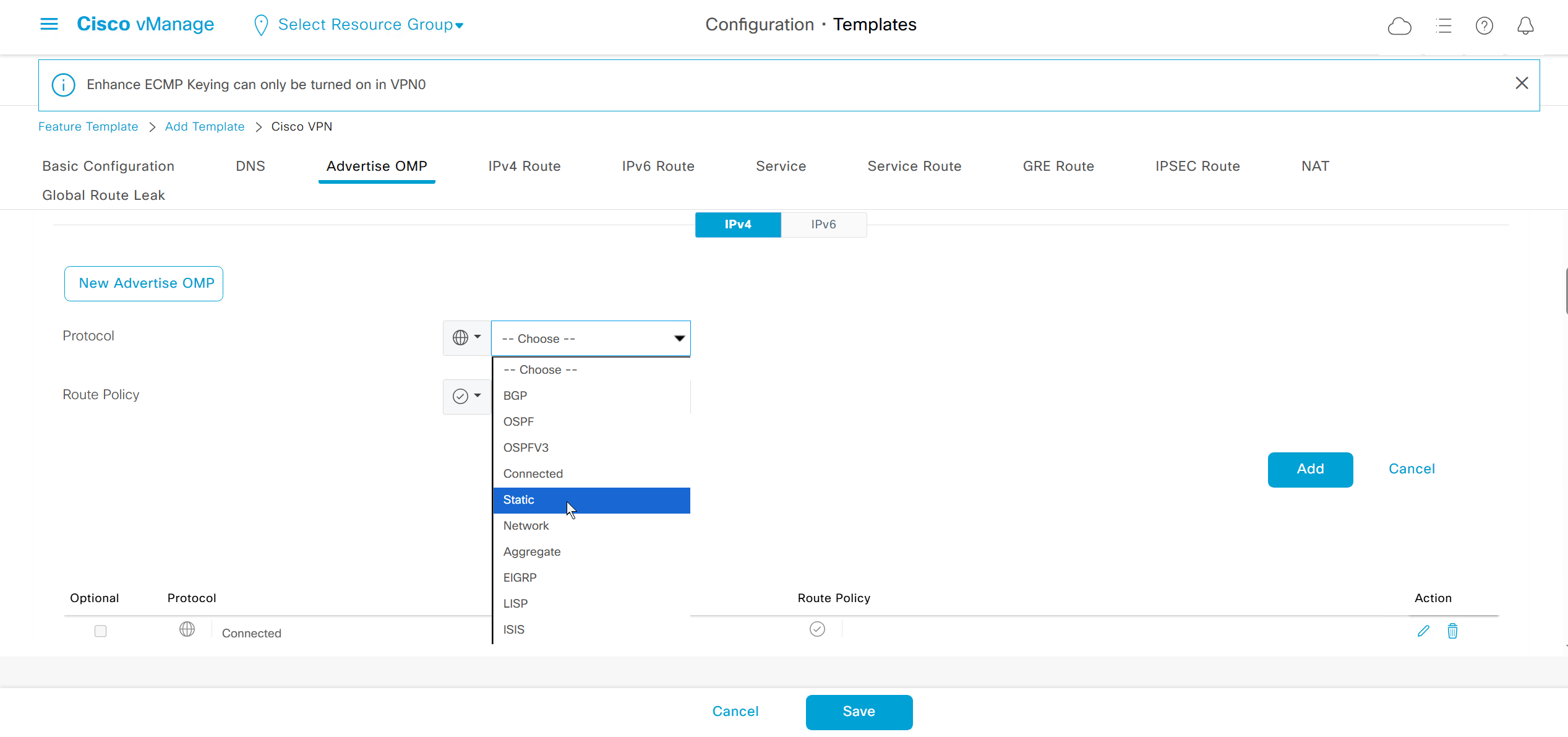
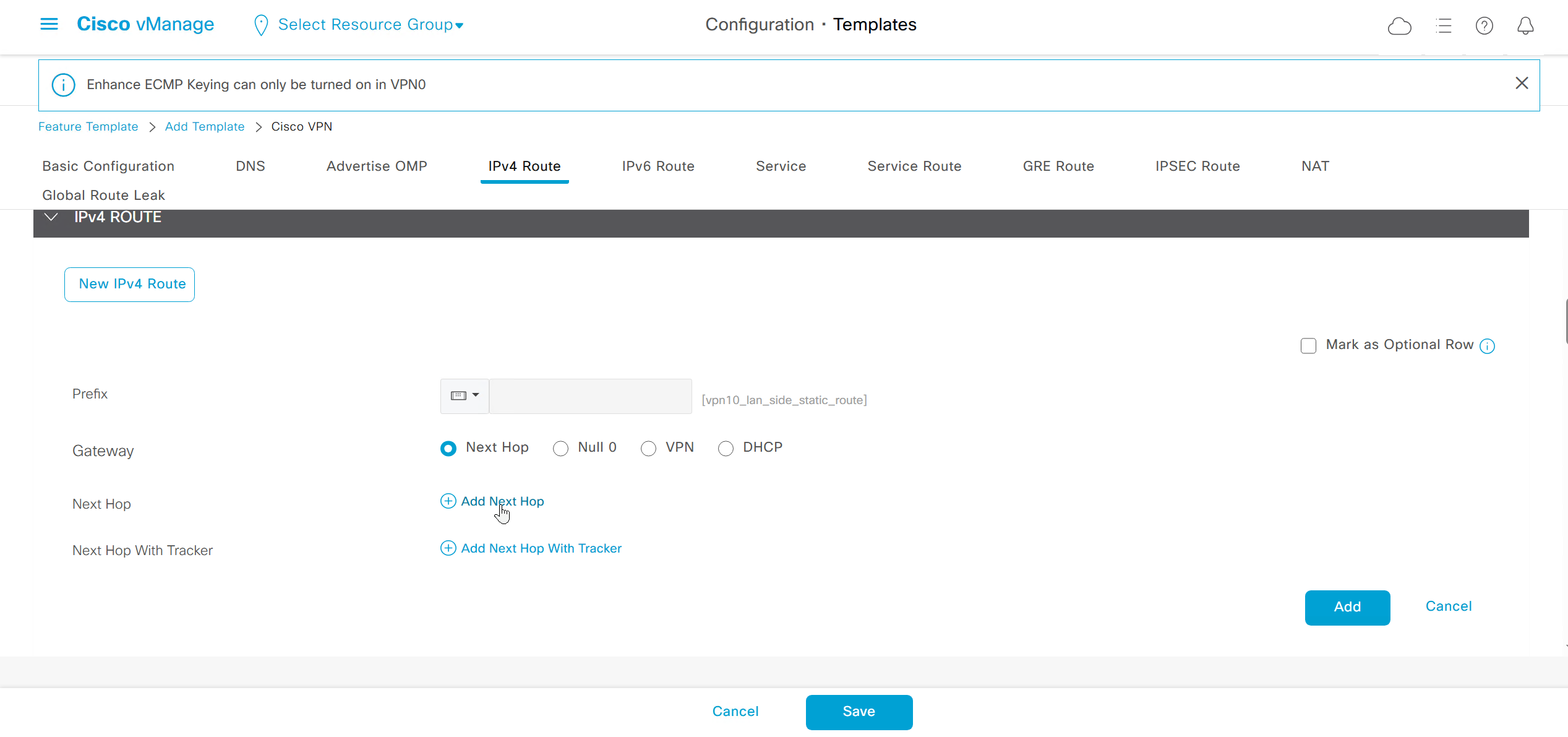
These IPv4 routes are for pointing at the LAN side networks
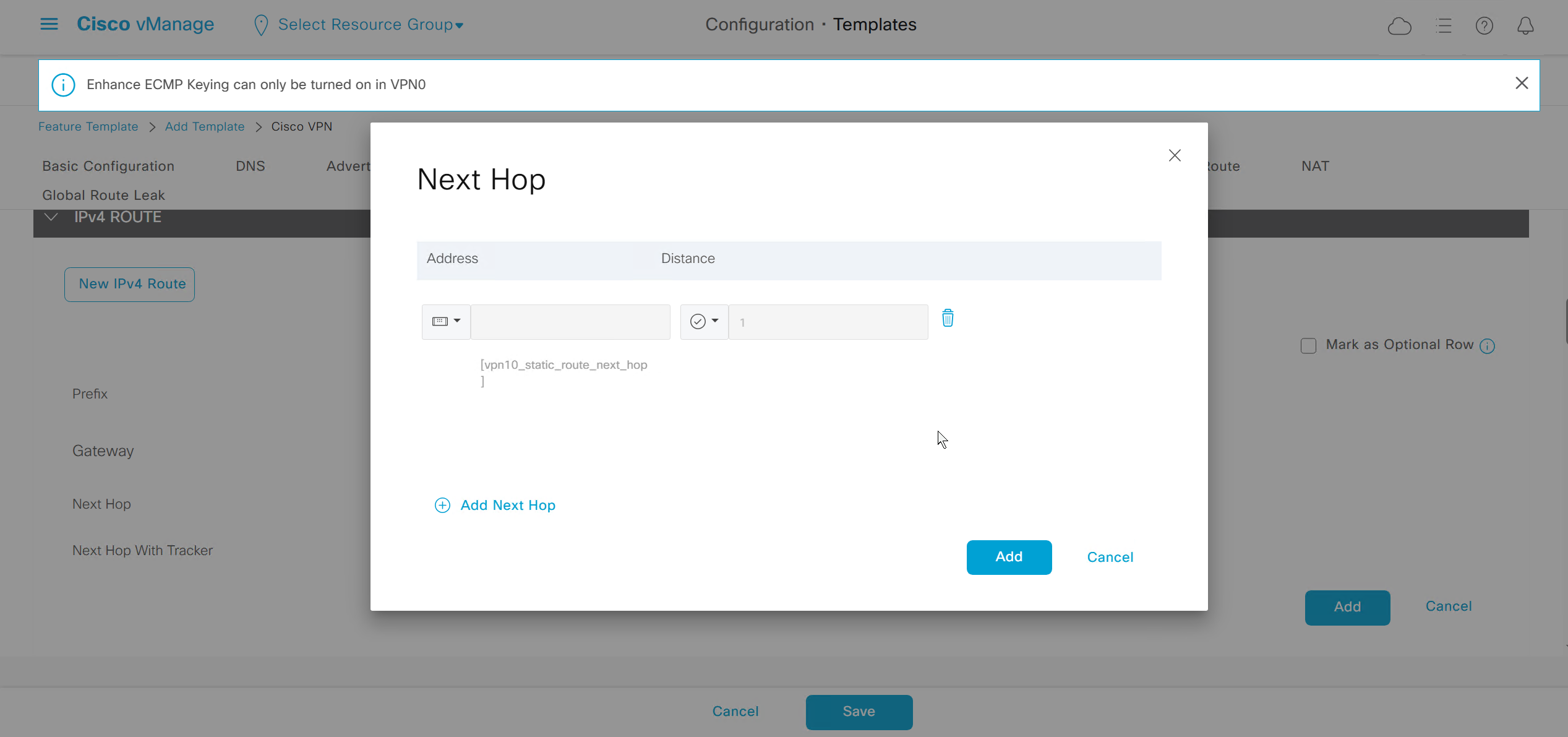
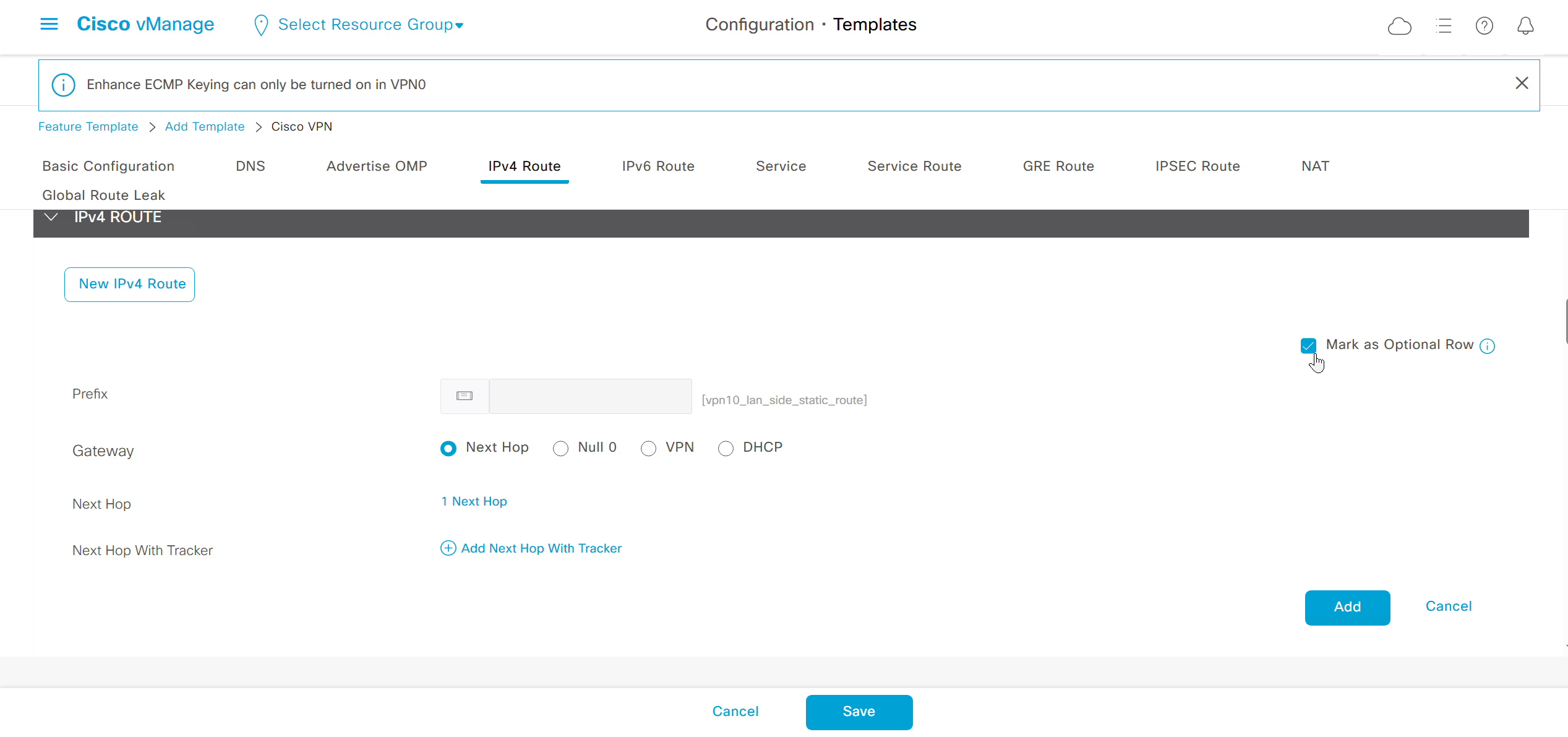
ECMP Keyring can only be turned on in VPN0
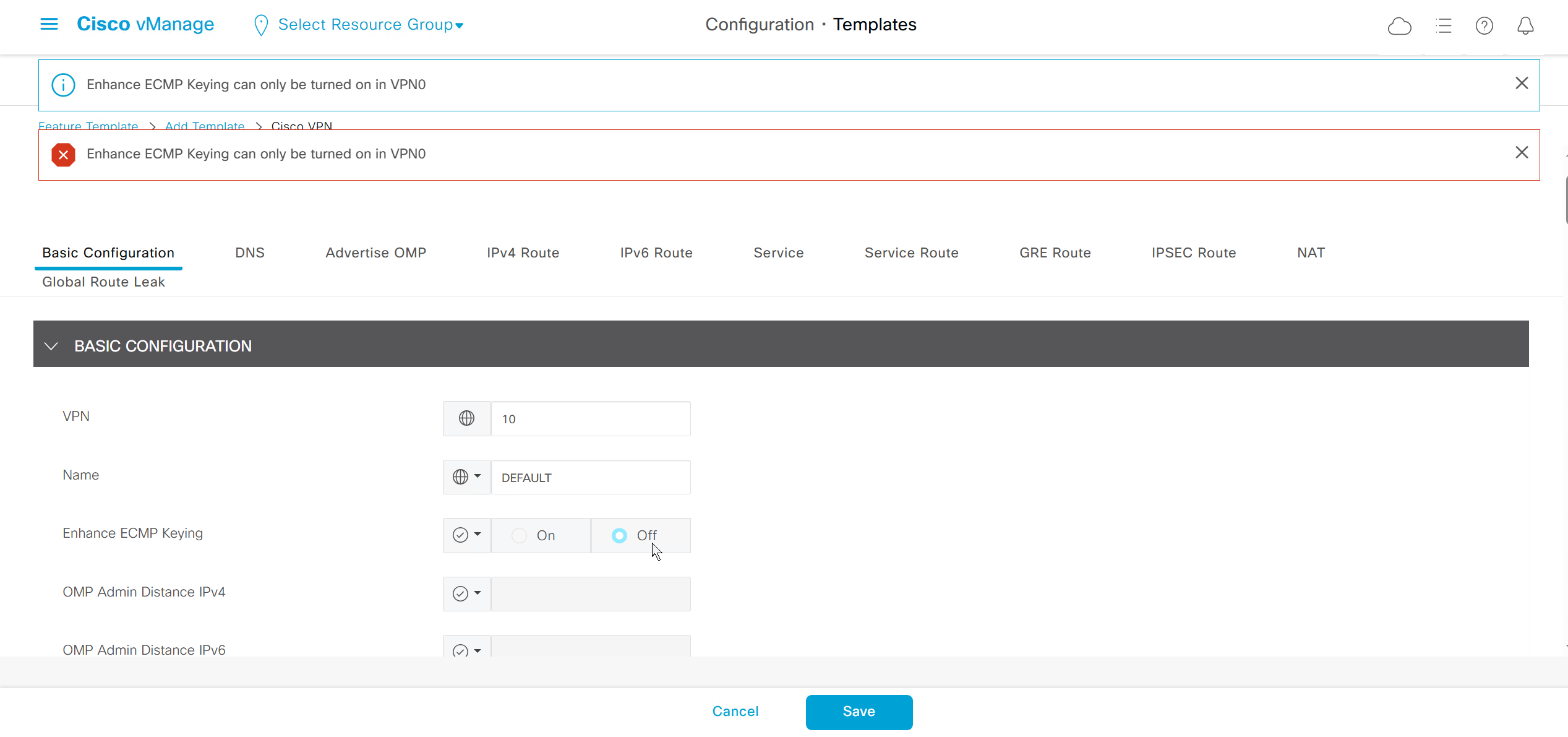
Create following new VPN Ethernet Interface Feature templates
Create Physical Interface GIG3 with IP address variable (so sites without dot1q switch can operate such as Branch 1)
Create Physical Interface GIG3 without IP address so sites like Branch 2 and Branch 3 can do trunk interface on router with dot1q switch
and finally create dot1q interface for Vlan 10 GIG3.10 with IP address and reduced MTU of 1496 to compensate for VLAN header on trunk
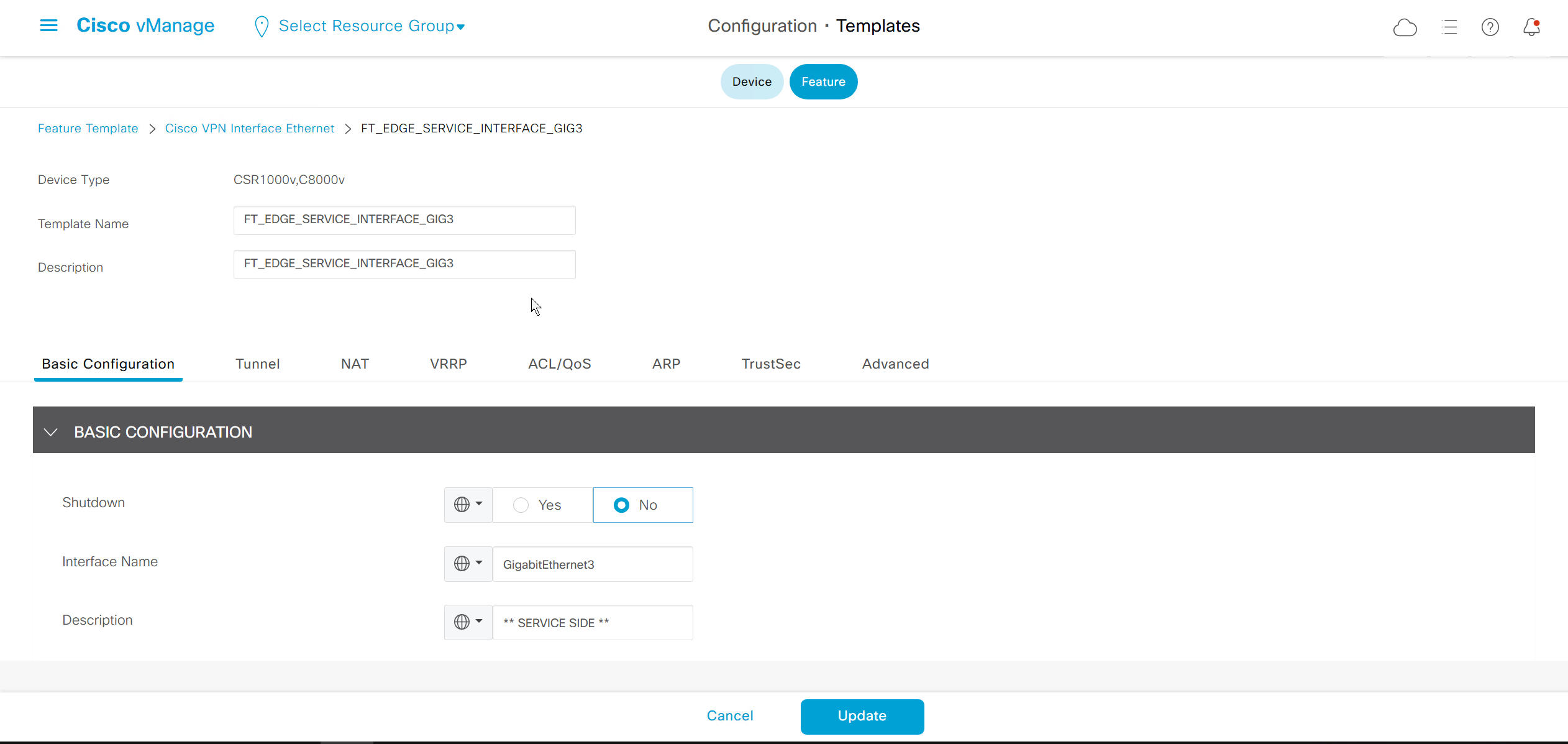
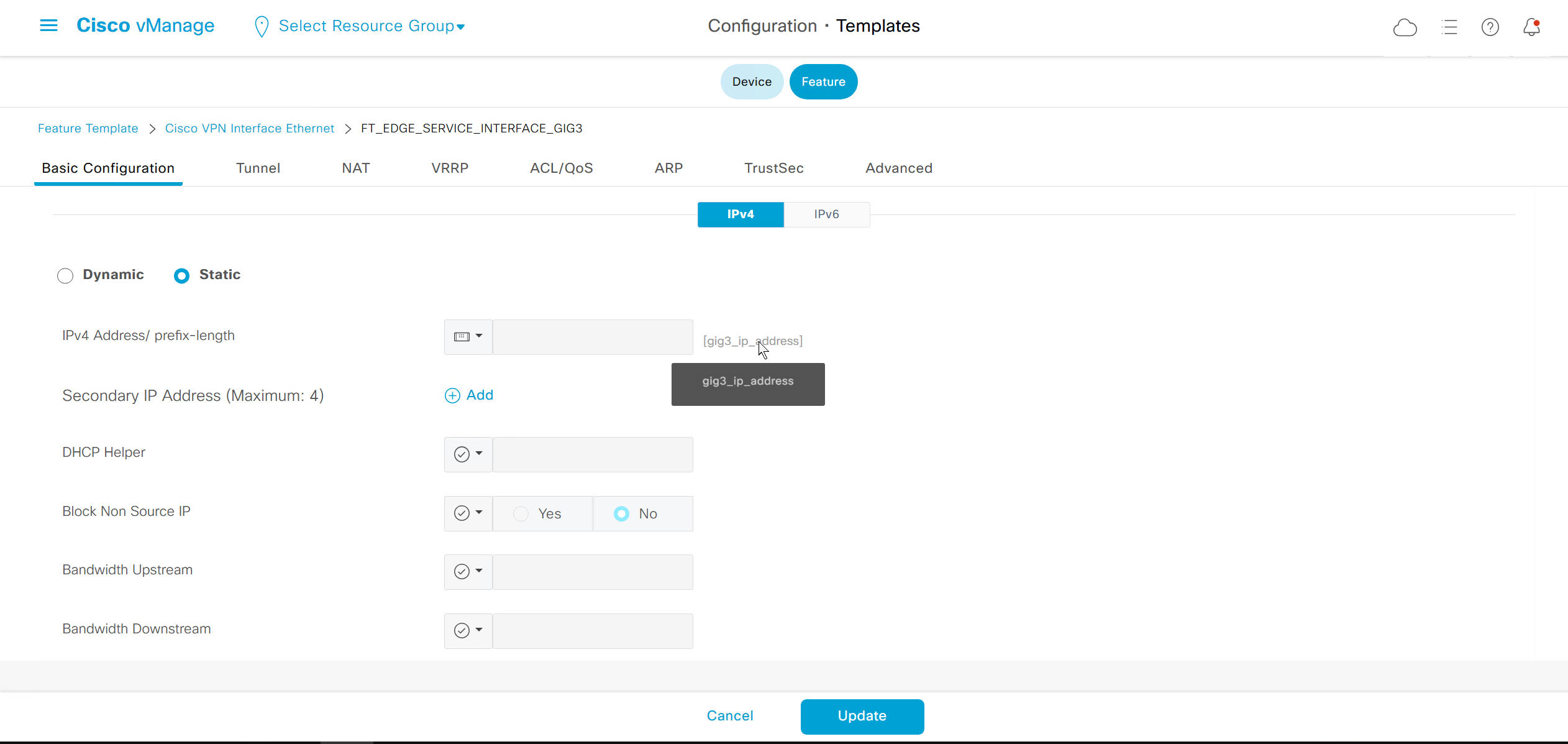
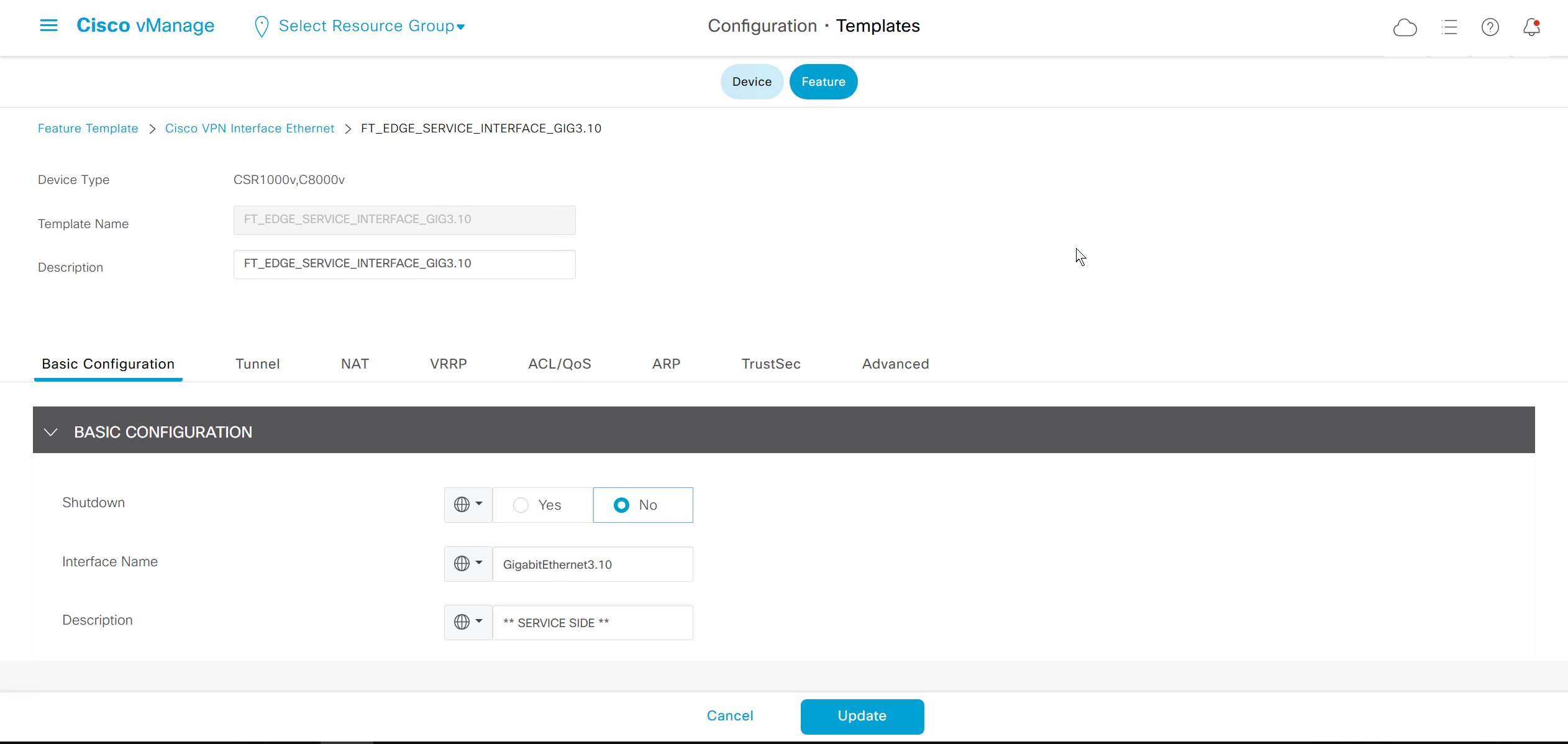
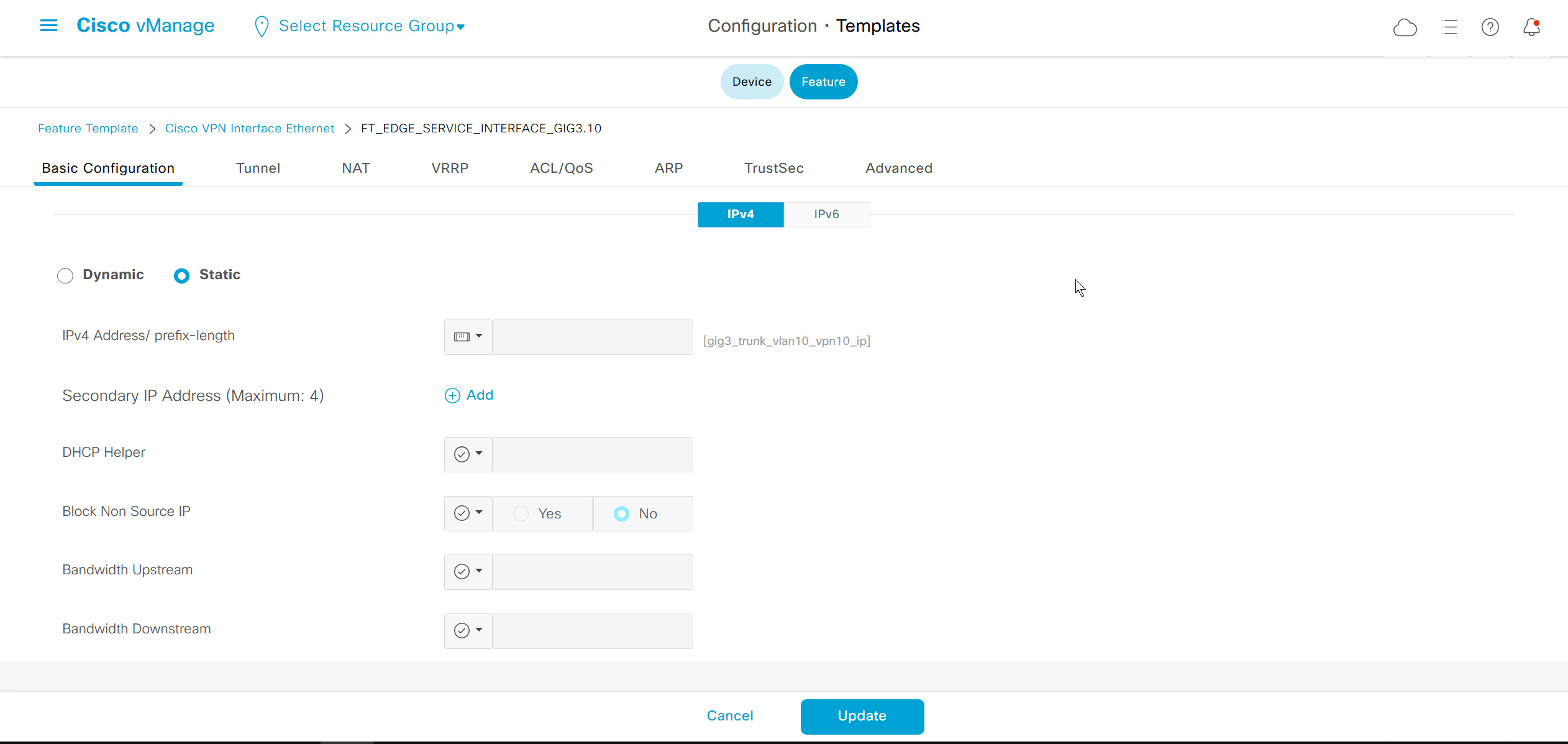
reduce the MTU to 1496
for dot1q interfaces we need to have Physical interface but without IP under VPN 0
and dot1q interface under service VPN
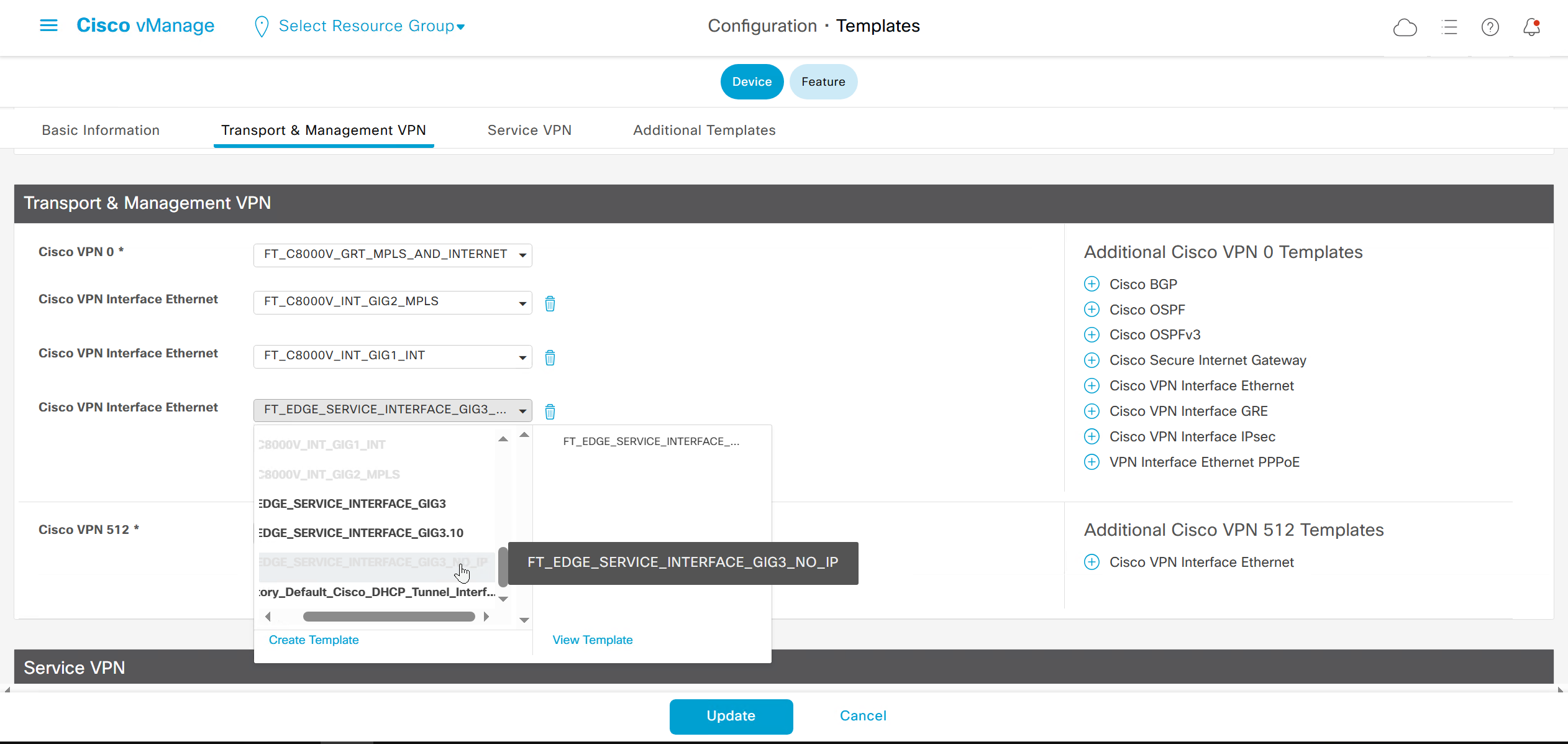
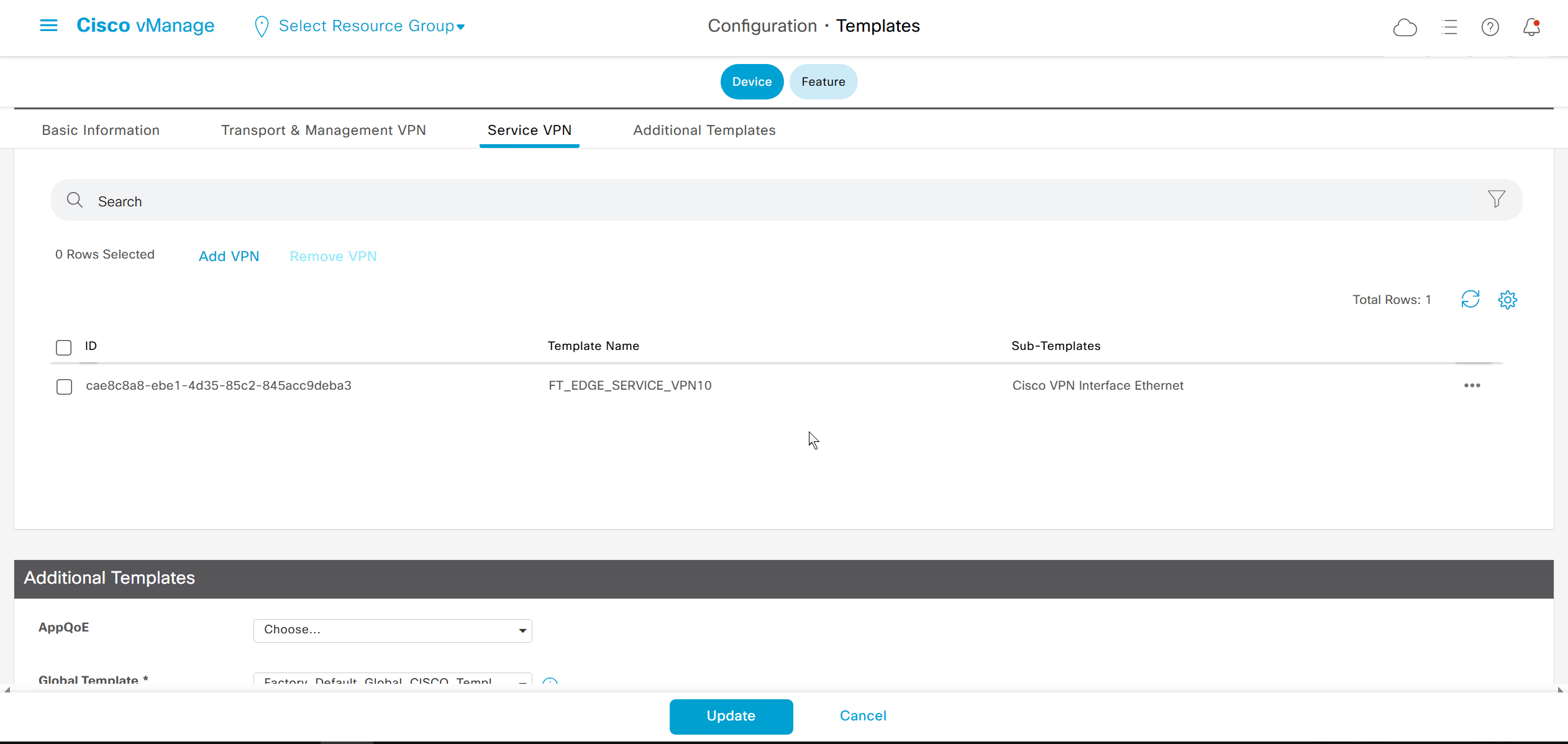
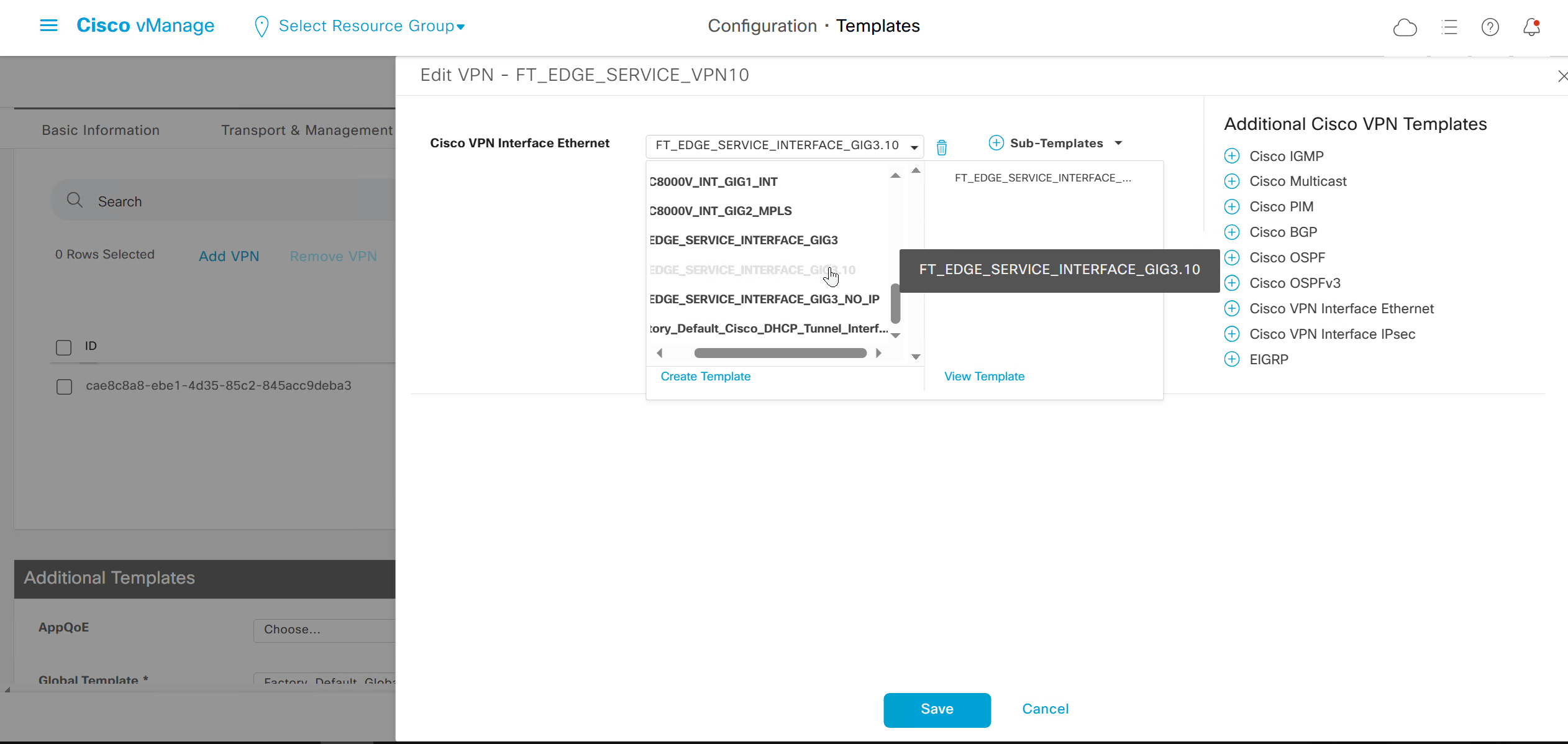
VPCS> ip 172.17.3.10 /25 172.17.3.1
Checking for duplicate address...
VPCS : 172.17.3.10 255.255.255.128 gateway 172.17.3.1
VPCS> ping 172.17.3.1
172.17.3.1 icmp_seq=1 timeout
84 bytes from 172.17.3.1 icmp_seq=2 ttl=255 time=1.393 ms
84 bytes from 172.17.3.1 icmp_seq=3 ttl=255 time=1.470 ms
84 bytes from 172.17.3.1 icmp_seq=4 ttl=255 time=1.429 ms
84 bytes from 172.17.3.1 icmp_seq=5 ttl=255 time=1.350 ms
VPCS> ping 172.17.3.10
172.17.3.10 icmp_seq=1 ttl=64 time=0.001 ms
172.17.3.10 icmp_seq=2 ttl=64 time=0.001 ms
172.17.3.10 icmp_seq=3 ttl=64 time=0.001 ms
172.17.3.10 icmp_seq=4 ttl=64 time=0.001 ms
172.17.3.10 icmp_seq=5 ttl=64 time=0.001 ms
VPCS> ping 172.17.2.1
84 bytes from 172.17.2.1 icmp_seq=1 ttl=254 time=6.716 ms
84 bytes from 172.17.2.1 icmp_seq=2 ttl=254 time=3.531 ms
84 bytes from 172.17.2.1 icmp_seq=3 ttl=254 time=2.678 ms
84 bytes from 172.17.2.1 icmp_seq=4 ttl=254 time=3.613 ms
84 bytes from 172.17.2.1 icmp_seq=5 ttl=254 time=3.625 ms
VPCS> ping 172.17.2.10
84 bytes from 172.17.2.10 icmp_seq=1 ttl=62 time=5.851 ms
84 bytes from 172.17.2.10 icmp_seq=2 ttl=62 time=2.274 ms
84 bytes from 172.17.2.10 icmp_seq=3 ttl=62 time=3.498 ms
84 bytes from 172.17.2.10 icmp_seq=4 ttl=62 time=3.398 ms
84 bytes from 172.17.2.10 icmp_seq=5 ttl=62 time=3.495 ms
VPCS>
VPCS> set pcname BR3-CLIENT
BR3-CLIENT>
BR3-CLIENT> save
Saving startup configuration to startup.vpc
. doneBR1-CLIENT> trace 172.17.2.10
trace to 172.17.2.10, 8 hops max, press Ctrl+C to stop
1 *172.17.1.1 0.351 ms 0.194 ms
2 *1.1.1.102 1.300 ms 1.543 ms
3 *172.17.2.10 5.741 ms (ICMP type:3, code:3, Destination port unreachable)BR3-cEdge#show sdwan omp routes
Generating output, this might take time, please wait ...
Code:
C -> chosen
I -> installed
Red -> redistributed
Rej -> rejected
L -> looped
R -> resolved
S -> stale
Ext -> extranet
Inv -> invalid
Stg -> staged
IA -> On-demand inactive
U -> TLOC unresolved
PATH ATTRIBUTE
VPN PREFIX FROM PEER ID LABEL STATUS TYPE TLOC IP COLOR ENCAP PREFERENCE
--------------------------------------------------------------------------------------------------------------------------------------
10 172.17.2.0/25 1.1.255.13 9 1003 C,I,R installed 172.16.0.102 mpls ipsec -
1.1.255.13 10 1003 C,I,R installed 172.16.0.102 biz-internet ipsec -
10 172.17.3.0/25 0.0.0.0 66 1003 C,Red,R installed 172.16.0.103 mpls ipsec -
0.0.0.0 68 1003 C,Red,R installed 172.16.0.103 biz-internet ipsec -BR3-cEdge#show sdwan omp routes 172.17.2.0/25 detail
---------------------------------------------------
omp route entries for vpn 10 route 172.17.2.0/25
---------------------------------------------------
RECEIVED FROM:
peer 1.1.255.13
path-id 9
label 1003
status C,I,R
loss-reason not set
lost-to-peer not set
lost-to-path-id not set
Attributes:
originator 172.16.0.102
type installed
tloc 172.16.0.102, mpls, ipsec
ultimate-tloc not set
domain-id not set
overlay-id 1
site-id 102
preference not set
tag not set
origin-proto connected
origin-metric 0
as-path not set
community not set
unknown-attr-len not set
RECEIVED FROM:
peer 1.1.255.13
path-id 10
label 1003
status C,I,R
loss-reason not set
lost-to-peer not set
lost-to-path-id not set
Attributes:
originator 172.16.0.102
type installed
tloc 172.16.0.102, biz-internet, ipsec
ultimate-tloc not set
domain-id not set
overlay-id 1
site-id 102
preference not set
tag not set
origin-proto connected
origin-metric 0
as-path not set
community not set
unknown-attr-len not setBR3-cEdge#routing-context vrf 10
BR3-cEdge%10#ping 172.17.3.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.17.3.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
BR3-cEdge%10#ping 172.17.3.10
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.17.3.10, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/2 ms
BR3-cEdge%10#ping 172.17.2.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.17.2.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/3 ms
BR3-cEdge%10#ping 172.17.2.10
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.17.2.10, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 2/3/6 ms
BR3-cEdge%10#exitnext post
SDWAN LM Notes 2
SDWAN Licensing
DNA C/P – Cloud managed or On-prem
Bandwidth Tier is the bandwidth offered on edge devices by license starting from 50Mbps to 20Gbps aggregate (bandwidth combined uploads and download bandwidths of all interfaces)
for example if you have 2 circuits of 100Mbps speed from ISP, your aggregate for WAN only will be 400Mbps – 200Mbps for one circuit and 200Mbps for another circuit and in that case we will need Tier 1 license offering 400Mbps of aggregate bandwidth
Then comes the DNA packages such as Essentials, Advantage and Premier
Essentials cover most of the SDWAN features needed and recently cisco has also moved some features down from Advantage into Essentials package in order to stay competitive
HSEC is something we need to keep an eye out for
Higher end routers will come with higher HSEC tier but still good to verify what is on the device
For larger environments it is good to get Cisco Enterprise Agreement as we can get a better deal on hundreds of edge devices
Recommended resources for vManage and controller numbers / sizing
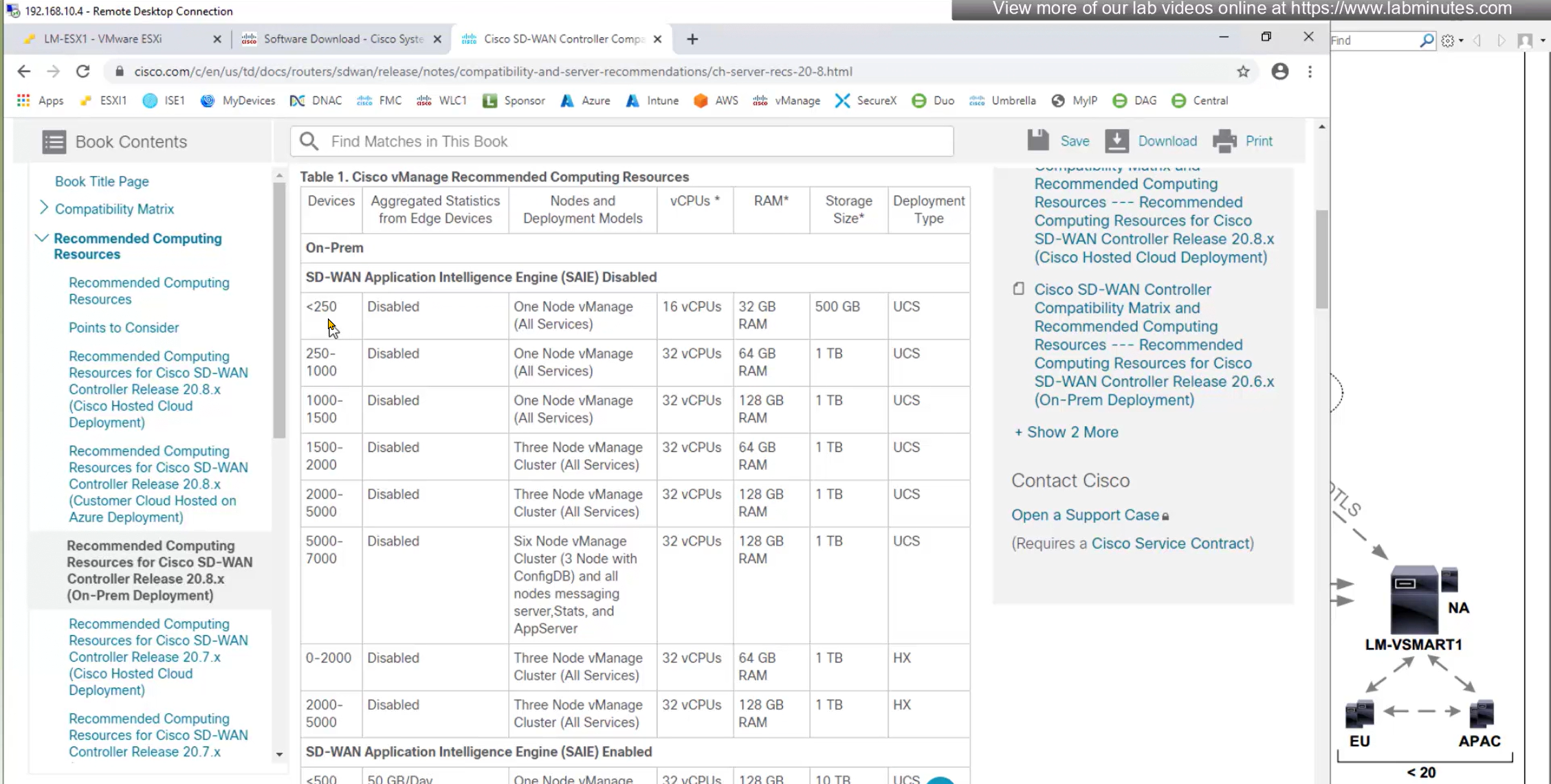
This starts by defining how many edge devices we have in the deployment and based on number of edge devices guide suggests to have vCPUs / RAM and additional VMs needed
Less than 1500 edge nodes will need 1 vManage, anything above 1500 edge nodes will require 3x vManage VMs
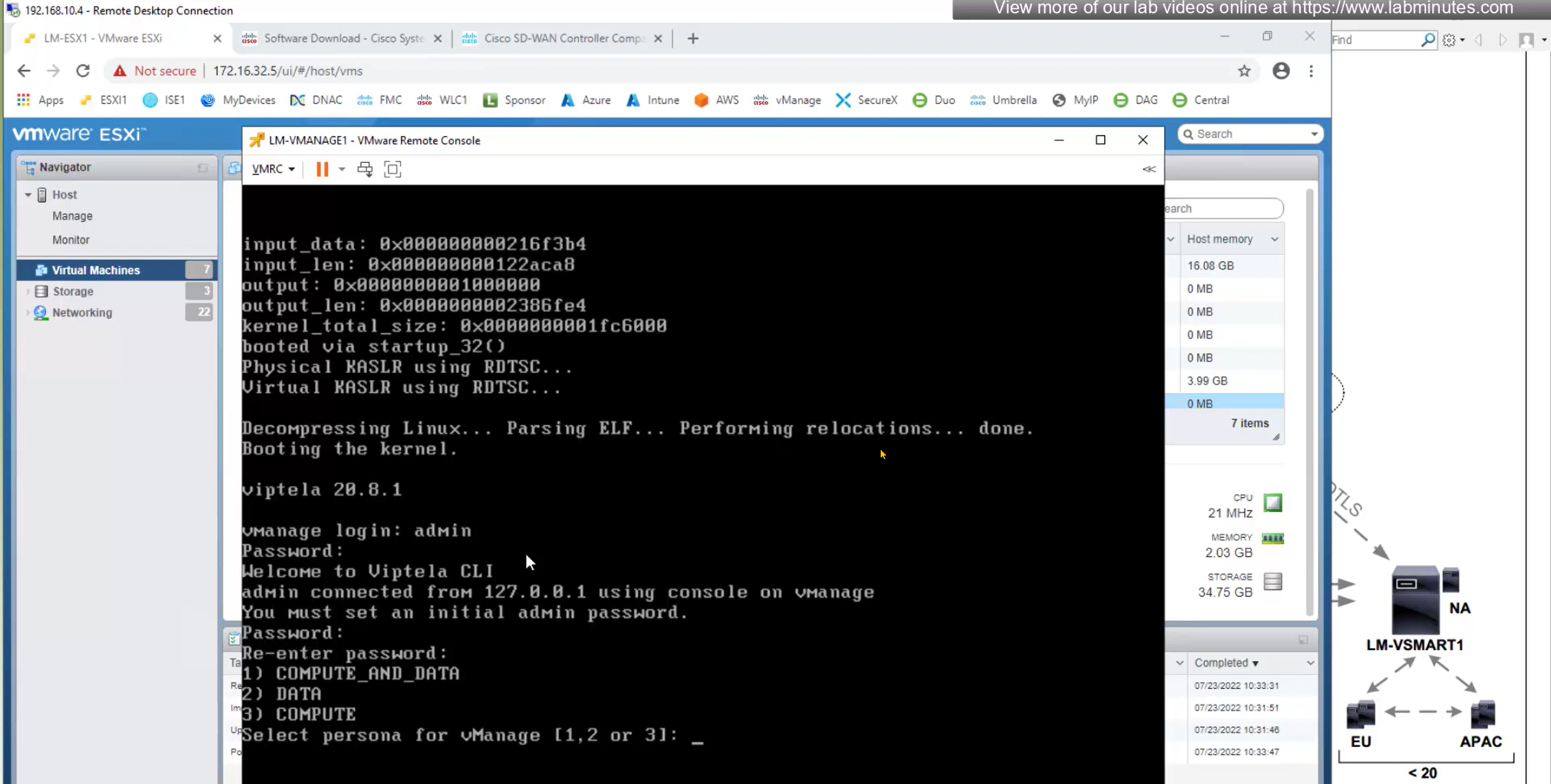
All services is a persona on vManage called COMPUTE_AND_DATA which is basically all services
A vManage with just a COMPUTE persona will only run vManage application, configuration and messaging but no Data statistics and vManage with with DATA stores statistics and data
Download software from cisco.com
we will select ova for ESXi VM
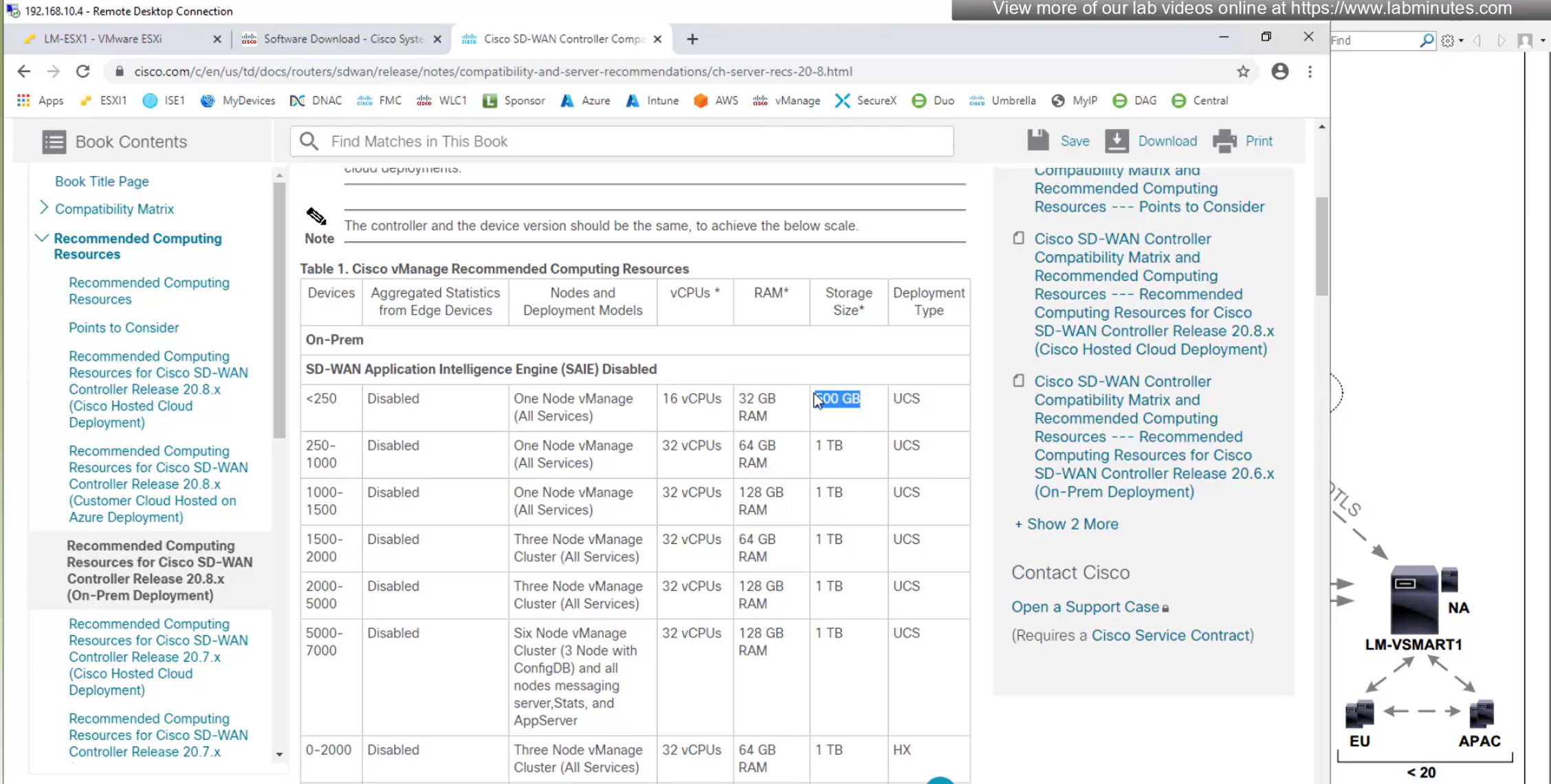
From version 20.8 onwards vManage minimum requires 500GB
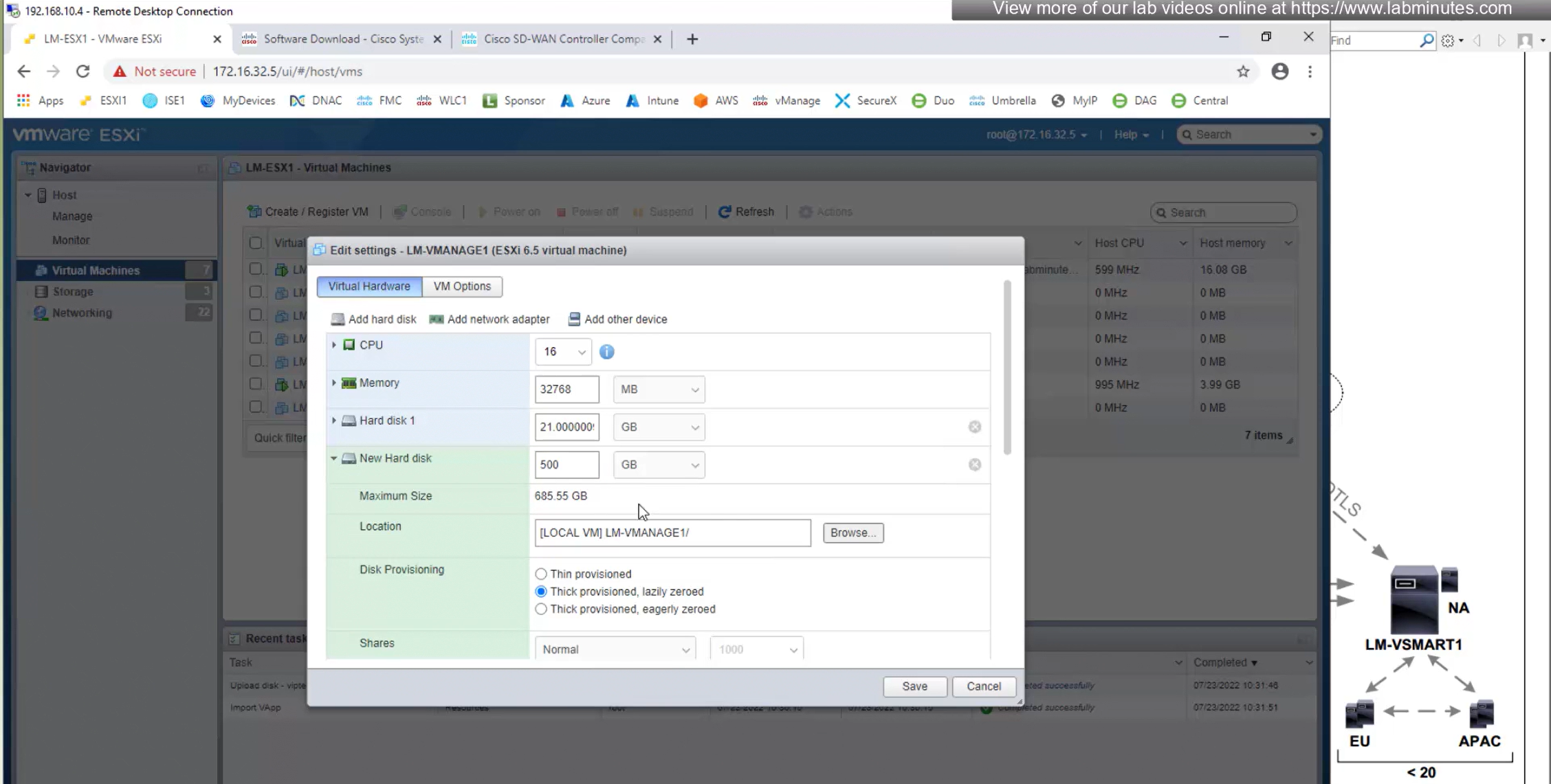
and for new version of vManage – controller type should be SCSI and not IDE
make sure that organistaion matches exactly as mentioned in Cisco smart account otherwise there will be sync issues
BFD polling
Default BFD polling is 1000 msec or 1 sec
OMP parameters
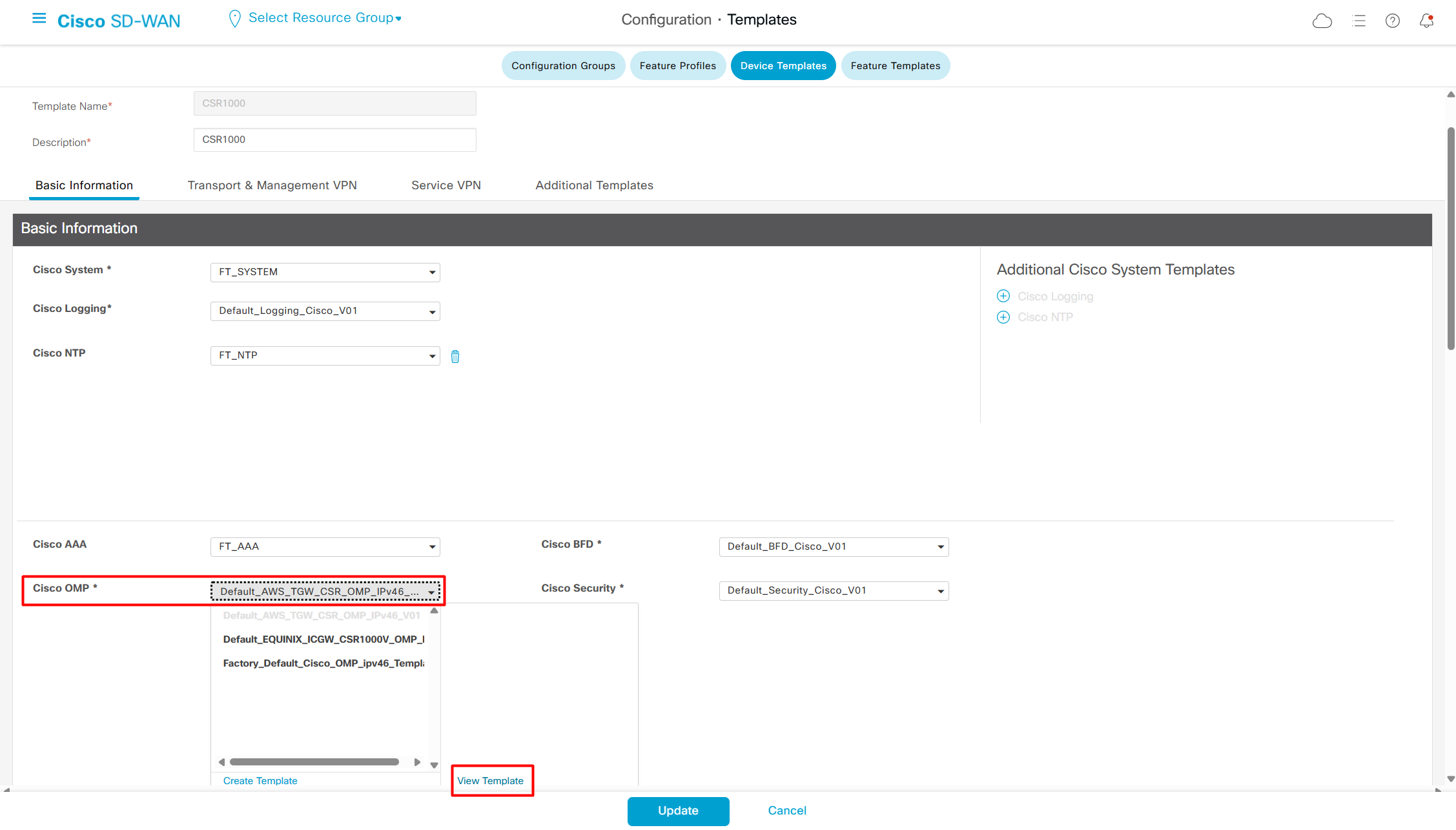
If you ever have to make changes in OMP such as increase ECMP limit then perform it here
OMP timers
Shows what kind or routes are injected into OMP by default
Create loopback on MPLS routers and then advertise it on Transport side using BGP
Loopback interface
MPLS interface
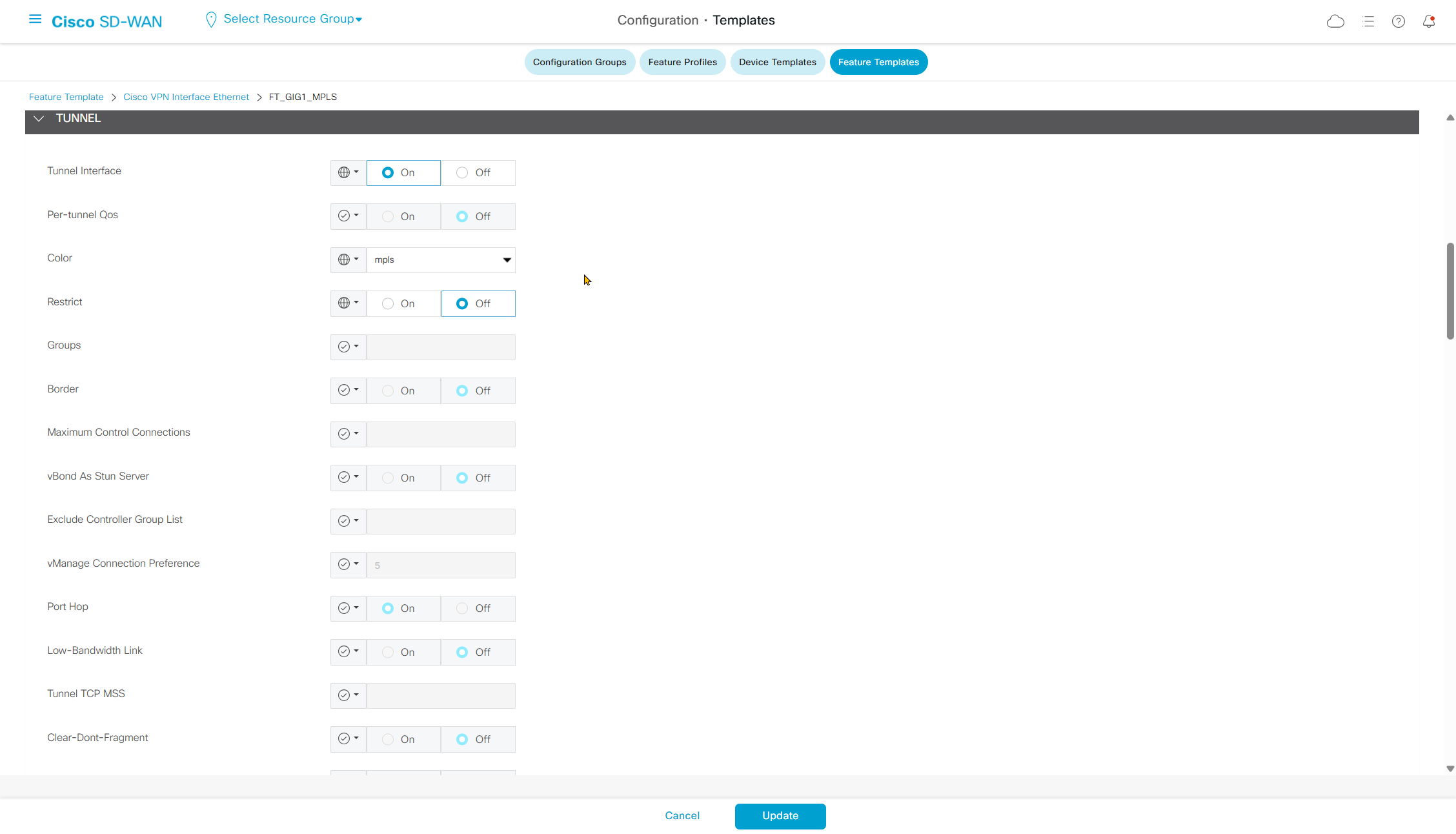
Make sure color is set under tunnel section
Also make sure that Allow service all is enabled, otherwise BGP did not come up and I was troubleshooting it for long time, when testing telnet at port 179 I realised SDWAN router is not sending TCP response back to switch
BGP Configuration
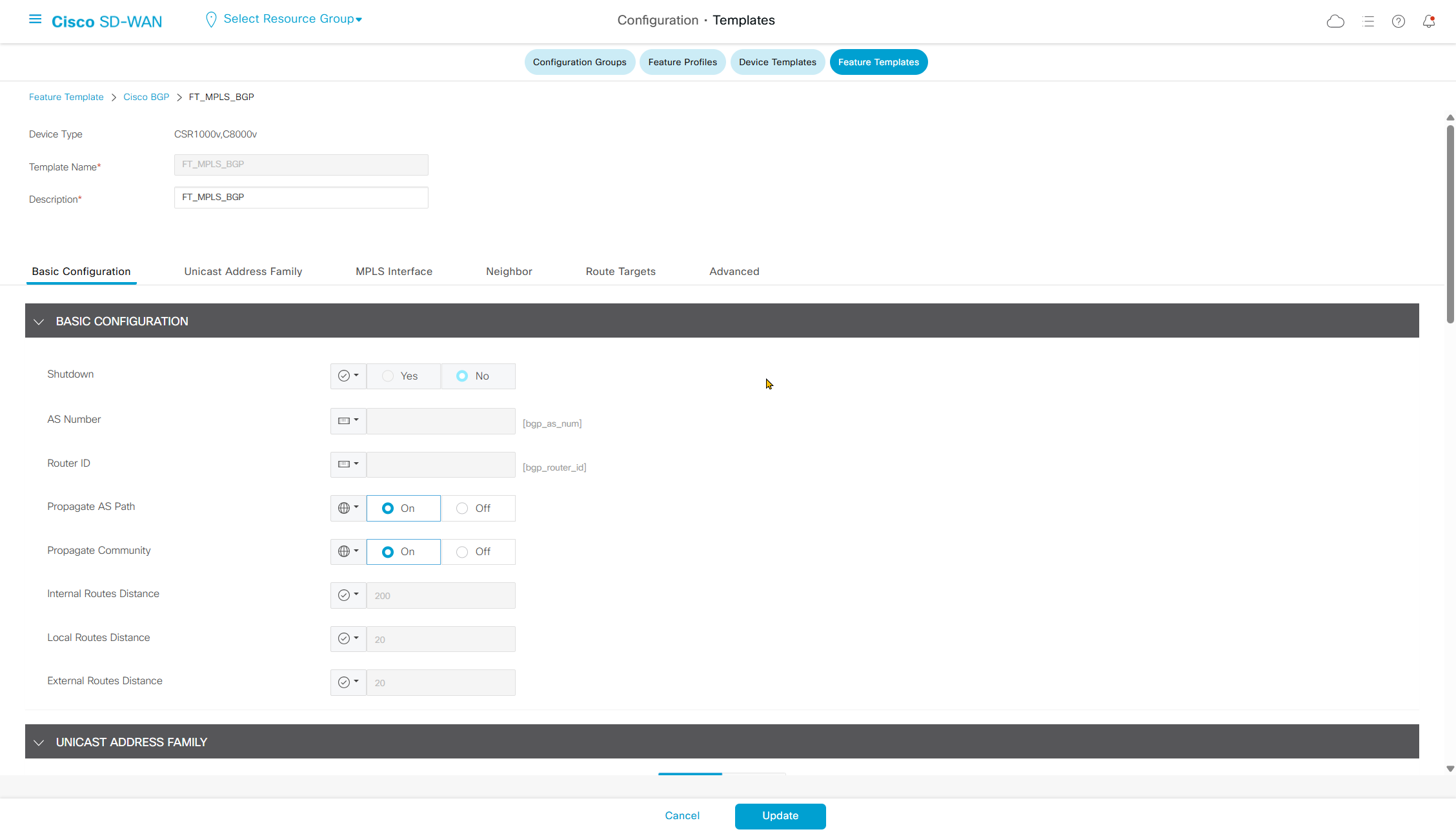
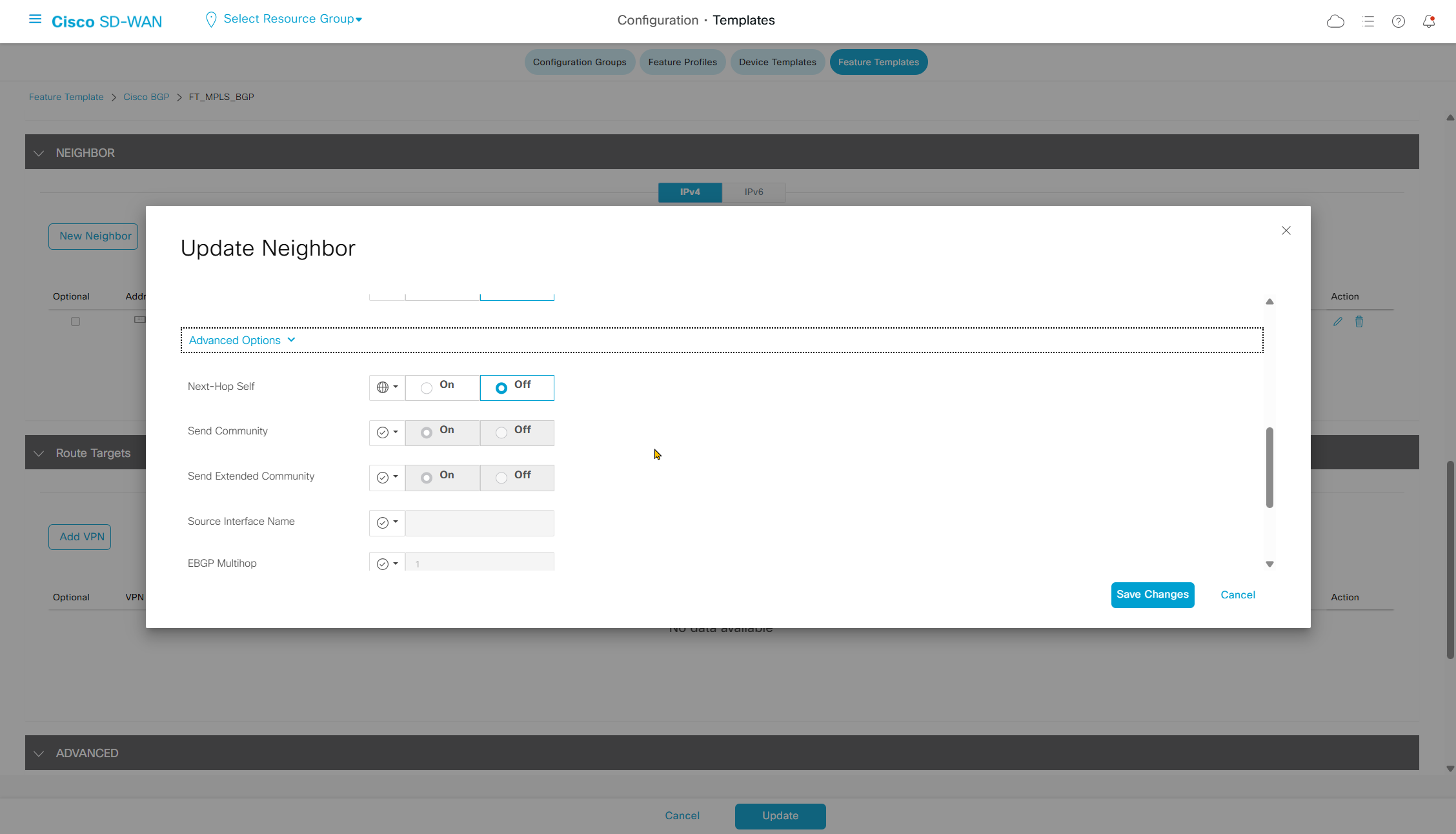
MPLS#show run
Building configuration...
Current configuration : 2669 bytes
!
! Last configuration change at 02:42:24 UTC Mon Mar 9 2026
!
version 17.12
service timestamps debug datetime msec
service timestamps log datetime msec
!
hostname MPLS
!
boot-start-marker
boot-end-marker
!
!
no aaa new-model
!
!
!
!
!
!
!
!
!
!
!
!
!
ip audit notify log
ip audit po max-events 100
ip cef
login on-success log
no ipv6 cef
!
!
!
!
!
!
!
vtp version 1
multilink bundle-name authenticated
!
!
!
!
memory free low-watermark processor 80589
!
!
spanning-tree mode rapid-pvst
spanning-tree extend system-id
!
!
vlan internal allocation policy ascending
!
!
!
!
!
interface Ethernet0/0
description INTERNET SW
no switchport
ip address 172.31.255.253 255.255.255.252
ip ospf 1 area 1
!
interface Ethernet0/1
no switchport
ip address 172.31.255.249 255.255.255.252
ip ospf 1 area 1
!
interface Ethernet0/2
no switchport
ip address 172.31.255.245 255.255.255.252
ip ospf 1 area 1
!
interface Ethernet0/3
no switchport
ip address 172.31.255.241 255.255.255.252
ip ospf 1 area 1
!
interface Ethernet1/0
no switchport
ip address 172.31.255.237 255.255.255.252
ip ospf 1 area 1
!
interface Ethernet1/1
!
interface Ethernet1/2
!
interface Ethernet1/3
!
router ospf 1
router-id 172.31.255.254
redistribute bgp 10
passive-interface default
no passive-interface Ethernet0/0
!
router bgp 10
template peer-policy CE
send-community both
exit-peer-policy
!
template peer-session CE
ebgp-multihop 5
timers 5 10
exit-peer-session
!
bgp log-neighbor-changes
neighbor 172.31.255.238 remote-as 65104
neighbor 172.31.255.238 inherit peer-session CE
neighbor 172.31.255.242 remote-as 65103
neighbor 172.31.255.242 inherit peer-session CE
neighbor 172.31.255.246 remote-as 65102
neighbor 172.31.255.246 inherit peer-session CE
neighbor 172.31.255.250 remote-as 65102
neighbor 172.31.255.250 inherit peer-session CE
!
address-family ipv4
network 172.31.255.236 mask 255.255.255.252
network 172.31.255.240 mask 255.255.255.252
network 172.31.255.244 mask 255.255.255.252
network 172.31.255.248 mask 255.255.255.252
network 172.31.255.252 mask 255.255.255.252
neighbor 172.31.255.238 activate
neighbor 172.31.255.238 inherit peer-policy CE
neighbor 172.31.255.242 activate
neighbor 172.31.255.242 inherit peer-policy CE
neighbor 172.31.255.246 activate
neighbor 172.31.255.246 inherit peer-policy CE
neighbor 172.31.255.250 activate
neighbor 172.31.255.250 inherit peer-policy CE
exit-address-family
!
ip forward-protocol nd
!
!
ip http server
ip http secure-server
ip ssh bulk-mode 131072
!
!
!
!
!
!
control-plane
!
!
!
line con 0
logging synchronous
line aux 0
line vty 0 4
login
transport input ssh
!
!
endTrunking configuration
This is the GIG3 template without IP variable – no IP address so we can configure trunking
This is GIG3.100 interface that will be trunking interface
but reduce the MTU on this interface by 4 bytes to 1496 to accomodate the VLAN tag
Now edit the device template
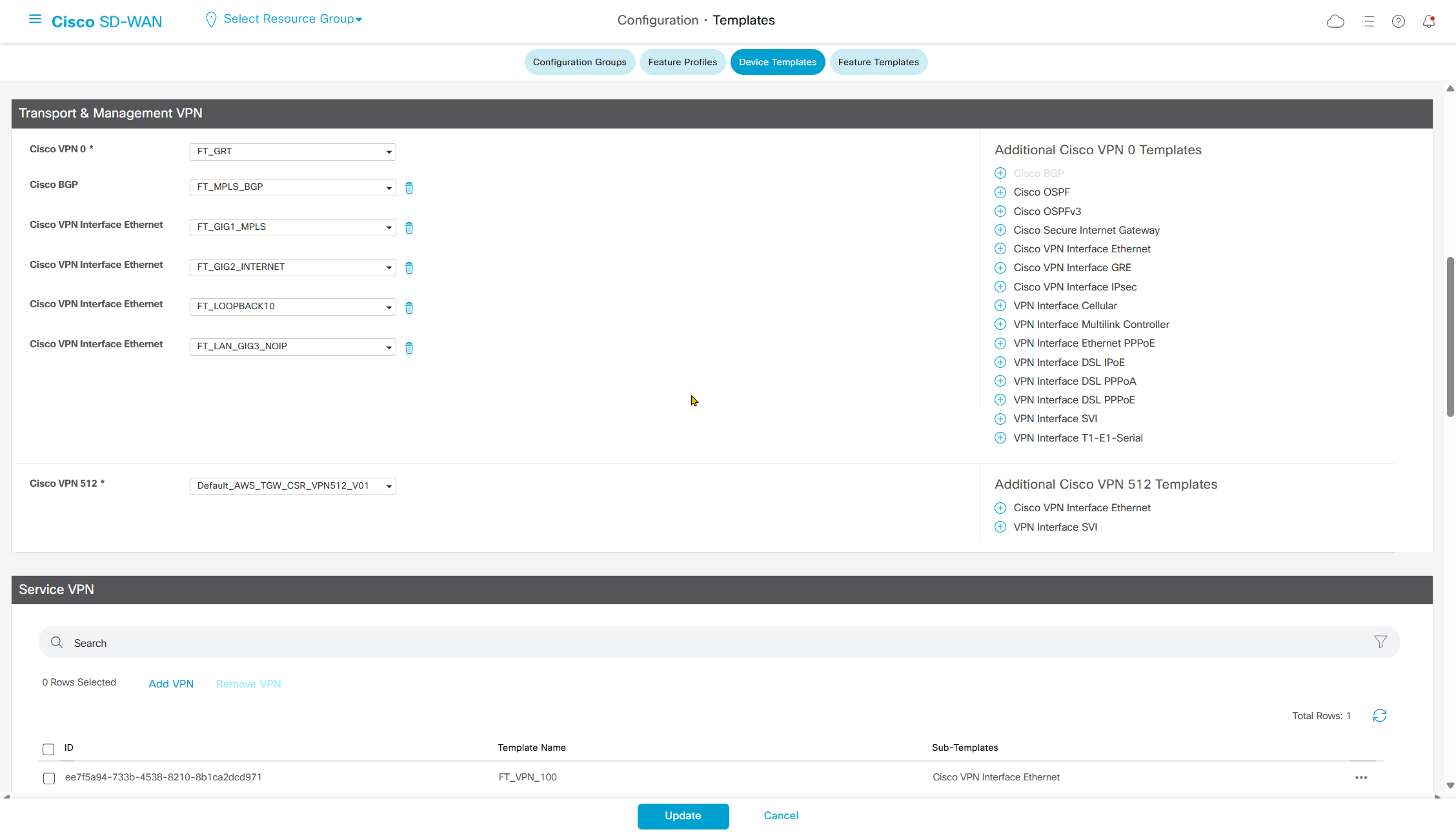
GIG3_NOIP will be assigned to VPN 0 transport VPN
And GIG3.100 will be assigned to the VPN 100 service VPN
VRRP configuration
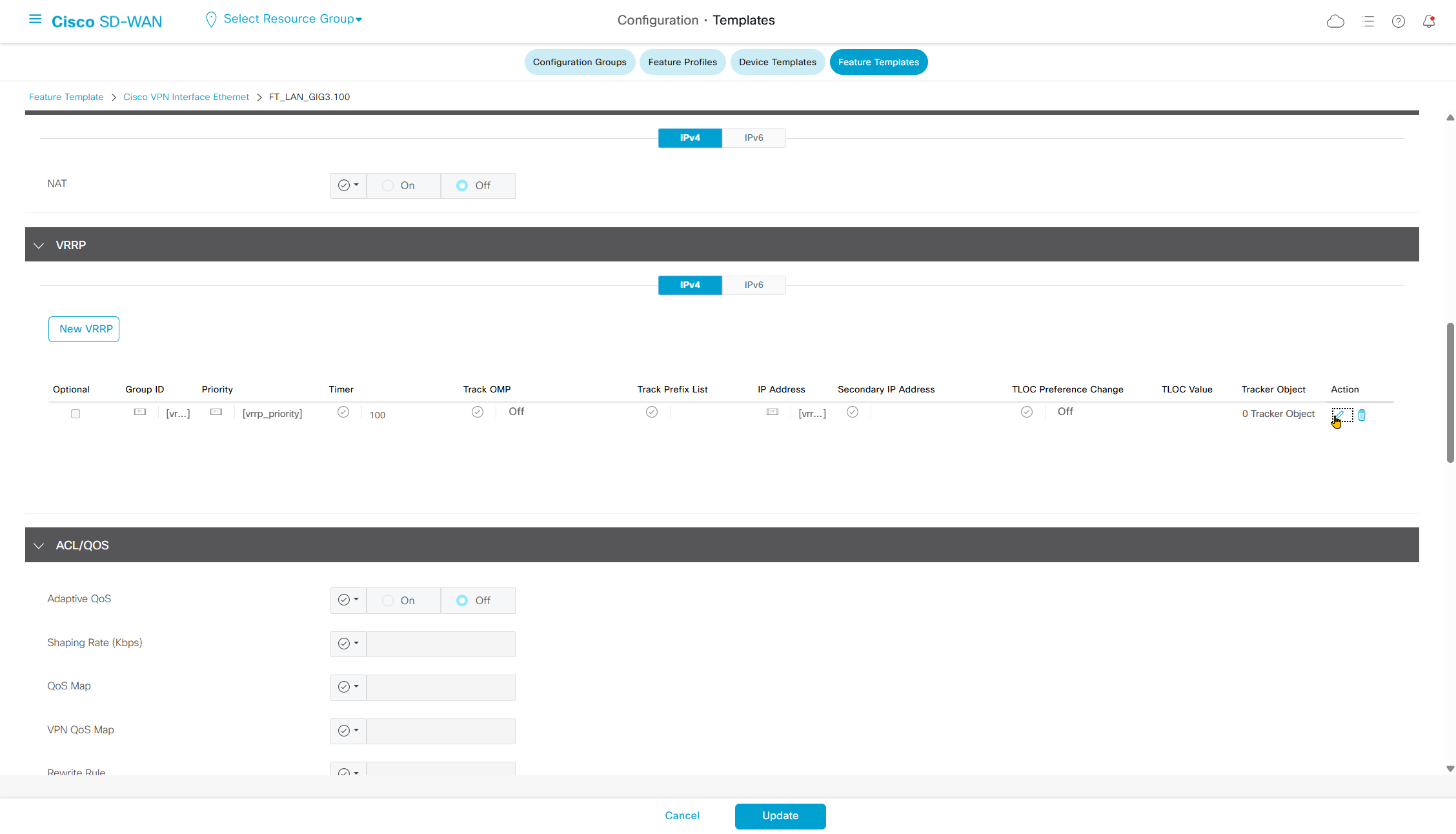
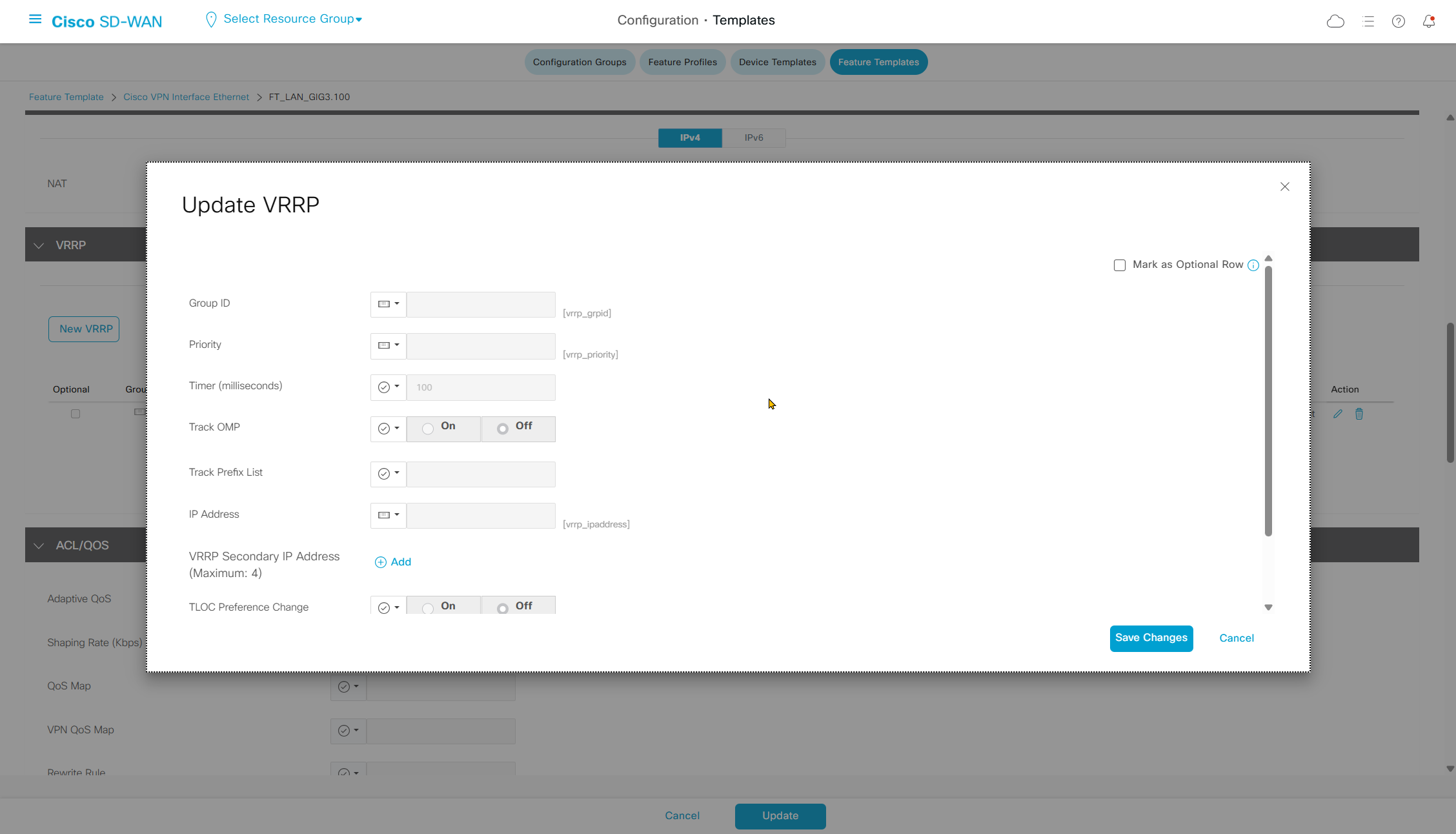
Static route
Make sure that VPN supports redistribution of connected and “static”, if static is not enabled then static route will only be on specific router but rest of the routers or sites will not learn via omp
Also make sure that static route is marked as optional row
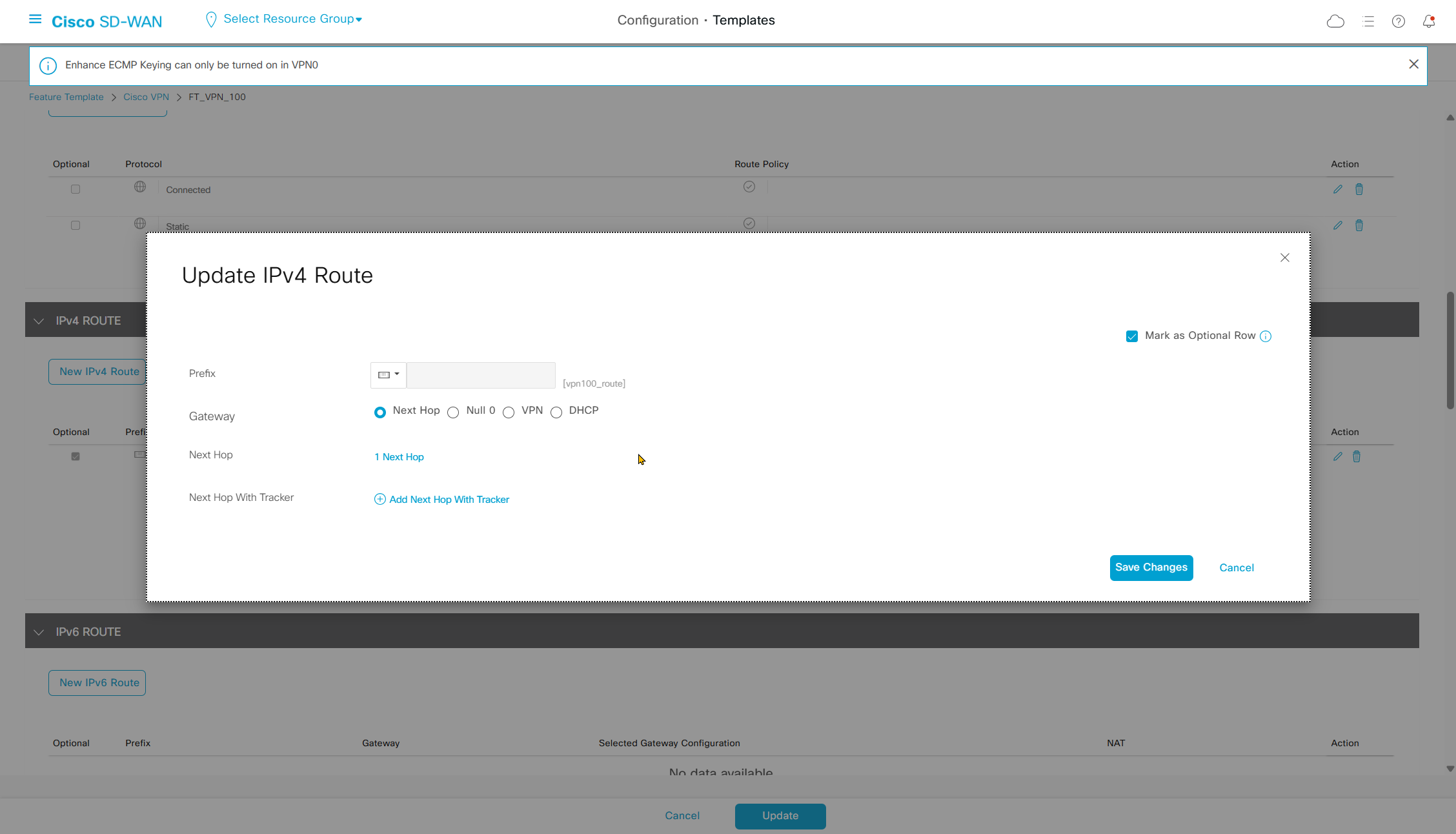
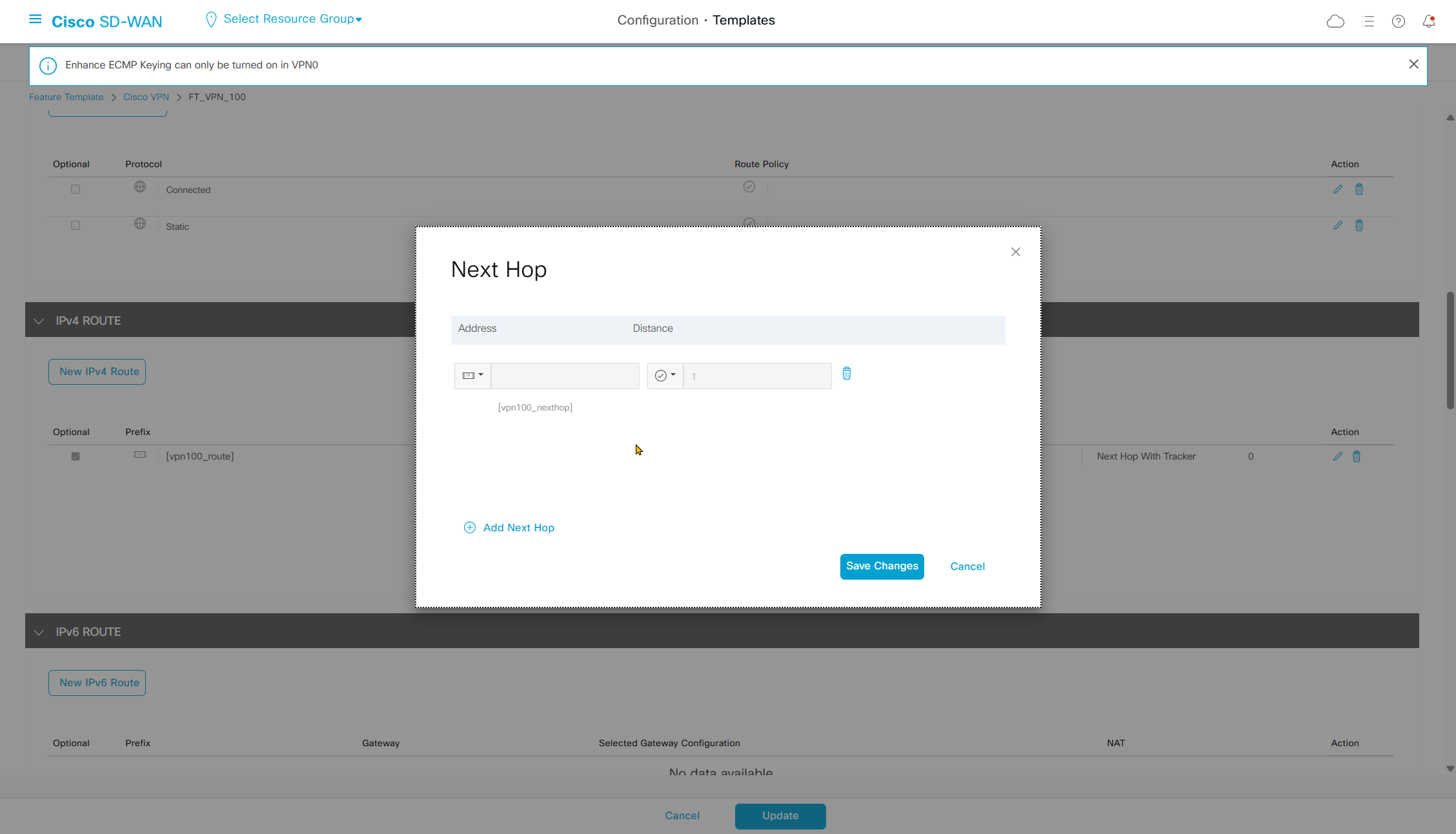
hostname SW-1002
!
interface Ethernet0/0
switchport access vlan 100
switchport trunk encapsulation dot1q
switchport trunk allowed vlan 100
switchport mode trunk
!
interface Ethernet0/1
switchport access vlan 100
switchport trunk encapsulation dot1q
switchport trunk allowed vlan 100
switchport mode trunk
!
interface Vlan100
ip address 172.16.2.11 255.255.254.0
!
interface Vlan200
ip address 172.16.4.1 255.255.254.0
!
ip route 0.0.0.0 0.0.0.0 172.16.2.1
!SW-1002#show ip int brief
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 unassigned YES unset up up
Ethernet0/1 unassigned YES unset up up
Ethernet0/2 unassigned YES unset down down
Ethernet0/3 unassigned YES unset down down
Ethernet1/0 unassigned YES unset down down
Ethernet1/1 unassigned YES unset down down
Ethernet1/2 unassigned YES unset up up
Ethernet1/3 unassigned YES unset up up
Vlan100 172.16.2.11 YES manual up up
Vlan200 172.16.4.1 YES manual down down <<<Vlan 200 SVI interface was down and not coming up
because no access port is assigned to vlan 200
so I allowed vlan 200 on the uplinks to C8000 edge routers to bring vlan 200 interface up
hostname SW-1002
!
interface Ethernet0/0
switchport access vlan 100
switchport trunk encapsulation dot1q
switchport trunk allowed vlan 100,200 <<<
switchport mode trunk
!
interface Ethernet0/1
switchport access vlan 100
switchport trunk encapsulation dot1q
switchport trunk allowed vlan 100,200 <<<
switchport mode trunk
!
interface Vlan100
ip address 172.16.2.11 255.255.254.0
!
interface Vlan200
ip address 172.16.4.1 255.255.254.0
!
ip route 0.0.0.0 0.0.0.0 172.16.2.1
!SW-1002#show ip int brief
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 unassigned YES unset up up
Ethernet0/1 unassigned YES unset up up
Ethernet0/2 unassigned YES unset down down
Ethernet0/3 unassigned YES unset down down
Ethernet1/0 unassigned YES unset down down
Ethernet1/1 unassigned YES unset down down
Ethernet1/2 unassigned YES unset up up
Ethernet1/3 unassigned YES unset up up
Vlan100 172.16.2.11 YES manual up up
Vlan200 172.16.4.1 YES manual up up <<<C801-1002-DUAL#
ip route vrf 100 172.16.4.0 255.255.254.0 172.16.2.11CSR-1004-MPLS#show sdwan omp route
Generating output, this might take time, please wait ...
Code:
C -> chosen
I -> installed
Red -> redistributed
Rej -> rejected
L -> looped
R -> resolved
S -> stale
Ext -> extranet
Inv -> invalid
Stg -> staged
IA -> On-demand inactive
U -> TLOC unresolved
PATH ATTRIBUTE
VPN PREFIX FROM PEER ID LABEL STATUS TYPE TLOC IP COLOR ENCAP PREFERENCE
--------------------------------------------------------------------------------------------------------------------------------------
100 172.16.0.0/23 22.22.22.22 6 1003 C,I,R installed 13.13.13.13 biz-internet ipsec -
100 172.16.2.0/23 22.22.22.22 7 1004 C,I,R installed 12.12.12.12 mpls ipsec -
22.22.22.22 8 1004 C,I,R installed 12.12.12.12 biz-internet ipsec -
22.22.22.22 19 1004 C,I,R installed 11.11.11.11 mpls ipsec -
22.22.22.22 20 1004 C,I,R installed 11.11.11.11 biz-internet ipsec -
100 172.16.4.0/23 >>> 22.22.22.22 19 1004 C,I,R installed 11.11.11.11 mpls ipsec -
>>> 22.22.22.22 20 1004 C,I,R installed 11.11.11.11 biz-internet ipsec -
>>> 22.22.22.22 27 1004 C,I,R installed 12.12.12.12 mpls ipsec -
>>> 22.22.22.22 29 1004 C,I,R installed 12.12.12.12 biz-internet ipsec -
100 172.16.8.0/23 0.0.0.0 66 1003 C,Red,R installed 16.16.16.16 mpls ipsec -
C801-1002-DUAL#show ip route vrf 100
Routing Table: 100
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 5 subnets, 2 masks
m 172.16.0.0/23 [251/0] via 13.13.13.13, 03:50:11, Sdwan-system-intf
C 172.16.2.0/23 is directly connected, GigabitEthernet3.100
L 172.16.2.2/32 is directly connected, GigabitEthernet3.100
S 172.16.4.0/23 [1/0] via 172.16.2.11
m 172.16.8.0/23 [251/0] via 16.16.16.16, 03:50:11, Sdwan-system-intf
C801-1002-DUAL# EIGRP Serviceside configuration
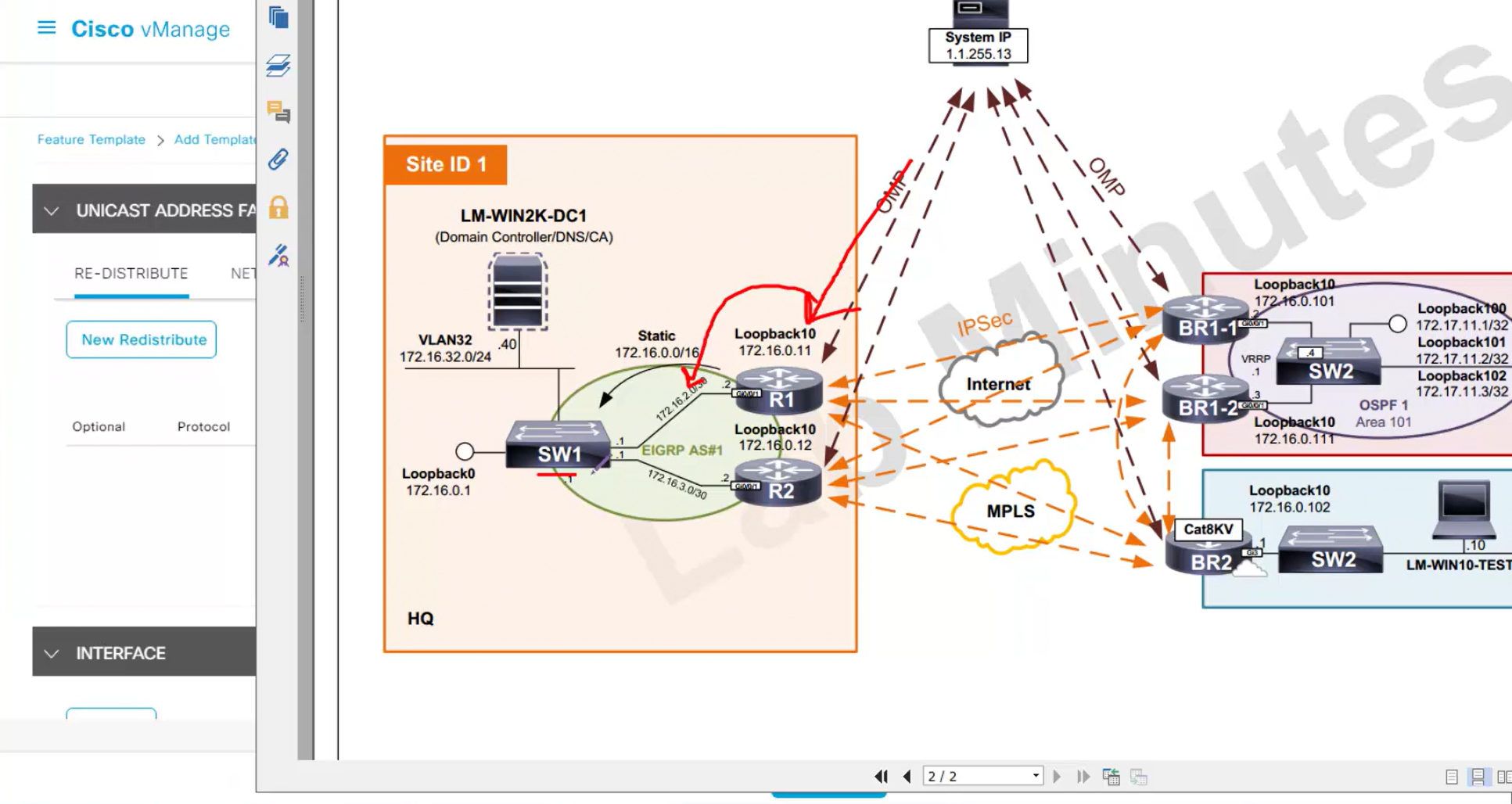
We will have to redistribute OMP routes into EIGRP in order to make sure that internal switch SW1 can ping remote site switches and remote destinations / subnets
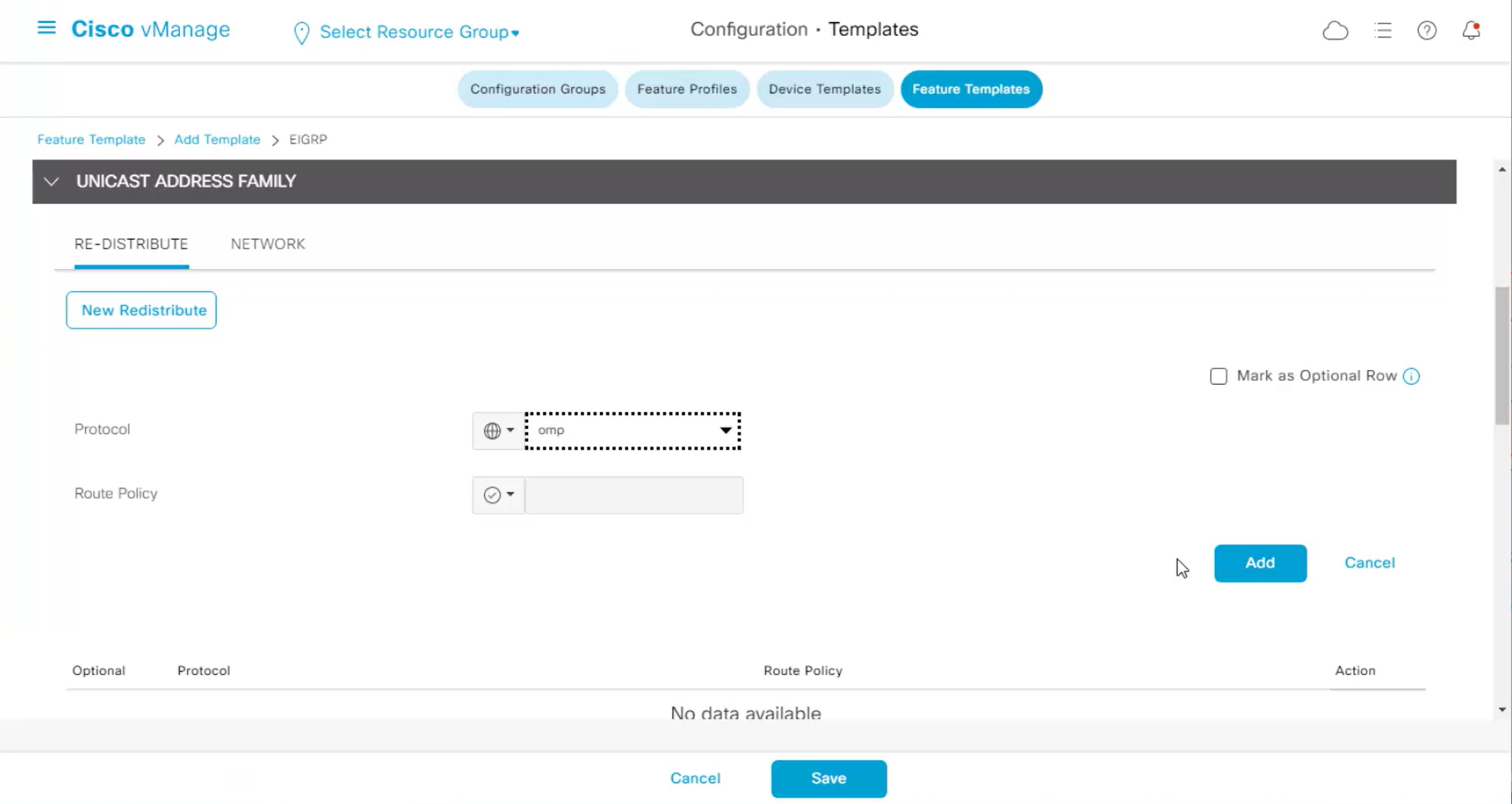
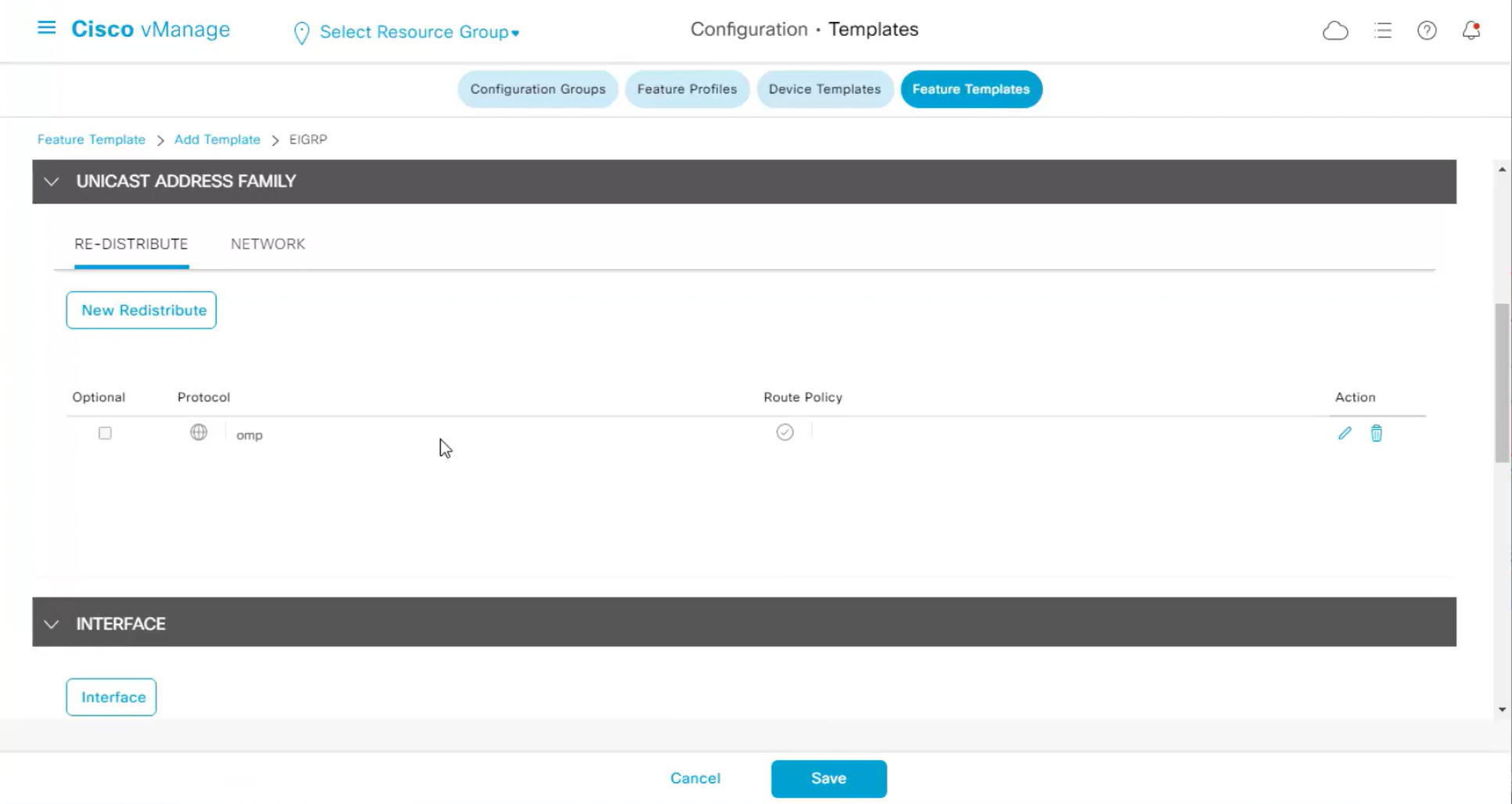
We need to have EIGRP enabled on service side LAN interfaces and also on the loopback
one network for physical interface
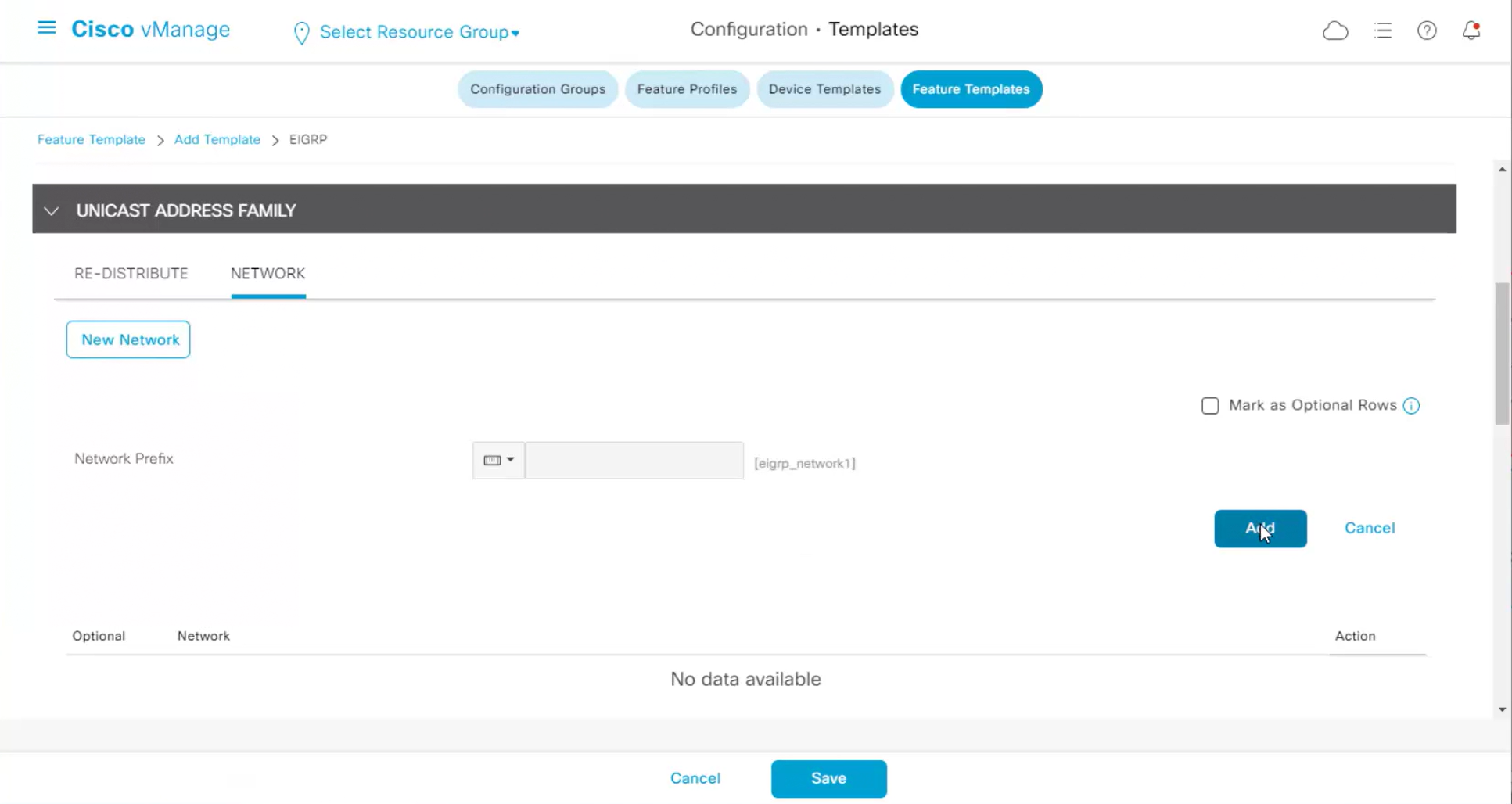
another network for loopback interface
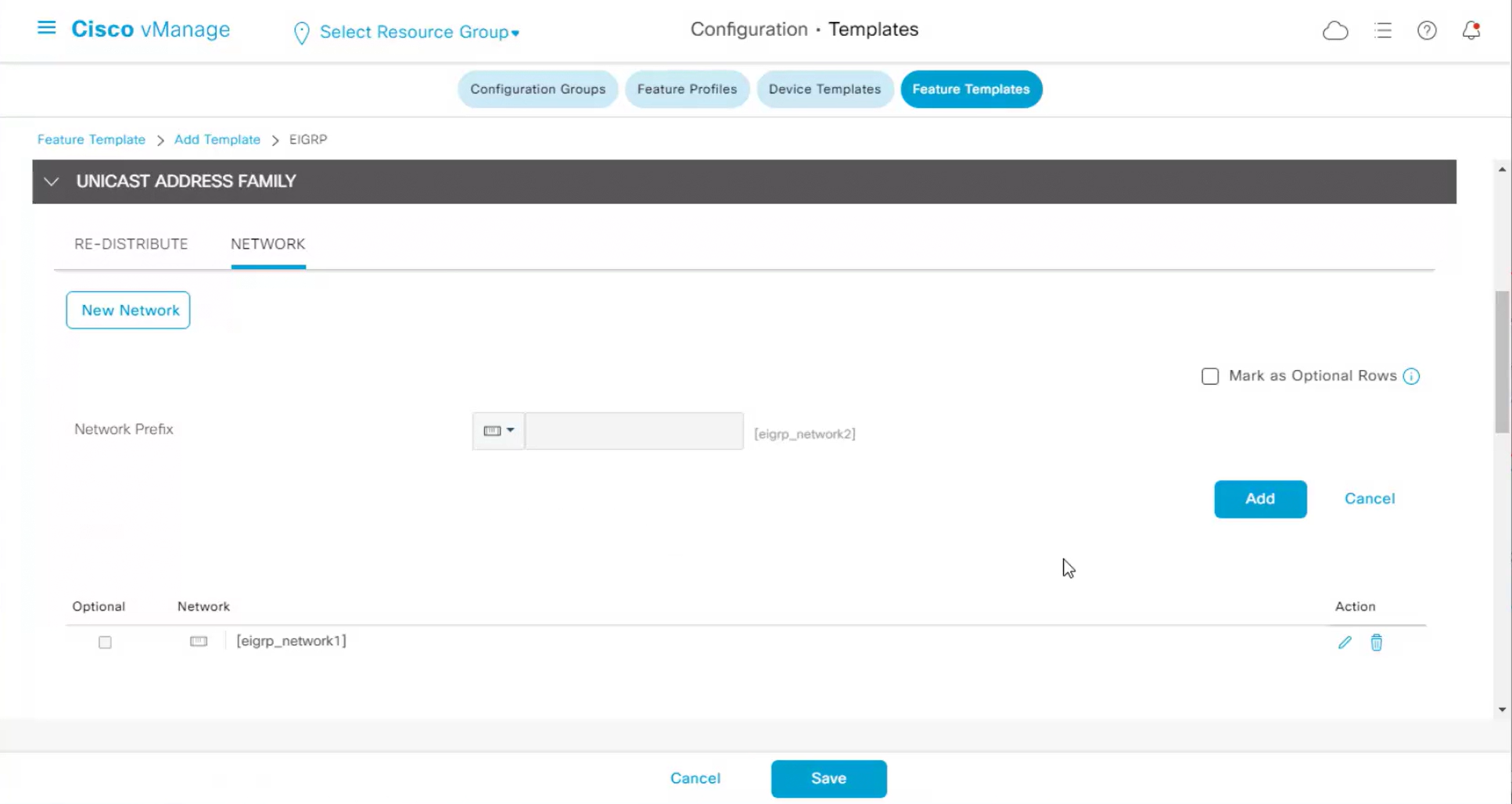
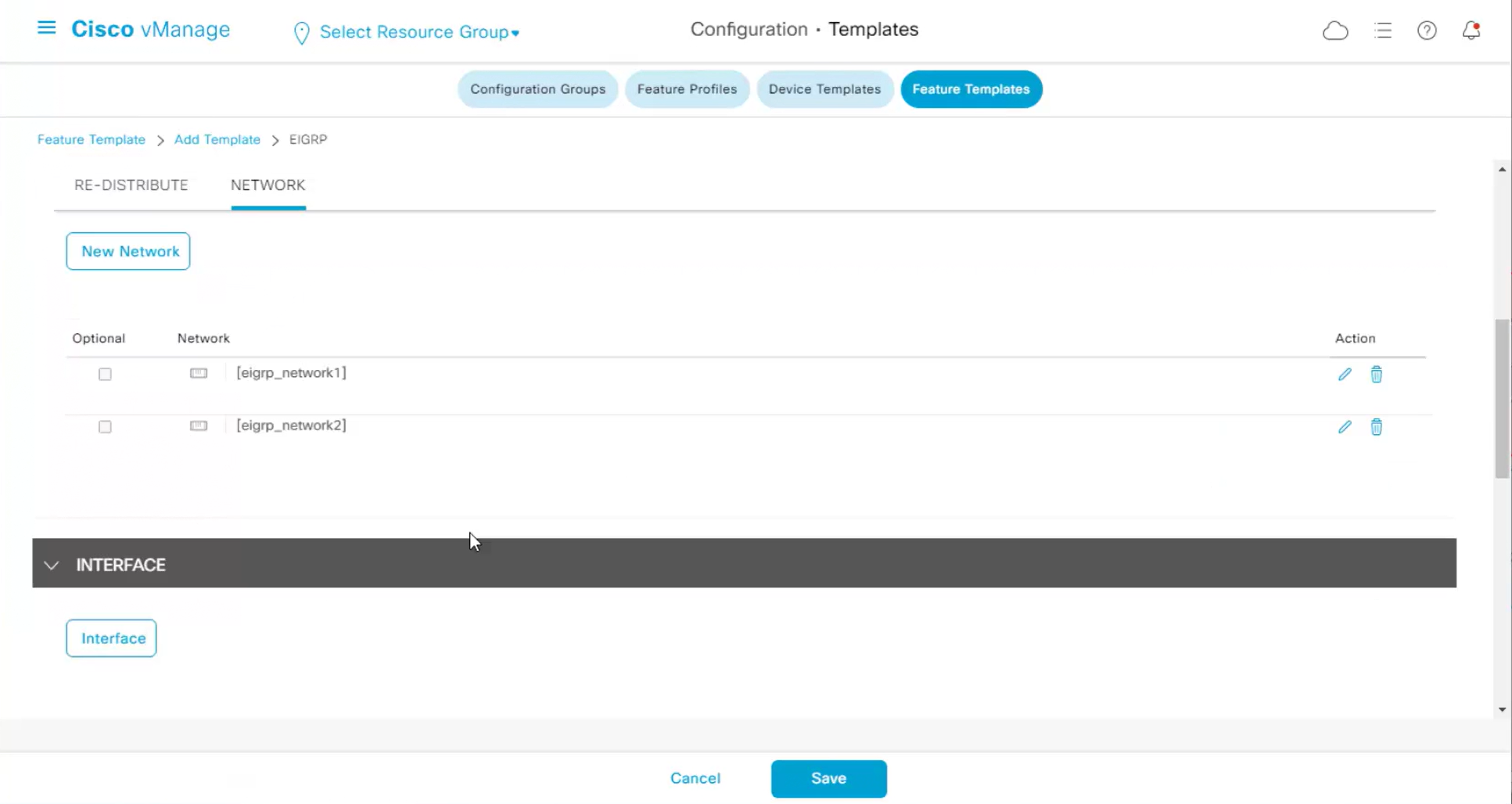
Now we need to specify the interface in GUI and that is for doing no passive interface
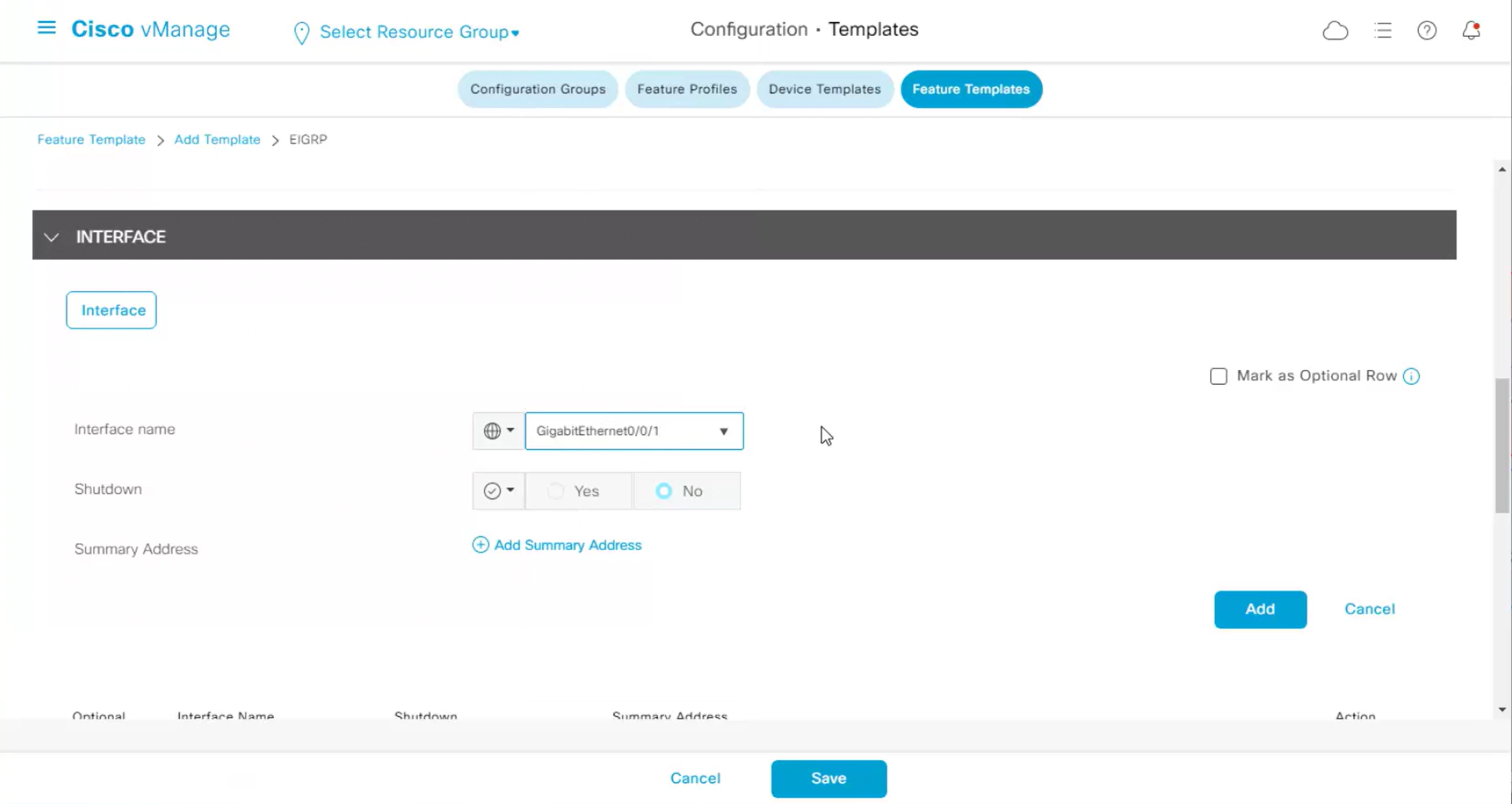
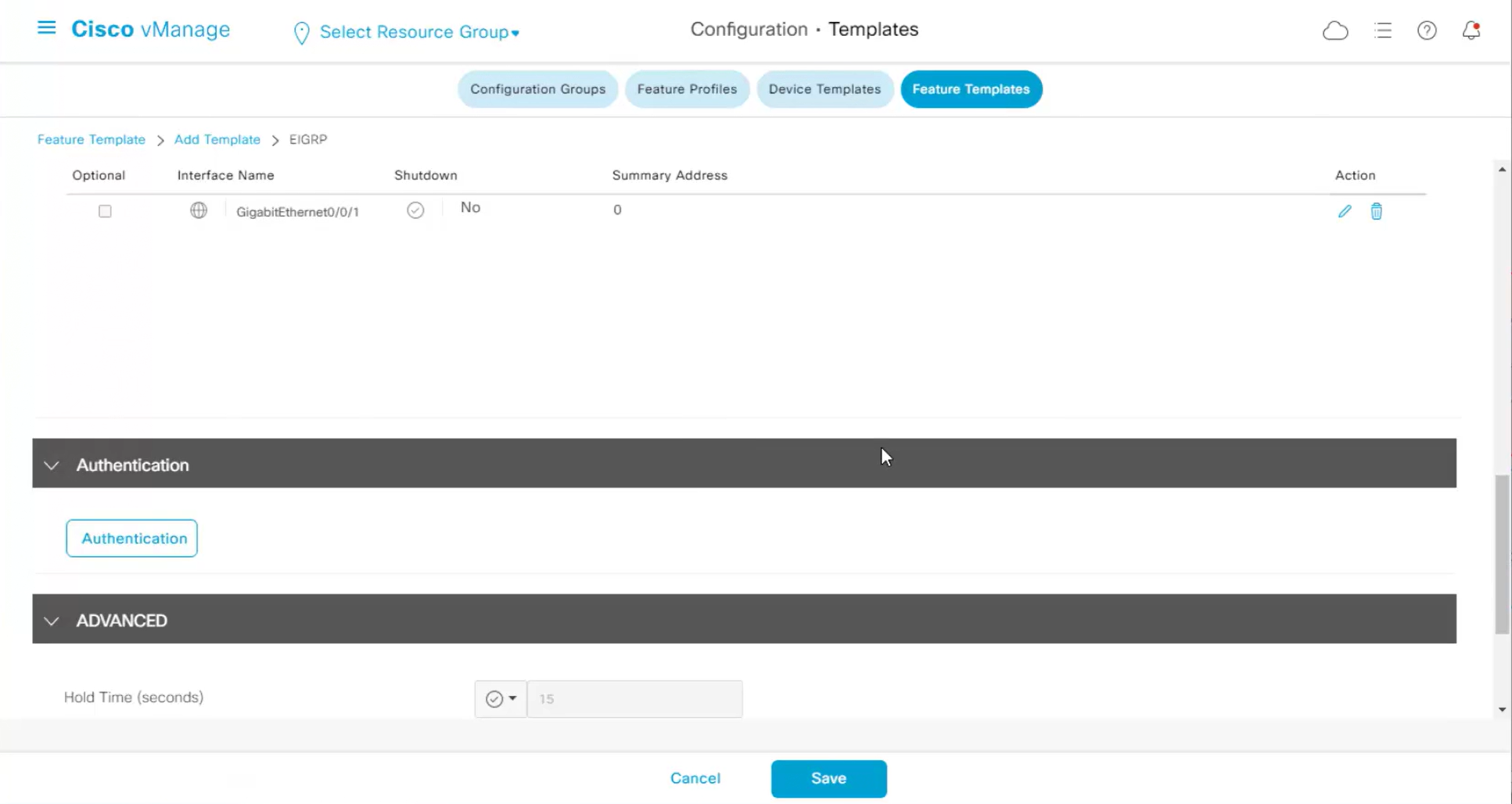
now we need to enable authentication
Rest of the configuration such as Hello time and hold time are left at defaults
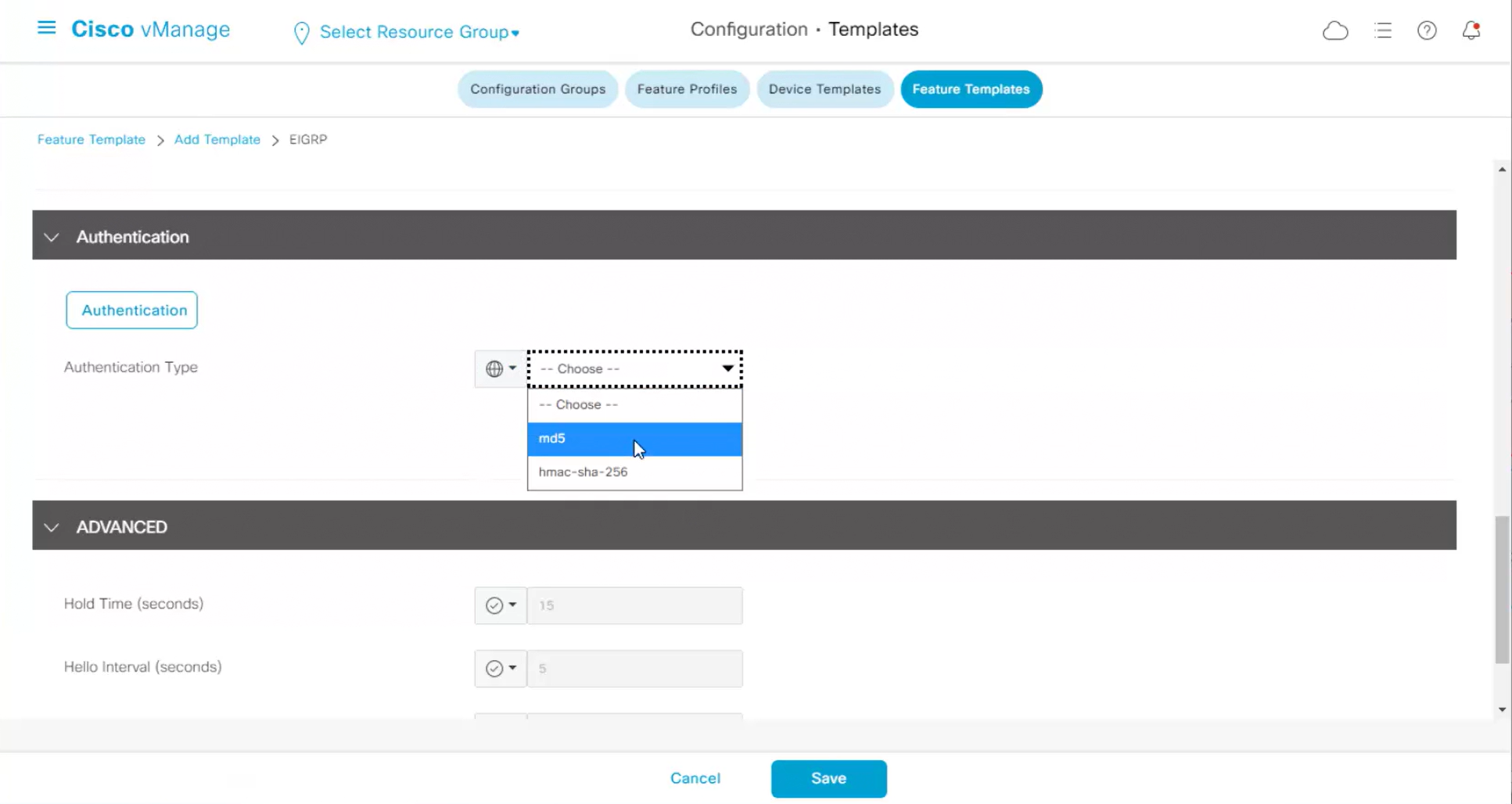
Authentication
Attach EIGRP template to VPN
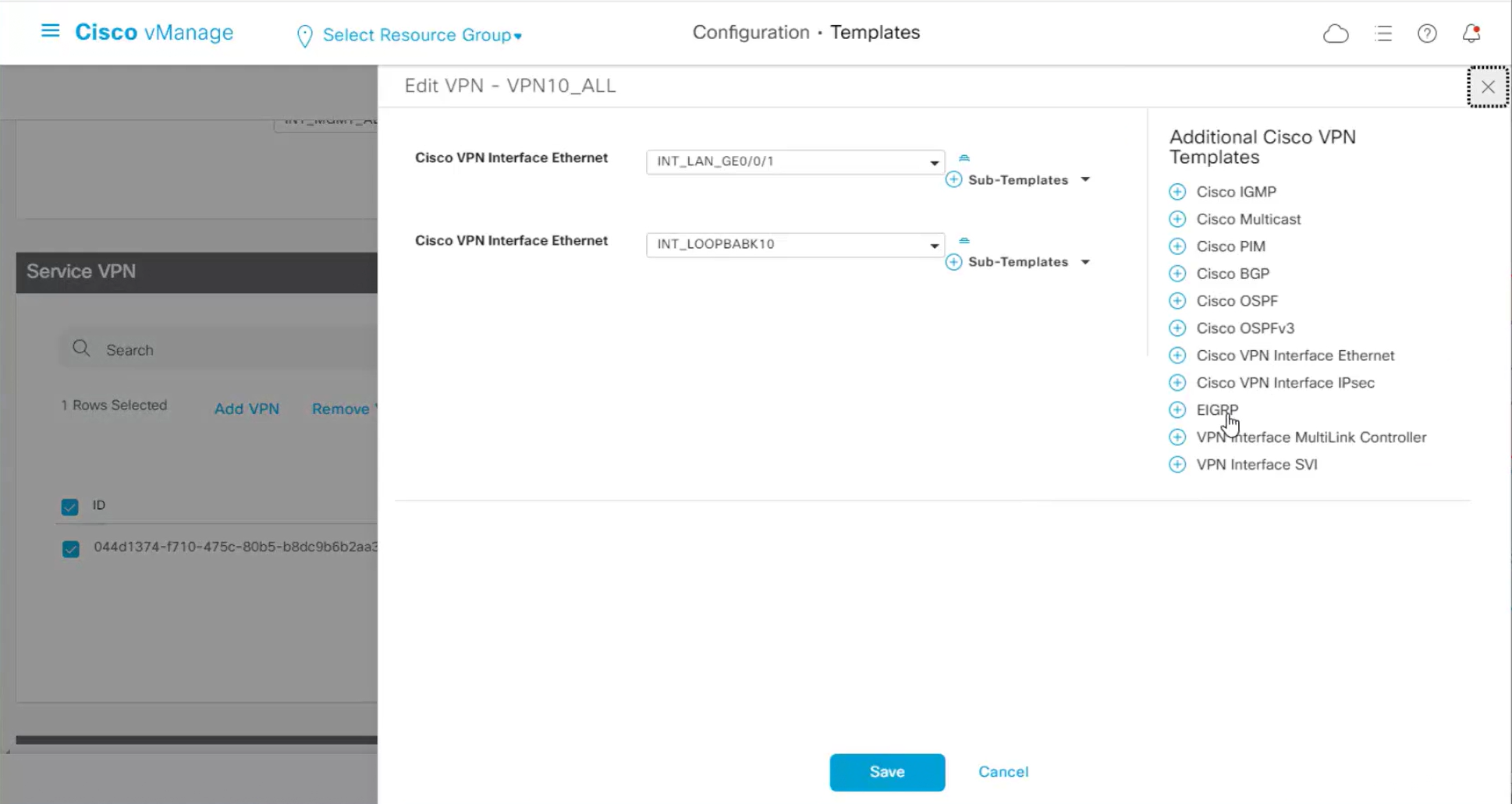
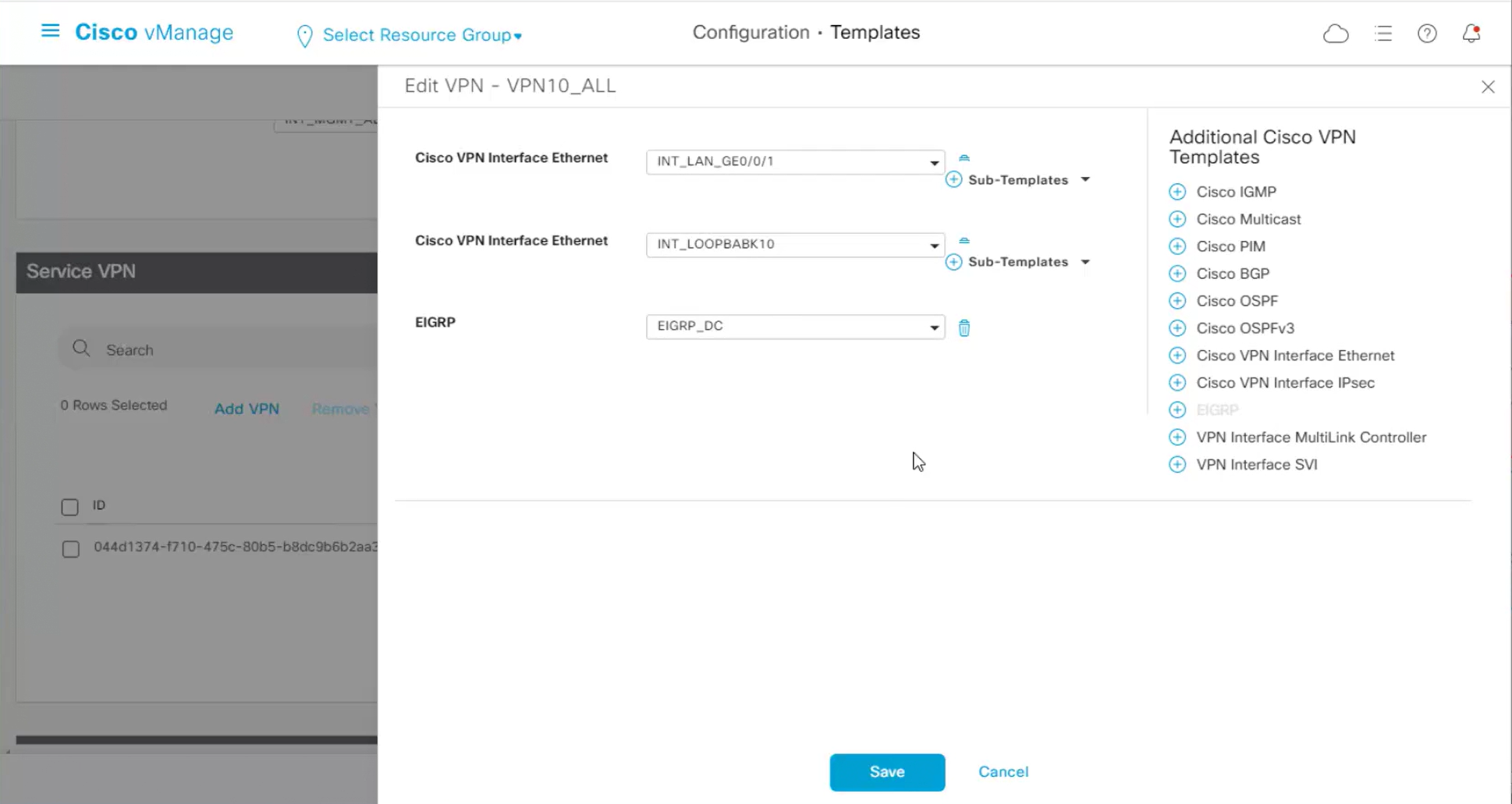
hello and hold time can be seen and also other EIGRP configuration that is being added
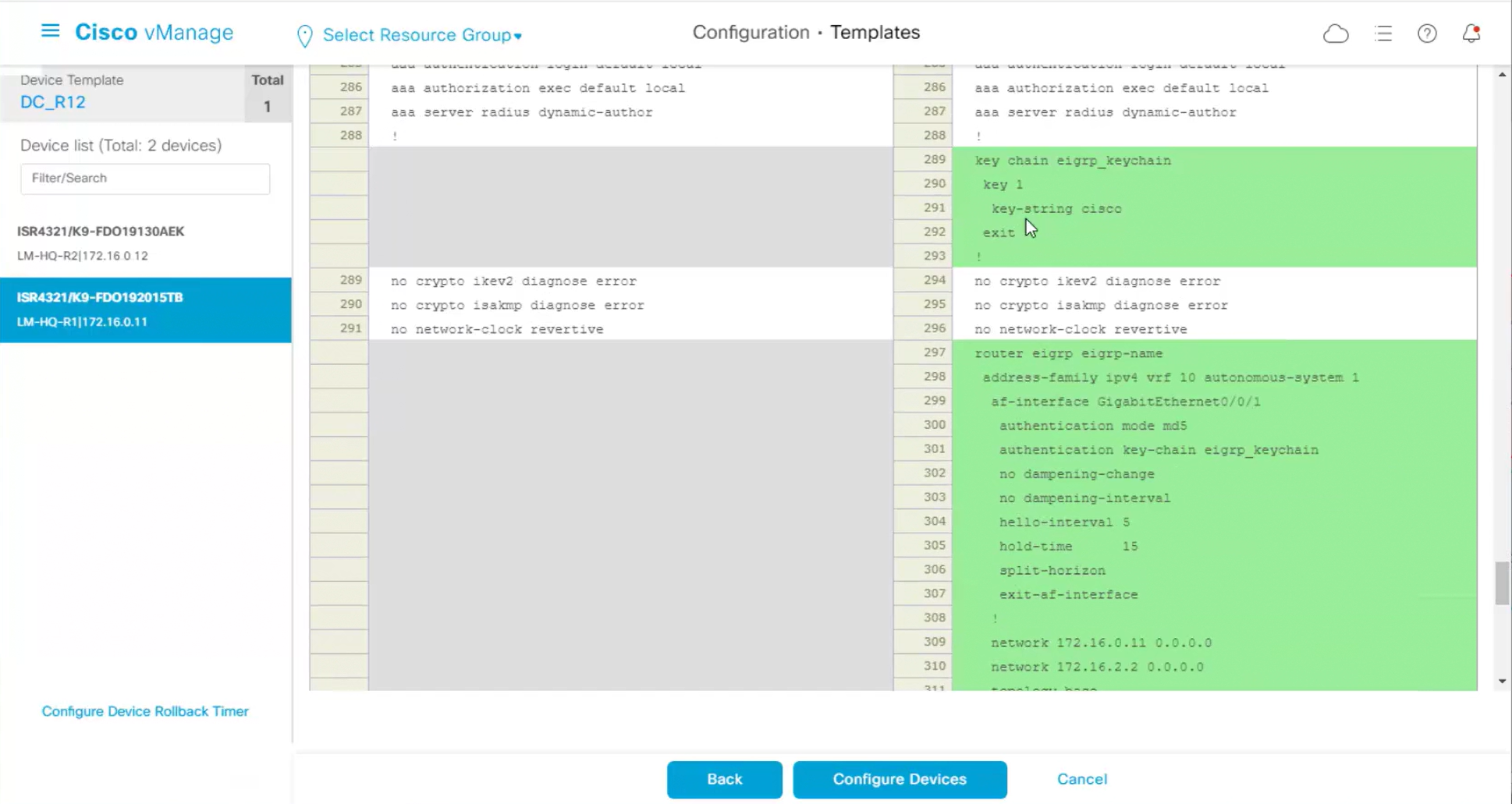
Neighborship on router will be on the vrf
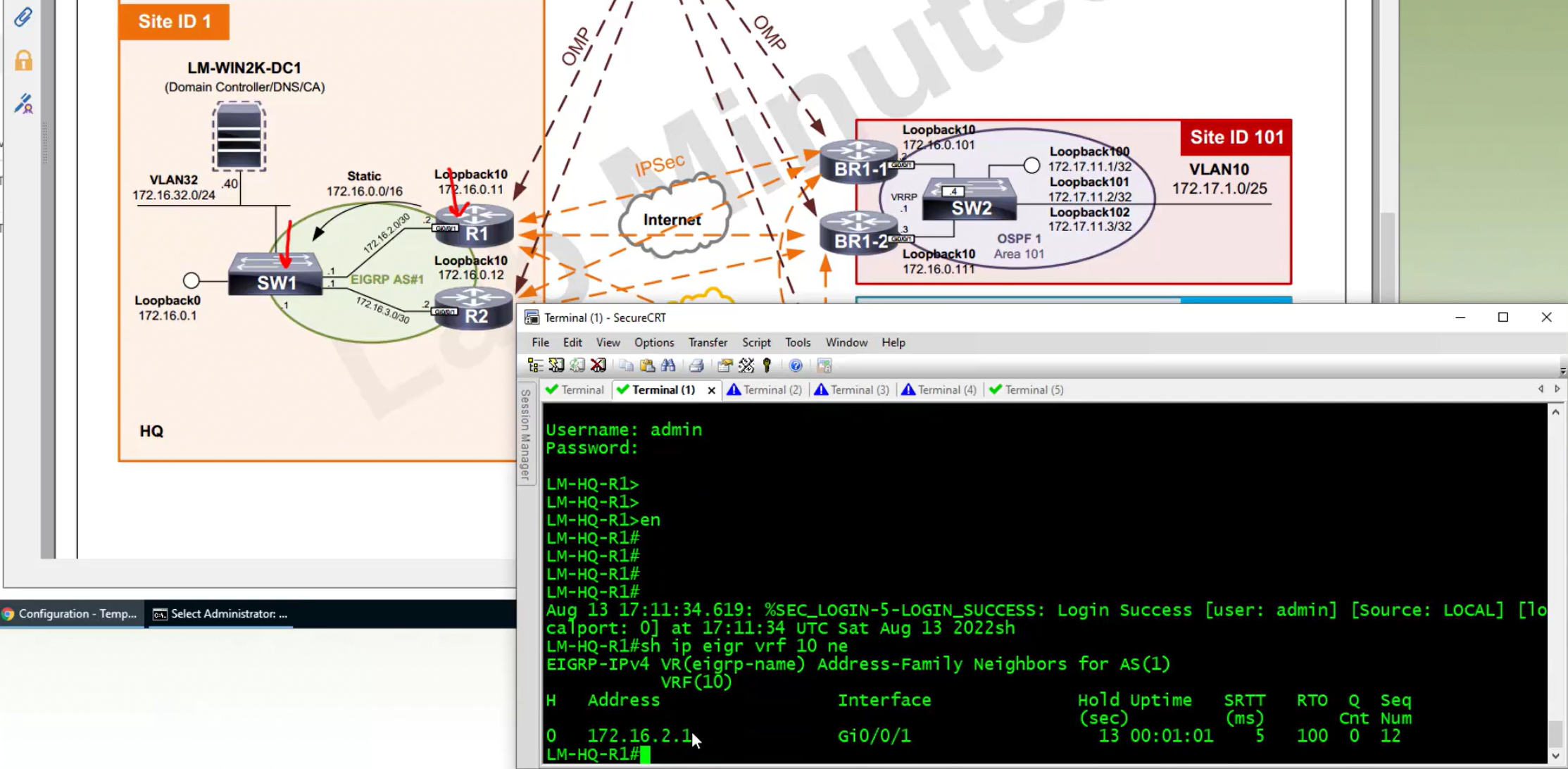
but other remote sites are not learning EIGRP routes because we imported or redistributed OMP into EIGRP but not EIGRP into OMP
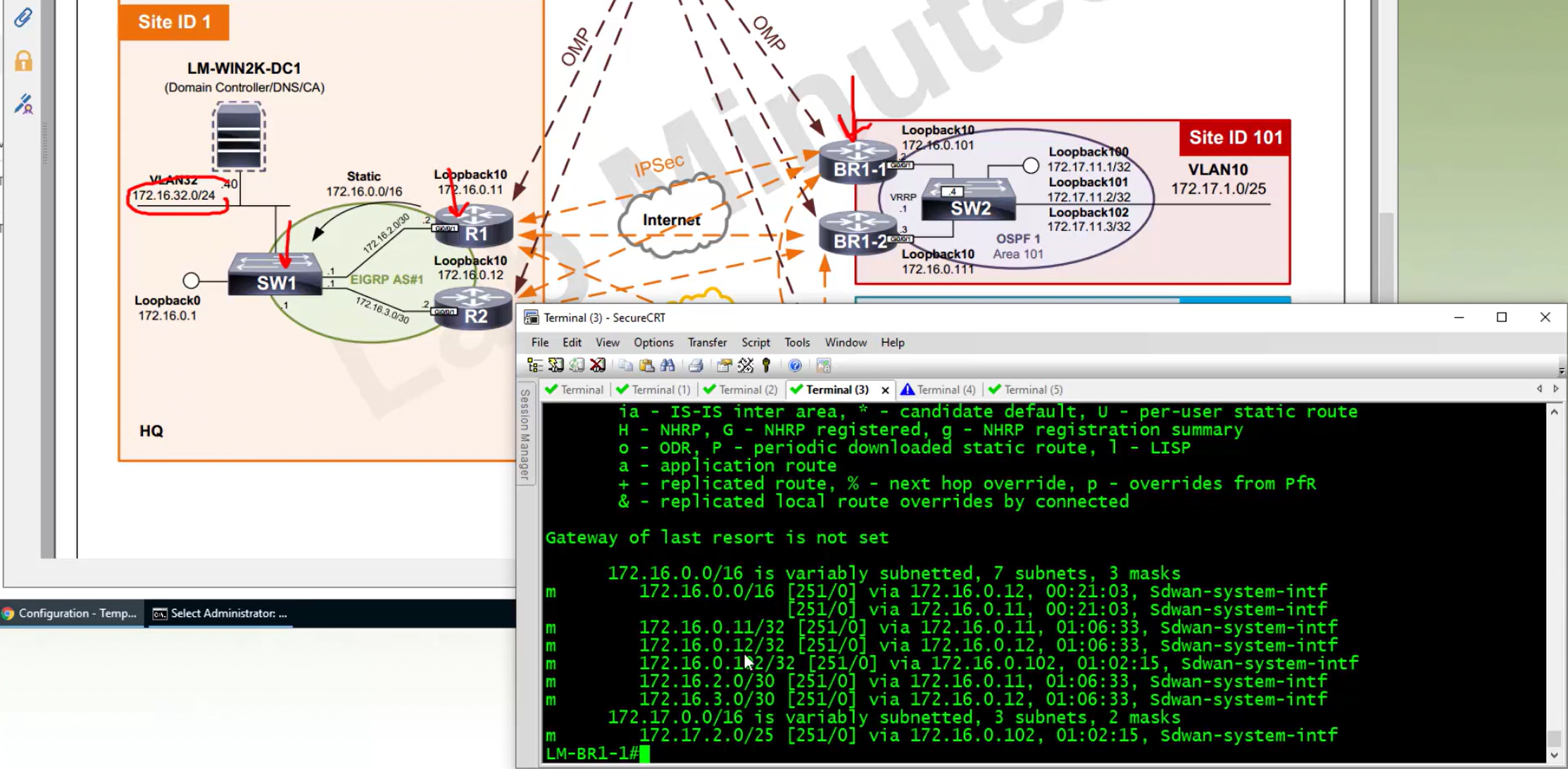
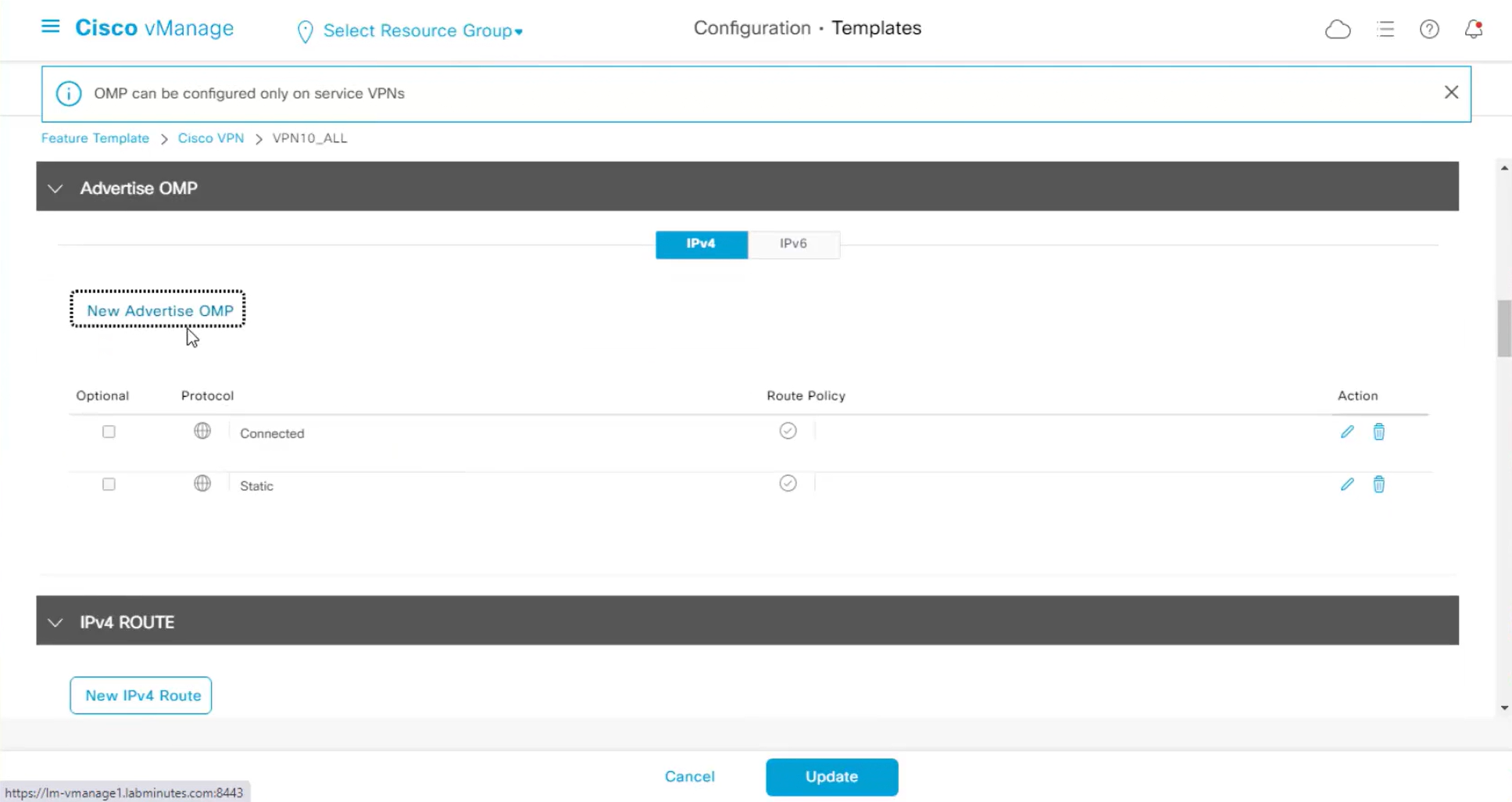
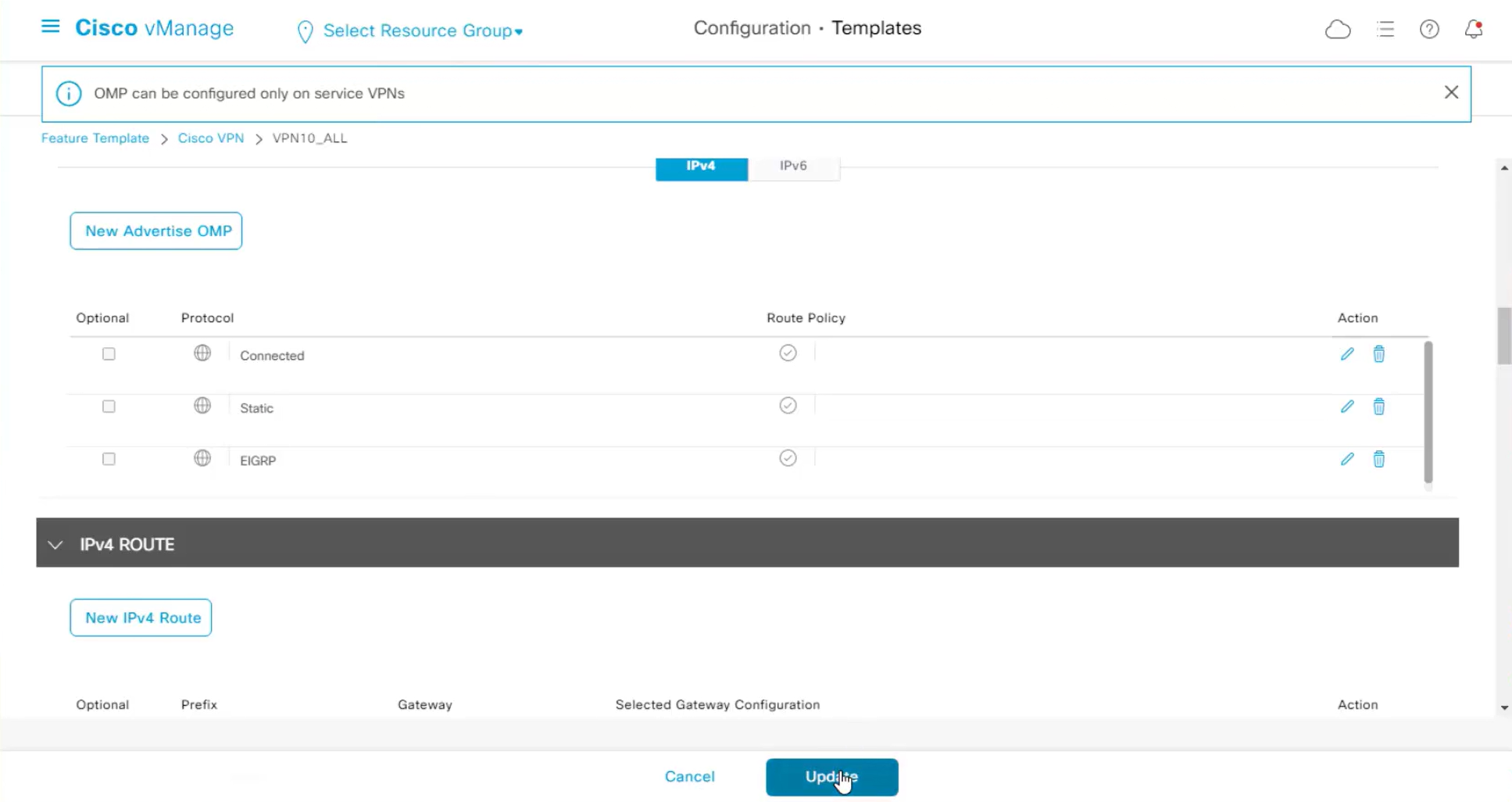
Now we are receiving EIGRP routes in OMP
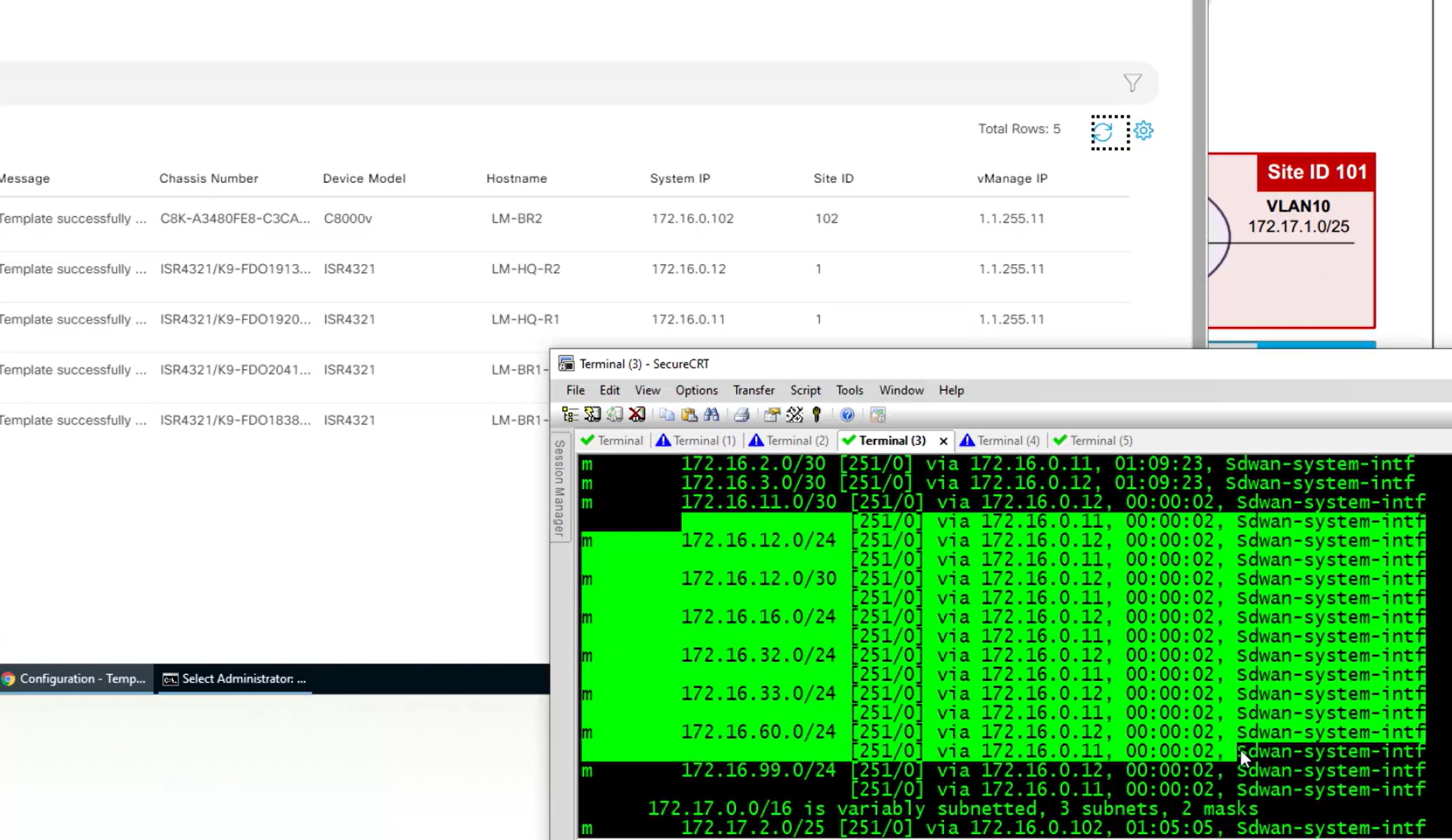
router eigrp 1
network 172.16.2.1 0.0.0.0
network 172.16.3.1 0.0.0.0
network 172.16.16.1 0.0.0.0
redistribute connected
redistribute static route-map STATIC2EIGRP
passive-interface default
no passive-interface GigabitEthernet1/0/2
no passive-interface GigabitEthernet1/0/5
eigrp router-id 172.16.0.1
interface GigabitEthernet1/0/2
no switchport
ip address 172.16.2.1 255.255.255.252
ip authentication mode eigrp 1 md5
ip authentication key-chain eigrp 1 KEY_EIGRPOSPF Serviceside configuration
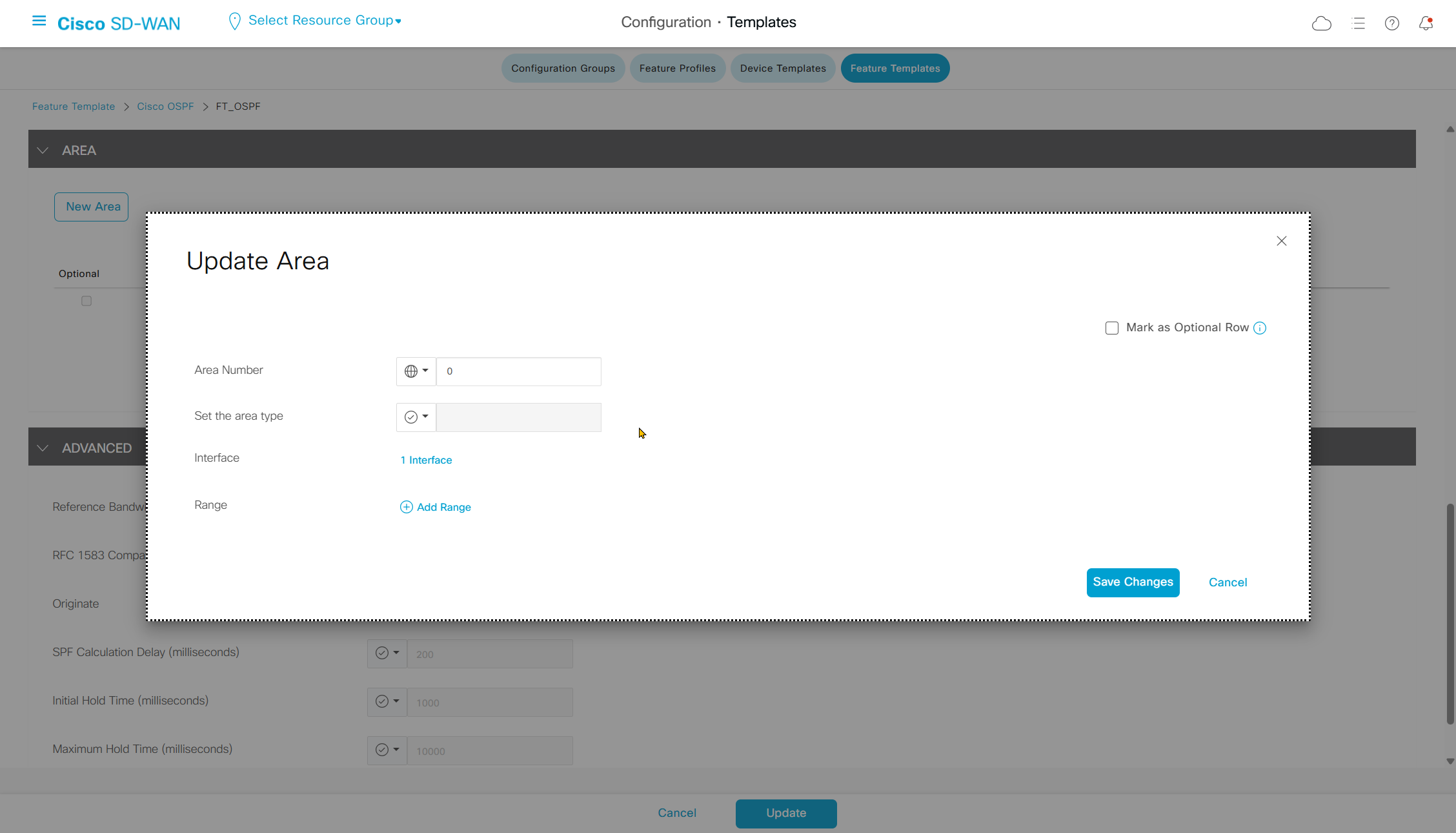
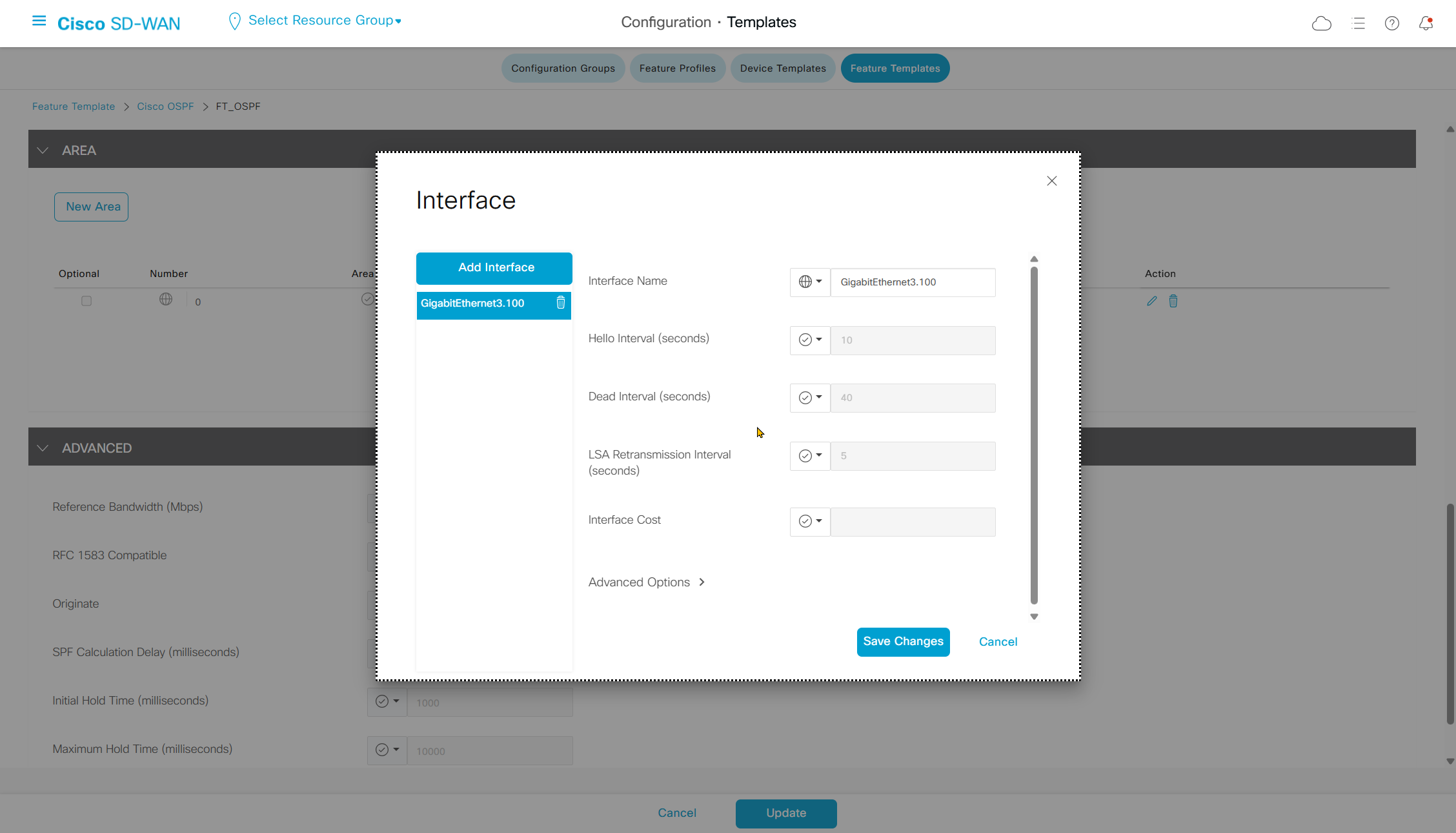
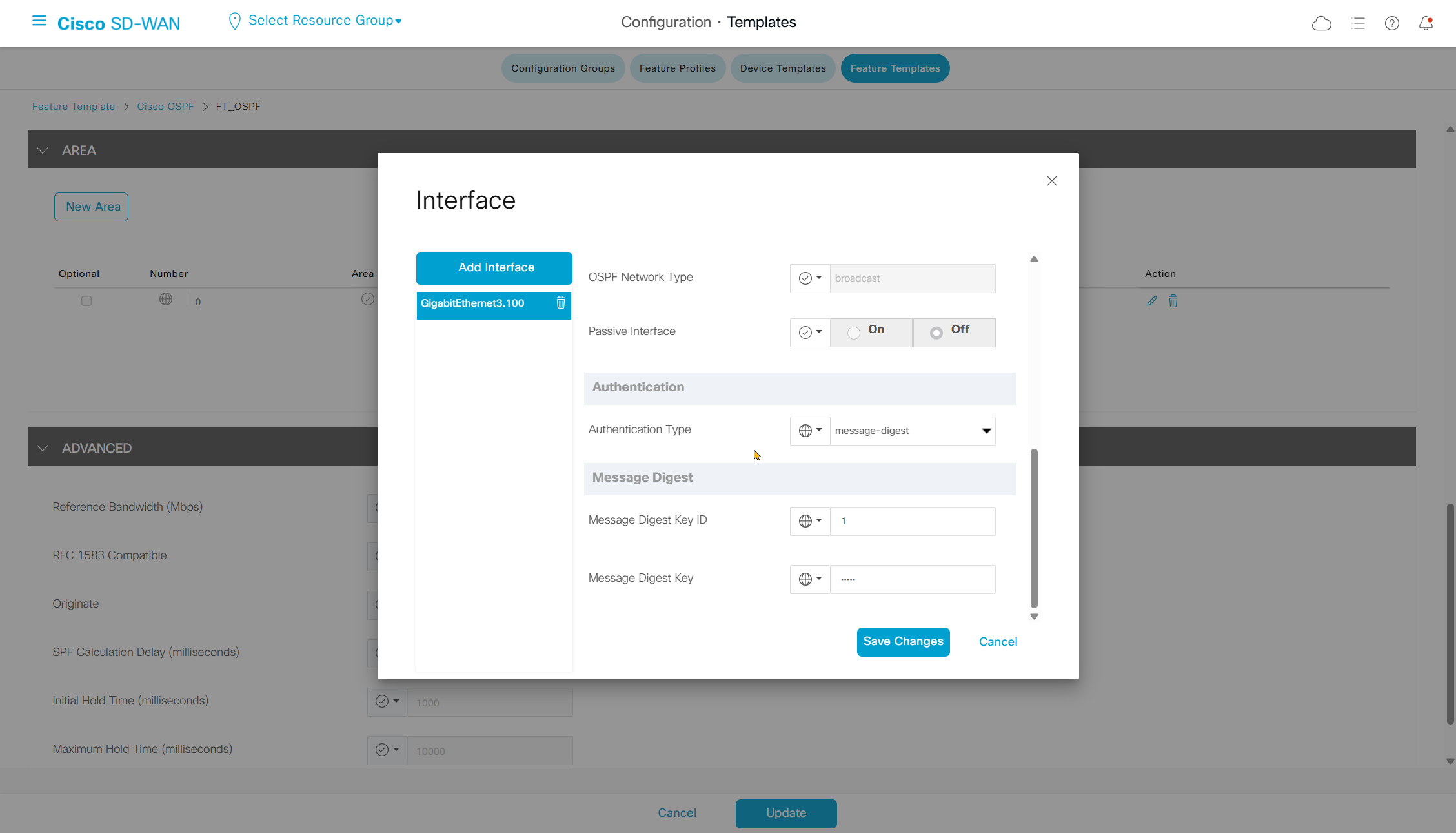
Neighborship was not coming up so I had to add this in CLI template
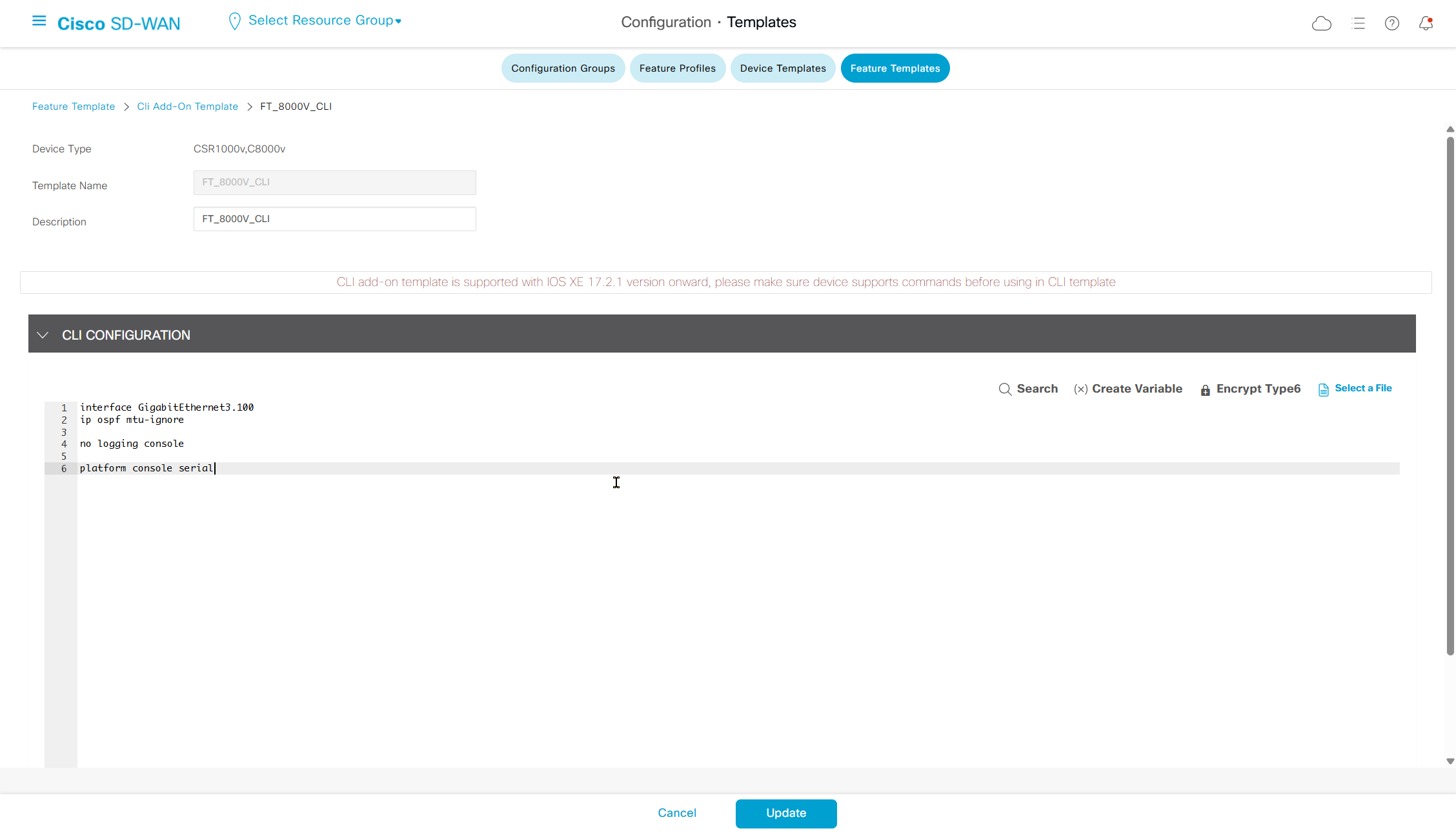
interface GigabitEthernet3.100
ip ospf mtu-ignore
no logging console
platform console serialSDWAN OSPF pushed configuration
router ospf 100 vrf 100
auto-cost reference-bandwidth 100
compatible rfc1583
distance ospf intra-area 110 inter-area 110 external 110
no local-rib-criteria
router-id 11.11.11.11
timers throttle spf 200 1000 10000
interface GigabitEthernet3.100
ip ospf 100 area 0
ip ospf authentication message-digest
ip ospf dead-interval 40
ip ospf hello-interval 10
ip ospf message-digest-key 1 md5 0 cisco
ip ospf network broadcast
ip ospf priority 1
ip ospf retransmit-interval 5
interface GigabitEthernet3.100 ! <<< coming from CLI template
ip ospf mtu-ignore
Switch OSPF configuration
router ospf 1
router-id 172.16.2.11
no auto-cost
area 0 authentication message-digest
! redistribute connected
passive-interface default
no passive-interface Vlan100
network 172.16.2.11 0.0.0.0 area 0
network 172.16.10.1 0.0.0.0 area 0
interface Vlan100
ip address 172.16.2.11 255.255.254.0
ip ospf authentication message-digest
ip ospf message-digest-key 1 md5 cisco
ip ospf mtu-ignoreTroubleshooting OMP route flow
This is much faster way of troubleshooting the routes instead of logging into each device CLI
This is also a quicker way of finding out whether a route is blocked by a policy inbound or outbound
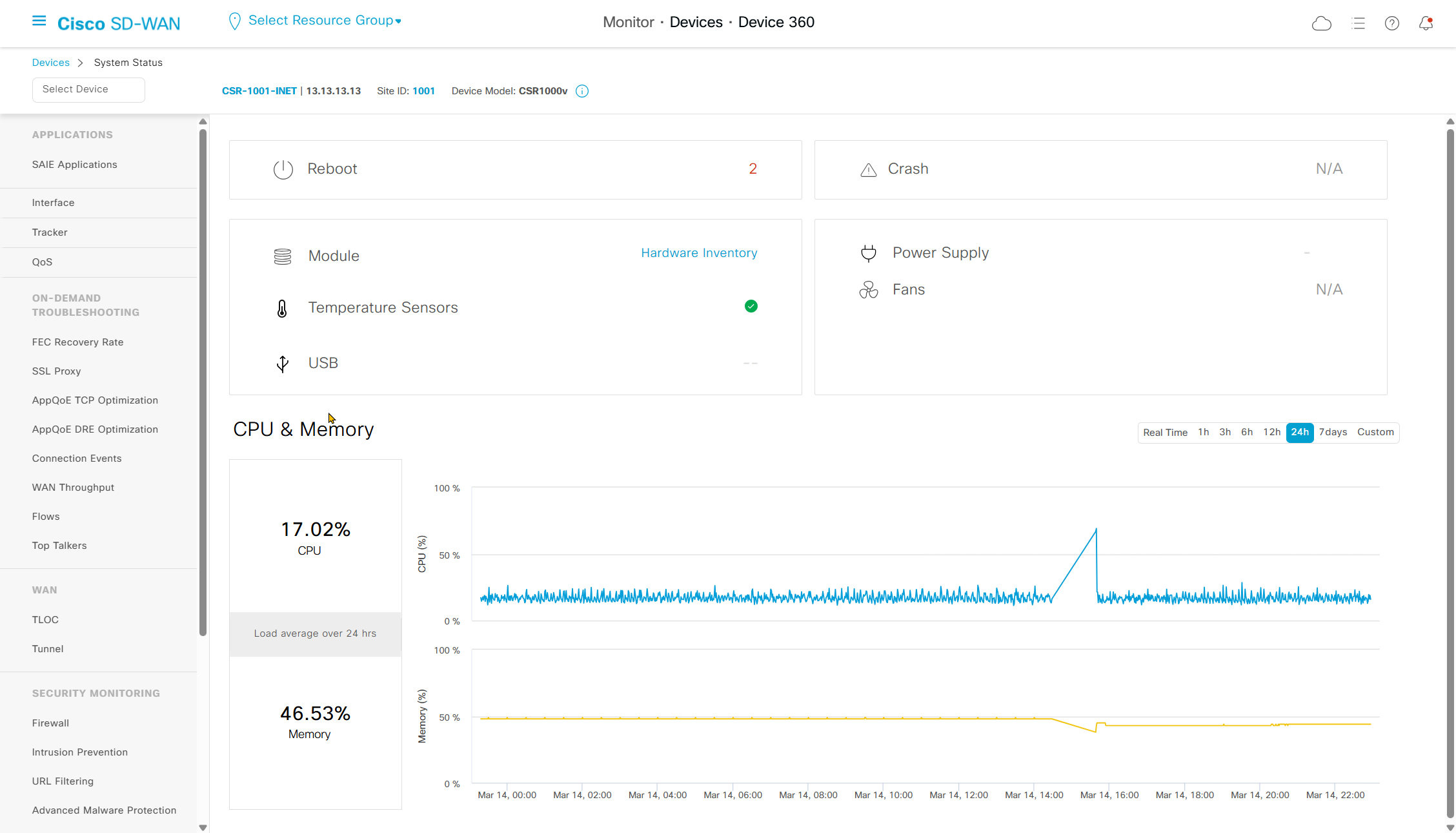
See if local router advertised it to vsmart or not
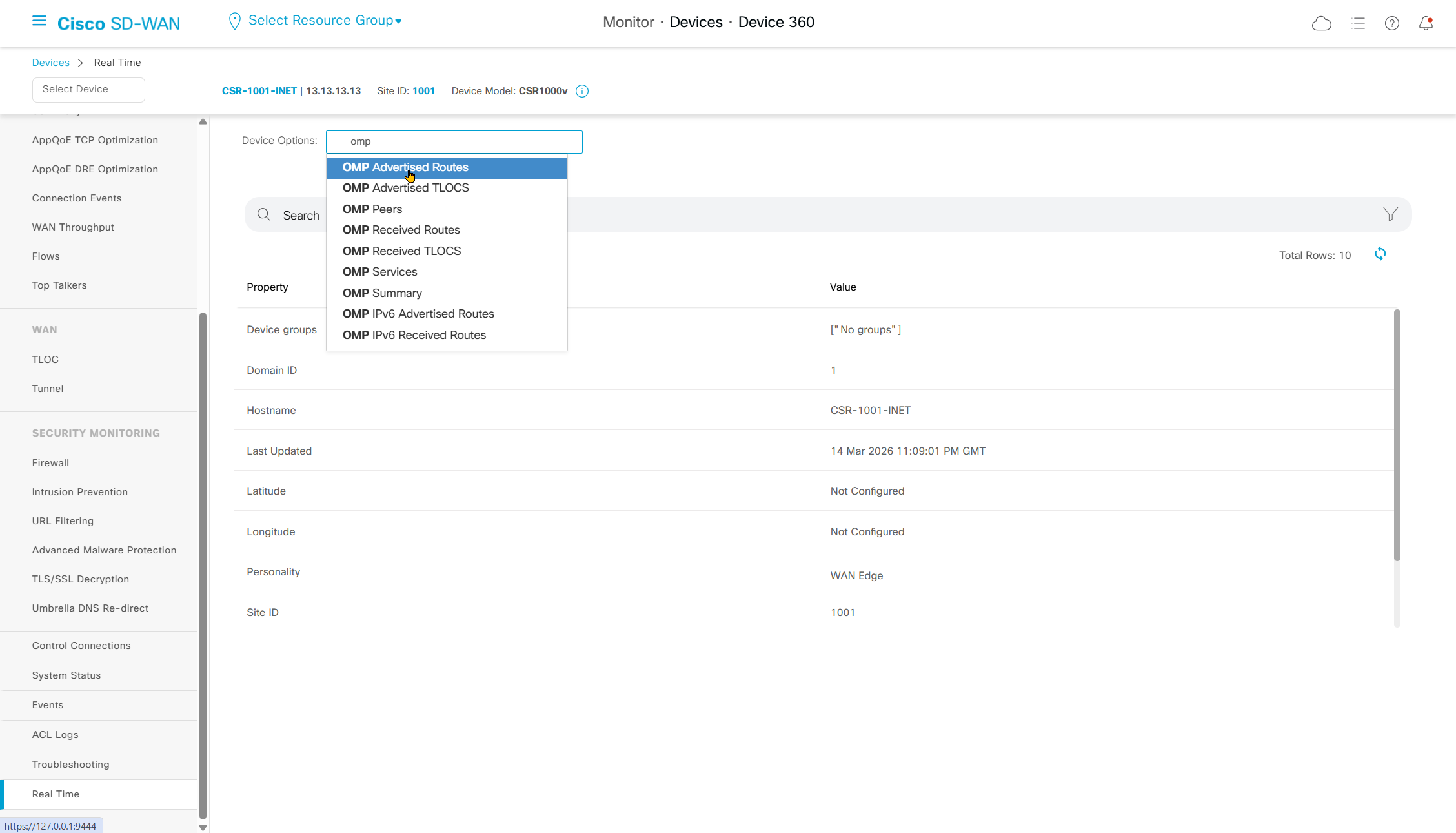
We can use filter to limit the results
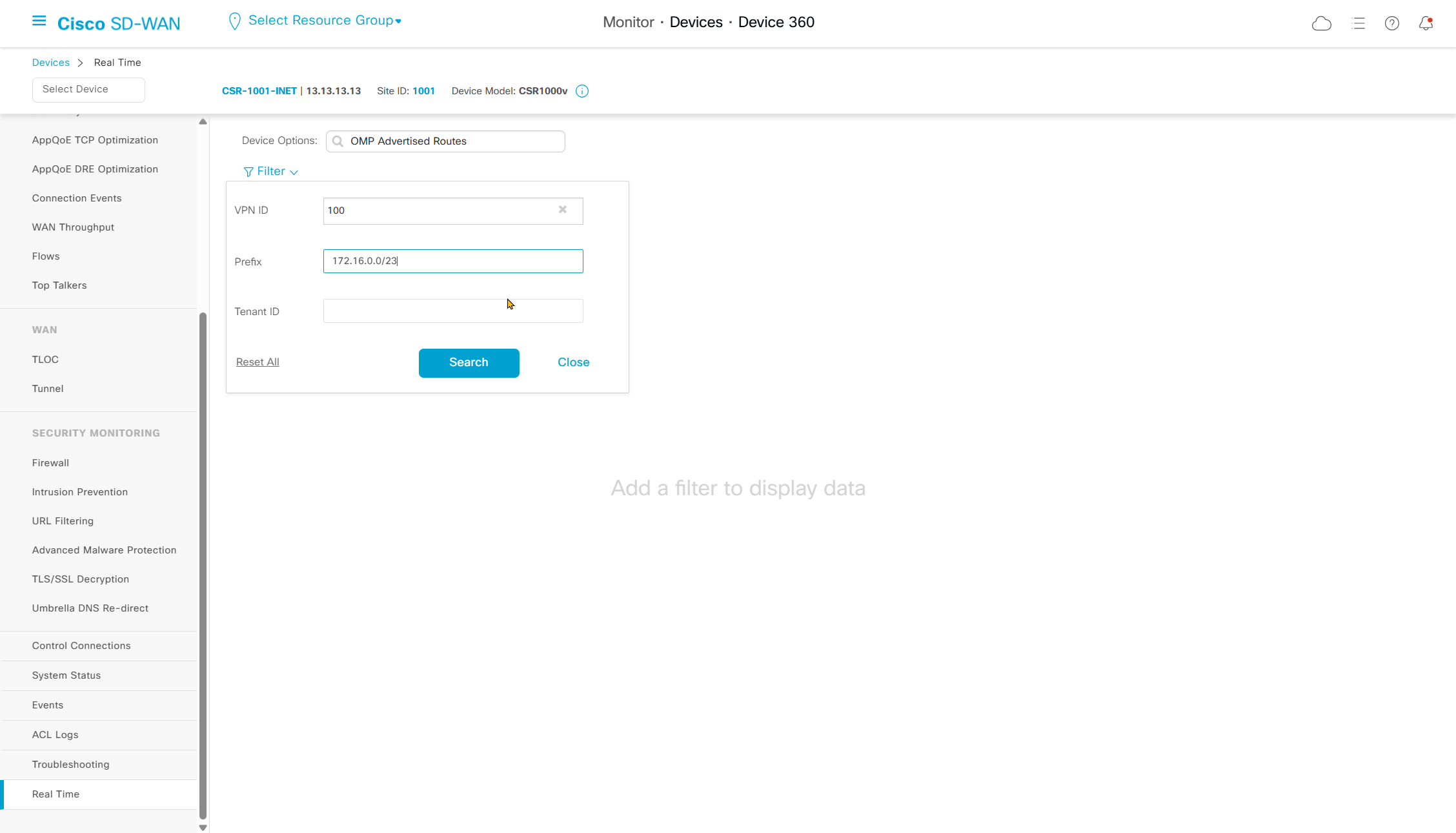
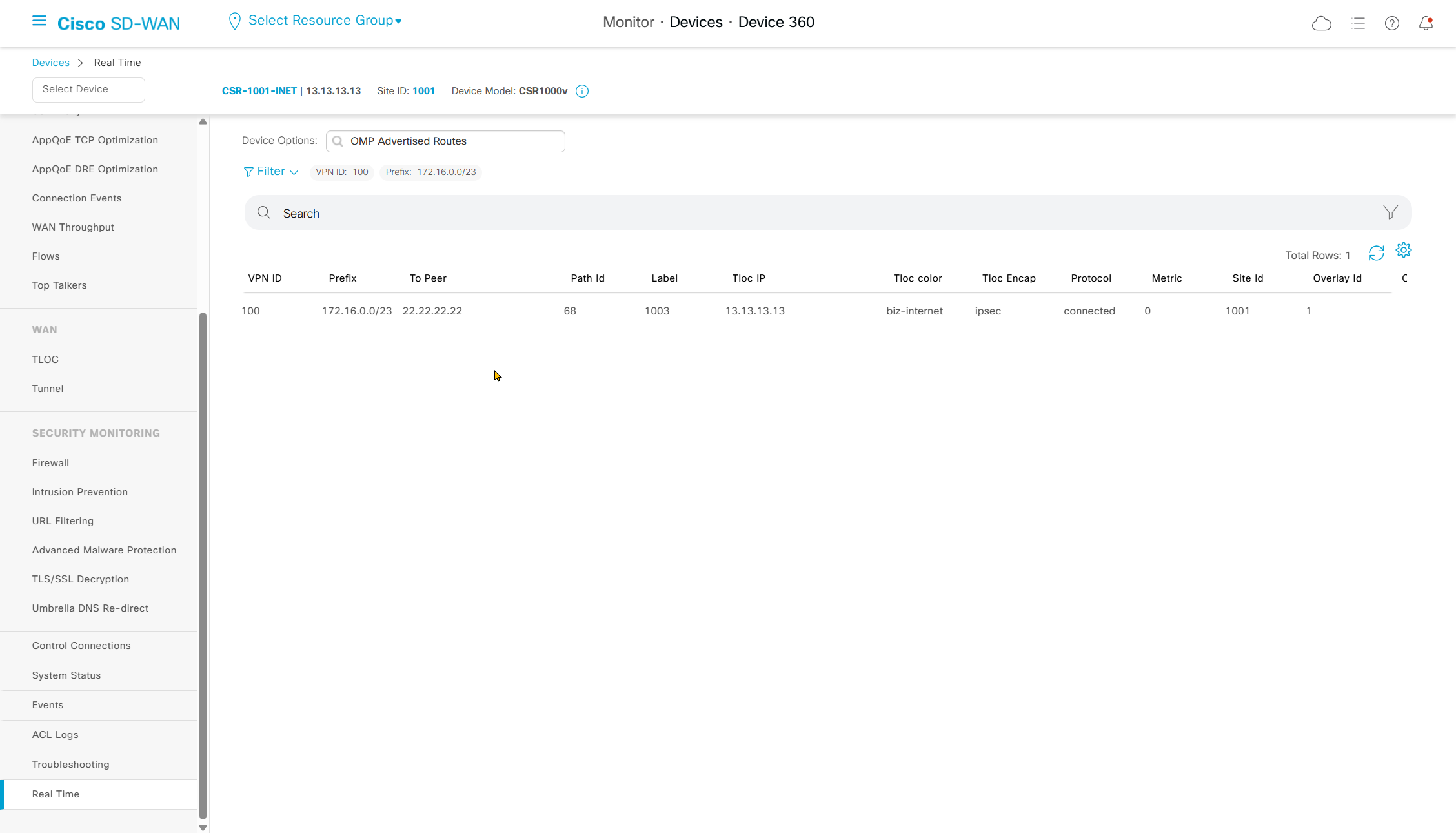
now we go to vsmart
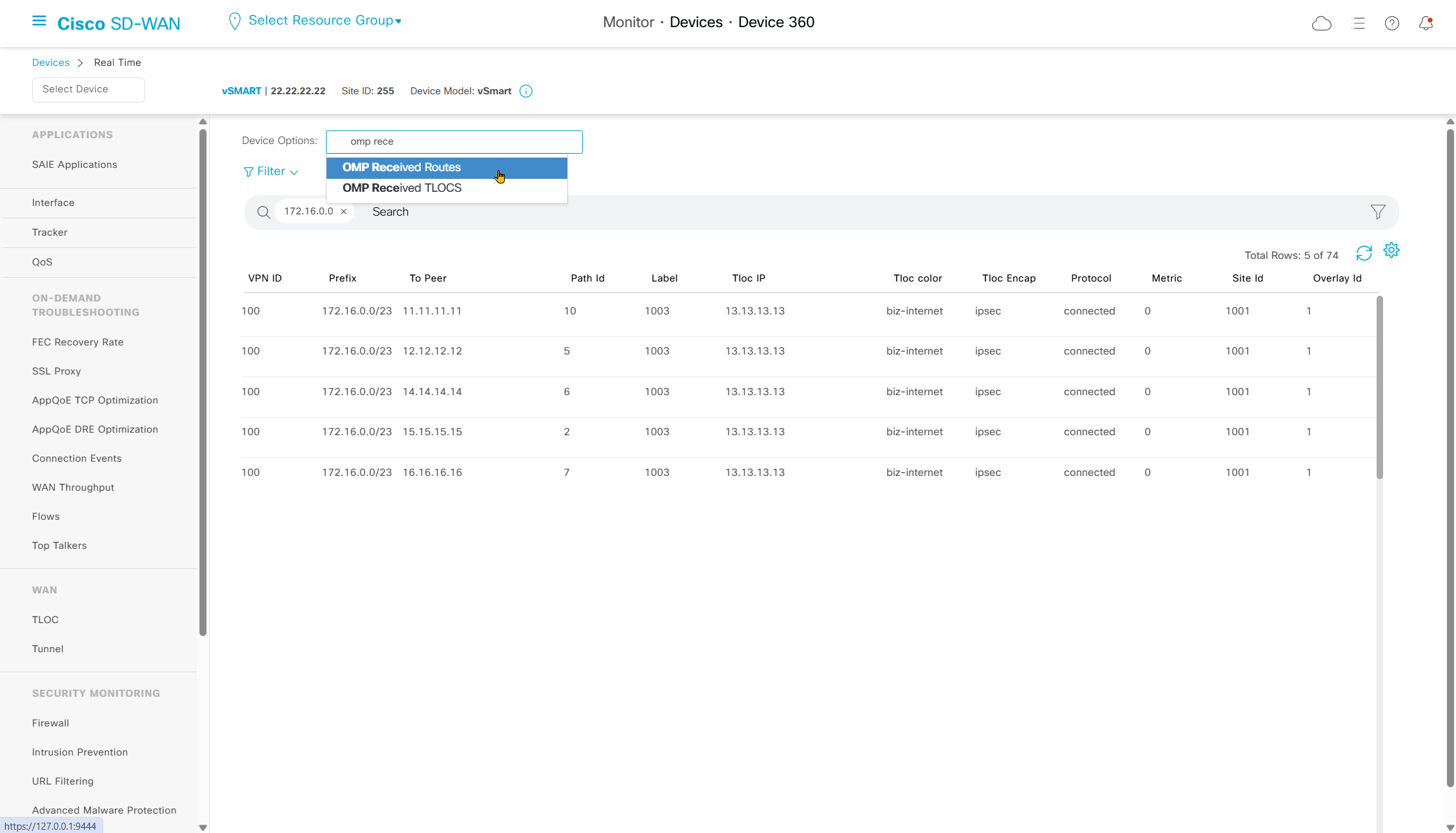
Check if vsmart received it
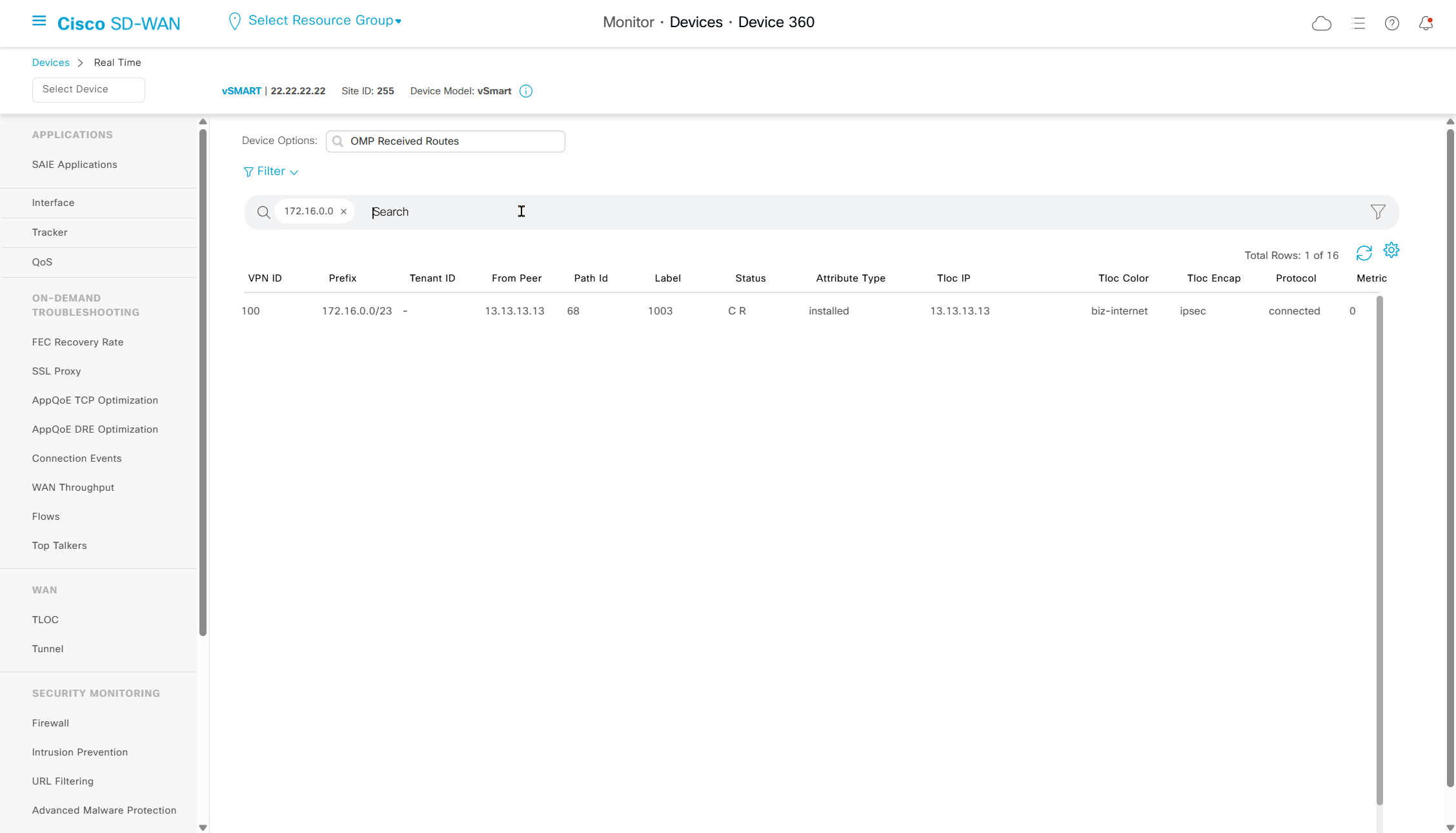
Check if vsmart advertised it to other edges
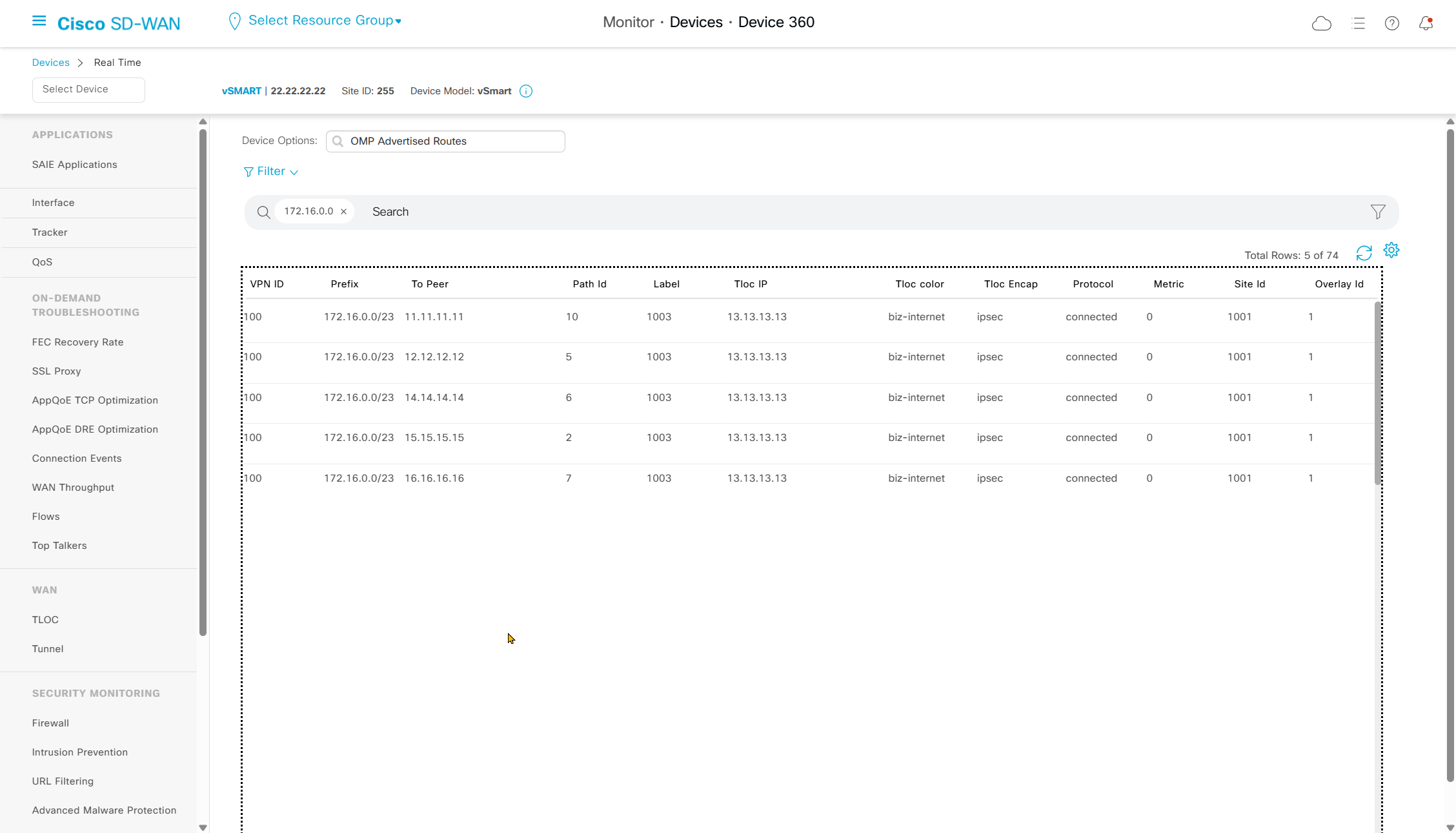
lets go to end router
check if received it
always pay attention to the status column to see if received routes have been installed or not
and that could be because of TLOC being down or route being less preferred
CIR means Chosen , Installed , Resolved
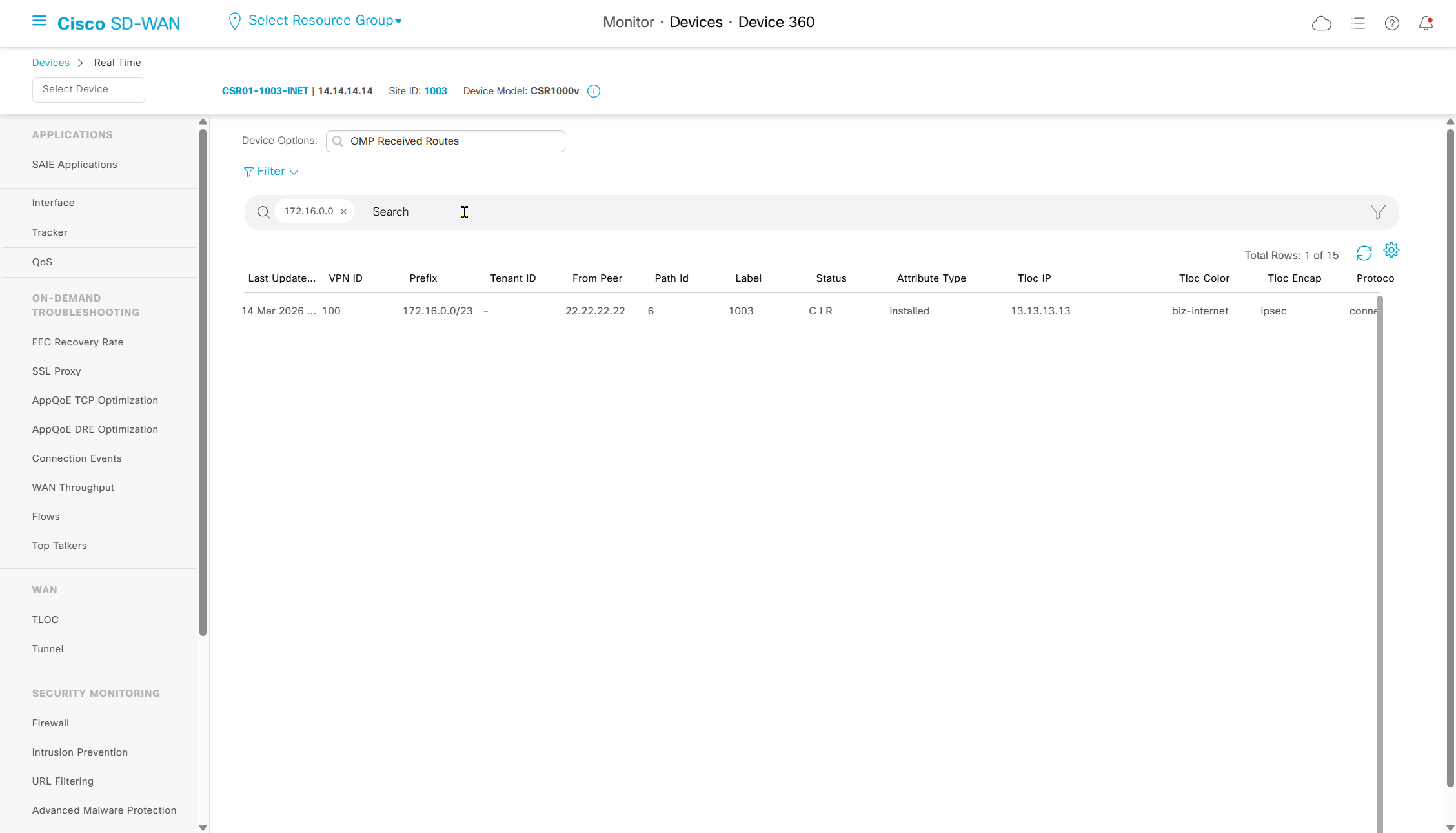
BFD configuration for transport facing IOS-XE peerings
Here we are talking about the IOS-XE BFD and not the BFD that runs over the overlay tunnels
This BFD runs over the router interfaces to quickly detect link failure
When we tie this BFD with routing protocol, it allows routing protocol to react to change much faster rather than its default protocol timer, BFD support started in version 17.3
CSR-1001-INET#show version
Cisco IOS XE Software, Version 17.03.05This BFD tieing to protocol can be done with BGP, EIGRP and OSPF
This can be applied to physical interfaces , SVI or sub interfaces
It works on service and transport side so we can use BFD on BGP peering with MPLS router to provide fast failure detection
As of 20.8 this is not supported in a feature template so we need to use CLI template
A test was carried out and an interface facing the edge node with bgp peering to this MPLS PE router was shut, but on edge node because this is not a direct connection the peering still showed as up for some time (hold time of 180 seconds) and this edge node could ping IP of its interface but could not reach the next hop IP of the MPLS router, so BGP neighborship should have gone down but it did not and it was blackholing the traffic for some time (hold time of 180 seconds) – this is where BFD is implemented
bfd-template single-hop BFD
interval min-tx 1000 min-rx 1000 multiplier 3
! BFD type single hop is used to monitor directly connected devices
! with single hop Neighbor must be directly connected
! Send BFD packets every 1 sec
! Expect to receive BFD packets every 1 sec
! If 3 packets are missed, the neighbor is declared down
interface GigabitEthernet1
bfd template BFD
! BFD will be applied on this interface
! but any protocol "originating" from this interface can use this BFD session
router bgp 10
neighbor 172.31.255.250 fall-over bfd
! telling BGP to use bfd result of the BGP interface IOS-XE configuration
bfd-template single-hop BFD
interval min-tx 1000 min-rx 1000 multiplier 3
interface Ethernet0/1
description MPLS CE
bfd template BFD
!
interface Ethernet0/2
description MPLS CE
bfd template BFD
!
interface Ethernet0/3
description MPLS CE
bfd template BFD
!
interface Ethernet1/0
description MPLS CE
bfd template BFD
router bgp 10
template peer-policy CE
send-community both
exit-peer-policy
!
template peer-session CE
ebgp-multihop 5
timers 5 10
fall-over bfd <<<
show bfd summary
show bfd interface
show bfd neighborsSDWAN CLI template configuration
BFD is attached to physical interface and not tunnel interface, because tunnel interface already has SDWAN version of BFD running
interface GigabitEthernet3.100
ip ospf mtu-ignore
bfd-template single-hop BFD
interval min-tx 1000 min-rx 1000 multiplier 3
interface GigabitEthernet1
bfd template BFD
router bgp {{as_num_cli}}
neighbor {{bgp_peer_ip_cli}} fall-over bfd
sdwan
interface GigabitEthernet1
tunnel-interface
allow-service bfd
no logging console
platform console serialTLOC extension
We could have an INET switch span internet vlan between 2 edge routers but issue is that ISP only provides one internet IP address to use
TLOC extension allows us to share or use one of the colors or WAN transport from another router and build IPSEC / BFD over it
All we need is a way for a router to router connection and there are few options
- Back to back connections per transport for example 1 back to back link on Gig4 for Internet and 1 back to back link on Gig5 for MPLS
- Only one back to back connection but use sub interfaces per transport
- and least preferred option in case you dont have any spare interfaces, is to do sub interfaces on LAN side of the router and use that as the TLOC extension
We are also not allowed to have tloc extension from tunnel interface that is why we either need dedicated interfaces / sub interfaces or we need sub interfaces on LAN interface
Notice that red are tunnels and green is TLOC extension
once a transport is extended via TLOC extension (green dot) and as it terminates on another router (red dot) that red dot becomes the tunnel interface / color
One thing to take care of on MPLS is that we need to advertise the TLOC subnet for MPLS into MPLS network
on the internet side we dont have to advertise the private TLOC subnet, instead everything will be NATed behind internet interface
more…
coming soon
next post
Redistribution
Redistribution
Redistribution is always import feature, when redistribution is configured under a routing protocol it is importing prefixes from the protocol mentioned in redistribute “xxx” command
Only routes that are selected as best paths and installed in the global routing table (RIB) are eligible for redistribution from source protocol, this stops from redistribution of backup paths or longer routes into the protocol, because you dont want EIGRP’s feasible successors (NOT in RIB) but only successor (installed in RIB) similarly OSPF may know multiple paths but you only want the best path (shortest path) from OSPF
A route must exist in the RIB in order for it to be redistributed into the destination protocol. In essence, this provides a safety mechanism by ensuring that the route is deemed reachable by the redistributing router.
OSPF from RIB is mentioned in the path information
show ip route
O 10.13.1.0/24 [110/3] via 10.45.1.4, 00:04:27, GigabitEthernet0/0
show ip eigrp topology 10.13.1.0/24
! Output omitted for brevity
EIGRP-IPv4 Topology Entry for AS(100)/ID(10.56.1.5) for 10.13.1.0/24
State is Passive, Query origin flag is 1, 1 Successor(s), FD is 2560000256
Descriptor Blocks:
10.45.1.4, from Redistributed, Send flag is 0x0
External data:
AS number of route is 1
External protocol is OSPF, external metric is 3When redistributing from a source protocol with a higher AD into a destination protocol with a lower AD, the route shown in the routing table is always that of the source protocol, its not like that now a route is redistributed in protocol of lower AD and ownership has transferred
Using a route map allows for the filtering or modification of route attributes during the injection (catch and change)
Redistribution Sources:
Static – Static routes that are present in RIB
Connected – Interfaces that are in up state only
EIGRP – Any routes in EIGRP, including EIGRP-enabled connected networks.
OSPF – Any routes in the OSPF link-state database (LSDB), including OSPF-enabled interfaces.
BGP – Any routes in the Border Gateway Protocol (BGP) Loc-RIB table learned externally. Internal BGP (iBGP) routes are not redistributed by default and require the command bgp redistribute-internal for redistribution into Interior Gateway Protocol (IGP) routing protocols.
Redistribution Is Not Transitive
When redistributing between two or more routing protocols on a single router, redistribution is not transitive. In other words, when a router redistributes protocol 1 into protocol 2, and protocol 2 redistributes into protocol 3, the routes from protocol 1 are not redistributed into protocol 3. Only routes from protocol 2 are injected into protocol 3 and not include protocol 1
Seed Metrics
Seed means default metric to start with, source protocol must provide some metrics to the destination protocols so that the destination protocol can calculate the best path for the redistributed routes, Every protocol provides a seed metric at the time of redistribution, following are the seed metric offered by protocols
| Protocol | Default Seed Metric |
|---|---|
| EIGRP | Infinity. Routes set with infinity are not installed into the EIGRP topology table. |
| OSPF | All routes are Type 2 external. Routes sourced from BGP use a seed metric of 1, and all other protocols uses a seed metric of 20. |
| BGP | Origin is set to incomplete, the multi-exit discriminator (MED) is set to the IGP metric, and the weight is set to 32,768. |
Protocol specific redistribution behavior
Every routing protocol has a unique redistribution behavior.
redistribute connected
redistribute static
redistribute eigrp as-number
redistribute ospf process-id
redistribute ospf process-id match internal << this is match without Route map
redistribute ospf process-id match external 1 << this is match without Route map
redistribute ospf process-id match external 2 << this is match without Route map
redistribute bgp as-number
redistribute xxx route-map route-map-nameRoute map “match” options
Redistribute connected route-map RM -> match interface Gixxxx
matching interface in route map applied to redistribute “connected”
router ospf 1
redistribute connected route-map RM
!
route-map RM permit 10
match interface GigabitEthernet0/1
!
interface GigabitEthernet0/1
ip address 10.1.1.1 255.255.255.0Matches 10.1.1.0/24
interface on which the connected network exists
It makes sense that when connected are being considered then matching interface will introduce only interfaces in route map – this when we only selectively want to introduce few router interfaces and not all router interface because redistribute connected imports all connected interfaces on routers
redistribute static route-map RM -> match interface Gixxxx
matching interface in route-map applied on redistribute “static”
ip route 10.2.2.0 255.255.255.0 GigabitEthernet0/2match interface matches:
The outgoing interface defined in the static route
✔ This works only if the static route explicitly references an interface ❌ It will NOT match if the static route points to a next-hop IP only – so this will never be used practically
Routes learned via a routing protocol (OSPF, EIGRP, RIP, etc.)
redistribute ospf route-map RM -> match interface Gixxxx
match interface matches:
Only routes learned from OSPF neighbor on that interface
match route-type external [type-1 | type-2]
match route-type internal
match route-type local
match route-type nssa-external [type-1 | type-2]
Selects prefixes based on routing protocol characteristics:
external: External BGP, EIGRP, or OSPF
internal: Internal EIGRP or intra-area/inter-area OSPF routes
local: Locally generated BGP routes
nssa-external: NSSA external (Type 7 LSAs)
Route map set actions
| set Action | Description |
|---|---|
| set as-path prepend {as-number-pattern | last-as 1-10} | Prepends the AS_Path for the network prefix with the pattern specified or uses multiple iterations from the neighboring autonomous system. |
| set ip next-hop {ip-address | peer-address | self} | Sets the next-hop IP address for any matching prefix. BGP dynamic manipulation requires the peer-address or self keywords. |
| set local-preference 0-4294967295 | Sets the BGP PA local preference. |
| set metric {+value | –value | value}* value parameters are 0–4294967295 | Modifies the existing metric or sets the metric for a route. |
| set origin {igp | incomplete} | Sets the BGP PA origin. |
| set weight 0-65535 | Sets the BGP PA weight. |
Connected Networks
A common scenario in “service provider” networks involves the need for external Border Gateway Protocol (eBGP) peering or transit subnet to exist in the routing table of internal BGP (iBGP) routers within the autonomous system. Instead of enabling the IGP routing protocol on the external interface so that the network is installed into the routing topology, the networks could be redistributed into the Interior Gateway Protocol (IGP). Choosing not to enable a routing protocol on that link removes security concerns within the IGP.
router bgp 65100
address-family ipv4
redistribute connected route-map RM-LOOPBACK0
!
route-map RM-LOOPBACK0 permit 10
match interface Loopback0BGP
By default, BGP redistributes only eBGP routes into IGP protocols
BGP’s default behavior requires that a route have an AS_Path to redistribute into an IGP, which means only the eBGP routes are redistributed and not iBGP routes, iBGP routes were not included because it is common assumption that the IGP routing topology already has those internal ibgp like routes
BGP is designed to handle a large routing table, whereas IGPs are not. To redistribute BGP into an IGP on a router with a larger BGP table (for example, the Internet table with 800,000+ routes), you use selective route redistribution. Otherwise, the IGP can become unstable in the routing domain, which can lead to packet loss.
You can change BGP behavior so that all BGP routes are redistributed by using the BGP configuration command bgp redistribute-internal. To enable the iBGP route 192.168.3.3/32 to redistribute into OSPF, the bgp redistribute-internal command is required on R2.
Redistributing iBGP routes into an IGP could result in routing loops. A more logical solution is to advertise the network into the IGP
EIGRP Behaviour
When EIGRP redistributes something into itself, that route is given an AD of 170 and classed as external EIGRP route and use a default seed metric of infinity.
Default seed metric of infinity (effectively “unreachable”) (prevents the route from being installed unless you manually define a metric)
The default path metric can be changed from infinity to specific values for bandwidth, load, delay, reliability, and maximum transmission unit (MTU), thereby allowing for the installation into the EIGRP topology table. Routers can set the default metric with the address family configuration command
default-metric bandwidth delay reliability load mtu
!BDRLMThe metric can also be set within a route map or at the time of redistribution with the command
redistribute source-protocol [metric bandwidth delay reliability load mtu] [route-map route-map-name]EIGRP to EIGRP redistribution (EIGRP AS X into EIGRP AS Y):
EIGRP does carry over the original EIGRP metric components
(bandwidth, delay, reliability, load, MTU)
BUT EIGRP still treats them as external routes in the receiving AS
The routes become EIGRP external (D EX) with:
AD = 170
External tag
“Original metric preserved”
Example config:
R2 mutually redistributes OSPF into EIGRP
R3 mutually redistributes BGP into EIGRP
R1 is advertising the Loopback 0 address 192.168.1.1/32
R4 is advertising the Loopback 0 address 192.168.4.4/32
R2 uses the default-metric configuration command
both classic and named mode configurations
Using default-metric on whole process
R2 (AS Classic Configuration)
router eigrp 100
default-metric 1000000 1 255 1 1500
network 10.23.1.0 0.0.0.255
redistribute ospf 1R2 (Named Mode Configuration)
router eigrp EIGRP-NAMED
address-family ipv4 unicast autonomous-system 100
topology base
default-metric 1000000 1 255 1 1500
redistribute ospf 1
exit-af-topology
network 10.23.1.0 0.0.0.255R3 (Named Mode Configuration)
router eigrp EIGRP-NAMED
address-family ipv4 unicast autonomous-system 100
topology base
redistribute bgp 65100 metric 1000000 1 255 1 1500
exit-af-topology
network 10.23.1.0 0.0.0.255
exit-address-familyUsing route-map
You can overwrite EIGRP seed metrics by setting K values also with the route map command set metric bandwidth delay reliability load mtu. Setting the metric on a prefix-by-prefix basis during redistribution
R2
router eigrp 100
network 10.23.1.0 0.0.0.255
redistribute ospf 1 route-map OSPF-2-EIGRP
!
route-map OSPF-2-EIGRP permit 10
set metric 1000000 1 255 1 1500
R2# show ip eigrp topology
EIGRP-IPv4 Topology Table for AS(100)/ID(192.168.2.2)
Codes: P - Passive, A - Active, U - Update, Q - Query, R - Reply,
r - reply Status, s - sia Status
P 10.34.1.0/24, 1 successors, FD is 3072
via 10.23.1.3 (3072/2816), GigabitEthernet0/1
P 192.168.4.4/32, 1 successors, FD is 3072, tag is 65200
via 10.23.1.3 (3072/2816), GigabitEthernet0/1
P 10.12.1.0/24, 1 successors, FD is 2816
via Redistributed (2816/0)
P 192.168.1.1/32, 1 successors, FD is 2816
via Redistributed (2816/0)
P 10.23.1.0/24, 1 successors, FD is 2816
via Connected, GigabitEthernet0/1The redistributed routes are shown in the routing table with D EX and an AD of 170
R2# show ip route | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 5 subnets, 2 masks
C 10.12.1.0/24 is directly connected, GigabitEthernet0/0
C 10.23.1.0/24 is directly connected, GigabitEthernet0/1
D EX 10.34.1.0/24 [170/3072] via 10.23.1.3, 00:07:43, GigabitEthernet0/1
O 192.168.1.1 [110/2] via 10.12.1.1, 00:29:22, GigabitEthernet0/0
D EX 192.168.4.4 [170/3072] via 10.23.1.3, 00:08:49, GigabitEthernet0/1R3# show ip route | begin Gateway
! Output omitted for brevity
D EX 10.12.1.0/24 [170/15360] via 10.23.1.2, 00:22:27, GigabitEthernet0/1
C 10.23.1.0/24 is directly connected, GigabitEthernet0/1
C 10.34.1.0/24 is directly connected, GigabitEthernet0/0
D EX 192.168.1.1 [170/15360] via 10.23.1.2, 00:22:27, GigabitEthernet0/1
B 192.168.4.4 [20/0] via 10.34.1.4, 00:13:21EIGRP-to-EIGRP Redistribution
Redistributing routes between EIGRP autonomous systems preserves the path metrics during redistribution but still classes them as EIGRP external routes
R2 mutually redistributes routes between AS 10 and AS 20
R3 mutually redistributes routes between AS 20 and AS 30
R1 advertises the Loopback 0 interface (192.168.1.1/32) into EIGRP AS 10
R4 advertises the Loopback 0 interface (192.168.4.4/32) into EIGRP AS 30
The default seed metrics do not need to be set because they are maintained between EIGRP ASs
R2 is using classic configuration mode, and R3 is using EIGRP named configuration mode.
R2
router eigrp 10
network 10.12.1.0 0.0.0.255
redistribute eigrp 20
router eigrp 20
network 10.23.1.0 0.0.0.255
redistribute eigrp 10R3
router eigrp EIGRP-NAMED-20
address-family ipv4 unicast autonomous-system 20
topology base
redistribute eigrp 30
exit-af-topology
network 10.23.1.0 0.0.0.255
!
router eigrp EIGRP-NAMED-30
address-family ipv4 unicast autonomous-system 30
topology base
redistribute eigrp 20
exit-af-topology
network 10.34.1.0 0.0.0.255
exit-address-familyVerification of redistribution on R1 and R4
R1# show ip route eigrp | begin Gateway
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 4 subnets, 2 masks
D EX 10.23.1.0/24 [170/3072] via 10.12.1.2, 00:09:07, GigabitEthernet0/0
D EX 10.34.1.0/24 [170/3328] via 10.12.1.2, 00:05:48, GigabitEthernet0/0
192.168.4.0/32 is subnetted, 1 subnets
D EX 192.168.4.4 [170/131328] via 10.12.1.2, 00:05:48, GigabitEthernet0/0R4# show ip route eigrp | begin Gateway
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 4 subnets, 2 masks
D EX 10.12.1.0/24 [170/3328] via 10.34.1.3, 00:07:31, GigabitEthernet0/0
D EX 10.23.1.0/24 [170/3072] via 10.34.1.3, 00:07:31, GigabitEthernet0/0
192.168.1.0/32 is subnetted, 1 subnets
D EX 192.168.1.1 [170/131328] via 10.34.1.3, 00:07:31, GigabitEthernet0/0EIGRP topology table for the route 192.168.4.4/32 in AS 10 and AS 20. The EIGRP path metrics for bandwidth, reliability, load, and delay are the same between the autonomous systems. Notice that the feasible distance (131,072) is the same for both autonomous systems, but the reported distance (RD) is 0 for AS 10 and 130,816 for AS 20. The RD was reset when it was redistributed into AS 10.
R2# show ip eigrp topology 192.168.4.4/32
! Output omitted for brevity
EIGRP-IPv4 Topology Entry for AS(10)/ID(192.168.2.2) for 192.168.4.4/32
State is Passive, Query origin flag is 1, 1 Successor(s), FD is 131072
Descriptor Blocks:
10.23.1.3, from Redistributed, Send flag is 0x0
Composite metric is (131072/0), route is External
Vector metric:
Minimum bandwidth is 1000000 Kbit
Total delay is 5020 microseconds
Reliability is 255/255
Load is 1/255
Minimum MTU is 1500
Hop count is 2
Originating router is 192.168.2.2
External data:
AS number of route is 20
External protocol is EIGRP, external metric is 131072
Administrator tag is 0 (0x00000000)
EIGRP-IPv4 Topology Entry for AS(20)/ID(192.168.2.2) for 192.168.4.4/32
State is Passive, Query origin flag is 1, 1 Successor(s), FD is 131072
Descriptor Blocks:
10.23.1.3 (GigabitEthernet0/1), from 10.23.1.3, Send flag is 0x0
Composite metric is (131072/130816), route is External
Vector metric:
Minimum bandwidth is 1000000 Kbit
Total delay is 5020 microseconds
Reliability is 255/255
Load is 1/255
Minimum MTU is 1500
Hop count is 2
Originating router is 192.168.3.3
External data:
AS number of route is 30
External protocol is EIGRP, external metric is 2570240OSPF Behaviour
The AD is set to 110 for intra-area, inter-area, and external OSPF routes. External OSPF routes are classified as Type 1 or Type 2, with Type 2 as the default setting. The seed metric is 1 for BGP-sourced routes and 20 for all other protocols
The exception is that if OSPF redistributes from another OSPF process, the path metric is transferred. The main differences between Type 1 and Type 2 external OSPF routes follow:
Type 1 routes are preferred over Type 2 routes.
The Type 1 metric equals the redistribution metric plus the total path metric to the autonomous system boundary router (ASBR). In other words, as the LSA propagates away from the originating ASBR, the metric increases.
The Type 2 metric equals only the redistribution metric. The metric is the same for the router next to the ASBR as for the router 30 hops away from the originating ASBR. If two Type 2 paths have exactly the same metric, the lower forwarding cost is preferred. This is the default external metric type used by OSPF.
For redistribution into OSPF, you use the command redistribute source-protocol [subnets] [metric metric] [metric-type {1 | 2}] [tag 0-4294967295] [route-map route-map-name].
If the optional subnets keyword is not included, only the classful networks are redistributed.
The optional tag keyword allows for a 32-bit route tag to be included on each redistributed route.
The metric and metric-type keywords can be set during redistribution.
R2 mutually redistributes EIGRP into OSPF
R3 mutually redistributes RIP into OSPF
R1 is advertising the Loopback 0 interface 192.168.1.1/32
R4 is advertising the Loopback 0 interface 192.168.4.4/32.
R2
router ospf 2
router-id 192.168.2.2
network 10.23.1.0 0.0.0.255 area 0
redistribute eigrp 100 subnetsR3
router ospf 3
router-id 192.168.3.3
redistribute rip subnets
network 10.23.1.3 0.0.0.0 area 0Redistribution verification
R3# show ip ospf database external
! Output omitted for brevity
OSPF Router with ID (192.168.3.3) (Process ID 2)
Type-5 AS External Link States
Link State ID: 10.12.1.0 (External Network Number )
Advertising Router: 192.168.2.2
Network Mask: /24
Metric Type: 2 (Larger than any link state path)
Metric: 20
Link State ID: 10.34.1.0 (External Network Number )
Advertising Router: 192.168.3.3
Network Mask: /24
Metric Type: 2 (Larger than any link state path)
Metric: 20
Link State ID: 192.168.1.1 (External Network Number )
Advertising Router: 10.23.1.2
Network Mask: /32
Metric Type: 2 (Larger than any link state path)
Metric: 20
Link State ID: 192.168.4.4 (External Network Number )
Advertising Router: 192.168.3.3
Network Mask: /32
Metric Type: 2 (Larger than any link state path)
Metric: 20R2# show ip route | begin Gateway
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 5 subnets, 2 masks
C 10.12.1.0/24 is directly connected, GigabitEthernet0/0
C 10.23.1.0/24 is directly connected, GigabitEthernet0/1
O E2 10.34.1.0/24 [110/20] via 10.23.1.3, 00:04:44, GigabitEthernet0/1
192.168.1.0/32 is subnetted, 1 subnets
D 192.168.1.1 [90/130816] via 10.12.1.1, 00:03:56, GigabitEthernet0/0
192.168.2.0/32 is subnetted, 1 subnets
C 192.168.2.2 is directly connected, Loopback0
O E2 192.168.4.0/24 [110/20] via 10.23.1.3, 00:04:42, GigabitEthernet0/1R3# show ip route | begin Gateway
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 5 subnets, 2 masks
O E2 10.12.1.0/24 [110/20] via 10.23.1.2, 00:05:41, GigabitEthernet0/1
C 10.23.1.0/24 is directly connected, GigabitEthernet0/1
C 10.34.1.0/24 is directly connected, GigabitEthernet0/0
192.168.1.0/32 is subnetted, 1 subnets
O E2 192.168.1.1 [110/20] via 10.23.1.2, 00:05:41, GigabitEthernet0/1
192.168.3.0/32 is subnetted, 1 subnets
C 192.168.3.3 is directly connected, Loopback0
R 192.168.4.0/24 [120/1] via 10.34.1.4, 00:00:00, GigabitEthernet0/0OSPF-to-OSPF Redistribution
Redistributing routes between OSPF processes preserves the path metric during redistribution, independent of the metric type
R2 redistributes routes between OSPF process 1 and OSPF process 2
R3 redistributes between OSPF process 2 and OSPF process 3.
R2 and R3 set the metric type to 1 during redistribution so that the path metric increments
R1 advertises the Loopback 0 interface 192.168.1.1/32 into OSPF process 1
R4 advertises the Loopback 0 interface 192.168.4.4/32 into OSPF process 3.
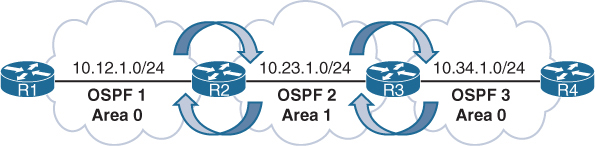
but it results in the loss of path information as the Type 1, Type 2, and Type 3 LSAs are not propagated through route redistribution, only metrics are maintained
R2# show running-config | section router ospf
router ospf 1
redistribute ospf 2 subnets metric-type 1
network 10.12.1.0 0.0.0.255 area 0
router ospf 2
redistribute ospf 1 subnets metric-type 1
network 10.23.1.0 0.0.0.255 area 1R3# show running-config | section router ospf
router ospf 2
redistribute ospf 3 subnets metric-type 1
network 10.23.1.0 0.0.0.255 area 1
router ospf 3
redistribute ospf 2 subnets metric-type 1
network 10.34.1.0 0.0.0.255 area 0Verification on R1 and R4
R1# show ip route ospf | begin Gateway
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 4 subnets, 2 masks
O E1 10.23.1.0/24 [110/2] via 10.12.1.2, 00:00:21, GigabitEthernet0/0
O E1 10.34.1.0/24 [110/3] via 10.12.1.2, 00:00:21, GigabitEthernet0/0
192.168.4.0/32 is subnetted, 1 subnets
O E1 192.168.4.4 [110/4] via 10.12.1.2, 00:00:21, GigabitEthernet0/0R4# show ip route ospf | begin Gateway
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 4 subnets, 2 masks
O E1 10.12.1.0/24 [110/3] via 10.34.1.3, 00:01:36, GigabitEthernet0/0
O E1 10.23.1.0/24 [110/2] via 10.34.1.3, 00:01:46, GigabitEthernet0/0
192.168.1.0/32 is subnetted, 1 subnets
O E1 192.168.1.1 [110/4] via 10.34.1.3, 02:38:49, GigabitEthernet0/0OSPF Forwarding Address
OSPF Type 5 LSAs include a field known as the forwarding address that optimizes forwarding traffic when the source uses a shared network segment
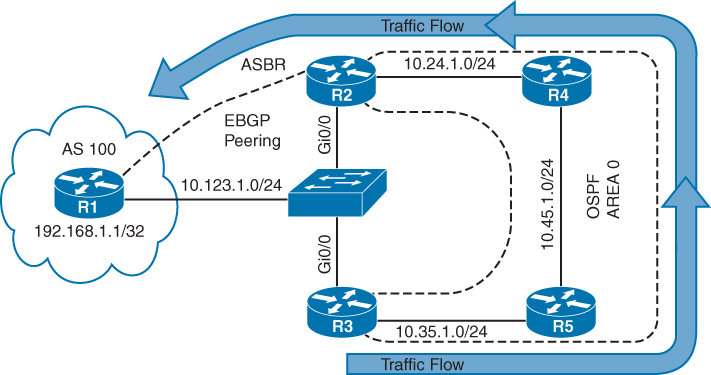
OSPF is enabled on all the links in Area 0 except for network 10.123.1.0/24
R1 forms an eBGP session with R2 (the ASBR) which then redistributes the AS 100 route 192.168.1.1/32 into the OSPF domain
R3 has direct connectivity to R1 but does not establish a BGP session with R1
ASBR is 10.123.1.2 which is the IP address that all OSPF routers forward packets to in order to reach the 192.168.1.1/32 network
Notice that the forwarding address is the default value 0.0.0.0
R3# show ip ospf database external
! Output omitted for brevity
Type-5 AS External Link States
Routing Bit Set on this LSA in topology Base with MTID 0
LS Type: AS External Link
Link State ID: 192.168.1.1 (External Network Number )
Advertising Router: 10.123.1.2
Network Mask: /32
Metric Type: 2 (Larger than any link state path)
Metric: 1
Forward Address: 0.0.0.0Network traffic from R3 (and R5) takes the suboptimal route R3→R5→R4→R2→R1
The optimal route would use the directly connected 10.123.1.0/24 network
R3# trace 192.168.1.1
Tracing the route to 192.168.1.1
1 10.35.1.5 0 msec 0 msec 1 msec
2 10.45.1.4 0 msec 0 msec 0 msec
3 10.24.1.2 1 msec 0 msec 0 msec
4 10.123.1.1 1 msec * 0 msecR5# trace 192.168.1.1
Tracing the route to 192.168.1.1
1 10.45.1.4 0 msec 0 msec 0 msec
2 10.24.1.2 1 msec 0 msec 0 msec
3 10.123.1.1 1 msec * 0 msecWhen the forwarding address is 0.0.0.0, all routers forward packets to the ASBR, introducing the potential for suboptimal routing.
The OSPF forwarding address changes from 0.0.0.0 “to the next-hop IP address in the source routing protocol” when:
- OSPF is enabled on the ASBR’s interface that points to the next-hop IP address.
- That interface is not set to passive.
- That interface is a broadcast or nonbroadcast OSPF network type.
When the forwarding address is set to a value besides 0.0.0.0, the OSPF routers forward traffic only to the forwarding address.
OSPF has been enabled on R2’s and R3’s Ethernet interface connected to the 10.123.1.0/24 network,
The interface is Ethernet, which defaults to the broadcast OSPF network type, and all conditions have been met.
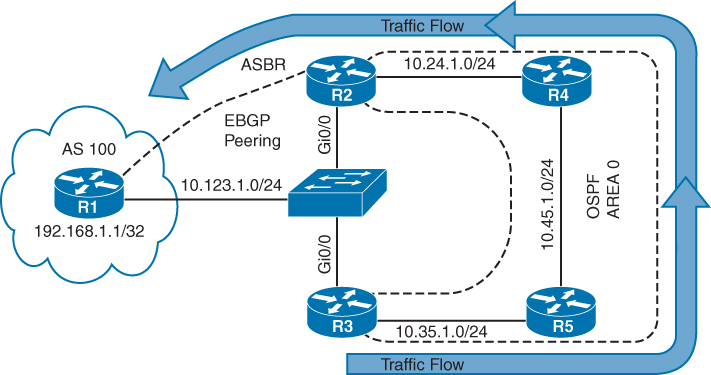
Type 5 LSA for the 192.168.1.1/32 network. Now that OSPF has been enabled on R2’s 10.123.1.2 interface and the interface is a broadcast network type, the forwarding address has changed from 0.0.0.0 to 10.123.1.1.
R3# show ip ospf database external
! Output omitted for brevity
Type-5 AS External Link States1
Options: (No TOS-capability, DC)
LS Type: AS External Link
Link State ID: 192.168.1.1 (External Network Number )
Advertising Router: 10.123.1.2
Network Mask: /32
Metric Type: 2 (Larger than any link state path)
Metric: 1
Forward Address: 10.123.1.1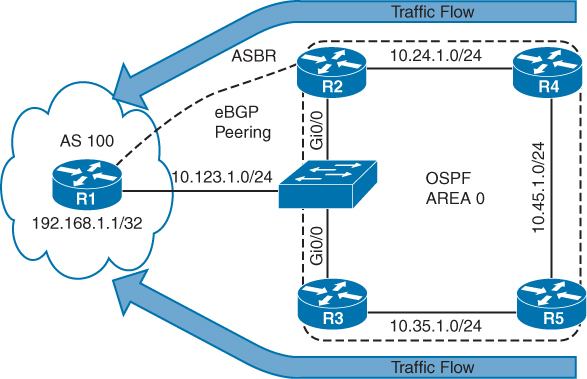
verifies that connectivity from R3 and R5 now takes the optimal path to R1 because the forwarding address has changed to 10.123.1.1.
R3# trace 192.168.1.1
Tracing the route to 192.168.1.1
1 10.123.1.1 0 msec * 1 msecR5# trace 192.168.1.1
Tracing the route to 192.168.1.1
1 10.35.1.3 0 msec 0 msec 1 msec
2 10.123.1.1 0 msec * 1 msecIf the Type 5 LSA forwarding address is not a default value, the address must be an intra-area or inter-area OSPF route
If the route does not exist, the LSA is ignored and is not installed into the RIB
The OSPF forwarding address optimizes forwarding toward the destination network, but return traffic is unaffected. Outbound traffic from R3 or R5 still exits at R3’s Gi0/0 interface, but return traffic is sent directly to R2.
BGP Behaviour
Redistributing routes into BGP does not require a seed metric because BGP is a path vector protocol. Redistributed routes have the following BGP attributes set.
The origin is set to incomplete.
The next-hop address is set to the IP address of the source protocol
The weight is set to 32,768
The MED is set to the path metric of the source protocol
R2 mutually redistributes between OSPF and BGP
R3 mutually redistributes between EIGRP AS 100 and BGP
R1 is advertising the Loopback 0 interface 192.168.1.1/32
R4 is advertising the Loopback 0 interface 192.168.4.4/32
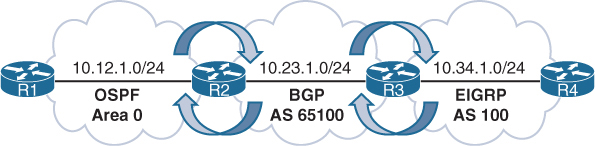
Notice that R2 and R3 have used the command bgp redistribute-internal, which allows for any iBGP learned prefixes to be redistributed into OSPF or EIGRP
R2 (Default IPv4 Address Family Enabled)
router bgp 65100
bgp redistribute-internal
network 10.23.1.0 mask 255.255.255.0
redistribute ospf 1
neighbor 10.23.1.3 remote-as 65100R3 (Default IPv4 Address Family Disabled)
router bgp 65100
no bgp default ipv4-unicast
neighbor 10.23.1.2 remote-as 65100
!
address-family ipv4
bgp redistribute-internal
network 10.23.1.0 mask 255.255.255.0
redistribute eigrp 100
neighbor 10.23.1.2 activate
exit-address-familyVerification, notice the metric is carried over from the IGP metric during redistribution
R2# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.12.1.0/24 0.0.0.0 0 32768 ?
* i 10.23.1.0/24 10.23.1.3 0 100 0 i
*> 0.0.0.0 0 32768 i
*>i 10.34.1.0/24 10.23.1.3 0 100 0 ?
*> 192.168.1.1/32 10.12.1.1 2 32768 ?
*>i 192.168.4.4/32 10.34.1.4 130816 100 0 ?Detailed BGP path information for the redistributed routes
The origin is incomplete, and the BGP metric matches the IGP metric.
R2# show bgp ipv4 unicast 192.168.1.1
! Output omitted for brevity
BGP routing table entry for 192.168.1.1/32, version 3
Paths: (1 available, best #1, table default)
Local
10.12.1.1 from 0.0.0.0 (192.168.2.2)
Origin incomplete, metric 2, localpref 100, weight 32768, valid, sourced, bestR3# show bgp ipv4 unicast 192.168.4.4
BGP routing table entry for 192.168.4.4/32, version 3
Paths: (1 available, best #1, table default)
Local
10.34.1.4 from 0.0.0.0 (10.34.1.3)
Origin incomplete, metric 130816, localpref 100, weight 32768, valid, sourced,
bestRedistribution of routes from OSPF to BGP does not include OSPF external routes by default. match external [1 | 2] is required to redistribute OSPHighly available network designs use multiple points of redistribution to ensure redundancy, which increases the probability of route feedback. Route feedback can cause suboptimal routing or routing loops, but it can be resolved with the techniques explained in this chapter and in Chapter 12, “Advanced BGP.”F external routes.
Redistribution and Redundancy
Due to redundancy in networks, there are usually 2 redistirbuting points in the network, but following issues may arise
- Suboptimal routing – slow connectivity
- Routing loops – Total loss of service
Suboptimal routing
Whenever redistribution takes place, network visiblity is lost and seed metric is used as a starting point and this is not an issue when there is only one point of redistribution in the network however it can become an issue if there are 2 or more points of redistribution and it can cause sub optimal routing to the destination learned via redistribution
Left to right, better path to reach 192.168.2.0/24 is via R2 because via R1 we will encounter R1’s 10Mbps link which is slowest in the topology
When you perform redistribution on R1 and R2 (Internal Routers) into EIGRP, EIGRP does not know that the 10 Mbps link or the 1 Gbps link exists in the OSPF domain, in order to avoid this situation we have to add lower seed metric on R2 and higher seed metric on R1
Same Seed Metric
In case seed metric defined on R1 and R2 are same, in EIGRP AS or domain, after adding seed metric (distance vector calculation) and cost of links (1 Gbps link and 100 Mbps links), inside EIGRP AS route to 192.168.2.0/24 through R1 will win and from there I will be routed over the 10 Mbps link
You can recognize this issue in a topological diagram and also by using the traceroute command
You can solve this issue by providing lower seed metric on R2 and higher seed metric on R1
In reverse when EIGRP routes (10.1.1.0/24) are redistributed into OSPF, the redistributed routes have a default seed metric of 20 and are classified as E2 routes;
Due to E2 routes, the metric remains as 20 throughout the OSPF domain, whenever E2 are used we need to keep in mind that routes
next post
OSPF
OSPF
OSPF is a link state routing protocol, an IGP
OSPF exchanges routing information with other routers , neighbors over LSA
LSA contains information on the link state (Subnet(s) on interface(s)) and link metric (cost to reach that IP and mask)
OSPF advertises this information to neighboring routers exactly as the original advertising router advertised it, in fact the whole area gets same LSAs and it is up to individual routers to compute SPT (Shortest Path Tree [to every subnet])
Received LSAs are stored in a local database called the link-state database (LSDB).
and then local router spreads LSAs through the OSPF area, interface by interface – link local multicast to next interface’s link local multicast.
All OSPF routers run Dijkstra’s shortest path first (SPF) algorithm to construct a loop-free topology of shortest paths. OSPF dynamically detects topology changes within the network and calculates loop-free paths in a short amount of time – this is the main purpose of all the routing protocols so we dont have to add static routes through the network and OSPF brings that
Each router sees itself as the root or top of the SPF tree (SPT), and the SPT contains all network destinations within the OSPF domain. The SPT differs for each OSPF router, but the LSDB used to calculate the SPT is identical for all OSPF routers.
There seems to be some difference in connectivity to the 10.3.3.0/24 network from R1’s and R4’s SPTs. From R1’s perspective, the serial link between R3 and R4 is missing; from R4’s perspective, the Ethernet link between R1 and R3 is missing.
The SPTs give the illusion that no redundancy exists to the networks, but remember that an SPT shows the shortest path to reach a network and is built from the LSDB, which contains all the links for an area.
A router can run multiple OSPF processes. Each process maintains its own unique database, and routes learned in one OSPF process are not available to a different OSPF process without redistribution of routes between processes.
The OSPF process numbers are locally significant and do not have to match among routers. If OSPF process number 1 is running on one router and OSPF process number 1234 is running on another, the two routers can become neighbors.
Areas
OSPF allows scalability by using areas
Area is set at interface level
An interface can belong to only one area
All routers within the same OSPF area maintain an identical copy of the LSDB.
Inside an area:
-A full SPT calculation runs when a link flaps within the area
-With a single area, the LSDB increases in size and becomes unmanageable, as area grows, consumes more memory, and takes longer during the SPF computation process.
-With a single area, no summarization of route information occurs.
If a router has interfaces in multiple areas, the router has multiple LSDBs (one for each area)
The internal topology of one area is invisible from outside that area. Outside areas only learn the prefixes of that area, only topology is not visible (like which prefix is attached to which router), outside areas just know about the prefixes
If a topology change occurs (such as a link flap or an additional network added) within an area, all routers in the same OSPF area calculate the SPT again. Routers outside that area do perform a partial SPF calculation
Segmenting the OSPF domain into multiple areas reduces the size of the LSDB for each area, making SPT calculations faster and decreasing LSDB flooding between routers when a link flaps.
Just because a router connects to multiple OSPF areas does not mean the routes from one area will be injected into another area
Area 0 is a special area called backbone area. OSPF uses a two-tier hierarchy in which all areas must connect to the upper tier Area 0.
All areas inject routing information into Area 0
Area 0 advertises the routes into other areas
Area ID is a 32-bit field and can be formatted as decimal (0 through 4294967295) or dotted decimal (0.0.0.0 through 255.255.255.255) like IPv4
If we use decimal format on one router and dotted-decimal format on a different router, the routers will be able to form an adjacency.
ABRs
Area border routers (ABRs) are OSPF routers connected to Area 0 and another OSPF area, ABR is responsible for sending its connected Area’s routes into -> Area 0 and send all the learned routes from all areas from Area 0’s routes into its areas
Every ABR must participate in Area 0
ABRs compute an SPT for every area that they participate in
OSPF Communication
OSPF runs directly over IPv4, using protocol 89 and does not use TCP or UDP because OSPF communication never travels over distance, it stays on link local using multicast
There are two OSPF multicast addresses:
AllSPFRouters: IPv4 address 224.0.0.5, 01:00:5E:00:00:05.
AllDRouters: IPv4 address 224.0.0.6, 01:00:5E:00:00:06
Remember multicast address of OSPF using 5E, E if flipped becomes M and 5 is S so Multicast
OSPF Packet Types
| 1 | Hello | Packets are sent out periodically on all OSPF interfaces to discover new neighbors while also ensuring that existing neighbors are still online. |
| 2 | Database description (DBD or DDP) | Packets are exchanged when an OSPF adjacency is first being formed. These packets are used to describe the contents of the LSDB, Remember only describe |
| 3 | Link-state request (LSR) | When a router thinks that part of its LSDB is stale after reading the DBD, it may request a portion of a neighbor’s database by using this packet type. |
| 4 | Link-state update (LSU) | This is the “LSA” for a specific network link, and normally it is sent in direct response to an LSR. |
| 5 | Link-state acknowledgment | These packets are sent in response to the flooding of LSAs, thus making the flooding a reliable transport feature. |
Router ID
The OSPF router ID (RID) is unique and identifies router in OSPF domain as a unique participant. The OSPF RID is an essential component in building an OSPF topology. The output of some OSPF commands uses the term neighbor ID as a synonym for RID. The RID must be unique for each OSPF process in an OSPF domain and must be unique between OSPF processes on a router.
The RID is dynamically allocated by default, using the highest IP address of any up loopback interfaces. If there are no up loopback interfaces, the highest IP address of any active up physical interfaces becomes the RID when the OSPF process initializes. The OSPF process selects the RID when the OSPF process initializes, and it does not change until the process restarts. This means that the RID can change if a higher loopback address has been added and the process (or router) is restarted.
Setting a static RID helps with troubleshooting and reduces LSAs when an RID changes in an OSPF environment
OSPF Hello Packets
OSPF Hello packets discover and maintain already discovered neighbors
OSPF router sends out hello on AllSPFRouters 224.0.0.5
Information carried inside OSPF hello:
| Router ID (RID) | A unique 32-bit ID within an OSPF domain that is used to build the topology. |
| Authentication Options | A field that allows secure communication between OSPF routers to prevent malicious activity. Options are none, plaintext, or Message Digest 5 (MD5) authentication. |
| Area ID | The OSPF area that the OSPF interface belongs to. It is a 32-bit number that can be written in dotted-decimal format (0.0.1.0) or decimal (256). |
| Interface Address Mask | The network mask for the primary IP address for the interface out which the hello is sent. |
| Interface Priority | The router interface priority for DR elections. |
| Hello Interval | The time interval, in seconds, at which a router sends out hello packets on the interface. |
| Dead Interval | The time interval, in seconds, that a router waits to hear a hello from a neighbor router before it declares that router down. |
| Designated Router and Backup Designated Router | The IP address of the DR and backup DR (BDR) for that network link. |
| Active Neighbor | A list of OSPF neighbors seen on that network segment. To qualify in this neighbor list a router must have received a hello from the neighbor within the dead interval. |
See how Active neighbors and DR / BDR information is inside the hello packets
Neighbors
An OSPF neighbor is a router that shares a common OSPF-enabled network link
Discover neighbors through hello messages
An adjacent OSPF neighbor is an OSPF neighbor that has shared all the LSDB to its neighbor as opposed to 2 way
OSPF Neighbor States
| Down | Router has not yet received hello yet |
| Attempt | A state that is relevant to nonbroadcast multi-access (NBMA) networks that do not support broadcast and require neighbor configuration. This state indicates that the router is still attempting communication. |
| Init | A state in which a hello packet has been received from another router, but bidirectional communication has not been established. Remember from “in” in Init |
| 2-Way | A state in which bidirectional communication has been established. If a DR or BDR is needed, the election occurs during this state. |
| ExStart | The first state in forming an adjacency. Routers identify which router will be the primary or secondary for the LSDB synchronization. |
| Exchange | A state during which routers are exchanging link states by using DBD packets. |
| Loading | A state in which LSR packets are sent to the neighbor, asking for the more recent LSAs that have been discovered (but not received) in the Exchange state. |
| Full | A state in which neighboring routers are fully adjacent. |
Neighbor Adjacency Requirements
R – The RIDs must be unique for whole OSPF domain, To prevent errors, they should be unique for the entire OSPF routing domain.
S – The interfaces must share a common subnet. OSPF uses the interface’s primary IP address when sending out OSPF hellos. The network mask (netmask) in the hello packet is used to extract the network ID of the hello packet.
M – The interface maximum transmission unit (MTU) must match because the OSPF protocol does not support fragmentation.
A – The area ID must match for that segment.
D – The need for a DR must match for that segment.
H – OSPF hello and dead timers must match for that segment.
A – The authentication type and credentials (if any) must match for that segment.
T – Area type flags must be identical for that segment (stub, NSSA, and so on).
see step 2 and 3, init and 2 way, how the neighbor list builds up
R1# debug ip ospf adj
OSPF adjacency events debugging is on
*21:10:01.735: OSPF: Build router LSA for area 0, router ID 192.168.1.1,
seq 0x80000001, process 1
*21:10:09.203: OSPF: 2 Way Communication to 192.168.2.2 on GigabitEthernet0/0,
state 2WAY
*21:10:39.855: OSPF: Rcv DBD from 192.168.2.2 on GigabitEthernet0/0 seq 0x1823
opt 0x52 flag 0x7 len 32 mtu 1500 state 2WAY
*21:10:39.855: OSPF: Nbr state is 2WAY
*21:10:41.235: OSPF: end of Wait on interface GigabitEthernet0/0
*21:10:41.235: OSPF: DR/BDR election on GigabitEthernet0/0
*21:10:41.235: OSPF: Elect BDR 192.168.2.2
*21:10:41.235: OSPF: Elect DR 192.168.2.2
*21:10:41.235: DR: 192.168.2.2 (Id) BDR: 192.168.2.2 (Id)
*21:10:41.235: OSPF: GigabitEthernet0/0 Nbr 192.168.2.2: Prepare dbase exchange
*21:10:41.235: OSPF: Send DBD to 192.168.2.2 on GigabitEthernet0/0 seq 0xFA9
opt 0x52 flag 0x7 len 32
*21:10:44.735: OSPF: Rcv DBD from 192.168.2.2 on GigabitEthernet0/0 seq 0x1823
opt 0x52 flag 0x7 len 32 mtu 1500 state EXSTART
*21:10:44.735: OSPF: GigabitEthernet0/0 Nbr 2.2.2.2: Summary list built, size 1
*21:10:44.735: OSPF: Send DBD to 192.168.2.2 on GigabitEthernet0/0 seq 0x1823
opt 0x52 flag 0x2 len 52
*21:10:44.743: OSPF: Rcv DBD from 192.168.2.2 on GigabitEthernet0/0 seq 0x1824
opt 0x52 flag 0x1 len 52 mtu 1500 state EXCHANGE
*21:10:44.743: OSPF: Exchange Done with 192.168.2.2 on GigabitEthernet0/0
*21:10:44.743: OSPF: Send LS REQ to 192.168.2.2 length 12 LSA count 1
*21:10:44.743: OSPF: Send DBD to 192.168.2.2 on GigabitEthernet0/0 seq 0x1824
opt 0x52 flag 0x0 len 32
*21:10:44.747: OSPF: Rcv LS UPD from 192.168.2.2 on GigabitEthernet0/0 length
76 LSA count 1
*21:10:44.747: OSPF: Synchronized with 192.168.2.2 GigabitEthernet0/0, state FULL
*21:10:44.747: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.2.2 on GigabitEthernet0/0
from LOADING to FULL, Loading DoneOSPF Configuration
Most configuration for OSPF is done under OSPF process but some configuration can be done at interface level
command ip ospf process-id area area-id [secondaries none]. This method also adds secondary connected networks to the LSDB unless the secondaries none option is used.
Making the network interface passive still adds the network segment to the LSDB but prevents the interface from forming OSPF adjacencies. A passive interface does not send out OSPF hellos and does not process any received OSPF packets.
The command passive-interface interface-id under the OSPF process makes the interface passive, and the command passive-interface default makes all interfaces passive, Then command no passive-interface interface-id is used to make interfaces non passive
Different ways of configuring OSPF
R1
router ospf 1
router-id 192.168.1.1
network 0.0.0.0 255.255.255.255 area 1234R2
router ospf 1
router-id 192.168.2.2
network 10.123.1.2 0.0.0.0 area 1234
network 10.24.1.2 0.0.0.0 area 1234R3
router ospf 1
router-id 192.168.3.3
network 0.0.0.0 255.255.255.255 area 1234
passive-interface GigabitEthernet0/1R3
router ospf 1
router-id 192.168.3.3
network 0.0.0.0 255.255.255.255 area 1234
passive-interface GigabitEthernet0/1R4
router ospf 1
router-id 192.168.4.4
!
interface GigabitEthernet0/0
ip ospf 1 area 0
interface Serial1/0
ip ospf 1 area 1234R5
router ospf 1
router-id 192.168.5.5
network 10.45.1.0 0.0.0.255 area 0
network 0.0.0.0 255.255.255.255 area 56R6
router ospf 1
router-id 192.168.6.6
network 0.0.0.0 255.255.255.255 area 56R4# show ip ospf interface
GigabitEthernet0/0 is up, line protocol is up
Internet Address 10.45.1.4/24, Area 0, Attached via Interface Enable
Process ID 1, Router ID 192.168.4.4, Network Type BROADCAST, Cost: 1
Topology-MTID Cost Disabled Shutdown Topology Name
0 1 no no Base
Enabled by interface config, including secondary ip addresses
Transmit Delay is 1 sec, State BDR, Priority 1
Designated Router (ID) 192.168.5.5, Interface address 10.45.1.5
Backup Designated router (ID) 192.168.4.4, Interface address 10.45.1.4
Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5
oob-resync timeout 40
Hello due in 00:00:02
..
Neighbor Count is 1, Adjacent neighbor count is 1
Adjacent with neighbor 192.168.5.5 (Designated Router)
Suppress hello for 0 neighbor(s)
Serial1/0 is up, line protocol is up
Internet Address 10.24.1.4/29, Area 1234, Attached via Interface Enable
Process ID 1, Router ID 192.168.4.4, Network Type POINT_TO_POINT, Cost: 64
Topology-MTID Cost Disabled Shutdown Topology Name
0 64 no no Base
Enabled by interface config, including secondary ip addresses
Transmit Delay is 1 sec, State POINT_TO_POINT
Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5
..
Neighbor Count is 1, Adjacent neighbor count is 1
Adjacent with neighbor 192.168.2.2
Suppress hello for 0 neighbor(s)R1# show ip ospf interface brief
Interface PID Area IP Address/Mask Cost State Nbrs F/C
Gi0/0 1 1234 10.123.1.1/24 1 DROTH 2/2R2# show ip ospf interface brief
Interface PID Area IP Address/Mask Cost State Nbrs F/C
Se1/0 1 1234 10.24.1.1/29 64 P2P 1/1
Gi0/0 1 1234 10.123.1.2/24 1 BDR 2/2R3# show ip ospf interface brief
Interface PID Area IP Address/Mask Cost State Nbrs F/C
Gi0/1 1 1234 10.3.3.3/24 1 DR 0/0
Gi0/0 1 1234 10.123.1.3/24 1 DR 2/2R4# show ip ospf interface brief
Interface PID Area IP Address/Mask Cost State Nbrs F/C
Gi0/0 1 0 10.45.1.4/24 1 BDR 1/1
Se1/0 1 1234 10.24.1.4/29 64 P2P 1/1PID
The OSPF process ID associated with this interface
Nbrs F
This is neighbors that are “Fully” adjacent, The number of neighbor OSPF routers for a segment that are fully adjacent
Nbrs C
This is neighbor “Count”, The number of neighbor OSPF routers for a segment that have been detected and are in a 2-Way state
DROTHERs do not establish full adjacency with other DROTHERs.
show ip ospf neighbor [detail]
R2# show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
192.168.4.4 0 FULL/ - 00:00:38 10.24.1.4 Serial1/0
192.168.1.1 1 FULL/DROTHER 00:00:37 10.123.1.1 GigabitEthernet0/0
192.168.3.3 1 FULL/DR 00:00:34 10.123.1.3 GigabitEthernet0/0Notice that the state for R2’s S1/0 interface does not reflect a DR status with its peering with R4 (192.168.4.4) because a DR can not exist on a point-to-point link so it simply shows –
R1# show ip route ospf
! Output omitted for brevity
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
Gateway of last resort is not set
O 10.3.3.0/24 [110/2] via 10.123.1.3, 00:18:54, GigabitEthernet0/0
O 10.24.1.0/29 [110/65] via 10.123.1.2, 00:18:44, GigabitEthernet0/0
O IA 10.45.1.0/24 [110/66] via 10.123.1.2, 00:11:54, GigabitEthernet0/0
O IA 10.56.1.0/24 [110/67] via 10.123.1.2, 00:11:54, GigabitEthernet0/0two sets of numbers are presented in brackets (for example, [110/2]). The first number is the administrative distance (AD), which is 110 by default for OSPF, and the second number is the metric
intra-area (O routes)
inter-area (O IA routes)
R5# show ip route ospf | begin Gateway
Gateway of last resort is not set
O IA 10.3.3.0/24 [110/67] via 10.45.1.4, 00:04:13, GigabitEthernet0/0
O IA 10.24.1.0/29 [110/65] via 10.45.1.4, 00:04:13, GigabitEthernet0/0
O IA 10.123.1.0/24 [110/66] via 10.45.1.4, 00:04:13, GigabitEthernet0/0routing table for R5 and R6. R5 and R6 contain only inter-area routes in the OSPF routing table because intra-area routes are directly connected. Directly connected routes are not installed in routing table only because of AD competition only, these O Intra area routes will still show in OSPF LSDB
Routes that are injected into an OSPF domain through redistribution are known as external OSPF routes.
The router that redistributes prefixes into an OSPF domain, the router is called an autonomous system boundary router (ASBR)
There are 2 types of external routes:
Type 1 routes are preferred over Type 2 routes.
The Type 1 metric equals the redistribution metric plus the total path metric to the ASBR. In other words, as the LSA propagates away from the originating ASBR, the metric increases.
The Type 2 metric equals only the redistribution metric. The metric is the same for the router next to the ASBR as the router 30 hops away from the originating ASBR. This is the default external metric type used by OSPF.
172.16.6.0/24 network is redistributed as a Type 1 route, and the 172.31.6.0/24 network is redistributed as a Type 2 route
External OSPF network routes are marked as O E1 and O E2
R1# show ip route ospf
! Output omitted for brevity
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
E1 - OSPF external type 1, E2 - OSPF external type 2
Gateway of last resort is not set
O 10.3.3.0/24 [110/2] via 10.123.1.3, 23:20:25, GigabitEthernet0/0
O 10.24.1.0/29 [110/65] via 10.123.1.2, 23:20:15, GigabitEthernet0/0
O IA 10.45.1.0/24 [110/66] via 10.123.1.2, 23:13:25, GigabitEthernet0/0
O IA 10.56.1.0/24 [110/67] via 10.123.1.2, 23:13:25, GigabitEthernet0/0
O E1 172.16.6.0 [110/87] via 10.123.1.2, 00:01:00, GigabitEthernet0/0
O E2 172.31.6.0 [110/20] via 10.123.1.2, 00:01:00, GigabitEthernet0/0R2# show ip route ospf | begin Gateway
Gateway of last resort is not set
O 10.3.3.0/24 [110/2] via 10.123.1.3, 23:24:05, GigabitEthernet0/0
O IA 10.45.1.0/24 [110/65] via 10.24.1.4, 23:17:11, Serial1/0
O IA 10.56.1.0/24 [110/66] via 10.24.1.4, 23:17:11, Serial1/0
O E1 172.16.6.0 [110/86] via 10.24.1.4, 00:04:45, Serial1/0
O E2 172.31.6.0 [110/20] via 10.24.1.4, 00:04:45, Serial1/0metric for the 172.31.6.0/24 network is the same on R1 as it is on R2, but the metric for the 172.16.6.0.0/24 network differs on two routers because Type 1 metrics include the path metric to the ASBR.
OSPF supports advertising the default route into the OSPF domain. The advertising router must have a default route in its routing table for the default route to be advertised. To advertise the default route, you use the command default-information originate [always] [metric metric-value] [metric-type type-value] underneath the OSPF process. The always optional keyword advertises the default route regardless of whether a default route exists in the RIB. In addition, the route metric can be changed with the metric metric-value option, and the metric type can be changed with the metric-type type-value option.
R1
ip route 0.0.0.0 0.0.0.0 100.64.1.2
!
router ospf 1
network 10.0.0.0 0.255.255.255 area 0
default-information originateOSPF advertises the default route as an external OSPF route.
R2# show ip route | begin Gateway
Gateway of last resort is 10.12.1.1 to network 0.0.0.0
O*E2 0.0.0.0/0 [110/1] via 10.12.1.1, 00:02:56, GigabitEthernet0/1
C 10.12.1.0/24 is directly connected, GigabitEthernet0/1
C 10.23.1.0/24 is directly connected, GigabitEthernet0/2Order of Route Preference
O — Intra-Area route
Most preferred
Best because it stays inside the same area
O IA — Inter-Area route
From another area
Preferred over all external types
N1 — NSSA External Type 1
External + internal cost
Same logic as E1 but inside NSSA
Most preferred external type
E1 — External Type 1
External + internal cost to ASBR
Preferred over type 2
N2 — NSSA External Type 2
External metric only
Treated like E2 but originates in NSSA
E2 — External Type 2
External metric only
Lowest preference
Designated Router and Backup Designated Router
Multi-access networks allow more than two routers to exist on a network segment. With OSPF when each router becomes neighbor of each router, it can flood more LSAs, we dont worry about the hellos since they are still sent to all ospf routers as they needed for 2 way neighborships, it is only the LSAs that can cause issues in n (n – 1) / 2 setup due to excessive traffic
Not just the network but having so many adjacencies per segment consumes more bandwidth, more CPU processing, and more memory to maintain each of the neighbor states.
One router on the network becomes a designated router DR and one router becomes BDR, all OSPF routers then become 2 way adjacent using hellos DROTHER but only fully adjacent with the DR and BDR by sending their full LSDB, this LSDB received by DR and BDR is then synced with all or rest of the OSPF routers, but all of this happens per subnet or per segment
DR/BDR election occurs with OSPF neighborship—specifically, during the last phase of the 2-Way neighbor state and just before the ExStart state
Router interface having OSPF priority of non-zero will attempts DR/BDR elections, if priority is 0 then that OSPF router “interface” (not the whole router) does not take part in DR/BDR elections
Default priority is 1, higher priority wins
If all OSPF routers on a multi-access segment (e.g., Ethernet) have the same priority, OSPF uses the highest Router ID (RID) as the tie-breaker to elect the DR and BDR.
Routers place their RID and also the priority inside hellos
The OSPF DR and BDR roles cannot be preempted but only upon the failure of router control plane
or
manual process restart from CLI
Wait timer
To ensure that all routers on a segment have fully initialized or booted into OS and running OSPF
OSPF initiates a wait timer when OSPF hello packets do not contain a DR/BDR router for a segment. The default value for the wait timer is the dead interval timer When the wait timer has expired, a router participates in the DR election.
The wait timer starts when OSPF first starts on an interface, so a router can still elect itself as the DR for a segment without other OSPF routers; it only waits until the wait timer expires
point-to-point link and has no DR/BDR
If all the OSPF routers have the same OSPF priority, and the next decision is to use the higher RID (and RID selection is also a per node’s local process, to find the highest IP on the loopback interfaces and if no loopback interfaces with IP, then highest IP address on the physical interfaces)
Increasing priority on one router increases its chances of becoming the DR or BDR since default priority on an OSPF interface is 1 and Remember that OSPF does not preempt the DR or BDR roles, so it might be necessary to restart the OSPF process on the current DR/BDR for the changes to take effect.
Setting an interface priority to 0 removes that interface from the DR/BDR election immediately.
OSPF Network Types
Not every transport or network is multiaccess
We have to determine the right network / media type and set OSPF network type based on that
Remember the rule for need of DR/BDR on the network, wherever B is then DR/BDR are needed such as “B”roadcast and non “B”roadcast
| Type | Description | DR/BDR Field in OSPF Hellos | Timers |
|---|---|---|---|
| Broadcast | Default setting on OSPF-enabled Ethernet links. | Yes | Hello: 10 Wait: 40 Dead: 40 |
| Nonbroadcast | Default setting on enabled OSPF Frame Relay main interface or Frame Relay multipoint sub-interfaces. | Yes | Hello: 30 Wait: 120 Dead: 120 |
| Point-to-point | Default setting on enabled OSPF Frame Relay point-to-point sub-interfaces. | No | Hello: 10Wait: 40Dead: 40 |
| Point-to-multipoint | Not enabled by default on any interface type. Interface is advertised as a host route (/32), and sets the next-hop address to the outbound interface. Primarily used for hub-and-spoke topologies. | No | Hello: 30 Wait: 120 Dead: 120 |
| Loopback | Default setting on OSPF-enabled loopback interfaces. Interface is advertised as a host route (/32). | N/A | N/A |
Broadcast
Broadcast networks are multi-access in that they are capable of connecting more than two devices, and broadcasts sent out one interface are capable of reaching all interfaces attached to that segment hence broadcast
ip ospf network broadcast overrides the automatically configured setting and statically sets an interface as an OSPF broadcast network type.
Nonbroadcast
Frame Relay, ATM, and X.25 are considered NBMA in that they can also connect more than two devices but some devices could be in different virtual circuits while in a same subnet
Virtual circuits may provide connectivity, but the topology may not be a full mesh and might only provide a hub-and-spoke topology.
Frame Relay interfaces set the OSPF network type to nonbroadcast by default. The hello protocol interval takes 30 seconds for this OSPF network type. Multiple routers can exist on a segment, so the DR functionality is used. Neighbors are statically defined with the neighbor ip-address command because multicast and broadcast functionality do not exist on this type of circuit. Configuring a static neighbor causes OSPF hellos to be sent using unicast.
command ip ospf network non-broadcast manually sets an interface as an OSPF nonbroadcast network type
R1
interface Serial 0/0
ip address 10.12.1.1 255.255.255.252
encapsulation frame-relay
no frame-relay inverse-arp
frame-relay map ip address 10.12.1.2 102
!
router ospf 1
router-id 192.168.1.1
neighbor 10.12.1.2
network 0.0.0.0 255.255.255.255 area 0R1# show ip ospf interface Serial 0/0 | include Type
Process ID 1, Router ID 192.168.1.1, Network Type
NON_BROADCAST, Cost: 64Point-to-Point Networks
Only two nodes can exist on this type of network medium, so OSPF does not waste CPU cycles on DR functionality. The hello timer is set to 10 seconds on OSPF point-to-point network types.
OSPF network type is set to point-to-point by default for serial interfaces (HDLC or PPP encapsulation), Generic Routing Encapsulation (GRE) tunnels, and point-to-point Frame Relay sub-interfaces
R1
interface serial 0/1
ip address 10.12.1.1 255.255.255.252
!
router ospf 1
router-id 192.168.1.1
network 0.0.0.0 255.255.255.255 area 0R2
interface serial 0/1
ip address 10.12.1.2 255.255.255.252
!
router ospf 1
router-id 192.168.2.2
network 0.0.0.0 255.255.255.255 area 0R1# show ip ospf interface s0/1 | include Type
Process ID 1, Router ID 192.168.1.1, Network Type POINT_TO_POINT, Cost: 64R2# show ip ospf interface s0/1 | include Type
Process ID 1, Router ID 192.168.2.2, Network Type POINT_TO_POINT, Cost: 64R1# show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
192.168.2.2 0 FULL/ - 00:00:36 10.12.1.2 Serial0/1Point-to-point OSPF network types do not use a DR. Notice the hyphen (-) in the State field.
Interfaces using an OSPF P2P network type form an OSPF adjacency quickly because the DR election is bypassed, and there is no wait timer. “Ethernet interfaces” that are directly connected with only two OSPF speakers in the subnet could be changed to the OSPF point-to-point network type to form adjacencies more quickly and to simplify the SPF computation
command ip ospf network point-to-point manually sets an interface as an OSPF point-to-point network type.
Point-to-Multipoint Networks
Point-to-multipoint OSPF network type supports hub-and-spoke connectivity while using the same IP subnet and is commonly found in Frame Relay and Layer 2 VPN (L2VPN) topologies.
OSPF network type point-to-multipoint is not enabled by default for any medium. It requires manual configuration. A DR is not enabled for this OSPF network type, and the hello timer is set to 30 seconds.
Interfaces set for the OSPF point-to-multipoint network type add the interface’s IP address to the OSPF LSDB as a /32 network which means that this interface address will be advertised as /32 network and will be received by neighbors as /32 and routes received on neighbors through this router and neighbors will use this /32 interface as the next hop
Why? Because OSPF wants to treat each neighbour as a separate logical link, not part of a shared network. Using /32: Removes the idea of a shared subnet.
command ip ospf network point-to-multipoint manually sets an interface as an OSPF point-to-multipoint network type
R1
interface Serial 0/0
encapsulation frame-relay
no frame-relay inverse-arp
!
interface Serial 0/0.123 multipoint
ip address 10.123.1.1 255.255.255.248
frame-relay map ip 10.123.1.2 102 broadcast
frame-relay map ip 10.123.1.3 103 broadcast
ip ospf network point-to-multipoint
!
router ospf 1
router-id 192.168.1.1
network 0.0.0.0 255.255.255.255 area 0R2
interface Serial 0/0
encapsulation frame-relay
no frame-relay inverse-arp
!
interface Serial 0/1/0/0.123 multipoint
ip address 10.123.1.2 255.255.255.248
frame-relay map ip 10.123.1.1 201 broadcast
ip ospf network point-to-multipoint
!
router ospf 1
router-id 192.168.2.2
network 0.0.0.0 255.255.255.255 area 0R3
interface Serial 0/0
encapsulation frame-relay
no frame-relay inverse-arp
!
interface Serial 0/0.123 multipoint
ip address 10.123.1.3 255.255.255.248
frame-relay map ip 10.123.1.1 301 broadcast
ip ospf network point-to-multipoint
!
router ospf 1
router-id 192.168.3.3
network 0.0.0.0 255.255.255.255 area 0R1# show ip ospf interface Serial 0/0.123 | include Type
Process ID 1, Router ID 192.168.1.1, Network Type POINT_TO_MULTIPOINT, Cost: 64R2# show ip ospf interface Serial 0/0.123 | include Type
Process ID 1, Router ID 192.168.2.2, Network Type POINT_TO_MULTIPOINT, Cost: 64R3# show ip ospf interface Serial 0/0.123 | include Type
Process ID 1, Router ID 192.168.3.3, Network Type POINT_TO_MULTIPOINT, Cost: 64Notice that all three routers are on the same subnet, but R2 and R3 do not establish an adjacency with each other.
R1# show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
192.168.3.3 0 FULL/ - 00:01:33 10.123.1.3 Serial0/0.123
192.168.2.2 0 FULL/ - 00:01:40 10.123.1.2 Serial0/0.123R2# show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
192.168.1.1 0 FULL/ - 00:01:49 10.123.1.1 Serial0/0.123R3# show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
192.168.1.1 0 FULL/ - 00:01:46 10.123.1.1 Serial0/0.123R1# show ip route ospf | begin Gateway
Gateway of last resort is not set
O 10.123.1.2/32 [110/64] via 10.123.1.2, 00:07:32, Serial0/0.123
O 10.123.1.3/32 [110/64] via 10.123.1.3, 00:03:58, Serial0/0.123
192.168.2.0/32 is subnetted, 1 subnets
O 192.168.2.2 [110/65] via 10.123.1.2, 00:07:32, Serial0/0.123
192.168.3.0/32 is subnetted, 1 subnets
O 192.168.3.3 [110/65] via 10.123.1.3, 00:03:58, Serial0/0.123R2# show ip route ospf | begin Gateway
Gateway of last resort is not set
O 10.123.1.1/32 [110/64] via 10.123.1.1, 00:07:17, Serial0/0.123
O 10.123.1.3/32 [110/128] via 10.123.1.1, 00:03:39, Serial0/0.123
192.168.1.0/32 is subnetted, 1 subnets
O 192.168.1.1 [110/65] via 10.123.1.1, 00:07:17, Serial0/0.123
192.168.3.0/32 is subnetted, 1 subnets
O 192.168.3.3 [110/129] via 10.123.1.1, 00:03:39, Serial0/0.123R3# show ip route ospf | begin Gateway
Gateway of last resort is not set
O 10.123.1.1/32 [110/64] via 10.123.1.1, 00:04:27, Serial0/0.123
O 10.123.1.2/32 [110/128] via 10.123.1.1, 00:04:27, Serial0/0.123
192.168.1.0/32 is subnetted, 1 subnets
O 192.168.1.1 [110/65] via 10.123.1.1, 00:04:27, Serial0/0.123
192.168.2.0/32 is subnetted, 1 subnets
O 192.168.2.2 [110/129] via 10.123.1.1, 00:04:27, Serial0/0.123Loopback Networks
OSPF network type loopback is enabled by default for loopback interfaces and can be used only on loopback interfaces, always advertised with a /32 prefix length, even if the IP address configured on the loopback interface does not have a /32 prefix length.
R1interface Loopback0
ip address 192.168.1.1 255.255.255.0
interface Serial 0/1
ip address 10.12.1.1 255.255.255.252
!
router ospf 1
router-id 192.168.1.1
network 0.0.0.0 255.255.255.255 area 0RR2’s loopback interface is set to the OSPF point-to-point network type to ensure that R2’s loopback interface advertises the network prefix 192.168.2.0/24
R2
interface Loopback0
ip address 192.168.2.2 255.255.255.0
ip ospf network point-to-point
interface Serial 0/0
ip address 10.12.1.2 255.255.255.252
!
router ospf 1
router-id 192.168.2.2
network 0.0.0.0 255.255.255.255 area 0R1# show ip ospf interface Loopback 0 | include Type
Process ID 1, Router ID 192.168.1.1, Network Type LOOPBACK, Cost: 1R2# show ip ospf interface Loopback 0 | include Type
Process ID 1, Router ID 192.168.2.2, Network Type POINT_TO_POINT, Cost: 1R1# show ip ospf database router | I Advertising|Network|Mask
Advertising Router: 192.168.1.1
Link connected to: a Stub Network
(Link ID) Network/subnet number: 192.168.1.1
(Link Data) Network Mask: 255.255.255.255
Link connected to: a Stub Network
(Link ID) Network/subnet number: 10.12.1.0
(Link Data) Network Mask: 255.255.255.0
Advertising Router: 192.168.2.2
Link connected to: a Stub Network
(Link ID) Network/subnet number: 192.168.2.0
(Link Data) Network Mask: 255.255.255.0
Link connected to: a Stub Network
(Link ID) Network/subnet number: 10.12.1.0
(Link Data) Network Mask: 255.255.255.0Design difference between P2MP and NBMA and Why use where
NBMA
Frame Relay, DMVPN, MPLS
Like Ethernet segment without broadcast
DR/BDR election due to Ethernet like segment and because of “B”
Hub can become DR
NBMA can’t do broadcast or multicast (no 224.0.0.5/6).
Hellos and LSAs must be sent using unicast to neighbours.
Neighbors must be configured manually neighbor x.x.x.x
Both P2MP and NBMA offer single subnet WAN
Configured using command ip ospf network non-broadcast
In NBMA spoke to spoke become neighbors but by default, in a typical hub-and-spoke NBMA design (like Frame Relay), spokes do not become neighbors with each other, because they cannot directly communicate unless the underlying NBMA network provides full-mesh VC connectivity.
P2MP
Frame Relay, DMVPN, MPLS
Hub-and-spoke and the spokes do not fully mesh
Can work with (broadcast command) or without broadcast (default P2MP)
P2MP (with broadcast capable media) can discover neighbours dynamically via multicast
This allows simpler configuration vs NBMA with manual config for many spokes
No DR but bunch of P2P while HUB is P2MP
For example, hub router with 20 spokes across DMVPN or MPLS, spokes never talk directly.
Neighbors are configured manually
/32 Host routes P2P links
Both P2MP and NBMA offer single subnet WAN
P2MP is used over NBMA when there is no spoke to spoke communication allowed
Failure Detection
OSPF Dead interval timer, which defaults to four times the hello timer. Upon receipt of the hello packet from a neighboring router, the OSPF dead timer resets to the initial value, and then it starts to decrement again.
If a router does not receive a hello before the OSPF dead interval timer reaches 0, the neighbor state is changed to down. The OSPF router immediately sends out the appropriate LSA, reflecting the topology change, and the SPF algorithm processes on all routers within the area.
Changing the hello timer interval modifies the default dead interval, too. The OSPF hello timer is modified with the interface configuration submode command ip ospf hello-interval 1-65,535
You can change the dead interval timer to a value between 1 and 65,535 seconds. You change the OSPF dead interval timer by using the command ip ospf dead-interval 1-65,535 under the interface configuration submode.
show ip ospf interface shows timers
R1# show ip ospf interface | i Timer|line
Loopback0 is up, line protocol is up
GigabitEthernet0/2 is up, line protocol is up
Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5
GigabitEthernet0/1 is up, line protocol is up
Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5Authentication
An attacker can forge OSPF packets or gain physical access to a network, manipulate the routing and take control of traffic
OSPF authentication is enabled on an interface-by-interface basis or for all interfaces in an area
You can set the password only as an interface parameter, and you must set it for every interface.
If you miss an interface, the default password is set to a null value.
OSPF supports two types of authentication:
Plaintext: This type of authentication provides little security, as anyone with access to the link can see the password by using a network sniffer.
You enable plaintext authentication for an OSPF area with the command area area-id authentication, then use the interface parameter command ip ospf authentication to set plaintext authentication only on that interface. You configure the plaintext password by using the interface parameter command ip ospf authentication-key password.
MD5 cryptographic hash: This type of authentication uses a hash, so the password is never sent out the wire. This technique is widely accepted as being the more secure mode. You enable MD5 authentication for an OSPF area by using the command area area-id authentication message-digest, and then the interface parameter command ip ospf authentication message-digest to set MD5 authentication for that interface. You configure the MD5 password with the interface parameter command ip ospf message-digest-key key-number md5 password.
MD5 authentication is a hash of the key number and password combined. If the keys do not match, the hash differs between the nodes. That is why keys much match between the nodes and this is the use of the keys
Area 12 uses plaintext authentication, and Area 0 uses MD5 authentication
R1 and R3 use interface-based authentication
R2 uses area-specific authentication
R1
interface GigabitEthernet0/0
ip address 10.12.1.1 255.255.255.0
ip ospf authentication
ip ospf authentication-key CISCO
!
router ospf 1
network 10.12.1.0 0.0.0.255 area 12R2
interface GigabitEthernet0/0
ip address 10.12.1.2 255.255.255.0
ip ospf authentication-key CISCO
!
interface GigabitEthernet0/1
ip address 10.23.1.2 255.255.255.0
ip ospf message-digest-key 1 md5 CISCO
!
router ospf 1
area 0 authentication message-digest
area 12 authentication
network 10.12.1.0 0.0.0.255 area 12
network 10.23.1.0 0.0.0.255 area 0R3
interface GigabitEthernet0/1
ip address 10.23.1.3 255.255.255.0
ip ospf authentication message-digest
ip ospf message-digest-key 1 md5 CISCO
!
router ospf 1
network 10.23.1.0 0.0.0.255 area 0You verify the authentication settings by examining the OSPF interface without the brief option
R1# show ip ospf interface | include line|authentication|key
GigabitEthernet0/0 is up, line protocol is up
Simple password authentication enabledR2# show ip ospf interface | include line|authentication|key
GigabitEthernet0/1 is up, line protocol is up
Cryptographic authentication enabled
Youngest key id is 1
GigabitEthernet0/0 is up, line protocol is up
Simple password authentication enabledR3# show ip ospf interface | include line|authentication|key
GigabitEthernet0/1 is up, line protocol is up
Cryptographic authentication enabled
Youngest key id is 1OSPF uses six LSA types for IPv4 routing:
Type 1, router: LSAs that advertise prefixes within an area
Type 2, network: LSAs that indicate the routers attached to broadcast segment within an area
Type 3, summary: LSAs that advertise prefixes that originate from a different area
Type 4, ASBR summary: LSA used to locate the ASBR from a different area
Type 5, AS external: LSA that advertises prefixes that were redistributed in to OSPF
Type 7, NSSA external: LSA for external prefixes that were redistributed in a local NSSA area
LSA Types 1, 2, and 3 are used for building the SPF tree for intra-area and inter-area route routes.
LSA Types 4, 5, and 7 are related to external OSPF routes (that is, routes that were redistributed into the OSPF routing domain).
LSA Sequences
In OSPF, the LSA sequence number is used for versioning, and the originating router increments it each time it reoriginates (updates) the LSA
If a receiving router receives an LSA sequence that is greater than the one in the LSDB, it processes the LSA, If the LSA sequence number is lower than the one in the LSDB, the router deems the LSA old and discards it.
LSA Age and Flooding
Every local router keeps the LSA and also maintains the timer against that LSA called “age”, when LSA is first created in database, that “age” field is 0 but it start incrementing in the DB each second locally, once that age reaches 1800 seconds which is 30 mins, the originating router automatically generates a new copy of that LSA.
This is built into OSPF to keep the LSDB fresh and ensure routers don’t accidentally keep stale information forever.
Another LSA increment (over the links – inflight)
When a router forwards (floods) an LSA to a neighbour, the age increases by a small calculated delay
This accounts for:
- Link transmission delay
- Router processing time
In practice, this increment is small, but the LSA age always increases as it moves across the network.
If any LSA reaches 3600 seconds, it is considered expired or MaxAge.
If a router receives an LSA that has reached MaxAge (3600 seconds), it will reflood that LSA with LS age = 3600 to all its neighbors.
This behaviour ensures that every router, both downstream and upstream, deletes the LSA from its LSDB.
This flooding happens even if the router is not the original creator of the LSA.
Why flood the MaxAge LSA?
Because OSPF relies on synchronized LSDBs.
If one router deletes an LSA silently but others don’t, the network becomes inconsistent.
Router A (originator) publishes LSA
↓
Routers B, C, D store it
↓
LSA in Router D reaches 3600 seconds
↓
Router D floods LSA age = 3600 to neighbors (C)
↓
Router C deletes LSA, floods MaxAge to Router B
↓
Router B deletes LSA, floods MaxAge to Router A
↓
Router A deletes its own stale LSA
LSA Types
ABRs maintain a separate set of LSAs for each OSPF area
LSA Type 1: Router Link
A Type 1 LSA entry exists for each OSPF-enabled link (that is, an interface and its attached networks).
Type 1 LSAs are not advertised outside Area thus making the underlying topology in an area invisible to other areas.

R1# show ip ospf database
OSPF Router with ID (192.168.1.1) (Process ID 1)
Router Link States (Area 1234)
Link ID ADV Router Age Seq# Checksum Link count
192.168.1.1 192.168.1.1 14 0x80000006 0x009EA7 1
192.168.2.2 192.168.2.2 2020 0x80000006 0x00AD43 3
192.168.3.3 192.168.3.3 6 0x80000006 0x0056C4 2
192.168.4.4 192.168.4.4 61 0x80000005 0x007F8C 2Link ID
Identifies the object that the link connects to. It can refer to the neighboring router’s RID, the IP address of the DR’s interface, or the IP network address.
ADV Router
The OSPF router ID of the router that originated the LSA
AGE
The age of the LSA on the router on which the command is being run. Values over 1800 are expected to refresh soon.
Seq #
Sequence number for the LSA
Checksum
The checksum of the LSA to verify integrity during flooding.
Link Count
3 links → Router has three OSPF interfaces/networks it advertises.
If we explore this LSA further we will see networks mentioned inside it
This makes it functions just like a router LSA, router telling us how many links it has in a certain area
You can examine the Type 1 OSPF LSAs by using the command show ip ospf database router
R1# show ip ospf database router
! Output omitted for brevity
OSPF Router with ID (192.168.1.1) (Process ID 1)
Router Link States (Area 1234)
LS age: 352 <<< start of LSA
Options: (No TOS-capability, DC)
LS Type: Router Links <<< Type 1 LSA
Link State ID: 192.168.1.1 <<< how it shows in sh ip ospf database
Advertising Router: 192.168.1.1
LS Seq Number: 80000014
Length: 36
Number of Links: 1
Link connected to: a Transit Network
(Link ID) Designated Router address: 10.123.1.3
(Link Data) Router Interface address: 10.123.1.1
|
No hint of the network yet
TOS 0 Metrics: 1
LS age: 381
Options: (No TOS-capability, DC)
LS Type: Router Links
Link State ID: 192.168.2.2
Advertising Router: 192.168.2.2
LS Seq Number: 80000015
Length: 60
Number of Links: 3
Link connected to: another Router (point-to-point)
(Link ID) Neighboring Router ID: 192.168.4.4
(Link Data) Router Interface address: 10.24.1.1
TOS 0 Metrics: 64
Link connected to: a Stub Network
(Link ID) Network/subnet number: 10.24.1.0
(Link Data) Network Mask: 255.255.255.248
TOS 0 Metrics: 64
Link connected to: a Transit Network
(Link ID) Designated Router address: 10.123.1.3
(Link Data) Router Interface address: 10.123.1.2
TOS 0 Metrics: 1
LS age: 226
Options: (No TOS-capability, DC)
LS Type: Router Links
Link State ID: 192.168.3.3
Advertising Router: 192.168.3.3
LS Seq Number: 80000014
Length: 48
Number of Links: 2
Link connected to: a Stub Network
(Link ID) Network/subnet number: 10.3.3.0
(Link Data) Network Mask: 255.255.255.0
TOS 0 Metrics: 1
Link connected to: a Transit Network
(Link ID) Designated Router address: 10.123.1.3
(Link Data) Router Interface address: 10.123.1.3
TOS 0 Metrics: 1
LS age: 605
Options: (No TOS-capability, DC)
LS Type: Router Links
Link State ID: 192.168.4.4
Advertising Router: 192.168.4.4
LS Seq Number: 80000013
Length: 48
Area Border Router <<< telling us that even though this
Number of Links: 2 is in our area but
this is an ABR with
one leg in our area
Link connected to: another Router (point-to-point)
(Link ID) Neighboring Router ID: 192.168.2.2
(Link Data) Router Interface address: 10.24.1.4
TOS 0 Metrics: 64
Link connected to: a Stub Network
(Link ID) Network/subnet number: 10.24.1.0
(Link Data) Network Mask: 255.255.255.248
TOS 0 Metrics: 64If a router is functioning as an ABR, an ASBR, or a virtual-link endpoint, the function is listed between the Length field and the Number of links field.

“show ip ospf database” Link ID can mean different things based the LSA type
Point-to-point link (IP address assigned)
Link type 1
Neighbor RID
Link to transit network
Link type 2
Interface address of the DR
Link to stub network
Link type 3
Network address
Virtual link
Link type 4
Neighbor RID
Transit link in router LSA shows DR and IP address facing DR
Point to point link in router LSA advertise two links
One link is the point-to-point link type that identifies the OSPF neighbor RID for that segment, and the other link is a stub network link that provides the subnet mask for that network
Stub Network in router LSA has no neighbors, Point-to-point and transit link types that did not become adjacent with another OSPF router are classified as a stub network link type
Secondary connected networks are always advertised as stub link types because OSPF adjacencies can never form on them
Just by using information from Router LSA type 1, we can build a topology
Notice that the three router links on R1, R2, and R3 (10.123.1.0) have not been directly connected yet.
Also see how topology uses Link ID and then its corresponding Link Data
R3 is elected as the DR (that is why Link ID is 10.123.1.3), and R2 is elected as the BDR
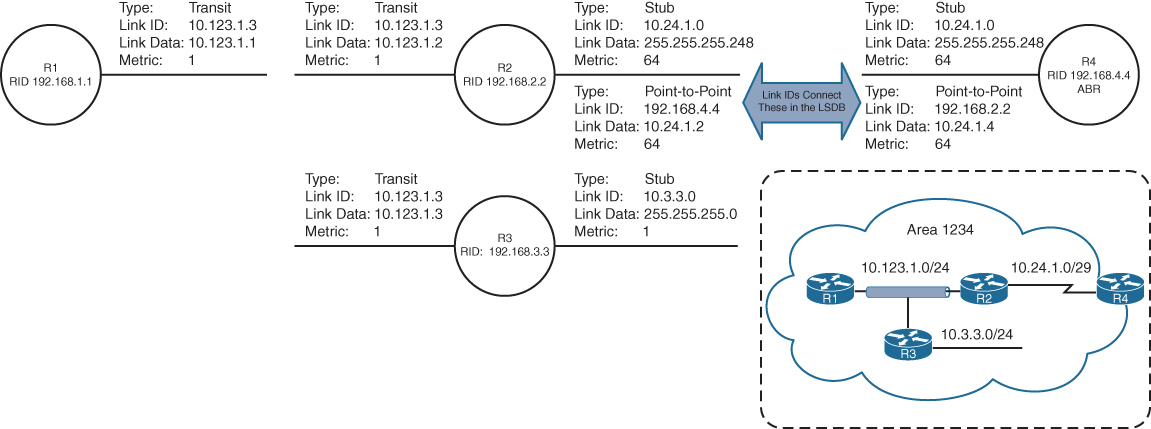
LSA Type 2: Network Link
A Type 2 LSA (network LSA) represents a multi-access network
DR always advertises the Type 2 LSA
identifies all the routers attached to that network segment.
If a DR has not been elected, a Type 2 LSA is not present in the LSDB
Type 2 LSAs are not flooded outside the originating OSPF area in an identical fashion to Type 1 LSAs.
R1# show ip ospf database
! Output omitted for brevity
OSPF Router with ID (192.168.1.1) (Process ID 1)
..
Net Link States (Area 1234)
Link ID ADV Router Age Seq# Checksum
10.123.1.3 10.192.168.3.3 1752 0x80000012 0x00ADC5Type 2 LSA that is advertised by “R3” but show command is on R1
The network mask for the subnet is included in the Type 2 LSA
R1# show ip ospf database network
OSPF Router with ID (192.168.1.1) (Process ID 1)
Net Link States (Area 1234)
LS age: 356
Options: (No TOS-capability, DC)
LS Type: Network Links
Link State ID: 10.123.1.3 (address of Designated Router)
Advertising Router: 192.168.3.3
LS Seq Number: 80000014
Checksum: 0x4DD
Length: 36
Network Mask: /24
Attached Router: 192.168.3.3
Attached Router: 192.168.1.1
Attached Router: 192.168.2.2Visualization of the Type 1 and Type 2 LSAs
When the DR changes for a network segment, a new Type 2 LSA is created, causing SPF to run again within the OSPF area.
Pseudonode because that box is considered a node in OSPF LSDB but it is not real node or router
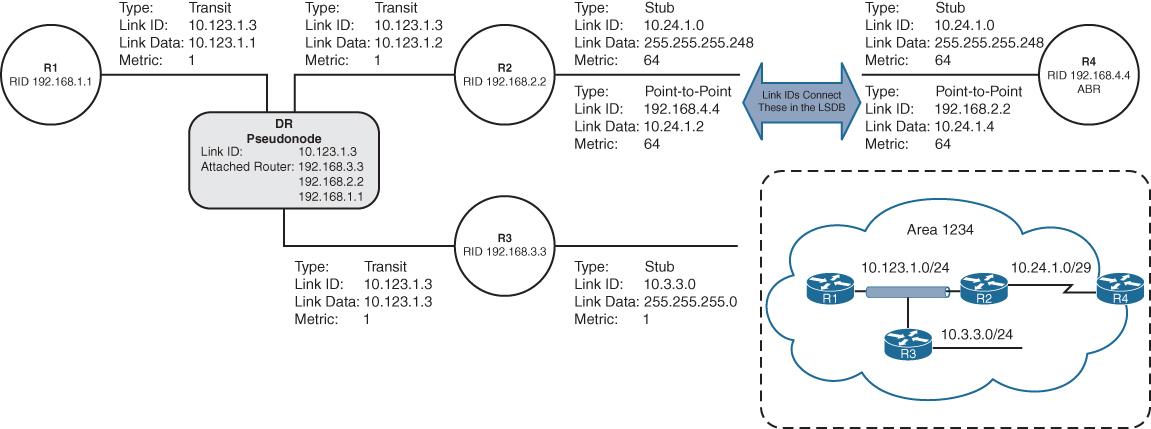
LSA Type 3: Summary Link
Type 3 LSAs (summary LSAs) represent networks from other areas. The role of the ABRs is to participate in multiple OSPF areas and ensure that these Type 1 networks are reachable from other areas
As explained earlier, ABRs do not forward Type 1 or Type 2 LSAs into other areas. When an ABR receives a Type 1 LSA, it creates an equivalent Type 3 LSA
The ABR then advertises the Type 3 LSA into other areas
If an ABR receives a Type 3 LSA from Area 0 (backbone area), it regenerates a new Type 3 LSA for the nonbackbone area and lists itself as the advertising router with the additional cost metric

Type 1 LSAs exist only in the area of origination and convert to Type 3 when they cross the ABRs (R4 and R5).
The Type 3 LSAs show up under the appropriate area where they exist in the OSPF domain. For example, the 10.56.1.0 Type 3 LSA exists only in Area 0 and Area 1234 on R4.
R4# show ip ospf database
! Output omitted for brevity
OSPF Router with ID (192.168.4.4) (Process ID 1)
..
Summary Net Link States (Area 0)
|
v
This just means that these are Type 1 LSAs of
foreign or remote areas in this area
Link ID ADV Router Age Seq# Checksum
10.3.3.0 192.168.4.4 813 0x80000013 0x00F373
10.24.1.0 192.168.4.4 813 0x80000013 0x00CE8E
10.56.1.0 192.168.5.5 591 0x80000013 0x00F181
10.123.1.0 192.168.4.4 813 0x80000013 0x005A97
..
Summary Net Link States (Area 1234)
|
v
This just means that these are Type 1 LSAs of
foreign or remote areas in this area
Link ID ADV Router Age Seq# Checksum
10.45.1.0 192.168.4.4 813 0x80000013 0x0083FC
10.56.1.0 192.168.4.4 813 0x80000013 0x00096BR5# show ip ospf database
! Output omitted for brevity
OSPF Router with ID (192.168.5.5) (Process ID 1)
..
Summary Net Link States (Area 0)
|
v
This just means that these are Type 1 LSAs of
foreign or remote areas in this area
Link ID ADV Router Age Seq# Checksum
10.3.3.0 192.168.4.4 893 0x80000013 0x00F373
10.24.1.0 192.168.4.4 893 0x80000013 0x00CE8E
10.56.1.0 192.168.5.5 668 0x80000013 0x00F181
10.123.1.0 192.168.4.4 893 0x80000013 0x005A97
..
Summary Net Link States (Area 56)
|
v
This just means that these are Type 1 LSAs of
foreign or remote areas in this area
Link ID ADV Router Age Seq# Checksum
10.3.3.0 192.168.5.5 668 0x80000013 0x00F073
10.24.1.0 192.168.5.5 668 0x80000013 0x00CB8E
10.45.1.0 192.168.5.5 668 0x80000013 0x007608
10.123.1.0 192.168.5.5 668 0x80000013 0x005797The advertising router for Type 3 LSAs is the last ABR that advertises the prefix. The metric in the Type 3 LSA uses the following logic:
- If the Type 3 LSA is created from a Type 1 LSA, it is the total path metric to reach the originating router in the Type 1 LSA.
- If the Type 3 LSA is created from a Type 3 LSA (from Area 0), it is the total path metric to the ABR plus the metric in the original Type 3 LSA
R4# show ip ospf database summary 10.56.1.0
OSPF Router with ID (192.168.4.4) (Process ID 1)
Summary Net Link States (Area 0)
LS age: 754
Options: (No TOS-capability, DC, Upward)
LS Type: Summary Links(Network)
Link State ID: 10.56.1.0 (summary Network Number)
Advertising Router: 192.168.5.5
LS Seq Number: 80000013
Checksum: 0xF181
Length: 28
Network Mask: /24
MTID: 0 Metric: 1 <<< this is in Area 0
Summary Net Link States (Area 1234)
LS age: 977
Options: (No TOS-capability, DC, Upward)
LS Type: Summary Links(Network)
Link State ID: 10.56.1.0 (summary Network Number)
Advertising Router: 192.168.4.4
LS Seq Number: 80000013
Checksum: 0x96B
Length: 28
Network Mask: /24
MTID: 0 Metric: 2 <<< when sent to non Area 0
incrementedshows the Type 3 LSA for the Area 56 prefix (10.56.1.0/24) from R4’s LSDB. R4 is an ABR, and the information is displayed for both Area 0 and Area 1234. Notice that the metric increases in Area 1234’s LSA compared to in Area 0’s LSA.
R4’s perspective of the Type 3 LSA created by ABR (R5) vs Reality visualized below
R4 does not know if the 10.56.1.0/24 network is directly attached to the ABR (R5) or if it is multiple hops away (due to area obfuscation). R4 knows that its metric to the ABR (R5) is 1 and that the Type 3 LSA already has a metric of 1, so its total path metric to reach the 10.56.1.0/24 network is 2.
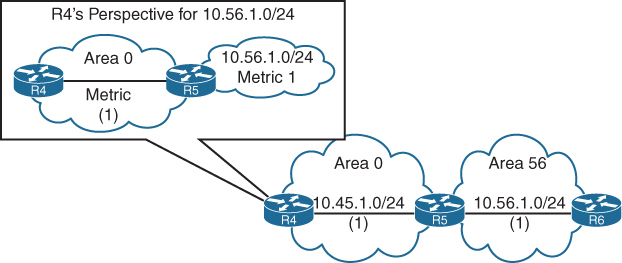
R3’s perspective of the Type 3 LSA created by the ABR (R4) for the 10.56.1.0/24 network vs reality visualised
R3 does not know if the 10.56.1.0/24 network is directly attached to the ABR (R4) or if it is multiple hops away (due to area obfuscation). R3 knows that its metric to the ABR (R4) is 65 and that the Type 3 LSA already has a metric of 2 (the metric R4 brings for network 10.56.1.0/24), so its total path metric is 67 to reach the 10.56.1.0/24 network
LSA Type 5: External Routes
When a route is redistributed into OSPF, the router is known as an autonomous system boundary router (ASBR). The external route is flooded throughout the entire OSPF domain (every area) as a Type 5 LSA (external LSAs).
Notice that the Type 5 LSA exists in all OSPF areas of the routing domain. Type 5 LSA is not regenerated unlike Type 4 instead only LSA Age is incremented
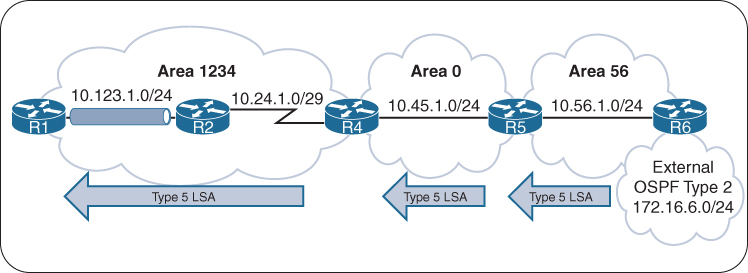
The link ID is the external network number, and the advertising router is the RID for the router originating the Type 5 LSA
R6# show ip ospf database
! Output omitted for brevity
Type-5 AS External Link States
Link ID ADV Router Age Seq# Checksum Tag
172.16.6.0 192.168.6.6 11 0x80000001 0x000866 0R6# show ip ospf database external
OSPF Router with ID (192.168.6.6) (Process ID 1)
Type-5 AS External Link States
LS age: 720
Options: (No TOS-capability, DC, Upward)
LS Type: AS External Link
Link State ID: 172.16.6.0 (External Network Number )
Advertising Router: 192.168.6.6
LS Seq Number: 8000000F
Checksum: 0xA9B0
Length: 36
Network Mask: /24
Metric Type: 2 (Larger than any link state path)
MTID: 0
Metric: 20
Forward Address: 0.0.0.0
External Route Tag: 0R1# show ip ospf database external
OSPF Router with ID (192.168.1.1) (Process ID 1)
Type-5 AS External Link States
LS age: 778
Options: (No TOS-capability, DC, Upward)
LS Type: AS External Link
Link State ID: 172.16.6.0 (External Network Number )
Advertising Router: 192.168.6.6
LS Seq Number: 8000000F
Checksum: 0xA9B0
Length: 36
Network Mask: /24
Metric Type: 2 (Larger than any link state path)
MTID: 0
Metric: 20
Forward Address: 0.0.0.0
External Route Tag: 0LSA Type 4: ASBR Summary
A Type 4 LSA (ASBR summary LSA) locates the ASBR for a Type 5 LSA
Routers examine the Type 5 LSA, check to see whether the RID is in the local area (because if in local area then cost advertised can be believed for E1), but if the ASBR is not local, a mechanism is required to locate the ASBR or measure distance to ASBR (for cases where we have 2 competing routes, which both have ASBR in remote area for which we dont have a view of)
Type 4 LSAs provide a way for routers to locate the ASBR when the ASBR is in a different area
A Type 4 LSA is created by the first ABR, and it provides a summary route strictly for the ASBR of a Type 5 LSA
The metric for a Type 4 LSA uses the following logic:
- When the Type 5 LSA crosses the first ABR (Area 0 ***ABR*** Area 56) creates a Type 4 LSA with a metric set to the total path metric to the ASBR.
- When an ABR receives a Type 4 LSA from Area 0, the ABR creates a new Type 4 LSA with a metric set to the total path metric of the first ABR (Area 1234 ***ABR*** Area 0) plus the metric to ASBR in the original Type 4 LSA, (Cost to ASBR or type 4 LSA is not added through every router’s outgoing interface)
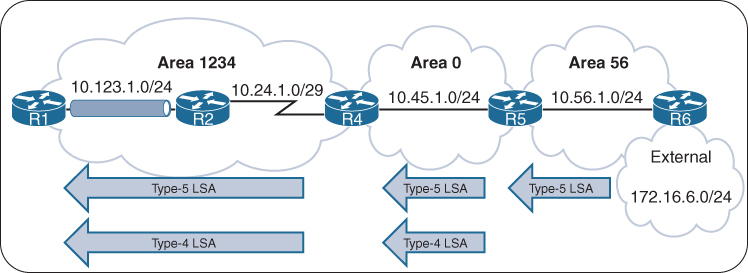
R4# show ip ospf database
! Output omitted for brevity
OSPF Router with ID (192.168.4.4) (Process ID 1)
..
Summary ASB Link States (Area 0)
Link ID ADV Router Age Seq# Checksum
192.168.6.6 192.168.5.5 930 0x8000000F 0x00EB58
..
Summary ASB Link States (Area 1234)
Link ID ADV Router Age Seq# Checksum
192.168.6.6 192.168.4.4 1153 0x8000000F 0x000342R4# show ip ospf database asbr-summary
! Output omitted for brevity
OSPF Router with ID (192.168.4.4) (Process ID 1)
Summary ASB Link States (Area 0)
LS age: 1039
Options: (No TOS-capability, DC, Upward)
LS Type: Summary Links(AS Boundary Router)
Link State ID: 192.168.6.6 (AS Boundary Router address)
Advertising Router: 192.168.5.5
Length: 28
Network Mask: /0
MTID: 0 Metric: 1
Summary ASB Link States (Area 1234)
LS age: 1262
Options: (No TOS-capability, DC, Upward)
LS Type: Summary Links(AS Boundary Router)
Link State ID: 192.168.6.6 (AS Boundary Router address)
Advertising Router: 192.168.4.4
Length: 28
Network Mask: /0
MTID: 0 Metric: 2An ABR advertises only one Type 4 LSA for every ASBR, even if the ASBR advertises thousands of Type 5 LSAs
LSA Type 7: NSSA External Summary
A Type 7 LSA (NSSA external LSA) exists only in NSSAs where route redistribution is occurring.
An ASBR sitting on the edge of an NSSA Area injects external routes as Type 7 LSAs in an NSSA
The ABR does not advertise Type 7 LSAs outside the originating NSSA but it converts the Type 7 LSA into a Type 5 LSA
If the Type 5 LSA crosses Area 0, the second ABR creates a Type 4 LSA for the Type 5 LSA

R5 injects the Type 5 LSA (only) in Area 0, which propagates to Area 1234, and R4 creates the Type 4 LSA for Area 1234 and also forwards Type 5 (only LSA age is incremented).
R5# show ip ospf database
! Output omitted for brevity
OSPF Router with ID (192.168.5.5) (Process ID 1)
..
Type-7 AS External Link States (Area 56) <<< Type 7
Link ID ADV Router Age Seq# Checksum Tag
172.16.6.0 192.168.6.6 46 0x80000001 0x00A371 0
! Notice that no Type-4 LSA has been generated. Only the Type-7 LSA for Area 56
! and the Type-5 LSA for the other areas. R5 advertises the Type-5 LSA
Type-5 AS External Link States <<< converted to Type 5
Link ID ADV Router Age Seq# Checksum Tag
172.16.6.0 192.168.5.5 38 0x80000001 0x0045DBR4# show ip ospf database
! Output omitted for brevity
OSPF Router with ID (192.168.4.4) (Process ID 1)
..
Summary ASB Link States (Area 1234) <<< Type 4
Link ID ADV Router Age Seq# Checksum
192.168.5.5 192.168.4.4 193 0x80000001 0x002A2C
Type-5 AS External Link States <<< for this Type 5
Link ID ADV Router Age Seq# Checksum Tag
172.16.6.0 192.168.5.5 176 0x80000001 0x0045DB 0R5# show ip ospf database nssa-external
OSPF Router with ID (192.168.5.5) (Process ID 1)
Type-7 AS External Link States (Area 56)
LS age: 122
Options: (No TOS-capability, Type 7/5 translation, DC, Upward)
LS Type: AS External Link
Link State ID: 172.16.6.0 (External Network Number )
Advertising Router: 192.168.6.6
LS Seq Number: 80000001
Checksum: 0xA371
Length: 36
Network Mask: /24
Metric Type: 2 (Larger than any link state path)
MTID: 0
Metric: 20
Forward Address: 10.56.1.6
External Route Tag: 0LSA Type Visualization
Notice that the Type 2 LSAs are present only on the broadcast network segments
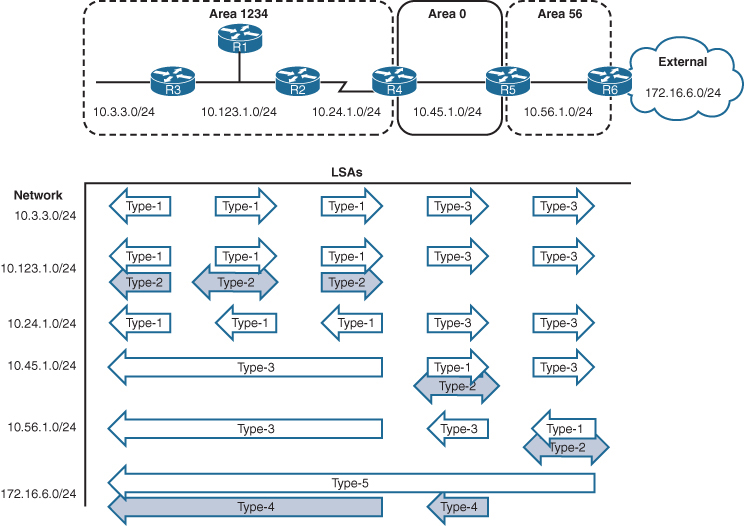
OSPF Stubby Areas
Stubby areas filter out external routes and even inter-area with some stub types – logic is to not have a massive Type 5 database on small routers, stub allows us to replace these massive type 5 in every area LSDB to be replaced with one external default route
OSPF stubby areas are identified by the area flag in the OSPF hello packet
Every router within an OSPF stubby area needs to be configured as a stub so that the routers can establish/maintain OSPF adjacencies
The following sections explain the four types of OSPF stubby areas in more detail:
- Stub areas
- Totally stubby areas
- Not-so-stubby areas (NSSAs)
- Totally NSSAs
Stub Areas
OSPF stub areas prohibit “Type 5” LSAs (external routes) and “Type 4” LSAs (ASBR summary LSAs) from entering the area at the ABR
When a Type 5 LSA reaches the ABR of a stub area, the ABR generates a default route for the stub via a Type 3 LSA
A Cisco ABR generates a default route when the area is configured as a stub and has an OSPF-enabled interface configured for Area 0

R3 and R4 before Area 34 is configured as a stub area, Notice the external 172.16.1.0/24
R3# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/2] via 10.23.1.2, 00:01:36, GigabitEthernet0/1
O E1 172.16.1.0 [110/22] via 10.23.1.2, 00:01:36, GigabitEthernet0/1
O IA 192.168.1.1 [110/3] via 10.23.1.2, 00:01:36, GigabitEthernet0/1
O 192.168.2.2 [110/2] via 10.23.1.2, 00:01:46, GigabitEthernet0/1
O 192.168.4.4 [110/2] via 10.34.1.4, 00:01:46, GigabitEthernet0/0R4# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/3] via 10.34.1.3, 00:00:51, GigabitEthernet0/0
O IA 10.23.1.0/24 [110/2] via 10.34.1.3, 00:00:58, GigabitEthernet0/0
O E1 172.16.1.0 [110/23] via 10.34.1.3, 00:00:46, GigabitEthernet0/0
O IA 192.168.1.1 [110/4] via 10.34.1.3, 00:00:51, GigabitEthernet0/0
O IA 192.168.2.2 [110/3] via 10.34.1.3, 00:00:58, GigabitEthernet0/0
O IA 192.168.3.3 [110/2] via 10.34.1.3, 00:00:58, GigabitEthernet0/0All routers in the stub area must be configured as stubs, or an adjacency cannot form because the area type flags in the hello packets do not match
R3# configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
R3(config)# router ospf 1
R3(config-router)# area 34 stubR4# configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
R4(config)# router ospf 1
R4(config-router)# area 34 stub
The routing table from R3’s perspective is not modified as it receives the Type 4 and Type 5 LSAs from Area 0, But when the Type 5 LSA (172.16.1.0/24) reaches the R3 ABR, the R3 ABR generates a default route by using a Type 3 LSA. While R4 only receives Intra Area routes, Inter-Area route and Type 3 (not Type 5) the default route
R3# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/2] via 10.23.1.2, 00:03:10, GigabitEthernet0/1
O E1 172.16.1.0 [110/22] via 10.23.1.2, 00:03:10, GigabitEthernet0/1
O IA 192.168.1.1 [110/3] via 10.23.1.2, 00:03:10, GigabitEthernet0/1
O 192.168.2.2 [110/2] via 10.23.1.2, 00:03:10, GigabitEthernet0/1
O 192.168.4.4 [110/2] via 10.34.1.4, 00:01:57, GigabitEthernet0/0R4# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is 10.34.1.3 to network 0.0.0.0
O*IA 0.0.0.0/0 [110/2] via 10.34.1.3, 00:02:45, GigabitEthernet0/0
O IA 10.12.1.0/24 [110/3] via 10.34.1.3, 00:02:45, GigabitEthernet0/0
O IA 10.23.1.0/24 [110/2] via 10.34.1.3, 00:02:45, GigabitEthernet0/0
O IA 192.168.1.1 [110/4] via 10.34.1.3, 00:02:45, GigabitEthernet0/0
O IA 192.168.2.2 [110/3] via 10.34.1.3, 00:02:45, GigabitEthernet0/0
O IA 192.168.3.3 [110/2] via 10.34.1.3, 00:02:45, GigabitEthernet0/0Totally Stubby Areas
An OSPF totally stubby area prohibits Type 3 LSAs (inter-area), Type 4 LSAs (ASBR summary LSAs), and Type 5 LSAs (external routes) from entering the area at the ABR
When an ABR of a totally stubby area receives a Type 3 or Type 5 LSA, the ABR generates a default route for the totally stubby area.
In fact, an ABR for a totally stubby area advertises the default route into the totally stubby area
Assigning the interface acts as the trigger for the Type 3 LSA that leads to the generation of the default route
Only intra-area and default routes should exist within a totally stubby area.
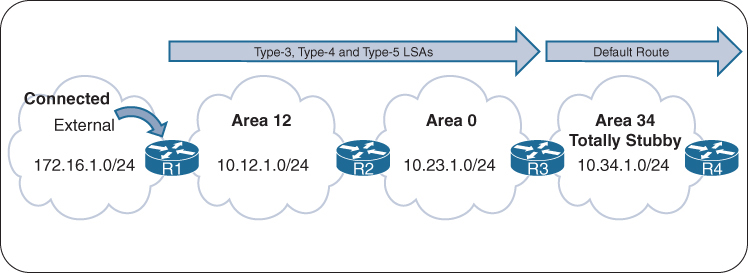
Routing Tables of R3 and R4 Before the Totally Stubby Area
R3# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/2] via 10.23.1.2, 00:01:36, GigabitEthernet0/1
O E1 172.16.1.0 [110/22] via 10.23.1.2, 00:01:36, GigabitEthernet0/1
O IA 192.168.1.1 [110/3] via 10.23.1.2, 00:01:36, GigabitEthernet0/1
O 192.168.2.2 [110/2] via 10.23.1.2, 00:01:46, GigabitEthernet0/1
O 192.168.4.4 [110/2] via 10.34.1.4, 00:01:46, GigabitEthernet0/0R4# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/3] via 10.34.1.3, 00:00:51, GigabitEthernet0/0
O IA 10.23.1.0/24 [110/2] via 10.34.1.3, 00:00:58, GigabitEthernet0/0
O E1 172.16.1.0 [110/23] via 10.34.1.3, 00:00:46, GigabitEthernet0/0
O IA 192.168.1.1 [110/4] via 10.34.1.3, 00:00:51, GigabitEthernet0/0
O IA 192.168.2.2 [110/3] via 10.34.1.3, 00:00:58, GigabitEthernet0/0
O IA 192.168.3.3 [110/2] via 10.34.1.3, 00:00:58, GigabitEthernet0/0ABRs of a totally stubby area have no-summary appended to the configuration, Member routers (non-ABRs) of a totally stubby area are configured the same as those in a stub area and do not need no-summary.
The command area area-id stub no-summary is configured under the OSPF process. The keyword no-summary does exactly what it states: It blocks all Type 3 (summary) LSAs going into the stub area, making it a totally stubby area.
R3# configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
R3(config)# router ospf 1
R3(config-router)# area 34 stub no-summaryR4# configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
R4(config)# router ospf 1
R4(config-router)# area 34 stubRouting tables for R3 and R4 after Area 34 is converted to a totally stubby area, Notice that only the default route exists on R4
The routing table on R3 has not changed at all
R3# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/2] via 10.23.1.2, 00:02:34, GigabitEthernet0/1
O E1 172.16.1.0 [110/22] via 10.23.1.2, 00:02:34, GigabitEthernet0/1
O IA 192.168.1.1 [110/3] via 10.23.1.2, 00:02:34, GigabitEthernet0/1
O 192.168.2.2 [110/2] via 10.23.1.2, 00:02:34, GigabitEthernet0/1
O 192.168.4.4 [110/2] via 10.34.1.4, 00:03:23, GigabitEthernet0/0R4# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is 10.34.1.3 to network 0.0.0.0
O*IA 0.0.0.0/0 [110/2] via 10.34.1.3, 00:02:24, GigabitEthernet0/0Not-So-Stubby Areas
An OSPF not-so-stubby-area (NSSA) prohibits Type 5 LSAs from entering at the ABR but allows for redistribution of external routes into the NSSA and into Area 0
As the ASBR redistributes the route into OSPF in the NSSA, the ASBR advertises the route with a Type 7 LSA instead of a Type 5 LSA. When the Type 7 LSA reaches the ABR, the ABR converts the Type 7 LSA to a Type 5 LSA
The ABR does not automatically advertise a default route into an NSSA when a Type 5 or Type 7 LSA is blocked (because it might have its own NSSA based default route so it does not do it automatically, thinking may be it is not needed)
During configuration, an option exists to advertise a default route to provide connectivity to the blocked LSAs; in addition, other techniques can be used to ensure bidirectional connectivity.
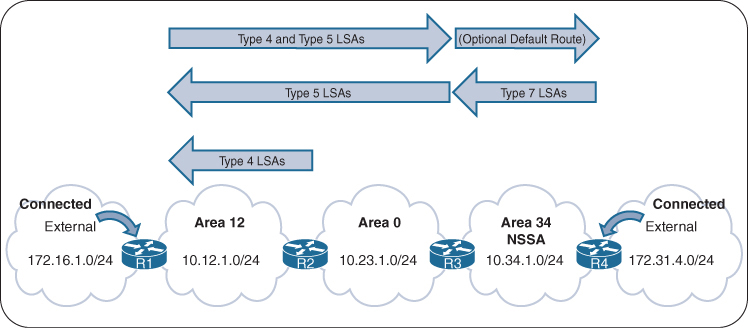
Routing tables of R1, R3, and R4 before Area 34 is converted to an NSSA
R1# show ip route ospf | section 172.31
O E1 172.31.4.0 [110/23] via 10.12.1.2, 00:00:38, GigabitEthernet0/0R3# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/2] via 10.23.1.2, 00:01:34, GigabitEthernet0/1
O E1 172.16.1.0 [110/22] via 10.23.1.2, 00:01:34, GigabitEthernet0/1
O E1 172.31.4.0 [110/21] via 10.34.1.4, 00:01:12, GigabitEthernet0/0
O IA 192.168.1.1 [110/3] via 10.23.1.2, 00:01:34, GigabitEthernet0/1
O 192.168.2.2 [110/2] via 10.23.1.2, 00:01:34, GigabitEthernet0/1
O 192.168.4.4 [110/2] via 10.34.1.4, 00:01:12, GigabitEthernet0/0R4# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/3] via 10.34.1.3, 00:02:28, GigabitEthernet0/0
O IA 10.23.1.0/24 [110/2] via 10.34.1.3, 00:02:28, GigabitEthernet0/0
O E1 172.16.1.0 [110/23] via 10.34.1.3, 00:02:28, GigabitEthernet0/0
O IA 192.168.1.1 [110/4] via 10.34.1.3, 00:02:28, GigabitEthernet0/0
O IA 192.168.2.2 [110/3] via 10.34.1.3, 00:02:28, GigabitEthernet0/0
O IA 192.168.3.3 [110/2] via 10.34.1.3, 00:02:28, GigabitEthernet0/0The command area area-id nssa [default-information-originate] is placed under the OSPF process on the ABR. All routers in an NSSA must be configured with the nssa option, or they do not become adjacent
A default route is not injected on the ABRs automatically for NSSAs, but the optional command default-information-originate can be appended to the configuration if a default route is needed in the NSSA.
R3# show run | section router ospf
router ospf 1
router-id 192.168.3.3
area 34 nssa default-information-originate
network 10.23.1.0 0.0.0.255 area 0
network 10.34.1.0 0.0.0.255 area 34
network 192.168.3.3 0.0.0.0 area 0R4# show run | section router ospf
router ospf 1
router-id 192.168.4.4
area 34 nssa
redistribute connected metric-type 1 subnets
network 10.34.1.0 0.0.0.255 area 34
network 192.168.4.4 0.0.0.0 area 34shows the routing tables of R3 and R4 after converting Area 34 to an NSSA
On R3, the previous external route from R1 still exists as an OSPF external Type 1 (O E1) route, and R4’s external route is now an OSPF external NSSA Type 1 (O N1) route
On R4, R1’s external route is no longer present. R3 is configured to advertise a default route, which appears as an OSPF external NSSA Type 2 (O N2) route.
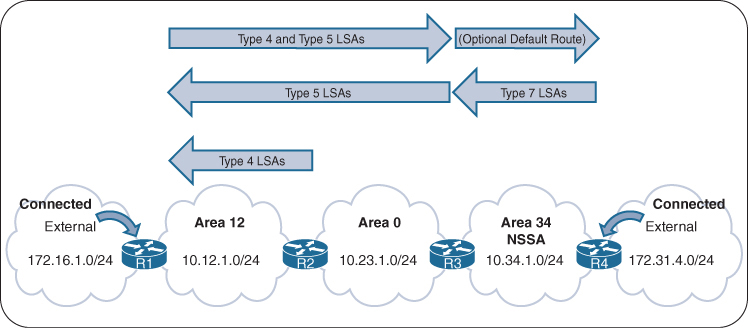
R3# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/2] via 10.23.1.2, 00:04:13, GigabitEthernet0/1
O E1 172.16.1.0 [110/22] via 10.23.1.2, 00:04:13, GigabitEthernet0/1
O N1 172.31.4.0 [110/22] via 10.34.1.4, 00:03:53, GigabitEthernet0/0
O IA 192.168.1.1 [110/3] via 10.23.1.2, 00:04:13, GigabitEthernet0/1
O 192.168.2.2 [110/2] via 10.23.1.2, 00:04:13, GigabitEthernet0/1
O 192.168.4.4 [110/2] via 10.34.1.4, 00:03:53, GigabitEthernet0/0R4# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is 10.34.1.3 to network 0.0.0.0
O*N2 0.0.0.0/0 [110/1] via 10.34.1.3, 00:03:13, GigabitEthernet0/0
O IA 10.12.1.0/24 [110/3] via 10.34.1.3, 00:03:23, GigabitEthernet0/0
O IA 10.23.1.0/24 [110/2] via 10.34.1.3, 00:03:23, GigabitEthernet0/0
O IA 192.168.1.1 [110/4] via 10.34.1.3, 00:03:23, GigabitEthernet0/0
O IA 192.168.2.2 [110/3] via 10.34.1.3, 00:03:23, GigabitEthernet0/0
O IA 192.168.3.3 [110/2] via 10.34.1.3, 00:03:23, GigabitEthernet0/0Totally NSSAs
Totally NSSA block Type 3 and Type 5 LSAs and still provide the capability of redistributing external networks
When the ASBR redistributes the route into OSPF, the ASBR advertises the route with a Type 7 LSA. As the Type 7 LSA reaches the ABR, the ABR converts the Type 7 LSA to a Type 5 LSA.
When an ABR for a totally NSSA receives a Type 3 LSA from the backbone, the ABR generates a default route for the totally NSSA. When an interface on the ABR is assigned to Area 0, it acts as the trigger for the Type 3 LSA that leads to the default route generation within the totally NSSA.
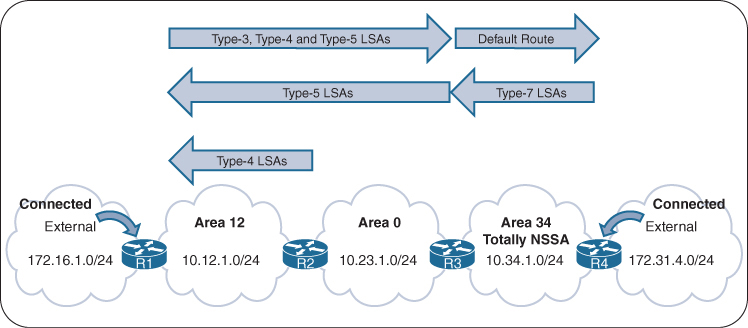
R1’s, R3s, and R4’s Routing Tables Before Area 34 Is a Totally NSSA
R1# show ip route ospf | section 172.31
172.31.0.0/24 is subnetted, 1 subnets
O E1 172.31.4.0 [110/23] via 10.12.1.2, 00:00:38, GigabitEthernet0/0R3# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/2] via 10.23.1.2, 00:01:34, GigabitEthernet0/1
O E1 172.16.1.0 [110/22] via 10.23.1.2, 00:01:34, GigabitEthernet0/1
O E1 172.31.4.0 [110/21] via 10.34.1.4, 00:01:12, GigabitEthernet0/0
O IA 192.168.1.1 [110/3] via 10.23.1.2, 00:01:34, GigabitEthernet0/1
O 192.168.2.2 [110/2] via 10.23.1.2, 00:01:34, GigabitEthernet0/1
O 192.168.4.4 [110/2] via 10.34.1.4, 00:01:12, GigabitEthernet0/0R4# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/3] via 10.34.1.3, 00:02:28, GigabitEthernet0/0
O IA 10.23.1.0/24 [110/2] via 10.34.1.3, 00:02:28, GigabitEthernet0/0
O E1 172.16.1.0 [110/23] via 10.34.1.3, 00:02:28, GigabitEthernet0/0
O IA 192.168.1.1 [110/4] via 10.34.1.3, 00:02:28, GigabitEthernet0/0
O IA 192.168.2.2 [110/3] via 10.34.1.3, 00:02:28, GigabitEthernet0/0
O IA 192.168.3.3 [110/2] via 10.34.1.3, 00:02:28, GigabitEthernet0/0Member routers of a totally NSSA use the same configuration as members of an NSSA and do not need no-summary, ABRs of a totally NSSA area have no-summary appended to the configuration. The command area area-id nssa no-summary is configured under the OSPF process.
R3# show run | section router ospf 1
router ospf 1
router-id 192.168.3.3
area 34 nssa no-summary
network 10.23.1.0 0.0.0.255 area 0
network 10.34.1.0 0.0.0.255 area 34
network 192.168.3.3 0.0.0.0 area 0R4# show run | section router ospf 1
router ospf 1
router-id 192.168.4.4
area 34 nssa
redistribute connected metric-type 1 subnets
network 10.34.1.0 0.0.0.255 area 34
network 192.168.4.4 0.0.0.0 area 34Routing tables of R3 and R4 after Area 34 is converted into a totally NSSA.

R3 detects R1’s redistributed route as an O E1 (Type 5 LSA) and R4’s redistributed route as an O N1 (Type 7 LSA)
R3# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/2] via 10.23.1.2, 00:02:14, GigabitEthernet0/1
O E1 172.16.1.0 [110/22] via 10.23.1.2, 00:02:14, GigabitEthernet0/1
O N1 172.31.4.0 [110/22] via 10.34.1.4, 00:02:04, GigabitEthernet0/0
O IA 192.168.1.1 [110/3] via 10.23.1.2, 00:02:14, GigabitEthernet0/1
O 192.168.2.2 [110/2] via 10.23.1.2, 00:02:14, GigabitEthernet0/1
O 192.168.4.4 [110/2] via 10.34.1.4, 00:02:04, GigabitEthernet0/0Notice that only the default route exists on R4
R4# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is 10.34.1.3 to network 0.0.0.0
O*IA 0.0.0.0/0 [110/2] via 10.34.1.3, 00:04:21, GigabitEthernet0/0OSPF Path Selection
OSPF executes Dijkstra’s shortest path first (SPF) algorithm to create a loop-free topology of shortest paths, All routers use same SPF algorithm and come up with their own topology of shortest paths.
Path selection prioritizes paths in the following order:
- O
- O IA
- N1
- E1
- N2
- E2
Link Costs
Router’s outgoing interface cost is used to accumulate path cost
but every interface is given its cost based on below formula

Or OSPF cost can be set manually with the command ip ospf cost 1-65535 under the interface.
Each OSPF link cost (interface cost) is stored in LSAs.
LSAs use a 16-bit field for cost → maximum value = 65,535.
But OSPF does not store the full path cost in the LSA, instead 1 – 65535 limited costs are assigned to interfaces in LSDB topology and then cumulative path cost is calculated each router when each router executes its own SPF, Therefore, the total path metric can exceed 65,535, even though each individual link cost cannot.
The default reference bandwidth is 100 Mbps due to legacy OSPF design
There is no differentiation in the link cost associated with a Fast Ethernet interface and a 10-Gigabit Ethernet interface which is bad because there is a huge difference and should be differentiated
Changing the reference bandwidth to a higher value allows for differentiation of cost between higher-speed interfaces.
Under the OSPF process, the command auto-cost reference-bandwidth bandwidth-in-mbps changes the reference bandwidth for all OSPF interfaces associated with that process.
If the reference bandwidth is changed on one router, then the reference bandwidth should be changed on all OSPF routers to ensure that SPF uses the same logic to prevent routing loops. It is a best practice to set the same reference bandwidth for all OSPF routers.
NX-OS uses a default reference cost of 40,000 Mbps
Intra-area Routes
OSPF intra-area routes (Type 1 and 2 LSAs) are always preferred over inter-area routes (Type 3 LSAs).

R1 is calculating the route to the 10.4.4.0/24 network. Instead of taking the faster Ethernet connection (R1→R2→R4), R1 takes the path across the slower serial link to R4 (R1→R3→R4) because that is the intra-area path.
R1# show ip route 10.4.4.0
Routing entry for 10.4.4.0/24
Known via "ospf 1", distance 110, metric 111, type intra area
Last update from 10.13.1.3 on GigabitEthernet0/1, 00:00:42 ago
Routing Descriptor Blocks:
* 10.13.1.3, from 10.34.1.4, 00:00:42 ago, via GigabitEthernet0/1
Route metric is 111, traffic share count is 1Inter-area Routes

R1 is computing the path to R6. R1 uses the path R1→R3→R5→R6 because its total path metric is 35 as compared to the metric of 40 for the R1→R2→R4→R6 path
External Route Selection
External routes are classified as Type 1 or Type 2. The main differences between Type 1 and Type 2 external OSPF routes are as follows:
- Type 1 routes are preferred over Type 2 routes.
- The Type 1 metric equals the redistribution metric plus the total path metric to the ASBR. In other words, as the LSA propagates away from the originating ASBR, the metric increases.
- The Type 2 metric equals only the redistribution metric. The metric is the same for the router next to the ASBR as for the router 30 hops away from the originating ASBR. This is the default external metric type that OSPF uses.
E1 and N1 External Routes
External OSPF Type 1 route calculation involves the redistribution metric plus the lowest path metric to reach the ASBR that advertised the network. Type 1 path metrics are lower for routers closer to the originating ASBR, whereas the path metric is higher for a router 10 hops away from the ASBR.
If there is a tie in the path metric, both routes are installed into the RIB. If the ASBR is in a different area, the path of the traffic must go through Area 0. An ABR does not install O E1 and O N1 routes into the RIB at the same time. O N1 is always given preference for a typical NSSA, and its presence prevents the O E1 from being installed on the ABR.
E2 and N2 External Routes
External OSPF Type 2 routes do not increment in metric, regardless of the path metric to the ASBR. If there is a tie in the redistribution metric, the router compares the metric to the ASBR that advertised the network, and the path with lower metric to ASBR wins. If there is a tie in metric to ASBR, both routes are installed into the routing table
An ABR does not install O E2 and O N2 routes into the RIB at the same time. O N2 is always given preference for a typical NSSA, and its presence prevents the O E2 from being installed on the ABR.
show ip ospf border-routersTypes of routers shown in above command
- ASBRs — Autonomous System Boundary Routers
(Routers that inject external routes into OSPF using E1/E2 LSAs) - ABRs — Area Border Routers
(Routers that connect one OSPF area to another and generate Type-3/4/5 LSAs)

172.16.0.0/24 has a metric of 20
R1→R2→R4→R6 path is 31, and the forwarding metric of the R1→R3→R5→R7 path is 30. R1 installs the R1→R3→R5→R7 path into the routing table.
R1# show ip route 172.16.0.0
Routing entry for 172.16.0.0/24
Known via "ospf 1", distance 110, metric 20, type extern 2, forward metric 30
Last update from 10.13.1.3 on GigabitEthernet0/1, 00:12:40 ago
Routing Descriptor Blocks:
* 10.13.1.3, from 192.168.7.7, 00:12:40 ago, via GigabitEthernet0/1
Route metric is 20, traffic share count is 1The logic of choosing an O Nx route over an O Ex route is defined in RFC 3101. Choosing an O Nx is the current default for IOS XE implementations. RFC 1583 prefers an O Ex route over an O Nx route. RFC 1583 path selection can be enabled with the command compatible rfc1583
Equal-Cost Multipathing
If OSPF calculates same path cost for multiple prefixes, they are all installed in the routing table. The default max ECMP paths is four. The default ECMP setting can be overwritten with the command maximum-paths maximum-paths under the OSPF process to modify the default setting.
Summarization
OSPF LSDB size can become large even after splitting OSPF into multiple areas due to large number of Type 3 LSAs and also the Type 5 LSAs
Summarization is a method of shrinking the LSDB
Newer routers have more memory and faster processors than do older ones, but because all routers have an identical copy of the LSDB, an OSPF area needs to accommodate the smallest and slowest router in that area.
Summarization of routes also helps SPF calculations run faster.
A router that has 10,000 network routes will take longer to run the SPF calculation than a router with 500 network routes. Because all routers within an area must maintain an identical copy of the LSDB
Summarization only occurs between areas on the ABRs.
Summarization can protect against the changes in prefixes outside the area for the summarized prefixes because the smaller prefixes are hidden.
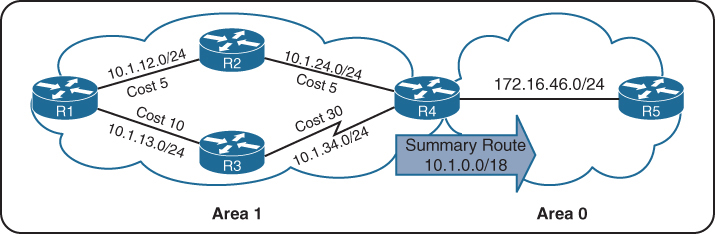
shows the networks in Area 1 being summarized at the ABR into the aggregate 10.1.0.0/18 prefix
If the 10.1.12.0/24 link fails, all the routers in Area 1 still run the SPF calculation, but routers in Area 0 are not affected because the 10.1.13.0/24 and 10.1.34.0/24 networks are not known outside Area 1.
Inter-area summarization reduces the number of Type 3 LSAs that an ABR advertises into an area when it receives Type 1 LSAs. The network summarization range is associated with a specific source area for Type 1 LSAs.
When a Type 1 LSA in the summarization range reaches the ABR from the source area, the ABR creates a Type 3 LSA for the summarized network range. The ABR suppresses the more specific Type 3 LSAs.
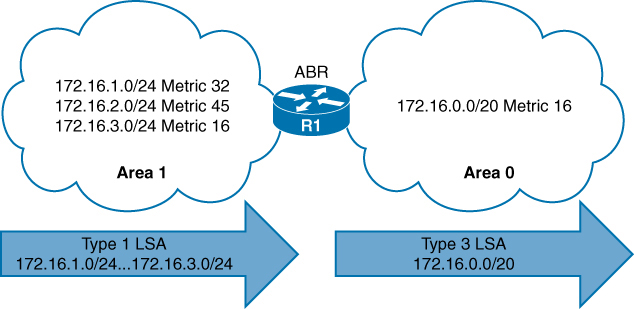
Type 1 LSAs (172.16.1.0/24, 172.16.2.0/24, and 172.16.3.0/24) being summarized into one Type 3 LSA
Summarization works only on Type 1 LSAs and is normally configured (or designed) so that summarization occurs as routes enter the backbone from nonbackbone areas Area x -> Area 0.
At the time of this writing, IOS XE routers set the default metric for the summary LSA to be the lowest metric associated with an LSA
However, the summary metric can statically be set as part of the configuration
R1 summarizes three prefixes with various path costs. The 172.16.3.0/24 prefix has the lowest metric, so that metric will be used for the summarized route.
OSPF behaves similar to Enhanced Interior Gateway Routing Protocol (EIGRP) in that it checks every prefix in the summarization range when a matching Type 1 LSA is added or removed. If a lower metric is available, the summary LSA is advertised with the newer metric; if the lowest metric is removed, a newer and higher metric is identified, and a new summary LSA is advertised with the higher metric.
Configuration of Inter-area Summarization
You define the summarization range and associated area by using the command area area-id range network subnet-mask [advertise | not-advertise] [cost metric] under the OSPF process.
The default behavior is to advertise the summary prefix, so the keyword advertise is not necessary. Appending cost metric to the command statically sets the metric on the summary route.

Routing Table Before OSPF Inter-area Route Summarization
R3# show ip route ospf | begin Gateway
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/2] via 10.23.1.2, 00:02:22, GigabitEthernet0/1
O IA 172.16.1.0 [110/3] via 10.23.1.2, 00:02:12, GigabitEthernet0/1
O IA 172.16.2.0 [110/3] via 10.23.1.2, 00:02:12, GigabitEthernet0/1
O IA 172.16.3.0 [110/3] via 10.23.1.2, 00:02:12, GigabitEthernet0/1router ospf 1
router-id 192.168.2.2
area 12 range 172.16.0.0 255.255.0.0 cost 45
network 10.12.0.0 0.0.255.255 area 12
network 10.23.0.0 0.0.255.255 area 0
R2 summarizes them into a single summary route, 172.16.0.0/16 static cost of 45 is added to the summary route to reduce CPU load if any of the three networks flap.
R3’s routing table shows that smaller component routes were suppressed while summary route is being advertised
Notice in this output that the path metric is 46 whereas previously the metric for the 172.16.1.0/24 network was 3.
R3# show ip route ospf | begin Gateway
Gateway of last resort is not set
O IA 10.12.1.0/24 [110/2] via 10.23.1.2, 00:02:04, GigabitEthernet0/1
O IA 172.16.0.0/16 [110/46] via 10.23.1.2, 00:00:22, GigabitEthernet0/1The ABR performing inter-area summarization installs discard routes, which are routes to the Null0 interface that match the summarized network. Discard routes prevent routing loops where portions of the summarized network range do not have a more specific route in the RIB. The administrative distance (AD) for the OSPF summary discard route for internal networks is 110, and it is 254 for external networks.
R2# show ip route ospf | begin Gateway
Gateway of last resort is not set
O 172.16.0.0/16 is a summary, 00:03:11, Null
O 172.16.1.0/24 [110/2] via 10.12.1.1, 00:01:26, GigabitEthernet0/0
O 172.16.2.0/24 [110/2] via 10.12.1.1, 00:01:26, GigabitEthernet0/0
O 172.16.3.0/24 [110/2] via 10.12.1.1, 00:01:26, GigabitEthernet0/0External Summarization
During OSPF redistribution, external routes are redistributed into the OSPF domain as Type 5 or Type 7 LSAs (NSSA). External summarization reduces the number of external LSAs in an OSPF domain
An external summarization route is configured on the ASBR router, and a smaller component route generates a Type 5/Type 7 external summary route, and the smaller component routes in the summary route are suppressed.
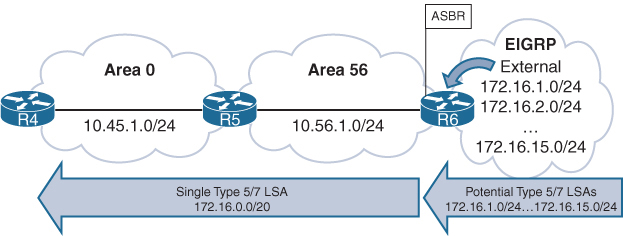
Routing Table Before External Summarization
R5# show ip route ospf | begin Gateway
! Output omitted for brevity
Gateway of last resort is not set
O IA 10.3.3.0/24 [110/67] via 10.45.1.4, 00:01:58, GigabitEthernet0/0
O IA 10.24.1.0/29 [110/65] via 10.45.1.4, 00:01:58, GigabitEthernet0/0
O IA 10.123.1.0/24 [110/66] via 10.45.1.4, 00:01:58, GigabitEthernet0/0
O E2 172.16.1.0 [110/20] via 10.56.1.6, 00:01:00, GigabitEthernet0/1
O E2 172.16.2.0 [110/20] via 10.56.1.6, 00:00:43, GigabitEthernet0/1
..
O E2 172.16.14.0 [110/20] via 10.56.1.6, 00:00:19, GigabitEthernet0/1
O E2 172.16.15.0 [110/20] via 10.56.1.6, 00:00:15, GigabitEthernet0/1R6
router ospf 1
router-id 192.168.6.6
summary-address 172.16.0.0 255.255.240.0
redistribute eigrp 1 subnets
network 10.56.1.0 0.0.0.255 area 56R5# show ip route ospf | begin Gateway
Gateway of last resort is not set
O IA 10.3.3.0/24 [110/67] via 10.45.1.4, 00:04:55, GigabitEthernet0/0
O IA 10.24.1.0/29 [110/65] via 10.45.1.4, 00:04:55, GigabitEthernet0/0
O IA 10.123.1.0/24 [110/66] via 10.45.1.4, 00:04:55, GigabitEthernet0/0
172.16.0.0/20 is subnetted, 1 subnets
O E2 172.16.0.0 [110/20] via 10.56.1.6, 00:00:02, GigabitEthernet0/1R5# show ip route 172.16.0.0 255.255.240.0
Routing entry for 172.16.0.0/20
Known via “ospf 1”, distance 110, metric 20, type extern 2, forward metric 1
Last update from 10.56.1.6 on GigabitEthernet0/1, 00:02:14 ago
Routing Descriptor Blocks:
* 10.56.1.6, from 192.168.6.6, 00:02:14 ago, via GigabitEthernet0/1
Route metric is 20, traffic share count is 1The summarizing ASBR installs a discard route to Null0 that matches the summary route as part of a loop-prevention mechanism and it will be seen on router that is doing summarization in this case R6
R6# show ip route ospf | begin Gateway
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 6 subnets, 3 masks
O IA 10.3.3.0/24 [110/68] via 10.56.1.5, 00:08:36, GigabitEthernet0/1
O IA 10.24.1.0/29 [110/66] via 10.56.1.5, 00:08:36, GigabitEthernet0/1
O IA 10.45.1.0/24 [110/2] via 10.56.1.5, 00:08:36, GigabitEthernet0/1
O IA 10.123.1.0/24 [110/67] via 10.56.1.5, 00:08:36, GigabitEthernet0/1
172.16.0.0/16 is variably subnetted, 15 subnets, 3 masks
O 172.16.0.0/20 is a summary, 00:03:52, Null0ABRs for NSSAs act as ASBRs when a Type 7 LSA is converted to a Type 5 LSA. External summarization can be performed on ABRs only when they match this scenario.
Discontiguous Network and Virtual links
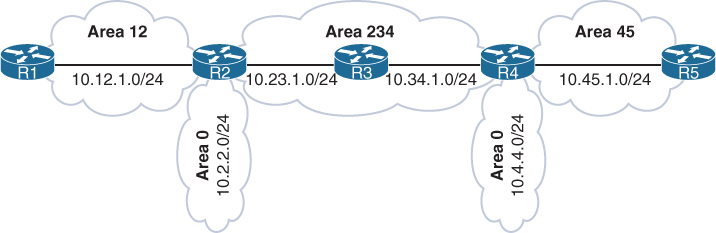
Above is a topology with mistake in design, where R2 and R4 are technically ABRs connected to Area 0 but this will not work, this is called discontiguous network. OSPF can catch this mistake because of all seeing LSDB
Most people would assume that R1 would learn about the route learned by Area 45 because R4 is an ABR. However, they would be wrong. ABRs follow three fundamental rules for creating Type 3 LSAs:
Type 1 LSAs received from an area create Type 3 LSAs into backbone area and nonbackbone areas.
Type 3 LSAs received from Area 0 are created for the nonbackbone area.
Type 3 LSAs received from a nonbackbone area are only inserted into the LSDB for the source area. An ABR does not create a Type 3 LSA for the other areas (including a segmented Area 0).
When suspect, make sure that every ABR is touching Area 0 where all other Aera 0 routers show to be part of it, In above topology only R2 will find itself in the Area 0 and also R4 will only see itself as part of Area 0
Create a detection strategy in lab and practice against that
Virtual Links
OSPF virtual links provide a method to overcome discontiguous networks
Virtual Links are not just used for discontiguous Area 0s but it is also used to connect a topology in which Area 0 <–R100–> Area 1 <–R101–> Area 2, R101 ABR is deprived of Area 0
Area 0 can be extended to remote Areas
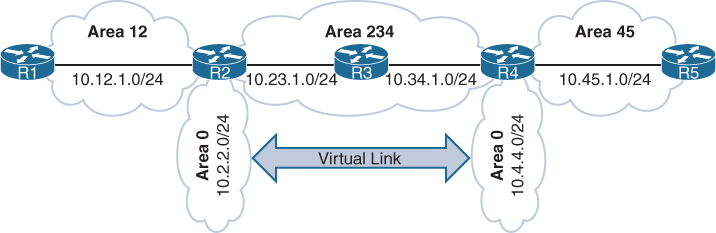
in above topology Area 12 and Area 45 were not orphaned
Area 12 , Area 0 and Area 234 kept working as R2 ABR has Area 0
Similarly Area 45 , Area 0 and Area 234 kept working as R4 ABR has Area 0
But Area 12 routes will not be learned by Area 45 and Area 45 routes will not be learned by Area 12 R2’s Area 0 and R4’s Area 0 are not same, practically preventing both from being in same Area 0
Virtual links are built between routers in the same area
The area in which the virtual link endpoints are established is known as the transit area
The virtual link can be one hop away or multiple hops away from the remote device between the ABRs
The virtual link is built using Type 1 LSAs
virtual links cannot be formed on any OSPF stubby areas
Area 234 cannot be an OSPF stub area. Or in this example Area 0 <–> Area 1 <–> Area 2 , Area 1 cannot be stub area
After Virtual Link configuration both Area 0 will become one Area 0 with 2x subnets 10.2.2.0/24 and 10.4.4.0/24 in Area 0
Think of virtual link being in Area 0, so once virtual link is established between ABRs, ABR that was not part of Area 0 will become part of Area 0 with one link in Area 0 which is virtual link
R2
router ospf 1
router-id 192.168.2.2
area 234 virtual-link 192.168.4.4 <<< like tunnel endpoint
network 10.2.2.2 0.0.0.0 area 0
network 10.12.1.2 0.0.0.0 area 12
network 10.23.1.2 0.0.0.0 area 234R4
router ospf 1
router-id 192.168.4.4
area 234 virtual-link 192.168.2.2 <<< like tunnel endpoint
network 10.4.4.4 0.0.0.0 area 0
network 10.34.1.4 0.0.0.0 area 234
network 10.45.1.4 0.0.0.0 area 45Interface cost for a virtual link cannot be set or dynamically generated as the metric for the intra-area distance between the two virtual link endpoints.
R2# show ip ospf virtual-links
Virtual Link OSPF_VL0 to router 192.168.4.4 is up
Run as demand circuit
DoNotAge LSA allowed.
Transit area 234, via interface GigabitEthernet0/1
Topology-MTID Cost Disabled Shutdown Topology Name
0 2 no no Base
Transmit Delay is 1 sec, State POINT_TO_POINT,
Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5
Hello due in 00:00:01
Adjacency State FULL (Hello suppressed)
Index 1/1/3, retransmission queue length 0, number of retransmission 0
First 0x0(0)/0x0(0)/0x0(0) Next 0x0(0)/0x0(0)/0x0(0)
Last retransmission scan length is 0, maximum is 0
Last retransmission scan time is 0 msec, maximum is 0 msecR4# show ip ospf virtual-links
! Output omitted for brevity
Virtual Link OSPF_VL0 to router 192.168.2.2 is up
Run as demand circuit
DoNotAge LSA allowed.
Transit area 234, via interface GigabitEthernet0/0
Topology-MTID Cost Disabled Shutdown Topology Name
0 2 no no Base
Transmit Delay is 1 sec, State POINT_TO_POINT,
Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5
Hello due in 00:00:08
Adjacency State FULL (Hello suppressed)Notice that the cost here is 2, which accounts for the metrics between R2 and R4
OSPF Virtual Link as an OSPF Interface
R4# show ip ospf interface brief
Interface PID Area IP Address/Mask Cost State Nbrs F/C
Gi0/2 1 0 10.4.4.4/24 1 DR 0/0
VL0 1 0 10.34.1.4/24 2 P2P 1/1
Lo0 1 34 192.168.4.4/32 1 DOWN 0/0
Gi0/1 1 45 10.45.1.4/24 1 BDR 1/1
Gi0/0 1 234 10.34.1.4/24 1 BDR 1/1A Virtual Link Displayed as an OSPF Neighbor
R4# show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
192.168.2.2 0 FULL/ - - 10.23.1.2 OSPF_VL0
192.168.5.5 1 FULL/DR 00:00:34 10.45.1.5 GigabitEthernet0/1
192.168.3.3 1 FULL/DR 00:00:38 10.34.1.3 GigabitEthernet0/0R1’s and R5’s Routing Tables After the Virtual Link Is Created
R1# show ip route ospf | begin Gateway
Gateway of last resort is not set
O IA 10.2.2.0/24 [110/2] via 10.12.1.2, 00:00:10, GigabitEthernet0/0
O IA 10.4.4.0/24 [110/4] via 10.12.1.2, 00:00:05, GigabitEthernet0/0
O IA 10.23.1.0/24 [110/2] via 10.12.1.2, 00:00:10, GigabitEthernet0/0
O IA 10.34.1.0/24 [110/3] via 10.12.1.2, 00:00:10, GigabitEthernet0/0
O IA 10.45.1.0/24 [110/4] via 10.12.1.2, 00:00:05, GigabitEthernet0/0R5# show ip route ospf | begin Gateway
Gateway of last resort is not set
O IA 10.2.2.0/24 [110/4] via 10.45.1.4, 00:00:43, GigabitEthernet0/1
O IA 10.4.4.0/24 [110/2] via 10.45.1.4, 00:01:48, GigabitEthernet0/1
O IA 10.12.1.0/24 [110/4] via 10.45.1.4, 00:00:43, GigabitEthernet0/1
O IA 10.23.1.0/24 [110/3] via 10.45.1.4, 00:01:48, GigabitEthernet0/1
O IA 10.34.1.0/24 [110/2] via 10.45.1.4, 00:01:48, GigabitEthernet0/1next post
SDA LM3 – Topology & Software Image Management
Videos
Topology & Software Image Management




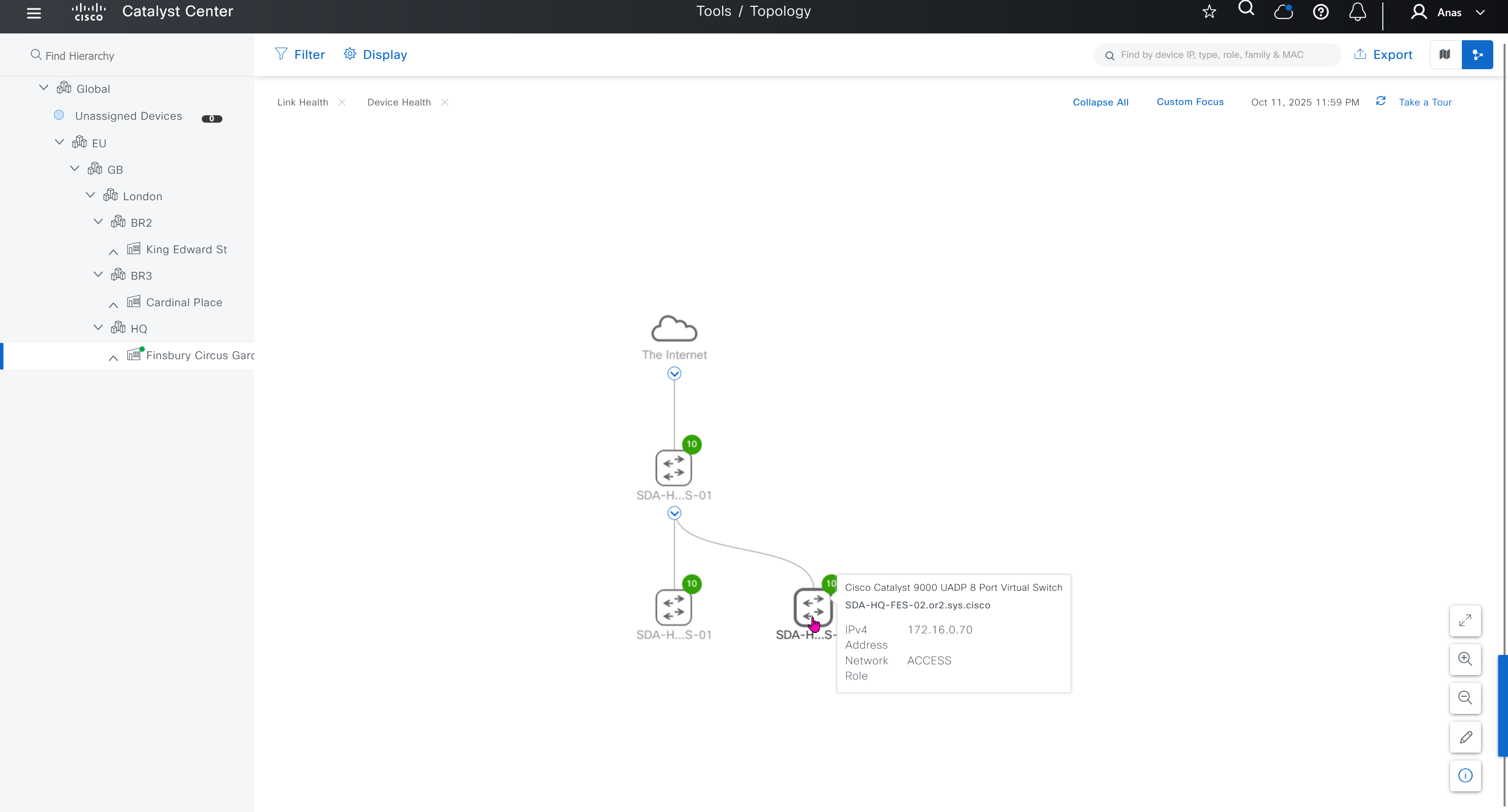
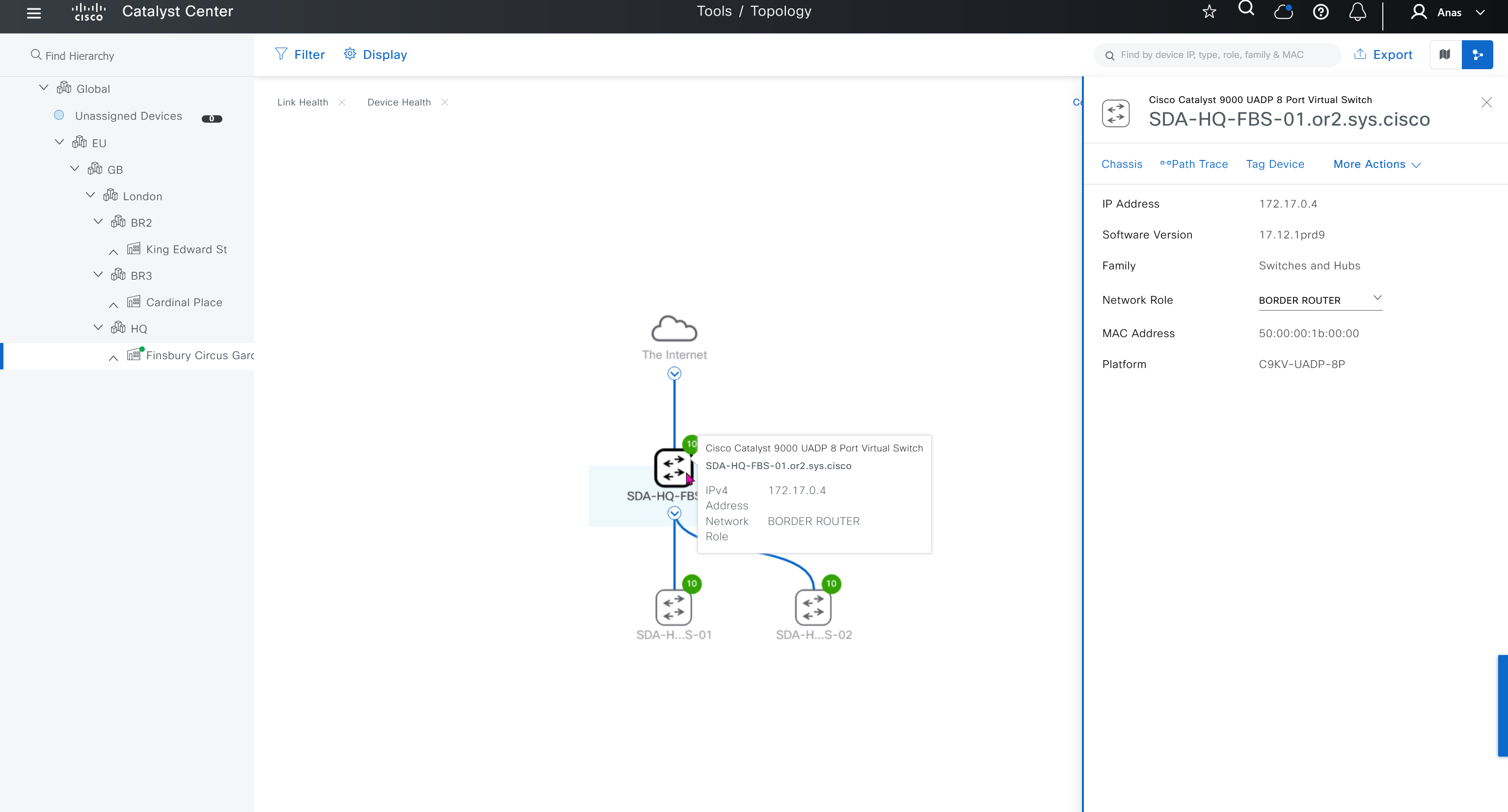


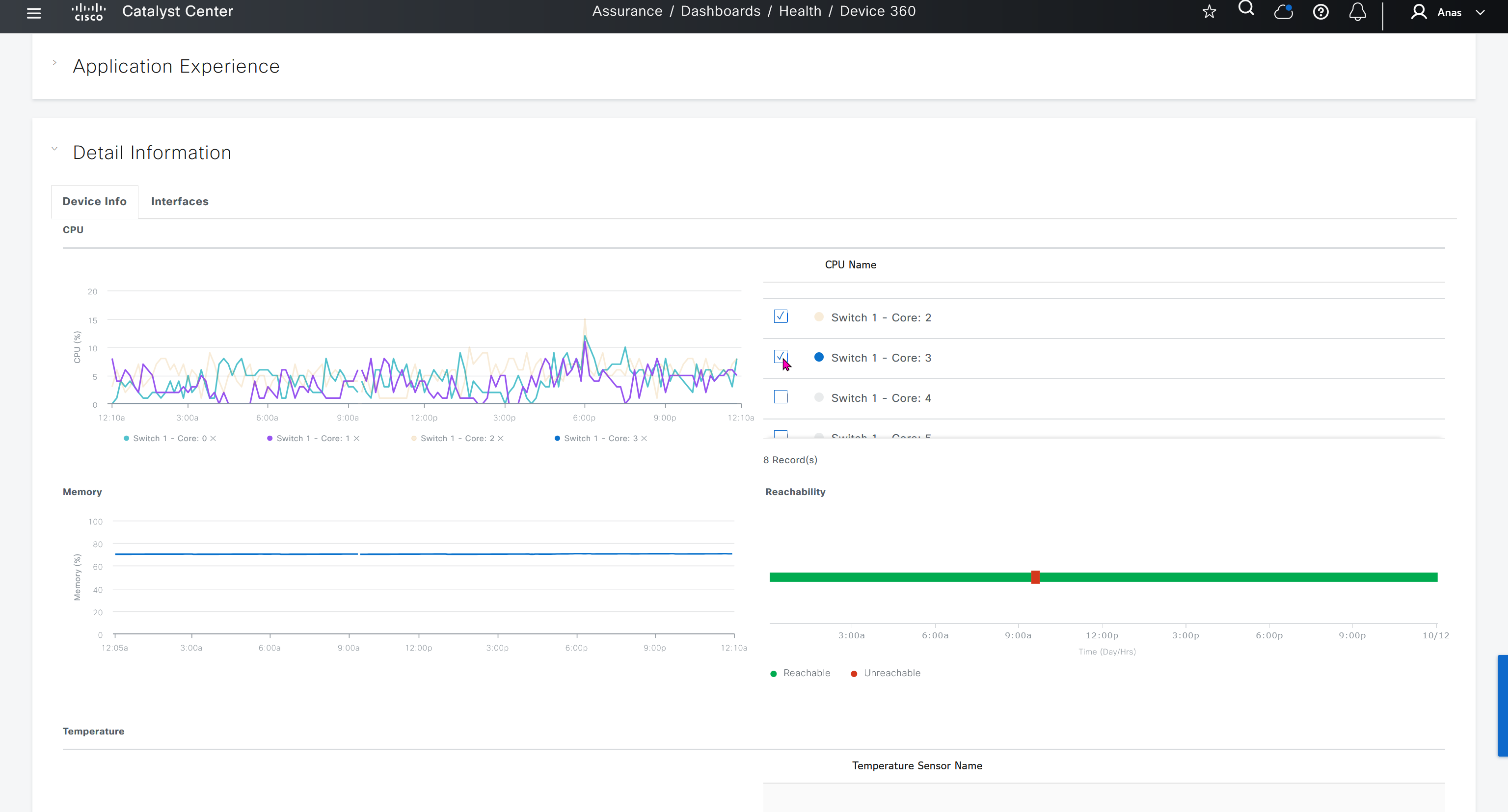
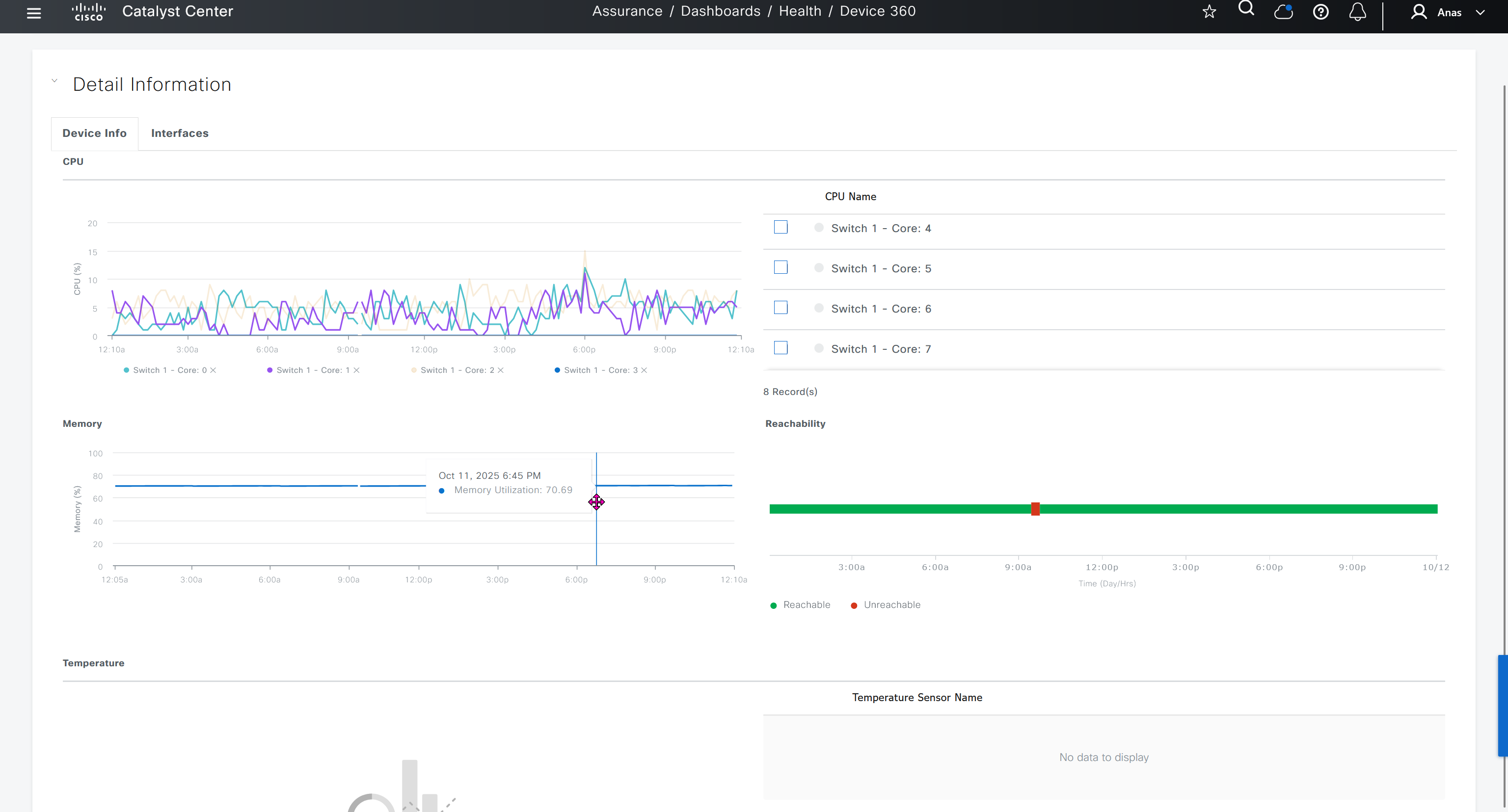
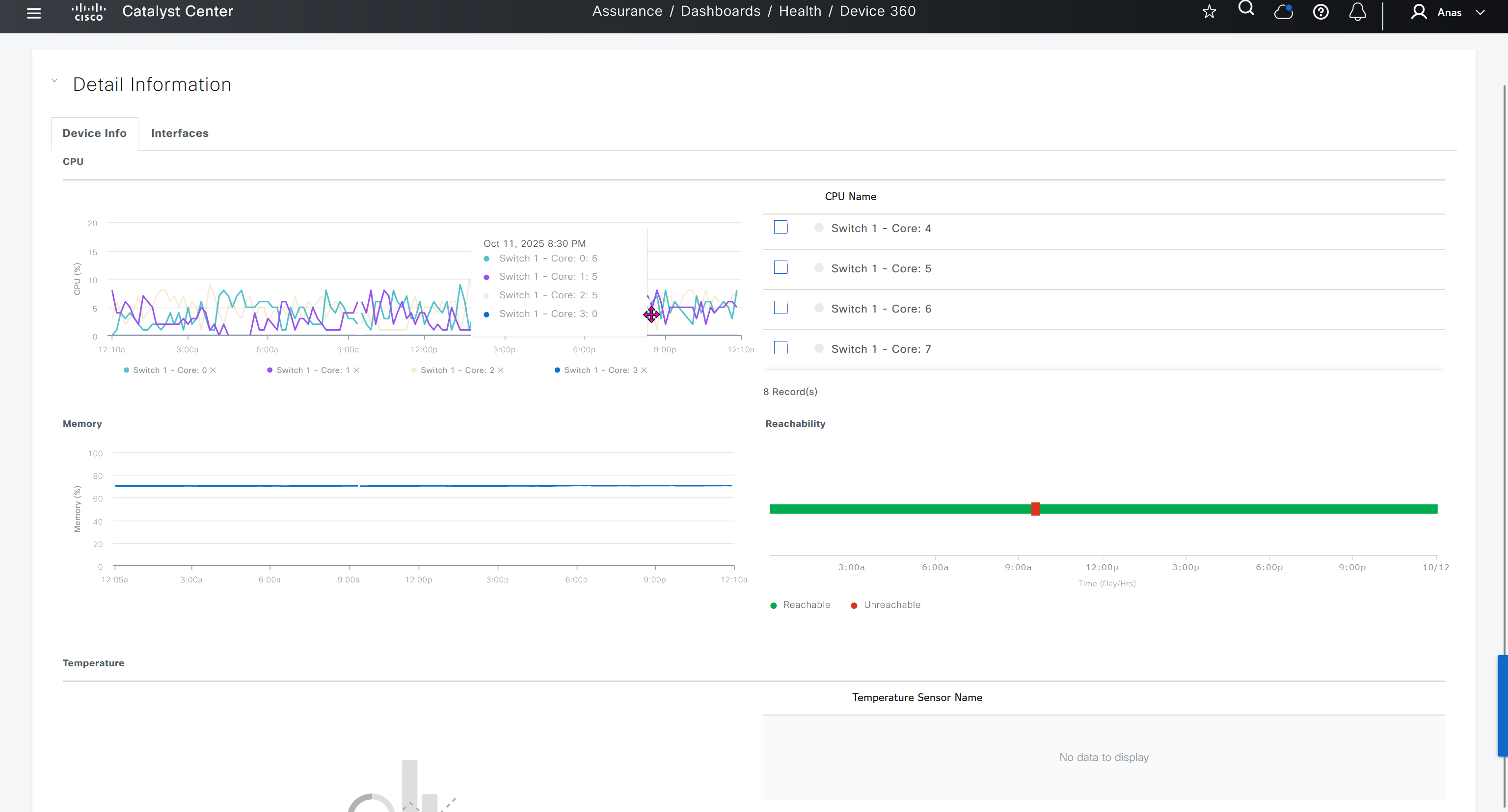
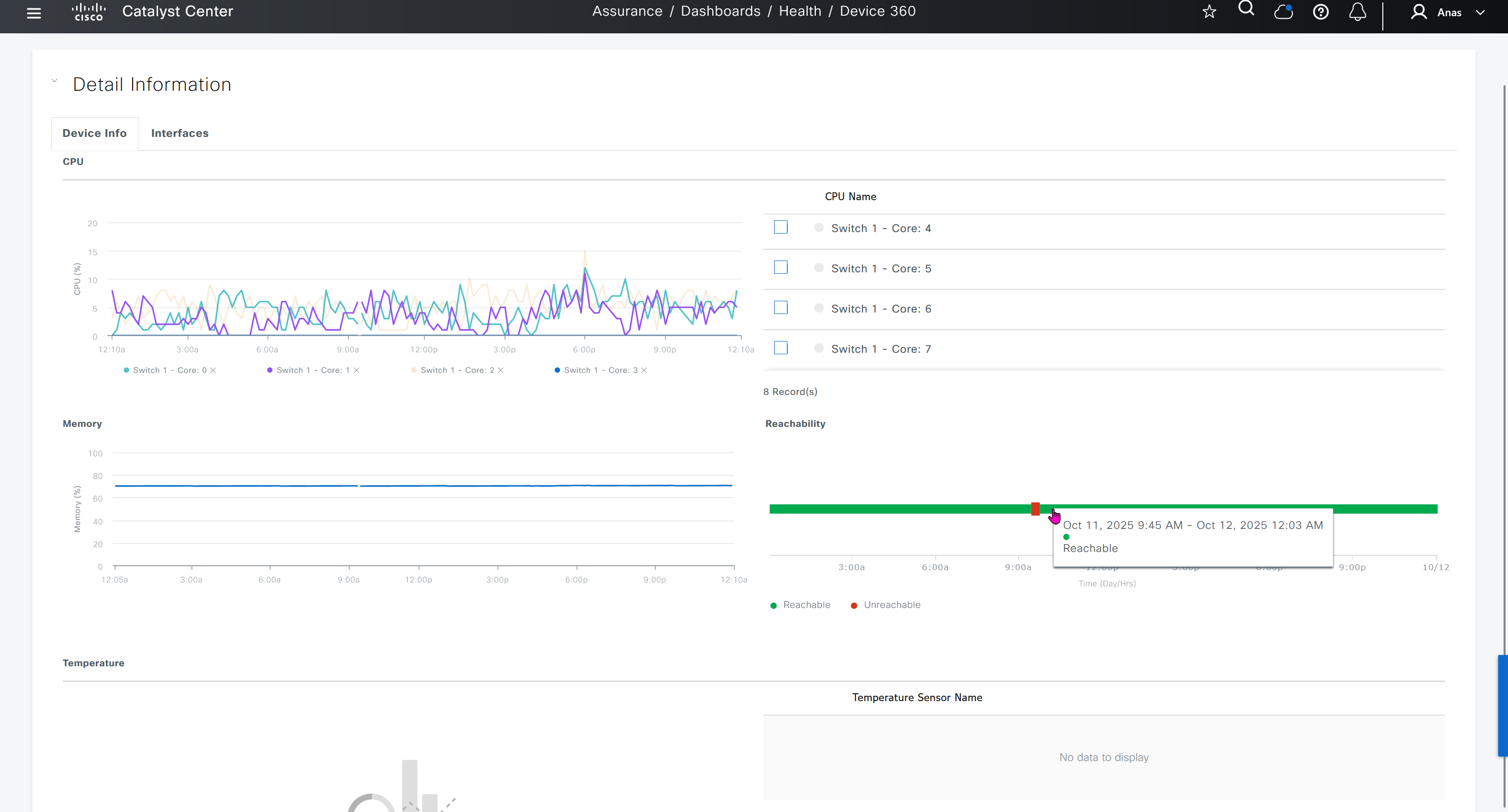
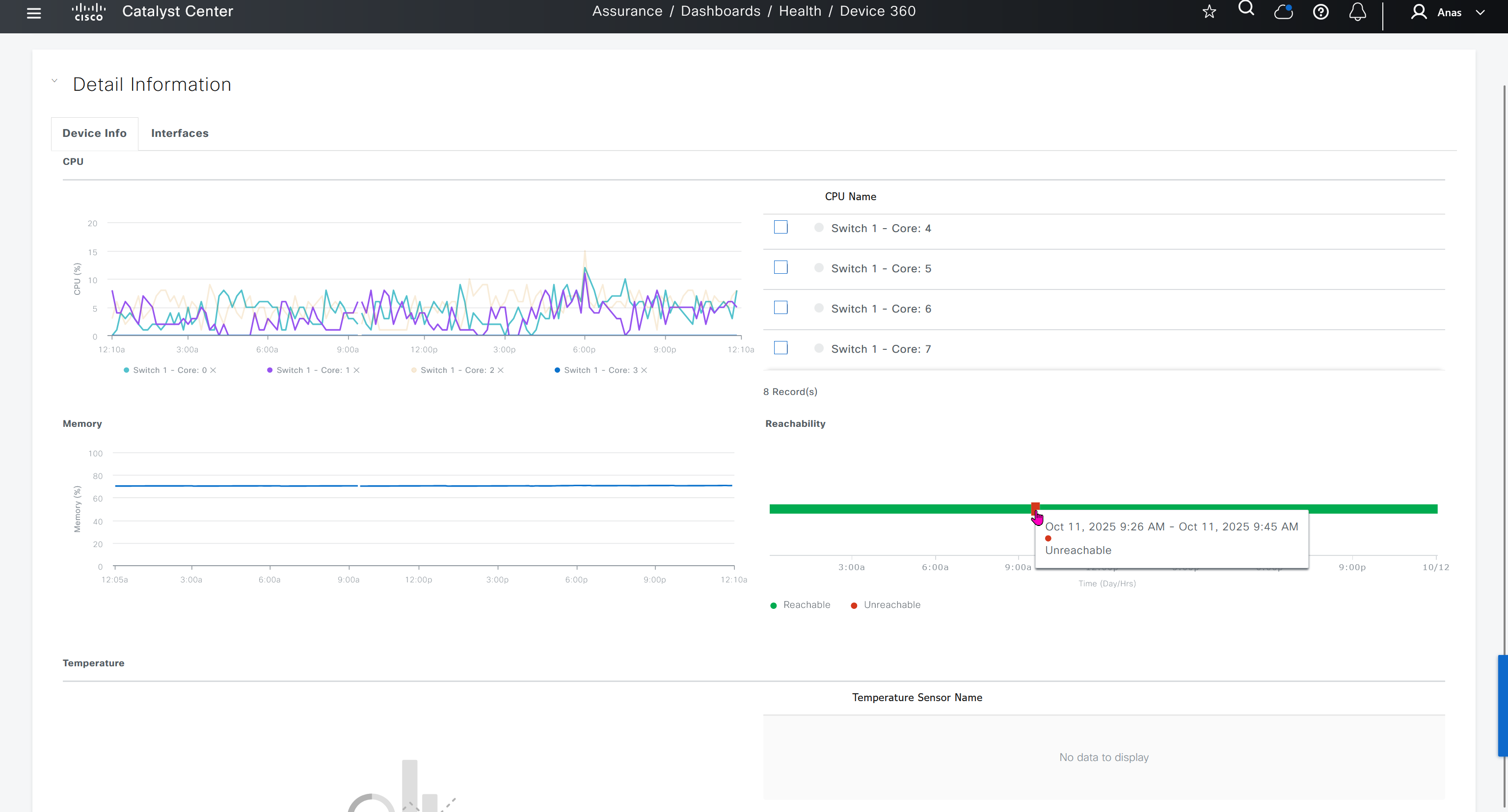
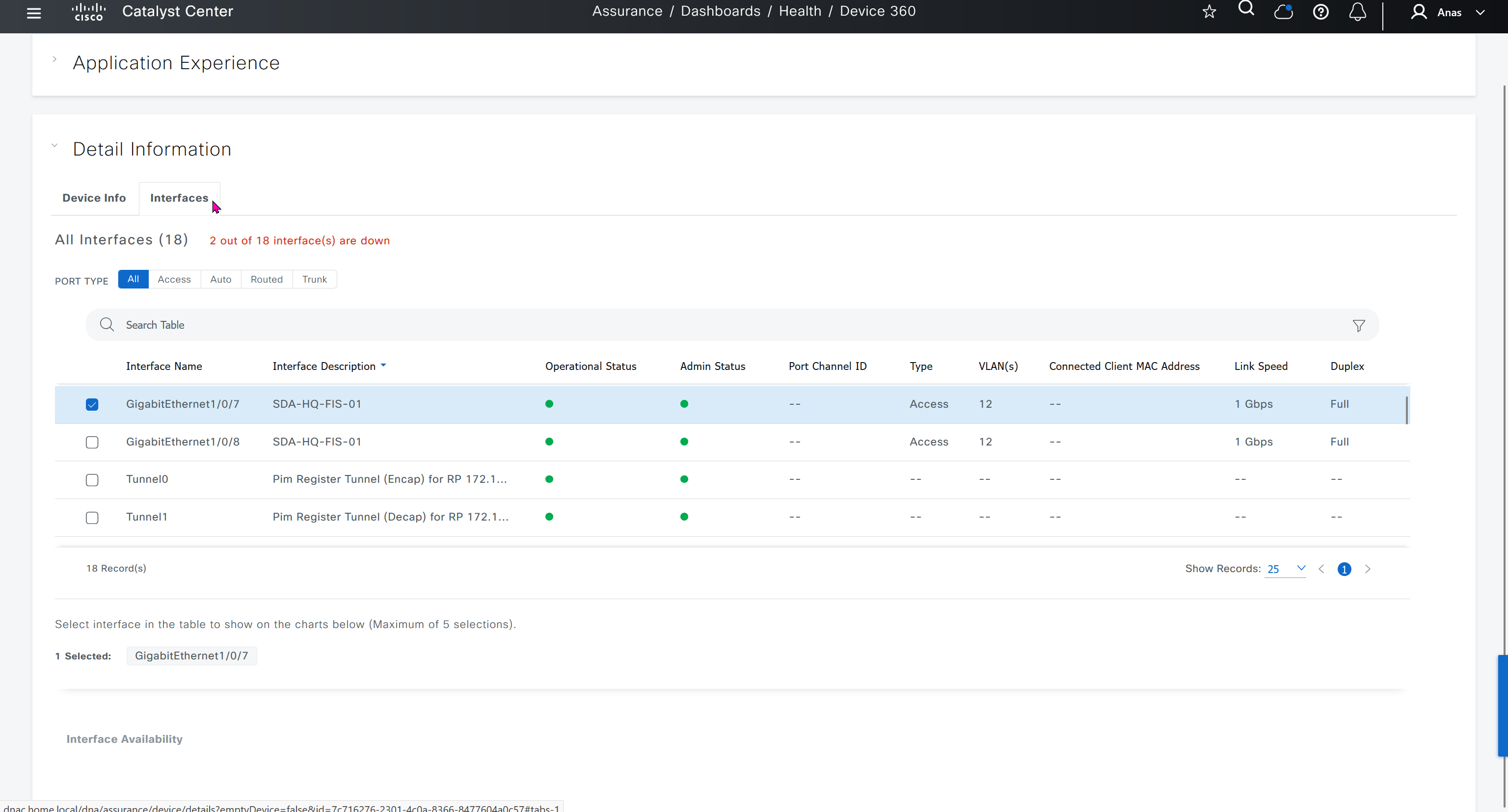
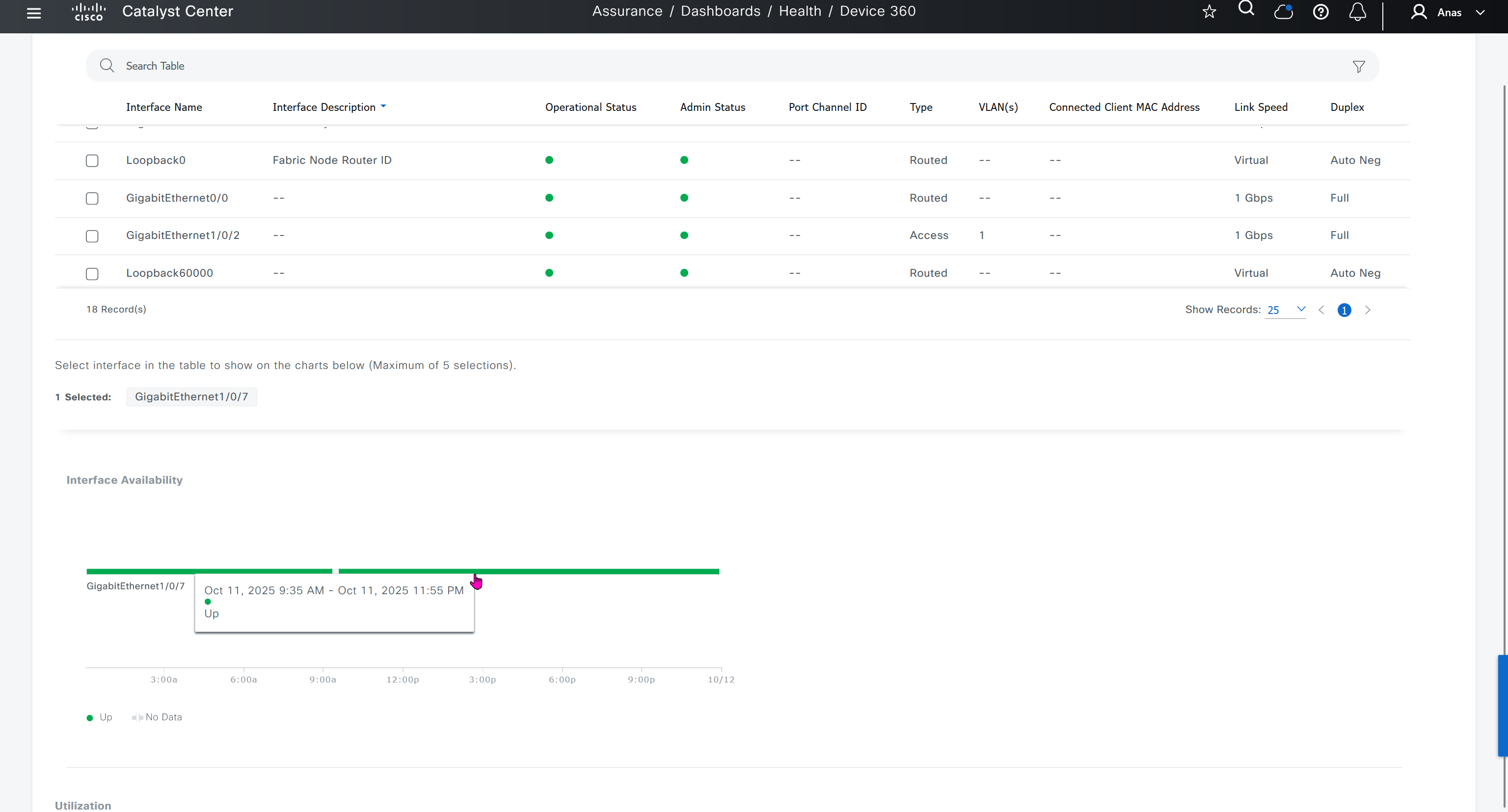
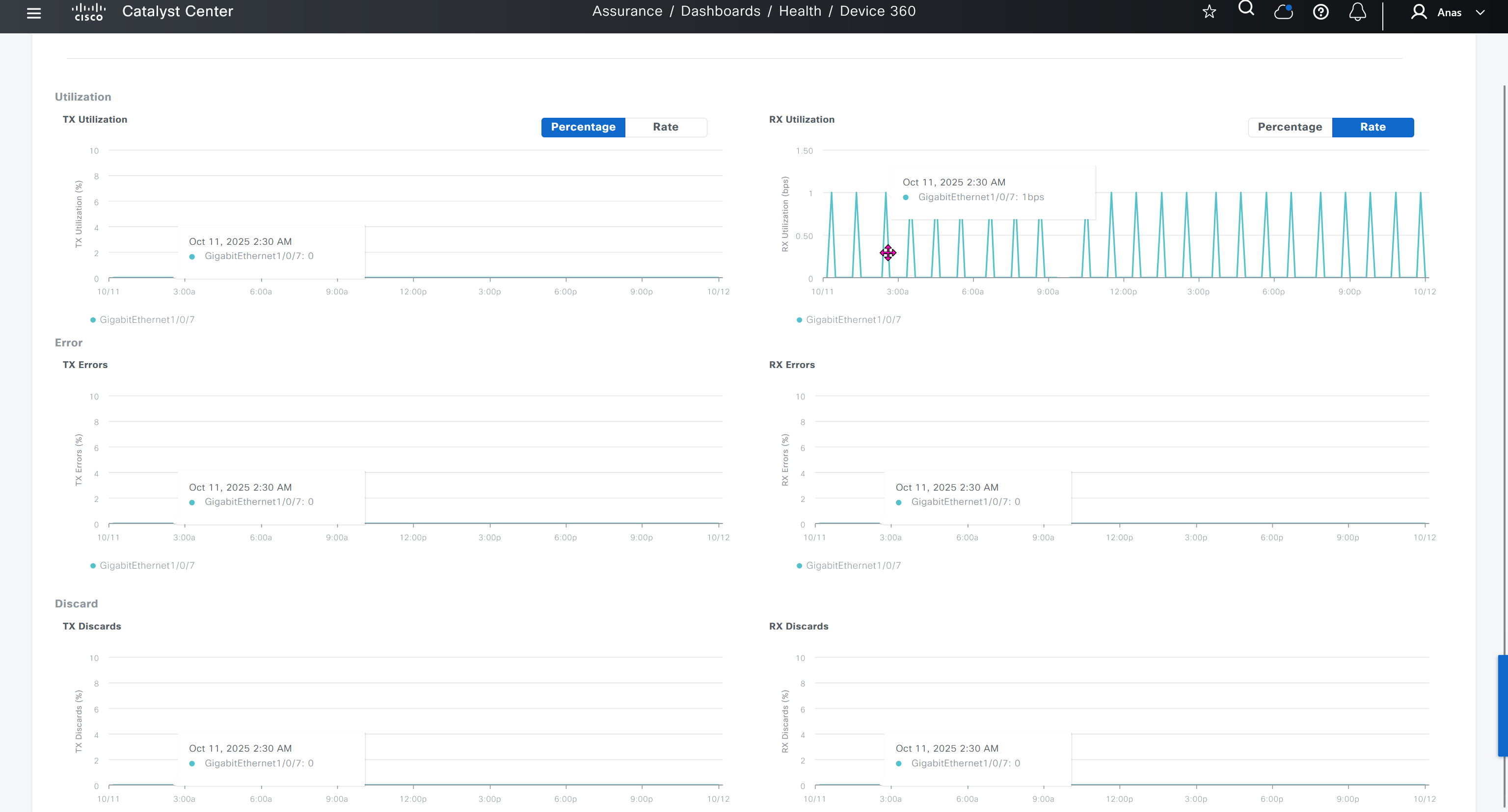

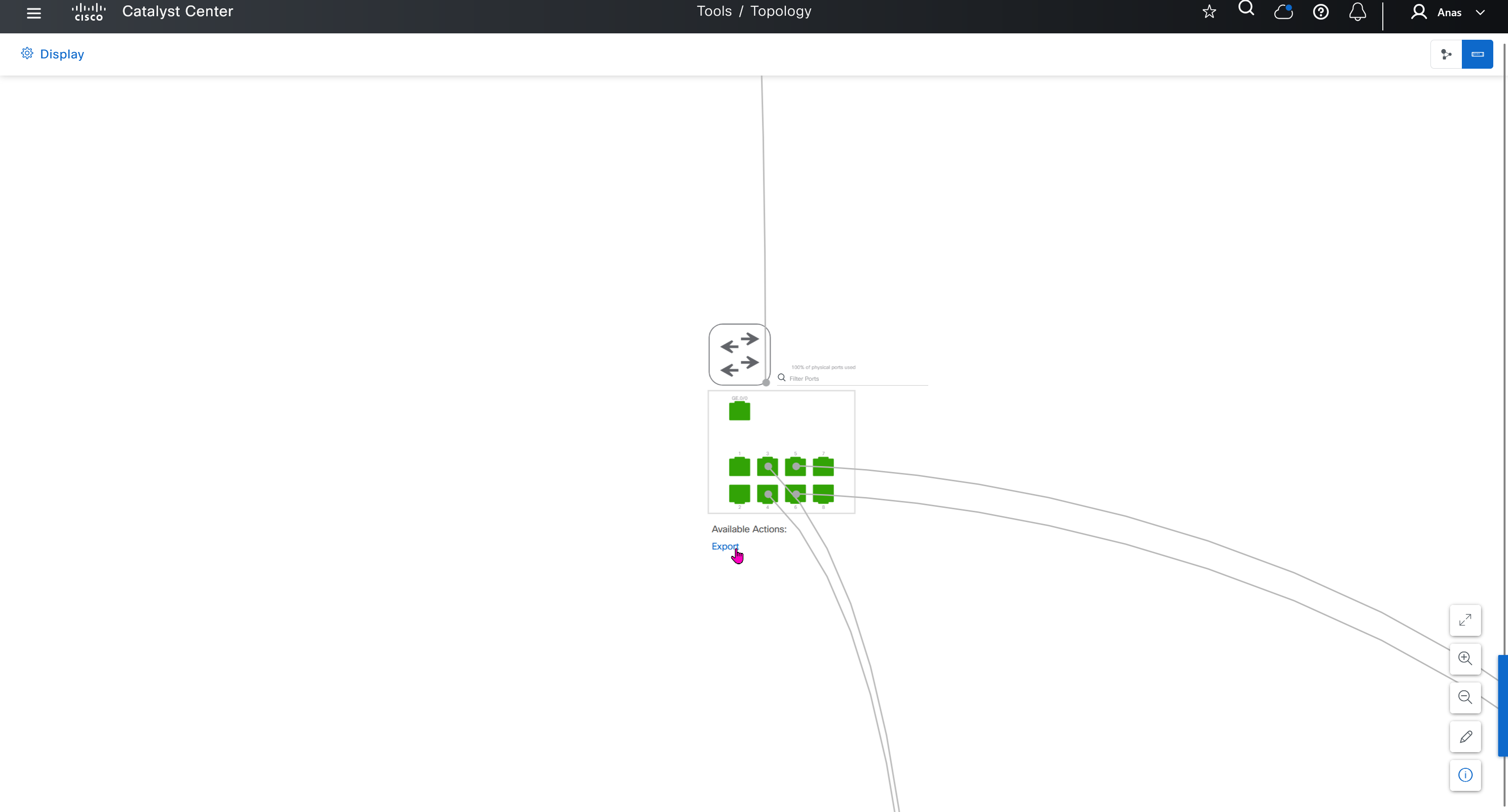

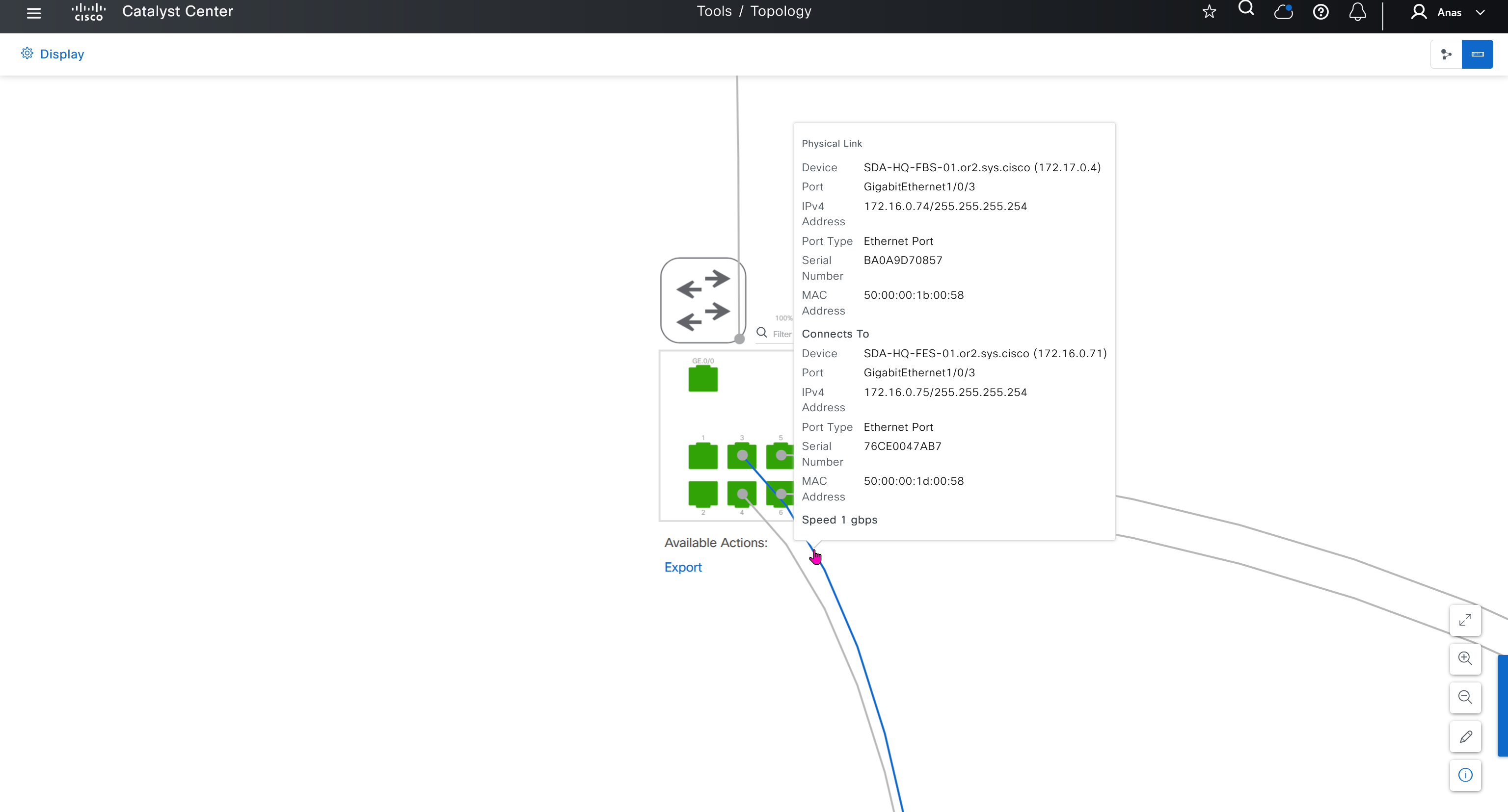


SWIM – Software Image Management
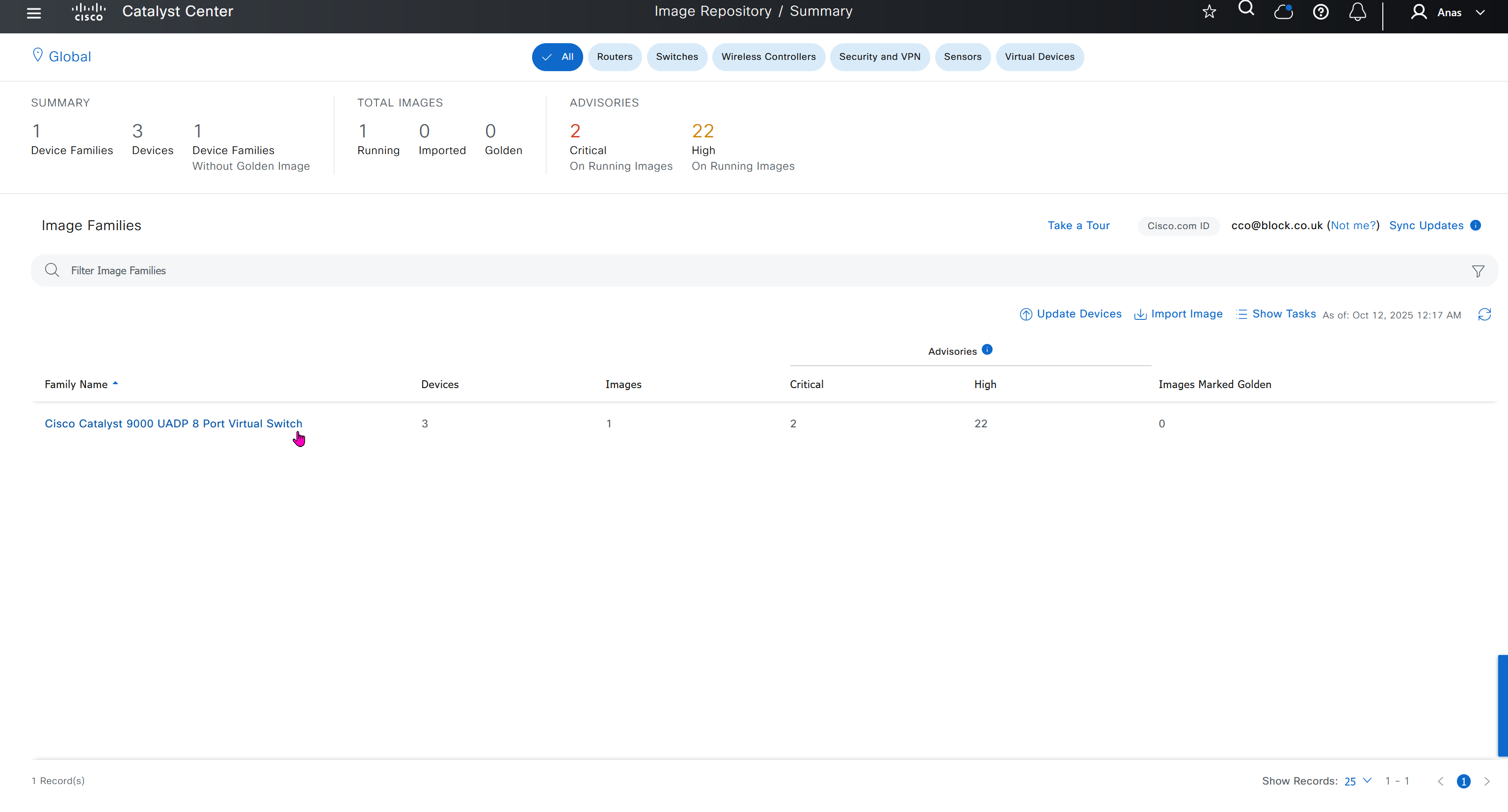
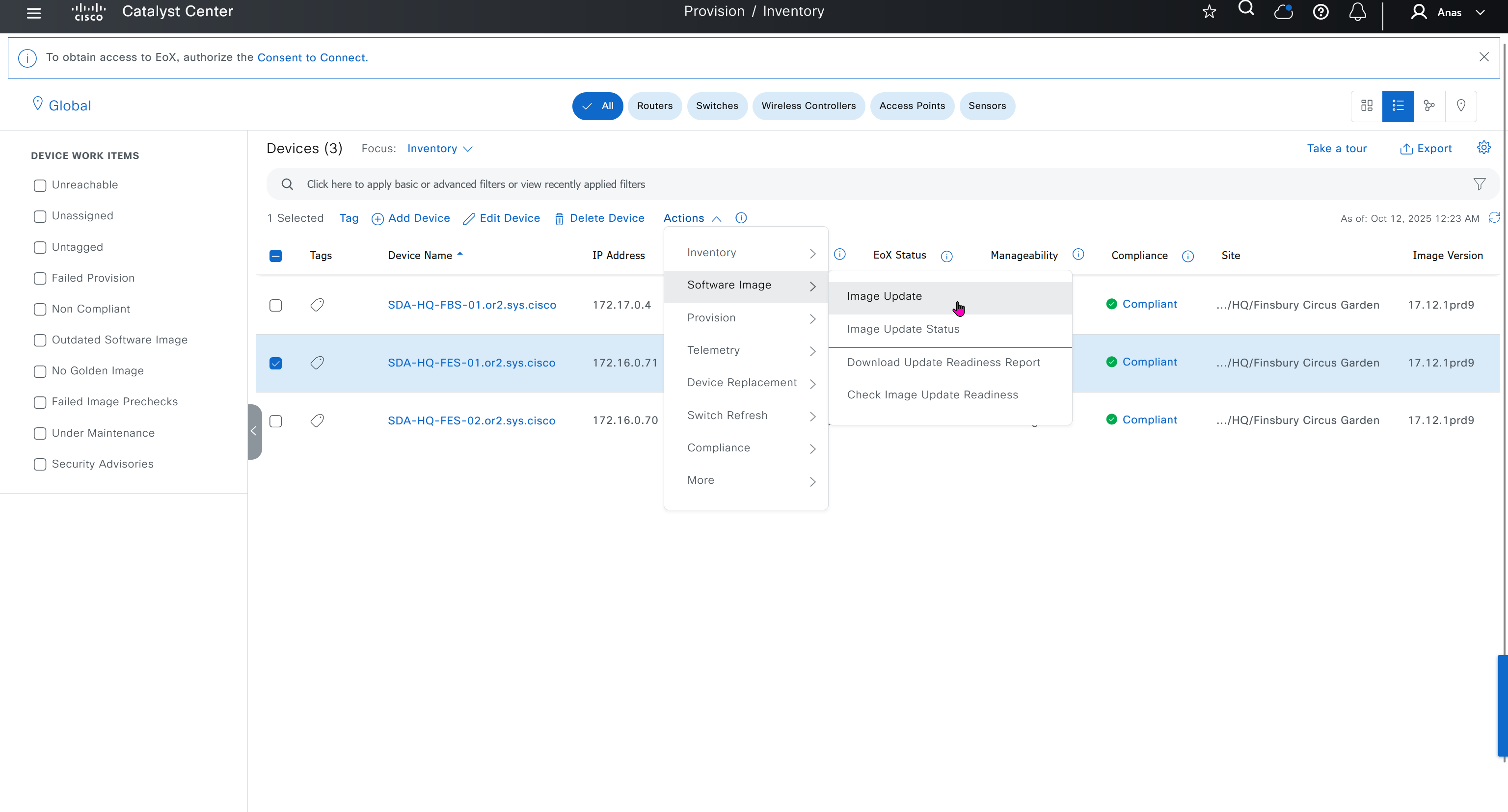





you can only start tagging devices one you have uploaded the image, because we have virtual C9Kv images there is no .bin or .smu images available for them, from ths point on we will have screenshots from lab minutes
One image can be marked as golden image per device type either at the global level or at the site level, then any device that is not running that golden image will be marked as out of compliance
DNAC also supports auto clean up where it cleans up older image files
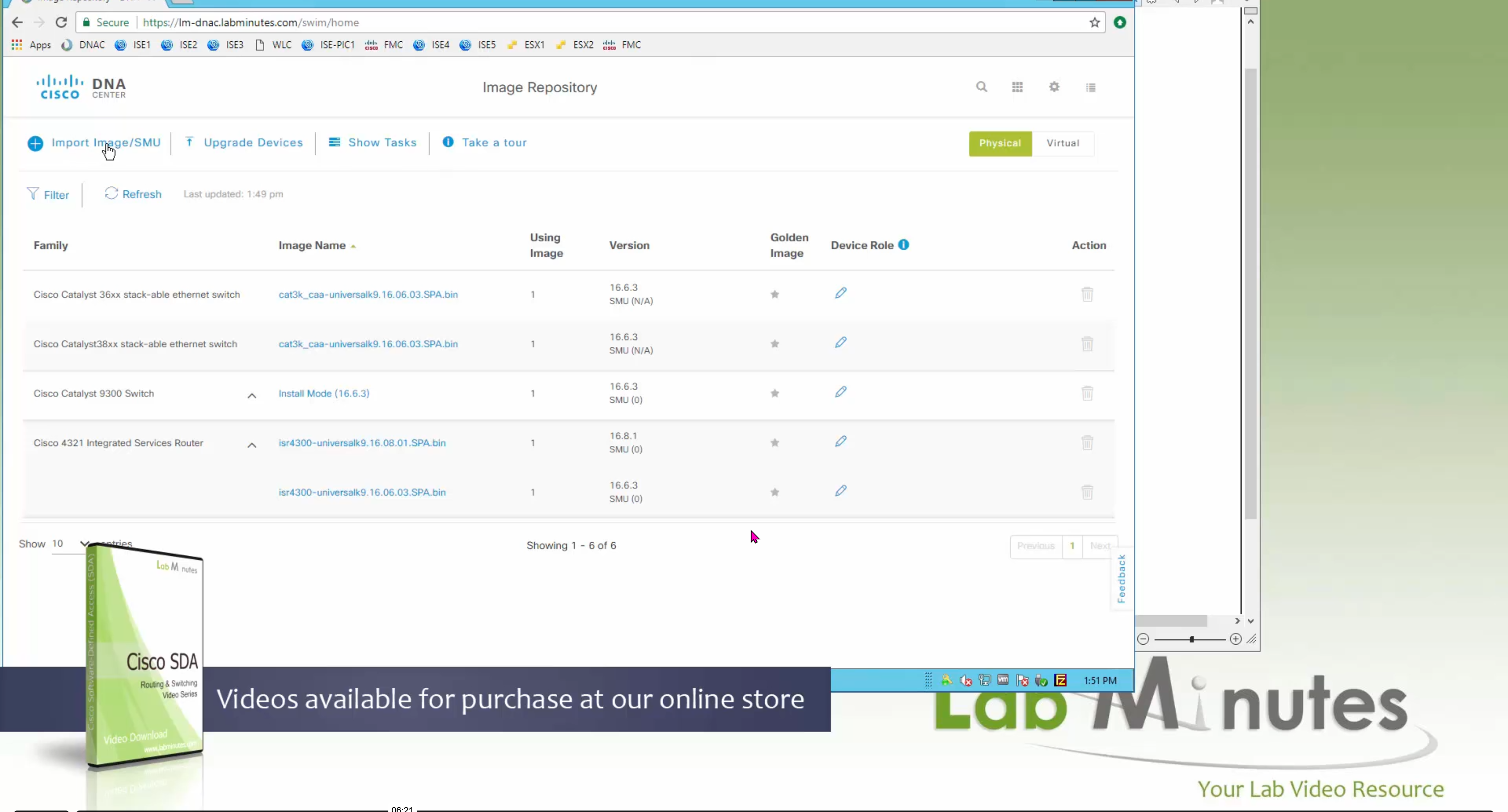
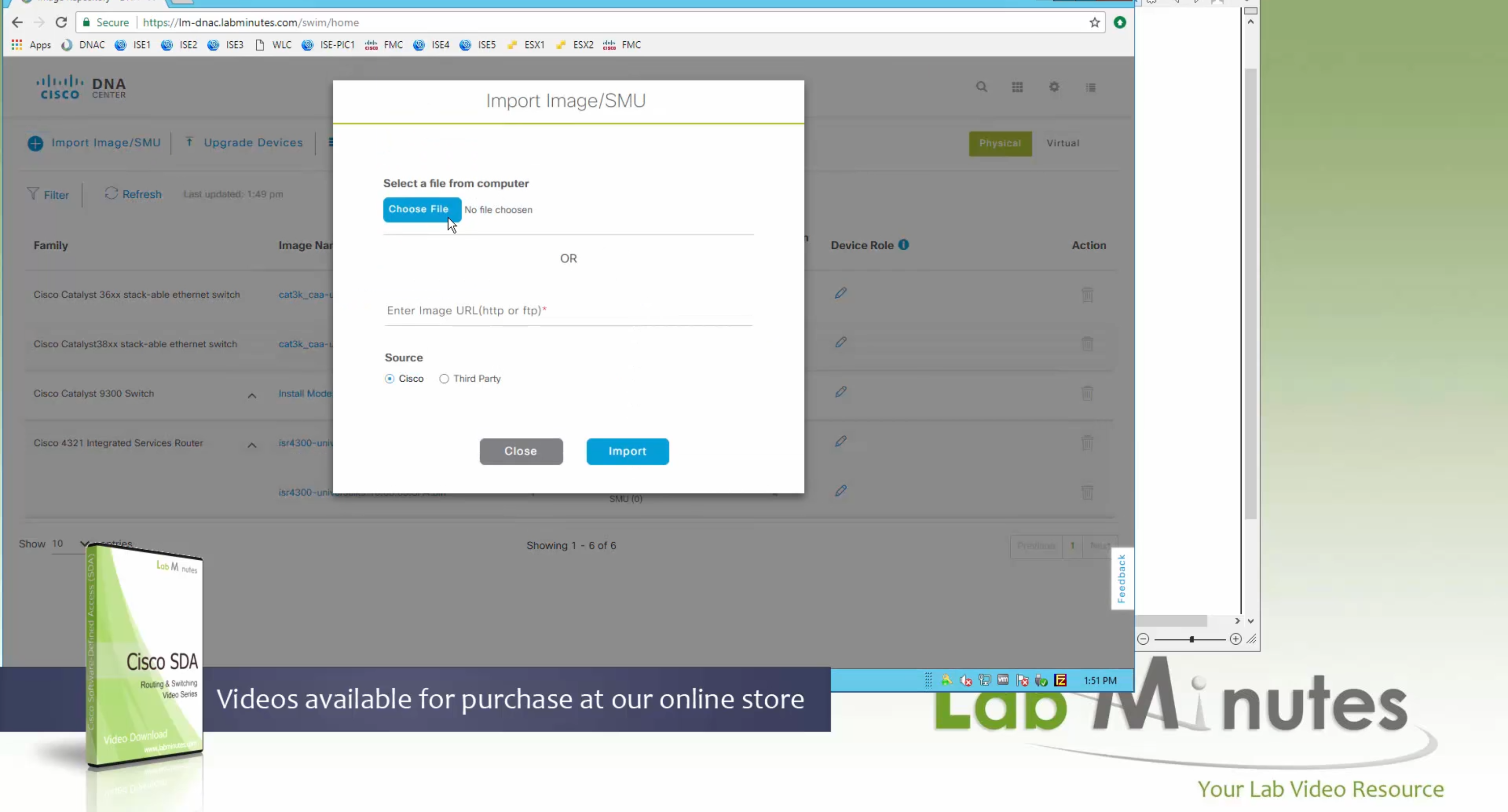
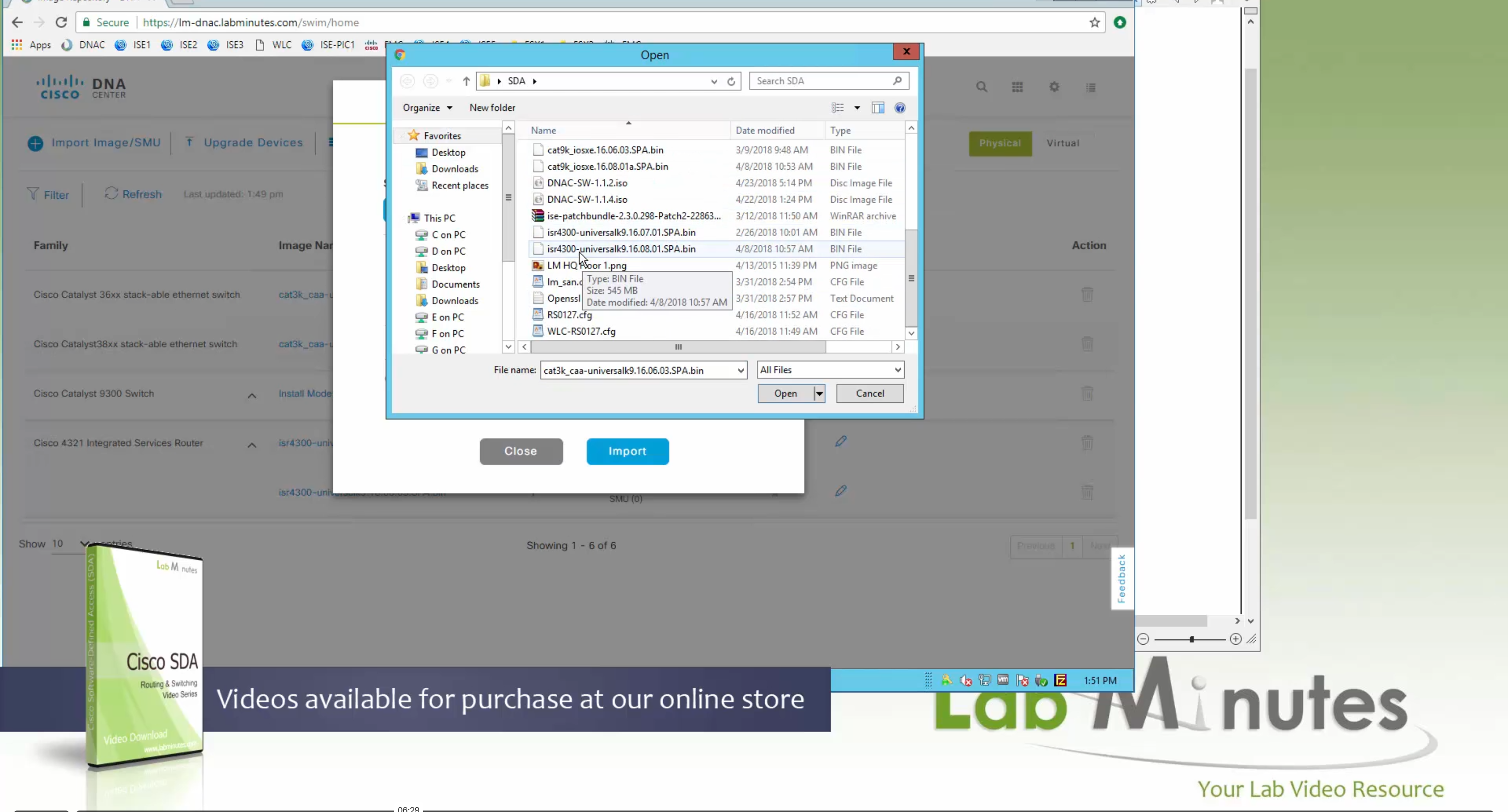
Using image column and version column with (Latest) means that these are the latest images, these images with (Latest) are being displayed from cisco.com and we can click on star icon to make them golden image
Making image golden enforces that image on that hardware model
Same thing can be repeated for different chassis or hardware types, their recommended Latest images can be marked as golden images
bundle mode images can be pulled from device and made golen image while for install mode we cannot pull from device and mark the image as golden image, instead we can either download from Cisco.com using gui or import image from file

Small “Verified” shows up next to image that shows that DNAC has downloaded the image, clicking that image makes it golden pretty fast because image is already on the DNAC server




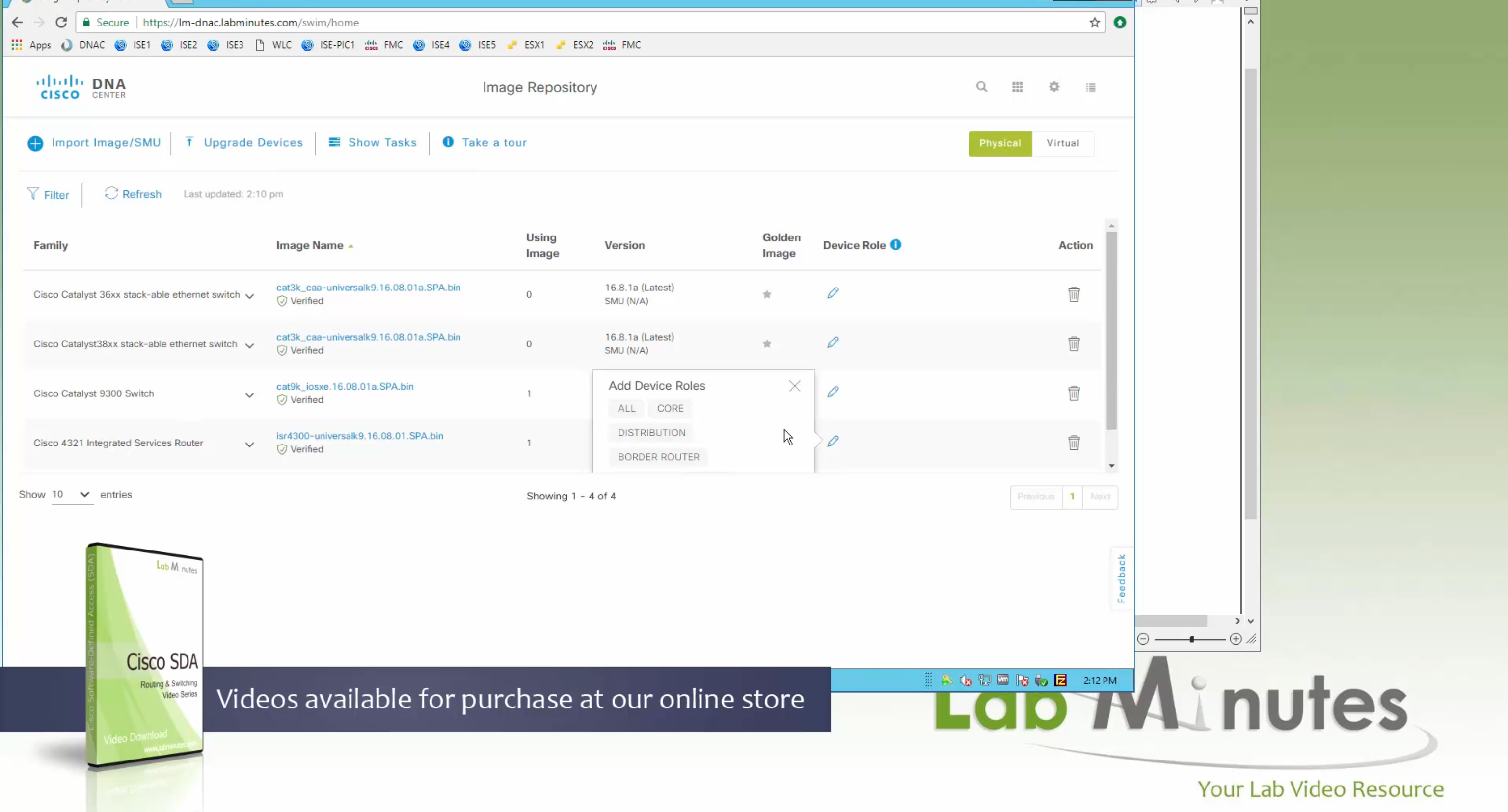
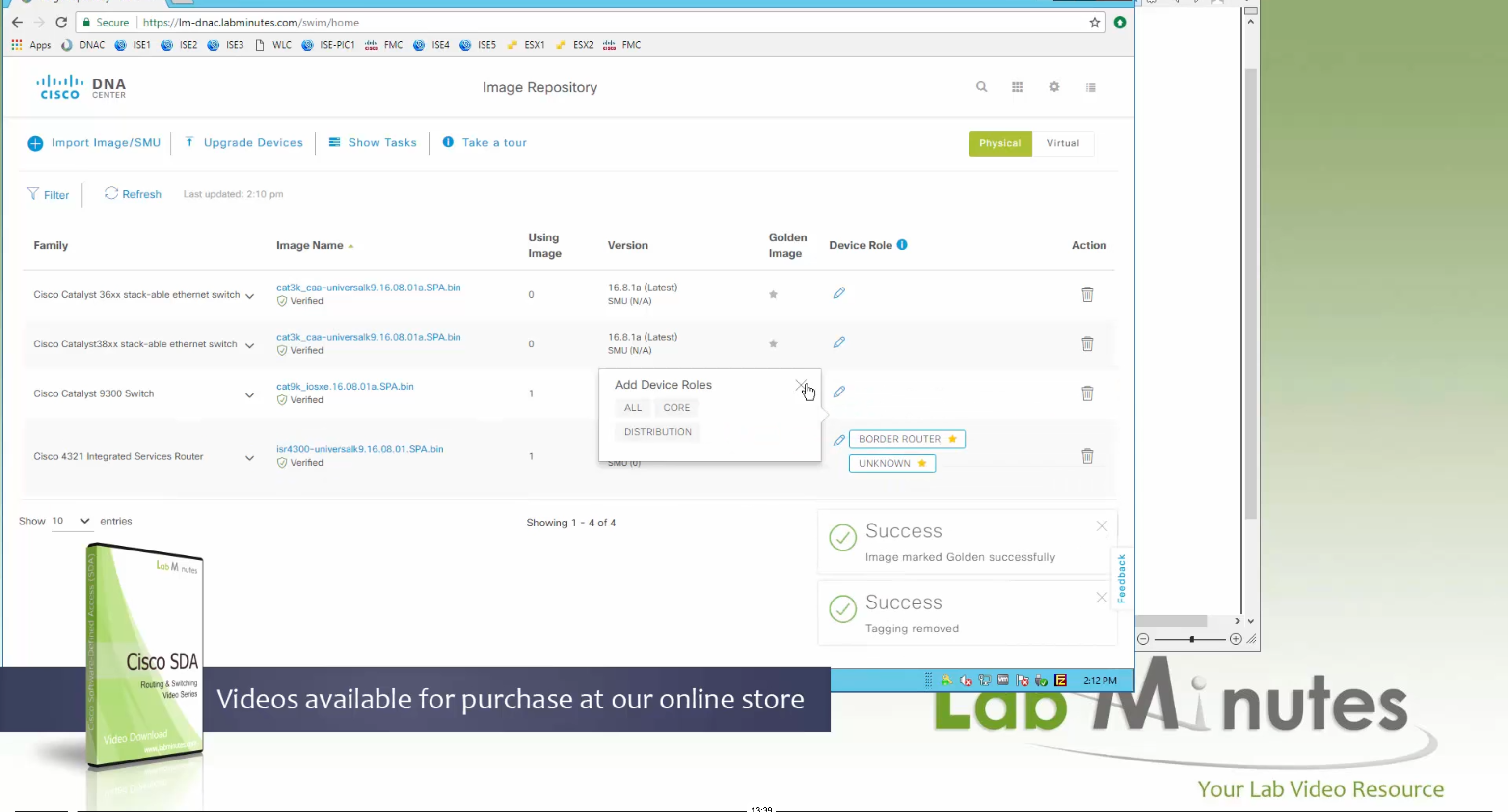

Now making an image golden makes it same for all devices of same hardware model same across different “Roles” and all locations (Globally) and sometimes you may not want that, you can click on edit icon in device role column and set golden image per hardware model per device role, such as all “C9300” / “Access” to have a specific image or you can even have golden image per hardware model per role per location – but first you must remove the golden image from global level and then set it on site level, there is no concept of override here, either set at global level or set at all sites independently
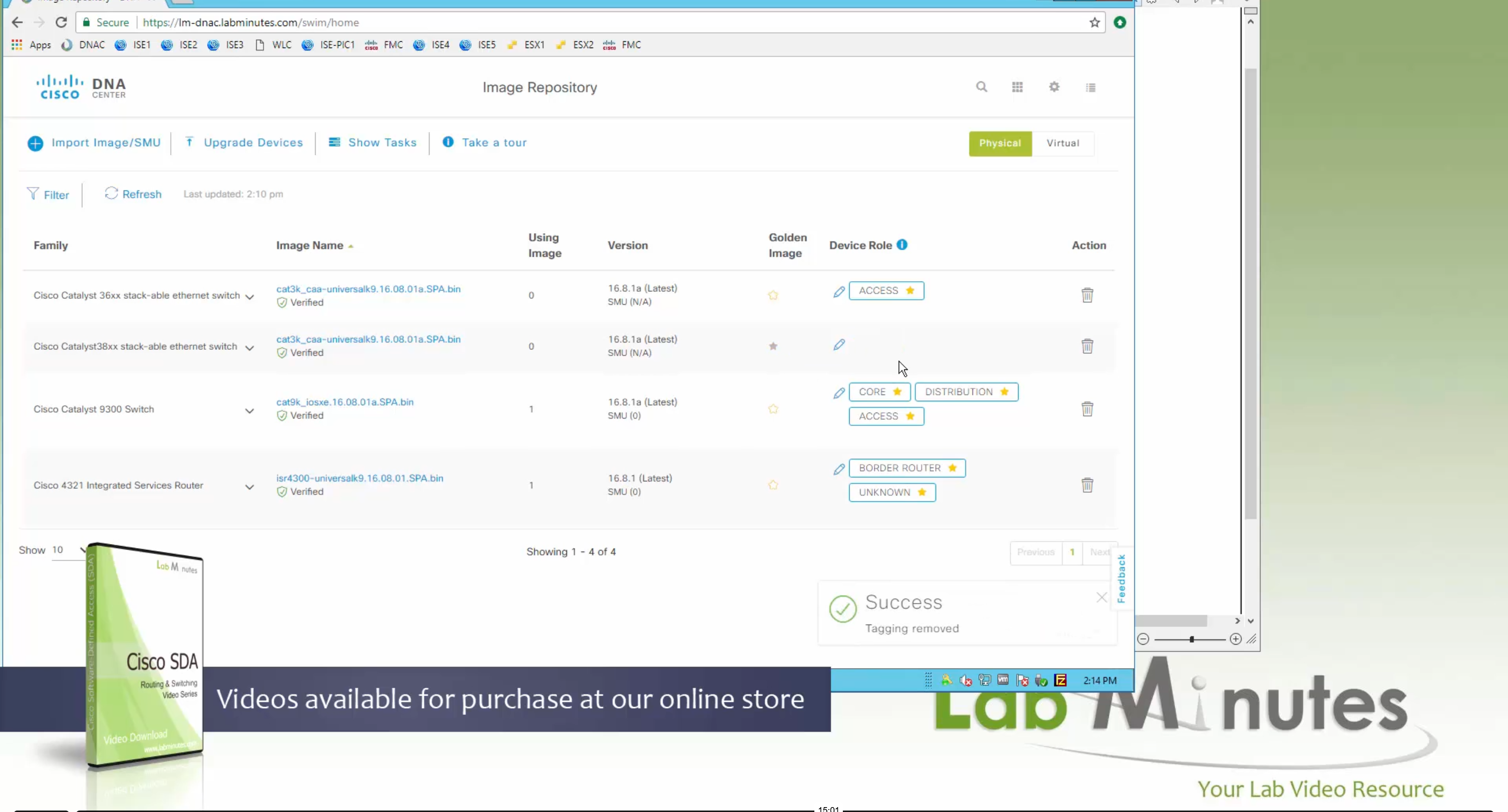




Next step is to see which devices are not in compliance and upgrade them in provision > OS image column


DNAC validates Flash, RAM and Reboot required




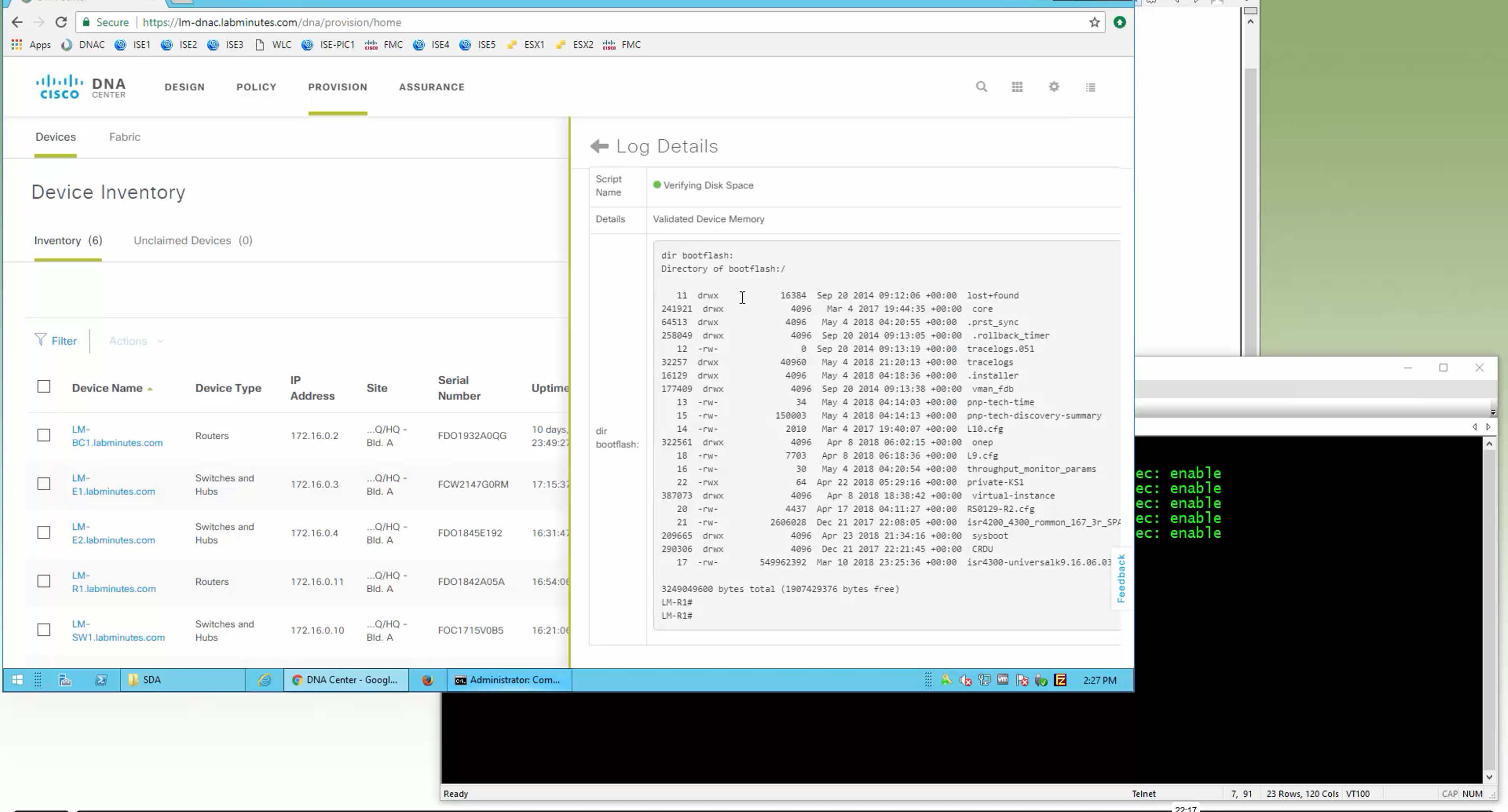
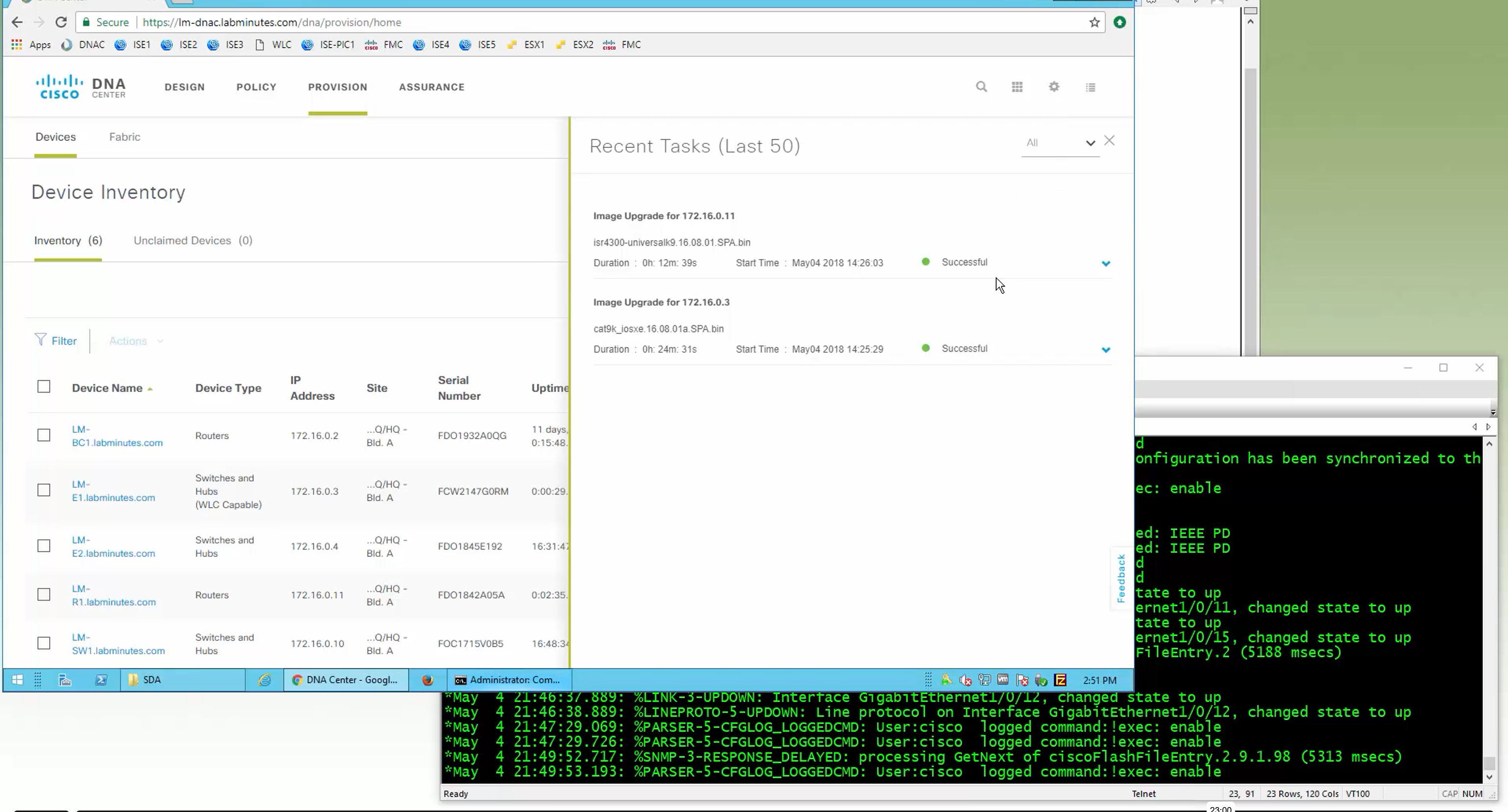
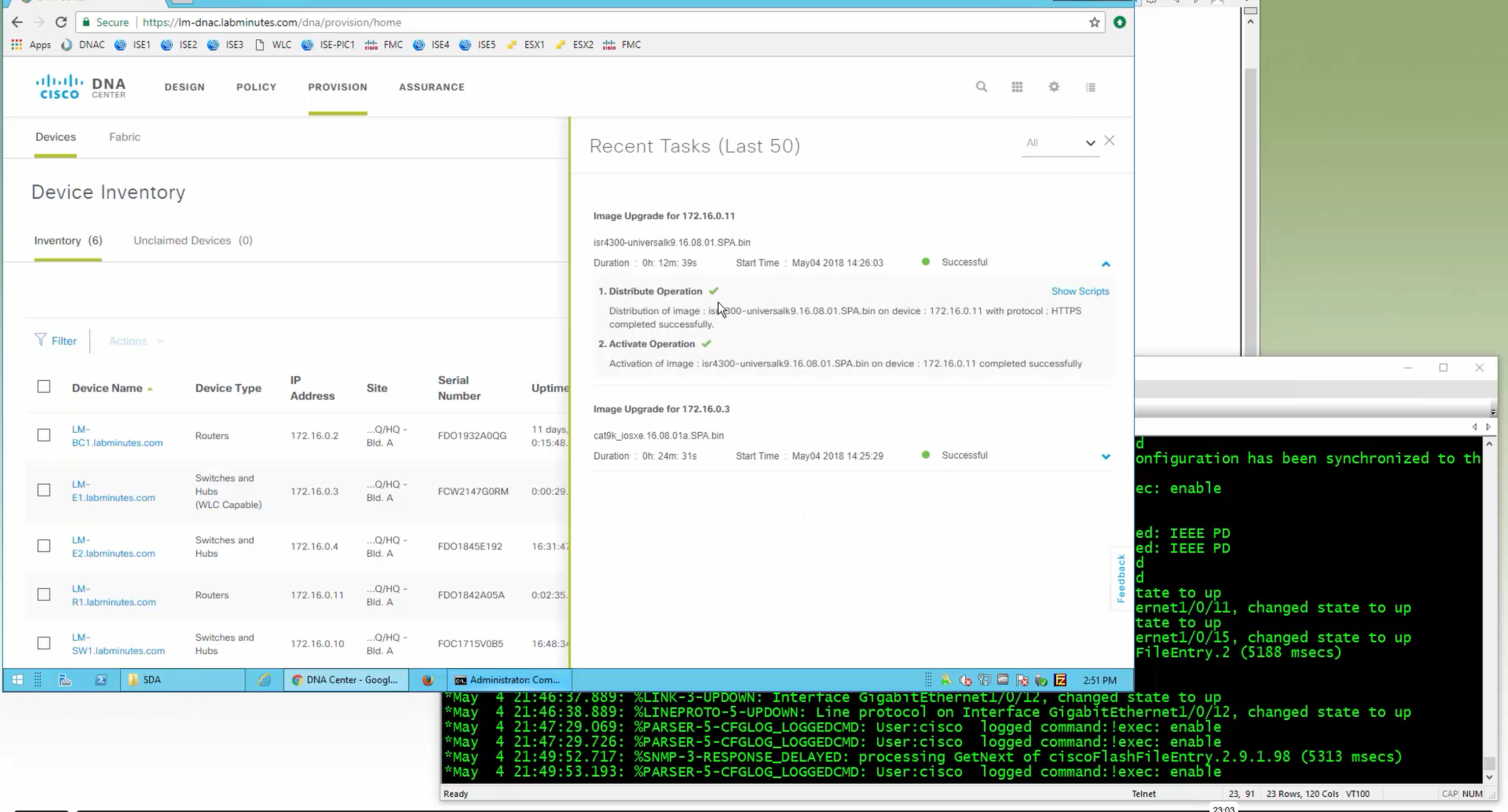

SMU(0) means that there is no SMU for this image version

one big improvement in version 2.1 is that you can download image from local server instead of DNAC over the WAN
“Provision > provision device” pushes the remaining config as config assigned during assignment of device to site is not full config, full config is deployed when device is provisioned
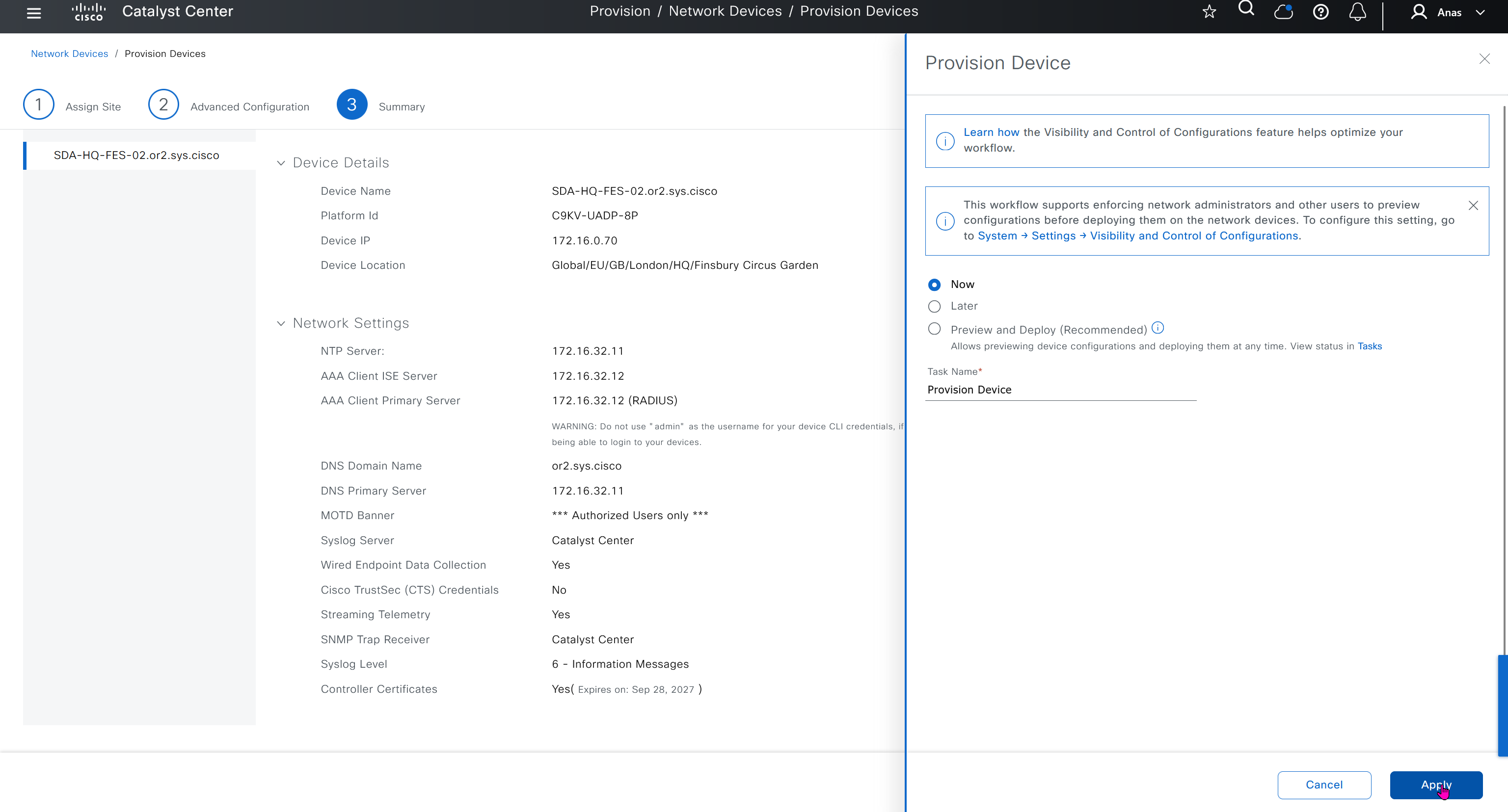

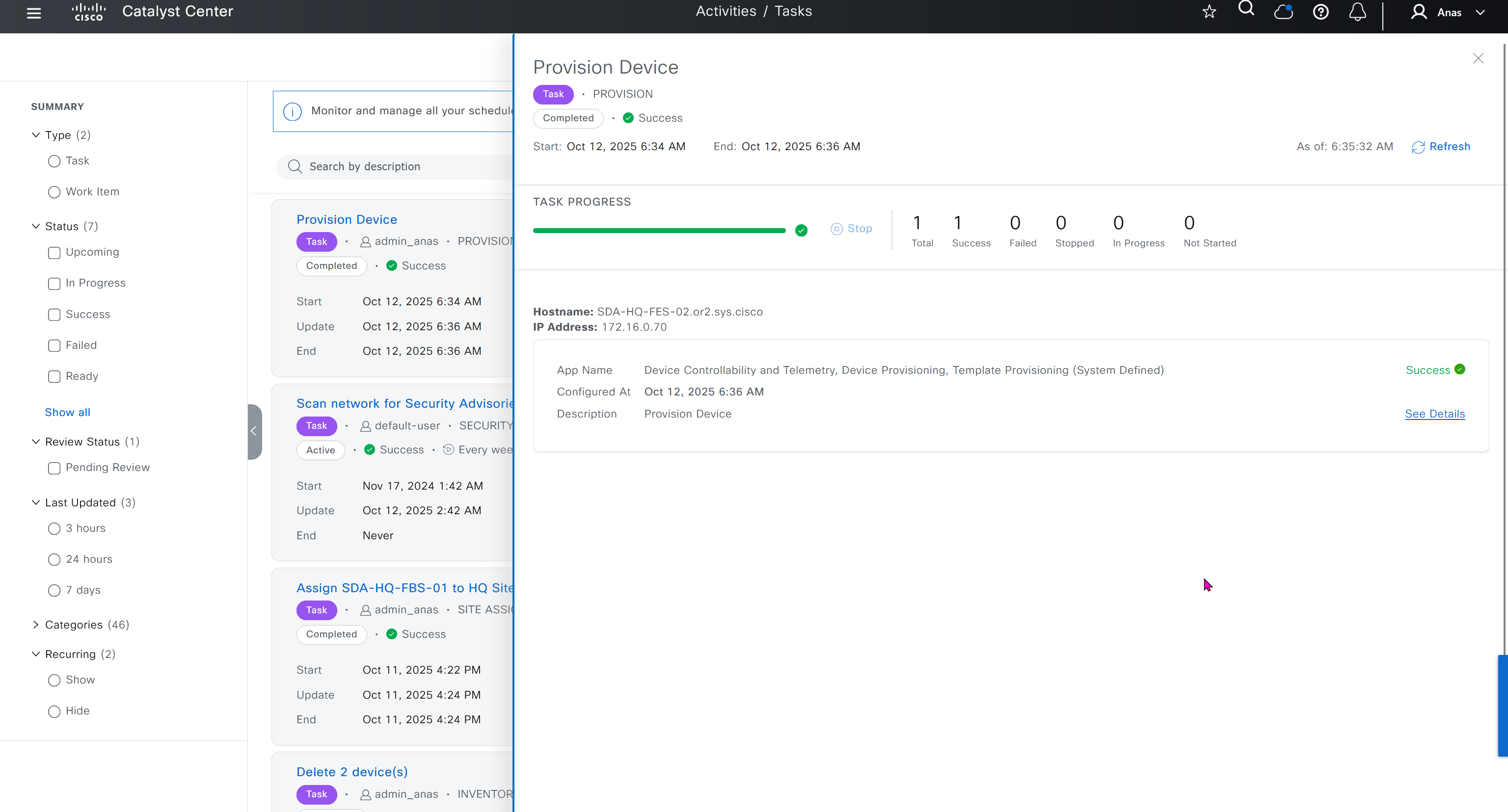
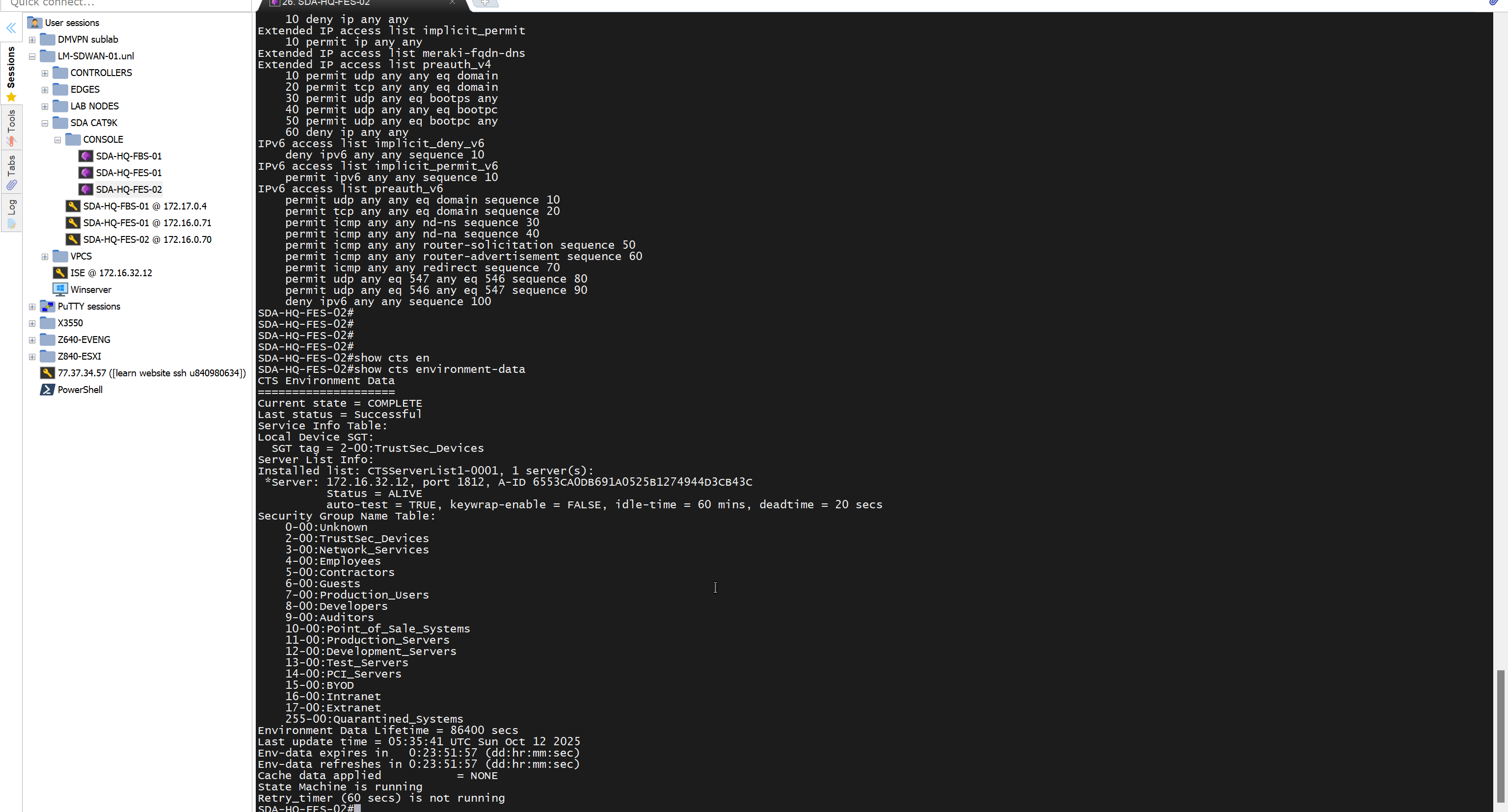
Mark for replacement is when we have to RMA the device
Compliance > Run Compliance, this is manual trigger of the compliance and checks if device has golden image and if startup-config is same running-config etc
As devices are discovered in DNAC, it is also added in ISE

In ISE live logs we can see entries for devices authenticating to ISE for Trust Sec Device authentication
next post
BGP
BGP
AS autonomous system, collection of router under a domain
An organization requiring connectivity to the Internet must obtain an ASN.
ASNs were originally 2 bytes (in the 16-bit range), 65,534 ASNs.
Due to exhaustion, ASN field expanded to accommodate 4 bytes (in the 32-bit range), This allows for 4,294,967,295 unique ASNs
https://ipwithease.com/basic-understanding-of-4-byte-asn/
Private ASN 16-bit range as 64512 to 65534
Public ASN 16-bit range 1 through 64511
Private ASN 32-bit range as 4200000000 to 4294967294
in 4 bytes ASN 0 – 65535 AS numbers are same as they were with 2 byte AS. These AS numbers help in interoperability between AS using 2 byte ASNs and AS using 4 byte ASNs.
4 Byte AS representation can be done in 3 ways as listed below:
- asplain – simple decimal representation of the ASN. For example, ASN 7747 will be represented as 7747, while 123456 will be represented as 123456.
- asdot+ – breaks the number up in two 16-bit values as low-order and high-order, separated by a dot. All the 2-byte ASNs can be represented in the low-order value. For example, ASN 65535 will be 0.65535, 65536 will be 1.0, 65537 will be 1.1 and so on. The last ASN 4294967296 will be 65535.65535.
- asdot – it is a mixture of asplain and asdot+. Any ASN in the 2-byte range is represented as asplain and any ASN above the 2-byte range is represented as asdot+. For example, 65535 will be 65535 while 65536 will be 1.0. Cisco uses this form of implementation.
It is significant to understand the interoperability of the 2 Byte AS number with the 4 Byte AS number.
4 byte AS support is advertised via BGP capability negotiation. Speakers who support 4-byte AS are known as New-BGP speakers & those who do not are known as Old-BGP speakers, it includes its 4-byte ASN in the Capability advertisement
No support / backwards compatibility scenario
If one neighbor or router is very old and it does not respond to 4-byte ASN capability, in this case new BGP speaker can bring up session with this very old router using a reserved 2 byte ASN called AS_TRANS (AS23456)
Because AS_TRANS AS23456 is reserved, no Old-BGP speaker can use it as its own ASN; only New-BGP speakers can use it.
New BGP Speaker to new BGP Speaker advertise routes using 4 byte ASN but new BGP Speaker to old BGP speaker
AS_PATH
- Any 4-byte ASN in the AS_PATH is replaced with AS_TRANS (23456) so the old router can “parse” it.
AS4_PATH (optional transitive attribute)
- The real 4-byte ASNs are preserved in the AS4_PATH attribute.
- Old routers ignore AS4_PATH.
- New routers later reconstruct the correct AS_PATH using AS4_PATH.
When an Old BGP Speaker advertises routes with AS4_PATH and AS_PATH attributes to a New BGP Speaker, the New BGP Speaker uses both attributes to reconstruct the path: AS4_PATH for 4-byte ASNs and AS_PATH for 2-byte ASNs by replacing 4-byte ASN with an AS_TRANS. In this way, the AS_PATH shows the correct number of hops
AS4_AGGREGATOR
A new attribute AS4_AGGREGATOR is introduced for similar reasons. If the New BGP Speaker has to send the AGGREGATOR attribute towards old speaker neighbor and if the aggregating ASN is a 4-byte ASN, then the speaker constructs the AS4_AGGREGATOR attributes by copying the attribute length and attribute value from the AGGREGATOR attribute, places the attribute length and attribute value in the AS4_AGGREGATOR attribute, and replaces the 4-byte ASN with AS_TRANS ASN.
BGP Peering
BGP peering is also called BGP session
There 2 types of peering,
iBGP peering and eBGP peering
ibgp can be like pseudowires
iBGP: Sessions established with a router that are in the same AS or that participate in the same BGP confederation
eBGP: Sessions established with a BGP router that are in a different AS
BGP does not use hello packets to discover neighbors
BGP was designed as an inter-autonomous routing protocol, implying that neighbor adjacencies should not change frequently and are coordinated.
BGP uses TCP port 179 to communicate with other routers
Relying on TCP allows for handling of fragmentation, sequencing, and reliability (acknowledgment and retransmission)
Most recent implementations of BGP set the do-not-fragment (DF) bit to prevent fragmentation and rely on path MTU discovery PMTUD https://learn.anasather.uk/ccie-misc/ccie-everything-else/
Multihop BGP peerings
BGP uses TCP that can cross boundaries unlike IGP which use link local multicast to form neighbors, BGP can form neighbor adjacencies that are directly connected or adjacencies that are multiple hops away.
BGP neighbors connected to the same network use the ARP table to locate the IP address of the peer.
Multi-hop BGP sessions require routing table information for finding the IP address of the peer.
A default route is not sufficient to establish a multi-hop BGP session.
Multi-hop sessions require that the router use an underlying route installed in the RIB (static or from any routing protocol) to establish the TCP session with the remote endpoint
If that neighbor’s IP isn’t specifically resolvable in the routing table (e.g., via a static route or an IGP-learned route), BGP won’t even attempt to start the TCP connection.
BGP Messages
OUNK
| Type | Name | Functional Overview |
|---|---|---|
| 1 | OPEN | Sets up and establishes BGP adjacency |
| 2 | UPDATE | Advertises, updates, or withdraws routes, CRUD |
| 3 | NOTIFICATION | Indicates an error condition to a BGP neighbor |
| 4 | KEEPALIVE | Ensures that BGP neighbors are still alive |
OPEN
OPEN message is used to establish adjacency,
Session capabilities are exchanged in open messages.
OPEN message contains following:
BGP version
ASN
Hold time
RID etc
Hold time: The hold time field in OPEN messages sets hold timer in seconds,
When establishing a BGP session, the routers use the smaller hold time value between the two routers.
The hold time value must be at least 3 seconds,
the hold time is set to 0 to disable KEEPALIVE messages.
For Cisco routers, the default hold time is 180 seconds.
BGP identifier RID: The BGP router ID (RID) is a 32-bit unique number that identifies the BGP router in the advertised prefixes.
The RID is used as a loop-prevention mechanism for routers advertised within an autonomous system.
The RID can be set manually or dynamically for BGP, setting manually is much stable way.
A nonzero value must be set in order for routers to become neighbors.
Dynamic RID allocation logic uses the highest IP address of any up loopback interfaces. If there is not an up loopback interface, then the highest IP address of any active up interfaces becomes the RID
To ensure that the RID does not change, a static RID is assigned (typically represented as an IPv4 address that resides on the router, such as a loopback address). Any IPv4 address can be used, including IP addresses not configured on the router
KEEPALIVE
KEEPALIVE messages are exchanged between neighbors, by default every 60 seconds, “3rd of the default Hold timer 180” seconds
If the hold time is set to 0, no KEEPALIVE messages are also sent between the BGP neighbors.
BGP keepalive timer and hold timer can be set at the process level or per neighbor session.
UPDATE
An Update can either advertise routes or withdraw routes
Prefixes that need to be withdrawn are advertised in the WITHDRAWN ROUTES field of the UPDATE message
Update message also serves as a keepalive as well,
Upon receipt of an UPDATE or KEEPALIVE, the hold timer resets to the initial value,
If the hold timer reaches zero, the BGP session is torn down, routes from that neighbor are removed, and an appropriate update route withdraw message is sent to other BGP neighbors for the affected prefixes
Notification
A Notification message is sent when an error is detected with the BGP session,
such as a hold timer expiring,
neighbor capabilities changing,
or a BGP session reset being requested.
Notification causes the BGP connection to close.
Notification message is basically a signal to neighbor to initiate session shutdown
BGP Neighbor States
BGP FSM
- Idle
- Connect
- Active
- OpenSent
- OpenConfirm
- Established
Idle
-BGP Process start
-BGP Process starts listening on TCP 179
-BGP tries to move to next state: connect
-In case any issues revert it back to idle – set ConnectRetry timer to 60 seconds, this time must count to 0 before any connection try can be made – ConnectRetry basically a delay timer
-Further failures to leave the Idle state result in the ConnectRetry timer doubling in length
Connect
-BGP initiates the TCP connection 3 way handshake
-If the TCP connection fails, the state changes to Active
-If the three-way TCP handshake completes,
-sends the OPEN message to the neighbor,
-moves to the OpenSent state
R1# show tcp brief
TCB Local Address Foreign Address (state)
F6F84258 10.12.1.1.179 10.12.1.2.59884 ESTAB
R2# show tcp brief
TCB Local Address Foreign Address (state)
EF153B88 10.12.1.2.59884 10.12.1.1.179 ESTABActive
-In the Active state, BGP starts a new three-way TCP handshake.
-If this attempt for TCP connection fails, the state moves back or downgrades to the Connect state
-If a connection is established,
-an OPEN message is sent,
-the hold timer is set to 4 minutes (longer hold time because of issues and hence Active state, longer hold time means that neighbor’s presence will not be checked quicker)
-and the state moves to OpenSent.
OpenSent
-OPEN message has been sent from the originating router and is awaiting an OPEN message from the other router.
-When the originating router receives the OPEN message from the other router, local OPEN and received OPEN message are checked for following:
-BGP versions must match
-The source IP address of the OPEN message must match what is configured for the neighbor
-The AS number must match what is configured for the neighbor
-RID must be unique
-Security parameters (such as password and time-to-live [TTL]) must qualify.
Hold times are compared, lowest hold time is used
Keepalive is sent
Connection state is then moved to OpenConfirm
If an error is found in the OPEN message, a NOTIFICATION message is sent, and the state is moved back to Idle.
OpenConfirm
In OpenConfirm state, BGP waits for a KEEPALIVE or NOTIFICATION message – so 2 way can be confirmed
Upon receipt of a neighbor’s KEEPALIVE, the state is moved to Established
If
-hold timer expires,
-a stop event occurs,
-a NOTIFICATION message is received
the state is moved to Idle
Established
BGP session is established
BGP neighbors exchange routes through UPDATE messages. As UPDATE and KEEPALIVE messages are received, the hold timer is reset.
If the hold timer expires, BGP moves the neighbor back to the Idle state and send a withdraw to other neighbors for routes learned through the now idle neighbor
BGP PA
BGP associates attributes with each network path / route and it is called its Path Attributes, which can also be considered as qualities of the path, such as AS Path shows the length of path and ASs the traffic will traverse, metric is cost associated with path – tells us about the thinking of admin assigning initial cost , weight to the path
These Path Attributes are of 4 different types:
Well-known mandatory
Well known man
Well-known attributes must be recognized by all BGP implementations – because it is well known and known by every BGP module that is written
Mandatory as well – mandatory attributes must be included with every prefix advertisement;
Well-known discretionary
well-known discretionary attributes may or may not be included with the prefix advertisement and can be skipped in sending of an update
Optional transitive
Optional attributes do not have to be recognized by all BGP implementations – BGP module writers can fully skip it as it is optional
Optional attributes can be transitive and stay with the route advertisement from AS to AS
Optional non-transitive
Some optional PAs are non-transitive and cannot be shared from AS to AS.
AS_PATH for Loop Prevention
AS_Path is used as a loop-prevention mechanism in BGP
BGP is a path vector routing protocol and does not contain a complete topology of the network, as do link-state routing protocols, BGP behaves like distance vector protocols
The BGP attribute AS_Path is a “well-known mandatory” attribute and includes a complete list of all the ASNs that the prefix advertisement has traversed from its source AS
“If a BGP router receives a prefix advertisement with its AS listed in AS_Path, it discards the prefix because the router thinks the advertisement forms a loop“
Multi-Protocol BGP (MP-BGP)
Originally BGP was designed around IPv4 but later on Multi-Protocol BGP (MP-BGP) allowed other protocols to be carried as well and that allowed BGP to carry (Address Family) AFI such as IPv6
An address family correlates to a specific network protocol, such as IPv4 or IPv6, and additional granularity is provided through a subsequent address family identifier (SAFI), such as unicast or multicast in that protocol
Multiprotocol BGP (MP-BGP) carries separate path attributes (PAs) for Multi protocol MP_REACH_NLRI and MP_UNREACH_NLRI than IPv4 based BGP, These PA attributes are held inside BGP update messages and that is why BGP can be used for different address families or protocols, that facilitates addresses just like IPv4 , IPv6 , Multicast and even MAC addresses. Address family maintains a separate database and configuration for each protocol under same BGP session.
Address family needs to be activated on peer
An address family must be activated for a BGP peer in order for BGP to initiate a session with that peer
IOS XE activates the IPv4 address family by default. This simplifies the configuration in an IPv4 environment, command no bgp default ipv4-unicast disables the automatic activation of the IPv4 AFI
Multiple Address families per neighbor
BGP Session parameters are configured such as neighbor IP , ASN , authentication , keepalive timers , source IP etc
but address family related configuration such as Network commands and summarization occur within the address family because IPv4 unicast and IPv6 multicast cannot have same configuration, although these 2 different AFI and SAFI can belong to same neighbor
Specifying the source interface
neighbor x.x.x.x update-source <interface> only changes the source IP address used in BGP packets. It does not change the actual outgoing interface used to send the packets. Outgoing interface can only be changed or dictated with static or dynamic route for that neighbor
BGP Authentication
BGP supports authentication with MD5 in order to prevent manipulation of BGP packets
BGP Configuration
R1 (Default IPv4 Address-Family Enabled)
router bgp 65100
neighbor 10.12.1.2 remote-as 65200
neighbor 10.12.1.2 password CISCOBGP
neighbor 10.12.1.2 timers 10 40R2 (Default IPv4 Address-Family Disabled)
router bgp 65200
no bgp default ipv4-unicast
neighbor 10.12.1.1 remote-as 65100
neighbor 10.12.1.1 password CISCOBGP
neighbor 10.12.1.1 timers 15 50
!
address-family ipv4
neighbor 10.12.1.1 activateUse show commands with AFI and SAFI
R1# show bgp ipv4 unicast summary
BGP router identifier 192.168.1.1, local AS number 65100
BGP table version is 1, main routing table version 1
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.12.1.2 4 65200 8 9 1 0 0 00:05:23 0
| | | |
| | | |
Number of messages received from peer and queued to be processed
| | |
| | |
Number of messages queued to be sent to the peer
| |
| |
Length of time the BGP session is established
|
|
Current BGP peer state or the number of prefixes received from the peerUp/Down column indicates that the BGP session is up for over 5 minutes.
R2# show bgp ipv4 unicast neighbors 10.12.1.1
! Output omitted for brevity
! The first section provides the neighbor's IP address, remote-as, indicates if
! the neighbor is 'internal' or 'external', the neighbor's BGP version, RID,
! session state, and timers.
BGP neighbor is 10.12.1.1, remote AS65100, external link
BGP version 4, remote router ID 192.168.1.1
BGP state = Established, up for 00:01:04
Last read 00:00:10, last write 00:00:09, hold is 40, keepalive is 13 seconds
Neighbor sessions:
1 active, is not multisession capable (disabled)
! This second section indicates the capabilities of the BGP neighbor and
! address-families configured on the neighbor.
Neighbor capabilities:
Route refresh: advertised and received(new)
Four-octets ASN Capability: advertised and received <<<
Address family IPv4 Unicast: advertised and received <<<
Enhanced Refresh Capability: advertised <<<
Multisession Capability:
Stateful switchover support enabled: NO for session 1 <<<
Message statistics:
InQ depth is 0
OutQ depth is 0
! This section provides a list of the BGP packet types that have been received
! or sent to the neighbor router.
Sent Rcvd
Opens: 1 1
Notifications: 0 0
Updates: 0 0
Keepalives: 2 2
Route Refresh: 0 0
Total: 4 3
Default minimum time between advertisement runs is 0 seconds
! This section provides the BGP table version of the IPv4 Unicast address-
! family. The table version is not a 1-to-1 correlation with routes as multiple
! route change can occur during a revision change. Notice the Prefix Activity
! columns in this section.
For address family: IPv4 Unicast
Session: 10.12.1.1
BGP table version 1, neighbor version 1/0
Output queue size : 0
Index 1, Advertise bit 0
Sent Rcvd
Prefix activity: ---- ----
Prefixes Current: 0 0
Prefixes Total: 0 0
Implicit Withdraw: 0 0
Explicit Withdraw: 0 0
Used as bestpath: n/a 0
Used as multipath: n/a 0
Outbound Inbound
Local Policy Denied Prefixes: -------- ------- <<<
Total: 0 0
Number of NLRIs in the update sent: max 0, min 0
! This section indicates that a valid route exists in the RIB to the BGP peer IP
! address, provides the number of times that the connection has established and
! time dropped, since the last reset, the reason for the reset, if path-mtu-
! discovery is enabled, and ports used for the BGP session.
Address tracking is enabled, the RIB does have a route to 10.12.1.1 <<<
Connections established 2; dropped 1
Last reset 00:01:40, due to Peer closed the session <<<
Transport(tcp) path-mtu-discovery is enabled <<<
Connection state is ESTAB, I/O status: 1, unread input bytes: 0
Minimum incoming TTL 0, Outgoing TTL 255 <<<
Local host: 10.12.1.2, Local port: 179
Foreign host: 10.12.1.1, Foreign port: 56824BGP Adj tables
BGP uses three tables for maintaining the network paths and path attributes (PAs)
There are 3 different ways of learning a route
-Network command
-Learned from neighbor
-Redistribution into BGP
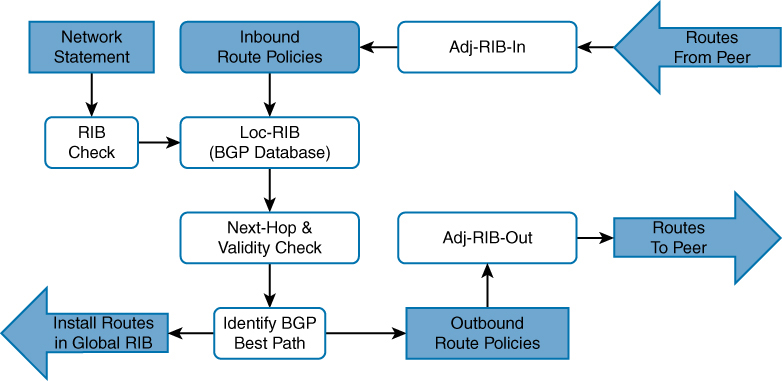
Adj-RIB-in: Contains the routes in original form (that is, from before inbound route policies were processed). The table is purgeable and is purged after all route policies are processed to save memory. After all routes have been fed through local policies it is emptied out
Loc-RIB:
-Loc-RIB contains routes after applying import policy, import policy only applies to routes learned from neighbors) Routes injected with the network command or redistributed – do not go through inbound policy – Locally-originated routes do go through best-path selection, but not through inbound policy + when a route comes from network statement then RIB check is made and only added in loc-RIB if there is same route with same subnet mask in RIB or routing table
-Routes collected in Loc-RIB are not the best routes and hence can contain multiple routes to a prefix
-contains routes that are originated locally and learned from neighbors.
-this table is “show ip bgp”
-after storing the routes here a validity check is performed, next-hop address in route if resolvable in the RIB then route is valid – and route is marked valid ” * “
-after valid routes are determined, these routes are passed through BGP best path algorithm and best routes is selected for “a prefix” and marked best with ” > ” – creating symbol of ” *> ” (valid + best)
Star means valid and not best
> means best
-Install the best-path route into the RIB
-After you enter a BGP network statement, the BGP process searches the global RIB for an exact network match. The network can be a connected network, a secondary connected network, or any route from a routing protocol.
-After verifying that the network statement matches a route in the RIB, the prefix is installed into the Loc-RIB table. As the BGP prefix is installed into the Loc-RIB, the following BGP PAs are set, depending on the RIB prefix type:
Connected network: The next-hop BGP attribute is set to 0.0.0.0, the BGP Origin attribute is set to i (for IGP), and the BGP weight is set to 32,768.
Static route or routing protocol: The next-hop BGP attribute is set to the next-hop IP address in the RIB, the BGP Origin attribute is set to i (for IGP), the BGP weight is set to 32,768, and the multi-exit discriminator (MED) is set to the IGP metric.
Remember best from > symbol, which means use this > route
Adj-RIB-out: Contains the routes after outbound route policies have been processed
This is a per neighbor table
By default, BGP only advertises the best path to other BGP peers
Advertise the route to BGP peers. If the route’s next-hop BGP PA is 0.0.0.0, the next-hop address is changed to the IP address of the BGP session.
It enables a network engineer to view routes advertised to a specific router using command show bgp afi safi neighbors ip-address advertised-routesMultiple BGP route sources
R1 already eBGP with R2
R1 has multiple routes learned from static routes, EIGRP, and OSPF
All the routes in R1’s routing table can be advertised into BGP, regardless of the source routing protocol.
Loopback networks are added as network statement except OSPF one, loopback learned over OSPF is redistributed instead
router bgp 65100
neighbor 10.12.1.2 remote-as 65200
address-family ipv4 unicast
neighbor 10.12.1.2 activate
network 10.12.1.0 mask 255.255.255.0
network 192.168.1.1 mask 255.255.255.255
network 192.168.3.3 mask 255.255.255.255
network 192.168.4.4 mask 255.255.255.255
redistribute ospf 1Redistributing routes learned from an IGP into BGP is completely safe; however, redistributing routes learned from BGP into an IGP should be done with caution. BGP is designed for large scale and can handle a routing table the size of the Internet (940,000+ prefixes), whereas IGPs could have stability problems with fewer than 20,000 routes.
Origin code is IGP (for routes learned from the network statement) or incomplete (redistributed)
R1# show bgp ipv4 unicast
BGP table version is 9, local router ID is 192.168.1.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 10.12.1.0/24 0.0.0.0 0 32768 i
* 10.12.1.2 0 0 65200 i
*> 10.15.1.0/24 0.0.0.0 0 32768 ?
*> 192.168.1.1/32 0.0.0.0 0 32768 i
*> 192.168.2.2/32 10.12.1.2 0 0 65200 i
! The following route comes from EIGRP and uses a network statement
*> 192.168.3.3/32 10.13.1.3 3584 32768 i
! The following route comes from a static route and uses a network statement
*> 192.168.4.4/32 10.14.1.4 0 32768 i
! The following route was redistributed from OSPF
*> 192.168.5.5/32 10.15.1.5 11 32768 ?if the LocPrf (Local Preference) attribute is not shown in the BGP table output, that means:The Local Preference is 100 by default, Cisco only displays non-default local preference values in the BGP table
R2# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
* 10.12.1.0/24 10.12.1.1 0 0 65100 i
*> 0.0.0.0 0 32768 i
*> 10.15.1.0/24 10.12.1.1 0 0 65100 ?
*> 192.168.1.1/32 10.12.1.1 0 0 65100 i
*> 192.168.2.2/32 0.0.0.0 0 32768 i
*> 192.168.3.3/32 10.12.1.1 3584 0 65100 i
*> 192.168.4.4/32 10.12.1.1 0 0 65100 i
*> 192.168.5.5/32 10.12.1.1 11 0 65100 ?If multiple paths exist for the same prefix, only the first prefix is listed and other paths leave an empty space in the output
* valid paths
> best paths
Next hop is also a PA attribute
Metric – MED optional non-transitive BGP path attribute used in the BGP best-path algorithm for that specific path.
Optional = routers are not required to understand or use the attribute.
Non-transitive = the attribute must not be passed beyond the neighboring AS.
AS X sends a route with a MED to AS Y.
AS Y does NOT pass that MED on when advertising the route to any other AS (AS Z, etc.).
The MED is only meaningful between two directly connected ASes — it influences which entry point the neighbor should use, not the entire global internet
LocPrf – Local preference, a well-known discretionary path attribute used in the BGP best-path algorithm for that specific path.
Weight – A locally significant Cisco-defined attribute used in the BGP best-path algorithm for that specific path.
Path – AS_Path, a well-known mandatory BGP path attribute used for loop prevention and in the BGP best-path algorithm for that specific path.
Origin – Origin, a well-known mandatory BGP path attribute used in the BGP best-path algorithm. The value i represents an IGP, e is for EGP, and ? is for a route that was redistributed into BGP.
R1# show bgp ipv4 unicast 10.12.1.0
BGP routing table entry for 10.12.1.0/24, version 2
Paths: (2 available, best #2, table default)
Advertised to update-groups:
2
Refresh Epoch 1
65200
10.12.1.2 from 10.12.1.2 (192.168.2.2)
Origin IGP, metric 0, localpref 100, valid, external
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
Local
0.0.0.0 from 0.0.0.0 (192.168.1.1)
Origin IGP, metric 0, localpref 100, weight 32768, valid, sourced, local, best
rx pathid: 0, tx pathid: 0x0Paths: (2 available, best #2)
Provides a count of BGP paths in the BGP Loc-RIB table and identifies the path selected as the BGP best path.
Advertised to update-groups
BGP neighbors are consolidated into BGP update groups. If a path is not advertised, Not advertised to any peer is displayed.
65200 (1st path)
Local (2nd path)
This is the AS_Path for the path as it was received or whether the prefix was locally advertised.
10.12.1.2 from 10.12.1.2 (192.168.2.2)
| | |
| | |
next hop | |
| |
advertising neighbor |
|
|
RID of the advertising neighborThe first entry lists the IP address of the next hop for the prefix.
The from field lists the IP address of the advertising neighbor. (The field could change when an external path is learned from an iBGP peer.)
The number in parentheses is the BGP identifier (RID) for the node.
Origin
Origin is well-known mandatory attribute that states the mechanism for advertising this path. In this instance, it is an internal path.
metric 0
Displays the optional non-transitive BGP attribute MED, also known as the BGP metric.
localpref 100
Displays the well-known discretionary BGP attribute Local Preference.
valid
Displays the validity of this path.
External (1st path)
Local (2nd path)
Displays how the path was learned: internal, external, or local.
R1# show bgp ipv4 unicast neighbors 10.12.1.2 advertised-routes
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 10.12.1.0/24 0.0.0.0 0 32768 i
*> 10.15.1.0/24 0.0.0.0 0 32768 ?
*> 192.168.1.1/32 0.0.0.0 0 32768 i
*> 192.168.3.3/32 10.13.1.3 3584 32768 i
*> 192.168.4.4/32 10.14.1.4 0 32768 i
*> 192.168.5.5/32 10.15.1.5 11 32768 ?
Total number of prefixes 6R2# show bgp ipv4 unicast neighbors 10.12.1.1 advertised-routes
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 10.12.1.0/24 0.0.0.0 0 32768 i
*> 192.168.2.2/32 0.0.0.0 0 32768 i
Total number of prefixes 2R1# show bgp ipv4 unicast summary
! Output omitted for brevity
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.12.1.2 4 65200 11 10 9 0 0 00:04:56 2eBGP and iBGP
Internal BGP (iBGP):
in the same AS
or in same BGP confederation
iBGP learned routes are assigned AD of 200
External BGP (eBGP):
in a different AS
eBGP learned routes are assigned AD of 20
iBGP
Need for iBGP is needed when transit connectivity is needed or multi-homing is needed
AS 65200 provides transit connectivity to AS 65100 and AS 65300
R2 could form an iBGP session directly with R4
but R3 would not know where to forward traffic when traffic from either AS reaches R3
You might assume that redistributing the BGP table into an IGP overcomes the problem, but this not a viable solution, incase the BGP table is way larger than IGP can handle:
Scalability: IGPs cannot scale to that level of routes.
Routing: Link-state protocols and distance vector routing protocols use metric as the primary method for routing, while BGP uses multiple steps to identify the best path, The best path from BGP perspective could be longer, which would normally be deemed suboptimal from an IGP’s perspective.
Path attributes: All the BGP path attributes cannot be maintained within IGP protocols, upon redistribution into IGP, PA are lost
Solution to above problem is iBGP on all routers R2, R3 and R4 also called full mesh iBGP, that will allow proper forwarding of traffic
Above was just an example scenario, Enterprise organizations are consumers and should not provide transit connectivity between autonomous systems across the Internet, only service providers do.
BGP synchronization
In early iBGP deployments where the AS was used as a transit AS, network prefixes would commonly be redistributed into the IGP, To ensure full connectivity in the transit AS, BGP would use synchronization. BGP synchronization is the process of verifying that the BGP route existed in the IGP before the route could be advertised to an eBGP peer. BGP synchronization is no longer a default and is not commonly used
iBGP Full Mesh
iBGP peers do not prepend their ASN to AS_Path.
No other method exists for detecting loops with iBGP sessions so writers of BGP prohibit the advertisement of a route received from an iBGP peer to another iBGP peer.
RFC 4271 states that all BGP routers in a single AS must be fully meshed to provide a complete loop-free routing table
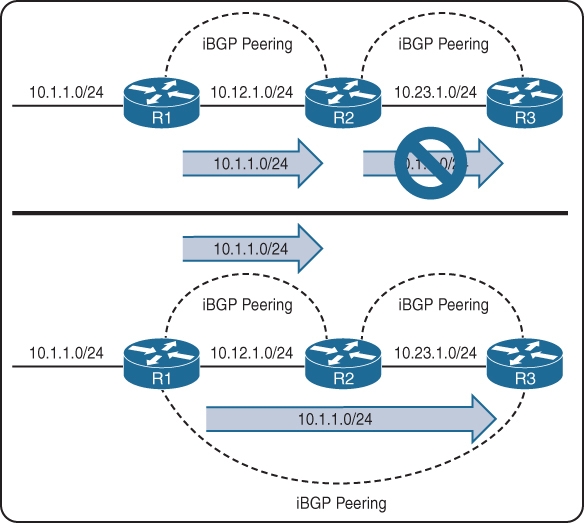
R1 advertises the 10.1.1.0/24 prefix to R2, which is processed and inserted into R2’s BGP table. R2 does not advertise the 10.1.1.0/24 route to R3 because it received the route from an iBGP peer R1
To resolve this issue, “R1 must form a multi-hop iBGP session with R3” so that R3 can receive the 10.1.1.0/24 route directly from R1
R1 and R3 either need a static route to the remote peering transit nets or R2 can advertise the 10.12.1.0/24 and 10.23.1.0/24 networks into BGP, if you think that R1’s 10.12.1.0/24 will not be passed by R2 to R3 but R1 did not advertise 10.12.1.0/24 instead R2 did, so 10.12.1.0/24 will be passed to R3 by R2
Need for peering using loopbacks

R1, R2, and R3 are a full mesh of iBGP sessions peered by transit links.
In the event of a link failure on the 10.13.1.0/24 network
R3’s BGP session with R1 will drop
R3 loses connectivity to the 10.1.1.0/24 network, even though R1 and R3 could communicate through R2 (through a multi-hop path).
This loss of connectivity occurs because iBGP does not advertise routes learned from another iBGP peer
You can overcome this issue by advertising the loopback into IGP and then creating BGP peering between loopback addresses
-loopback interface is virtual and always stays up
-Flexibility to failure: In the event of link failure, the session stays intact, and the IGP finds another path to the loopback address
-multi-hop iBGP session
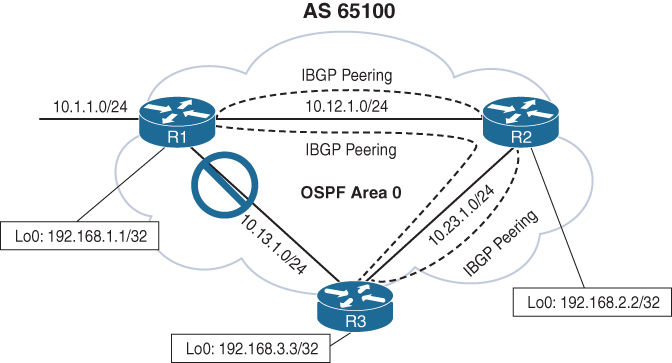
10.13.1.0/24 link fails. R1 and R3 still maintain BGP session connectivity by reaching each other’s loopback through R2, R2 will simply route the BGP packets between R1 and R3 without taking part in that BGP session
R1 (Default IPv4 Address Family Enabled)
router ospf 1
network 10.12.0.0 0.0.255.255 area 0
network 10.13.0.0 0.0.255.255 area 0
network 192.168.1.1 0.0.0.0 area 0
!
router bgp 65100
network 10.1.1.0 mask 255.255.255.0
neighbor remote-as 192.168.2.2 65100
neighbor 192.168.2.2 update-source Loopback0
neighbor remote-as 192.168.3.3 65100
neighbor 192.168.3.3 update-source Loopback0
!
address-family ipv4
neighbor 192.168.2.2 activate
neighbor 192.168.3.3 activateR2 (Default IPv4 Address Family Disabled)
router ospf 1
network 10.0.0.0 0.255.255.255 area 0
network 192.168.2.2 0.0.0.0 area 0
!
router bgp 65100
no bgp default ipv4-unicast
neighbor remote-as 192.168.1.1 65100
neighbor 192.168.1.1 update-source Loopback0
neighbor remote-as 192.168.3.3 65100
neighbor 192.168.3.3 update-source Loopback0
!
address-family ipv4
neighbor 192.168.1.1 activate
neighbor 192.168.3.3 activateas side effect of using loopback interfaces for peering is that next hop addresses are loopback addresses and recursive lookup is performed to find the outgoing interface
Another side effect that can happen is that if loopbacks are advertised It end up providing automatic load balancing if there are multiple equal-cost paths through the IGP to the loopback address (but only for iBGP)
eBGP
eBGP peerings
-AS is different from the AS configured locally in bgp router command
-The time-to-live (TTL) on eBGP packets is set to 1. BGP packets drop in transit if a multi-hop BGP session is attempted. The TTL on iBGP packets is set to 255, which allows for multi-hop sessions by default
-The advertising router modifies the BGP next hop for updates to the IP address sourcing the BGP connection
-The advertising router prepends its ASN to the existing AS_Path
-most recent AS is always prepended (the furthest to the left) since AS path is right to left
-The receiving router verifies that the AS_Path does not contain an ASN that matches the local routers. BGP discards the update if it fails the AS_Path loop-prevention check.
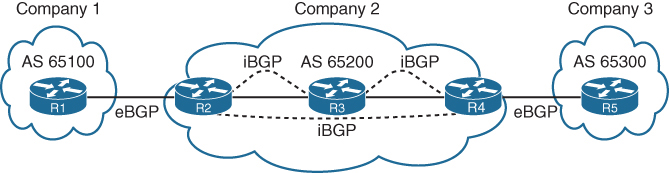
In above picture we can see ebgp peering and ibgp full mesh peering
Next hop issue for routes from eBGP to iBGP
As an eBGP prefix is advertised to an iBGP neighbor from local router, a route may not pass validity check because of next-hop reachability check and that route might be advertised from local router to first iBGP peer but not any further from that iBGP peer because that first iBGP peer considers route to be invalid due to next hop validity check failure
Because (local router) iBGP peer do not modify the next-hop address and when that foreign next hop address of eBGP router is passed to first iBGP peer and because that iBGP peer is not aware of that foreign address (next hop validity check which is first step in BGP best path selection fails), it is not advertised further to other iBGP peers as it is not even a valid route let alone best route.
The next-hop address must be resolvable in the RIB in order for it to be valid and advertised to other BGP peers.
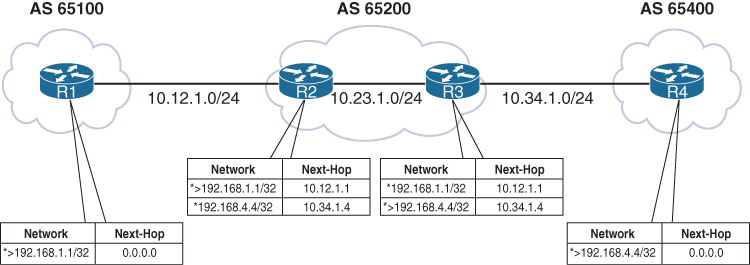
Notice that the BGP best-path symbol (>) is missing for the 192.168.4.4/32 prefix on R2 and for the 192.168.1.1/32 prefix on R3.
R1’s BGP table is missing the 192.168.4.4/32 route because the route did not pass R2’s next-hop accessibility check, preventing the execution of the BGP best-path algorithm
R4 advertised the route to R3 with the next-hop address 10.34.1.4, and R3 advertised the route to R2 with the next-hop address 10.34.1.4. R2 does not have a route for the 10.34.1.4 IP address and deems the next hop inaccessible. The same logic applies to R1’s 192.168.1.1/32 route when advertised toward R4.
R3# show bgp ipv4 unicast 192.168.1.1
BGP routing table entry for 192.1681.1/32, version 2
Paths: (1 available, no best path)
Not advertised to any peer
Refresh Epoch 1
65100
10.12.1.1 (inaccessible) from 10.23.1.2 (192.168.2.2)
Origin IGP, metric 0, localpref 100, valid, internalTo correct the issue, we can advertise those peering links using either below methods:
- IGP advertisement (Remember to use the passive interface to prevent an accidental adjacency from forming. Most IGPs do not provide the filtering capability provided by BGP.)
- Advertisement of the networks into BGP
or we could change next hop using next-hop-self, which is much better solution due to scalability as shown below
next-hop-self
Imagine that a service provider network has 500 routers, and every router has 200 eBGP peering links. To ensure that the next-hop address is reachable to the iBGP peers, the provider needs the advertisement of 100,000 peering networks in BGP or an IGP consuming router resources
using next-hop-self on ibgp neighbor we can achieve modification of that foreign ebgp peer’s address to its ibgp session address towards that ibgp peer
The next-hop-self feature only modifies prefixes going from ebgp peers to iBGP peers by default, but using the command next-hop-self [all] modifies the next-hop address on prefixes learned from iBGP to iBGP peers
R2 (Default IPv4 Address-Family Enabled)
router bgp 65200
neighbor 10.12.1.1 remote-as 65100
neighbor 10.23.1.3 remote-as 65200
neighbor 10.23.1.3 next-hop-selfR3 (Default IPv4 Address-Family Disabled)
router bgp 65200
no bgp default ipv4-unicast
neighbor 10.23.1.2 remote-as 65200
neighbor 10.34.1.4 remote-as 65400
!
address-family ipv4
neighbor 10.23.1.2 activate
neighbor 10.23.1.2 next-hop-self
neighbor 10.34.1.4 activate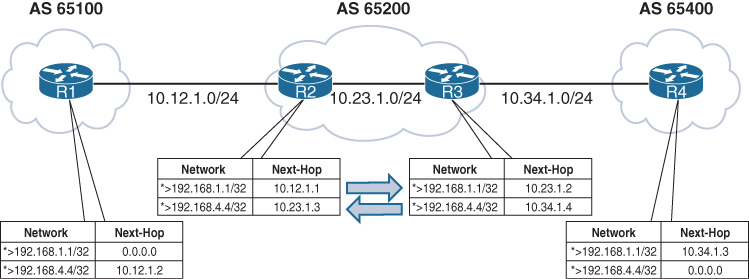
iBGP Scalability Solutions
The inability of BGP to advertise a route learned from one iBGP peer to another iBGP peer can lead to scalability issues within an AS. The formula n(n − 1)/2 provides the number of sessions required, where n represents the number of routers. A full mesh topology of 5 routers requires 10 sessions, and a topology of 10 routers requires 45 sessions
Route Reflectors
The router that is reflecting routes is known as a route reflector (RR),
the router that is receiving reflected routes is a route reflector client.
This reflector model is like an OSPF DR concept but for neighborships and not full sync, instead of all iBGP routers making adjacency with every other router, one router makes iBGP peering with all the routers
But there are few rules to follow
- Rule 1: If an RR receives an NLRI from a non-RR client, the RR advertises the NLRI to an RR client. It does not advertise the NLRI to a non-RR client.
- Rule 2: If an RR receives an NLRI from an RR client, it advertises the NLRI to RR clients and non-RR clients.
- Rule 3: If an RR receives a route from an eBGP peer, it advertises the route to RR clients and non-RR clients.
remember that RR clients receive in all scenarios / rules
Only Route Reflector is configured with RR configuration, and RR clients do not need to modify configuration, they just need to make iBGP peering with route reflecting RR router
BGP route reflector is an address family command like other loc-RIB commands
BGP route reflection is specific to each address family.
The command neighbor ip-address route-reflector-client is used under the neighbor address family configuration.
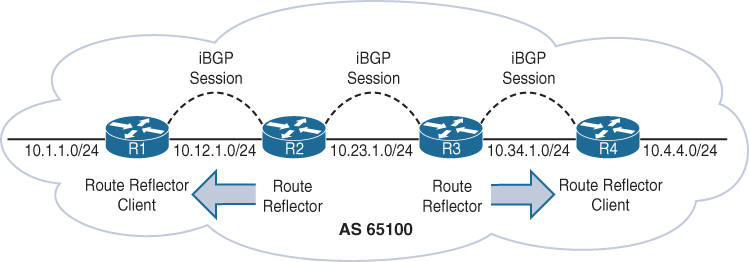
R1 is a route reflector client to R2, and R4 is a route reflector client to R3. R2 and R3 have a normal iBGP peering
You can have a gap in between 2 RRs in your design
R1 (Default IPv4 Address-Family Enabled)
router bgp 65100
network 10.1.1.0 mask 255.255.255.0
redistribute connected
neighbor 10.12.1.2 remote-as 65100R2 (Default IPv4 Address-Family Enabled)
router bgp 65100
redistribute connected
neighbor 10.12.1.1 remote-as 65100
neighbor 10.12.1.1 route-reflector-client
neighbor 10.23.1.3 remote-as 65100R3 (Default IPv4 Address-Family Disabled)
router bgp 65100
no bgp default ipv4-unicast
neighbor 10.23.1.2 remote-as 65100
neighbor 10.34.1.4 remote-as 65100
!
address-family ipv4
redistribute connected
neighbor 10.23.1.2 activate
neighbor 10.34.1.4 activate
neighbor 10.34.1.4 route-reflector-clientR4 (Default IPv4 Address-Family Disabled)
router bgp 65100
no bgp default ipv4-unicast
neighbor 10.34.1.3 remote-as 65100
!
address-family ipv4
neighbor 10.34.1.3 activate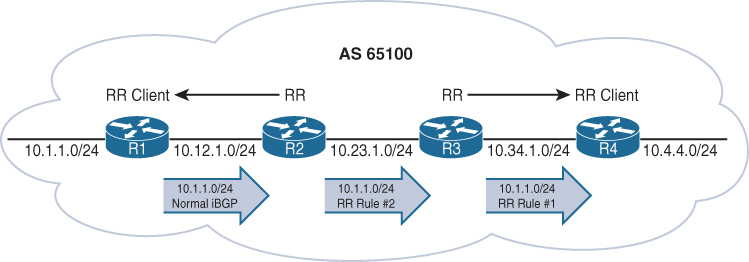
R1 advertises the 10.1.1.0/24 route to R2 as a normal iBGP advertisement.
R2 receives and advertises the 10.1.1.0/24 route using the route reflector rule 2 as just explained to R3 (a non-route reflector client) (this is why above gap [normal ibgp peering] can be made)
R3 receives and advertises the 10.1.1.0/24 route using the route reflector rule 1 as explained to R4 (a route reflector client).
- Rule 1: If an RR receives an NLRI from a non-RR client, the RR advertises the NLRI to an RR client. It does not advertise the NLRI to a non-RR client.
- Rule 2: If an RR receives an NLRI from an RR client, it advertises the NLRI to RR clients and non-RR clients.
- Rule 3: If an RR receives a route from an eBGP peer, it advertises the route to RR clients and non-RR clients.
See how iBGP between R2 and R3 is non client s
R1# show bgp ipv4 unicast | i Network|10.1.1
Network Next Hop Metric LocPrf Weight Path
*> 10.1.1.0/24 0.0.0.0 0 32768 iR2# show bgp ipv4 unicast | i Network|10.1.1
Network Next Hop Metric LocPrf Weight Path
*>i 10.1.1.0/24 10.12.1.1 0 100 0 iR3# show bgp ipv4 unicast | i Network|10.1.1
Network Next Hop Metric LocPrf Weight Path
*>i 10.1.1.0/24 10.12.1.1 0 100 0 iR4# show bgp ipv4 unicast | i Network|10.1.1
Network Next Hop Metric LocPrf Weight Path
*>i 10.1.1.0/24 10.12.1.1 0 100 0 iNotice the i immediately after the best-path indicator (>) on R2, R3, and R4. This indicates that the prefix is learned through iBGP.
Important notes on RR
Route reflector can be inband or in path or it can be outband or out of data path
With Route Reflector in our iBGP network we dont need to do full mesh iBGP instead we only do iBGP with Route Reflector only
Route Reflectors choose best path based on their perspective or exit point and not perspective of the client this can result in a situation where certain exit point in the network for a prefix is optimal for RR but not optimal for clients
When ibgp routers have multiple paths to compare then one ibgp router can say path A is better and another ibgp router can say that path B is best (based on IGP cost) but when RR is used then RR decides one best path for a prefix and then pushes that to all the clients and now all clients have one best path for a prefix regardless of IGP cost to the next hop
RR only advertise one path for a prefix to the clients and do not advertise any other path to clients
The fix for this is BGP Add Path
BGP Add Path
In standard BGP, a router advertises only one best path per prefix to its neighbors. Because of best path good alternative routes exist but are not advertised
Similarly RRs only advertise their single best path, reducing path diversity.
BGP Add-Path is an extension to BGP that allows a router to advertise multiple paths for the same prefix to a neighbor and this is how router can switch to second path faster.
BGP add path is useful for Datacenters and Large ISP, also networks that use route reflectors
But remember that add path is a capability and is exchanged in open message and needs to be supported and sent by peer
BGP routing table entry for 10.10.10.0/24
Paths: (2 available, best #1)
Advertised to update-groups:
1
Path 1:
Received Path ID 1 <<< ! Received Path ID confirms ADD-PATH
65001 65002
192.0.2.1 from 192.0.2.1 (192.0.2.1)
Origin IGP, localpref 100, valid, external, best
Path 2:
Received Path ID 2 <<< ! Received Path ID confirms ADD-PATH
65003 65002
192.0.2.1 from 192.0.2.1 (192.0.2.1)
Origin IGP, localpref 100, valid, external
Why is BGP Add Path needed when multipath is available?
Multipath makes router use multiple paths, while Additional paths from add path are kept as backup for faster failover
For multipath to work the routes must be equal including AS numbers and AS Path hops must be same and for ibgp routes must be equal including AS numbers and AS Path hops must be same + also the IGP metric to next hop too
Loop Prevention in Route Reflectors
Removing the full mesh requirement in an iBGP topology using route-reflector introduces the potential for routing loops. When RFC 1966 was drafted, two other BGP route reflector–specific attributes were added to prevent loops:
Originator: This optional non-transitive BGP attribute is created by the first route reflector and sets the value to the RID of the router that injected/advertised the prefix into the iBGP network. If Originator is already populated on a route, it should not be overwritten. If a router receives a route with its RID in the Originator attribute, the route is discarded.
Cluster List: This optional non-transitive BGP attribute is updated by the route reflector. This attribute is appended (hence the list , not overwritten) by the route reflector with its cluster ID. By default, this is the BGP identifier. If a route reflector receives a route with its cluster ID in the Cluster List attribute, the route is discarded.
R4# show bgp ipv4 unicast 10.1.1.0/24
! Output omitted for brevity
Paths: (1 available, best #1, table default)
Refresh Epoch 1
Local
10.12.1.1 from 10.34.1.3 (192.168.3.3)
Origin IGP, metric 0, localpref 100, valid, internal, best
Originator: 192.168.1.1, Cluster list: 192.168.3.3, 192.168.2.2Confederations
BGP confederations is also an alternative solution to the iBGP full mesh scalability issues
Sub-ASs known as member ASs
Larger AS known as an AS confederation
Member ASs normally use ASNs from the private ASN range (64,512 to 65,534)
eBGP peers peer using confederation AS
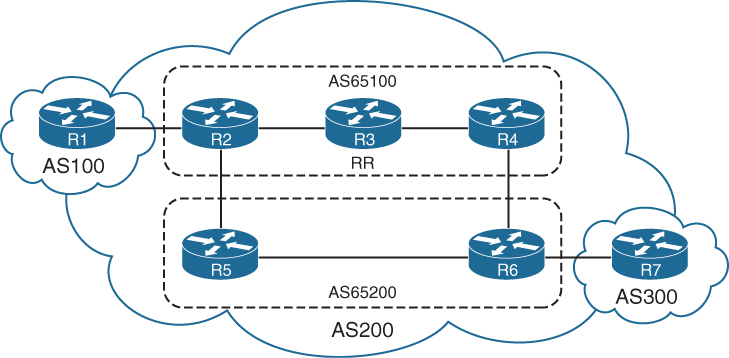
Notice that R3 provides route reflection in member AS 65100.
R1
router bgp 100
neighbor 10.12.1.2 remote-as 200R2
router bgp 65100 <<< local bubble
bgp confederation identifier 200 <<< larger bubble
bgp confederation peers 65200 <<< other bubbles we peer with
neighbor 10.12.1.1 remote-as 100 <<< normal peering
neighbor 10.23.1.3 remote-as 65100 <<< normal peering
neighbor 10.25.1.5 remote-as 65200 <<< normal peeringR3
router bgp 65100
bgp confederation identifier 200
neighbor 10.23.1.2 remote-as 65100
neighbor 10.23.1.2 route-reflector-client
neighbor 10.34.1.4 remote-as 65100
neighbor 10.34.1.4 route-reflector-clientR4
router bgp 65100
bgp confederation identifier 200
bgp confederation peers 65200
neighbor 10.34.1.3 remote-as 65100
neighbor 10.46.1.6 remote-as 65200R5
router bgp 65200
bgp confederation identifier 200
bgp confederation peers 65100
neighbor 10.25.1.2 remote-as 65100
neighbor 10.56.1.6 remote-as 65200R6
router bgp 65200
bgp confederation identifier 200
bgp confederation peers 65100
neighbor 10.46.1.4 remote-as 65100
neighbor 10.56.1.5 remote-as 65200
neighbor 10.67.1.7 remote-as 300R7
router bgp 300
neighbor 10.67.1.6 remote-as 200The AS_Path attribute contains a subfield called AS_CONFED_SEQUENCE.
AS_CONFED_SEQUENCE is confederation’s AS PATH but displayed in parentheses before any external ASNs in AS_Path.
As the route passes from member AS to member AS, AS_CONFED_SEQUENCE is appended to contain the member AS ASNs.
The AS_CONFED_SEQUENCE attribute is only used to prevent loops but is not used (counted) when choosing the shortest AS_Path.
Route reflectors can be used within the member AS as in normal iBGP peerings.
The BGP MED attribute is transitive to all other member ASs and Within the confederation, MED is propagated between member sub-ASes but MED is NOT advertised outside the confederation to external ASes. When routes leave the confederation and are advertised to a true external AS: The MED is stripped (unless explicitly re-set by policy).
The LOCAL_PREF attribute is transitive to all other member ASs just like iBGP
The next-hop address for external confederation routes does not change as the route is exchanged between member ASs
AS_CONFED_SEQUENCE is removed from AS_Path when the route is advertised outside the confederation.
AS 100 is not aware that AS 200 is a confederation
R1-AS100# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.1.1.0/24 0.0.0.0 0 32768 ?
*> 10.7.7.0/24 10.12.1.2 0 200 300 i
* 10.12.1.0/24 10.12.1.2 0 0 200 ?
*> 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 10.12.1.2 0 0 200 ?
*> 10.25.1.0/24 10.12.1.2 0 0 200 ?
*> 10.46.1.0/24 10.12.1.2 0 200 ?
*> 10.56.1.0/24 10.12.1.2 0 200 ?
*> 10.67.1.0/24 10.12.1.2 0 200 ?
*> 10.78.1.0/24 10.12.1.2 0 200 300 ?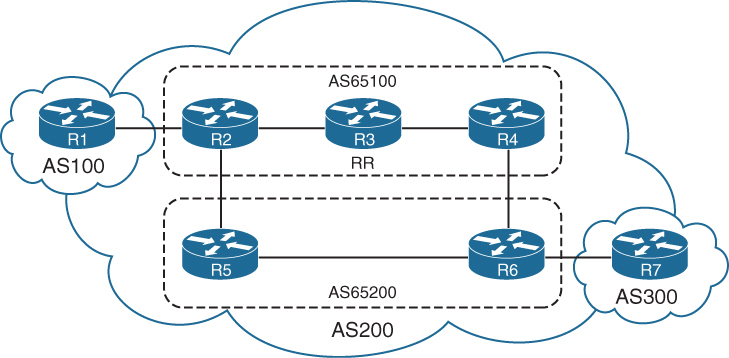
R2’s BGP table which is in member AS 65100, see that next hop IP address for 10.7.7.0/24 was not changed (advertised by R7) even though it passed different member AS
AS_CONFED_SEQUENCE in parentheses indicates that it passed through sub AS 65200
R2# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.1.1.0/24 10.12.1.1 111 0 100 ?
*> 10.7.7.0/24 10.67.1.7 0 100 0 (65200) 300 i
*> 10.12.1.0/24 0.0.0.0 0 32768 ?
* 10.12.1.1 111 0 100 ?
*> 10.23.1.0/24 0.0.0.0 0 32768 ?
* 10.25.1.0/24 10.25.1.5 0 100 0 (65200) ?
*> 0.0.0.0 0 32768 ?
*> 10.46.1.0/24 10.56.1.6 0 100 0 (65200) ?
*> 10.56.1.0/24 10.25.1.5 0 100 0 (65200) ?
*> 10.67.1.0/24 10.56.1.6 0 100 0 (65200) ?
*> 10.78.1.0/24 10.67.1.7 0 100 0 (65200) 300 ?
Processed 9 prefixes, 11 pathsNotice that the path information includes the attribute confed-internal or confed-external, based on whether the route was received within the same member AS or a different one.
R4# show bgp ipv4 unicast 10.7.7.0/24
! Output omitted for brevity
BGP routing table entry for 10.7.7.0/24, version 504
Paths: (2 available, best #1, table default)
Advertised to update-groups:
3
Refresh Epoch 1
(65200) 300
10.67.1.7 from 10.34.1.3 (192.168.3.3)
Origin IGP, metric 0, localpref 100, valid, confed-internal, best
Originator: 192.168.2.2, Cluster list: 192.168.3.3
rx pathid: 0, tx pathid: 0x0
Refresh Epoch 1
(65200) 300
10.67.1.7 from 10.46.1.6 (192.168.6.6)
Origin IGP, metric 0, localpref 100, valid, confed-external
rx pathid: 0, tx pathid: 0Multiprotocol BGP for IPv6
Multiprotocol BGP (MP-BGP) enables BGP to carry NLRI for different protocols
such as IPv6, MPLS Layer 3 with VRFs info
New BGPv4 optional and nontransitive attributes:
-Multiprotocol reachable NLRI: Describes IPv6 route information
-Multiprotocol unreachable NLRI: Withdraws the IPv6 route from service
These attributes are optional and nontransitive, so if an older router does not understand the attributes, the information can just be ignored as there are a lot of old routing equipment in internet
MP-BGP for IPv6 continues to use the same well-known TCP port 179
IPv4 unicast: AFI:1, SAFI:1
IPv6 unicast: AFI:2, SAFI:1
Unique global unicast addressing is the recommended method for BGP peering to avoid operational complexity. BGP peering using the link-local address may introduce risk if the address is not manually assigned to an interface
R1 advertises all its networks through redistribution
R2 and R3 use the network statement to advertise all their connected networks.
R1
router bgp 65100
bgp router-id 192.168.1.1
no bgp default ipv4-unicast
neighbor 2001:DB8:0:12::2 remote-as 65200
!
address-family ipv6
neighbor 2001:DB8:0:12::2 activate
redistribute connectedR2
router bgp 65200
bgp router-id 192.168.2.2
no bgp default ipv4-unicast
neighbor 2001:DB8:0:12::1 remote-as 65100
neighbor 2001:DB8:0:23::3 remote-as 65300
!
address-family ipv6
neighbor 2001:DB8:0:12::1 activate
neighbor 2001:DB8:0:23::3 activate
network 2001:DB8::2/128
network 2001:DB8:0:12::/64
network 2001:DB8:0:23::/64R3
router bgp 65300
bgp router-id 192.168.3.3
no bgp default ipv4-unicast
neighbor 2001:DB8:0:23::2 remote-as 65200
!
address-family ipv6
neighbor 2001:DB8:0:23::2 activate
network 2001:DB8::3/128
network 2001:DB8:0:3::/64
network 2001:DB8:0:23::/64IPv4 unicast routing capability is advertised by default in IOS XE
for pure IPv6 environment shut down the bgp on IPv4 neighbor or globally within the BGP process with the command no bgp default ipv4-unicast
show bgp ipv6 unicast neighbors ip-address [detail] displays detailed information about whether the IPv6 capabilities were negotiated successfully.
R1# show bgp ipv6 unicast neighbors 2001:DB8:0:12::2
! Output omitted for brevity
BGP neighbor is 2001:DB8:0:12::2, remote AS 65200, external link
BGP version 4, remote router ID 192.168.2.2
BGP state = Established, up for 00:28:25
Last read 00:00:54, last write 00:00:34, hold time is 180, keepalive interval is 60 seconds
Neighbor sessions:
1 active, is not multisession capable (disabled)
Neighbor capabilities:
Route refresh: advertised and received(new)
Four-octets ASN Capability: advertised and received
Address family IPv6 Unicast: advertised and received <<<
Enhanced Refresh Capability: advertised and received
..
For address family: IPv6 Unicast
Session: 2001:DB8:0:12::2
BGP table version 13, neighbor version 13/0
Output queue size : 0
Index 1, Advertise bit 0
1 update-group member
Slow-peer detection is disabled
Slow-peer split-update-group dynamic is disabled
Sent Rcvd
Prefix activity: ---- ----
Prefixes Current: 3 5 (Consumes 520 bytes)
Prefixes Total: 6 10R2# show bgp ipv6 unicast summary
BGP router identifier 192.168.2.2, local AS number 65200
BGP table version is 19, main routing table version 19
7 network entries using 1176 bytes of memory
8 path entries using 832 bytes of memory
3/3 BGP path/bestpath attribute entries using 456 bytes of memory
2 BGP AS-PATH entries using 48 bytes of memory
0 BGP route-map cache entries using 0 bytes of memory
0 BGP filter-list cache entries using 0 bytes of memory
BGP using 2512 total bytes of memory
BGP activity 7/0 prefixes, 8/0 paths, scan interval 60 secs
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
2001:DB8:0:12::1 4 65100 35 37 19 0 0 00:25:08 3
2001:DB8:0:23::3 4 65300 32 37 19 0 0 00:25:11 3Notice that some of the prefixes include the unspecified address as the next hop. The unspecified address indicates that the local router is generating the prefix for the BGP table
The weight value 32,768 also indicates that the prefix is locally originated by the router.
This is to force select this as always the best path since BGP best path algorithm has highest weight as top criteria
R1# show bgp ipv6 unicast
BGP table version is 13, local router ID is 192.168.1.1
Status codes: s suppressed, d damped, h history, * valid, > best, – - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: – - IGP, – - EGP, – - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8::1/128 :: 0 32768 ?
*> 2001:DB8::2/128 2001:DB8:0:12::2 0 0 65200 i
*> 2001:DB8::3/128 2001:DB8:0:12::2 0 65200 65300 i
*> 2001:DB8:0:1::/64 :: 0 32768 ?
*> 2001:DB8:0:3::/64 2001:DB8:0:12::2 0 65200 65300 i
* 2001:DB8:0:12::/64 2001:DB8:0:12::2 0 0 65200 i
*> :: 0 32768 ?
*> 2001:DB8:0:23::/64 2001:DB8:0:12::2 0 65200 iR2# show bgp ipv6 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8::1/128 2001:DB8:0:12::1 0 0 65100 ?
*> 2001:DB8::2/128 :: 0 32768 i
*> 2001:DB8::3/128 2001:DB8:0:23::3 0 0 65300 i
*> 2001:DB8:0:1::/64 2001:DB8:0:12::1 0 0 65100 ?
*> 2001:DB8:0:3::/64 2001:DB8:0:23::3 0 0 65300 i
*> 2001:DB8:0:12::/64 :: 0 32768 i
* 2001:DB8:0:12::1 0 0 65100 ?
*> 2001:DB8:0:23::/64 :: 0 32768 i
2001:DB8:0:23::3 0 0 65300 iR3# show bgp ipv6 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8::1/128 2001:DB8:0:23::2 0 65200 65100 ?
*> 2001:DB8::2/128 2001:DB8:0:23::2 0 0 65200 i
*> 2001:DB8::3/128 :: 0 32768 i
*> 2001:DB8:0:1::/64 2001:DB8:0:23::2 0 65200 65100 ?
*> 2001:DB8:0:3::/64 :: 0 32768 i
*> 2001:DB8:0:12::/64 2001:DB8:0:23::2 0 0 65200 i
*> 2001:DB8:0:23::/64 :: 0 32768 i
*> 2001:DB8:0:23::2 :: 0 32768 i
* 2001:DB8:0:23::2 0 0 65200 iR3# show bgp ipv6 unicast 2001:DB8::1/128
BGP routing table entry for 2001:DB8::1/128, version 9
Paths: (1 available, best #1, table default)
Not advertised to any peer <<<
Refresh Epoch 2
65200 65100
2001:DB8:0:23::2 (FE80::2) from 2001:DB8:0:23::2 (192.168.2.2)
Origin incomplete, localpref 100, valid, external, best
rx pathid: 0, tx pathid: 0x0Notice that the next-hop address is the link-local address for the next-hop forwarding address, which is resolved through a recursive lookup.
R2# show ipv6 route bgp
IPv6 Routing Table - default - 10 entries
Codes: C - Connected, L - Local, S - Static, U - Per-user Static route
B - BGP, HA - Home Agent, MR - Mobile Router, R - RIP
H - NHRP, I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea
IS - ISIS summary, D - EIGRP, EX - EIGRP external, NM - NEMO
ND - ND Default, NDp - ND Prefix, DCE - Destination, NDr - Redirect
RL - RPL, O - OSPF Intra, OI - OSPF Inter, OE1 - OSPF ext 1
OE2 - OSPF ext 2, ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
la - LISP alt, lr - LISP site-registrations, ld - LISP dyn-eid
a - Application
B 2001:DB8::1/128 [20/0]
via FE80::1, GigabitEthernet0/0
B 2001:DB8::3/128 [20/0]
via FE80::3, GigabitEthernet0/1
B 2001:DB8:0:1::/64 [20/0]
via FE80::1, GigabitEthernet0/0
B 2001:DB8:0:3::/64 [20/0]
via FE80::3, GigabitEthernet0/1IPv6 over IPv4
BGP can exchange routes using either an IPv4 or IPv6 TCP session
In a typical deployment, IPv4 routes are exchanged using a dedicated IPv4 session, and IPv6 routes are exchanged with a dedicated IPv6 session
However, it is possible to share IPv6 routes over an IPv4 TCP session or IPv4 routes over an IPv6 TCP session
it is also possible to share IPv4 and IPv6 using a single BGP session.
R1
router bgp 65100
bgp router-id 192.168.1.1
no bgp default ipv4-unicast
neighbor 10.12.1.2 remote-as 65200
!
address-family ipv6 unicast
redistribute connected
neighbor 10.12.1.2 activateR2
router bgp 65200
bgp router-id 192.168.2.2
no bgp default ipv4-unicast
neighbor 10.12.1.1 remote-as 65100
neighbor 10.23.1.3 remote-as 65300
!
address-family ipv6 unicast
network 2001:DB8::2/128
network 2001:DB8:0:12::/64
aggregate-address 2001:DB8::/62 summary-only
neighbor 10.12.1.1 activate <<< ipv4 neighbor inside IPv6 address family
neighbor 10.23.1.3 activate <<< ipv4 neighbor inside IPv6 address familyR3
router bgp 65300
bgp router-id 192.168.3.3
no bgp default ipv4-unicast
neighbor 10.23.1.2 remote-as 65200
!
address-family ipv6 unicast
network 2001:DB8::3/128
network 2001:DB8:0:3::/64
network 2001:DB8:0:23::/64
neighbor 10.23.1.2 activateR1# show bgp ipv6 unicast summary | begin Neighbor
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.12.1.2 4 65200 115 116 11 0 0 01:40:14 2R2# show bgp ipv6 unicast summary | begin Neighbor
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.12.1.1 4 65100 114 114 8 0 0 01:39:17 3
10.23.1.3 4 65300 113 115 8 0 0 01:39:16 3R3# show bgp ipv6 unicast summary | begin Neighbor
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.23.1.2 4 65200 114 112 7 0 0 01:38:49 2The IPv6 routes advertised over an IPv4 BGP session are assigned an IPv4-mapped IPv6 address in the format (::FFFF:xx.xx.xx.xx) for the next hop, where xx.xx.xx.xx is the IPv4 address of the BGP peering. This is not a valid forwarding address, so the IPv6 route does not populate the RIB.
R1# show bgp ipv6 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
* 2001:DB8::/62 ::FFFF:10.12.1.2 0 0 65200 i
*> 2001:DB8::1/128 :: 0 32768 ?
*> 2001:DB8:0:1::/64 :: 0 32768 ?
* 2001:DB8:0:12::/64 ::FFFF:10.12.1.2 0 0 65200 i
*> :: 0 32768 ?R2# show bgp ipv6 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8::/62 :: 32768 i
S 2001:DB8::1/128 ::FFFF:10.12.1.1 0 0 65100 ?
s> 2001:DB8::2/128 :: 0 32768 i
s 2001:DB8::3/128 ::FFFF:10.23.1.3 0 0 65300 i
s 2001:DB8:0:1::/64 ::FFFF:10.12.1.1 0 0 65100 ?
s 2001:DB8:0:3::/64 ::FFFF:10.23.1.3 0 0 65300 i
* 2001:DB8:0:12::/64 ::FFFF:10.12.1.1 0 0 65100 ?
*> :: 0 32768 i
* 2001:DB8:0:23::/64 ::FFFF:10.23.1.3 0 0 65300 iR3# show bgp ipv6 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
* 2001:DB8::/62 ::FFFF:10.23.1.2 0 0 65200 i
*> 2001:DB8::3/128 :: 0 32768 i
*> 2001:DB8:0:3::/64 :: 0 32768 i
* 2001:DB8:0:12::/64 ::FFFF:10.23.1.2 0 0 65200 i
*> 2001:DB8:0:23::/64 :: 0 32768 iA quick connectivity test between R1 and R3. The output confirms that connectivity cannot be maintained.
R1# ping 2001:DB8:0:3::3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 2001:DB8:0:3::3, timeout is 2 seconds:
% No valid route for destination
Success rate is 0 percent (0/1)R1# traceroute 2001:DB8:0:3::3
Type escape sequence to abort.
Tracing the route to 2001:DB8:0:3::3
1 * * *
2 * * *
3 * * *
..To correct the problem, the BGP route map needs to manually set the IPv6 next hop.
R1
route-map FromR1R2Link permit 10
set ipv6 next-hop 2001:DB8:0:12::1
!
router bgp 65100
address-family ipv6 unicast
neighbor 10.12.1.2 route-map FromR1R2LINK outR2
route-map FromR2R1LINK permit 10
set ipv6 next-hop 2001:DB8:0:12::2
route-map FromR2R3LINK permit 10
set ipv6 next-hop 2001:DB8:0:23::2
!
router bgp 65200
address-family ipv6 unicast
neighbor 10.12.1.1 route-map FromR2R1LINK out
neighbor 10.23.1.3 route-map FromR2R3LINK outR3
route-map FromR3R2Link permit 10
set ipv6 next-hop 2001:DB8:0:23::3
!
router bgp 65300
address-family ipv6 unicast
neighbor 10.23.1.2 route-map FromR3R2Link outThe next-hop IP address is valid, and the route can now be installed into the RIB.
R1# show bgp ipv6 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8::/62 2001:DB8:0:12::2 0 0 65200 i
*> 2001:DB8::1/128 :: 0 32768 ?
*> 2001:DB8:0:1::/64 :: 0 32768 ?
*> 2001:DB8:0:12::/64 :: 0 32768 ?
* 2001:DB8:0:12::2 0 0 65200 iR2# show bgp ipv6 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8::/62 :: 32768 i
s> 2001:DB8::1/128 2001:DB8:0:12::1 0 0 65100 ?
s> 2001:DB8::2/128 :: 0 32768 i
s> 2001:DB8::3/128 2001:DB8:0:23::3 0 0 65300 i
s> 2001:DB8:0:1::/64 2001:DB8:0:12::1 0 0 65100 ?
s> 2001:DB8:0:3::/64 2001:DB8:0:23::3 0 0 65300 i
*> 2001:DB8:0:12::/64 :: 0 32768 i
r> 2001:DB8:0:23::/64 2001:DB8:0:23::3 0 0 65300 iR3# show bgp ipv6 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8::/62 2001:DB8:0:23::2
0 0 65200 i
*> 2001:DB8::3/128 :: 0 32768 i
*> 2001:DB8:0:3::/64 :: 0 32768 i
*> 2001:DB8:0:12::/64 2001:DB8:0:23::2 0 0 65200 i
*> 2001:DB8:0:23::/64 :: 0 32768 iSummarization
Summarizing prefixes conserves router resources and accelerates best-path calculation by reducing the size of the table.
Summarization, also known as route aggregation, provides the benefit of stability by hiding route flaps from downstream routers, thereby reducing routing churn
While most service providers do not accept prefixes larger than /24 for IPv4 (/25 through /32), the Internet, at the time of this writing, still has more than 940,000 routes and continues to grow. A router has to receive first and then summaries it towards it neighbors
Dynamic BGP summarization consists of the configuration of an aggregate network prefix. When viable component routes that match the aggregate network prefix enter the BGP table, the aggregate prefix is created. The originating router creates a discard route with next hop to Null0 for the aggregated prefix for loop prevention.
Dynamic route summarization is accomplished with the BGP address family configuration command aggregate-address network subnet-mask [summary-only] [as-set].
R1# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
* 10.12.1.0/24 10.12.1.2 0 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 10.12.1.2 0 0 65200 ?
*> 172.16.1.0/24 0.0.0.0 0 32768 ?
*> 172.16.2.0/24 0.0.0.0 0 32768 ?
*> 172.16.3.0/24 0.0.0.0 0 32768 ?
*> 192.168.1.1/32 0.0.0.0 0 32768 ?
*> 192.168.2.2/32 10.12.1.2 0 0 65200 ?
*> 192.168.3.3/32 10.12.1.2 0 65200 65300 ?R2# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
* 10.12.1.0/24 10.12.1.1 0 0 65100 ?
*> 0.0.0.0 0 32768 ?
* 10.23.1.0/24 10.23.1.3 0 0 65300 ?
*> 0.0.0.0 0 32768 ?
*> 172.16.1.0/24 10.12.1.1 0 0 65100 ?
*> 172.16.2.0/24 10.12.1.1 0 0 65100 ?
*> 172.16.3.0/24 10.12.1.1 0 0 65100 ?
*> 192.168.1.1/32 10.12.1.1 0 0 65100 ?
*> 192.168.2.2/32 0.0.0.0 0 32768 ?
*> 192.168.3.3/32 10.23.1.3 0 0 65300 ?R3# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.12.1.0/24 10.23.1.2 0 0 65200 ?
* 10.23.1.0/24 10.23.1.2 0 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 172.16.1.0/24 10.23.1.2 0 65200 65100 ?
*> 172.16.2.0/24 10.23.1.2 0 65200 65100 ?
*> 172.16.3.0/24 10.23.1.2 0 65200 65100 ?
*> 192.168.1.1/32 10.23.1.2 0 65200 65100 ?
*> 192.168.2.2/32 10.23.1.2 0 0 65200 ?
*> 192.168.3.3/32 0.0.0.0 0 32768 ?R1 aggregates all the stub networks (172.16.1.0/24, 172.16.2.0/24, and 172.16.3.0/24) into a 172.16.0.0/20 summary route
R2 aggregates all the router’s loopback addresses into a 192.168.0.0/16 summary route
R1# show running-config | section router bgp
router bgp 65100
bgp log-neighbor-changes
aggregate-address 172.16.0.0 255.255.240.0
redistribute connected
neighbor 10.12.1.2 remote-as 65200R2# show running-config | section router bgp
router bgp 65200
bgp log-neighbor-changes
no bgp default ipv4-unicast
neighbor 10.12.1.1 remote-as 65100
neighbor 10.23.1.3 remote-as 65300
!
address-family ipv4
aggregate-address 192.168.0.0 255.255.0.0
redistribute connected
neighbor 10.12.1.1 activate
neighbor 10.23.1.3 activate
exit-address-family
R1# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
* 10.12.1.0/24 10.12.1.2 0 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 10.12.1.2 0 0 65200 ?
*> 172.16.0.0/20 0.0.0.0 32768 i >>> R1 will also install
*> 172.16.1.0/24 0.0.0.0 0 32768 ?
*> 172.16.2.0/24 0.0.0.0 0 32768 ?
*> 172.16.3.0/24 0.0.0.0 0 32768 ?
*> 192.168.0.0/16 10.12.1.2 0 0 65200 i >>> summary received with AS of only 65200 loosing all previous AS PATH info
*> 192.168.1.1/32 0.0.0.0 0 32768 ?
*> 192.168.2.2/32 10.12.1.2 0 0 65200 ?
*> 192.168.3.3/32 10.12.1.2 0 65200 65300 ?R2# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
* 10.12.1.0/24 10.12.1.1 0 0 65100 ?
*> 0.0.0.0 0 32768 ?
* 10.23.1.0/24 10.23.1.3 0 0 65300 ?
*> 0.0.0.0 0 32768 ?
*> 172.16.0.0/20 10.12.1.1 0 0 65100 i
*> 172.16.1.0/24 10.12.1.1 0 0 65100 ?
*> 172.16.2.0/24 10.12.1.1 0 0 65100 ?
*> 172.16.3.0/24 10.12.1.1 0 0 65100 ?
*> 192.168.0.0/16 0.0.0.0 32768 i
*> 192.168.1.1/32 10.12.1.1 0 0 65100 ?
*> 192.168.2.2/32 0.0.0.0 0 32768 ?
*> 192.168.3.3/32 10.23.1.3 0 0 65300 ?R3# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.12.1.0/24 10.23.1.2 0 0 65200 ?
* 10.23.1.0/24 10.23.1.2 0 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 172.16.0.0/20 10.23.1.2 <<< 0 65200 65100 i
*> 172.16.1.0/24 10.23.1.2 0 65200 65100 ?
*> 172.16.2.0/24 10.23.1.2 0 65200 65100 ?
*> 172.16.3.0/24 10.23.1.2 0 65200 65100 ?
*> 192.168.0.0/16 10.23.1.2 <<< 0 0 65200 i
*> 192.168.1.1/32 10.23.1.2 0 65200 65100 ?
*> 192.168.2.2/32 10.23.1.2 0 0 65200 ?
*> 192.168.3.3/32 0.0.0.0 0 32768 ?Notice that the 172.16.0.0/20 and 192.168.0.0/16 network prefixes are visible, but the smaller component network prefixes still exist on all the routers. The aggregate-address command advertises the aggregated network prefix in addition to the original component network prefixes. The optional summary-only keyword suppresses the component network prefixes in the summarized network prefix range.
Configuration with the summary-only keyword.
R1# show running-config | section router bgp
router bgp 65100
bgp log-neighbor-changes
aggregate-address 172.16.0.0 255.255.240.0 summary-only
redistribute connected
neighbor 10.12.1.2 remote-as 65200R2# show running-config | section router bgp
router bgp 65200
bgp log-neighbor-changes
no bgp default ipv4-unicast
neighbor 10.12.1.1 remote-as 65100
neighbor 10.23.1.3 remote-as 65300
!
address-family ipv4
aggregate-address 192.168.0.0 255.255.0.0 summary-only
redistribute connected
neighbor 10.12.1.1 activate
neighbor 10.23.1.3 activate
exit-address-familyR3# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.12.1.0/24 10.23.1.2 0 0 65200 ?
* 10.23.1.0/24 10.23.1.2 0 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 172.16.0.0/20 10.23.1.2 0 65200 65100 i
*> 192.168.0.0/16 10.23.1.2 0 0 65200 i
*> 192.168.3.3/32 0.0.0.0 0 32768 ?R2# show bgp ipv4 unicast
BGP table version is 10, local router ID is 192.168.2.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
* 10.12.1.0/24 10.12.1.1 0 0 65100 ?
*> 0.0.0.0 0 32768 ?
* 10.23.1.0/24 10.23.1.3 0 0 65300 ?
*> 0.0.0.0 0 32768 ?
*> 172.16.0.0/20 10.12.1.1 0 0 65100 i
*> 192.168.0.0/16 0.0.0.0 32768 i
s> 192.168.1.1/32 10.12.1.1 0 0 65100 ? >>> suppressed routes
s> 192.168.2.2/32 0.0.0.0 0 32768 ? >>> suppressed routes
s> 192.168.3.3/32 10.23.1.3 0 0 65300 ? >>> suppressed routes
! all component routes of summary route are suppressed as shown above due to summary-only keyworda summary discard route is installed to Null0 as a loop-prevention mechanism, this null0 route is generated on summarizing router only
R2# show ip route bgp | begin Gateway
Gateway of last resort is not set
172.16.0.0/20 is subnetted, 1 subnets
B 172.16.0.0 [20/0] via 10.12.1.1, 00:06:18
B 192.168.0.0/16 [200/0], 00:05:37, Null0
192.168.1.0/32 is subnetted, 1 subnets
B 192.168.1.1 [20/0] via 10.12.1.1, 00:02:15
192.168.3.0/32 is subnetted, 1 subnets
B 192.168.3.3 [20/0] via 10.23.1.3, 00:02:15R1 suppressing component routes in Loc-RIB
R1# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
* 10.12.1.0/24 10.12.1.2 0 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 10.12.1.2 0 0 65200 ?
*> 172.16.0.0/20 0.0.0.0 32768 i
s> 172.16.1.0/24 0.0.0.0 0 32768 ?
s> 172.16.2.0/24 0.0.0.0 0 32768 ?
s> 172.16.3.0/24 0.0.0.0 0 32768 ?
*> 192.168.0.0/16 10.12.1.2 0 0 65200 i
*> 192.168.1.1/32 0.0.0.0 0 32768 ?R1# show ip route bgp | begin Gateway
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
B 10.23.1.0/24 [20/0] via 10.12.1.2, 00:12:50
172.16.0.0/16 is variably subnetted, 7 subnets, 3 masks
B 172.16.0.0/20 [200/0], 00:06:51, Null0
B 192.168.0.0/16 [20/0] via 10.12.1.2, 00:06:10The Atomic Aggregate Attribute
Summarized routes act like new BGP routes with a shorter prefix length.
When a BGP router summarizes a route, it does not advertise the AS_Path information from before the route was summarized.
Also path attributes like multi-exit discriminator (MED), and BGP communities are not included in the new BGP aggregate prefix. The atomic aggregate attribute indicates that a loss of path information has occurred.
R2 can be configured to summarize the 172.16.0.0/20 and 192.168.0.0/16 routes with component route suppression
R2# show running-config | section router bgp
router bgp 65200
bgp log-neighbor-changes
no bgp default ipv4-unicast
neighbor 10.12.1.1 remote-as 65100
neighbor 10.23.1.3 remote-as 65300
!
address-family ipv4
aggregate-address 192.168.0.0 255.255.0.0 summary-only
aggregate-address 172.16.0.0 255.255.240.0 summary-only
redistribute connected
neighbor 10.12.1.1 activate
neighbor 10.23.1.3 activateR2 is aggregating and suppressing R1’s component networks (172.16.1.0/24, 172.16.2.0/24, and 172.16.3.0/24) into the 172.16.0.0/20 summary route
The component network prefixes maintain an AS_Path of 65100 on R2
with the aggregate 172.16.0.0/20 appears to be locally generated on R2.
From R3’s perspective, R2 does not advertise R1’s stub networks; instead, it is advertising the 172.16.0.0/20 network as its own
The AS_Path for the 172.16.0.0/20 route on R3 is simply AS 65200 and does not include AS 65100
R2# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
* 10.12.1.0/24 10.12.1.1 0 0 65100 ?
*> 0.0.0.0 0 32768 ?
* 10.23.1.0/24 10.23.1.3 0 0 65300 ?
*> 0.0.0.0 0 32768 ?
*> 172.16.0.0/20 0.0.0.0 32768 i >>> summarized looks like
>>> locally originated route
s> 172.16.1.0/24 10.12.1.1 0 0 65100 ? >>> while these original
s> 172.16.2.0/24 10.12.1.1 0 0 65100 ? >>> component routes
s> 172.16.3.0/24 10.12.1.1 0 0 65100 ? >>> with real AS PATH
>>> are suppressed
*> 192.168.0.0/16 0.0.0.0 32768 i
s> 192.168.1.1/32 10.12.1.1 0 0 65100 ?
s> 192.168.2.2/32 0.0.0.0 0 32768 ?
s> 192.168.3.3/32 10.23.1.3 0 0 65300 ?R3’s BGP entry for the 172.16.0.0/20 prefix
R3# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.12.1.0/24 10.23.1.2 0 0 65200 ?
* 10.23.1.0/24 10.23.1.2 0 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 172.16.0.0/20 10.23.1.2 0 0 65200 i
*> 192.168.0.0/16 10.23.1.2 0 0 65200 i
*> 192.168.3.3/32 0.0.0.0 0 32768 ?Drilling down into it further we see that routes were summarized by AS 65200 by the router with the router ID (RID) 192.168.2.2
In addition, the atomic aggregate attribute has been set to indicate a loss of path attributes such as AS_Path in this scenario.
R3# show bgp ipv4 unicast 172.16.0.0
BGP routing table entry for 172.16.0.0/20, version 25
Paths: (1 available, best #1, table default)
Not advertised to any peer
Refresh Epoch 2
65200, (aggregated by 65200 192.168.2.2)
10.23.1.2 from 10.23.1.2 (192.168.2.2)
Origin IGP, metric 0, localpref 100, valid, external, atomic-aggregate, best
rx pathid: 0, tx pathid: 0x0Route Aggregation with AS_SET
To keep the component route’s BGP path information, the optional as-set keyword may be used with the aggregate-address command
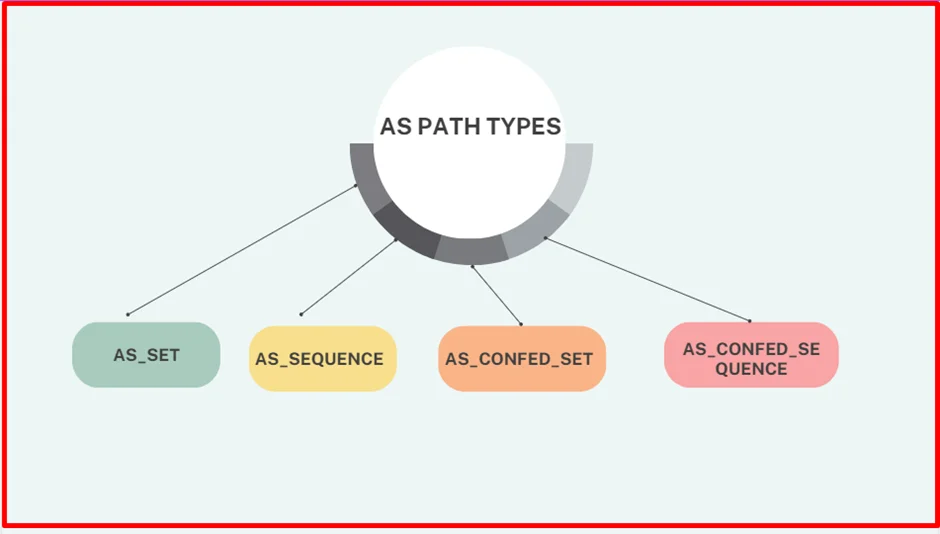
There are two types of copy actions that take place inside the AS Path of the aggregate route in BGP
- AS_SEQUENCE copy – this is when all component routes have same AS_PATH info and that is copied over as is (without { })
R3# show bgp ipv4 unicast 172.16.0.0
BGP routing table entry for 172.16.0.0/20, version 30
Paths: (1 available, best #1, table default)
Not advertised to any peer
Refresh Epoch 2
65200 65100, (aggregated by 65200 192.168.2.2)
10.23.1.2 from 10.23.1.2 (192.168.2.2)
Origin incomplete, metric 0, localpref 100, valid, external, best
rx pathid: 0, tx pathid: 0x0- AS_SET – this is when multiple component routes have differing AS_PATH, They are displayed inside { } counts as only one AS hop
R2# show bgp ipv4 unicast 192.168.0.0
BGP routing table entry for 192.168.0.0/16, version 28
Paths: (1 available, best #1, table default)
Advertised to update-groups:
1
Refresh Epoch 1
{65100,65300}, (aggregated by 65200 192.168.2.2)
0.0.0.0 from 0.0.0.0 (192.168.2.2)
Origin incomplete, localpref 100, weight 32768, valid, aggregated, local, best
rx pathid: 0, tx pathid: 0x0Configuring as-set for differing prefixes
R2# show running-config | section router bgp
router bgp 65200
bgp log-neighbor-changes
no bgp default ipv4-unicast
neighbor 10.12.1.1 remote-as 65100
neighbor 10.23.1.3 remote-as 65300
!
address-family ipv4
aggregate-address 192.168.0.0 255.255.0.0 as-set summary-only
aggregate-address 172.16.0.0 255.255.240.0 as-set summary-only
redistribute connected
neighbor 10.12.1.1 activate
neighbor 10.23.1.3 activateWe check 172.16.0.0/20 summary route again, now with the BGP path information copied into it . Notice that the AS_Path information now contains AS 65100.
R3# show bgp ipv4 unicast 172.16.0.0
BGP routing table entry for 172.16.0.0/20, version 30
Paths: (1 available, best #1, table default)
Not advertised to any peer
Refresh Epoch 2
65200 65100, (aggregated by 65200 192.168.2.2)
10.23.1.2 from 10.23.1.2 (192.168.2.2)
Origin incomplete, metric 0, localpref 100, valid, external, best
rx pathid: 0, tx pathid: 0x0R3# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.12.1.0/24 10.23.1.2 0 0 65200 ?
* 10.23.1.0/24 10.23.1.2 0 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 172.16.0.0/20 10.23.1.2 0 0 65200 65100 ?
*> 192.168.3.3/32 0.0.0.0 0 32768 ?Did you notice that the 192.168.0.0/16 summary route is no longer present in R3’s BGP table? The reason for this is on R2; R2 is summarizing all the loopback networks from R1 (AS 65100), R2 (AS 65200), and R3 (AS 65300). And now that R2 is copying the BGP AS_Path attributes of all the component network prefixes into the AS_SET information, the AS_Path for the 192.168.0.0/16 summary route contains AS 65300. When the aggregate is advertised to R3, R3 discards that prefix because it sees its own AS_Path in the advertisement and thinks that it is a loop.
R2# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
* 10.12.1.0/24 10.12.1.1 0 0 65100 ?
*> 0.0.0.0 0 32768 ?
* 10.23.1.0/24 10.23.1.3 0 0 65300 ?
*> 0.0.0.0 0 32768 ?
*> 172.16.0.0/20 0.0.0.0 100 32768 65100 ?
s> 172.16.1.0/24 10.12.1.1 0 0 65100 ?
s> 172.16.2.0/24 10.12.1.1 0 0 65100 ?
s> 172.16.3.0/24 10.12.1.1 0 0 65100 ?
*> 192.168.0.0/16 0.0.0.0 100 32768 {65100,65300} ?
s> 192.168.1.1/32 10.12.1.1 0 0 65100 ?
s> 192.168.2.2/32 0.0.0.0 0 32768 ?
s> 192.168.3.3/32 10.23.1.3 0 0 65300 ?R2# show bgp ipv4 unicast 192.168.0.0
BGP routing table entry for 192.168.0.0/16, version 28
Paths: (1 available, best #1, table default)
Advertised to update-groups:
1
Refresh Epoch 1
{65100,65300}, (aggregated by 65200 192.168.2.2)
0.0.0.0 from 0.0.0.0 (192.168.2.2)
Origin incomplete, localpref 100, weight 32768, valid, aggregated, local, best
rx pathid: 0, tx pathid: 0x0R1 does not install the 192.168.0.0/16 summary route for the same reason that R3 does not install the 192.168.0.0/16 summary route. R1 thinks that the advertisement is a loop because it detects AS 65100 in AS_Path. You can confirm this by examining R1’s BGP table
R1# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
* 10.12.1.0/24 10.12.1.2 0 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 10.12.1.2 0 0 65200 ?
*> 172.16.1.0/24 0.0.0.0 0 32768 ?
*> 172.16.2.0/24 0.0.0.0 0 32768 ?
*> 172.16.3.0/24 0.0.0.0 0 32768 ?
*> 192.168.1.1/32 0.0.0.0 0 32768 ?Solution here would be not to use as-set command
IPv6 Summarization
The same process for summarizing or aggregating IPv4 prefixes occurs with IPv6 prefixes, and the format is identical except that the configuration is placed under the IPv6 address family using the command aggregate-address prefix/prefix-length [summary-only] [as-set]
Summarization of the IPv6 loopback addresses (2001:db8:::1/128, 2001:db8:::2/128, and 2001:db8::3/128) and R1/R3’s stub networks (2001:db8:0:1::/64 and 2001:db8:0:3/64) is fairly simple as they all fall into the base IPv6 summary range 2001:db8:0:0::/64
The fourth hextet, beginning with a decimal value of 1, 2, or 3, would consume only 2 bits; the range could be summarized easily into the 2001:db8:0:0::/62 (or 2001:db8::/62) network range.
R2# show running-config | section router bgprouter bgp 65200
bgp router-id 192.168.2.2
bgp log-neighbor-changes
neighbor 2001:DB8:0:12::1 remote-as 65100
neighbor 2001:DB8:0:23::3 remote-as 65300
!
address-family ipv4
no neighbor 2001:DB8:0:12::1 activate
no neighbor 2001:DB8:0:23::3 activate
!
address-family ipv6
network 2001:DB8::2/128
network 2001:DB8:0:12::/64
network 2001:DB8:0:23::/64
aggregate-address 2001:DB8::/58 summary-only
neighbor 2001:DB8:0:12::1 activate
neighbor 2001:DB8:0:23::3 activateshows the BGP tables on R1 and R3. Notice that all the smaller component routes are summarized and suppressed into the 2001:db8::/58 summary route, as expected.
R3# show bgp ipv6 unicast | b Network
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8::/58 2001:DB8:0:23::2 0 0 65200 i
*> 2001:DB8::3/128 :: 0 32768 i
*> 2001:DB8:0:3::/64 :: 0 32768 i
*> 2001:DB8:0:23::/64 :: 0 32768 iR1# show bgp ipv6 unicast | b Network
Network Next Hop Metric LocPrf Weight Path
*> 2001:DB8::/58 2001:DB8:0:12::2 0 0 65200 i
*> 2001:DB8::1/128 :: 0 32768 ?
*> 2001:DB8:0:1::/64 :: 0 32768 ?
*> 2001:DB8:0:12::/64 :: 0 32768 ?BGP Route Filtering and Manipulation
Controlling what we learn and advertise can give us control and security, simply relying on peer to be able to install any prefix into our routing domain is not a good idea
IOS XE provides four methods of filtering routes inbound or outbound for a specific BGP peer. Each of these methods can be used individually, or they can be used simultaneously with other methods:
There are multiple ways of filtering or allowing prefixes from BGP neighbors
- Route maps
- Filter List
- AS_Path ACL filtering
- Prefix List or
- Distribute List
A BGP neighbor cannot use a distribute list (ACL) and prefix list at the same time in the same direction (inbound or outbound).
If all are applied together on a BGP neighbor, following are the order of operation for both inbound and outbound
RFAP|D
Filtering on below Loc-RIB
R1# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.3.3.0/24 10.12.1.2 33 0 65200 65300 3003 ?
* 10.12.1.0/24 10.12.1.2 22 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 10.12.1.2 333 0 65200 ?
*> 100.64.2.0/25 10.12.1.2 22 0 65200 ?
*> 100.64.2.192/26 10.12.1.2 22 0 65200 ?
*> 100.64.3.0/25 10.12.1.2 22 0 65200 65300 300 ?
*> 192.168.1.1/32 0.0.0.0 0 32768 ?
*> 192.168.2.2/32 10.12.1.2 22 0 65200 ?
*> 192.168.3.3/32 10.12.1.2 3333 0 65200 65300 ?Distribute List Filtering
Distribute lists has the allow or whitelisting effect
Distribute list uses standard or extended ACLs
Remember that extended ACLs for BGP use the source fields to match the network portion and the destination fields to match against the network mask
The first entry allows any network that starts in the 192.168.0.0 to 192.168.255.255 range with a network length of only /32. The second entry allows networks that contain the 100.64.x.0 pattern with prefix length /25 to demonstrate the wildcard abilities of an extended ACL with BGP
R1
ip access-list extended ACL-ALLOW
permit ip 192.168.0.0 0.0.255.255 host 255.255.255.255
permit ip 100.64.0.0 0.0.255.0 host 255.255.255.128
!
router bgp 65100
neighbor 10.12.1.2 remote-as 65200
address-family ipv4
neighbor 10.12.1.2 distribute-list ACL-ALLOW inThe 100.64.2.192/26 network is rejected because the prefix length or mask does not match the second ACL-ALLOW entry while two of the networks in the 100.64.x.0 pattern (100.64.2.0/25 and 100.64.3.0/25) are accepted
R1# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.12.1.0/24 0.0.0.0 0 32768 ?
*> 100.64.2.0/25 10.12.1.2 22 0 65200 ?
*> 100.64.3.0/25 10.12.1.2 22 0 65200 65300 300 ?
*> 192.168.1.1/32 0.0.0.0 0 32768 ?
*> 192.168.2.2/32 10.12.1.2 22 0 65200 ?
*> 192.168.3.3/32 10.12.1.2 3333 0 65200 65300 ?Prefix List Filtering
Prefix list also has the whitelisting effect same as distribute list but instead of ACL uses prefix list
A prefix list called RFC1918 is created to permit only prefixes in the RFC1918 address space.
R1# configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
R1(config)# ip prefix-list RFC1918 seq 10 permit 10.0.0.0/8 le 32
R1(config)# ip prefix-list RFC1918 seq 20 permit 172.16.0.0/12 le 32
R1(config)# ip prefix-list RFC1918 seq 30 permit 192.168.0.0/16 le 32
R1(config)# router bgp 65100
R1(config-router)# address-family ipv4 unicast
R1(config-router-af)# neighbor 10.12.1.2 prefix-list RFC1918 inNotice that the 100.64.2.0/25, 100.64.2.192/26, and 100.64.3.0/25 routes are filtered as they do not fall within the prefix list matching criteria.
R1# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.3.3.0/24 10.12.1.2 33 0 65200 65300 3003 ?
* 10.12.1.0/24 10.12.1.2 22 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 10.12.1.2 333 0 65200 ?
*> 192.168.1.1/32 0.0.0.0 0 32768 ?
*> 192.168.2.2/32 10.12.1.2 22 0 65200 ?
*> 192.168.3.3/32 10.12.1.2 3333 0 65200 65300 ?AS_Path Filtering
There may be times when conditionally matching prefixes may be too complicated, and identifying all routes from a specific organization is preferred, in such cases we can use AS PATH ACL to filer out routes using regex against AS PATH PA
| Modifier | Description |
|---|---|
| _ (underscore) | Matches a space |
| ^ (caret) | Indicates the start of the string |
| $ (dollar sign) | Indicates the end of the string |
| [] (brackets) | Matches a single character or nesting within a range |
| – (hyphen) | Indicates a range of numbers in brackets |
| [^] (caret in brackets) | Excludes the characters listed in brackets |
| () (parentheses) | Used for nesting of search patterns |
| | (pipe) | Provides or functionality to the query |
| . (period) | Matches a single character, including a space |
| * (asterisk) | Matches zero or more characters or patterns |
| + (plus sign) | Matches one or more instances of the character or pattern |
| ? (question mark) | Matches one or no instances of the character or pattern |
BGP table can be parsed with regex using the command show bgp afi safi regexp regex-pattern
so we can test locally before applying it to neighbor
R2# show bgp ipv4 unicast
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.0.0/24 172.32.23.3 0 0 300 80 90 21003 2100 i
*> 172.16.4.0/23 172.32.23.3 0 0 300 878 1190 1100 1010 i
*> 172.16.16.0/22 172.32.23.3 0 0 300 779 21234 45 i
*> 172.16.99.0/24 172.32.23.3 0 0 300 145 40 i
*> 172.16.129.0/24 172.32.23.3 0 0 300 10010 300 1010 40 50 i
*> 192.168.0.0/16 172.16.12.1 0 0 100 80 90 21003 2100 i
*> 192.168.4.0/23 172.16.12.1 0 0 100 878 1190 1100 1010 i
*> 192.168.16.0/22 172.16.12.1 0 0 100 779 21234 45 i
*> 192.168.99.0/24 172.16.12.1 0 0 100 145 40 i
*> 192.168.129.0/24 172.16.12.1 0 0 100 10010 300 1010 40 50 iAS_Path for the 172.16.129.0/24 route includes AS 300 twice non-consecutively for a specific purpose. This would not be seen in real life because it indicates a routing loop.
_ (Underscore) – Matches a space – AS anywhere regardless of AS position as origin or transit or last AS
Display prefixes coming via AS 100 (regardless of AS 100 position as last or transit or origin AS)
R2# show bgp ipv4 unicast regex 100
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.0.0/24 172.32.23.3 0 0 300 80 90 21003 2100 i
*> 172.16.4.0/23 172.32.23.3 0 0 300 878 1190 1100 1010 i
*> 172.16.129.0/24 172.32.23.3 0 0 300 10010 300 1010 40 50 i
*> 192.168.0.0/16 172.16.12.1 0 0 100 80 90 21003 2100 i
*> 192.168.4.0/23 172.16.12.1 0 0 100 878 1190 1100 1010 i
*> 192.168.16.0/22 172.16.12.1 0 0 100 779 21234 45 i
*> 192.168.99.0/24 172.16.12.1 0 0 100 145 40 i
*> 192.168.129.0/24 172.16.12.1 0 0 100 10010 300 1010 40 50 iabove did not work so lets try again, The regex query includes the following unwanted ASN: 10010.
R2# show bgp ipv4 unicast regexp _100
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.129.0/24 172.32.23.3 0 0 300 10010 300 1010 40 50 i <<<
*> 192.168.0.0/16 172.16.12.1 0 0 100 80 90 21003 2100 i
*> 192.168.4.0/23 172.16.12.1 0 0 100 878 1190 1100 1010 i
*> 192.168.16.0/22 172.16.12.1 0 0 100 779 21234 45 i
*> 192.168.99.0/24 172.16.12.1 0 0 100 145 40 i
*> 192.168.129.0/24 172.16.12.1 0 0 100 10010 300 1010 40 iStill did not work, lets try _ before and after _
R2# show bgp ipv4 unicast regexp _100_
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 192.168.0.0/16 172.16.12.1 0 0 100 80 90 21003 2100 i
*> 192.168.4.0/23 172.16.12.1 0 0 100 878 1190 1100 1010 i
*> 192.168.16.0/22 172.16.12.1 0 0 100 779 21234 45 i
*> 192.168.99.0/24 172.16.12.1 0 0 100 145 40 i
*> 192.168.129.0/24 172.16.12.1 0 0 100 10010 300 1010 40 50 iThis one worked because it satisfies the condition of AS 100 existing as either last, or transit, or as origin
^ (Caret) – start of the string – Last AS
Display only prefixes that were advertised from directly connected AS 300 or last AS 300.
R2# show bgp ipv4 unicast regexp ^300_
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.0.0/24 172.32.23.3 0 0 300 80 90 21003 2100 i
*> 172.16.4.0/23 172.32.23.3 0 0 300 878 1190 1100 1010 i
*> 172.16.16.0/22 172.32.23.3 0 0 300 779 21234 45 i
*> 172.16.99.0/24 172.32.23.3 0 0 300 145 40 i
*> 172.16.129.0/24 172.32.23.3 0 0 300 10010 300 1010 40 50 i$ (Dollar Sign) – End of the string
Display only prefixes that originated in AS 40
R2# show bgp ipv4 unicast regexp _40$
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.99.0/24 172.32.23.3 0 0 300 145 40 i
*> 192.168.99.0/24 172.16.12.1 0 100 0 100 145 40 i[ ] (Brackets) – Matches a single character – used for common characters in same place
Display only prefixes with an AS that contains 11 or 14 in it
R2# show bgp ipv4 unicast regexp _1[14]_
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.4.0/23 172.32.23.3 0 0 300 878 14 1100 1010 i
*> 172.16.99.0/24 172.32.23.3 0 0 300 14 40 i
*> 192.168.4.0/23 172.16.12.1 0 0 100 878 1190 14 1010 i
*> 192.168.99.0/24 172.16.12.1 0 0 100 14 40 i– Hyphen (range matching to reduce the regex size)
Display only prefixes with the last two digits of the AS (40, 50, 60, 70, or 80).
R2# show bgp ipv4 unicast regexp [4-8]0_
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.0.0/24 172.32.23.3 0 0 300 80 90 21003 2100 i
*> 172.16.99.0/24 172.32.23.3 0 0 300 145 40 i
*> 172.16.129.0/24 172.32.23.3 0 0 300 10010 300 1010 40 50 i
*> 192.168.0.0/16 172.16.12.1 0 0 100 80 90 21003 2100 i
*> 192.168.99.0/24 172.16.12.1 0 0 100 145 40 i
*> 192.168.129.0/24 172.16.12.1 0 0 100 10010 300 1010 40 50 i[^] (Caret in Brackets) – Excludes the character
Display only prefixes where the second AS from AS 100 or AS 300 does not start with 3, 4, 5, 6, 7, or 8
The first component of the regex query restricts the AS to start with 100 or 300 with the regex query ^[13]00_
and the second component filters out AS starting with 3 through 8 with the regex filter _[^3-8].
R2# show bgp ipv4 unicast regexp ^[13]00_[^3-8]
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.99.0/24 172.32.23.3 0 0 300 145 40 i
*> 172.16.129.0/24 172.32.23.3 0 0 300 10010 300 1010 40 50 i
*> 192.168.99.0/24 172.16.12.1 0 0 100 145 40 i
*> 192.168.129.0/24 172.16.12.1 0 0 100 10010 300 1010 40 50 i^[3][0-9]+_[3][0-9]+_[3][0-9]+_
frr.routeviews.org> show bgp ipv4 unicast regexp ^[3][0-9]+_[3][0-9]+_[3][0-9]+_
BGP table version is 264529750, local router ID is 128.223.51.23, vrf id 0
Default local pref 100, local AS 65123
Status codes: s suppressed, d damped, h history, u unsorted, * valid, > best, = multipath,
i internal, r RIB-failure, S Stale, R Removed
Nexthop codes: @NNN nexthop's vrf id, < announce-nh-self
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
V*> 1.6.9.0/24 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i
V*> 1.6.11.0/24 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i
V*> 1.6.12.0/22 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i
V*> 1.6.13.0/24 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i
V*> 1.6.17.0/24 128.223.253.9 0 3582 3701 3356 2914 9583 i
V*= 128.223.253.10 0 3582 3701 3356 2914 9583 i
V*> 1.6.19.0/24 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i
V*> 1.6.32.0/22 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i
V*> 1.6.40.0/22 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i
V*> 1.6.48.0/22 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i
V*> 1.6.56.0/22 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i
V*> 1.6.59.0/24 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i
V*> 1.6.67.0/24 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i
V*> 1.6.69.0/24 128.223.253.9 0 3582 3701 3356 6453 4755 9583 i
V*= 128.223.253.10 0 3582 3701 3356 6453 4755 9583 i( ) and | (Parentheses and Pipe) – for ‘or’ functionality
AS_Path ends with AS 40 or 45 in it
R2# show bgp ipv4 unicast regexp _4(5|0)$
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.16.0/22 172.32.23.3 0 0 300 779 21234 45 i
*> 172.16.99.0/24 172.32.23.3 0 0 300 145 40 i
*> 192.168.16.0/22 172.16.12.1 0 0 100 779 21234 45 i
*> 192.168.99.0/24 172.16.12.1 0 0 100 145 40 i. (Period) – single character, including a space
Display only prefixes originating from single digit AS
R2# show bgp ipv4 unicast regexp _.$
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.16.0/22 172.32.23.3 0 0 300 779 21234 4 i
*> 172.16.99.0/24 172.32.23.3 0 0 300 145 4 i
*> 172.16.129.0/24 172.32.23.3 0 0 300 10010 300 1010 40 5 i
*> 192.168.16.0/22 172.16.12.1 0 0 100 779 21234 4 i
*> 192.168.99.0/24 172.16.12.1 0 0 100 145 4 i
*> 192.168.129.0/24 172.16.12.1 0 0 100 10010 300 1010 40 5 ito match prefixes originating from 2 digit AS
show bgp ipv4 unicast regexp _[0-9][0-9]?$
or
show bgp ipv4 unicast regexp _..$+ (Plus Sign) – one or more instances of the character or pattern.
Display only prefixes that contain “at least one 10” in the AS path but where the pattern 100 should not be used in matching
R2# show bgp ipv4 unicast regexp (10)+[^(100)]
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.4.0/23 172.32.23.3 0 0 300 878 1190 1100 1010 i
*> 172.16.129.0/24 172.32.23.3 0 0 300 10010 300 1010 40 50 i
*> 192.168.4.0/23 172.16.12.1 0 0 100 878 1190 1100 1010 i
*> 192.168.129.0/24 172.16.12.1 0 0 100 10010 300 1010 40 50 i
(133388)+
frr.routeviews.org> show bgp ipv4 unicast regexp (133388)+
BGP table version is 264877433, local router ID is 128.223.51.23, vrf id 0
Default local pref 100, local AS 65123
Status codes: s suppressed, d damped, h history, u unsorted, * valid, > best, = multipath,
i internal, r RIB-failure, S Stale, R Removed
Nexthop codes: @NNN nexthop's vrf id, < announce-nh-self
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
V*> 1.7.24.0/24 128.223.253.9 0 3582 3701 11164 4637 64049 55836 9583 133388 133388 133388 133388 i
V*= 128.223.253.10 0 3582 3701 11164 4637 64049 55836 9583 133388 133388 133388 133388 i
N*> 162.44.150.0/23 128.223.253.9 0 3582 3701 174 55410 133388 i
N*= 128.223.253.10 0 3582 3701 174 55410 133388 i
N*> 162.44.150.0/24 128.223.253.10 0 3582 3701 11164 4637 64049 55836 55410 133388 i
N*= 128.223.253.9 0 3582 3701 11164 4637 64049 55836 55410 133388 i
N*> 162.44.151.0/24 128.223.253.10 0 3582 3701 11164 4637 64049 55836 55410 133388 i
N*= 128.223.253.9 0 3582 3701 11164 4637 64049 55836 55410 133388 i
N*> 162.44.250.0/24 128.223.253.10 0 3582 3701 11164 4637 64049 55836 55410 133388 i
N*= 128.223.253.9 0 3582 3701 11164 4637 64049 55836 55410 133388 i? (Question Mark) – one or no instances of the character or pattern.
Display only prefixes from the neighboring AS or its directly connected AS (that is, restrict to two ASs away).
You must use the Ctrl+V escape sequence before entering the ?.
R1# show bgp ipv4 unicast regexp ^[0-9]+ ([0-9]+)?$
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.99.0/24 172.32.23.3 0 0 300 40 i
*> 192.168.99.0/24 172.16.12.1 0 100 0 100 40 i* (Asterisk) – zero or more characters or patterns.
Display all prefixes from any AS
decoding .*
. means any character including symbols, alphabets and numbers and * means 0 or more
combining the two means any character 0 or more times which will include content that is null empty (zero) or more (anything)
This may seem like a useless task, but it might be a valid requirement when using AS_Path access lists, which are explained in the following section.
R1# show bgp ipv4 unicast regexp .*
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 172.16.0.0/24 172.32.23.3 0 0 300 80 90 21003 2100 i
*> 172.16.4.0/23 172.32.23.3 0 0 300 1080 1090 1100 1110 i
*> 172.16.16.0/22 172.32.23.3 0 0 300 11234 21234 31234 i
*> 172.16.99.0/24 172.32.23.3 0 0 300 40 i
*> 172.16.129.0/24 172.32.23.3 0 0 300 10010 300 30010 30050 i
*> 192.168.0.0/16 172.16.12.1 0 100 0 100 80 90 21003 2100 i
*> 192.168.4.0/23 172.16.12.1 0 100 0 100 1080 1090 1100 1110 i
*> 192.168.16.0/22 172.16.12.1 0 100 0 100 11234 21234 31234 i
*> 192.168.99.0/24 172.16.12.1 0 100 0 100 40 i
*> 192.168.129.0/24 172.16.12.1 0 100 0 100 10010 300 30010 30050 iDifference to remember between + * and ?
+ is 1 or more
while ? and * are more similar to one another
? is 0 or one
* is 0 or more / multiple
AS_Path ACLs
Selecting routes from a BGP neighbor by using AS_Path requires the definition of an AS_Path ACL
The AS_Path ACL processing is performed in a sequential top-down order just like normal ACL,
and the first qualifying match processes against the appropriate permit or deny action.
An implicit deny exists at the end of the AS path ACL.
R2# show bgp ipv4 unicast neighbors 10.12.1.1 advertised-routes | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.3.3.0/24 10.23.1.3 33 0 65300 3003 ?
*> 10.12.1.0/24 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 0.0.0.0 0 32768 ?
*> 100.64.2.0/25 0.0.0.0 0 32768 ?
*> 100.64.2.192/26 0.0.0.0 0 32768 ?
*> 100.64.3.0/25 10.23.1.3 3 0 65300 300 ?
*> 192.168.2.2/32 0.0.0.0 0 32768 ?
*> 192.168.3.3/32 10.23.1.3 333 0 65300 ?
Total number of prefixes 8R2 is advertising the routes learned from R3 (AS 65300) to R1, using an AS_Path ACL to restrict the advertisement of only AS 65200 routes is recommended.
R2 using an AS_Path ACL to restrict traffic to only “locally originated” traffic using the regex pattern ^$
R2
ip as-path access-list 1 permit ^$
!
router bgp 65200
address-family ipv4 unicast
neighbor 10.12.1.1 filter-list 1 out
neighbor 10.23.1.3 filter-list 1 outR2# show bgp ipv4 unicast neighbors 10.12.1.1 advertised-routes | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.12.1.0/24 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 0.0.0.0 0 32768 ?
*> 100.64.2.0/25 0.0.0.0 0 32768 ?
*> 100.64.2.192/26 0.0.0.0 0 32768 ?
*> 192.168.2.2/32 0.0.0.0 0 32768 ?
Total number of prefixes 5Route Maps
Route maps provide more functionality than pure filtering; they provide a method to manipulate BGP path attributes, Route maps are applied on a BGP neighbor basis for routes that are advertised or received. A different route map can be used for each direction
R1# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.1.1.0/24 0.0.0.0 0 32768 ?
*> 10.3.3.0/24 10.12.1.2 33 0 65200 65300 3003 ?
* 10.12.1.0/24 10.12.1.2 22 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 10.12.1.2 333 0 65200 ?
*> 100.64.2.0/25 10.12.1.2 22 0 65200 ?
*> 100.64.2.192/26 10.12.1.2 22 0 65200 ?
*> 100.64.3.0/25 10.12.1.2 22 0 65200 65300 300 ?
*> 192.168.1.1/32 0.0.0.0 0 32768 ?
*> 192.168.2.2/32 10.12.1.2 22 0 65200 ?
*> 192.168.3.3/32 10.12.1.2 3333 0 65200 65300 ?Step 1. Deny any routes that are in the 192.168.0.0/16 network by using a prefix list.
Step 2. Match any routes originating from AS 65200 that are within the 100.64.0.0/10 network range and set the BGP local preference to 222.
Step 3. Match any routes originating from AS 65200 that did not match step 2 and set the BGP weight to 65200.
Step 4. Permit all other routes to process.
R1
ip prefix-list FIRST-RFC1918 permit 192.168.0.0/16 le 32
ip as-path access-list 1 permit _65200$
ip prefix-list SECOND-CGNAT permit 100.64.0.0/10 le 32
!
route-map AS65200IN deny 10
description Deny any RFC1918 networks via Prefix List Matching
match ip address prefix-list FIRST-RFC1918
route-map AS65200IN permit 20
description Change local preference for AS65200 originate route in 100.64.x.x/10
match ip address prefix-list SECOND-CGNAT
match as-path 1
set local-preference 222
route-map AS65200IN permit 30
description Change the weight for AS65200 originate routes
match as-path 1
set weight 65200
route-map AS65200IN permit 40
description Permit all other routes un-modified
!
router bgp 65100
neighbor 10.12.1.2 remote-as 65200
address-family ipv4 unicast
neighbor 10.12.1.2 route-map AS65200IN indisplays R1’s BGP routing table, which shows that the following actions occurred:
The 192.168.2.2/32 and 192.168.3.3/32 routes were discarded. The 192.168.1.1/32 route is a locally generated route.
The 100.64.2.0/25 and 100.64.2.192/26 networks had the local preference modified to 222 because they originate from AS 65200 and are within the 100.64.0.0/10 network range.
The 10.12.1.0/24 and 10.23.1.0/24 routes from R2 have been assigned the locally significant BGP attribute weight 65,200.
All other routes were received and not modified.
R1# show bgp ipv4 unicast | b Network
Network Next Hop Metric LocPrf Weight Path
*> 10.1.1.0/24 0.0.0.0 0 32768 ?
*> 10.3.3.0/24 10.12.1.2 33 0 65200 65300 3003 ?
r> 10.12.1.0/24 10.12.1.2 22 65200 65200 ?
r 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 10.12.1.2 333 65200 65200 ?
*> 100.64.2.0/25 10.12.1.2 22 222 0 65200 ?
*> 100.64.2.192/26 10.12.1.2 22 222 0 65200 ?
*> 100.64.3.0/25 10.12.1.2 22 0 65200 65300 300 ?
*> 192.168.1.1/32 0.0.0.0 0 32768 ?clear ip bgp
A hard reset tears down and rebuilds the peering sessions and rebuilds the BGP routing tables
Hard neighborship reset
clear ip bgp *
clear ip bgp neighbor-address
clear ip bgp peer-group group-nameSoft Reconfiguration
A soft reconfiguration uses stored prefix cache without tearing down existing peering sessions at the cost of additional memory for storing the updates, Soft reconfiguration is not on by default and needs to be configured for inbound on neighbors at least, Soft reconfiguration can be configured for inbound or outbound sessions.
neighbor soft-reconfiguration inbound
clear ip bgp 10.100.0.1 soft inRoute Refresh
route refresh capability allows the local router to reset inbound routing tables dynamically by sending route refresh requests given the neighbor not just supports it but also negotiated route refresh capability
clear ip bgp 172.16.10.2 inBGP Communities
BGP communities are optional attributes that let routers attach tags to routes so other routers can apply routing policies (like prefer, filter, or modify routes) without inspecting prefixes in detail.
A BGP community is an optional transitive BGP attribute that can traverse from AS to AS.
A BGP community is a 32-bit number that can be included with a route
A BGP community can be displayed as a full 32-bit number (0 through 4,294,967,295) or as two 16-bit numbers (0 through 65535):(0 through 65535), commonly referred to as new format.
By convention, with private BGP communities, the first 16 bits represent the AS of the community and the second 16 bits represent a pattern defined by the originating AS
Format
- 32-bit value
- Usually written as:
ASN:VALUE(e.g.65000:100)
Well-known standard communities
These have predefined meanings:
no-export→ do not advertise to eBGP peersno-advertise→ do not advertise to any peerinternet→ advertise everywhere
Extended BGP communities:
Format
- 64-bit value
- Structured into sub-fields, not just a single number
- Encoded as Type + Value
Examples (vendor CLI format varies):
rt 65000:100(Route Target)soo 65000:200(Site of Origin)
What they’re used for
Extended communities were introduced to solve the limitations of standard communities, especially for:
- MPLS VPNs
- L3VPN / L2VPN
- Advanced traffic engineering
- EVPN
- Policy precision across large networks
Common types of extended communities
- Route Target (RT) – controls VPN route import/export
- Route Distinguisher-related signaling
- Site of Origin (SoO) – prevents routing loops
- Bandwidth, color, QoS, and traffic engineering attributes
Advantages
Much more expressive
Globally meaningful when standardized
Safer for large multi-AS or service provider networks
Designed for scalable VPN and EVPN environments
Enabling BGP Community Support
IOS XE routers do not advertise BGP communities to peers by default. Communities are enabled on a neighbor-by-neighbor basis
neighbor ip-address send-community [standard | extended | both]
! If a keyword is not specified, standard communities are sent by defaultIOS XE nodes can display communities in new format, and they are easier to read if you use the global configuration command
ip bgp-community new-format! DECIMAL FORMAT
R3# show bgp 192.168.1.1
! Output omitted for brevity
BGP routing table entry for 192.168.1.1/32, version 6
Community: 6553602 6577023! New-Format
R3# show bgp 192.168.1.1
! Output omitted for brevity
BGP routing table entry for 192.168.1.1/32, version 6
Community: 100:2 100:23423Well-Known Communities
RFC 1997 defined a set of global communities (known as well-known communities) that use the community range 4,294,901,760 (0xFFFF0000) to 4,294,967,295 (0xFFFFFFFF).
All routers that are capable of sending/receiving BGP communities must implement well-known communities.
The following are the common well-known communities:
- Internet
- No_Advertise
- No_Export
- Local AS
The No_Advertise BGP Community
For the No_Advertise community (0xFFFFFF02 or 4,294,967,042), routes should not be advertised to any BGP peer. The No_Advertise BGP community can be advertised from an upstream BGP peer or locally with an inbound BGP policy.
In either method, the No_Advertise community is set in the BGP Loc-RIB table that affects outbound route advertisement. The No_Advertise community is set with the command set community no-advertise within a route map

R1 is advertising the 10.1.1.0/24 route to R2.
R2 sets the BGP No_Advertise community on the prefix on an inbound route map associated with R1.
R2 does not advertise the 10.1.1.0/24 route to R3
Notice that the route was “not advertised to any peer” and has the BGP community No_Advertise set.
R2# show bgp 10.1.1.0/24
! Output omitted for brevity
BGP routing table entry for 10.1.1.0/24, version 18
Paths: (1 available, best #1, table default, not advertised to any peer)
Not advertised to any peer
Refresh Epoch 1
100, (received & used)
10.1.12.1 from 10.1.12.1 (192.168.1.1)
Origin IGP, metric 0, localpref 100, valid, external, best
Community: no-advertiseYou can quickly see BGP routes that are set with the No_Advertise community by using the command show bgp afi safi community no-advertise
R2# show bgp ipv4 unicast community no-advertise
! Output omitted for brevity
Network Next Hop Metric LocPrf Weight Path
*> 10.1.1.0/24 10.1.12.1 0 0 100 iThe No_Export BGP Community
When a route is received with the No_Export community (0xFFFFFF01 or 4,294,967,041), the route is not advertised to any eBGP peer. If the router receiving the No_Export route is a confederation member, the route can be advertised to other sub-ASs in the confederation
The No_Export community is set with the command set community no-export within a route map.
AS 200 is a BGP confederation composed of member AS 65100 and AS 65200
R1 is advertising the 10.1.1.0/24 route to R2, and R2 sets the No_Export community on an inbound route map associated with R1. R2 advertises the prefix to R3, and R3 advertises the prefix to R4. R4 does not advertise the prefix to R5 because it is an eBGP session
Notice that R4 display not advertised to EBGP peer.
R3# show bgp ipv4 unicast 10.1.1.0/24
BGP routing table entry for 10.1.1.0/24, version 6
Paths: (1 available, best #1, table default, not advertised to EBGP peer)
Advertised to update-groups:
3
Refresh Epoch 1
100, (Received from a RR-client), (received & used)
10.1.23.2 from 10.1.23.2 (192.168.2.2)
Origin IGP, metric 0, localpref 100, valid, confed-internal, best
Community: no-exportR4# show bgp ipv4 unicast 10.1.1.0/24
! Output omitted for brevity
BGP routing table entry for 10.1.1.0/24, version 4
Paths: (1 available, best #1, table default, not advertised to EBGP peer)
Not advertised to any peer
Refresh Epoch 1
(65100) 100, (received & used)
10.1.23.2 (metric 20) from 10.1.34.3 (192.168.3.3)
Origin IGP, metric 0, localpref 100, valid, confed-external, best
Community: no-exportYou can see all the BGP prefixes that contain the No_Export community by using the command show bgp afi safi community no-export
R4# show bgp ipv4 unicast community no-export | b Network
Network Next Hop Metric LocPrf Weight Path
*> 10.1.1.0/24 10.1.23.2 0 100 0 (65100) 100 iR2# show bgp ipv4 unicast community no-export | b Network
Network Next Hop Metric LocPrf Weight Path
*> 10.1.1.0/24 10.1.12.1 0 0 100 iThe Local AS (No_Export_SubConfed) BGP Community
With the No_Export_SubConfed community (0xFFFFFF03 or 4,294,967,043), known as the local AS community, a route is not advertised outside the local AS. The local AS community is set with the command set community local-as within a route map.
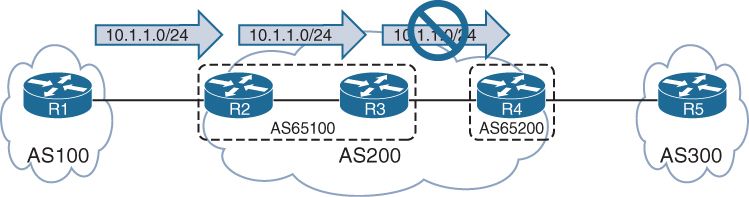
R2 sets the local AS community on an inbound route map associated with R1. R2 advertises the prefix to R3, but R3 does not advertise the prefix to R4 because the prefix contains the local AS community.
R3# show bgp ipv4 unicast 10.1.1.0/24
BGP routing table entry for 10.1.1.0/24, version 8
Paths: (1 available, best #1, table default, not advertised outside local AS)
Not advertised to any peer
Refresh Epoch 1
100, (Received from a RR-client), (received & used)
10.1.23.2 from 10.1.23.2 (192.168.2.2)
Origin IGP, metric 0, localpref 100, valid, confed-internal, best
Community: local-ASYou can see all the BGP prefixes that contain the local AS community by using the command show bgp afi safi community local-as
R3# show bgp ipv4 unicast community local-AS | b Network
Network Next Hop Metric LocPrf Weight Path
*>i 10.1.1.0/24 10.1.23.2 0 100 0 100 iR2# show bgp ipv4 unicast community local-AS | b Network
Network Next Hop Metric LocPrf Weight Path
*> 10.1.1.0/24 10.1.12.1 0 0 100 iConditionally Matching BGP Communities
R1# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.1.1.0/24 0.0.0.0 0 32768 ?
* 10.12.1.0/24 10.12.1.2 22 0 65200 ?
*> 0.0.0.0 0 32768 ?
*> 10.23.1.0/24 10.12.1.2 333 0 65200 ?
*> 192.168.1.1/32 0.0.0.0 0 32768 ?
*> 192.168.2.2/32 10.12.1.2 22 0 65200 ?
*> 192.168.3.3/32 10.12.1.2 3333 0 65200 65300 ?show bgp afi safi detail and then manually select a route with a specific community. However, if the BGP community is known, you can display all the routes by using the command show bgp afi safi community community, as shown in the following snippet:
R1# show bgp ipv4 unicast community 333:333 | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.23.1.0/24 10.12.1.2 333 0 65200 ?10.23.1.0/24 route and all the BGP path attributes. Notice that two BGP communities (333:333 and 65300:333) are added to the path.
R1# show ip bgp 10.23.1.0/24
BGP routing table entry for 10.23.1.0/24, version 15
Paths: (1 available, best #1, table default)
Not advertised to any peer
Refresh Epoch 3
65200
10.12.1.2 from 10.12.1.2 (192.168.2.2)
Origin incomplete, metric 333, localpref 100, valid, external, best
Community: 333:333 65300:333 <<<
rx pathid: 0, tx pathid: 0x0Conditionally matching requires the creation of a community list that shares a structure similar to that of an ACL
Standard community lists are numbered 1 to 99 and match either well-known communities or a private community number (as-number:16-bit-number)
Expanded community lists are numbered 100 to 500 and use regex patterns.
When multiple communities are on the same ip community list statement, all communities for that statement must exist in that route’s community list. If only one out of many communities is required, you can use multiple ip community list statements.
ip community 1 permit 11:100 11:200BGP community list that matches on the community 333:333
The BGP community list is then used in the first sequence of route map COMMUNITY-CHECK, which denies any routes with that community.
The second route map sequence allows for all other BGP routes and sets the BGP weight (locally significant) to 111. The route map is then applied on routes advertised from R2 toward R1.
R1
ip community-list 100 permit 333:333
!
route-map COMMUNITY-CHECK deny 10
description Block Routes with Community 333:333 in it
match community 100
route-map COMMUNITY-CHECK permit 20
description Allow routes with either community in it
set weight 111
!
router bgp 65100
neighbor 10.12.1.2 remote-as 65200
address-family ipv4 unicast
neighbor 10.12.1.2 route-map COMMUNITY-CHECK in10.23.1.0/24 prefix is discarded, and all the other prefixes learned from AS 65200 have the BGP weight set to 111
R1# show bgp ipv4 unicast | begin Network
Network Next Hop Metric LocPrf Weight Path
*> 10.1.1.0/24 0.0.0.0 0 32768 ?
* 10.12.1.0/24 10.12.1.2 22 111 65200 ?
*> 0.0.0.0 0 32768 ?
*> 192.168.1.1/32 0.0.0.0 0 32768 ?
*> 192.168.2.2/32 10.12.1.2 22 111 65200 ?
*> 192.168.3.3/32 10.12.1.2 3333 111 65200 65300 ?Setting Private BGP Communities
You set a private BGP community in a route map by using the command set community bgp-community [additive]. By default, when you set a community, any existing communities are overwritten, but you can preserve them by using the optional additive keyword.
10.23.1.0/24 route, which has the 333:333 and 65300:333 BGP communities. The 10.3.3.0/24 route has the 65300:300 community.
R1# show bgp ipv4 unicast 10.23.1.0/24
! Output omitted for brevity
BGP routing table entry for 10.23.1.0/24, version 15
65200
10.12.1.2 from 10.12.1.2 (192.168.2.2)
Origin incomplete, metric 333, localpref 100, valid, external, best
Community: 333:333 65300:333R1# show bgp ipv4 unicast 10.3.3.0/24
! Output omitted for brevity
BGP routing table entry for 10.3.3.0/24, version 12
65200 65300 3003
10.12.1.2 from 10.12.1.2 (192.168.2.2)
Origin incomplete, metric 33, localpref 100, valid, external, best
Community: 65300:300When additive keyword is not used, so the previous community values of 333:333 and 65300:333 are overwritten with the 10:23 community.
ip prefix-list PREFIX10.23.1.0 seq 5 permit 10.23.1.0/24
ip prefix-list PREFIX10.3.3.0 seq 5 permit 10.3.3.0/24
!
route-map SET-COMMUNITY permit 10
match ip address prefix-list PREFIX10.23.1.0
set community 10:23
route-map SET-COMMUNITY permit 20
match ip address prefix-list PREFIX10.3.3.0
set community 3:0 3:3 10:10 additive
route-map SET-COMMUNITY permit 30
!
router bgp 65100
address-family ipv4
neighbor 10.12.1.2 route-map SET-COMMUNITY inAfter the route map has been applied and the routes have been refreshed, the path attributes can be examined
As anticipated, the previous BGP communities are removed for the 10.23.1.0/24 route, but they are maintained with the 10.3.3.0/24 route.
R1# show bgp ipv4 unicast 10.23.1.0/24
! Output omitted for brevity
BGP routing table entry for 10.23.1.0/24, version 22
65200
10.12.1.2 from 10.12.1.2 (192.168.2.2)
Origin incomplete, metric 333, localpref 100, valid, external, best
Community: 10:23R1# show bgp ipv4 unicast 10.3.3.0/24
BGP routing table entry for 10.3.3.0/24, version 20
65200 65300 3003
10.12.1.2 from 10.12.1.2 (192.168.2.2)
Origin incomplete, metric 33, localpref 100, valid, external, best
Community: 3:0 3:3 10:10 65300:300Maximum Prefix
Multiple Internet outages have occurred because routers have received more routes than they can handle. The BGP maximum prefix feature restricts the number of routes that are received from a BGP peer.
Prefix limits are typically set for BGP peers on low-end routers as a safety mechanism to ensure that they do not become overloaded.
You can have routers place prefix restrictions on a BGP neighbor by using the BGP address family configuration command neighbor ip-address maximum-prefix prefix-count [warning-percentage] [restart time] [warning-only].
When a peer advertises more routes than the maximum prefix count, the peer moves the neighbor to the Idle (PfxCt) state in the finite-state machine (FSM)
closes the BGP session, and sends out the appropriate syslog message. The BGP session is not automatically reestablished by default. This behavior prevents a continuous cycle of loading routes, resetting the session, and reloading the routes. If you want to restart the BGP session after a certain amount of time, you can use the optional keyword restart time.
A warning is not generated before the prefix limit is reached. By adding a warning percentage (set to 1 to 100) after the maximum prefix count, you can have a warning message sent when the percentage is exceeded. The command for a maximum of 100 prefixes with a warning threshold of 75 is maximum-prefix 100 75. When the threshold is reached, the router reports the following warning message:
%ROUTING-BGP-5-MAXPFX : No. of IPv4 Unicast prefixes received from
192.168.1.1 has reached 75, max 100You can change the maximum prefix behavior of closing the BGP session by using the optional keyword warning-only so that a warning message is generated instead.
router bgp 65100
neighbor 10.12.1.2 remote-as 65200
!
address-family ipv4
neighbor 10.12.1.2 activate
neighbor 10.12.1.2 maximum-prefix 7shows that the 10.12.1.2 neighbor has exceeded the maximum prefix threshold and shut down the BGP session.
R1# show bgp ipv4 unicast summary | begin Neighbor
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
10.12.1.2 4 65200 0 0 1 0 0 00:01:14 Idle (PfxCt)R1# show log | include BGP
05:10:04.989: %BGP-5-ADJCHANGE: neighbor 10.12.1.2 Up
05:10:04.990: %BGP-4-MAXPFX: Number of prefixes received from 10.12.1.2 (afi 0)
reaches 6, max 7
05:10:04.990: %BGP-3-MAXPFXEXCEED: Number of prefixes received from 10.12.1.2
(afi 0): 8 exceeds limit 7
05:10:04.990: %BGP-3-NOTIFICATION: sent to neighbor 10.12.1.2 6/1
(Maximum Number of Prefixes Reached) 7 bytes 00010100 000007
05:10:04.990: %BGP-5-NBR_RESET: Neighbor 10.12.1.2 reset
(Peer over prefix limit)
05:10:04.990: %BGP-5-ADJCHANGE: neighbor 10.12.1.2 Down Peer over prefix limitIOS XE Peer Groups
IOS XE peer groups simplify BGP configuration and reduce system resource use (CPU and memory) by grouping BGP peers together into BGP update groups. BGP update groups enable a router to perform the outbound routing policy processing one time and then replicate the update to all the members (as opposed to performing the outbound routing policy processing for every router).
The routers in a BGP peer group must contain the same outbound routing policy and same bgp connection type iBGP or eBGP
In addition to enhancing router performance, BGP peer groups simplify the BGP configuration
All routers in the peer group are in the same update group and therefore must be of the same session type: internal (iBGP) or external (eBGP).
Members of a peer group can have a unique inbound routing policy.
router bgp 100
no bgp default ipv4-unicast
neighbor AS100 peer-group
neighbor AS100 remote-as 100
neighbor AS100 update-source Loopback0
neighbor 192.168.2.2 peer-group AS100
neighbor 192.168.3.3 peer-group AS100
neighbor 192.168.4.4 peer-group AS100
!
address-family ipv4
neighbor AS100 next-hop-self
neighbor 192.168.2.2 activate
neighbor 192.168.3.3 activate
neighbor 192.168.4.4 activateIOS XE Peer Templates
A restriction for BGP peer groups is that they require all neighbors to have the same outbound routing policy.
BGP peer templates allow for a reusable pattern of settings that can be applied as needed in a hierarchical format through inheritance and nesting of templates.
If a conflict exists between an inherited configuration and the invoking peer template, the invoking template preempts the inherited value
There are two types of BGP peer templates:
- Peer session: This template allows bgp neighbor configuration, template peer-session template-name and then enter any BGP session-related configuration commands.
- Peer policy: This template allows loc-RIB related configuration, template peer-policy template-name and then enter any BGP address family–related configuration commands.
BGP neighbor 10.12.1.2 invokes TEMPLATE-PARENT-POLICY for address family policy settings. TEMPLATE-PARENT-POLICY sets the inbound route map to FILTERROUTES and invokes TEMPLATE-CHILD-POLICY, which sets the maximum prefix limit to 10.
router bgp 100
template peer-policy TEMPLATE-PARENT-POLICY
route-map FILTERROUTES in
inherit peer-policy TEMPLATE-CHILD-POLICY 20
exit-peer-policy
!
template peer-policy TEMPLATE-CHILD-POLICY
maximum-prefix 10
exit-peer-policy
!
bgp log-neighbor-changes
neighbor 10.12.1.2 remote-as 200
!
address-family ipv4
neighbor 10.12.1.2 activate
neighbor 10.12.1.2 inherit peer-policy TEMPLATE-PARENT-POLICYA BGP peer can be associated with either a peer group or a template but not both.
A BGP peer can be attached to either peer group or peer template
BGP Deterministic MED
https://ipwithease.com/understanding-bgp-deterministic-med/
To understand the use of BGP deterministic-MED we must first understand behavior of BGP algorithm when a route is received on a router via multiple paths
As prefixes are being received, BGP algorithm assigns the first valid path as the current best path
This first valid path is then compared with the next path that is received for “same prefix”
1st and 2nd path are compared and out them the one chosen as best is then compared with 3rd path and so on until the end of paths is reached – best paths are compared as they are being received
Because of above behavior we can have an effect where it looks like MED is not being used.
Similar to BGP always compare-MED feature that ensures the MED gets compared when different AS are advertising the same route
BGP Deterministic-med feature ensures the MED gets compared deterministically for a routes advertised from different paths in same AS.
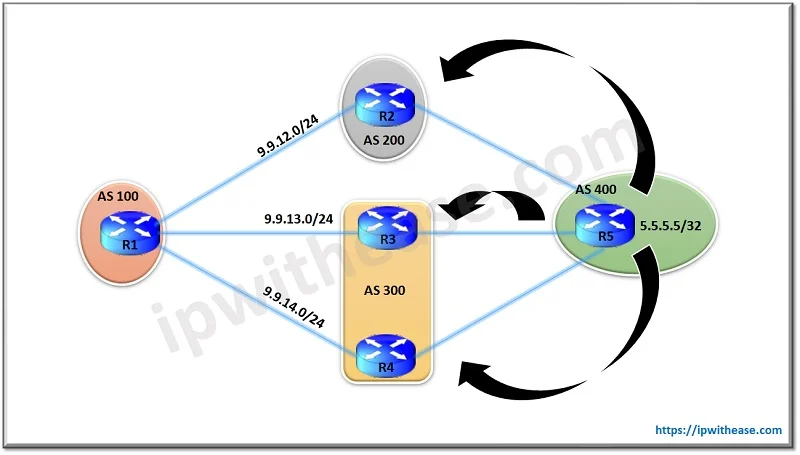
show ip bgp 5.5.5.5
BGP routing table entry for 5.5.5.5/32, version 29
Paths: (3 available, best #3, table Default-IP-Routing-Table)
Flag: 0x4842
Advertised to update-groups:
1
300 400
9.9.13.3 from 9.9.13.3
Origin IGP, metric 100, localpref 100, valid, external
200 400
9.9.12.2 from 9.9.12.2
Origin IGP, metric 150, localpref 100, valid, external
300 400
9.9.14.4 from 9.9.14.4
Origin IGP, metric 200, localpref 100, valid, external, best <<<
N
WLLA
OMNI
MAR-CL N
Next hop - Valid
Weight - Higher weight
Local preference - Highest preference
Locally originated - locally originated preferred over learned from neighbors
AS Path - shorter AS Path
Origin - origin codes i over ?
MED - lower MED from same AS <<<
Neighbor type - ebgp over ibgp
IGP metric - lower IGP metric of next hop
Multipath - if configured then BGP will keep both
Age - oldest route that was learned <<<
Router ID - lower RID
CL - shorter Cluster list length
Neighbor address - lower Between the Route from R3 and R2 , R2 is chosen as the best path. This is so because the MED isn’t compared for BGP updates from R2 & R3 as they are part of different AS and as per BGP algorithms working the older route is preferred one which here is from R2 (because if you look at the output everything else is same)
Now comparing routes from R2 with route from R4 again MED isn’t compared as they are both from different AS. R4 being the older route here is preferred over the route from R2 and hence is selected as the best. So we see in this scenario how the MED working of preferring the lower MED updates hasn’t taken effect in this scenario.
To overcome this situation we use BGP deterministic-med
Deterministic-med groups all routes for a prefix from same AS under a same group in BGP table and then compare against each other, Then the best of the group is compared against the next group down
R1(config)#router bgp 100
R1(config-router)#bgp deterministic-medshow ip bgp 5.5.5.5
BGP routing table entry for 5.5.5.5/32, version 29
Paths: (3 available, best #3, table Default-IP-Routing-Table)
Flag: 0x4842
Advertised to update-groups:
1
200 400
9.9.12.2 from 9.9.12.2
Origin IGP, metric 100, localpref 100, valid, external
300 400
9.9.13.3 from 9.9.13.3
Origin IGP, metric 150, localpref 100, valid, external best <<<
300 400
9.9.14.4 from 9.9.14.4
Origin IGP, metric 200, localpref 100, valid, external,Now we see the table has been restructured and the routes with same AS path are grouped together.
Routes from R3 and R4 are compared because they are from same AS 300 and since route from R3 has lower MED it is best out of the group.
Now R3’s route is compared with the only route of other group i.e. from R2 and since both routes are from different AS, MED comparison will be skipped again, the route from R3 is older and it wins as best despite R2 having lower MED, this comparison still takes place because of belonging to same prefix
Dynamic BGP Neighbors
https://ipwithease.com/dynamic-bgp-peering/
we use the concept of BGP peer Group, where we can group the BGP Neighbors who are sharing the same outbound policies but with peer groups alone we need to manually configure 100 Peers and then add to the peer group so we need to combine it with another feature
Configuration step of iBGP Peer Group
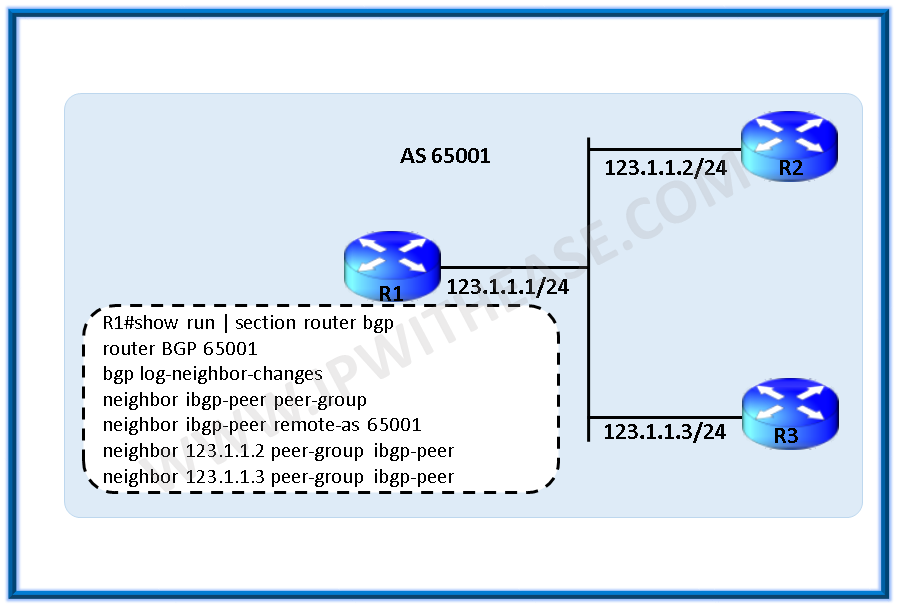
router bgp 65001
bgp log-neighbor-changes
neighbor ibgp-peers peer-group
neighbor ibgp-peers remote-as 65001
neighbor 123.1.1.2 peer-group ibgp-peers
neighbor 123.1.1.3 peer-group ibgp-peersConfiguration step of eBGP peer Group

ip route 1.1.1.2 255.255.255.255 123.1.1.2
ip route 1.1.1.3 255.255.255.255 123.1.1.3
router bgp 65001
bgp log-neighbor-changes
neighbor ebgp-peers peer-group
neighbor ebgp-peers ebgp-multihop 2
neighbor ebgp-peers update-source loopback0
neighbor 123.1.1.2 remote-as 65002
neighbor 123.1.1.2 peer-group ebgp-peers
neighbor 123.1.1.3 remote-as 65003
neighbor 123.1.1.3 peer-group ebgp-peersWith the Dynamic BGP peering feature, BGP router dynamically establishes peering with a group of remote neighbors that are configured using a range of IP addresses + BGP peer group.

R1(config-router)# neighbor dynamic-peers peer-groupCreate a global limit of BGP dynamic subnet range neighbors. The value ranges from 1 to 5000.
R1(config-router)# bgp listen limit 100define IP range for this peer-group
R1(config-router)# bgp listen range 172.16.0.0/16 peer-group dynamic-peersDefine the remote-as for the peer group, optionally, define the list of AS numbers that can be accepted to form neighborship with, max limit of alternate-as numbers is 5
R1(config-router)# neighbor dynamic-peers remote-as 65002 alternate-as 65003 65004Activate the peer group under ipv4 address-family, just like we activate a neighbor
R1(config-router)#address-family ipv4
R1(config-router-af)# neighbor dynamic-peers activate.Full configuration
R1
router bgp 65001
bgp log-neighbor-changes
bgp listen range 172.16.0.0/16 peer-group dynamic-peers
neighbor dynamic-peers peer-group
neighbor dynamic-peers remote-as 65002 alternate-as 65003 65004
!
address-family ipv4
neighbor dynamic-peers activate
exit-address-familyR2
router bgp 65002
bgp log-neighbor-changes
!
neighbor 172.16.1.1 remote-as 65001R3
router bgp 65003
bgp log-neighbor-changes
!
neighbor 172.16.2.1 remote-as 65001BGP router identifier 10.10.10.1, local AS number 65001
BGP table version is 1, main routing table version 1
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
*172.16.1.2 4 65002 4 4 1 0 0 00:00:38 0
*172.16.2.2 4 65003 4 2 1 0 0 00:00:29 0
! Dynamically created based on a listen range command
Dynamically created neighbors: 2, Subnet ranges: 1
BGP peer group Dynamic-peer listen range group members:
172.16.0.0/16
Total dynamically created neighbors: 2/(100 max), Subnet ranges: 1show tcp brief all
TCB Local Address Foreign Address (state)
A2B61B90 172.16.1.1.179 172.16.1.2.64321 ESTAB
A2B62F48 172.16.2.1.179 172.16.2.2.17764 ESTAB
A2B19B20 0.0.0.0.179 *.* LISTENThe output illustrates that the router is listening on port 179 but with foreign address of *.*
BGP Allowas-in
https://ipwithease.com/allowas-in-configuration-in-bgp-2/
BGP allowas-in feature allows a router to accept BGP routes that contain its own AS number in the AS path
R2(config)#router bgp 200
R2(config-router)#neighbor 192.168.23.2 allowas-inBGP local-AS
https://journey2theccie.wordpress.com/2020/06/15/bgp-as-path-manipulations/
The local-AS feature allows a router to fool its neighbor to have a different AS then real AS at “router bgp ” configuration, but only for neighborship, the real AS still appears in AS Path and then the faked AS
R1#sh run | s router bgp
router bgp 65000
bgp log-neighbor-changes
network 1.1.1.0 mask 255.255.255.0
neighbor 12.0.0.2 remote-as 2
neighbor 12.0.0.2 local-as 1 <<<R2#sh run | s router bgp
router bgp 2
bgp log-neighbor-changes
network 2.2.2.0 mask 255.255.255.0
neighbor 12.0.0.1 remote-as 1 <<<R2#show bgp | b Network
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.0/24 12.0.0.1 0 0 1 65000 iAs you can see, both AS numbers are there in the path. They also are there on routes that R1 is learning from R2, this fake AS really acts as another AS inserted in topology:
R1#sh ip bgp | b Network
Network Next Hop Metric LocPrf Weight Path
*> 2.2.2.0/24 12.0.0.2 0 0 1 2 i
There are a couple of ways to change this. First, if we want to stop the alternate ASN from being prepended when receiving routes, we can use no-prepend:
R1(config-router)#neighbor 12.0.0.2 local-as 1 no-prepend
R1#sh bgp | b Network
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.0/24 0.0.0.0 0 32768 i
*> 2.2.2.0/24 12.0.0.2 0 0 2 i
We can see that the routes learned from R2 no longer are showing 1 in the path. However, if we look at R2….
R2#sh bgp | b Network
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.0/24 12.0.0.1 0 0 1 65000 i
*> 2.2.2.0/24 0.0.0.0 0 32768 iBoth of our ASNs are in the path. So to stop the alternate ASN from being prepended when sending routes, we can use the following:
R1(config-router)#neighbor 12.0.0.2 local-as 1 no-prepend replace-asNow if we look at R2:
R2#sh bgp | b Network
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.0/24 12.0.0.1 0 0 1 i
*> 2.2.2.0/24 0.0.0.0 0 32768 i
We can see that only 1 is in the path. Using both the no-prepend replace-as keywords allow all routers to see the BGP advertisements as if they were running AS 1 in the BGP process.
There is still one more keyword for this command, and it is the dual-as keyword:
R1(config-router)#neighbor 12.0.0.2 local-as 1 no-prepend replace-as ?
dual-as Accept either real AS or local AS from the ebgp peer
<cr>This allows the remote peer to use either ASN for the BGP session. This feature is useful during migrations.
BGP remove-private-as
https://journey2theccie.wordpress.com/2020/06/15/bgp-as-path-manipulations/
There are situations where a customer with a single ISP may use a private ASN on the internet connection. In these cases, when the ISP forwards the customer’s prefix(s) out it will remove the private ASN in the process.
This is where Cisco router’s use the remove-private-as command. However, there are certain restrictions:
EBGP neighbors only
The private ASNs are removed from outbound updates
This only works if the path has only private ASNs in the AS_PATH. If there is a mix of public and private this will not work, however there is a way to fix this
If the AS_PATH contains the ASN of the EBGP neighbor, it won’t be removed
R1#sh run | s bgp
router bgp 65000
bgp log-neighbor-changes
network 1.1.1.0 mask 255.255.255.0
neighbor 12.0.0.2 remote-as 2R2#sh run | s bgp
router bgp 2
bgp log-neighbor-changes
neighbor 12.0.0.1 remote-as 65000
neighbor 24.0.0.4 remote-as 4R4#sh run | s router bgp
router bgp 4
bgp log-neighbor-changes
neighbor 24.0.0.2 remote-as 2If we look at R2 & R4, we can see they have learned the route with the private AS in the path:
R2#show ip bgp | b Network
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.0/24 12.0.0.1 0 0 65000 i
!
R4#sh bgp | b Network
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.0/24 24.0.0.2 0 2 65000 iSo let’s enable that command on R2 and see how it shows up on R4:
R2(config-router)#neighbor 24.0.0.4 remove-private-as
!
R4#sh bgp | b Network
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.0/24 24.0.0.2 0 2 i
That worked easily enough.
So remember what I said about not being able to do it when there are public and private AS numbers in the AS path? Let’s test that by adding a bunch of AS numbers to the path and see if it still works.
R1(config)#route-map PREPEND permit 10 R1(config-route-map)#set as-path prepend 1 10 100 R1(config-route-map)#exit R1(config)#router bgp 65000 R1(config-router)#neighbor 12.0.0.2 route-map PREPEND out
Let’s check the route back on R4:
R4#sh bgp | b Network
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.0/24 24.0.0.2 0 2 65000 1 10 100 iAs you can see, the private AS is still in the path because there are public AS numbers there and Cisco IOS assumes that the remote-private-as command was a misconfiguration. We can override this with the all keyword:
R2(config-router)#neighbor 24.0.0.4 remove-private-as allThis will remove private AS numbers regardless of what else is in the path. Let’s check R4:
R4#sh bgp | b Network
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.0/24 24.0.0.2 0 2 1 10 100 iPerfect, now the private AS is gone, but the rest of the ASNs remain.
Removal of AS shortens the path unintentionally so sometimes it is important to keep the ASN entries to equal number, instead of removing them, so instead we can use replace-as with remove-private-as
R2(config-router)#neighbor 24.0.0.4 remove-private-as all replace-as
!
R4#sh bgp | b Network
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.0/24 24.0.0.2 0 2 2 1 10 100 i
Now we can see our AS (2) in the path instead of the private AS of 65000.
BGP Conditional Advertisement
https://ipwithease.com/bgp-conditional-route-advertisement-using-non-exist-map-advertise-map/
By default BGP router advertises all best path routes from Loc-RIB to all its neighbors.
Using conditional advertisement some prefixes are advertised to one of the providers only if information from the other provider is not present. This will help keep routing symmetric
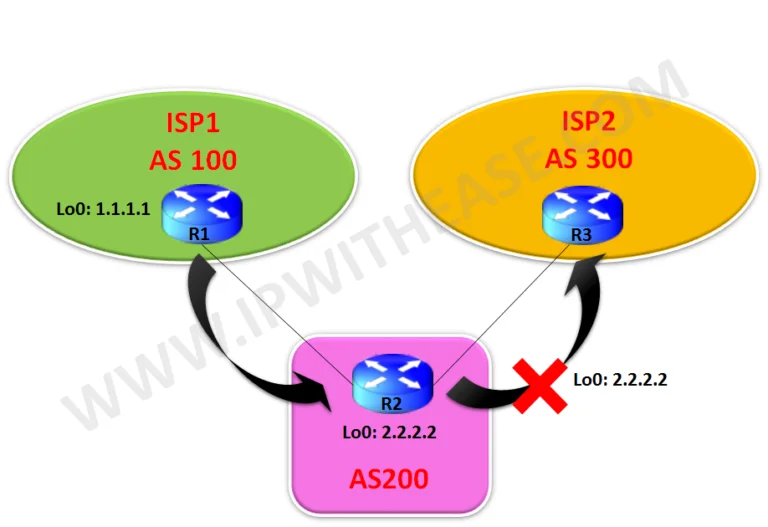
With the BGP conditional advertisement feature, you can now accomplish these tasks on R2:
- If 1.1.1.1/32 exists in R2’s BGP table, then do not advertise the 2.2.2.2/32 network to R3.
- If 1.1.1.1/32 does not exist in R2’s BGP table, then advertise the 2.2.2.2/32 network to R3.
R1
router bgp 100
bgp log-neighbor-changes
network 1.1.1.1 mask 255.255.255.255
neighbor 9.9.12.2 remote-as 200R2
router bgp 200
bgp log-neighbor-changes
network 2.2.2.2 mask 255.255.255.255
neighbor 9.9.12.1 remote-as 100
neighbor 9.9.23.3 remote-as 300
neighbor 9.9.23.3 advertise-map Advertise non-exist-map Non-Exist
!
access-list 10 permit 2.2.2.2
access-list 20 permit 1.1.1.1
!
route-map Non-Exist permit 10
match ip address 20
!
route-map Advertise permit 10
match ip address 10R3
router bgp 300
bgp log-neighbor-changes
neighbor 9.9.23.2 remote-as 200R2#sh ip bgp
BGP table version is 3, local router ID is 2.2.2.2Status codes: s suppressed, d damped, h history, * valid, > best, i – internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i – IGP, e – EGP, ? – incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.1/32 9.9.12.1 0 0 100 i
*> 2.2.2.2/32 0.0.0.0 0 32768 iR2#sh ip bgp neighbors 9.9.23.3 advertised-routes
BGP table version is 3, local router ID is 2.2.2.2Status codes: s suppressed, d damped, h history, * valid, > best, i – internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i – IGP, e – EGP, ? – incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.1/32 9.9.12.1 0 0 100 i
Total number of prefixes 1R3#sh ip bgp
BGP table version is 8, local router ID is 9.9.23.3Status codes: s suppressed, d damped, h history, * valid, > best, i – internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i – IGP, e – EGP, ? – incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 1.1.1.1/32 9.9.23.2 0 200 100 i <<<
! Only 1.1.1.1/32 is received and not 2.2.2.2Now we will shut down Lo0 interface on R1 to stop the advertisement of 1.1.1.1 to R2 and hence will see 2.2.2.2 is received on R3 now from R2.
R1(config)#int loop 0
R1(config-if)#shutdownR2#sh ip bgp neighbors 9.9.23.3 advertised-routes
BGP table version is 5, local router ID is 2.2.2.2Status codes: s suppressed, d damped, h history, * valid, > best, i – internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i – IGP, e – EGP, ? – incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 2.2.2.2/32 0.0.0.0 0 32768 i
Total number of prefixes 1R3#sh ip bgp
BGP table version is 10, local router ID is 9.9.23.3Status codes: s suppressed, d damped, h history, * valid, > best, i – internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i – IGP, e – EGP, ? – incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 2.2.2.2/32 9.9.23.2 0 0 200 iBGP Multipath
https://ipwithease.com/bgp-multipath-scenario/

R1(config)#router bgp 100
R1(config-router)#maximum-paths 2R1#sh ip bgp
BGP table version is 3, local router ID is 1.1.1.1
Status codes: s suppressed, d damped, h history, * valid, > best, i – internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i – IGP, e – EGP, ? – incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*m 4.4.4.4/32 9.9.12.2 0 200 i <<< ‘m’ means multipath enabled #
*> 9.9.13.3 0 200 iBGP Route Dampening
A route is considered to be flapping when its availability changes repeatedly. Route Dampening is a way to suppress flapping routes so that they are “suppressed” instead of being advertised.
Since BGP routing tables are huge, it’s not practical to send route flaps to neighbors, This could affect the performance of the network as well as consume more routers resources like CPU, As a best practice most ISPs use route dampening regularly.
https://ipwithease.com/bgp-route-dampening-configuration/
router bgp 1
no synchronization
bgp log-neighbor-changes
bgp dampening 10 750 2000 40 <<<
network 1.1.1.0 mask 255.255.255.0
network 192.168.12.0
neighbor 192.168.12.2 remote-as 2
no auto-summary- Penalty should be reduced by half after 10 minutes
- The dampened route must be reused when it reaches value of 750.
- Route should not be used when it reaches 2000 points.
- The routes experiencing Route flaps should not be suppressed for more than 40 minutes
R1#show ip bgp dampening parameters
dampening 10 750 2000 40
Half-life time : 10 mins Decay Time : 1550 secs
Max suppress penalty: 12000 Max suppress time: 40 mins
Suppress penalty : 2000 Reuse penalty : 750BGP backdoor
https://ipwithease.com/understanding-bgp-backdoor/
….The “Backdoor Feature” can be used to up the administrative distance of eBGP to 200 to make sure that IGP learned routes are given priority. This feature means that a backdoor network will be treated like a local one….
R1#
router bgp 100
network 9.9.0.2 mask 255.255.255.255 backdoor
neighbor 9.9.13.3 remote-as 300Impact of Load balancing due neighborship to loopbacks
+ difference between nexthop and advertising router
+ Multipathing to multiple paths through 1 neighbor vs 2 or more neighbors
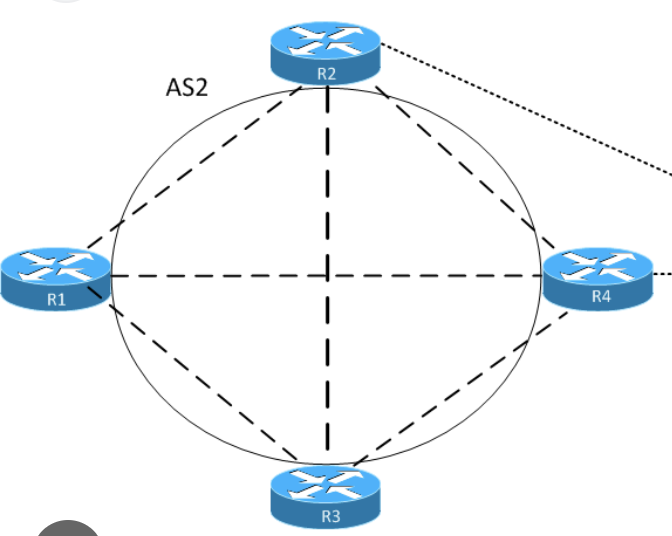
R3 has connected network 192.168.4.0/24 which is advertised in BGP
ibgp peering is only between R2 and R3,
while R1 and R4 are not participating in BGP
If direct link between R2 and R3 is lost
peering is reestablished via R1 and R4 because of peering using loopbacks
All loopbacks are advertised in IGP Multipath is enabled on R2
1. Given that R2 sees loopback of R3 from R1 and R4, how will bgp packets travel to R3?
2. Will it load balance traffic over both R1 and R4?
3. what will be “BGP” next hop for 192.168.4.0/24 on R2?
BGP control-plane traffic (the TCP session itself)
Usually: no per-packet balancing. Most routers do per-flow hashing for ECMP.
A single BGP session is typically:
- One TCP flow (same src/dst IPs + ports)
- So it gets hashed onto one of the ECMP paths (either via R1 or via R4)
It will only switch if:
- the chosen path fails, or
- the hash outcome changes
Data-plane traffic toward 192.168.4.0/24
Because not true next hop or non connected next hop is always recursively resolved, if the next-hop of ibgp in IGP is ECMP then data will be load balanced per flow.
R2 will forward traffic to the BGP next hop (R3 loopback), and if the IGP has ECMP to that loopback, then traffic to 192.168.4.0/24 can be load-balanced over R1 and R4 (again, typically per-flow hashing).
Important: “maximum-paths / BGP multipath on R2”
That only helps if R2 learns multiple BGP paths for 192.168.4.0/24 (different BGP next-hops, etc.).
Here R2 has only one iBGP neighbor (R3), so it only learns one BGP path. Multipath doesn’t create extra BGP paths; ECMP here comes from the IGP to the BGP next hop.
In case R1 and R4 are running bgp then next hop for 192.168.4.0/24 will be different and advertising router will be R3’s loopback address?
On R2, you will see:
- Next hop: ✅ R3’s loopback
- Advertising neighbor: not R3 but R1 or R4 (whoever sent the update) & RID: RID of R1 or R4
So:
✔ Advertising router ≠ next hop
✔ Next hop still points to R3 unless we use next-hop-self all on ibgp neighbor
✔ Traffic recursively follows IGP to R3 (possibly ECMP via R1/R4)
instances where you will see different next hop compared to advertising router is when route is coming from ebgp to ibgp network, on internal ibgp routes next hop is usually same as advertising router because ibgp never changes next hop when advertising to neighbor
next post
CCIE DHCP
DHCP
DHCP Client uses source port 68 and destination UDP port 67

DHCPDISCOVER
DHCPDISCOVER is a broadcast message to 255.255.255.255 and MAC address FFFF:FFFF:FFFF, The source IP address is 0.0.0.0, and the source MAC address is the MAC address of the sending device
DHCPOFFER
DHCP server if on subnet or remote, responds with DHCPOFFER, if more than one DHCP servers respond then client typically selects the server that sent the first DHCPOFFER response it received
DHCPREQUEST
DHCP client selects a server and responds by sending a broadcasted DHCPREQUEST message indicating that it will be using the address provided in the DHCPOFFER
DHCPDECLINE
This message is sent from a client to a DHCP server to inform the server that an IP address is already in use on the network.
DHCPACK
DHCP server responds to the client with a DHCPACK message indicating that the IP address is leased to the client and includes any additional DHCP options
DHCPNAK
A DHCP server sends this message to a client and informs the client that the DHCP server declines to provide the client with the requested IP configuration information.
DHCPRELEASE
A client sends this message to a DHCP server and informs the DHCP server that the client has released its DHCP lease, thus allowing the DHCP server to reassign the client IP address to another client.
DHCPINFORM
A client sends this message to a DHCP server and requests IP configuration parameters. Such a message might be sent from an access server requesting IP configuration information for a remote client attaching to the access server.
DHCP relay
If DHCP server is located in remote subnet then it gateway on client’s subnet need to have DHCP relay agent configured in order to forward the broadcast packets as unicast packets to the server
Routers dont just relay DHCP but can also relay following protocols to remote servers
- TFTP
- Domain Name System (DNS)
- Internet Time Service (ITS)
- NetBIOS name server
- NetBIOS datagram server
- BootP
- TACACS
Router interface as DHCP client
Router or switch can act as DHCP client to obtain IP address on its own interface “ip address dhcp”
Router interface as DHCP server
When router or switch is configured as a DHCP and pool is configured, excluding IP address with “ip dhcp excluded-address 10.8.8.1 10.8.8.10”, command prevents DHCP from assigning those IP addresses to a client. Note that you do not have to include the IP address of the router interface in this exclusion because the router never hands out its own interface IP address.
Potential DHCP issues
Helper address not configured: Router not configured with helper address under the interface facing clients – dhcp relay not configured
Incorrect Server configured: Incorrect DHCP server IP configured under helper address
Pool missing from DHCP server: Request originating from VLAN does not exist on DHCP server as pool, that VLAN or interface must also have IP address and helper configured
Pool exhaustion: DHCP pool could be out of IP addresses – pool exhaustion
High lease duration can cause pool exhaustion: A too high lease duration may cause pool exhaustion if you have more clients than the pool can support
Consider a wireless network at an airport. Let’s say there are 4096 addresses in the pool with a lease duration of 12 hours. Since users are typically not in an airport for more than 4 hours, this lease duration is too long, and the IP address will still be leased to that user until the lease expires, even if the user is no longer in the airport. Therefore, as the day progresses, more addresses are leased, until the pool is exhausted. So, setting a lower lease duration, such as 3 hours, would ensure that the lease expires sooner rather than later and helps prevent pool exhaustion.
Duplicate IP addresses: A DHCP server might hand out an IP address to a client that is already statically assigned to another host on the network. These duplicate IP addresses can cause connectivity issues for both the DHCP client and the host that was statically configured for the IP address.
next post
Multicast
Multicast
It allows a source to send packets to a group of destination hosts (receivers) in an efficient manner
IGMP operates on Layer 2 (on receivers’ side)
PIM operates on Layer 3 (Routed network)
Multicast starts from source and then branch out to receivers top to bottom
Multicast Source sits behind a router called First-Hop router or FHR
Router that has receivers connected is called Last-Hop router or LHR
on its LAN side it will have IGMP enabled, and also a role called IGMP querier will be active on that LAN side
Between these 2 routers, PIM will operate
Switch will run IGMP snooping in order to snoop the IGMP messages
Without Mutlicast
the network link between R1 and R2 needs 50 Mbps of bandwidth
Stream of data is sent to special addresses called group addresses
Local network control block 224.0.0.0 to 224.0.0.255
Addresses in the local network control block are used for “control traffic” which is not forwarded outside of a local broadcast domain.
Examples of this type of multicast control traffic are:
1. all hosts in this subnet (224.0.0.1)
2. all routers in this subnet (224.0.0.2)
3. all PIM routers (224.0.0.13)
Control traffic sent out on this range has TTL of 1 and packet expires as soon as it enters next hop router, you might think that packers from 224.0.0.0 network cannot propagate through the network? even though the packet expires reaching next router but that “control” message is delivered through out the network router by router using these packets with TTL of 1
224.0.0.1 – all hosts in this subnet (all hosts listen on this address)
224.0.0.2 – all routers in this subnet
224.0.0.5 – all OSPF routers (AllSPFRouters)
224.0.0.6 – all OSPF DRs (AllDRouters)
224.0.0.10 – all EIGRP routers
224.0.0.13 – all PIM routers
224.0.0.18 – VRRP
224.0.0.22 – IGMPv3
224.0.0.102 – HSRPv2 and GLBP
Internetwork control block (224.0.1.0/24):m
Addresses in the internetwork control block are used for “control traffic” that may be forwarded through the Internet. Examples include Network Time Protocol (NTP) (224.0.1.1), Cisco-RP-Announce (224.0.1.39), and Cisco-RP-Discovery (224.0.1.40).
224.0.1.1 – NTP
224.0.1.39 – Cisco-RP-Announce (Auto-RP)
224.0.1.40 – Cisco-RP-Discovery (Auto-RP)
Source Specific Multicast (SSM) block
232.0.0.0 to 232.255.255.255 232.0.0.0/8
This is the default range used by SSM. SSM is a PIM extension
SSM forwards traffic only from sources for which the receivers have explicitly expressed or chosen, for example, receivers input the sender address in the software. Used for one-to-many applications.
Administratively scoped block 239.0.0.0 to 239.255.255.255
This range is like private 10.0.0.0/8 range that can be used for multicasting internally in organsiation’s network and is used for normal multicasting or non SSM
Multicast & Layer 2
In order for multicast packets to be delivered to end hosts, their NIC needs to listen to “Multicast Group’s MAC address”
The first 24 bits of a multicast MAC address always start with “01:00:5E”
This is very much like “OLOOSE”
That “01” is Individual / Group bit (group means multicast group)
remaining 23 bits of the MAC address come from the lower 23 bits of the IPv4 multicast address.
“an example of mapping the multicast IP address 239.255.1.1 into the multicast MAC address 01:00:5E:7F:01:01”

When bits from IP address (top row) are transfered down into last 23 bits with first 24 bits 01:00:5E: and one individual / group bit (total 24 + 1 = 25 bits)
“some multicast group IP addresses can map to single MAC address“
because first 9 bits of the multicast IP address are not copied into the multicast mac address because of this phenomenon there are 32 (25) multicast IP addresses that are not universally unique and could correspond to a single MAC address or overlap, this can result in some machines which are subscribed to one multicast address, also receive multicast for another IP address

To keep it all simple just imagine that due to 01:00:5E (0LOOSE) only last 23 bits are copied from IP address
When a receiver wants to receive a specific multicast feed, it sends an IGMP join using the multicast IP or group address
The receiver programs its interface to accept the multicast MAC group address that correlates to the group address
IGMPv2
Receivers use IGMP to join multicast groups and leave multicast groups,
When a receiver wants to receive multicast traffic from a source, it sends an IGMP join to its router. If the router does not have IGMP enabled on the interface, the request is ignored.
Most common IGMP version is IGMPv2
IGMPv3 is used by SSM
IGMPv2 uses “packet” that travels to the router with TTL of 1,
if a router is the one that decremented the TTL from 1 to 0,
that router does not proceed with forwarding / routing of that packet and that packet is then discarded.
Type Field
Version 2 membership report
also known as IGMP join , remember M in IGMP for Membership
used by receivers to join a multicast group
or to respond to a local router’s membership query message
Version 1 membership report
is used by receivers for backward compatibility with IGMPv1
Version 2 leave group
is used by receivers to indicate they want to stop receiving multicast traffic for a group they joined.
General membership query is periodically sent to the all-hosts group address 224.0.0.1 to see whether there are any receivers in the attached subnet. It sets the group address field to 0.0.0.0 (and not to a specific group address).
Group specific query is sent in response to a leave group message to the group address the receiver requested to leave, this is a test by local router to see if there are any more receivers on LAN and if this leaving router is the last receiver.
Upstream after receiving IGMP join message from LAN
The local router once receives an IGMP join message on LAN side then sends a PIM join message upstream toward the source to request the multicast stream
When the local router starts receiving the multicast stream, it forwards it downstream to the subnet where the receiver that requested it resides.
Router then starts periodically sending general membership query messages into the subnet, to the all-hosts group address 224.0.0.1, to see whether any members are in the attached subnet. The general query message contains a max response time field that is set to 10 seconds by default
In response to this query, “receivers” set an internal random timer between 0 and 10 seconds (which can change if the max response time is using a non-default value). When the timer expires, receivers send membership reports for each group they belong to. If a receiver receives another receiver’s report for one of the groups it belongs to while it has a timer running, it stops its timer for the specified group and does not send a report; this is meant to suppress duplicate reports from everybody
When the leave group message is received by the router, it follows with a group-specific membership query to the group multicast address to determine whether there are any receivers interested in the group remaining in the subnet. If there are none, the router removes the IGMP state for that group.
IGMP querier election (if there is more than one IGMP router on segment)
If there is more than one router in a LAN segment, an IGMP querier election takes place to determine which router will be the querier.
IGMPv2 routers send general membership “query” messages destined to the 224.0.0.1 multicast address
When an IGMPv2 router receives such a message, It cannot receive this “query” message, as host only “report” and not “query” that means there is another router on thet network
The router with the lowest (Layer 2) interface IP address in the LAN subnet is elected as the IGMP querier.
All the non-
querier routers (routers that did not have lowest IP and lost) start a timer that resets each time they receive a membership query report from the querier router.
If the querier router stops sending membership queries for some reason (for instance, if it is powered down), a new querier election takes place. A non-querier router waits twice the query interval, which is by default 60 seconds, and if it has heard no queries from the IGMP querier, it triggers IGMP querier election.
IGMPv3
In IGMPv2, when a receiver sends a membership report to join a multicast group, it does not specify which source it would like to receive multicast traffic from. IGMPv3 is an extension of IGMPv2 that adds support for multicast source
gives the receivers the capability to pick the source they wish to accept multicast traffic from, it could be sender in same group such as 239.0.0.12 but receiver has ability to receive from better sender
IGMPv3 is designed to coexist with IGMPv1 and IGMPv2
IGMPv3 sources can be mentioned by receivers in following ways:
Include mode: In this mode, the receiver announces membership to a multicast group address and provides a list of source addresses (the include list) from which it wants to receive traffic.
Exclude mode: In this mode, the receiver announces membership to a multicast group address and provides a list of source addresses (the exclude list) from which it does not want to receive traffic. The receiver then receives traffic only from sources whose IP addresses are not listed on the exclude list. To receive traffic from all sources, which is the behavior of IGMPv2, a receiver uses exclude mode membership with an empty exclude list.
IGMPv3 is used to provide source filtering for Source Specific Multicast (SSM).
IGMP Snooping
To optimize forwarding and remove flooding, switches need a method of sending traffic only to interested receivers.
A multicast MAC address is never used as a source MAC address
And because multicast mac address is never seen as source MAC address, and never learned (because of source based learning), multicast frame going into the switch as destination is treated as unknown frame and flood them out all ports just like broadcast
IGMP snooping works by examining IGMP joins sent by receivers and maintaining a table of groups, IGMP groups and interfaces. When the switch receives a multicast frame destined for a multicast group, it forwards the packet only out the ports where IGMP joins were received for that specific multicast group
source sending traffic to 239.255.1.1 (01:00:5E:7F:01:01). Switch 1 receives this traffic, and it forwards it out only the g0/0 and g0/2 interfaces because those are the only ports that received IGMP joins for that group.
Even with IGMP snooping enabled, some multicast groups are still flooded on all ports (for example, 224.0.0.0/24 reserved addresses Local Network Control Block).
If IGMP snooping is not enabled, then a static entry can also be added in mac address table. A multicast static entry can also be manually programmed into the MAC address table, but this is not a scalable solution because it cannot react dynamically to changes; for this reason, it is not a recommended approach.
Protocol Independent Multicast
PIM uses routing table already built that is why it is called Protocol Independent
PIM works at Layer 3
The two basic types of multicast distribution trees are
source trees as shortest path trees (SPTs), and shared trees (not shortest)
Source Trees or Shortest Path Tree SPT
A source tree or SPT or (S,G) is a multicast distribution tree where the source is the root of the tree, and branches form a distribution tree through the network towards receivers. When this tree is built, it has the shortest path through from the source to the leaves of the tree; for this reason, it is also referred to as a shortest path tree (SPT).
Forwarding state of the SPT is known by the notation (S,G), pronounced “S comma G,” where S is the sender of the multicast stream (server), and G is the multicast group address
Notice that this is Specific source / sending server per group, if a new server or sender is created, a new (S,G) will need to be built
Shared Trees or Rendezvous Point Trees RPT
A shared tree or (*,G) is a multicast distribution tree where the root of the shared tree is not the source but a router designated as the rendezvous point (RP) is, For this reason, shared trees are also referred to as rendezvous point trees (RPTs)
Multicast traffic is forwarded to RP even if source is next to receivers because of shared tree
shared tree is referred to by the notation (*,G), pronounced “star comma G.”
notice that it is “any” source per group
RP keeps record of all the senders (while R1 only has record of its sender) and is also responsible for receiving all Mcast streams, and then forwarded out of the RP
One of the benefits of shared trees over source trees is that they require fewer multicast entries (for example, S,G and *,G). For instance, as more sources are introduced into the network, sending traffic to the same multicast group, the number of multicast entries for R3 and R4 always remains the same: (*,239.1.1.1)
The major drawback of shared trees is that the receivers receive traffic from all the sources sending traffic to the same multicast group. Even though the receivers’ applications can filter out the unwanted traffic, this situation still generates a lot of unwanted network traffic, wasting bandwidth. In addition, because shared trees can allow all sources in an IP multicast group, there is a potential network security issue because unintended sources could send unwanted packets to receivers.
PIM Terminology
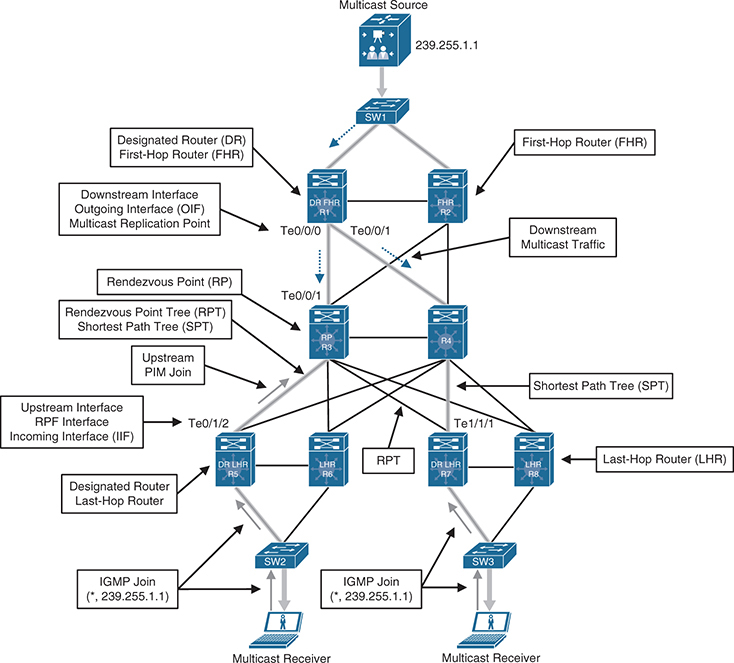
This diagram should be read from top or source to down, all the roles are from top to bottom such as First-hop Router
Reverse Path Forwarding (RPF) interface
The interface with the lowest-cost path to the IP address of the source (SPT) or the RP, If multiple interfaces have the same cost, the interface with the highest IP (Layer 3) address is chosen as the tiebreaker
Also known as the incoming interface (IIF) (Incoming interface because this is where incoming multicast traffic will come), The only type of interface that can accept multicast traffic coming from the source, which is the same as the RPF interface. An example of this type of interface is Te0/0/1 on R3 because the shortest path to the source is known through this interface.
Another example of this type of interface is Te0/1/2 on R5 because it is the shortest path to the source. Another example is Te1/1/1 on R7 because the shortest path to the source was determined to be through R4.
RPF neighbor
The PIM neighbor or PIM enabled router on the RPF interface, if R7 is using the RPT shared tree, the RPF neighbor would be R3, which is the lowest-cost path to the RP. If it is using the SPT, R4 would be its RPF neighbor because it offers the lowest cost to the source.
A PIM join always travels upstream toward the source
Downstream interface
Any interface that is used to forward multicast traffic down the tree, also known as an outgoing interface (OIF). An example of a downstream interface is R1’s Te0/0/0 interface, which forwards multicast traffic to R3’s Te0/0/1 interface.
Outgoing interface (OIF)
Any interface that is used to forward multicast traffic down the tree, also known as the downstream interface.
Outgoing interface list (OIL)
A group of OIFs that are forwarding multicast traffic to the same group. An example of this is R1’s Te0/0/0 and Te0/0/1 interfaces sending multicast traffic downstream to R3 and R4 for the same multicast group.
Last-hop router (LHR)
A router that is directly attached to the receivers, also known as a leaf router. It is responsible for sending PIM joins upstream toward the RP or to the source.
First-hop router (FHR)
A router that is directly attached to the source, also known as a root router. It is responsible for sending register messages to the RP.
Multicast Routing Information Base (MRIB)
A topology table that is also known as the multicast route table (mroute). It is built based on information from the unicast routing table and PIM. MRIB contains the
source S, group G,
incoming interfaces (IIF),
outgoing interfaces (OIFs),
and RPF neighbor information
for each multicast route as well as other multicast-related information.
Multicast Forwarding Information Base (MFIB)
A forwarding table that uses the MRIB to program multicast forwarding information in hardware for faster forwarding.
There are currently five PIM operating modes:
- PIM Dense Mode (PIM-DM) or ASM (Any Source Multicast)
- PIM Sparse Mode (PIM-SM)
- PIM Sparse Dense Mode
- PIM Source Specific Multicast (PIM-SSM) or ASM (Any Source Multicast)
- PIM Bidirectional Mode (Bidir-PIM)
PIM-DM and PIM-SM are also commonly referred to as any-source multicast (ASM)
All PIM control messages use the IP protocol number 103
they are either unicast (higher TTL)
or multicast, with a TTL of 1 to the all PIM routers address 224.0.0.13
PIM Hello and Neighborship
PIM hello messages are sent by default every 30 seconds out each PIM-enabled interface to learn about the neighboring PIM routers on each interface to the all PIM routers address 224.0.0.13 (all PIM routers)
In both PIM-SM and PIM-DM, PIM neighborship is created the same way:
when directly connected routers running PIM exchange PIM Hello messages on an interface.
The difference between Sparse Mode and Dense Mode is how multicast forwarding works afterward—not how neighbors form.
When is a PIM neighborship created?
A PIM neighborship forms when:
1️ PIM is enabled on an interface
2 Another router on the same subnet also has PIM enabled
3 They exchange PIM Hello packets
These Hellos are sent to:
IPv4: 224.0.0.13
IPv6: FF02::D
Once received, routers become PIM neighbors (adjacent).
No RP, no source, no receiver required to form neighborship
Just PIM enabled + Hello exchange
PIM-SM neighborship (Sparse Mode)
In PIM-SM, neighbors are required to build multicast trees using Join messages.
What happens after neighborship forms?
Depending on router role:
LHR (Last-Hop Router) sends Join toward RP
FHR (First-Hop Router) sends Register to RP
Intermediate routers forward Join/Prune
So flow is:
Enable PIM → Hello exchange → neighborship forms → Join/Register messages start
Key idea:
Sparse Mode builds trees only where receivers exist
PIM-DM neighborship (Dense Mode)
In PIM-DM, neighborship still forms via Hello messages, but forwarding behavior differs.
After adjacency:
Routers immediately:
1 Flood multicast traffic everywhere
2 Then send Prune messages where receivers don’t exist
3 Later send Graft if receivers appear again
So flow is:
Enable PIM → Hello exchange → neighborship forms → Flood traffic → Prune unwanted paths
Key idea:
Dense Mode assumes receivers are everywhere first
Hello messages are also the mechanism used to elect a designated router (DR)
PIM Dense Mode
PIM Dense Mode (PIM-DM), Dense means that there are Multicast receivers in every subnet of the network, in other words, when the multicast receivers of a multicast group are densely populated across the network.
For PIM-DM, the multicast tree is built by flooding traffic out every interface from the source to every Dense Mode router in the network (forced feed)
As each router receives traffic for the multicast group, it must decide whether it already has active receivers wanting to receive the multicast traffic. If so, the router remains quiet and lets the multicast flow continue. If no receivers have requested the multicast stream for the multicast group on the LHR, the router sends a prune message toward the source.
That branch of the tree is then pruned off or goes offline so that the unnecessary traffic does not continue.
Initial Flooding in PIM-DM
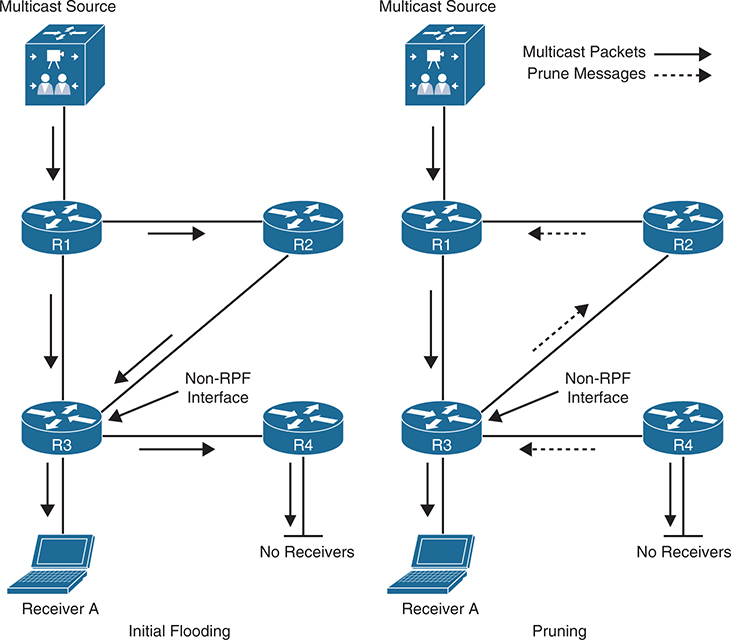
As each router receives the multicast traffic from its upstream neighbor via its RPF interface, it forwards the multicast traffic to all its PIM-DM neighbors, This results in some traffic arriving via a non-RPF interface, as in the case of R3 receiving traffic from R2 on its non-RPF interface. Packets arriving via the non-RPF interface are discarded because it is duplicate traffic and a prune message is prepared
Each router uses Reverse Path Forwarding (RPF) to decide which incoming interface is the correct one for multicast traffic from a particular source.
R3 checks its unicast routing table to see “Which interface would I use to reach the source?”
Route to the source (through R1) is the best path.
So, the interface from R1 is the RPF interface.
The interface from R2 is non-RPF.
That means:
R3 accepts multicast packets coming from R1 (RPF interface)
R3 drops multicast packets received from R2 (non-RPF interface)
These non-RPF multicast flows are normal for the initial flooding of multicast traffic and are corrected by the normal PIM-DM pruning mechanism.
Pruning after Initial Flooding in PIM-DM
Prunes are sent out even the RPF interface when the router has no downstream members that need the multicast traffic, as is the case for R4, which has no interested receivers,
and they are also sent out non-RPF interfaces to stop the flow of multicast traffic that is arriving on non-RPF interface, in case of R3
the resulting topology after all unnecessary links have been pruned off. This results in an SPT from the source to the receiver.
This (S,G) state remains until the source stops transmitting. S is the source IP address and G is the group IP address along with the OIL containing OIF or Outgoing Interfaces and also the Incoming / RPF interfaces
In PIM-DM, prunes expire after three minutes.
This causes the multicast traffic to be reflooded to all routers just as was done during the initial flooding. This periodic (every three minutes) flood and prune behavior is normal and must be taken into account when a network is designed to use PIM-DM.
PIM-DM is applicable to small networks where there are active receivers on every subnet of the network. Because this is rarely the case, PIM-DM is not widely deployed and not recommended for production environments.
PIM Sparse Mode
PIM Sparse Mode (PIM-SM) was designed for networks with multicast application receivers scattered throughout the network—in other words, when the multicast receivers of a multicast group are sparsely populated across the network. However, PIM-SM also works well in densely populated networks. It also assumes that no receivers are interested in multicast traffic unless they explicitly request, it opposite of PIM DM
Just like PIM-DM, PIM-SM uses the unicast routing table to perform RPF checks, and it does not care which routing protocol (including static routes) populates the unicast routing table; therefore, it is protocol independent.
PIM Shared and Source Path Trees
PIM-SM uses an explicit join model where the receivers send an IGMP join to their locally connected router, which is also known as the last-hop router (LHR), and this join causes the LHR to send a PIM join in the direction of the root of the tree, which is either the RP in the case of a shared tree (RPT) or in case of SPT, the first-hop router (FHR) where the source transmitting the multicast streams is connected
A multicast forwarding state is created as the result of these explicit joins
Multicast source sends multicast traffic to the FHR. The FHR then sends this multicast traffic to the RP, which makes the multicast source known to the RP
Receiver sends an IGMP join to the LHR to join the multicast group. The LHR then sends a PIM join (*,G) to the RP, and this forms a shared tree from the RP to the LHR, this (*,G) PIM join would travel hop-by-hop to the RP, building (*,G) on all routers it is passing through.
In essence, two trees are created: an SPT from the FHR to the RP (S,G) and a shared tree from the RP to the LHR (*,G).
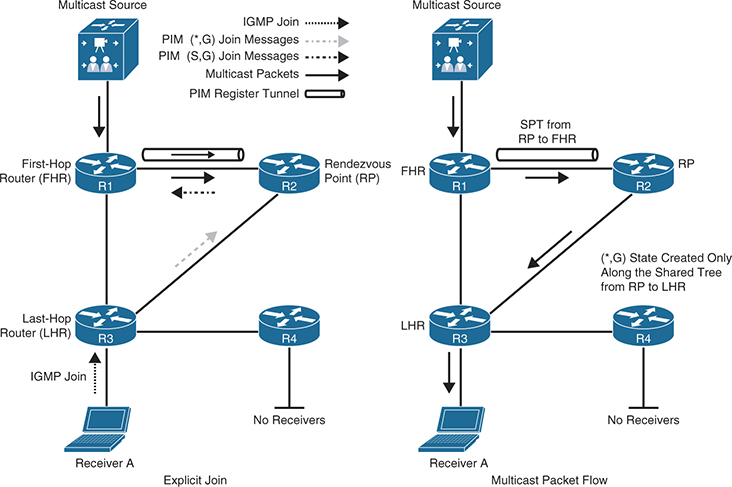
multicast starts flowing down from the source to the RP
and from the RP to the LHR and then finally to the receiver.
Remember and also from diagram these S,G and *,G messages always travel in reverse direction of multicast traffic flow
*,G is from LHR to RP and S,G is from RP to FHR
Receiver A attached to the LHR joins multicast group G using IGMP join. The LHR knows the IP address of the “RP for group G” – “there can be different RP per group” and LHR then sends (*,G) PIM join for this “group“ to the RP.
Source for a group G sends a packet, the FHR that is attached to this source creates a “unidirectional ” PIM register tunnel interface that encapsulates the multicast data received from the source in a special PIM-SM (Sparse Mode) message called the register message. The encapsulated multicast data is then unicasted due to tunnel to the RP using the PIM register tunnel. This Multicast packet needs to be encapsulated in a unicast packet to RP, so it is not multicasted through the network below FHR and this PIM register tunnel is for one way traffic (Multicast stream from FHR to RPT inside a tunnel / unicasted to RPT)
When the RP receives a register message, it decapsulates the multicast data packet inside the register message, and if there is no active shared tree because there are no interested receivers, the RP unicasts a register stop message directly to the registering FHR, without traversing the PIM register tunnel, instructing it to stop sending the register messages.
If there is an active shared tree for the group, it forwards the multicast packet down the shared tree, and it sends an (S,G) join back toward the source network S to create an (S,G) SPT. If there are multiple hops (routers) between the RP and the source, this results in an (S,G) state being created in all the routers along the SPT, There will also be a (*,G) in R1 and all of the routers between the FHR and the RP. So how can (*,G) and (S,G) co exist on same router?
(*,G): The “shared tree” state — means “any source for group G.”
It’s built towards the Rendezvous Point (RP) in both forward (Between LHR and RP) and reverse direction (between FHR and RP)?
Used before the specific source is known or joined.
(S,G): The “source tree” state — means “specific source S for group G.”
It’s built directly toward the multicast source between FHR and RPT
1. Initial IGMP Join
Receiver A (host) on R3 sends an IGMP Join for group G.
R3 (the Last-Hop Router, LHR) sends a PIM Join (*,G) upstream — towards the RP (R2).
So:
- R3 and R2 now have (*,G) state entries.
- This builds the shared tree (R3 → R2 → R1).
2. Source Starts Sending
When the multicast source (at R1) begins transmitting for group G:
- R1 (the First-Hop Router, FHR) registers with the RP using a PIM Register message.
- The RP learns that source S exists for group G.
3. Receiver Activity Triggers (S,G) Join
When the RP receives traffic from S, it knows there are active receivers (due to the earlier (*,G) join from R3).
So, the RP sends a PIM (S,G) Join back toward the source network — i.e., towards R1.
This creates:
- An (S,G) entry in R2 and R1 (routers along that source tree path).
- But — crucially — the (*,G) state still remains in R1 (and the path between R1 ↔ R2).
So Why Does (*,G) Exist in R1?
Even though R1 is the first-hop router (directly connected to the source), it forms a (*,G) state because:
- It’s part of the shared tree path from the RP to the source (built earlier when RP didn’t yet know the source existed).
The shared tree extends from RP → R1, so all routers on that path (including R1) must maintain(*,G)state. So this (*,G) is created on all routers around RP in 360 degrees. - Transitions are gradual, not instantaneous — both trees (shared and source) coexist temporarily while the network optimizes to the SPT.
As soon as the SPT is built from the source router to the RP, multicast traffic begins to flow natively from the source S to the RP instead of being encapsulated inside unicast PIM Regsiter tunnel and once the RP begins receiving data natively from source S
it sends a register stop message to the source’s FHR to inform it that it can stop sending the unicast register messages inside a tunnel. At this point, multicast traffic from the source is flowing down the SPT to the RP and, from there, down the shared tree (RPT) to the receiver – register stop message’s only function is to make FHR stop sending register message for speicific group and not to stop multicast operation
The PIM register tunnel from the FHR to the RP remains in an active up/up state even when there are no active multicast streams, and it remains active as long as there is a valid RPF path for the RP.
PIM SPT Switchover
PIM-SM allows the LHR to switch from the RPT (shared tree) to an SPT for a specific source
In Cisco routers, this is the default behavior, and it happens immediately after the first multicast packet is received from the RP via the RPT on LHR, even if shortest parth to the source is through RP.
When the LHR receives the first multicast packet from the RP, it becomes aware of the IP address of the multicast source, at this point LHR sends (S,G) PIM Join towards the “source IP” following routing table (and not RP IP) and that can result in PIM Join going out of a different interface (shorter route) than interface through which RP is reachable
This PIM Join going from LHR to FHR creates (S,G) on all routers in the path
When the LHR receives a multicast packet from the source through the SPT, if the SPT RPF interface differs from the RPT RPF interface, the LHR will start receiving duplicate multicast traffic from the source; at this moment, it will switch the RPF interface to be the SPT RPF interface and send an (S,G) PIM prune message to the RP to shut off the duplicate multicast traffic coming through the RPT.
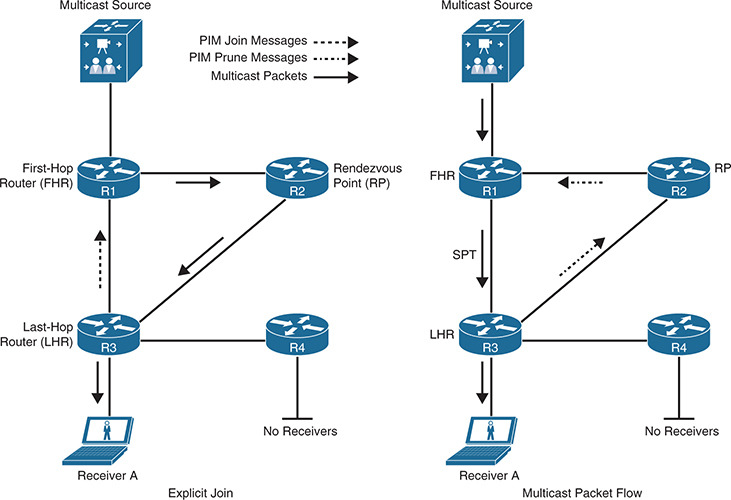
the shortest path to the source is between R1 and R3; if that link were shut down or not present, the shortest path would be through the RP, in which case an SPT switchover would still take place, even though the path used by the SPT is the same as the RPT.
The PIM SPT switchover mechanism can be disabled for all groups or for specific groups.
If the RP has no other interfaces that are interested in the multicast traffic, it sends a PIM prune message in the direction of the FHR. If there are any routers between the RP and the FHR, this prune message would travel hop-by-hop until it reaches the FHR.
What if SPT switchover takes place and LHR’s RPF incoming interface is same for new source as last RP, Then does the reciever recieve duplicate streams? One stream from new source following the SPT switchover and one stream from RP?
No — the receiver should not continue to receive duplicate streams after the SPT switchover, even if the RPF incoming interface toward the new source is the same as toward the RP.
LHR:
Builds an (S,G) entry
Joins directly toward the source
Sends a (S,G) prune toward the RP, That prune stops the RP path from forwarding traffic downstream.
Designated Routers
When multiple PIM-SM routers exist on a LAN segment, PIM hello messages are used to elect a designated router (DR) to avoid sending duplicate multicast traffic into the LAN (LHR) or to the RP (FHR). “Designated” router on LAN to receive traffic or send traffic, so second router does not duplicate multicast on network.
By default, the DR priority value of all PIM routers is 1, and it can be changed to force a particular router to become the DR during the DR election process, where a higher DR priority is preferred. If a router in the subnet does not support the DR priority option or if all routers have the same DR priority, the highest IP address in the subnet is used as a tiebreaker.
On an FHR, the designated router is responsible for encapsulating in unicast register messages any multicast packets originated by a source that are destined to the RP.
On an LHR, the designated router is responsible for sending PIM join and prune messages toward the RP to inform it about host group membership, and it is also responsible for performing a PIM SPT switchover.
Without DRs, all LHRs on the same LAN segment would be capable of sending PIM joins upstream, which could result in duplicate multicast traffic arriving on the LAN.
On the source side, if multiple FHRs exist on the LAN, they all send register messages to the RP at the same time.
The default DR hold time is 3.5 times the PIM hello interval (PIM Hello is 30 seconds) which makes DR hold time to 105 seconds. If there are no hellos after this interval, a new DR is elected. To reduce DR failover time, the hello query interval can be reduced to speed up failover with a trade-off of more control plane traffic and CPU resource utilization of the router.
Reverse Path Forwarding
Reverse Path Forwarding is a method routers use when multicast traffic arrives on interface and it checks source address against routing table and if this is the interface., if not then interface is non RPF interface.
This is used to prevent loops and also avoid duplicated multicast traffic
If a router receives a multicast packet on an interface it uses to send unicast packets to the source, the packet has arrived on the RPF interface.
Next If the packet arrives on the RPF interface, a router forwards the packet out the interfaces present in the outgoing interface list (OIL) of a multicast routing table entry.
If the packet does not arrive on the RPF interface, the packet is discarded to prevent loops.
RPF check is performed differently for RPT and SPT
If a PIM router has an (S,G) entry present in the multicast routing table (an SPT state), the router performs the RPF check against the IP address of the “source” for the multicast packet.
If a PIM router has no explicit source-tree state, this is considered a shared-tree state. The router performs the RPF check on the address of the RP, which is known when members join the group.
PIM Assert , forwarder role
PIM assert mechanism is used to stop duplicate flows into LAN, well was it not the function of DR? yes DR does its best from control plane perspective to prevent duplicate flows, after DR elections only one router sends out PIM Join to receive traffic only on that specific DR router but in some cases (discussed below) you can still end up having duplicate multicast coming from 2 routers on same LAN and if that happens then this condition is detected and remediated using PIM Assert mechanism
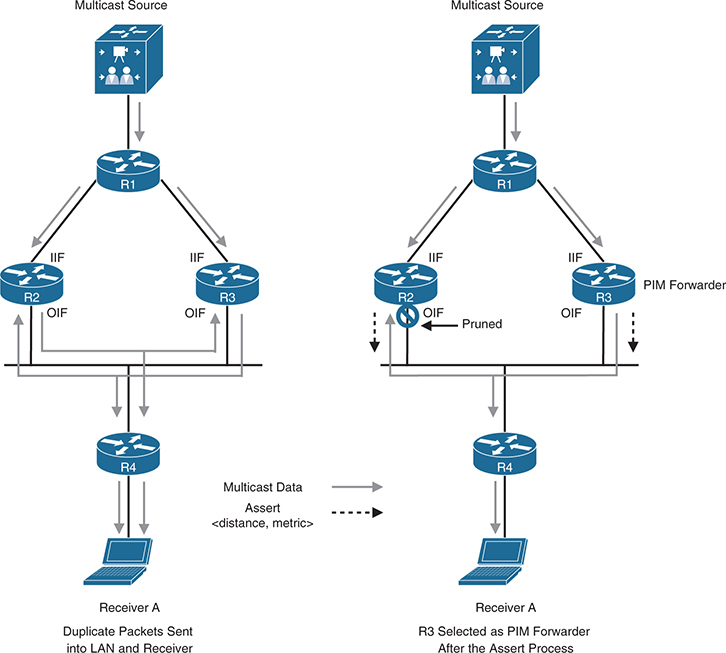
in above figure, Both R2 and R3 receive traffic on their (one and only) RPF interface, as these routers dispatch multicast traffic on LAN, R2’s sent multicast hits R3’s OIF interface (due to LAN) and R3’s sent multicast traffic hits R2’s OIF, this triggers the PIM Assert mechanism on both routers as this should not happen
In other words, they detect a multicast packet for a specific (S,G) coming into their OIF that is also OIF for the same (S,G) (this OIF cannot be also IIF for same group)
R2 and R3 both send PIM assert messages into the LAN. These assert messages “send” each other following inside PIM Assert message to determine which router should forward the multicast traffic to that network segment.
- Administrative distance to source
- Metric or cost to the source (unicast since siurce is unicast address)
- Highest IP address (tie-breaker)
Each router compares its own values with the received values. Preference is given to the PIM message with the lowest AD to the source. If a tie exists, the lowest route metric for the protocol wins; and as a final tiebreaker, the highest IP address is used.
The losing router prunes its interface just as if it had received a prune on this interface, and the winning router is the PIM forwarder for the LAN.
The prune times out after three minutes on the losing router and causes it to begin forwarding on the interface again. This triggers the assert process to repeat. If the winning router were to go offline, the loser would take over the job of forwarding on to this LAN segment after its prune timed out. Remember that anything relying on Prune messages will only last 3 minutes as Prune messages expire in 3 mins
The PIM forwarder concept applies to PIM-DM and PIM-SM. It is commonly used by PIM-DM but rarely required by PIM-SM because duplicate packets can end up in a LAN only if there is some sort of routing inconsistency.
PIM-SM would not send duplicate flows into the LAN as PIM-DM would because of the way PIM-SM operates.
Corner case for PIM-SM to send duplicated Multicast in LAN
PIM-SM will only forward duplicated multicast in LAN because of routing inconsistency only
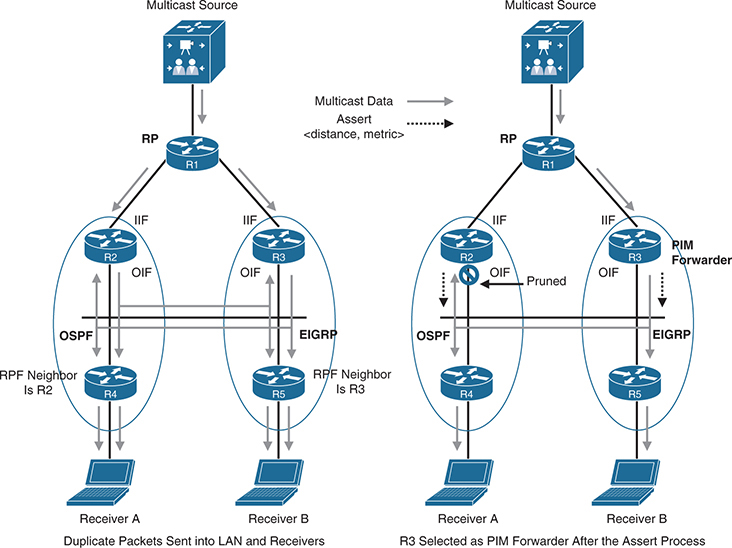
R1 is the RP
R2 and R4 are running the OSPF, and R3 and R5 are running EIGRP, and this is inconsistency in this network – to be more specific 2 different routing domains on same LAN.
R4 learns about the RP (R1) through R2, and R5 learns about the RP through R3
when R4 sends a PIM join message upstream toward it, it sends the message to the all PIM routers address 224.0.0.13, and R2 and R3 receive it but in PIM-SM PIM join message includes the IP address of the upstream neighbor, also known as the RPF neighbor (which is only one neighbor – PIM neighbor on RPF interface)
R4’s RPF neighbor is R2, and R5’s RPF neighbor is R3
Receiver A and Receiver B join the same group
Receiver A’s IGMP join will cause PIM Join from R4 to both R2 and R3 (because of same LAN) R2 is the only one that will send a PIM join to R1 because PIM join from R4 has header that contains R2 as its RPF neighbor, R3 will not because the PIM join was not meant for it, from R4 it was only meant for R2 (its RPF neighbor) and R2 will send PIM Join message to RP
Similarly IGMP join from receiver B will trigger R5 to send a PIM join to to both R2 and R3, but because PIM SM’s PIM Join has RPF neighbor R3 is specified in packet, R3 is the one that will send a PIM join to R1.
At this point, traffic starts flowing downstream from R1 into R2 and R3, and duplicate packets are then sent out into the LAN and to the receivers.
At this point, the PIM assert mechanism kicks in, R3 is elected as the PIM forwarder, and R2’s OIF interface is pruned, as illustrated in the topology on the right side.
Rendezvous Points
In PIM-SM, it is mandatory to choose one or more routers to operate as rendezvous points (RPs). An RP is a single common root placed at a chosen point of a shared distribution tree, as described earlier in this chapter. An RP can be either configured statically in each router or learned through a dynamic mechanism. A PIM router can be configured to function as an RP either statically in each router in the multicast domain or dynamically by configuring Auto-RP or a PIM bootstrap router (BSR), as described in the following sections.
Note
BSR and Auto-RP were not designed to work together and may introduce unnecessary complexities when deployed in the same network. The recommendation is not to use them concurrently.
Static RP
It is possible to statically configure RP for a multicast group range by configuring the address of the RP on every router in the multicast domain. Configuring static RPs is relatively simple and can be achieved with one or two lines of configuration on each router. If the network does not have many different RPs defined or if the RPs do not change very often, this could be the simplest method for defining RPs. It can also be an attractive option if the network is small.
However, static configuration can increase administrative overhead in a large and complex network. Every router must have the same RP address. This means changing the RP address requires reconfiguring every router. If several RPs are active for different groups, information about which RP is handling which multicast group must be known by all routers. To ensure this information is complete, multiple configuration commands may be required. If a manually configured RP fails, there is no failover procedure for another router to take over the function performed by the failed RP, and this method by itself does not provide any kind of load splitting.
Auto-RP
Auto-RP is a Cisco proprietary mechanism that automates the distribution of group-to-RP mappings in a PIM network. Auto-RP has the following benefits:
- It is easy to use multiple RPs within a network to serve different group ranges.
- It allows load splitting among different RPs.
- It simplifies RP placement according to the locations of group participants.
- It prevents inconsistent manual static RP configurations that might cause connectivity problems.
- Multiple RPs can be used to serve different group ranges or to serve as backups for each other.
- The Auto-RP mechanism operates using two basic components: candidate RPs (C-RPs) and RP mapping agents (MAs).
Candidate RPs
A C-RP advertises its willingness to be an RP via RP announcement messages. These messages are sent by default every RP announce interval, which is 60 seconds by default, to the reserved well-known multicast group 224.0.1.39 (Cisco-RP-Announce). The RP announcements contain the default group range 224.0.0.0/4, the C-RP’s address, and the hold time, which is three times the RP announce interval. If there are multiple C-RPs, the C-RP with the highest IP address is preferred.
Note
The RP announcement can be configured to announce specific multicast groups instead of the default group range 224.0.0.0/4. This allows for having multiple RPs in the network serving different multicast groups, which is useful for RP design.
RP Mapping Agents
RP MAs join group 224.0.1.39 to receive the RP announcements. They store the information contained in the announcements in a group-to-RP mapping cache, along with hold times. If multiple RPs advertise the same group range, the C-RP with the highest IP address is elected.
The RP MAs advertise the RP mappings to another well-known multicast group address, 224.0.1.40 (Cisco-RP-Discovery). These messages are advertised by default every 60 seconds or when changes are detected. The MA announcements contain the elected RPs and the group-to-RP mappings. All PIM-enabled routers join 224.0.1.40 and store the RP mappings in their private cache.
Multiple RP MAs can be configured in the same network to provide redundancy in case of failure. There is no election mechanism between them, and they act independently of each other; they all advertise identical group-to-RP mapping information to all routers in the PIM domain.
Auto-RP mechanism where the MA periodically receives the C-RP Cisco RP announcements to build a group-to-RP mapping cache and then periodically multicasts this information to all PIM routers in the network using Cisco RP discovery messages.
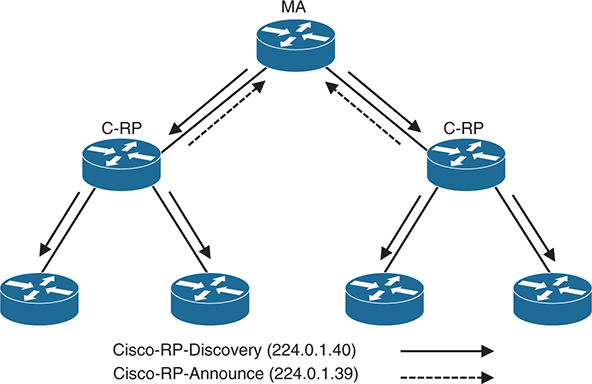
With Auto-RP, all routers automatically learn the RP information, which makes it easier to administer and update RP information. Auto-RP permits backup RPs to be configured, thus enabling an RP failover mechanism.
PIM Bootstrap Router
The bootstrap router (BSR) mechanism, described in RFC 5059, is a nonproprietary mechanism that provides a fault-tolerant, automated RP discovery and distribution mechanism.
PIM uses the BSR to discover and announce RP set information for each group to all the routers in a PIM domain. This is the same function accomplished by Auto-RP, but BSR is implemented in a different way and is not compatible with Auto-RP. BSR is an IETF standard that is part of the PIM Version 2 specification, which is defined in RFC 4601.
The RP set is a group-to-RP mapping that contains the following components:
- Multicast group range
- RP priority
- RP address
- Hash mask length
- SM/Bidir flag
Bootstrap messages (BSMs) originate on the BSR, and they are flooded hop-by-hop by intermediate routers. When a Bootstrap message is forwarded, it is forwarded out of every PIM-enabled interface that has PIM neighbors (including the one over which the message was received). Bootstrap messages use the all PIM routers address 224.0.0.13 with a TTL of 1.
To avoid a single point of failure, multiple candidate BSRs (C-BSRs) can be deployed in a PIM domain. All C-BSRs participate in the BSR election process by sending PIM Bootstrap messages containing their BSR priority out all interfaces.
The C-BSR with the highest priority is elected as the BSR and sends Bootstrap messages to all PIM routers in the PIM domain. If the BSR priorities are equal or if the BSR priority is not configured, the C-BSR with the highest IP address is elected as the BSR.
Candidate RPs
A router that is configured as a candidate RP (C-RP) receives the Bootstrap messages, which contain the IP address of the currently active BSR. Because it knows the IP address of the BSR, the C-RP can unicast candidate RP advertisement (C-RP-Adv) messages directly to it. A C-RP-Adv message carries a list of group address and group mask field pairs. This enables a C-RP to specify the group ranges for which it is willing to be the RP.
The active BSR stores all incoming C-RP advertisements in its group-to-RP mapping cache. The BSR then sends the entire list of C-RPs from its group-to-RP mapping cache in Bootstrap messages every 60 seconds by default to all PIM routers in the entire network. As the routers receive copies of these Bootstrap messages, they update the information in their local group-to-RP mapping caches, and this allows them to have full visibility into the IP addresses of all C-RPs in the network.
Unlike with Auto-RP, where the mapping agent elects the active RP for a group range and announces the election results to the network, the BSR does not elect the active RP for a group. Instead, it leaves this task to each individual router in the network.
Each router in the network uses a well-known hashing algorithm to elect the currently active RP for a particular group range. Because each router is running the same algorithm against the same list of C-RPs, they will all select the same RP for a particular group range. C-RPs with a lower priority are preferred. If the priorities are the same, the C-RP with the highest IP address is elected as the RP for the particular group range.
Figure 13-23 illustrates the BSR mechanism, where the elected BSR receives candidate RP advertisement messages from all candidate RPs in the domain, and it then sends Bootstrap messages with RP set information out all PIM-enabled interfaces, which are flooded hop-
by-hop to all routers in the network.
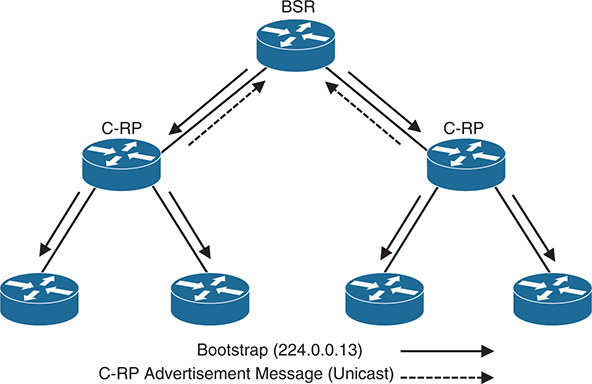
Multicast Listener Discovery (MLD)
Multicast Listener Discovery (MLD) is the IPv6 equivalent of IGMP (Internet Group Management Protocol) used in IPv4. It allows IPv6 hosts to signal their interest in receiving multicast traffic and enables routers to learn which multicast groups have active receivers on a link.
It operates between hosts and LHR, not between routers themselves.
MLD supports
PIM-SM (Protocol Independent Multicast – Sparse Mode)
PIM-SSM (Source-Specific Multicast)
Application → Multicast Group Join
↓
Host sends MLD Report
↓
Router updates membership table
↓
Router builds multicast forwarding tree (via PIM)Step 1: Router Sends Query
Router periodically transmits: MLD General Query
Step 2: Host Responds with Report
Interested hosts reply: MLD Report: Join FF3E::1
MLD Snooping
Switches can inspect MLD messages using MLD snooping.
MLD Packet Characteristics:
- Encapsulated inside ICMPv6
- Sent with hop limit = 1
- Operate only on the local link
- Use link-local scope addresses
Multicast commands
Using Cisco routers as hosts for Multicast send and Multicast receive
no ip routing
ip default-gateway x.x.x.xBasic PIM-DM configuration
no ip pim autorpmore…
coming soon
next post
SDA LM4 – DNAC Web Interface
Videos
Introduction to UI
You can modify these authentication templates but cannot define more
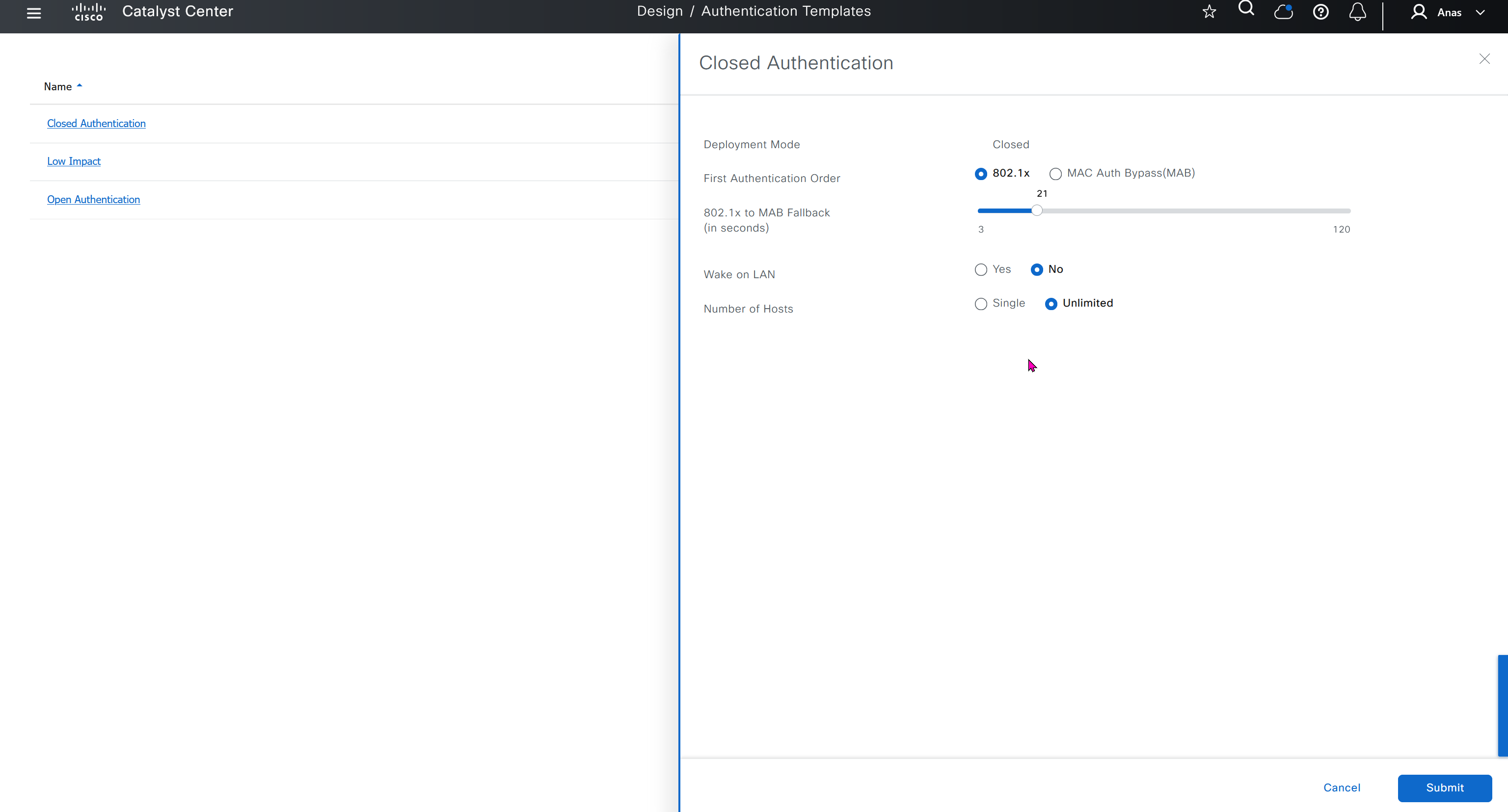
If you want to define different SSID in europe or you want different ISE server for europe then use hierarchy and go to site specific level and override


IP based access control is used when you create non fabric based wireless and this is a very specific use, if we dont use non-fabric wireless then we will not have to touch this page
AI Endpoint Analytics
With new DNAC, AI Endpoint Analytics was introduced and this leverages AI capabilities in cloud and uses deep packet inspection in Catalyst 9K infrastructure to “identify types of endpoints” – this information can then be fed to ISE and can then be used as part of endpoint authentication, this provides additional network packet level context along side the profiling probes that ISE performs on its own and that information is communicated to ISE using PXGrid
Application policies is the feature that was known as Easy QoS and it allows you to deploy QoS end to end in your network, for more details checkout RS0122 – SDA Application Policy (EasyQoS)
Traffic Copy is the way to span traffic from Fabric to a remote destination and this is part of SGT, as you can capture traffic between specific contracts or tags
Finally Virtual networks which are essentially VRFs and separate different (virtual) fabric on same network
Service catalog, these are different services that are offered
User defined network is a cool concept as it allows users to create personal network on top of shared infrastructure, users can then register their personal devices using an app and also invite other users into that network using same app and these networks are like bubbles
These 4 services are also listed under the services section of provision tab
Assurance does not just measures health and experience of network devices but also includes clients and helps us measure client’s experience on the network also and it does not stay at client but its scope one level more deep into application as well






Events are for both Network devices and also for the clients, these are any events that happen in the network for network devices and its connected clients

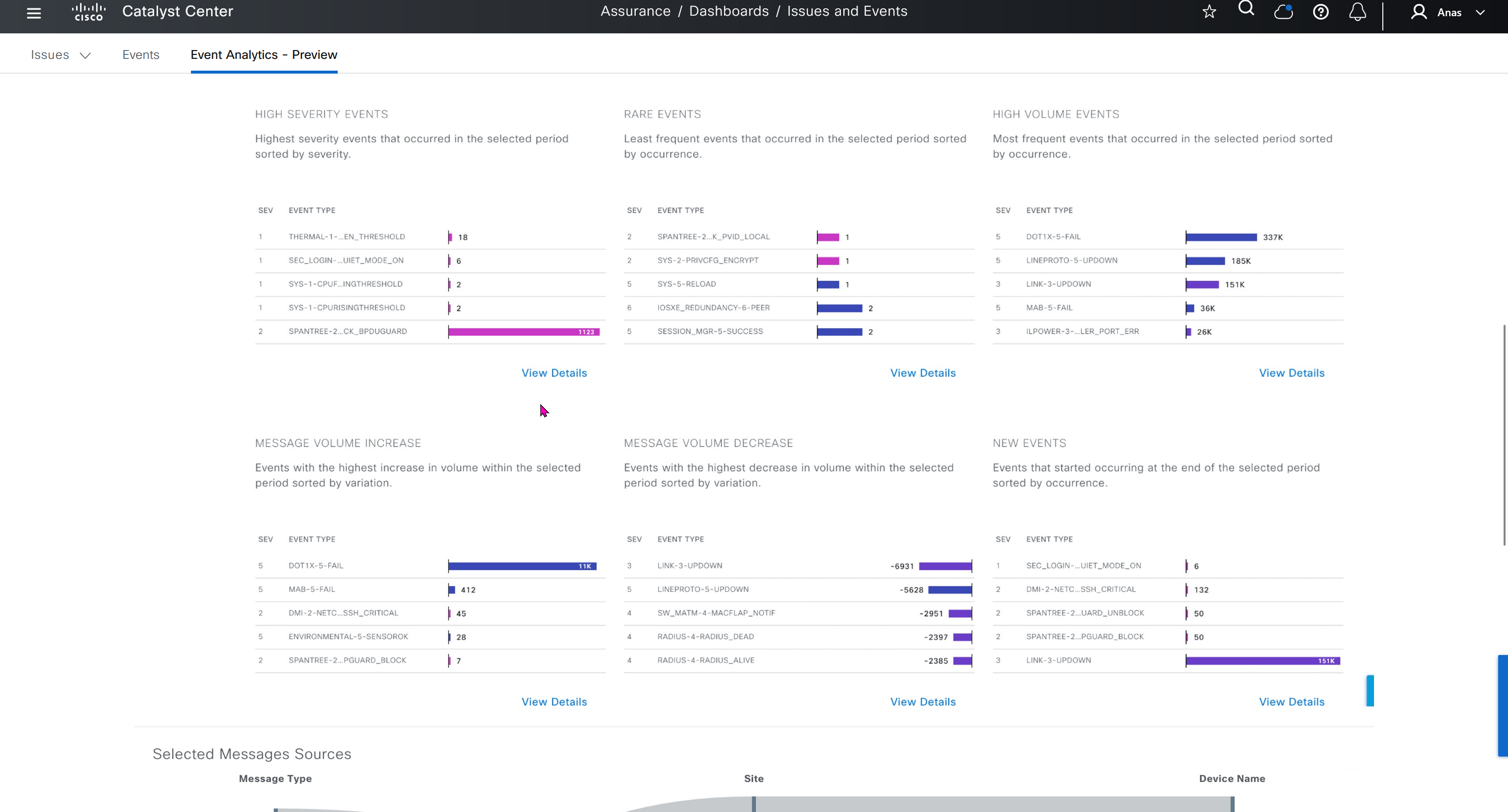
DNAC offers dedicated sensors that can perform series of tests to gauge performance from client perspective. These wireless sensors join network as wireless device and these can either be dedicated sensors or an AP can also be converted to a wireless sensor


Wi-Fi6 section is for Wi-Fi6 readiness assessment which shows us the percentage of AP and clients that are capable of Wi-Fi6, if large number of clients support Wi-Fi6 then we can think about more APs to be deployed that support Wi-Fi6


Dashboard Library is where we can create our own dashboards
This Trends and Insights leverage AI in Cloud and Machine learning to spot issues in network,
Trends and Insights deals with deviation in capacity and performance
Site comparison shows us how one site compares to another, as in some cases one site can perform worse than the others


Issue settings is where we can control what issues such as P1 and P2 can be raised by DNAC such as Assurance > Issues & Events, we can enable or disable some of these issues if they are not important to us, we can also change priority on them

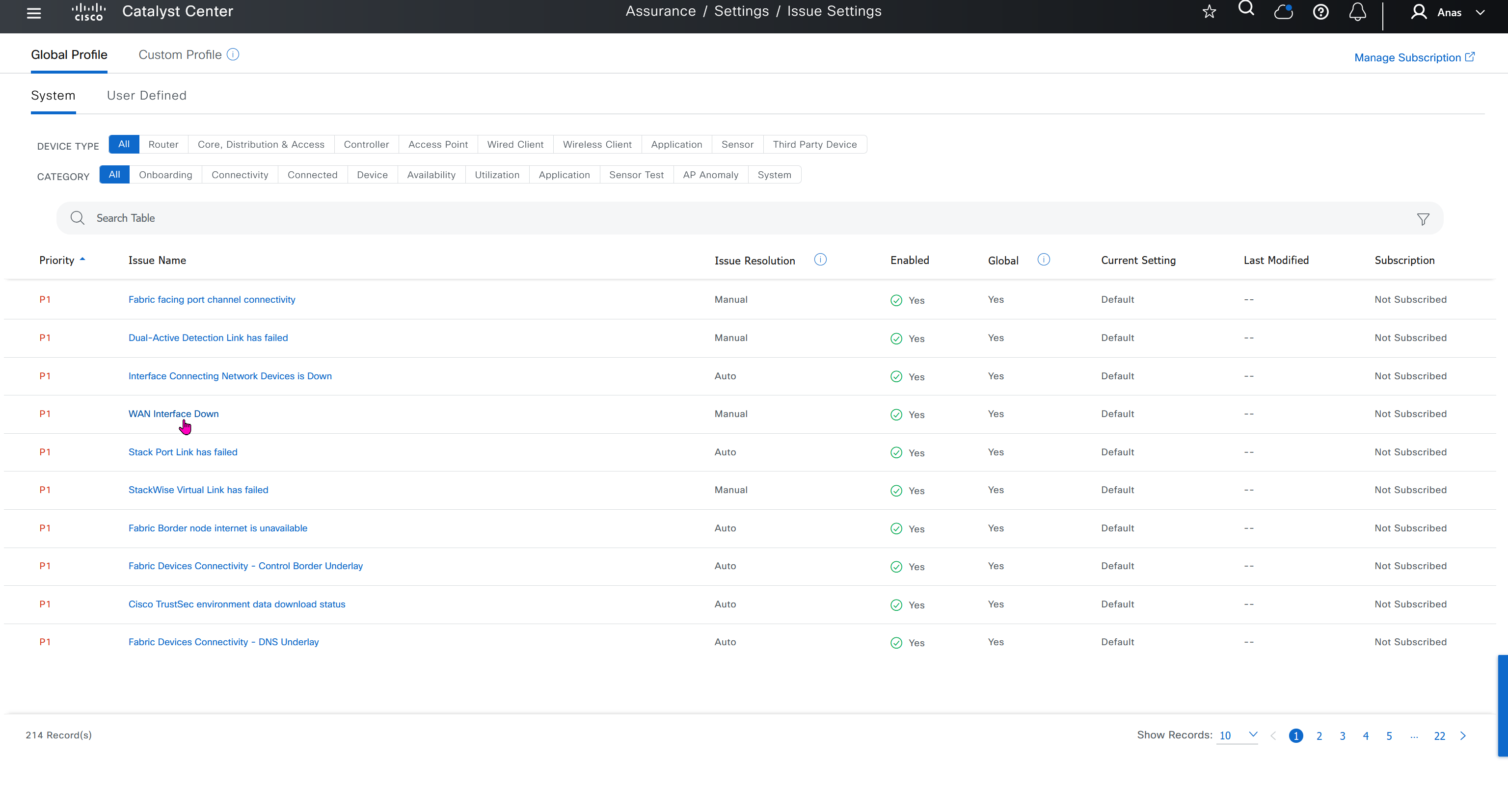
Health score is where you can turn on or off on what is included in determining device health score, these health score threshold values can be modified as well


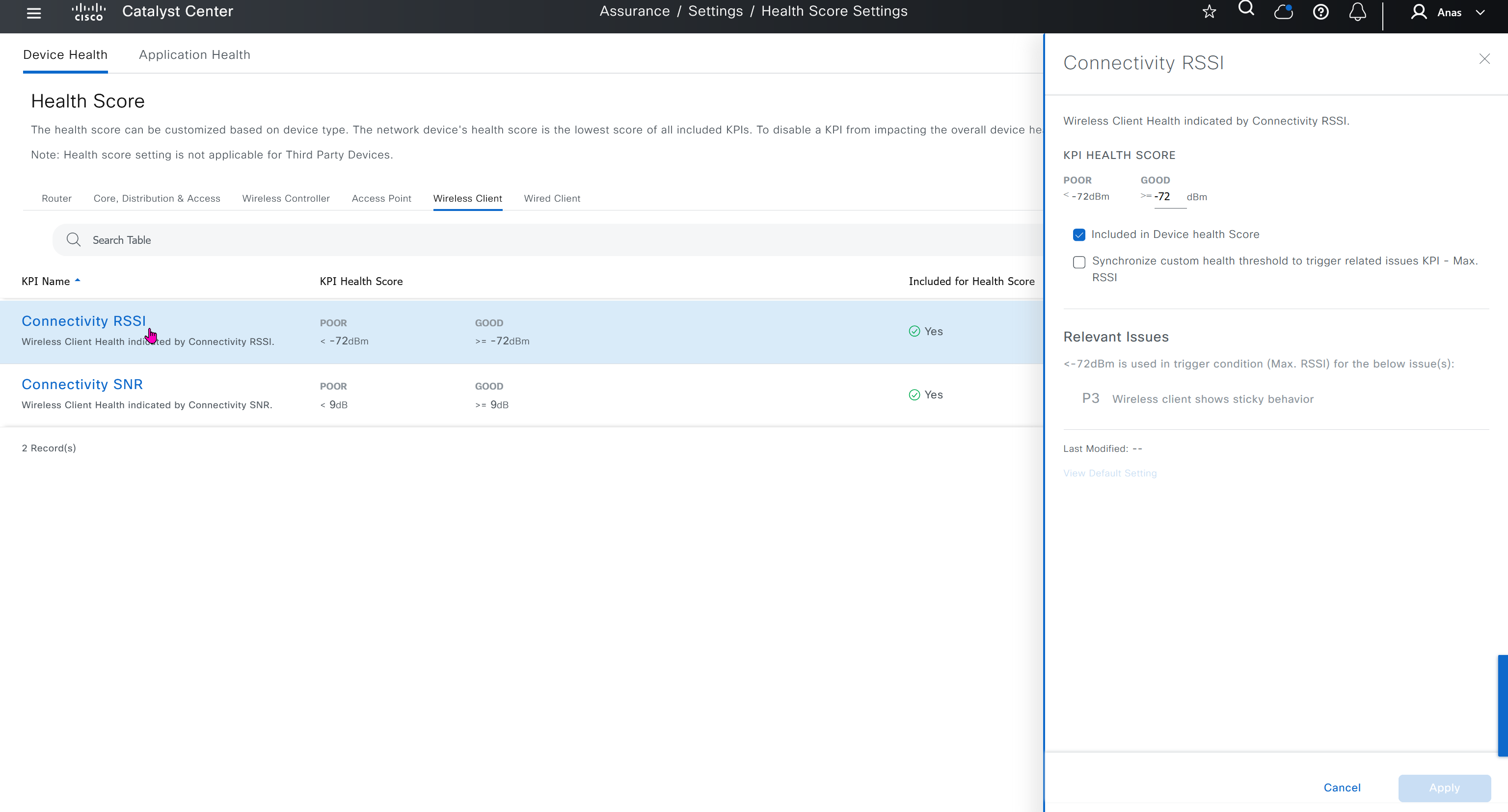

Sensor section here we define test settings such as ping, HTTPs, association test etc
Intelligent capture is where you define how and when you want your AP to perform capture of client traffic
Workflows make things easy for us as they are guided configuration wizards that help us configure things easily and quickly without making mistakes




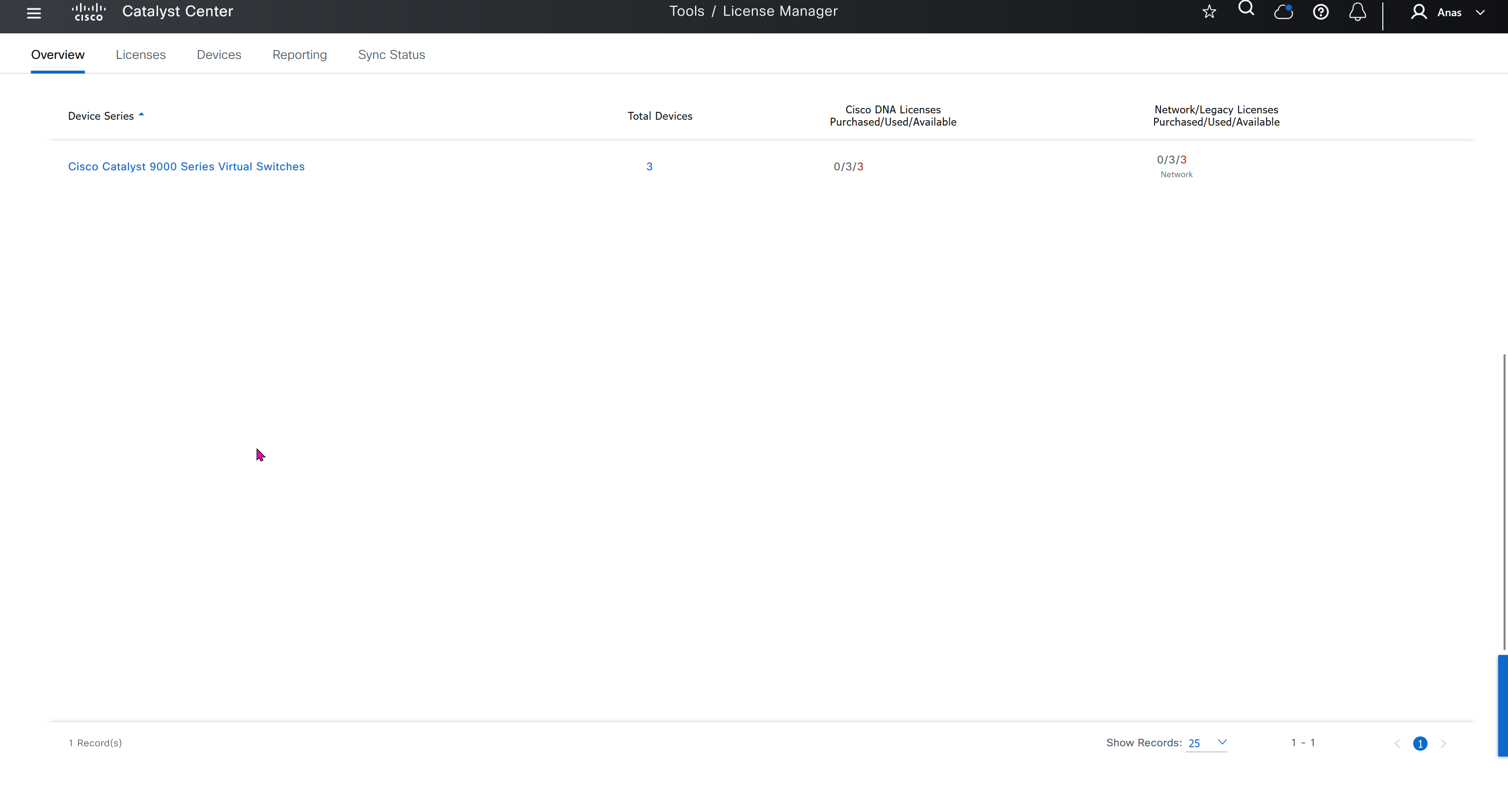
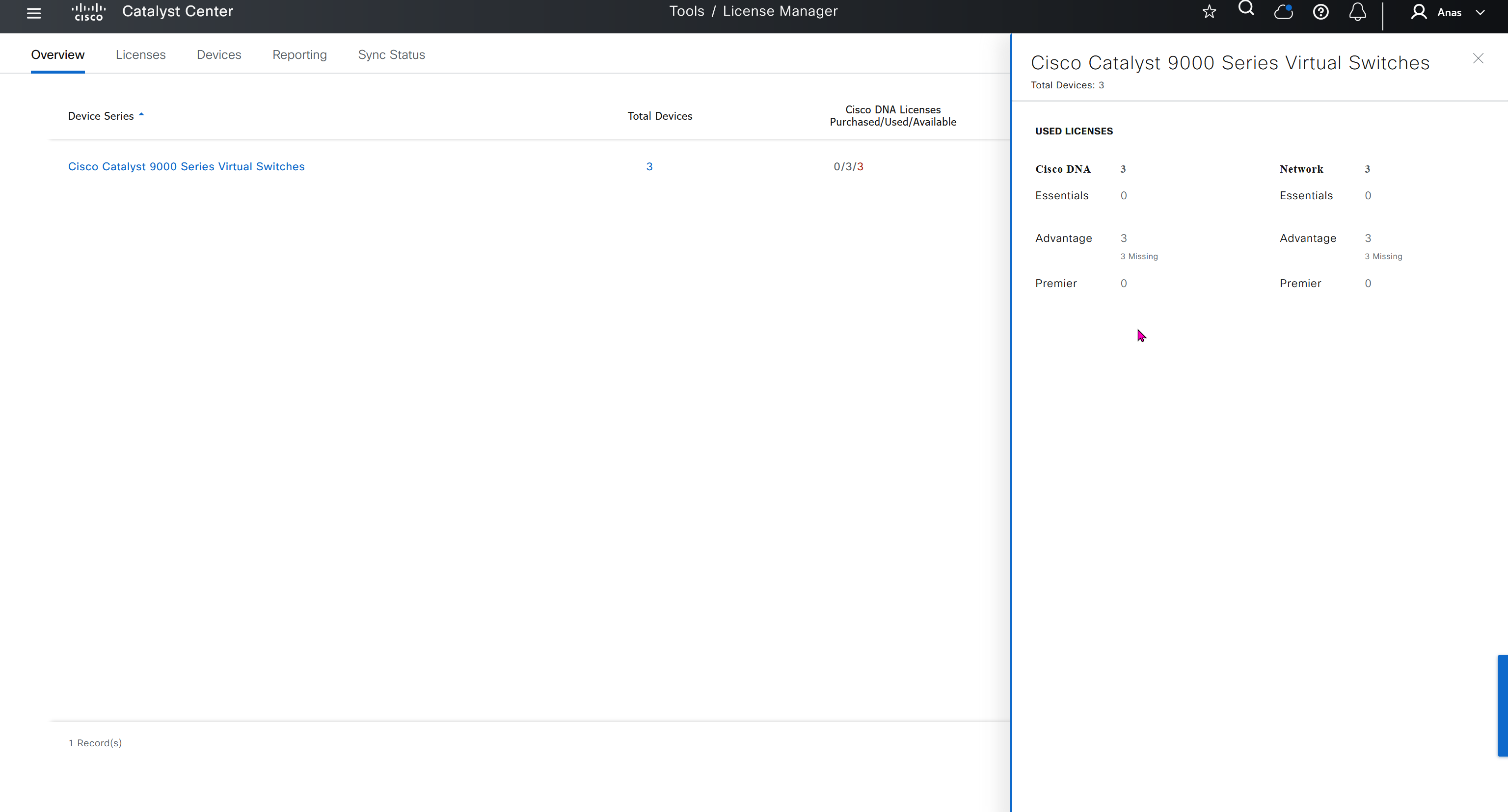
CLI templates is where we create templates, when it is time to apply template then we apply them using Network profiles

Feature templates are graphical UI based configuration unlike CLI template and they dictate best practice rather than manual CLI based templates, this makes configuration like Meraki but we only have this wireless at the moment

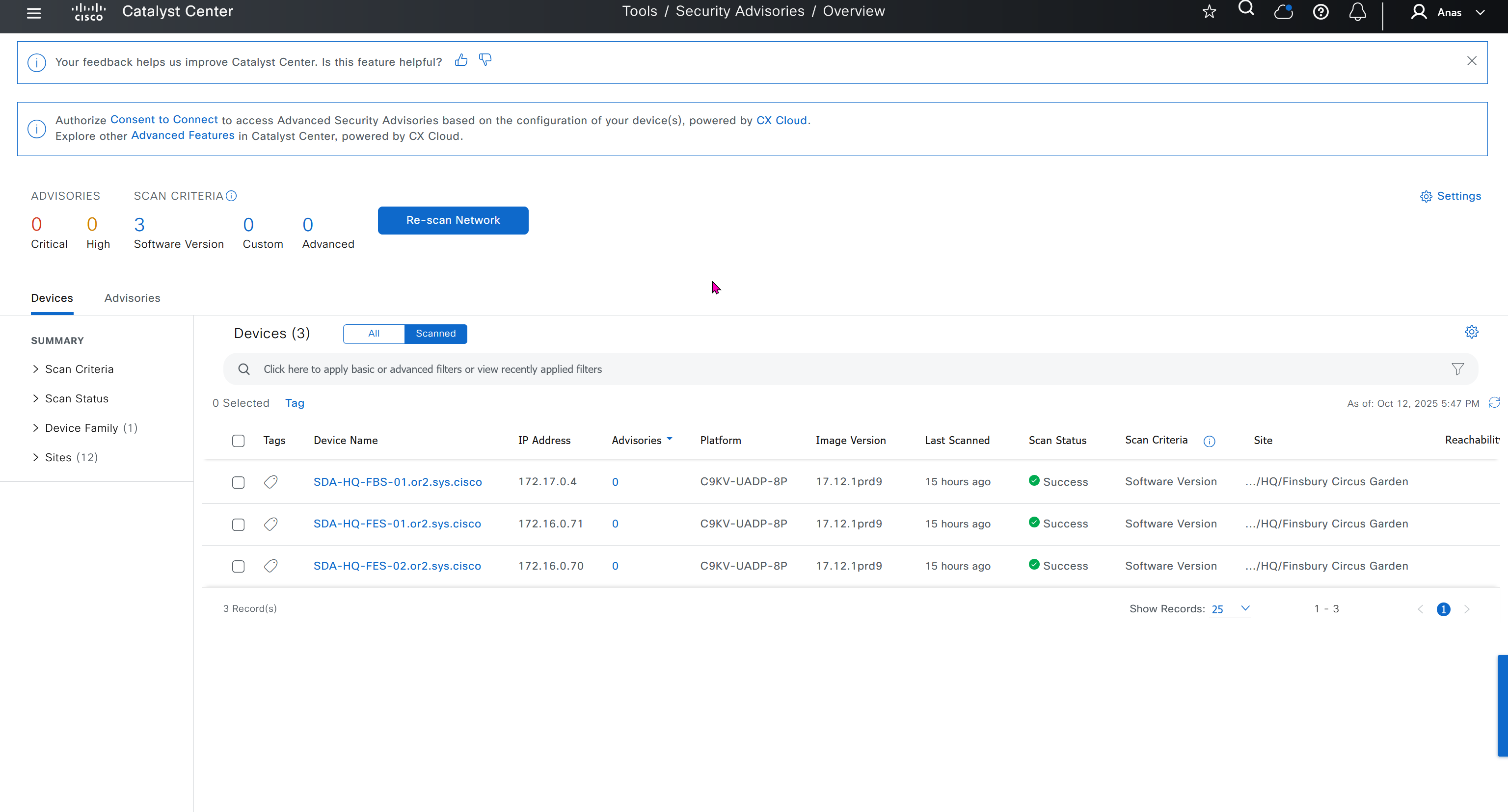
Network reasoner helps troubleshoot offered issues in Network reasoner dashboard

Platform section allows us to use DNAC API for automation and API interaction, it is also used to install device packs for non Cisco devices and also 3rd Party integration such as service now






DNAC comes with report templates







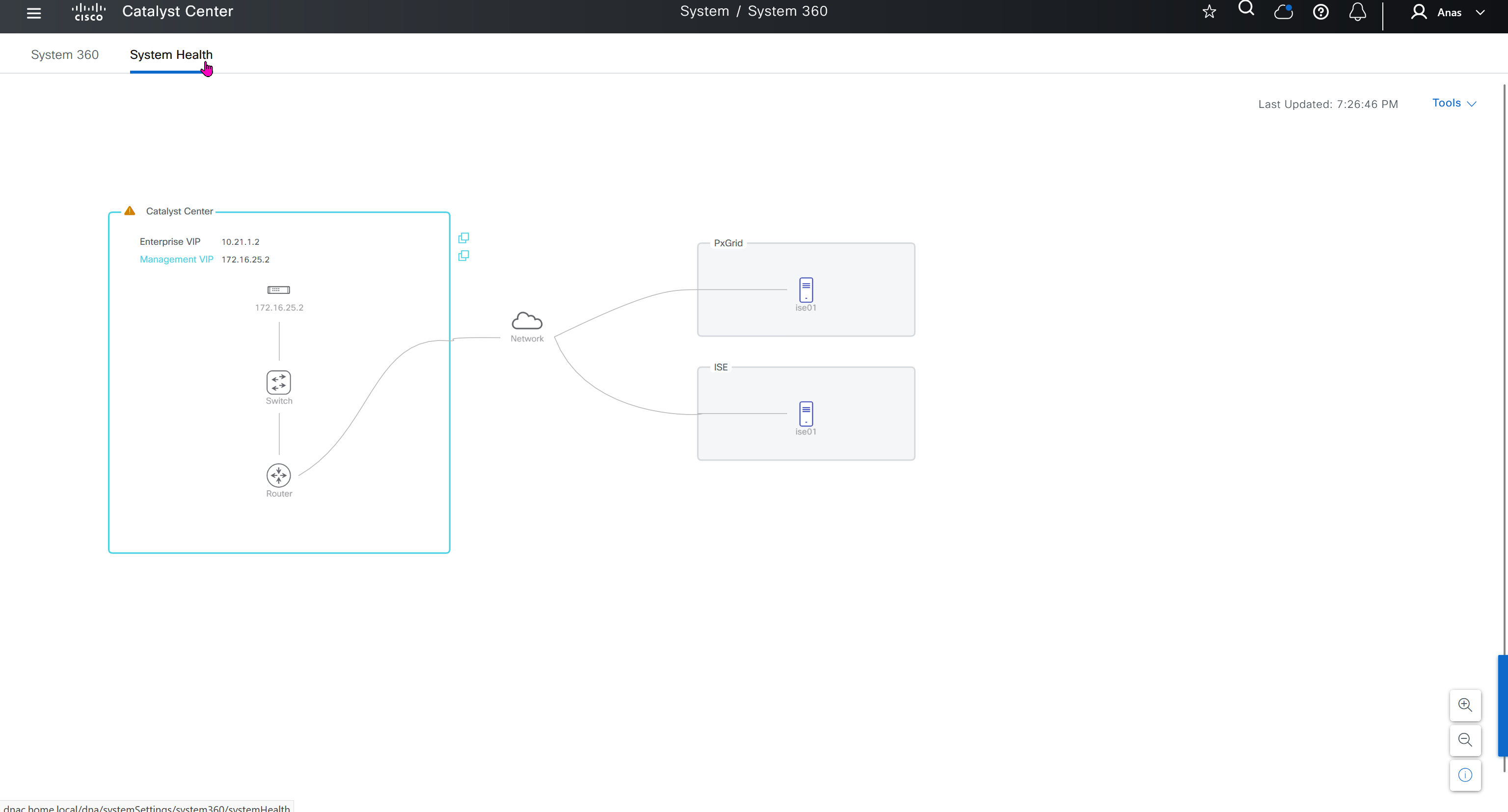




Cisco.com Credentials
Cisco credentials is the same credentials we entered after changing password for DNAC admin on first time login
PnP Connect
PnP connect lets you sync your devices from internet based Cisco’s PnP to DNAC directly, this is used for onboarding routers and switches using PnP in Cloud
Cisco Plug and Play (PnP) Connect is a cloud-based onboarding service that helps you automatically provision new Cisco network devices (switches, routers, access points, etc.) with Cisco DNA Center — no manual configuration or console access needed similar to SDWAN or Meraki onboarding
When a new Cisco device boots up:
- It connects to the PnP Cloud portal.
- The PnP Cloud checks the device’s serial number.
- The device is matched to your DNA Center project.
- The device is redirected to your DNA Center for zero-touch provisioning.
Smart account
“Auto register smart license enabled devices” allows devices to register to selectable “Virtual account inside the Smart account”

Smart Licensing
Smart account defined earlier is used in Smart licensing section, register a smart account and virtual account to have DNAC licensed and in compliance state
Device EULA Acceptance
For LAB I will not accept as not sure what might be the impact on CCO account against licenses
Image Distribution Servers
10.21.1.2 (LOCAL) is DNAC itself, but we can define other image distribution servers not to burden the WAN
Network Resync Interval
This is how often DNAC syncs with network devices, default is 24 hours

SNMP
is timeouts and retires

Authentication and Policy Servers
defined ISE servers
Cisco AI Analytics
This is where you configure AI analytics
Destinations
This is to deliver event notifications when events happen on DNAC
Integrity Verification
Checks if device is compromised on software, hardware level using Known Good Values KGV file from Cisco, which also requires updates from Cisco
IP Address Manager
This is integration with IPAM
Machine Reasoning Engine
Download and keep upto date Cisco’s latest machine learned troubleshooting and reasoning database, make sure it is set to auto update


Debugging Logs
This is to debug logs for DNAC itself, specify a syslog server


Search
Search in DNAC is amazing and you can search clients by MAC address or IP address / track clients with Client 360 link in search result and even search IP pools
API Reference
This comes handy when you are working with API
next post
SDA LM5 – SDA Fabric Virtual Networks
Videos
SDA Fabric Virtual Networks
Fabric Site
Fabric Site contains its own components such as border node, control node, access switches and Wireless controllers – imagine a typical site or building or campus that has network components
A fabric site can span multiple building but only over a high speed, low latency network and not WAN connection
Transit Network
Transit Network either connects multiple Fabric Sites together or connects a Fabric site to an external network
and there are different types of transit networks which will be discussed
Fabric Domain
Fabric Domain is made up of one or more Fabric Sites
Geographic distance between buildings and location decides the fabric site’s boundary
Type of WAN decides the Transit Network type
Depending on the version of SDA and cisco documentation, fabric site can only be so big and scale, if fabric site is bigger than what is supported by SDA, then you will have to break up the single fabric site into 2 Fabric sites
So make sure to check scalability number in Cisco documentation
Make sure you have all devices that will be part of the fabric already discovered, reachable, managed and synced and LAN Automated, preferable compliant also

- Second most important thing is that, make sure that your edge devices do not have a route to DNAC via their default route and must have a specific route, I learned this the hard way
SDA-HQ-FES-01#show ip route 10.21.1.2
% Network not in tableSDA-HQ-FBS-01
conf t
ip route 10.21.1.0 255.255.255.0 172.17.0.3
!
router isis
redistribute static ipSDA-HQ-FES-01#show ip route 10.21.1.2
Routing entry for 10.21.1.0/24
Known via "isis", distance 115, metric 10, type level-2
Redistributing via isis
Last update from 172.16.0.72 on GigabitEthernet1/0/4, 00:00:05 ago
Routing Descriptor Blocks:
* 172.16.0.74, from 172.16.0.64, 00:00:05 ago, via GigabitEthernet1/0/3
Route metric is 10, traffic share count is 1
172.16.0.72, from 172.16.0.64, 00:00:05 ago, via GigabitEthernet1/0/4
Route metric is 10, traffic share count is 1SDA-HQ-FES-01#ping 10.21.1.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.21.1.2, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 114/131/164 msSDA-HQ-FES-01#ping 10.21.1.2 source loopback 0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.21.1.2, timeout is 2 seconds:
Packet sent with a source address of 172.16.0.71
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 111/122/134 ms
DNAC comes with default LAN fabric
We can either choose to use this or create a new fabric
We should always create a new fabric and not use the default
next post
SDA list all mac addresses under a specific VLAN/LISP instances
On All FES switches run this command to collect the LISP instances
show lisp instance-id * ethernet database | include VlanThen on FBS check all the mac addresses under specific VLAN / LISP Instance
show lisp instance-id 8191 ethernet servernext post
Device Telemetry issue
WLC telemtry issue
provision > inventory > select WLCs >
actions > telemtry > update telem settings > check the push config button > deploy
show telemetry internal connectionnext post
dot1x, mab, authenitcation, access-session commands
Command
authentication periodicEnables periodic reauthentication of connected devices.
-The switch forces the endpoint to re-authenticate at regular intervals.
-Helps ensure that access permissions stay valid.
-The interval is usually controlled by the RADIUS server (or another timer setting).
Example use case:
If a device changes security posture (e.g., antivirus disabled), access can be revoked after reauthentication.
authentication timer reauthenticate serverTells the switch to use the reauthentication interval provided by the RADIUS server instead of a locally configured timer.
Common when using Cisco ISE.
Ensures centralized control of session refresh timing.
access-session inherit disable interface-template-stickyPrevents the port from inheriting sticky interface-template settings after authentication.
Why useful
Avoids persistent policy settings staying applied after the session ends.
access-session inherit disable autoconfStops automatic inheritance of autoconfiguration session settings.
Why useful
Gives tighter manual control over authentication behaviour on the interface.
access-session port-control autoSets the port to automatic authentication mode.
Meaning:
Port starts unauthorized
Device must authenticate
Access granted only after successful authentication
This is the standard mode for secure access ports.
Other possible modes (for reference):
| Mode | Behaviour |
|---|---|
| auto | Authenticate before allowing access |
| force-authorized | Always allow access |
| force-unauthorized | Always block access |
mabEnables MAC Authentication Bypass for devices without supplicant
Used when a device does NOT support 802.1X, such as:
printers
IP phones
IoT devices
cameras
Instead of credentials, the switch sends the MAC address to the RADIUS server for authentication.
Typical workflow:
Switch tries 802.1X
If no response → fallback to MAB
MAC checked in RADIUS database
dot1x pae authenticator| Role | Device |
|---|---|
| Supplicant | Client device |
| Authenticator | Switch |
| Authentication server | RADIUS / ISE |
Configures the switch port as an 802.1X authenticator.
This command enables the switch to perform authentication enforcement.
dot1x timeout tx-period 5Sets the interval between EAP request transmissions to 5 seconds.
0 sec → request sent
5 sec → request sent again
10 sec → request sent again
This controls the gap between attempts.
dot1x timeout supp-timeout 5Sets how long the switch waits for a supplicant response before retrying.
Example:
If client doesn’t respond in 5 seconds → retry
dot1x max-req 3Maximum number of authentication request retries sent to the supplicant.
After 3 failures:
Switch may fall back to MAB (if enabled).
Retries up to 3 times If no response → tries MAB
dot1x max-reauth-req 3Maximum number of retries during reauthentication attempts.
If exceeded:
Session may be terminated or fallback triggered depending on policy.
Putting timers together
Switch sends request
Waits 5 seconds (supp-timeout)
Retry after 5 seconds gap (tx-period)
Repeat up to 3 times (max-req)
tx-period – How often I ask – this will be continuous process when port comes up
supp-timeout – How long I wait – this is what triggers retries
Retries are controlled by max-req, and the spacing between retries is controlled by tx-period.
supp-timeout only controls how long the switch waits for a response after sending each request. supp-timeout simply marks the device as having no supplicant
dot1x timeout supp-timeout 3
dot1x timeout tx-period 10
dot1x max-req 3t=0 send request
t=3 no reply → supp-timeout expires
t=10 next retry sent (tx-period controls this)
t=13 no reply → supp-timeout expires
t=20 next retry sent
t=23 no reply → supp-timeout expires
STOP (max-req reached)
more…
coming soon
next post
QoS
QoS
Why QoS?
Even in the presence of 10G links or 100G links we still need QoS since we could have 100Mbps internet link

Some oversubscribed topologies have a need for QoS (just in case all servers start transmitting at the same time)
QoS only works when there is congestion at times of the day, if your network is congested all the time then you need to increase more bandwidth
2 types of QoS models
Best Effort – FIFO queuing , first packet that comes into the router is the first packet that will exit the [queue + interface] without any preferential treatment in a straight line
DiffServ – means “differentiated” “services” which means different treatment for different services
QoS Tools
Classification and Marking (tagging at IPv4 level)
Congestion Avoidance via Policing / Dropping (it is best to “avoid” first by cutting)
Congestion Management via Queueing | Scheduling | Shaping (delaying only as cutting / policing has been done earlier) – at this stage you can only manage as avoidance was earlier (tried to avoid but can only manage now)
CMPQS – Classification , Marking , Policing , Queueing , Shaping

CMP — <ROUTER> — CMPQS
Classification may happen on ingress (3) and egress (8) in the packet path
but classification should be done as close to the source on ingress
but sometimes the attributes for classification are not known until the exit interface has been chosen. This is true for locally generated packets and even some transit packets,
If exit interface has service policy applied and that interface is chosen based on destination IP and routing table, Classify on Egress (8) is for those scenarios
Similarly, a packet may be marked on ingress (4), but perhaps requires to be re-marked on egress (9). For example, a policer may re-mark a nonconforming packet on egress rather than drop it—the fact that the packet is nonconforming is not known until the packet reaches the egress interface (where non conformance is determined by filling up queues and congestion) that has service policy applied and that interface is chosen based on destination IP and routing table, Mark on Egress (9) is for those scenarios
Classification and Marking
We want to save on processing for all nodes in the network and classify only once and best way to do is for edge nodes to classify once but tag or mark for it to be used forever through the network
All other tools in the list also use marked packets such as queueing , congestion avoidance and policing / shaping etc
IPv4 packet carries an 8-bit Type of Service (ToS) byte
IPv6 header carries an 8-bit Traffic Class field
first 3 bits in both IPv4 and IPv6 are for IP Presedence
DSCP first 6 bits offer a maximum of 64 possible classes of service
There is also layer 2 marking called Ethernet 802.1p CoS bits
General marking guidance
but in reality only 8 classes traffic model is implemented instead of 12 shown above

Marking can be new marking or even remarking such as marking down the class of non conforming or violating traffic
Class-based marking occurs after classification of the packet (in other words, set happens after the match criteria). Therefore, if used on an output policy, the packet marking applied can be used by the next-hop node to classify the packet but cannot be used on this node for classification purposes. However, if class-based marking is used on an ingress interface (blindly without going through match purely based on interface the traffic is coming from) as an input policy, the marking applied to the packet can be used on the same device on its egress interface for classification purposes.
On output policies both classification and marking can happen before or after tunnel encapsulation, depending on where the service policy is attached. Therefore, if a policy is attached to a GRE or IPsec tunnel interface, the marking is applied to the original inner packet header. However, if the policy is attached to the physical interface, only the tunnel header (the outer header) is marked, and the inner packet header is left unchanged.
CoS is usually used at Ethernet Layer 2 frames, contains 3 bits and can only be done at trunk, it makes sense to have it only on trunk since trunk is the only place where multiple VLANs traffic aggregate and compete from one another
CS is a term used to indicate a 3-bit subset of DSCP values; it designates the same 3 bits of the field as IP Precedence, but the interpretation of the field values maps to the per-hop behaviors as per the RFCs defining 6-bit DSCPs.
DSCP is a set of values, based on a 6-bit width
TID is a term used to indicate a 3-bit field in the QoS Control field of the 802.11 WiFi MAC frame. The 8 values of this field correspond to eight user priorities (UPs). TID is typically used for wireless Ethernet connections, and CoS is used for wired Ethernet connections
Trust Boundary
A trust boundary is a network location where packet markings are not accepted and are rewritten
In an enterprise campus network, the trust boundary is almost always at the edge switch
For example, a user computer set up to mark all traffic at DSCP EF will be ignored by the access switch at the trust boundary, and the traffic is inspected and re-marked according to enterprise QoS policies implemented on the switch.
Video traffic comes in a wide array of different traffic types belonging to applications that may be extremely high priority and delay sensitive (such as immersive Cisco TelePresence traffic) to unwanted Scavenger class traffic (nonorganization entertainment videos, such as YouTube) that in many cases may be dropped outright.
IEEE 802.11 specification, which provides a means for wireless devices to request traffic in different access categories with different markings (which are usually on the untrusted side of the network trust boundary and so raises the question of whether the trust boundary for wireless devices could, or should, be extended to the wireless device under certain circumstances).
L2 Frame
Ethernet frames can be marked with their relative importance at Layer 2 by setting the 802.1p user priority bits (CoS) of the 802.1Q
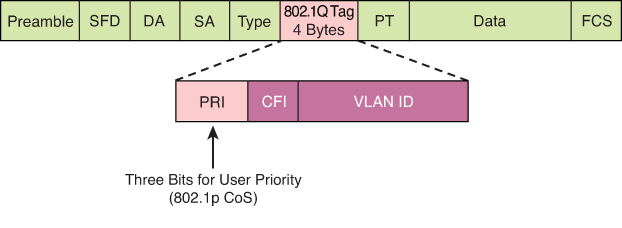
Wireless Ethernet frames can be marked at Layer 2 by setting the 802.11 WiFi Traffic Identifier (TID) field with in the QoS Control field
GRE , IPSec

The marking field from the inner header might or might not be copied automatically to the outer header. If not, explicit CLI must be used to mark the outer header. Methods to achieve this include the qos pre-classify CLI on the tunnel interface
l2tp tos reflect CLI can also be used on L2TP tunnels. L2TPv3 is widely used to transport L2 frames over IP networks.
MPLS
4-bit CoS field – 3 bits MPLS EXP (Experimental) bits and 1 bit Bottom of Stack Indicator
In MPLS tunneling scenarios, there can be multiple MPLS headers on a packet. The set mpls experimental imposition command sets a value on all labels on the packet, and the set mpls experimental topmost command sets a specific value only on the outermost label.
DSCP PHBs: Best-Effort (BE or DSCP 0), Assured Forwarding (AFxy), Expedited Forwarding (EF) and Class-Selector (CSx) code points
Class-Selector (CSx) code points have been defined to be backward compatible with IP precedence. (In other words, CS1 through CS7 are identical to IP precedence values 1 through 7

The first digit denotes the “AF class” and can range from 1 through 4. The second digit refers to the level of drop preference within each AF class and can range from 1 (lowest drop preference) to 3 (highest drop preference).
For example, during periods of congestion (on an RFC 2597-compliant node), AF33 would statistically be dropped more often than AF32, which, in turn, would be dropped more often than AF31
NBAR
NBAR is a L4–L7 deep-packet inspection classifier triggered by the match protocol in class-map
It is a more CPU-intensive than classifiers that match traffic by markings (DSCPs), addresses, or ACLs.
identifying application layer protocols by matching them against a Protocol Description Language Module (PDLM)
PDLM definitions are modular, and new ones can be added to a system without requiring a Cisco IOS upgrade.
Two modes of operation that NBAR offers:
Passive mode: Discovers and provides real-time statistics on applications per interface or protocol and gives bidirectional statistics such as bit rate (bps), packet, and byte counts
Active mode: Classifies applications for the purpose of marking the traffic so that QoS policies can be applied.
Router# show run
interface fastethernet 0/0
ip nbar protocol-discovery
! NBAR used as a classifier
Router# show run
class-map match-any MY-VIDEO
match protocol cuseeme
match protocol h323
match protocol rtp video
-----------------------------------------------------
class-map match-any ERP
match protocol sqlnet
match protocol ftp
match protocol telnet
class-map match-any AUDIO-VIDEO
match protocol http mime "*/audio/*"
match protocol http mime "*/video/*"
class-map match-any WEB-IMAGES
match protocol http url "*.gif"
match protocol http url "*.jpg|*.jpeg"
-----------------------------------------------------
match protocol h323 ! identifies all H.323 voice traffic
match protocol rtp [audio | video | payload-type payload-string]Sequence of classes within a policy map
Sequence of classes within a policy map is significant
packet is examined against each subsequent class within a policy map until a match is found. When found, the examination process terminates, and no further classes are checked. If no matches are found, the packet ends up in the default class (because policy map is applied on the interface and every policy map has class class-default section)
class-map match-all FAX-RELAY
match dscp ef
class-map match-all VOICE
match protocol rtp audio
!
policy-map VOICE-AND-FAX
class FAX-RELAY
priority 64
police cir 64000
class VOICE
priority 216
police cir 216000No traffic would ever show against the VOICE class because both voice and fax-relay traffic would match on DSCP EF and would therefore be assigned to the FAX-RELAY class, to fix it we will need to reverse the order of classes inside policy map
service-policy command also specifies whether the policies should be applied to ingress or egress traffic on this interface using keywords input and output.
policy-map POLICY-1
...
bandwidth 20000
policy-map POLICY-2
...
bandwidth 64000
!
interface Ethernet 1/0
service-policy input POLICY-1
!
interface Ethernet 1/1
service-policy output POLICY-2Subinterfaces

the two subinterfaces are collectively allowing 22K of traffic, which in turn is shaped to 20K throughput, on the main interface to maintain an aggregate throughput not to exceed 20K and shave off the extra 2Kbps.
! Definitions for sub-interface GE1.1
policy-map CHILD1
class VOICE1
priority 3000
class VIDEO1
bandwidth 5000
policy-map PARENT1
class class-default
shape average 15000
service-policy CHILD1
!
! Definitions for sub-interface GE1.2
policy-map CHILD2
class VOICE2
priority 1500
class VIDEO2
bandwidth 2500
policy-map PARENT2
class class-default
shape average 7000
service-policy CHILD2
!
! Definitions for the main interface
policy-map AGGREGATE
class class-default
shape average 20000
!
interface ge 1/1.1
service-policy output PARENT1
interface ge 1/1.2
service-policy output PARENT2
interface ge 1/1
service-policy output AGGREGATEPARENT1 policy:
Shapes all traffic on GE1.1 to an average of 15 Mbps.
Within that shaped pipe, it applies the CHILD1 policy, enforcing priority for voice and bandwidth for video.
AGGREGATE policy:
Shapes the whole physical interface GE1/1 to 20 Mbps total.
This ensures the combined traffic from both sub-interfaces (GE1.1 + GE1.2) cannot exceed 20 Mbps.
GE1/1.1 → applies PARENT1 (→ CHILD1) = 15 Mbps max.
GE1/1.2 → applies PARENT2 (→ CHILD2) = 7 Mbps max.
GE1/1 → applies AGGREGATE = 20 Mbps total for both.
all traffic at the interface level being shaped overall to 20K (policy-map AGGREGATE), while voice traffic within that rate is guaranteed to get a minimum of 3K or 1.5K of bandwidth
Marking conversion with table map
You can build a conversion table with the table-map CLI and then reference the table in a set command to do the translation
Any values not explicitly defined in a “to-from” relationship are set to the default value
If the default value is omitted from the table, the content of the packet header is left unchanged.
In this example, the DSCP value will be set according to the CoS value defined in the table
table-map MAP1
map from 0 to 0
map from 2 to 1
default 3
!
policy-map POLICY1
class traffic1
set dscp cos table MAP1Congestion Avoidance
Congestion avoidance aims to control traffic before it enters the queueing phase. Congestion should be avoided at all cost because it can cause TCP global sync for all TCP connection flows simultaneously
dropping and marking the packet, are applied before the packet enters a queue for egress scheduling
“bandwidth,” “police,” and “shape”
Bandwidth
The bandwidth command is used to assign “minimum bandwidth” to a traffic class during congestion times. Just like a rubber “band” can be stretched and then it comes back to its original size, This is how a class can use positively more bandwidth or minimum of defined bandwidth (under congestion)
It is often used in conjunction with the Low Latency Queueing (LLQ) or Class-Based Weighted Fair Queueing (CBWFQ) to assign different classes different bandwidths. Assigning predictable bandwidth or chunks of interface speed to classes is much better way to handle the times of congestion
bandwidth {value in kbps}bandwidth 2000 (This allocates 2000 kbps to the class.)Police
The police command is used to force traffic to a rate limit regardless of congestion or not. Police command and shape command are applied all the time regardless if congestion is happening or not
Traffic of class where policing is applied can use less or equal to rate specified in police command
It is used to control the “max” speed a traffic can use often used to hard rate limit certain class.
Remember this from Police on highway, they make public drivers conform to max speeds defined, if a driver exceeds that speed, police stops or gives ticket to that person
Policing drops or marks packets that exceed the specified rate, traffic exceeding the specified rate is either dropped or remarked for lower marking
police {rate in bps} [burst-normal in bytes] [burst-max in bytes] [conform-action transmit] [exceed-action drop] [violate-action {drop | remark}]
police 1000000 20000 20000 conform-action transmit exceed-action drop
(This limits the traffic to 1 Mbps, with a normal burst of 20,000 bytes and a maximum burst of 20,000 bytes. Conforming packets are transmitted, while exceeding packets are dropped.)
Shape
The shape command (traffic shaping) is used to buffer and smooth out bursts of traffic to a specified rate regardless of the congestion or not. Like police command, it also has a reducing function, It is used to ensure that traffic rate is controlled, and used in scenarios where you want to rate limit traffic to a rate but also not drop any traffic instead delay it.
Shaping delays excess packets by storing them in a queue , buffer and releasing them at a controlled rate. This helps in smoothing traffic flows and prevents sudden bursts that could overwhelm network devices.
shape average {rate in bps} [burst-size in bytes] [excess-burst-size in bytes]
Example: shape average 1000000 20000 20000
(This shapes the traffic to an average rate of 1 Mbps, with a burst size of 20,000 bytes and an excess burst size of 20,000 bytes.)
Key Differences:
Bandwidth vs. Police:
bandwidth reserves a minimum guaranteed bandwidth, ensuring that a class gets its share of the link capacity even under congestion.
police enforces a maximum rate, dropping or marking packets that exceed this rate.
Police vs Shape:
police drops or marks packets that exceed the specified rate, providing a hard limit.shape smooths out bursts of traffic instead of dropping packets, sending traffic at a controlled rate.

Policers are also often deployed at egress to control bandwidth used (or allocated) to a particular class of traffic, because such a decision often cannot be made until the packets reach the egress interface.
Shapers are commonly used on enterprise-to-service-provider links (on the enterprise egress side) to ensure that traffic destined for the service provider (SP) does not exceeds a contracted rate
Policer and Tail drop
When traffic exceeds the policed pipe, it does not expand the pipe but instead excess traffic / rate stays at the tail of the pipe and that is why it is called tail drop
A policer does tail drop, which describes an action that drops every packet that exceeds the given rate, until the traffic drops below the rate
Tail drop can have adverse effects on TCP retransmission methods and cause TCP global sync. Another mechanism of dropping packets is random dropping, which proactively drop packets before the queue is full to signal TCP flows to slow down inside the queue, known as random early detection (RED) and weighted RED (WRED). These methods work more effectively with TCP retransmission logic, but they are not policing/shaping tools. RED and WRED which are part of queue management / congestion avoidance (sometimes described as “intelligent dropping” inside the queue)
Instead of waiting for the queue to fill up and then tail-drop, RED/WRED randomly drop packets early, which prevents global synchronization and keeps throughput smoother.
Policing and RED/WRED can be applied on same service policy on interface but they work at different stages of packet handling, so you need to be clear how they interact.
Policing action will be taken as shown in above diagram since Congestion Avoidance takes place first and that controls the rate but for some reason if queue starts to fill up due to any other reason (since back pressure is on due to constant rate coming through policer) then WRED will activate
police command for tail drop and random-detect for WRED
They don’t “conflict,” but the policer acts first. If the policer already drops excess traffic, less traffic even reaches the queue, so WRED might do little and in production networks only should be implemented, unless there are complaints about TCP Global Sync, then honestly pipe should be increased rather than implementation of WRED
More common combo = shaping + WRED (because shaping delays bursts, then WRED handles congestion gracefully inside the queue).
policer when drops packets, it does “tail drop” on queues, it sounds like a queueing function (congestion management) but it is not, it is part of policer and it is general drop of traffic that simply exceeds the rate or pipe
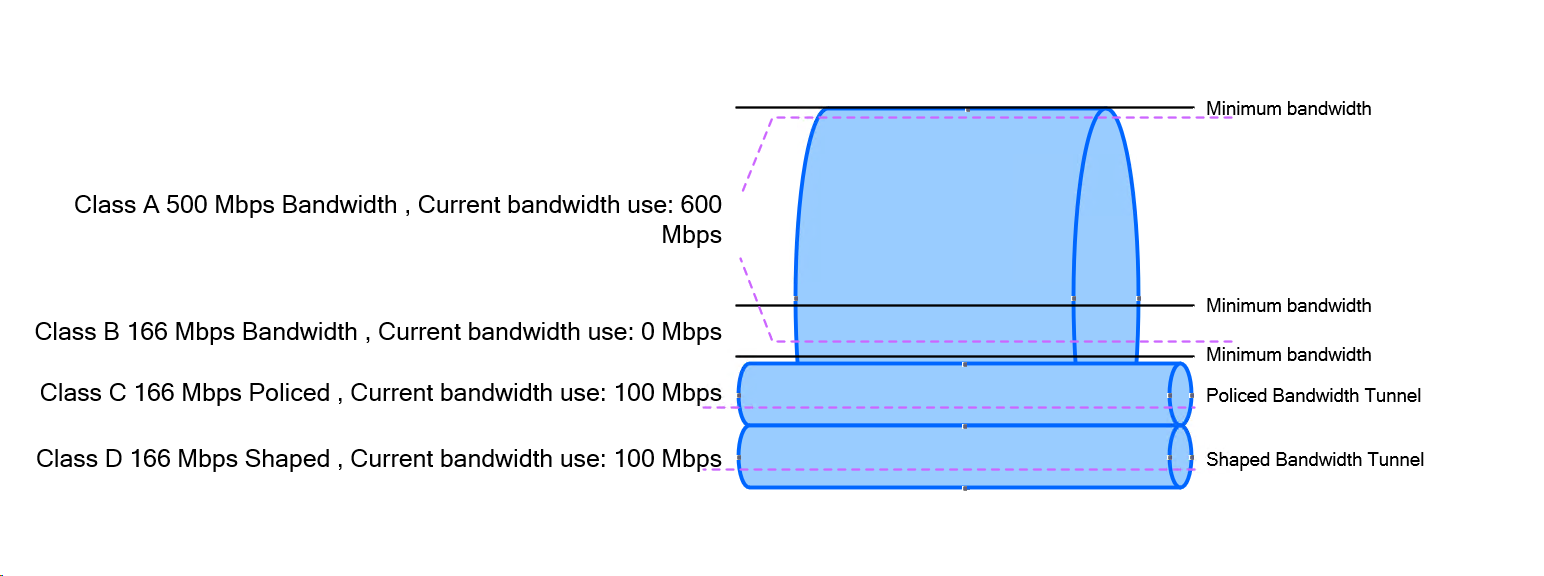
When a traffic rate is exceeded, a policer can take one of two actions:
- Drop the traffic
- Re-mark
Section: Random Detect example with remark , mark down
re-marking (or markdown) should be done according to standards-based defined in Per Hop Behavior PHB – Assured Forwarding (AF) for example: excess traffic arriving as AFx1 should be marked down to AFx2 (or AFx3, whenever dual-rate policing is supported)
Then when traffic reaches the queue (congestion management), queue should be configured with (DSCP)-based WRED, WRED policy should be to drop AFx3 (statistically) more aggressively than AFx2, which in turn should be dropped (statistically) more aggressively than AFx1.
! ---- Classify AF queues (typical) ----
class-map match-any AF1
match dscp af11 af12 af13
class-map match-any AF2
match dscp af21 af22 af23
class-map match-any AF3
match dscp af31 af32 af33
class-map match-any AF4
match dscp af41 af42 af43
! ---- Policy with WRED tuned by drop precedence ----
policy-map WAN-OUT
class AF1
bandwidth percent 10
random-detect dscp-based
! AF13 (x3) most aggressive
random-detect dscp af13 20 40 5
! AF12 (x2) medium aggressive
random-detect dscp af12 30 55 7
! AF11 (x1) least aggressive
random-detect dscp af11 40 70 10
class AF2
bandwidth percent 10
random-detect dscp-based
random-detect dscp af23 20 40 5
random-detect dscp <DSCP-value> <min-threshold> <max-threshold> <mark-prob-denominator>
random-detect dscp af23
This tells the router to apply DSCP-based WRED to packets marked AF23.
Each DSCP value can have its own drop profile.
<min-threshold> → 20
This is the queue depth (in packets) at which WRED starts dropping probabilistically.
At queue length below 20 packets, no drops occur for AF23.
<max-threshold> → 40
This is the queue depth at which WRED reaches 100% drop probability for AF23.
At 40 packets or more, all AF23 packets are dropped.
<mark-prob-denominator> → 5
This controls the slope of the drop curve between min and max threshold (as seen in chart below).
Drop probability = 1 / denominator at max-threshold
Here: 1/5 = 20% max probability (at threshold just below 40).
So queue depth
at 20 → 0% drop chance,
at 30 → ~10% drop chance,
at 39 → ~20% drop chance,
at ≥40 → 100% drop.
AF23 (x3): min 20, max 40, denom 5 → starts dropping early, ramps quickly → Most aggressive (drops at shallow queue depth).
AF22 (x2): min 30, max 55, denom 7 → later start, gentler slope → Medium aggressive.
AF21 (x1): min 40, max 70, denom 10 → starts dropping late, gentlest slope → Least aggressive (protected).
random-detect dscp af22 30 55 7
random-detect dscp af21 40 70 10
class AF3
bandwidth percent 10
random-detect dscp-based
random-detect dscp af33 20 40 5
random-detect dscp af32 30 55 7
random-detect dscp af31 40 70 10
class AF4
bandwidth percent 10
random-detect dscp-based
random-detect dscp af43 20 40 5
random-detect dscp af42 30 55 7
random-detect dscp af41 40 70 10
class class-default
fair-queue
random-detect
! Apply to the egress interface
interface GigabitEthernet0/0
service-policy output WAN-OUT✅ So: AFx3 packets hit drop earliest and hardest, AFx2 later/softer, AFx1 latest and mildest.
This all happening in a single queue and this queue contains multiple packets with AF21 , AF22 and AF23 packets and as queue if filling up they are all getting dropped in progression but AF23 will start dropping early and hard before AF21 starts dropping
See how drop probability gets lower and lower (AF21 at 10%) before 100% drop, as this is design intention to have AF21 suffer from only 10% of total packets drop before queue that has multiple packets made up of AF23 , AF22 and AF21 hits queue size of 70
What if we want drop probability to be 80%?

1 / 80 = 0.0125
0.0125 * 100 = 1.25
If we enter 1.25 that will not be accepted by cisco command line and it only allows us whole numbers
If we want increase in drop probability we can use 2 which will give us sharp drop of 50%
Token Bucket Algorithms
Token bucket algorithms are metering engines that keep track of how much traffic can be sent
One token permits a single unit (usually a bit, but can be a byte) of traffic to be sent
New Tokens equal to “CIR” are granted usually every second
For example, if the CIR is set to 8000 bps, 8000 tokens are placed in a bucket at the beginning of the time period. Each time a 1 bit of traffic passes “policer”, the bucket is checked for tokens
-> If there are tokens in the bucket, the traffic is viewed as conforming to the rate and the typical action is to send the traffic.
-> One token is removed from the bucket for each bit of traffic passed.
-> If there are no tokens, any additional offered traffic is viewed to exceed the rate, and the exceed action is taken, which is typically either to re-mark or drop the traffic.
At the end of the second, there might be unused tokens. The handling of unused tokens is a key differentiator among policers
Rate limit using TDM
With TDM, when a rate limit (or CIR) is imposed on an interface, the traffic bits are pinned to subsecond milliseconds – 1 thousandth of a second units
This multiple subsecond time slices are combined into larger interval called “Tc”
For example, if an 8-Kbps CIR is imposed on a 64-Kbps link, traffic can be sent for an interval of 125 ms (64,000 bps / 8000 bits). We just divided the total rate of the link with desired rate 64000 / 8000 = 8, and 8th of a second is 125 ms and that 125 ms will be our Tc value.
The entire amount allowed by the CIR (8000 bits) could theoretically be sent at once, but then the algorithm would have to wait 875 ms before it could send any more data
Therefore, to smooth out the allowed flow over each second, traffic is released on the link in smaller bursts called committed burst “Bc” which can be sent per Tc interval
Below illustration only shows scenarios for different Tc times and not Tc of 125 ms
It is not necessary for device to keep sending during whole of Tc, instead device can send for some duration of Tc but send whole of Bc and wait for next Tc interval as shown in last example of Bc = 1000 in illustration above
token bucket algorithm is as follows: Bc = CIR * Tc (Bits = Rate * Time)
Cisco IOS Software does not allow the explicit definition of the interval (Tc). Instead, it takes the CIR and Bc values as arguments
From a practical perspective, when implementing networks, Tc should not exceed 125 ms. Shorter intervals can be configured and are necessary to limit jitter in real-time traffic, but longer intervals are not practical for most networks because the interpacket delay becomes too large
so we can drive down the value of Tc from 125 ms to 62.5 ms (half) using below
Bc = CIR * Tc (Bits = Rate * Time) using this formula we can figure out or set the Tc
for Tc of 125 ms
CIR or total rate 64000 bits/sec * Tc 125 ms = 8000000
8000000 / 1000 ms or 1 sec for result in seconds = 8000 -> Bc
( 64000 * 125 ) / 1000 = 8000 -> Bc
for Tc of 62.5 ms
( 64000 * 62.5 ) / 1000 = 4000 -> Bc
Types of Policers
There are different variations of policing algorithms, including the following:
Single-rate two-color
Single-rate three-color
Dual-rate three-color
Single-Rate Two-Color Policers
The original policers implemented use a single-rate, two-color model with
A single rate and single token bucket algorithm
Traffic identified as one of two states (or colors): conforming to or exceeding the CIR. Marking or dropping actions are performed on each of the two states of traffic
Single-Rate Three-Color Policers
An improvement on single-rate two-color policer algorithm
Traffic identified as one of three states (or colors): conforming to, exceeding or “violating” the CIR.
First part operates just like the single-rate two-color system But if there are any tokens left over in the bucket after each time period, these are placed in the second bucket to be used as credits later for temporary bursts that might exceed the CIR
Tokens placed in this second bucket are called the excess burst (Be). Be is the maximum number of bits that can exceed the Bc burst size.
With this two token-bucket mechanism, traffic can be identified in three states (or three colors) as follows:
Conform: Traffic within the CIR—usually sent (optionally re-marked)
Exceed: Traffic within the excess burst allowance above CIR—can be dropped, or re-marked and sent
Violate: Traffic beyond the excess burst—usually dropped (optionally re-marked and transmitted)
CIR: Committed information rate, the policed rate
CBS: Committed burst size, the maximum size of the first token bucket
EBS: Excess burst size, the maximum size of the second token bucket
Tc: Token count of CBS, the number of tokens in the CBS bucket (Do not confuse the term Tc here with the earlier use of Tc in the context of time but this Tc is only used for diagram below)
Te: Token count of EBS, the instantaneous number of tokens left in the EBS bucket
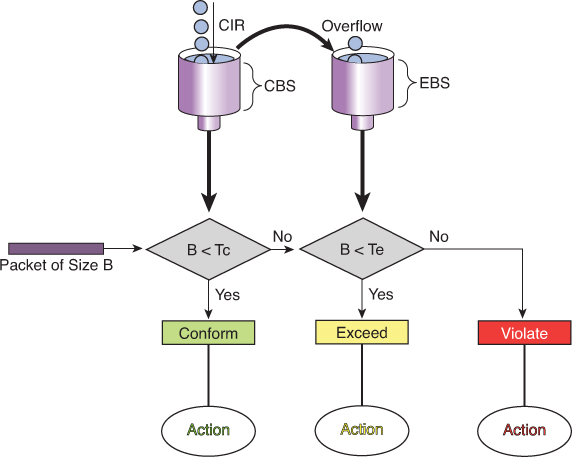
Single-rate three-color policer’s tolerance of temporary bursts results in fewer TCP retransmissions and is therefore more efficient for bandwidth utilization. It is a highly suitable tool for marking according to RFC 2597 AF classes, which have three “colors” (or drop preferences) defined per class (AFx1, AFx2, and AFx3). Using a three-color policer generally makes sense only if the actions taken for each color differ. If the actions for two or more colors are the same, a simpler policer (and therefore a simpler QoS policy) is more suitable to implement, making the network easier to maintain.
! -----------------------------
! Classify traffic (examples)
! -----------------------------
ip access-list extended AF1-TRAFFIC
remark <<< define your AF1 class traffic here >>>
permit ip 10.1.0.0 0.0.255.255 any
ip access-list extended AF2-TRAFFIC
remark <<< define your AF2 class traffic here >>>
permit ip 10.2.0.0 0.0.255.255 any
ip access-list extended AF3-TRAFFIC
remark <<< define your AF3 class traffic here >>>
permit ip 10.3.0.0 0.0.255.255 any
class-map match-any CLASS-AF1
match access-group name AF1-TRAFFIC
class-map match-any CLASS-AF2
match access-group name AF2-TRAFFIC
class-map match-any CLASS-AF3
match access-group name AF3-TRAFFIC
! ---------------------------------------------------------
! Single-rate three-color policer per AF class
! - Adjust CIR/Bc/Be to your needs (bps / bytes).
! - Typical starting point: Be ≈ 2*Bc
! ---------------------------------------------------------
policy-map POLICE-AF
class CLASS-AF1
! Example: 10 Mbps CIR, Bc/Be placeholders
police cir 10000000 bc 312500 be 625000 \
conform-action set-dscp-transmit af11 \
exceed-action set-dscp-transmit af12 \
violate-action drop
class CLASS-AF2
! Example: 5 Mbps CIR
police cir 5000000 bc 156250 be 312500 \
conform-action set-dscp-transmit af21 \
exceed-action set-dscp-transmit af22 \
violate-action drop
class CLASS-AF3
! Example: 2 Mbps CIR
police cir 2000000 bc 62500 be 125000 \
conform-action set-dscp-transmit af31 \
exceed-action set-dscp-transmit af32 \
violate-action drop
class class-default
set dscp default
! ---------------------------------------
! Apply the policy (ingress or egress)
! ---------------------------------------
interface GigabitEthernet0/0
description WAN-Uplink
service-policy output POLICE-AF
police cir 10000000 bc 312500 be 625000 -> in order to find its Tc
This Bc of 312500 is not optimal as it results in 250 ms

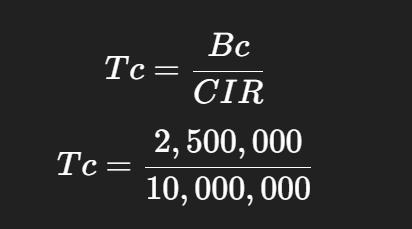

Bc = CIR * Tc
10000000 bits * 125 ms = 1250000000 / 1000 ms = 1250000 bits of Bc
for command line we will convert it to bytes 1250000 / 8 = 156,250 bytes
police cir 10000000 bc 156250 be 312500
Dual-Rate Three-Color Policers
The single-rate three-color marker/policer was a significant improvement for policers—it made allowance for temporary traffic bursts
the two-rate three-color marker/policer allows for a sustainable excess burst (negating the need to accumulate credits to accommodate temporary bursts) and allows for different actions for the traffic exceeding the different burst values.
This policer addresses the peak information rate (PIR), which is unpredictable in the RFC 2697 model two-rate three-color marker/policer. Furthermore, the two-rate three-color marker/policer allows for a sustainable excess burst (negating the need to accumulate credits to accommodate temporary bursts) and allows for different actions for the traffic exceeding the different burst values.
The dual-rate three-color marker/policer uses the following definitions parameters to meter the traffic stream:
PIR: Peak information rate, the maximum rate that traffic ever is allowed
PBS: Peak burst size, the maximum size of the first token bucket
CIR: Committed information rate, the policed rate
CBS: Committed burst size, the maximum size of the second token bucket
Tp: Token count of PBS, the instantaneous number of tokens left in the PBS bucket
Tc: Token count of CBS, the instantaneous number of tokens left in the CBS bucket
B: Byte size of offered packet
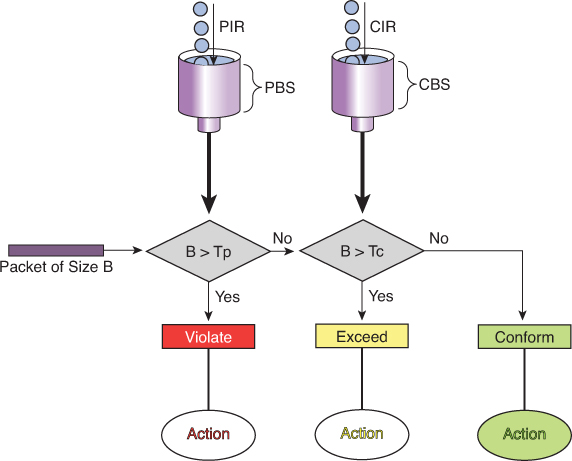
Policing Logic
- First check against PIR (Peak Bucket):
- If B > Tp (packet size larger than available tokens in PBS) → Violate (red).
- Packet is non-conformant and marked/dropped depending on policy.
- Otherwise, move to next step.
- If B > Tp (packet size larger than available tokens in PBS) → Violate (red).
- Then check against CIR (Committed Bucket):
- If B > Tc (packet size larger than tokens in CBS) → Exceed (yellow).
- Packet is considered “in excess traffic” but not outright violation.
- Otherwise → Conform (green).
- If B > Tc (packet size larger than tokens in CBS) → Exceed (yellow).
Actions
- Violate (Red): Drop or heavily penalize traffic.
- Exceed (Yellow): Forward, but mark as lower-priority (may be dropped if congestion occurs).
- Conform (Green): Forward as guaranteed/priority traffic.
! Class-map: match the traffic you want to police
class-map match-any APP-TRAFFIC
match access-group 101
! or DSCP/ACL/etc.
policy-map POLICE-TRTCM
class APP-TRAFFIC
police cir 1000000 bc 10000 pir 2000000 be 20000 \
conform-action transmit \
exceed-action set-dscp-transmit cs1 \
violate-action drop
!
! Apply inbound (or outbound if supported)
interface GigabitEthernet0/0/0
description Ingress toward core
service-policy input POLICE-TRTCMCoPP is a feature that allows the configuration of QoS policers to rate-limit the traffic destined to the main CPU of the switch/router. Such CoPP policers serve to protect the control plane of the switch/router from DoS attacks and reconnaissance activity in order to protect the CPU and control plane running as CPU processes
! Single-rate policer
policy-map POLICY1
class C1
police cir 1000000 conform-action transmit exceed-action drop
!
! Dual-rate policer
policy-map POLICY2
class C2
police cir 500000 bc 10000 pir 1000000 be 10000 conform-action
transmit exceed-action set-prec-transmit 2 violate-action drop
!
! Percentage-based policing
policy-map POLICY3
class C3
police cir percent 20 bc 300 ms be 400 ms pir percent 40
conform-action set-cos-inner-transmit 3Summary
Policing happens before packets enter the output queue.
A policer enforces a traffic contract (rate/committed burst).
Packets that exceed the configured rate are either dropped (default) or remarked (e.g. to a lower priority).
This happens regardless of whether there is congestion or not.
Congestion occurs after packets have entered the interface output queue.
Congestion management mechanisms (like Weighted Fair Queuing, Priority Queuing, CBWFQ, LLQ, etc.) decide which packets get queued and transmitted.
If a queue overflows (due to congestion), packets are dropped from that queue.
This can happen even for traffic that has already been policed — if the queue fills, traffic is dropped.
Hierarchical Policing
it might be desirable to limit all TCP traffic to 10 Mbps, while at the same time limiting FTP traffic (a subset of TCP traffic) to no more than 1.5 Mbps. To achieve this nested policing requirement, hierarchical policing can be used with up to three levels.
policy-map FTP-POLICER
class FTP
police cir 1500000
conform-action transmit
exceed-action drop
!
policy-map TCP-POLICER
class TCP
police cir 10000000
conform-action transmit
exceed-action drop
service-policy FTP-POLICER
!
interface ge 1/1
service-policy output TCP-POLICERPercentage-Based Policing
Most networks contain a wide array of interfaces with different bandwidths. If it is desirable to have an overall network policy in which, for example, FTP traffic is not to exceed 10 percent of the bandwidth on any interface, percentage-based policing can be used.
CIR and PIR values can be specified with percent, but not the burst sizes; the burst sizes are configured in units of milliseconds. If the CIR is configured in percent, the PIR also must be
When the service policy is attached to an interface, the CIR (and PIR, if configured) is determined as a percentage of the interface bandwidth. If the interface bandwidth is changed, the CIR and PIR values and burst sizes are automatically recalculated using the new interface bandwidth value
For subinterfaces, the bandwidth of the main interface is used for the calculation
If the percent feature is used in a second- or third-level policy, the bandwidth of the lower-level policy statement is determined by the configuration of the higher or parent level
LLQ is a policer and not bandwidth
LLQ mechanism “priority” contains an implicit policer and LLQ gives strict transmission priority to real-time traffic, and by doing so it introduces the possibility of starving lower-priority traffic. To prevent this situation, the LLQ mechanism polices traffic to the bandwidth specified in the priority statement by indiscriminately tail-dropping traffic exceeding the configured rate
priority statement can be specified with an absolute bandwidth or by using a percentage.
Control Plane Policing
CoPP allows the configuration of QoS policers to rate-limit the traffic handled by the main CPU of the switch. These policers serve to protect the control plane of the switch/router from DoS attacks and reconnaissance activity. With CoPP, QoS policies are configured to permit, block, or rate-limit packets destined to the main CPU. For example, if a large amount of multicast traffic is introduced into the network with a Time To Live (TTL) of 1, this traffic would force the switch to decrement the TTL, and thereby force the control plane to send an ICMP (Internet Control Message Protocol) error message. If enough of these events happened, the CPU would not be able to process them all, and the node would be effectively taken out of service
CoPP can protect a node against this type of attack
Shaper
Continue from file:///G:/My%20Drive/Learn%20Journey/2_QoS/Book%20HTMLs/End-to-End%20QoS%20Network%20Design%20Quality%20of%20Service%20for%20Rich-Media%20&%20Cloud%20Networks,%20Second%20Edition/online%20version/Chapter%204.%20Policing,%20Shaping,%20and%20Markdown%20Tools.html
“Traffic Shaping Tools”
! PRACTICE
! This class map relies on packets with marking already applied
class-map match-any REALTIME
match dscp ef ! Matches VoIP bearer traffic
match dscp cs5 ! Matches Broadcast Video traffic
match dscp cs4 ! Matches Realtime-Interactive traffic
!
class-map match-any CONTROL
match dscp cs6 ! Matches Network-Control traffic
match dscp cs3 ! Matches Voice/Video Signaling traffic
match dscp cs2 ! Matches Network Management traffic
!
class-map match-any CRITICAL-DATA
match dscp af41 af42 af43 ! Matches Multimedia Conf. on AF4
match dscp af31 af32 af33 ! Matches Multimedia Streaming on AF3
match dscp af21 af22 af23 ! Matches Transactional Data on AF2
match dscp af11 af12 af13 ! Matches Bulk Data on AF1
!
policy-map WAN-EDGE-4-CLASS
class REALTIME
priority percent 33 ! 33% LLQ for REALTIME class
class CONTROL
bandwidth percent 7 ! 7% CBWFQ for CONTROL class
class CRITICAL-DATA
bandwidth percent 35 ! 35% CBWFQ for CRITICAL-DATA class
fair-queue ! Fair-queuing on CRITICAL-DATA
random-detect dscp-based ! DSCP-based WRED on CRITICAL-DATA
class class-default
bandwidth percent 25 ! 25% CBWFQ for default class
fair-queue ! fair-queuing on default class
random-detect dscp-based ! DSCP-based WRED on default class
!
interface serial 1/0/0
service-policy output WAN-EDGE-4-CLASS
-----------------------------------------------------
class-map markings
match dscp af41 af42 af43
!
class-map mac-address
match destination-address mac 00:00:00:00:00:00
!
class-map ftp
match protocol ftp
-----------------------------------------------------
policy-map SET-DSCP
class DSCP-AF31
set dscp af31
-----------------------------------------------------
class-map match-any TRAFFICTYPE1
match <criteria1>
match <criteria2>
class-map match-all TRAFFICTYPE2
match <criteria3>
match <criteria4>
class-map TRAFFICTYPE3
match not <criteria5>
! reusing previously defined class
class-map DETAILS
match <criteria6>
class-map HIGHER-LEVEL
match class-map DETAILS
match <criteria7>
-----------------------------------------------------
! police set actions for remarking
Router(config)# policy-map CB-POLICING
Router(config-pmap)# class FOO
Router(config-pmap-c)# police 8000 conform-action ?
drop drop packet
exceed-action action when rate is within conform and
conform + exceed burst
set-clp-transmit set atm clp and send it
set-discard-class-transmit set discard-class and send it
set-dscp-transmit set dscp and send it
set-frde-transmit set FR DE and send it
set-mpls-exp-imposition-transmit set exp at tag imposition
and send it
set-mpls-exp-topmost-transmit set exp on topmost label
and send it
set-prec-transmit rewrite packet precedence
and send it
set-qos-transmit set qos-group and send it
transmit transmit packetWhen you configure multiple DSCP values on the same line, like this:
match dscp af41 af42 af43This is treated as a logical OR within that line.
match-any → logical OR
The packet only needs to match one of the listed conditions to be considered a match.
match-all → logical AND
The packet must satisfy all of the listed conditions at the same time to be considered a match.
The default logical operator (if unspecified) is match-all.
match not
will select inverse traffic
Note that class map and policy map names are case sensitive. Thus, class-map type1 is different from class-map Type1, which is different from class-map TYPE1. Class map names and cases must match exactly the class names specified in policy maps.
Unclassified traffic (traffic that does not meet the match criteria specified in the explicit traffic classes) is treated as belonging to the implicit default class.
specifying a policy map for “class-default” is optional, and if not specified, default class traffic has no QoS features assigned
default class traffic has no QoS features assigned, receives best-effort treatment, and can use all bandwidth not allotted or needed by the classes explicitly specified in the configuration – so if a lot of bandwidth is left on link then this class wins, if there is a less bandwidth left on the link then this class default traffic is looser
The default treatment for unclassified traffic with no QoS features enabled is a first-in, first-out (FIFO) queue with tail drop (which treats all traffic equally and simply drops packets when the output queue is full).
priority queuing, fair queuing are queueing treatments called priority queuing and fair queuing
priority command allocates bandwidth and also sets queuing treatment of priority as well, any traffic that has priority applied is sent out as soon as received, “skips to the front of the queue and scheduled first over anything else”
Queueing
Queueing types FIFO, CBWFQ and LLQ
Queue is a memory or buffer allocated on the interface and queue is always there on an interface, it only comes into play (holds packet to wait) when packets are coming into router faster than it can send them out or dispatch them out of egress interface
queue or buffer is a limited memory that can fill up and overflow and if we try to put a packet into this overflowing queue, packet will be dropped
A brilliant solution is to make sub queues or smaller queues carved out of that one big queue
so queue for best effort overflows it does not effect the voip traffic, only best effort packets will be denied or dropped while traffic for all other services keep working
Cisco recommends no more than 11 sub queues
If all traffic is dropped due to single queue for all services – TCP global Sync
TCP has sliding window, which means that TCP can gradually start skipping the acknowledgements as time passes and this window or set or number of segments start to increase till one ack is missed and TCP thinks that there is no accountability for what was sent and what was received (from remote end) so it shrinks that window down
random-detect
random-detect command enables Weighted Random Early Detection (WRED) on a queue.
It monitors the average queue depth.
If the queue starts filling:
Below the minimum threshold → no packets dropped.
Between min and max thresholds → packets are randomly dropped with increasing probability.
Above the maximum threshold → all packets are dropped (tail drop).
This prevents global synchronization of TCP flows and smooths congestion
See Section: Random Detect example with remark , mark down
for config example and explanation
fair-queue (queueing)
fair-queue command is one of the older queueing mechanisms in IOS, before CBWFQ and LLQ became standard
Fair Queueing (FQ) = A congestion management method that automatically creates separate queues per flow (based on source/destination IP and port), Used mainly on slow links (≤ 2 Mbps)
The router then services each queue in a round-robin fashion, so no single flow (e.g. a big FTP transfer) can dominate the link
Cisco recommends CBWFQ/LLQ instead of fair-queue on modern WANs
QoS commands
show qos interface show queueing interface show class-map show policy-map show policy-map interface show table-map C4500# show policy-map interface TenGigabitEthernet 1/1 TenGigabitEthernet1/1 Service-policy output: 1P7Q1T Class-map: PRIORITY-QUEUE (match-any) 102598 packets Match: dscp ef (46) 102598 packets Match: dscp cs5 (40) 0 packets Match: dscp cs4 (32) 0 packets priority queue: Transmit: 22782306 Bytes, Queue Full Drops: 0 Packets Class-map: CONTROL-MGMT-QUEUE (match-any) 24847 packets Match: dscp cs7 (56) 0 packets Match: dscp cs6 (48) 0 packets Match: dscp cs3 (24) 24847 packets Match: dscp cs2 (16) 0 packets bandwidth remaining 10 (%) Transmit: 24909844 Bytes, Queue Full Drops: 0 Packets Class-map: MULTIMEDIA-CONFERENCING-QUEUE (match-all) 22280511 packets Match: dscp af41 (34) af42 (36) af43 (38) bandwidth remaining 10 (%) Transmit: 4002626800 Bytes, Queue Full Drops: 0 Packets dbl Probabilistic Drops: 0 Packets Belligerent Flow Drops: 0 Packets Class-map: MULTIMEDIA-STREAMING-QUEUE (match-all) 0 packets Match: dscp af31 (26) af32 (28) af33 (30) bandwidth remaining 10 (%) Transmit: 0 Bytes, Queue Full Drops: 0 Packets dbl Probabilistic Drops: 0 Packets Belligerent Flow Drops: 0 Packets Class-map: TRANSACTIONAL-DATA-QUEUE (match-all) 235852 packets Match: dscp af21 (18) af22 (20) af23 (22) bandwidth remaining 10 (%) Transmit: 247591260 Bytes, Queue Full Drops: 0 Packets dbl Probabilistic Drops: 0 Packets Belligerent Flow Drops: 0 Packets Class-map: BULK-DATA-QUEUE (match-all) 2359020 packets Match: dscp af11 (10) af12 (12) af13 (14) bandwidth remaining 4 (%) Transmit: 2476460700 Bytes, Queue Full Drops: 0 Packets dbl Probabilistic Drops: 0 Packets Belligerent Flow Drops: 0 Packets Class-map: SCAVENGER-QUEUE (match-all) 78607323 packets Match: dscp cs1 (8) bandwidth remaining 1 (%) Transmit: 98144078642 Bytes, Queue Full Drops: 26268 Packets Class-map: class-default (match-any) 12388183 packets Match: any 12388183 packets bandwidth remaining 25 (%) Transmit: 13001465825 Bytes, Queue Full Drops: 0 Packets dbl Probabilistic Drops: 0 Packets Belligerent Flow Drops: 0 Packets C4500#
next post
Kill Running Task on vManage
Kill Running Task on vManage
https://1.1.0.11:8443/dataservice/device/action/status/tasks
{"runningTasks":[{"detailsURL":"/dataservice/device/action/status","userSessionUserName":"admin","@rid":327,"tenantName":"DefaultTenant","processId":"push_feature_template_configuration-a25f3f2f-32a3-47f7-8022-ee86554f7062","userSessionIP":"172.16.32.11","name":"Push Feature Template Configuration","tenantId":"default","action":"push_feature_template_configuration","startTime":1756007925476,"endTime":0,"status":"in_progress"}]}to kill this task we need to run below with processid from above
https://1.1.0.11:8443/dataservice/device/action/status/tasks/clean?processid=push_feature_template_configuration-a25f3f2f-32a3-47f7-8022-ee86554f7062next post
SDA Operations / tshoot
SDA Operations / tshoot
LISP vs BGP in Cisco SDA
In Software-Defined Access:
LISP = fabric internal control plane 🧠
(endpoint location + VXLAN tunnel resolution)
BGP = external route exchange 🌍
(connect fabric to outside networks)
They operate in different routing domains but meet at the border node.
BGP runs only at the border node.
Purpose:
- learn external prefixes from fusion routers / upstream
- advertise fabric prefixes outward
- exchange routes between border nodes (iBGP)
Then how is LISP pub sub deployment in SDA different?
Cisco SDA uses a modified LISP publish–subscribe (pub-sub) model, which changes how mappings are distributed, not what LISP does.
Traditional LISP:
Edge nodes ask the control plane for mappings when needed (Map-Request).
SDA LISP pub-sub:
Edge nodes subscribe to mappings, and the control plane pushes updates automatically.
So SDA reduces lookup latency and improves scale ⚡
Classical LISP control-plane behaviour (pull model)
Host A → Host B
Edge node doesn't know B
→ sends Map-Request to control plane
→ receives Map-Reply
→ builds VXLAN tunnel
→ forwards trafficSDA LISP publish–subscribe model
Edge node registers endpoints
↓
Control plane stores mappings
↓
Other edge nodes subscribe to updates
↓
Mappings pushed proactivelySo instead of:
request → reply
you get:
subscribe → push updates automatically
Much faster convergence and fewer queries.
What exactly gets published?
When an endpoint appears:
Host joins fabric
↓
Edge node registers endpoint to Control Plane Node
↓
Control Plane Node distributes mapping to subscribers
Endpoint mappings in its VN (primary subscription)
Example:
If Edge-1 participates in:
VN = Corp
it subscribes to:
All Corp endpoint location updates
So when a device appears anywhere in the Corp VN:
10.10.20.5 → Edge-3 loopback
the Control Plane Node pushes that mapping to Edge-1.
Edge-1 now already knows where that endpoint lives.
No lookup required later.
What triggers subscription updates
Control Plane Node pushes updates when:
New endpoint appears
Host joins fabric
Endpoint roams
Edge changes
Endpoint disappears
Host disconnects
External prefix changes
New route learned via border node
Border nodes also subscribe
Border nodes subscribe too.
They receive:
Internal endpoint mappings
so they know how to forward inbound traffic from:
Fusion router → fabric endpoint
without querying first.
But does it not cause scalability issues and that is why map-request and map-reply model were used if you are learning / pulling all hosts in a VN?
At first glance, pushing all endpoint mappings to all edge nodes in a VN sounds like it would break scalability. That’s exactly why classical LISP used Map-Request / Map-Reply (pull) instead of flooding mappings everywhere.
But Cisco SDA does NOT push all mappings to all edges. It uses a selective pub-sub model, not a full broadcast subscription model.
Here’s how scalability is preserved.
The key clarification
SDA does not mean:
Every edge node learns every endpoint in the VN
Instead it means:
Edge nodes subscribe only to mappings they are likely to need
The control plane node performs selective distribution.
Edges subscribe to:
Local VN mappings (selectively)
Not the entire VN database.
Instead:
- active mappings
- relevant mappings
- recently used mappings
- mobility-related mappings
The control plane node tracks interest dynamically.
Example with numbers (realistic campus)
Suppose:
Fabric size = 10,000 endpoints
Edges = 40
Endpoints per edge ≈ 250
Each edge typically knows:
its own endpoints
+
active remote peers
+
border mappings
NOT:
all 10,000 endpoints
Another hidden scaling mechanism: map-cache still exists
Even in SDA pub-sub mode:
Edge nodes still maintain a map-cache.
So behaviour is actually hybrid:
Push updates when relevant
Pull mappings when unknown
Cache results locally
This keeps control-plane chatter low.
Host-A talked to Edge-1 and Edge-2
Host-A disconnected
→ notify Edge-1 and notify Edge-2
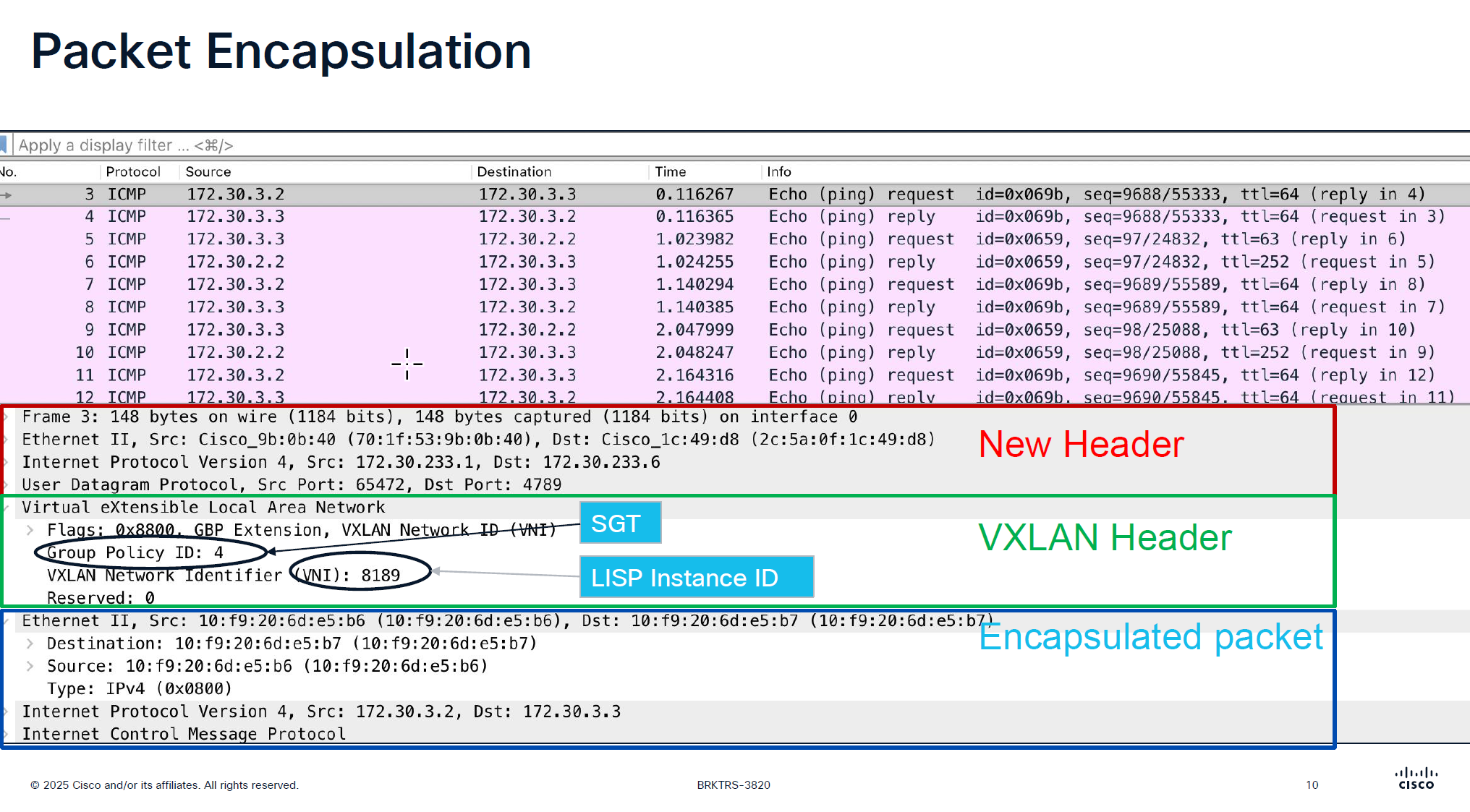
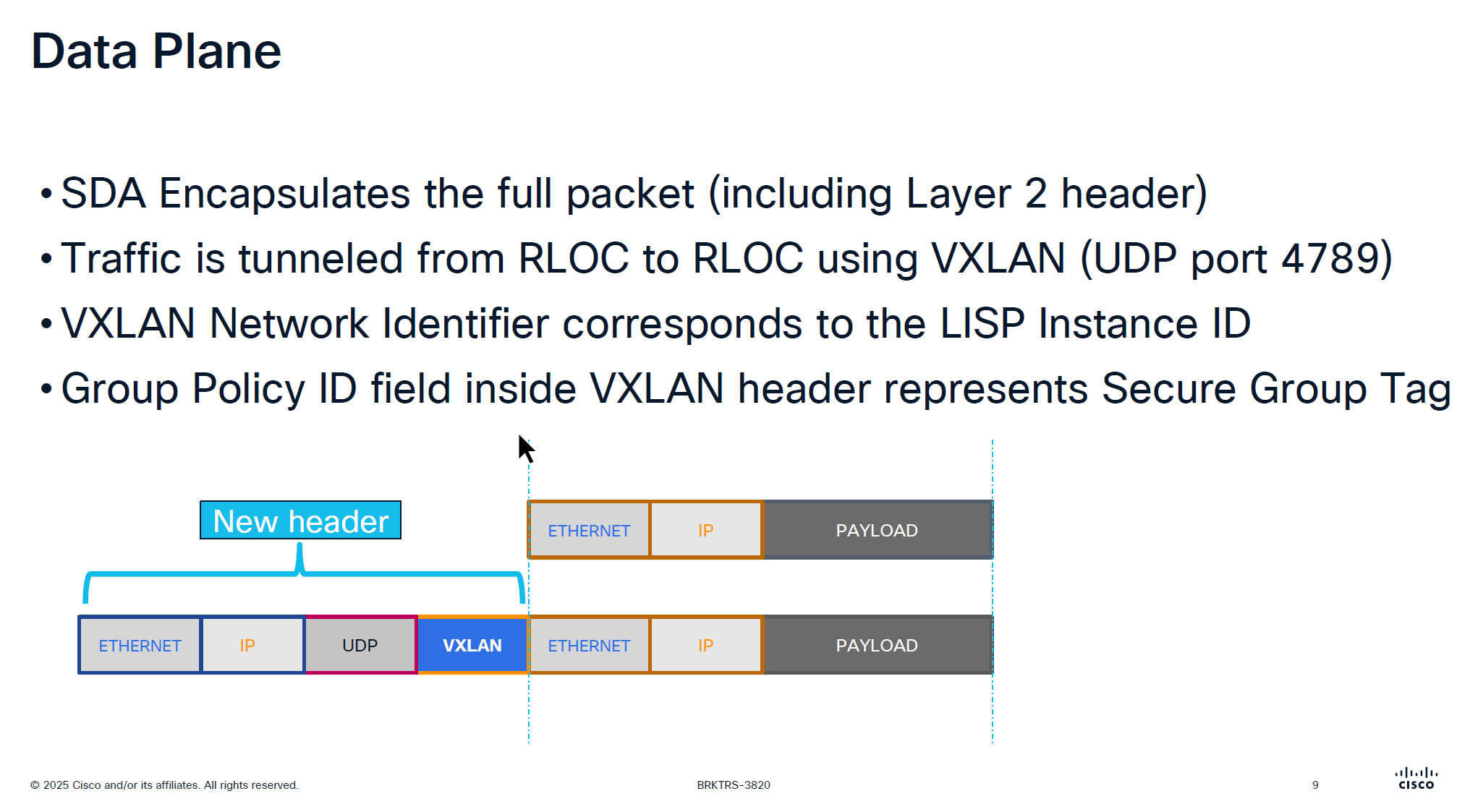
VXLAN looks like an “application” in above picture
Destination Port used by VXLAN is UDP 4’789
Cisco could have used source UDP 4789 to destination UDP 4789 but they wanted the possibility of load balancing through the underlay network that is why Cisco uses random source port because if everything is using same path then we are wasting bandwidth in thet network

Any endpoint that is connected and is picked up by device tracking and it is in this subnet then it is registered in LISP
but anything outside of this range will still be learned in device tracking but not learned in LISP and will not be advertised out by FBS because security wise anything could connect and get advertised out of the fabric, these endpoints will still be able to speak to devices connected on same switch, but not through fabric
In every VRF a loopback is created dynamically and that loopback is not in underlay but on the overlay, and is used for multicasting and it is shown in above screenshot as “Loopback for Multicasting”

Because we have same Anycast IP and same mac address on all edge devices and because of that we should never connect 2 edges together via a layer 2 trunk, if we do then we will see all sorts of instabilities
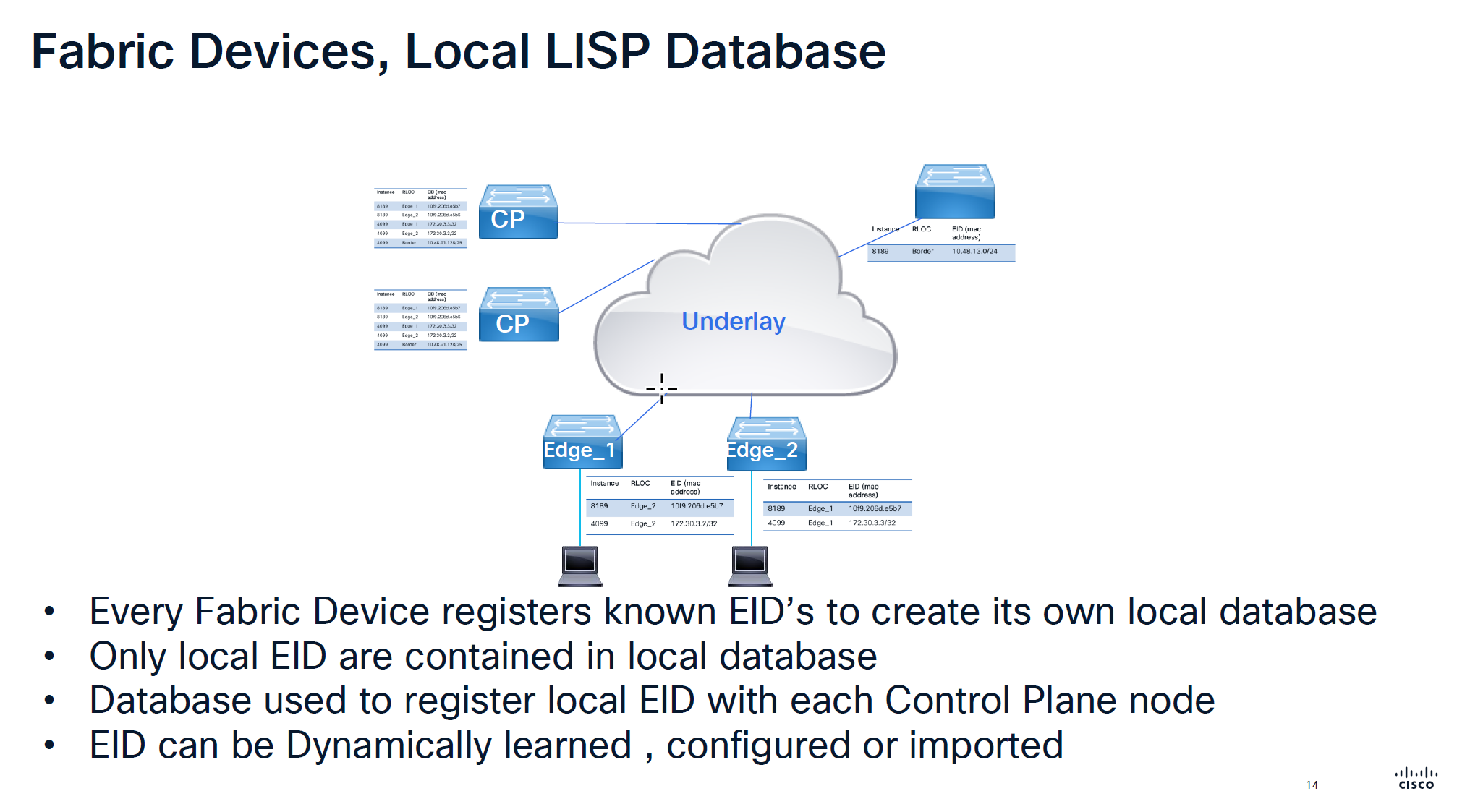
Local Database is built on the edge switch for both IPv4 instance and ethernet instance and the eid learned from local database are registered to the control plane
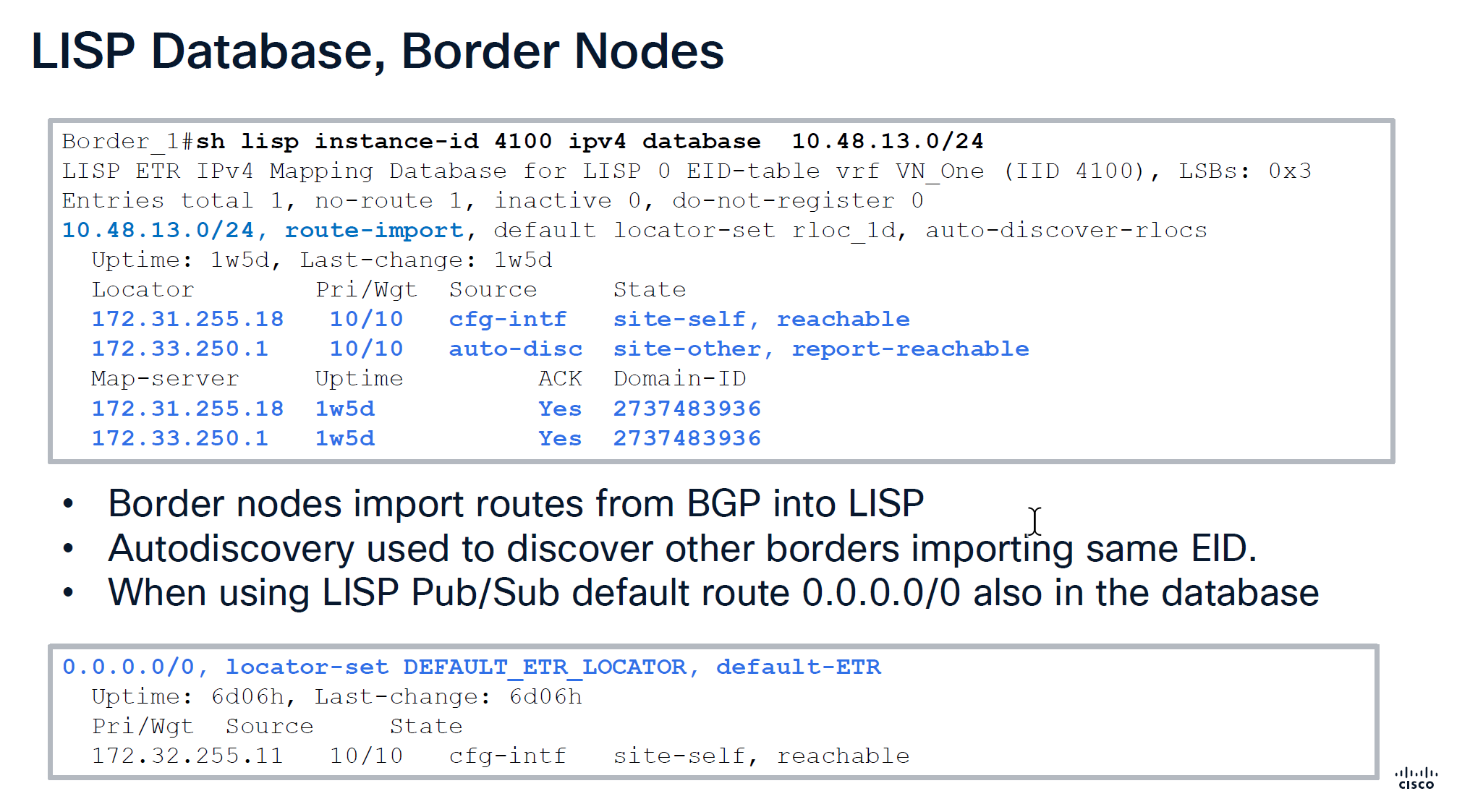
Route import tells us how it came into border node,
It then tells us about the locators it knows about
172.31.255.18 is itself marked as “cfg-intf”
and 172.33.250.1 is other border node known through “auto-disc”
Make sure that control plane has actually acknowledged
With LISP Pub/Sub comes with a ‘dynamic default border’ feature that works if we have advertisesed 0.0.0.0/0 into border per VN > then it is put into LISP database and that is how it becomes default ETR for all of the fabric
With LISP BGP we select the nodes as ‘default border’ but because there is no default route tracking or no default route, in case border node looses routes to uplink, traffic gets blackholed
With ‘dynamic default border’ if default route is not present then it will not be put into LISP and if it is not in the LISP then that device will not be used as default border
During troubleshooting with LISP pub sub, if you see fabric cannot get out and if default route is not present in LISP then that is the issue, in that case check if 0.0.0.0 is on the border node
Below we can see Map-server column having same address as border which means control and border are colocated on same node and it also shows ACK, telling us that it has registered these prefixes and sent ACK back to border saying that it has registered this prefix, if we dont see ACK then it means that there is some issue in border and control communication, either key mismatch and packets were sent to control but it was not accepted

This is edge node that is saying that this endpoint EID has matched this dyanmic EID range and state is ‘site-self’ which means I regsitered it and also tells which map servers or control plane nodes it has been registered and ACK was received for the registeration
This do not register is set for SVI IP because it is anycast IP that is available on all edge nodes
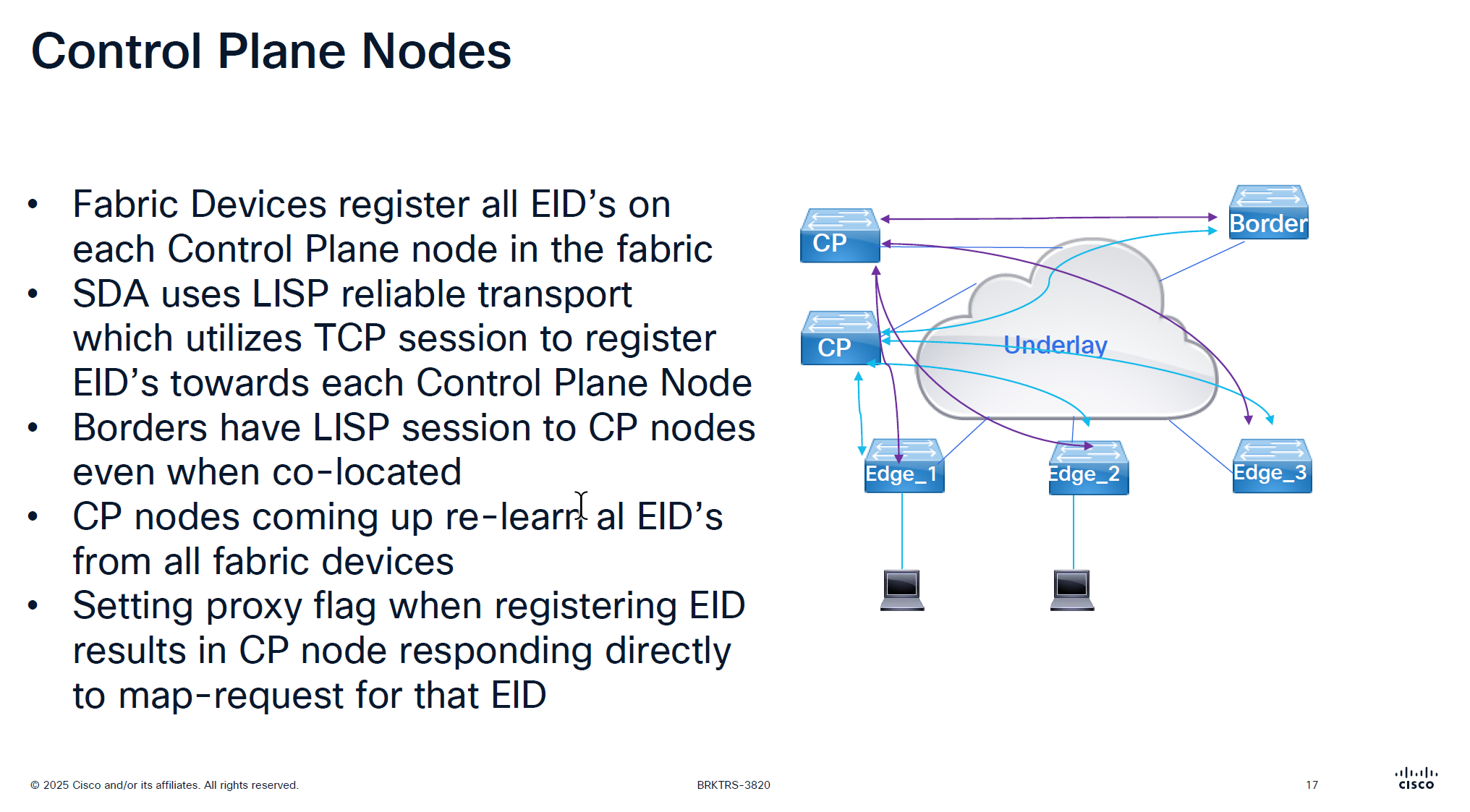
There is no communication between the control plane node, if a control plane node goes down and then comes backup then it has to relearn all the EID from all the edge nodes, CP nodes do not sync with one another , so typically when network is stable it can give the illusion that they are synced due to equal number of EID on both but CP nodes do not talk to one another
map request and map reply
map request is not a request to map an entry or register but it is a query to get a reply from control plane node
Last point is saying that in traditional LISP, Map server only responds to the edge that registered the endpoint, but in SDA version of LISP, map server responds to query from anyone by setting the proxy flag on registration time

CP and border still make connections to one another if they are colocated on same box
So in LISP sessions you will see it establishing LISP sessions from itself to itself
On the edge node you will see LISP sessions based on number of control plane nodes you have
Users column is not actual user but how many instance IDs are using it
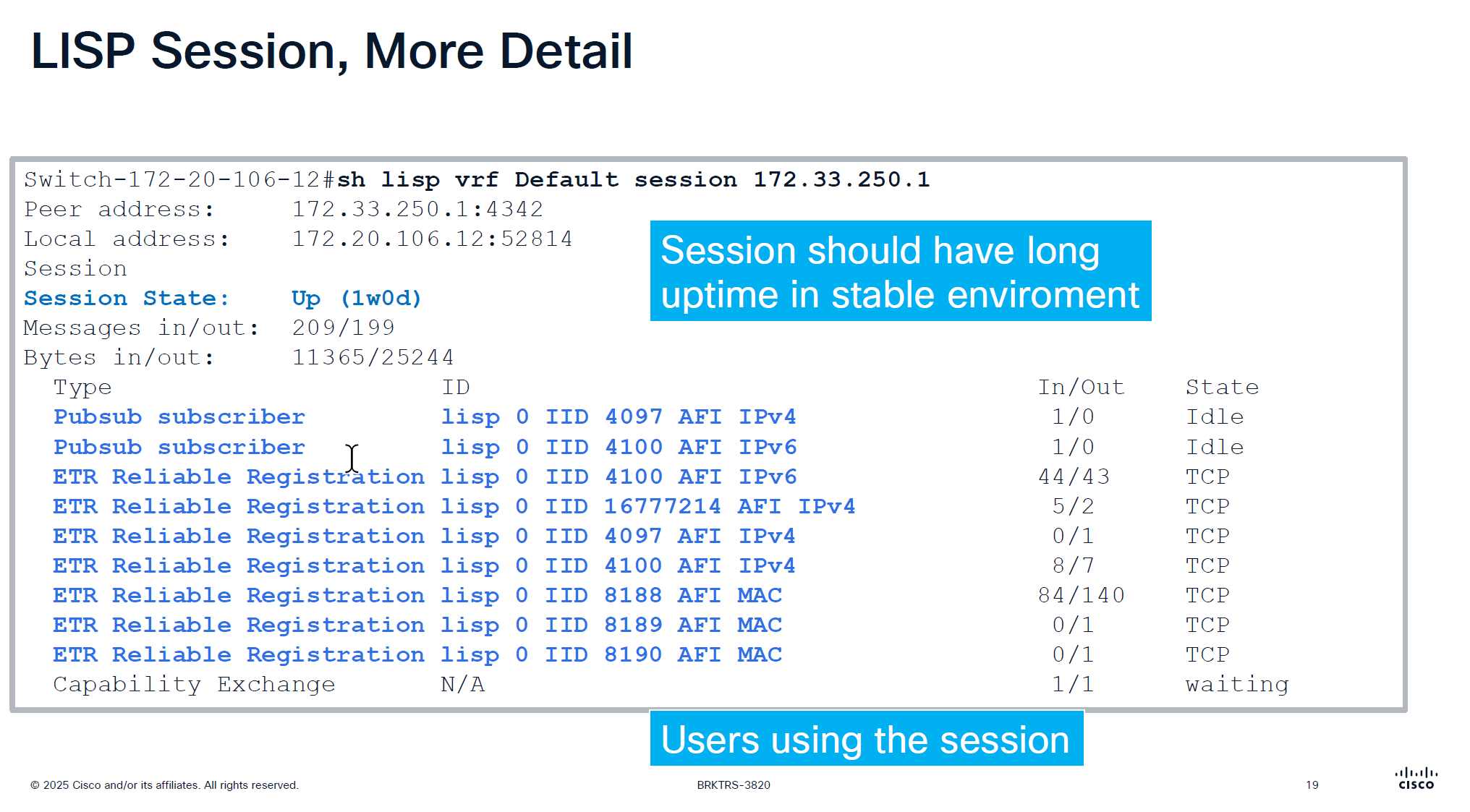
Checking detailed command shows us the LISP instances using the LISP session
make sure that your session up time is big and if it is small then it indicates some sort of network instability and network issues
This command actually shows us that there are LISP instances exchanging information with Control plane node and not just TCP session on port 4342 that is up
That message at the bottom that is “Capability Echange” means that there is a session trying to establish but there is something wrong like key exchange and state is also in “waiting”
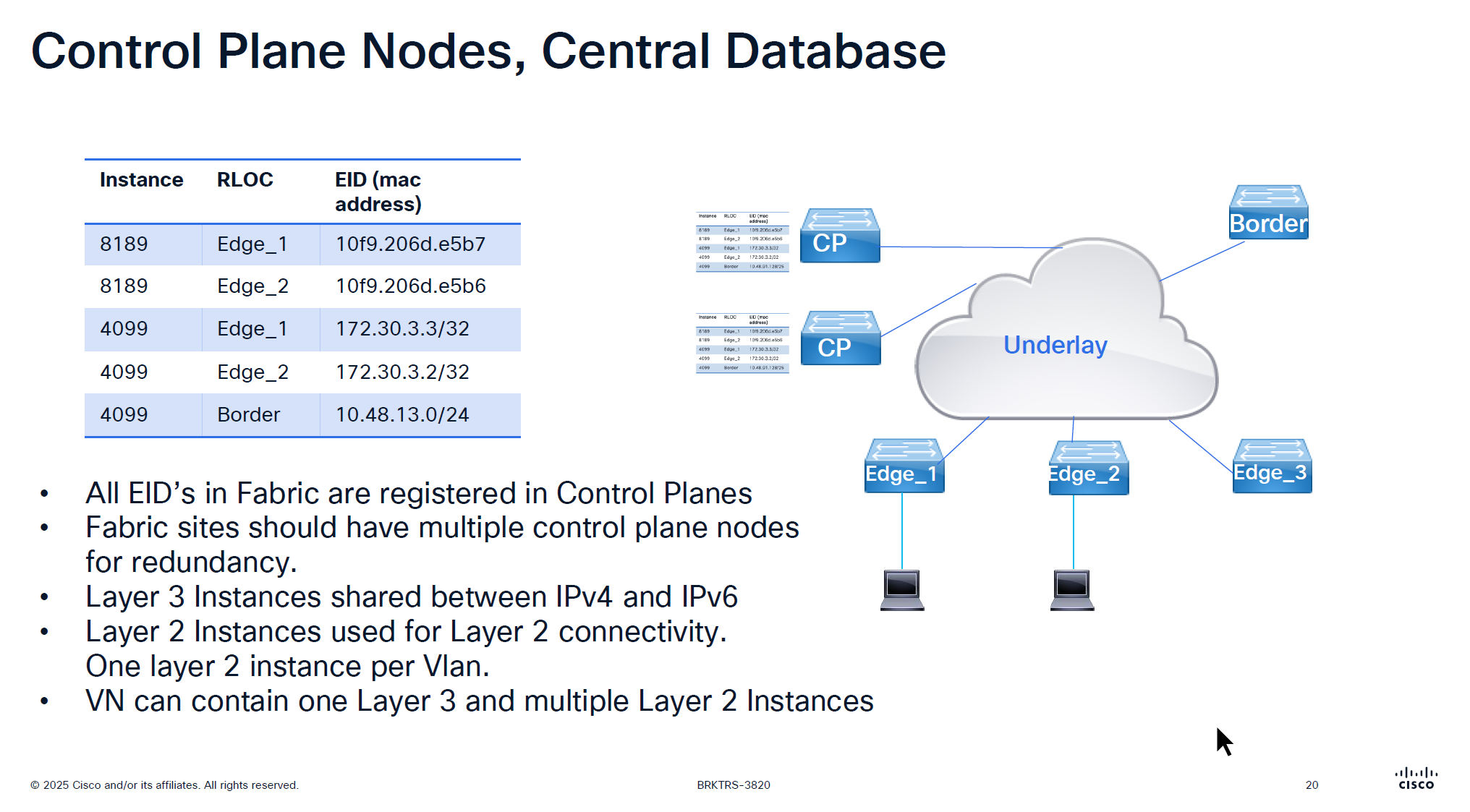
For IPv4 the instance ID start from 4097 and up
for Ethernet instance ID it starts from 8189 and layer 2 instances are used for Layer 2 connectivity and it creates one layer 2 instances per vlan
One VN is one Layer 3 instance and multiple Layer 2 instances
If there are 2 devices in one IP pool across different edges then they will use Layer 2 instance
if 2 devices are on different IP pool or 2 different subnets then they will speak using Layer 3 instance

When you see “server” keyword that means we are asking control plane node
This is imporant command to troubleshoot endpoint and LISP registration, it shows when it first registered and when it last regsitered
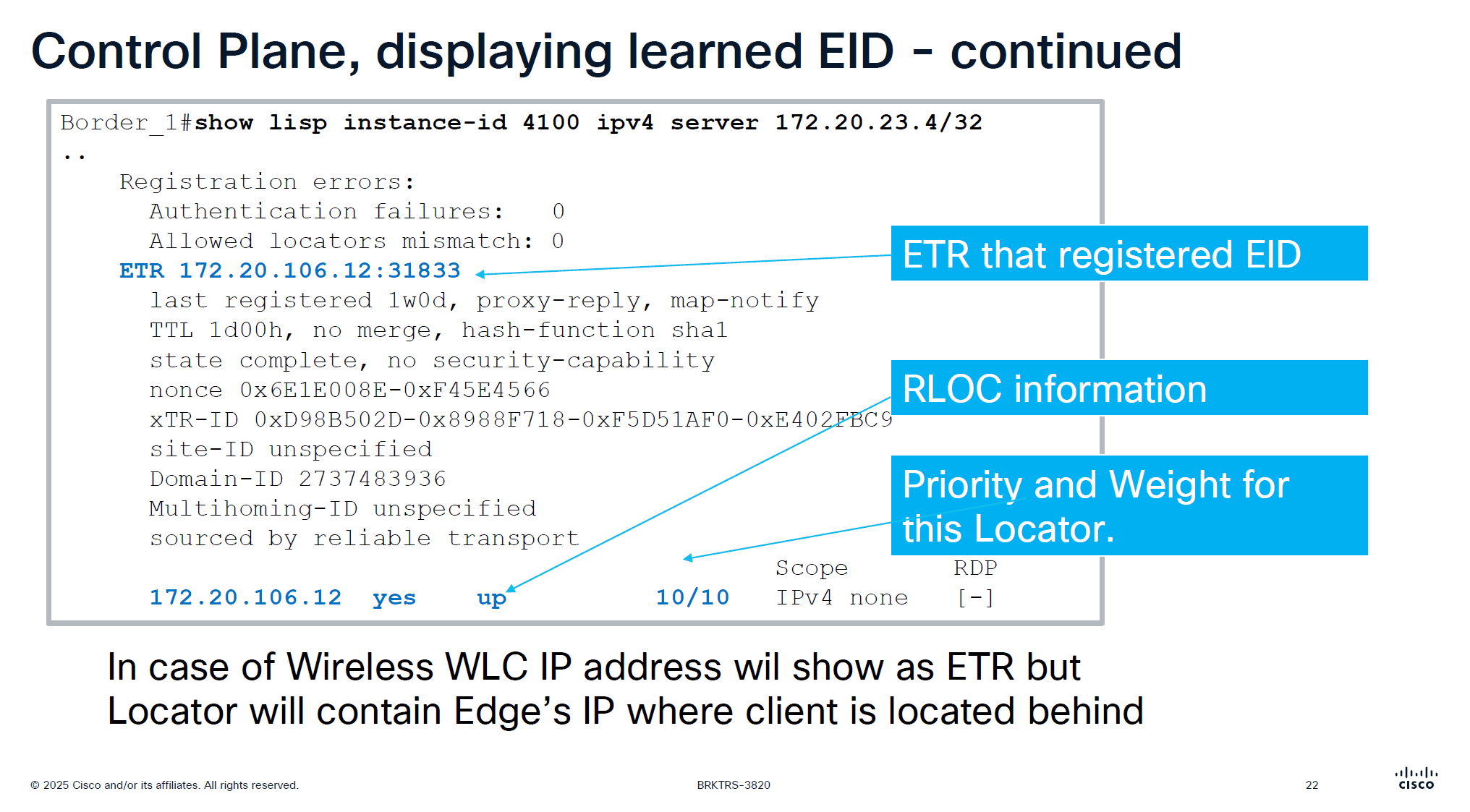
This is output from border node and it is showing ETR as edge node behind which this endpoint lives

only server command will show us last registering ETR
server command with prefix will show us the ETRs (borders) that are registering that prefix and notice that because of priority/weight of 10/10
LISP priority uses lowest priority number as preferred
If RLOC1 has Priority 1 and RLOC2 has Priority 10, all traffic goes to RLOC1 (Active/Standby)
if both RLOC have priority of 10, then it means both routes will be used in loadbalancing fashion then weights are considered, how much traffic will be sent if priorities are same
If both RLOCs have the same priority (e.g., 10), they are considered equal, and traffic is distributed based on weight.
Weight is used for traffic engineering when multiple paths have the same priority.
It specifies the percentage of traffic a particular RLOC should receive relative to other RLOCs in the same priority group.
If weight is set to 0 on an RLOC then no traffic is load balanced to it, unless it is the last one left

Very important command for troubleshooting for a client, may be it got disconnected or roamed or what not
Notice that first entry that is L3 /32 address being registered inside Layer 2 instance that is ARP regsitration and not the real registration that is also regsitered inside Layer 2 instances

Above command is “server address-resolution” on “Layer 2 instance” on “control node”
Due to VXLAN we can only unicast the packets and broadcasting is not supported unless flooding is enabled on the VLAN but for ARP to specifically work there is a special support in order to get the ARP working, switches snoop the ARP packets for destination inside the ARP message but dont actually flood them yet
LISP then asks for control pane for that destination IP from ARP and control responds with layer 2 mac address corresponding to that L3 address (from device tracking)
then LISP simply rewrites or replaces the broadcast address with the MAC address it received from control plane
this ARP packet is now able to be sent over the unicast over the VXLAN tunnel using Layer 2 instance
This is why silent devices are hard to troubleshoot and do not work over the fabric, this is because they do not produce any traffic and simply want to receive traffic, this makes it hard for device tracking and in turn fabric to not work for those devices
edges nodes have multiple probes going on to speak to those silent devices but there are some devices which are ultra silent and dont even respond to those probes
This command helps in troubleshooting those scenarios because if ARP is not working over fabric then communication will not work

This someone pinging 172.20.23.100 and it arrived on Gi1/0/15
If you see entry for API with mac 0000.0000.00fd in command “show device-tracking database” then it means that ARP packet arrived on the edge node but did not have response from Control node over LISP yet and waiting to be resolved to convert ARP broadcast into unicast
After this resolution completes entry becomes “RMT” (which I guess means remote) with L2LI0 as interface
Because device tracking timers age quickly, this process of ARP resolution might be happening again
Important to note that unicast ARP is received on the remote device and sometimes some IoT devices in testing showed that does not like unicast ARP and only respond to broadcast ARP so in that case we will have to enable the Flooding over the VLAN


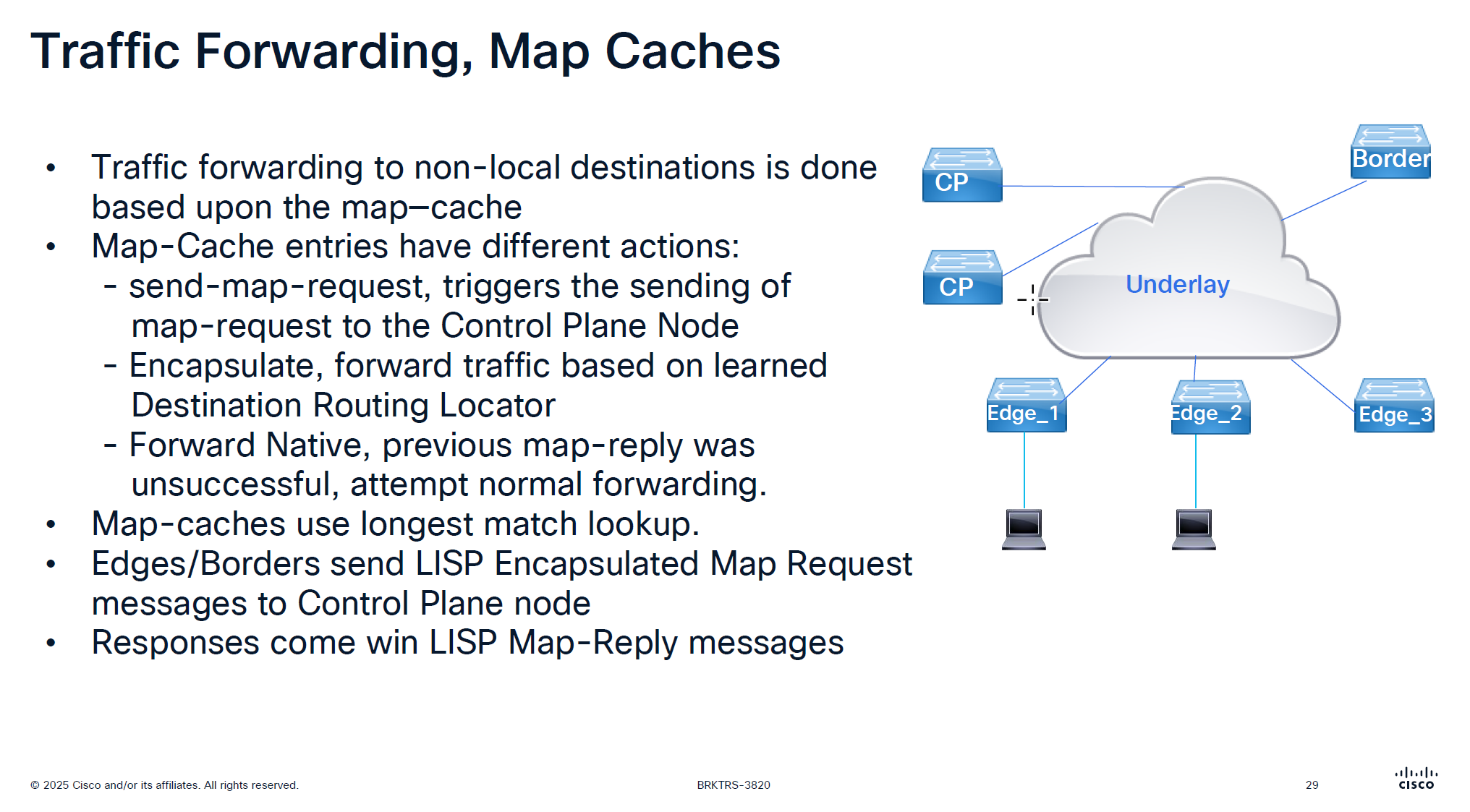
It is no good to speak to control plane about every packet we get
That is why edge node has map-cache to cache the RLOC received for an endpoint for 24 hours

See action
The reason it is 0.0.0.0/0 has action send-map-request because even if we have default border or even dynamic default border we need to still ask control plane node as there might be a better path for destination
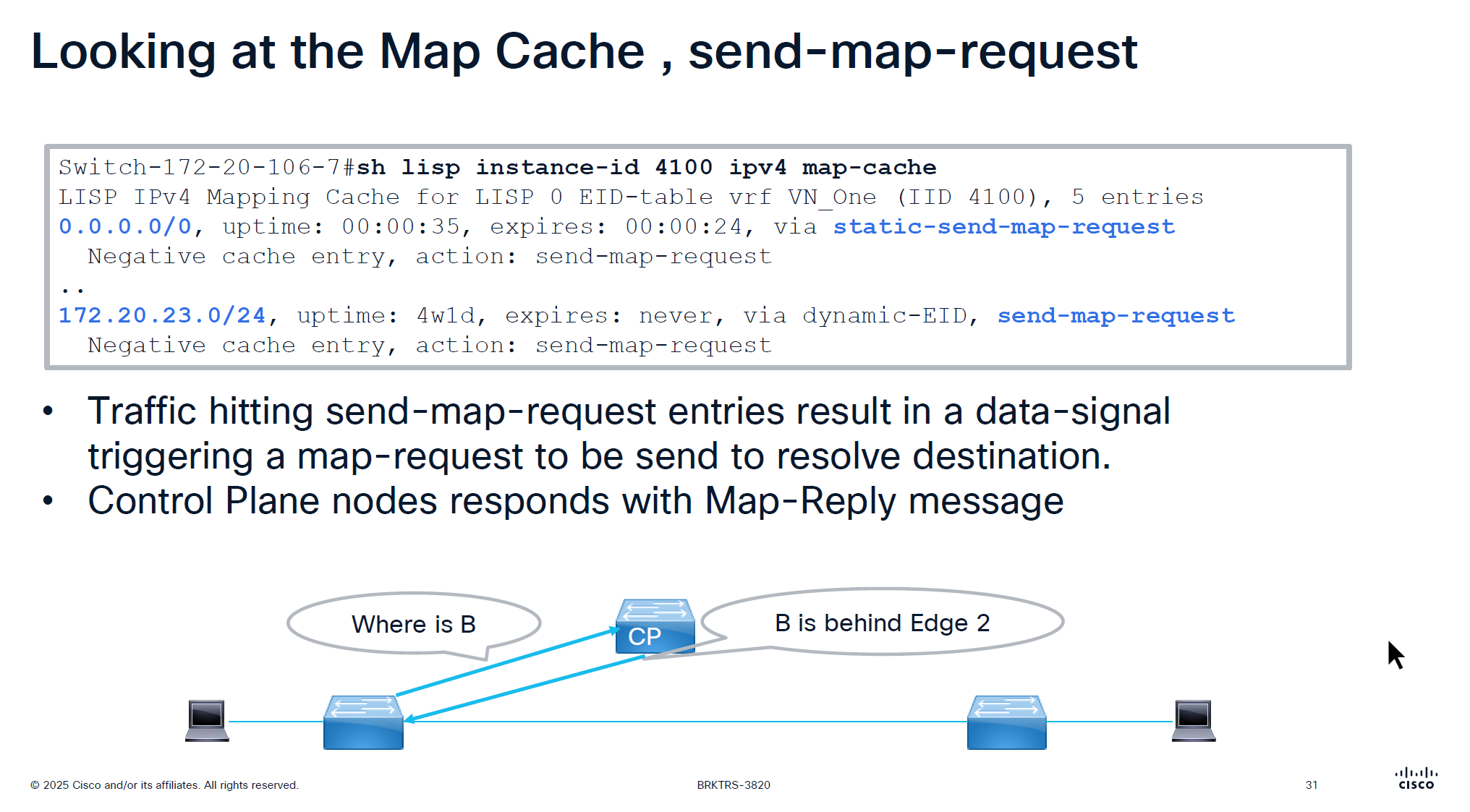

On each edge node in order to reduce queries to control plane node a few “negative” map-cache entries are added in advance with forward native action, forward native on border means to use routing table and not LISP which can have ISIS , OSPF , BGP or static entry for any routes falling under this range but for edge nodes forward-native means connection will be dropped as there is no other means other than LISP
This is done in weird blocks of 0.0.0.0/5 and 8.0.0.0/7 to tell that I dont have routes for those but I have default route 0.0.0.0 and other prefixes we learned from outside fusion world
This is only there for “expires” time which is 15 minutes, the whole function of map-cache is to not consult control node, so this entry means that for those unknonwn destinations do not ask or reach control plane but as this entry expires, edge can reach out to the control plane node instead try to use the routing table (action: forward-native)
0.0.0.0/0, uptime: 1y29w, expires: never, via static-send-map-request
Encapsulating to proxy ETR
0.0.0.0/5, uptime: 00:00:34, expires: 00:14:25, via map-reply, forward-native
Encapsulating to proxy ETR
! 0.0.0.1 - 7.255.255.255
8.0.0.0/7, uptime: 38w5d, expires: 00:04:38, via map-reply, forward-native
Encapsulating to proxy ETR
! 8.0.0.1 - 9.255.255.254
10.16.101.0/24, uptime: 1y29w, expires: never, via dynamic-EID, send-map-request
Encapsulating to proxy ETR
10.64.0.0/11, uptime: 38w5d, expires: 00:05:08, via map-reply, forward-native
Encapsulating to proxy ETR
10.116.2.0/24, uptime: 1y29w, expires: never, via dynamic-EID, send-map-request
Encapsulating to proxy ETR
10.116.3.0/24, uptime: 1y29w, expires: never, via dynamic-EID, send-map-request
Encapsulating to proxy ETR
10.116.4.0/24, uptime: 1y29w, expires: never, via dynamic-EID, send-map-request
Encapsulating to proxy ETRAbove slide is little bit wrong
For LISP Pub Sub deployment we see “Negative cache entry, action: forward-native” but for LISP BGP deloyment we see “Encapsulating to proxy ETR” but see below
8.0.0.0/7, uptime: 38w5d, expires: 00:13:47, via map-reply, forward-native
Sources: map-reply
State: forward-native, last modified: 38w5d, map-source: 172.20.239.124
Active, Packets out: 1535384(884381184 bytes), counters are not accurate (~ 00:00:35 ago)
Encapsulating to proxy ETRit will use the normal routing table (no VXLAN/LISP encapsulation) because the entry is forward-native, even though a proxy ETR (172.20.239.124) is listed
This line can appear in map-cache entries when:
- the prefix is learned via map-reply
- a proxy ETR exists – A Proxy ETR (PETR) in Cisco LISP / SD-Access is typically the Default Border Node, not the Internal Border Node
A Proxy ETR is used when a fabric device needs to send traffic to destinations outside the LISP mapping system (for example: internet prefixes like 8.0.0.0/7).
Instead of dropping the packet (because no mapping exists), the fabric edge or border node:
➡ encapsulates the packet
➡ sends it to the PETR
➡ PETR forwards it toward external networks using normal routing
So PETR acts like an exit gateway for unknown/non-fabric destinations.
the state field of forward-native overrides it and tells to use RIB/FB
Cisco explains proxy-ETR usage like this:
When a destination EID is not reachable via the mapping system, a proxy ETR can be used for encapsulation, But only when the map-cache entry is in encapsulating state.
State Meaning forward-native use RIB/FIB encapsulating or complete send to ETR negative drop incomplete awaiting mapping

Because this is a subnet 10.48.13.0/24 behind a border, we see 2 borders
Whenever we see Pri/Wgt of 10 and 10 on both borders then it means we are load balancing at VXLAN level, like half flows are sent to one border and half flows are sent to another border and it is not gauranteed that VXLAN UDP packets to 172.31.255.18 are taking a single path through network always and not getting load balanced, even these VXLAN tunnel packets are also load balanced

showing ip route in vrf will not show much except on border nodes but on the edge device there is no default route and no other routing present other than LISP VXLAN and fabric stuff
But if we check CEF there is more info because LISP -> CEF directly talks to CEF

Layer 2 forwarding ia s bit different in fabric
Entry for dynamic MAC learning on edge shows CP_LEARN via L2LI0 tells that this MAC belongs to this vlan on a different edge node


For layer 2 flooding to work on a vlan, the underlay multcasting needs to work
If LAN automation is used, it sets up the underlay multicast
Every edge device shows up as source for a multicast group
We can see the 2 instances that are receiving the multicast traffic (flooded traffic)

This is to verify if LISP is programming stuff correctly in hardware and this is where MATM comes in
MATM is CEF equivalent in layer 2


traditionally we could debug dot1x, debug authentication and debug radius etc but now we cannot do that, SMD sits as a seperate process outside of the iosd so we need to follow show logging <process> <name> format
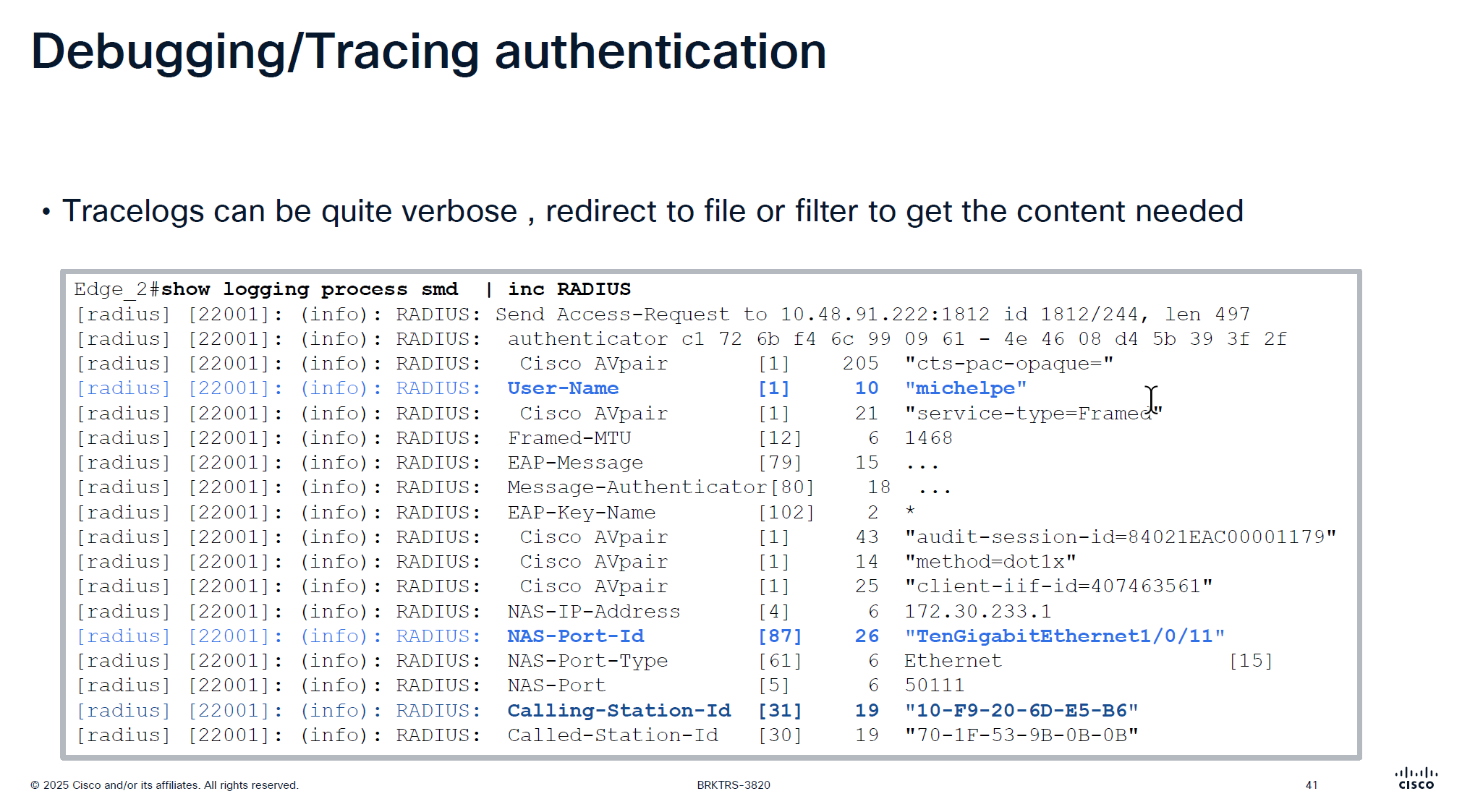

It is very important that RADIUS is up from SMD state as well
in some cases IOS thinks RADIUS server is up, but if it is down for SMD then it will not communicate with RADIUS server and it is waiting on keepalive timer to try again


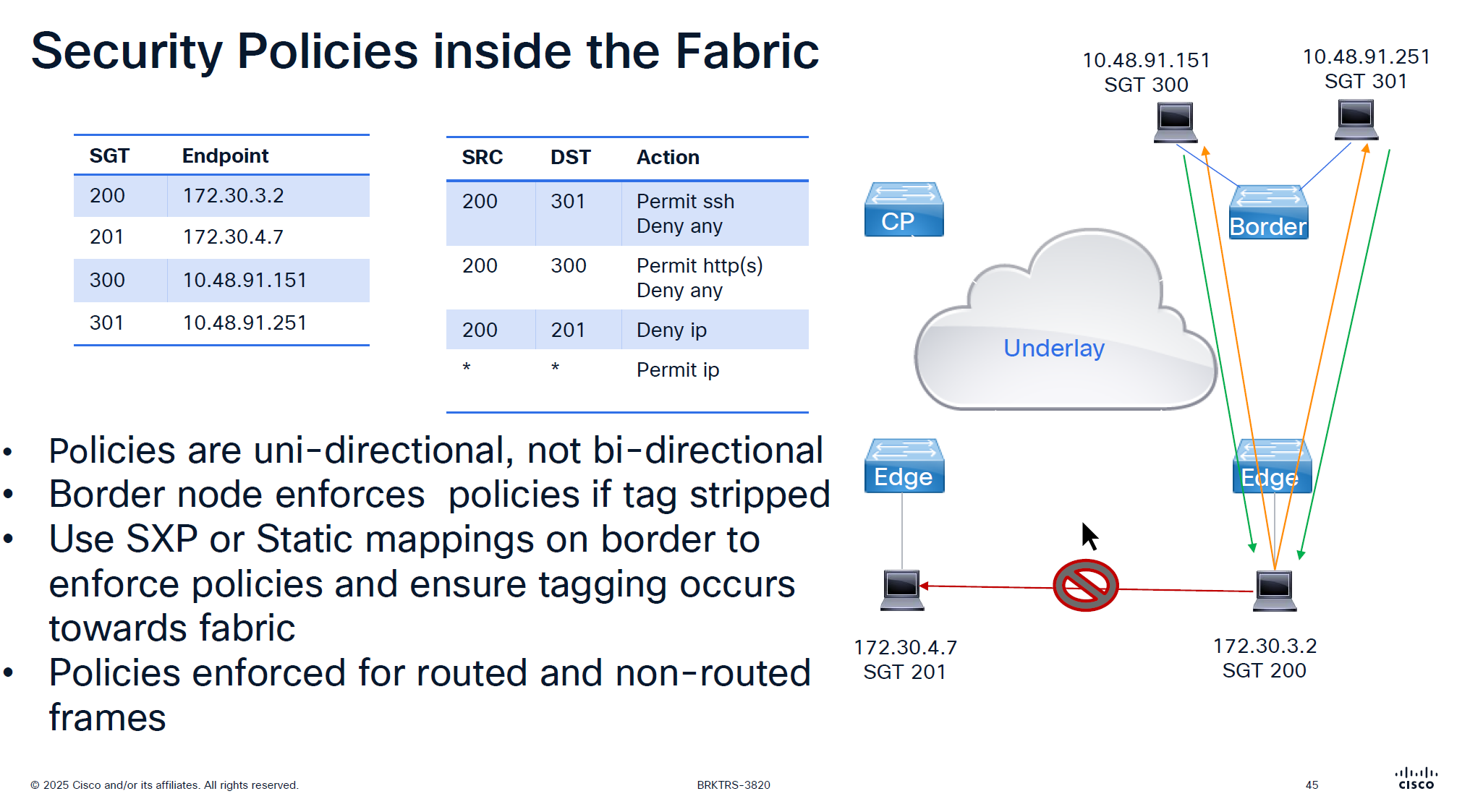
more…
coming soon
next post
SDA SGT
SGT BRKSEC-3690 – PDF
SGT BRKSEC-3690 – Notes
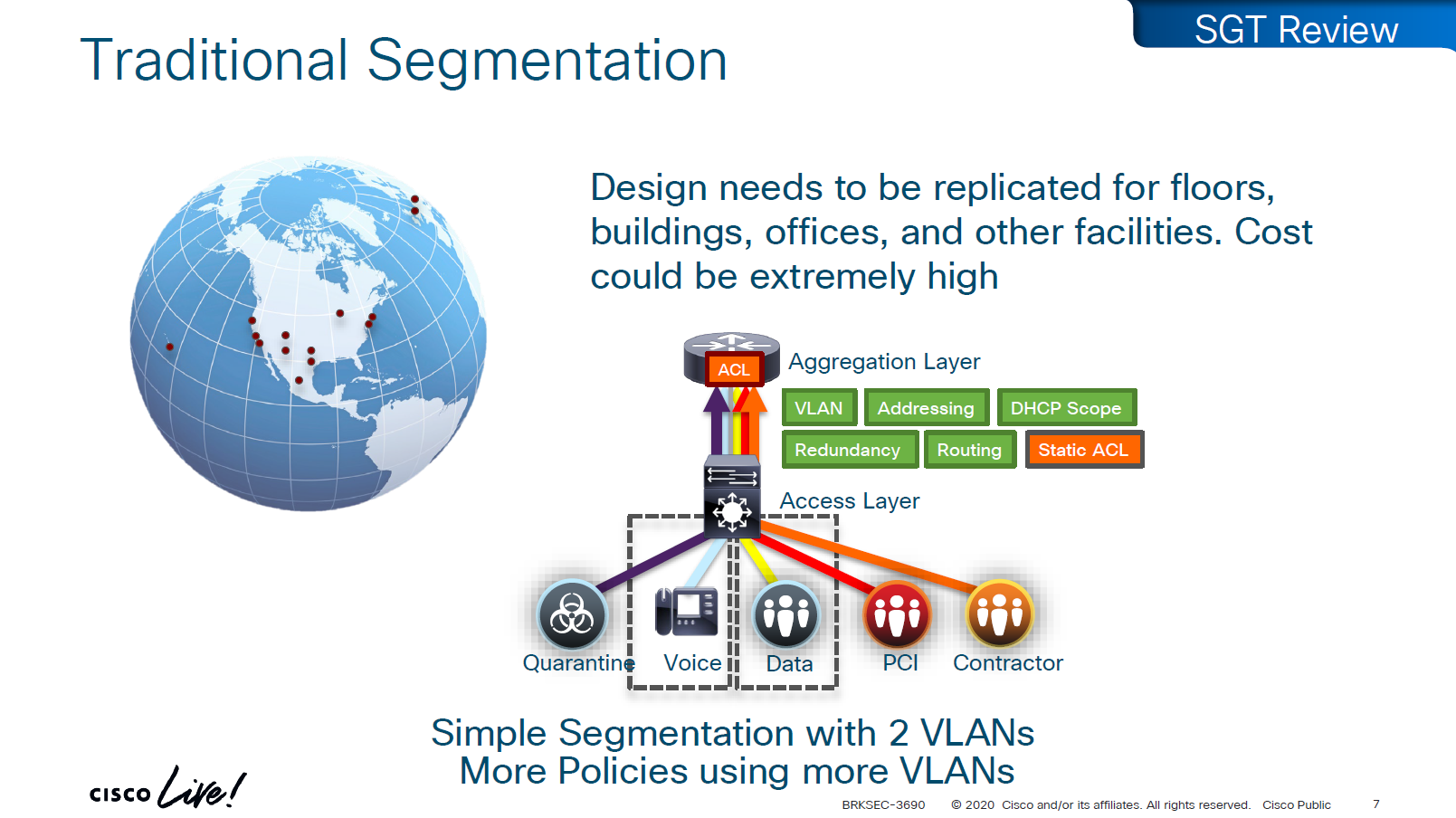
A Security Group Tag is a 16-bit label attached to traffic to identify the security group or role of the source (e.g., Employees, Guests, IoT Devices).
SGTs are used in Cisco TrustSec / SD-Access environments to create role-based access control policies that don’t rely on IP addresses.
SGT is not just used for SGACL or filtering only, because it is a tag on IP packet, this is also being used Policy based routing and also QoS – QoS based on SGT
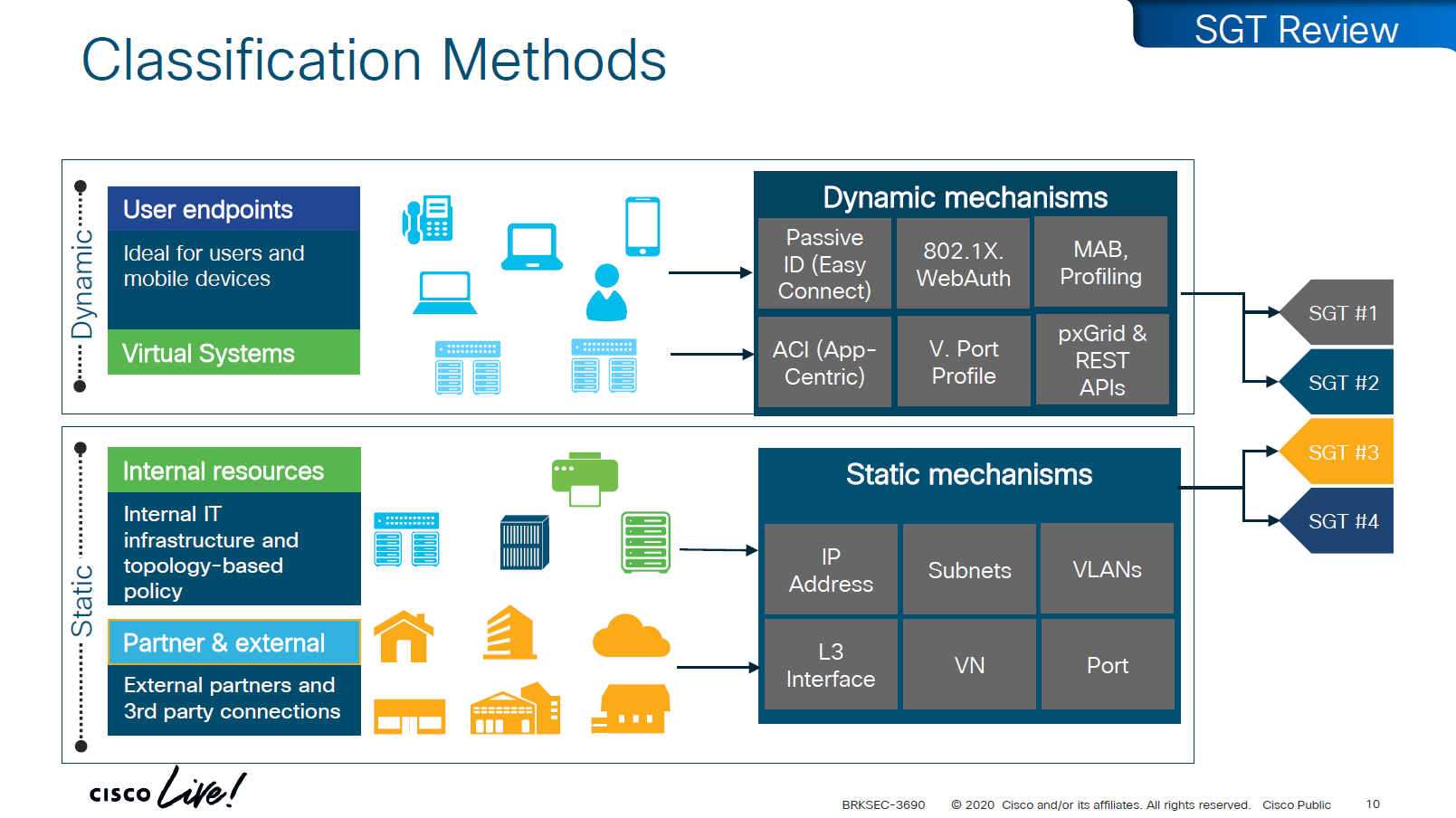
There are 2 ways of classifying the devices in an SGT group
- Dynamic
- ISE
- 802.1x
- MAB, profiling
- pxGrid, Rest API
- ACI
- ISE
- Static
- IP address
- Subnets
- VLANs
- L3 interface
- VN
- Port
Traffic or packets are classified and tagged on ingress into the network which is access layer and filter on the egress of the network
Because classification and tagging on ingress of the network and filtering on egress of the network, it is very important to have tags pushed or transport the tags to all devices on the network
There are 2 ways to do that,
No packet tagging, but use control plane, using SXP (Scalable Group Exchange) protocol to teach foreign devices about the IP to SGT over TCP control plane
This way frame or packet has not been modified or tag is not added in the IP header, and target device also understood the tag that applies to that traffic.
SXP can be activated on a headend only that makes drop or allow policy decisions, it does not have to be applied on all intermediate nodes in the topology hop by hop unlike QoS that requires every hop to do QoS enforcement.
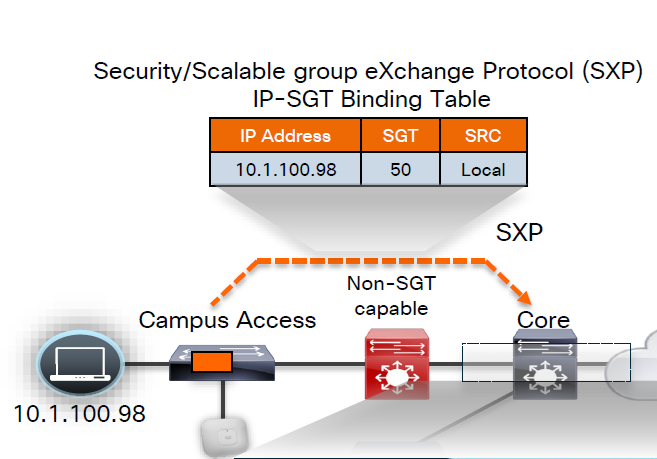
other one is inline tagging
with inline tagging we also have some encryption options such as IPSec or MACsec to prevent people from messing with tags
By default you can go from SXP to inline tagging
to go from inline tagging to SXP you must enable SGT caching
All firewall vendors like Firepower, Checkpoint, Fortigate and Palo Alto, do support pxGrid based implementation for SXP, pxGrid is a publisher and subscriber model where publisher can push information down to subscribers for different topics and one topic can be SXP protocol that has a table that contains IP address to SGT tag mapping
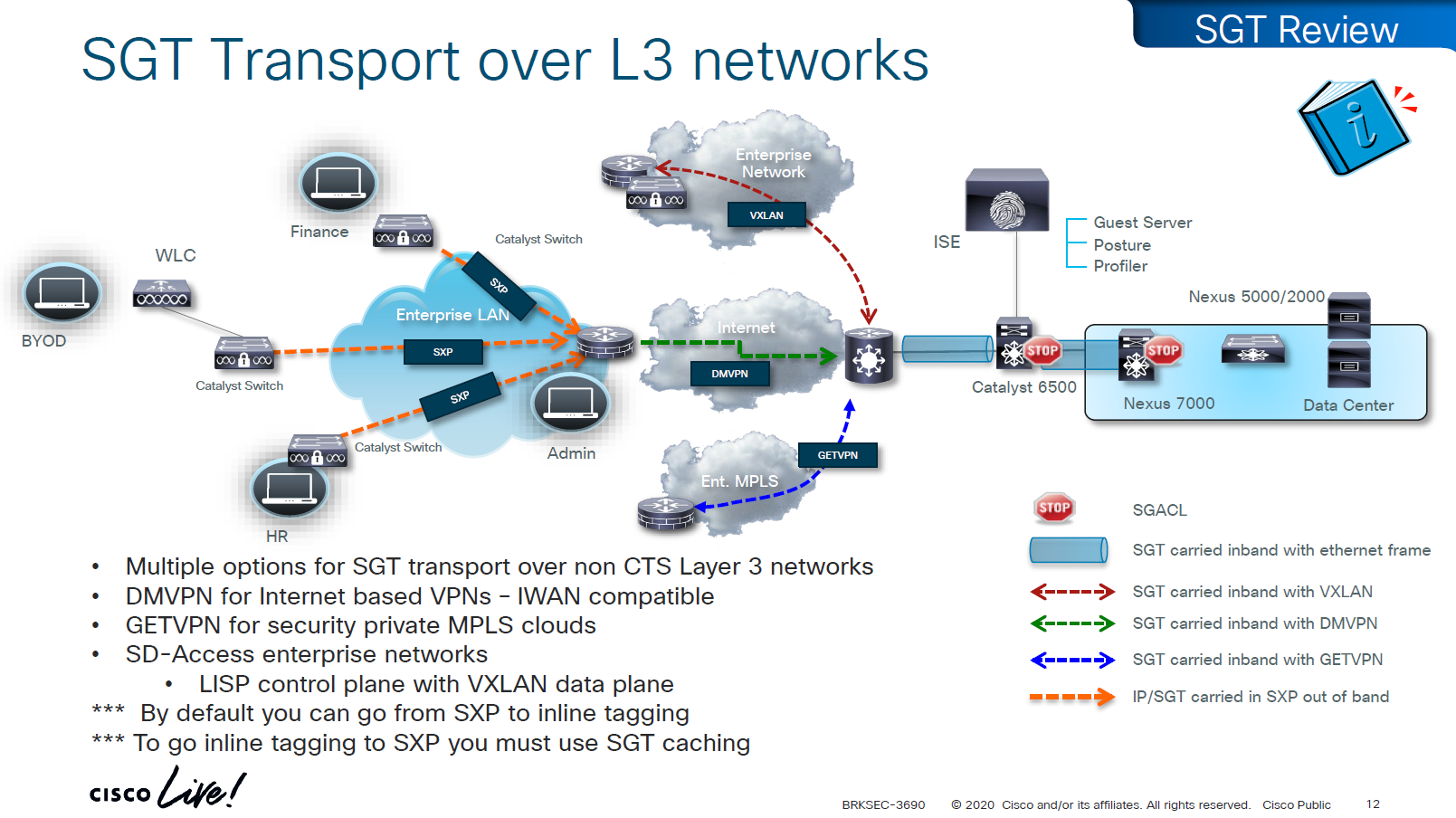
SXP can be activated on a headend only that makes drop or allow policy decisions, it does not have to be applied on all intermediate nodes in the topology hop by hop unlike QoS that requires every hop to do QoS enforcement.
End to end SGT work flow
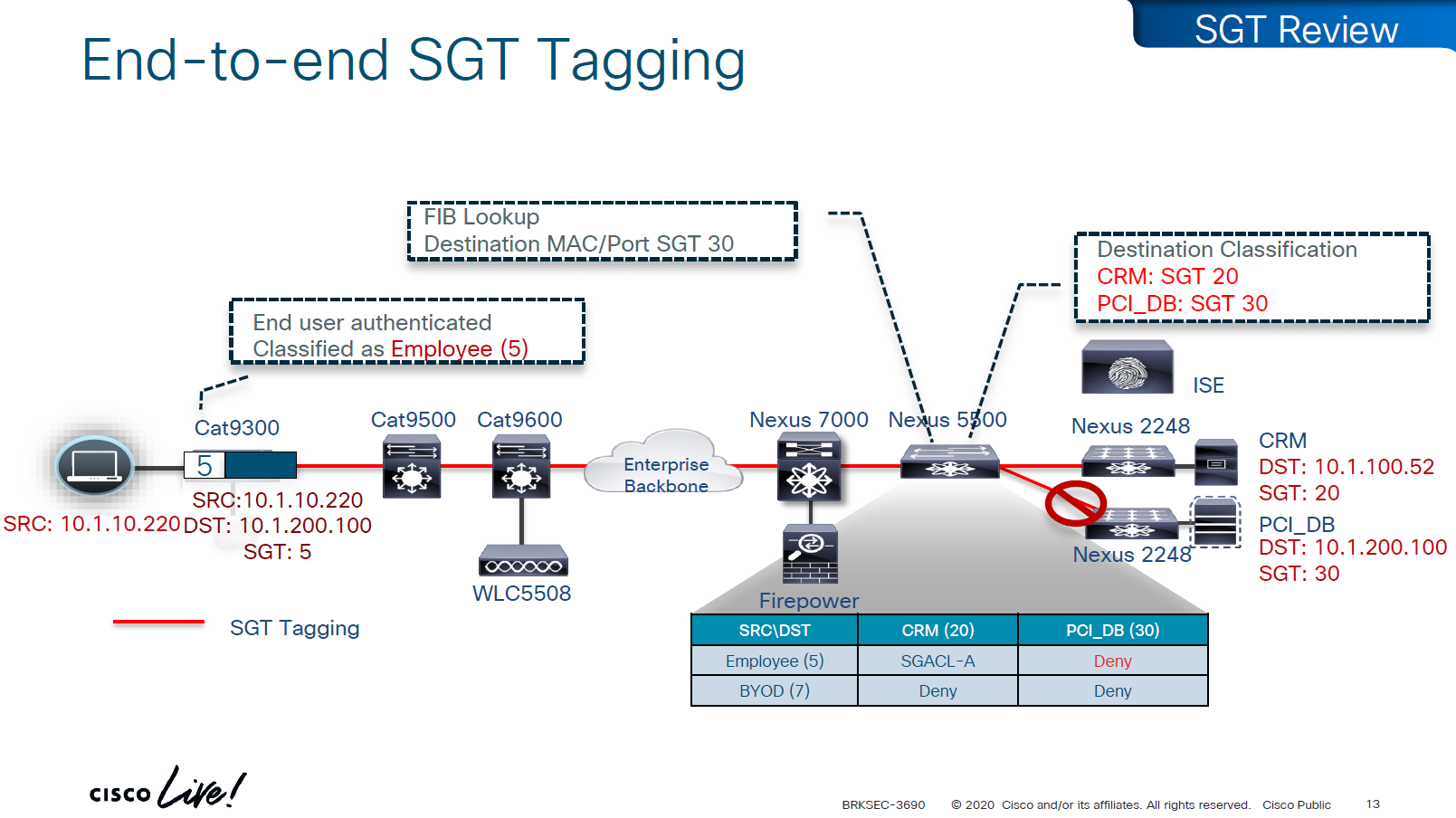
Filtering with SGTs is always done on egress or last switch where destination is connected,
this is because we do not want to overload our access layer switches with all policies and track of all devices connected on the network ahead of it
This optimizes and keeps memory size smaller for small devices,
Access or ingress will only add tag to the traffic and send,
it is the destination switch after it has received the packet,
checks the SGT on the packet – if not on packet, derive SGT from the SXP learned IP to SGT table.
Find out the mac / destination port + the SGT assigned to host on that port – if not assigned on port derive from SXP learned IP to SGT table for that IP
then egress switch will take a policy decision and drop or allow based on policy,
Switches in aggregation or core can be set to look at the destination IP and determine the SGT from SXP learned IP to SGT tag before sending packet out towards destination, this is to drop traffic in core rather than egress
on destination egress or core a log is generated for all deny or drops, if all switches in network point to central logging server, these logs can tell us about the dropped traffic

This shows the policy matrix and how switches that have hosts with certain SGT only pull “columns” from matrix for those hosts only, as soon as a host is connected that has a new SGT, policy column for that SGT is downloaded on the switch, this is very on demand like fashion where switch does not have to download all the policies of the policy matrix and be light weight
Be careful of platform support for SGT when implementing to make sure that platform does support trustsec for all actions such as Classification, Propagation and Enforcement
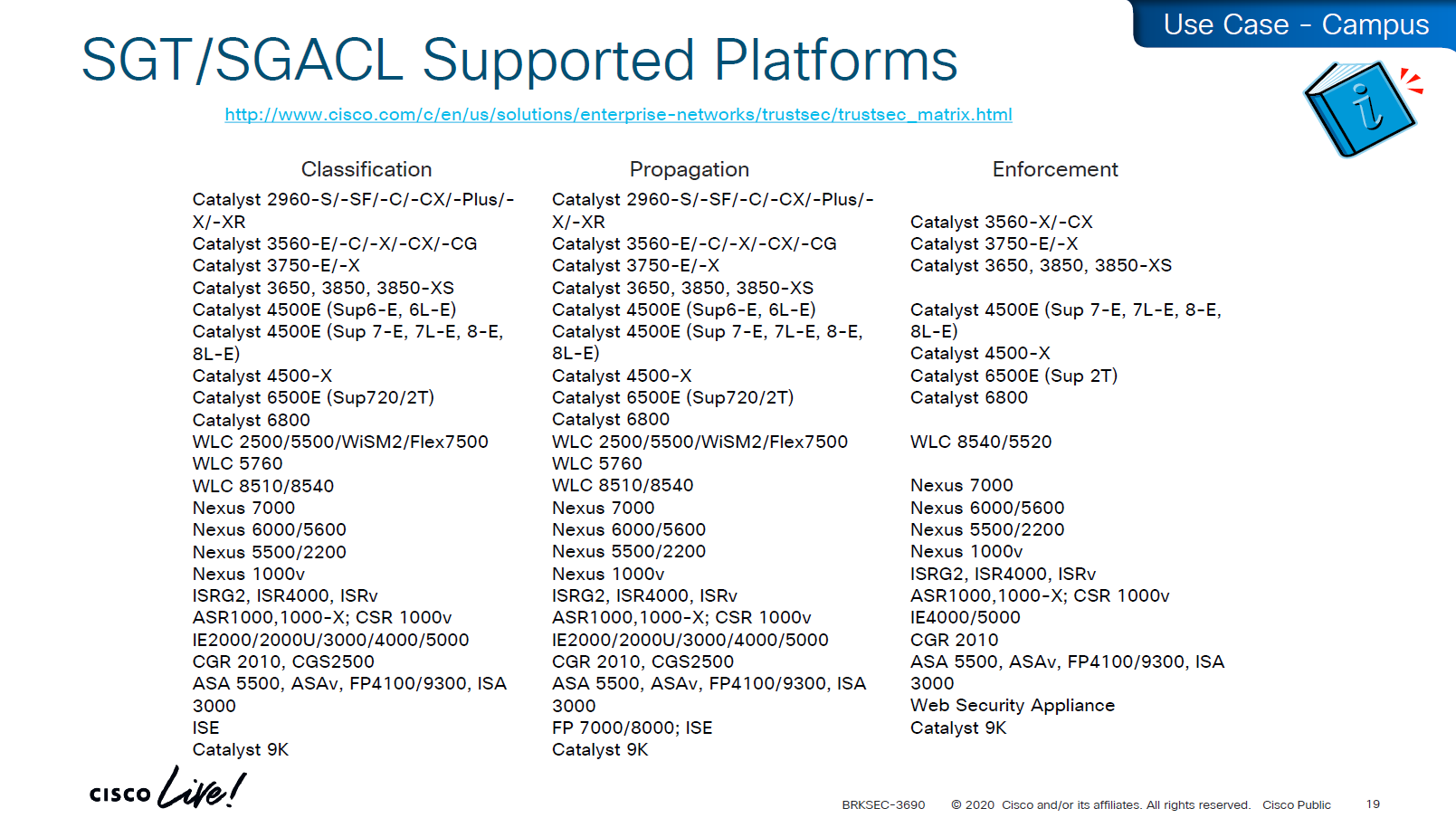

on 3850 as a client we are setting SXP peer (almost like a routing peer) to send it the IP to SGT mappings (local mode)
9K is SXP receiver only using “mode local listener” instead of a speaker
Think of Speaker / local as “teacher” and listener as “learner”
show cts role-based sgt-map all details
! check mappings on 3850 switch
show cts sxp connections brief
! check peersin above “show cts role-based sgt-map all details” – we can see the one attached host got SGT tag of 6:Full_Access and source is “LOCAL”
similarly not shown here but WLC also a client that got SGT of 3:BYOD and at the bottom we run “show cts role-based sgt-map all details” command on core C9K and we can see both tags learned from SXP (3850 and WLC). Aggregation layer is building table automatically as devices are learned from Access layer devices
Enabling SGT/SGACL Enforcement
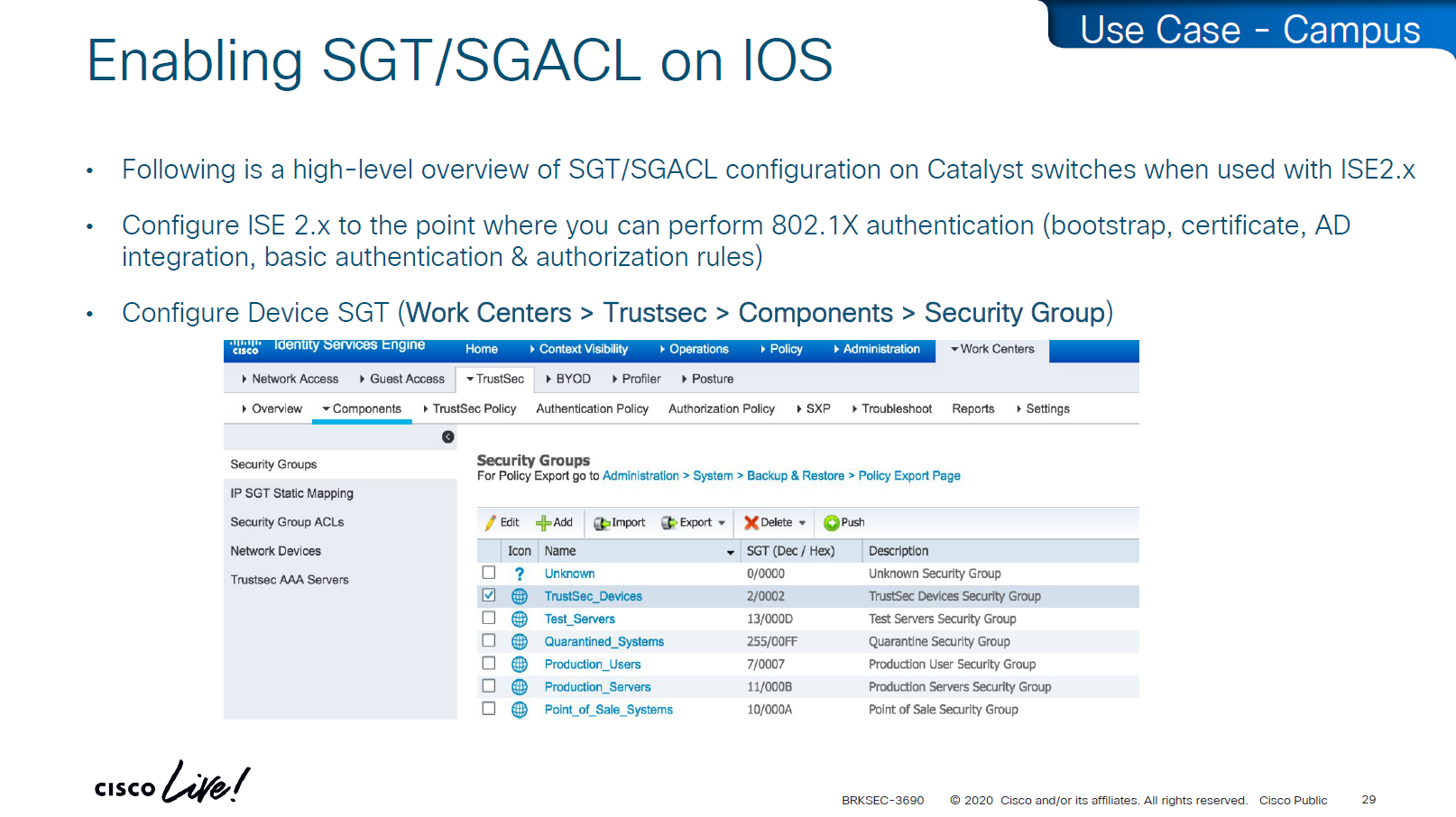
Before SGT/SGACL can be enabled on Cisco devices, make sure that SGT tag for network devices TrustSec_Devices is assigned by default to the network device and make a policy that always allows TrustSec_Devices is always allowed to speak to ISE and infrastructure, why is that needed? because there is a default rule in policy, if it is set to deny then all control plane traffic from device to ISE will be dropped
There was a case once when 2000 switches disappeared from the network, that customer did not have network device SGT like TrustSec_Devices above, they also did not have policy against it to make devices from TrustSec_Devices speak to infrastructure servers SGT, third thing is that they turned on default deny rule in policy
Do not turn on that default deny unless you are really sure that every protocol and everything has been taken care off as it will start dropping the Unknown / untagged SGT traffic as well
Unknown SGT refers to the default tag used when a packet, user, or device does not have a valid SGT assigned. In Cisco TrustSec, this value is typically SGT = 0 and is considered unclassified or unauthenticated traffic. Whenever Unknown SGT of 0 is seen on traffic or host, it means following:
-The client is not authenticated via 802.1X/MAB/web-auth
-Even if authenticated from ISE, there was no SGT in Auth Z results from ISE
-The TrustSec policy mapping isn’t configured
Most TrustSec deployments deny or restrict traffic with Unknown SGT:
- Best practice: Block or isolate Unknown to → Protected traffic in policy matrix
- Allow Unknown to → Internet (e.g., guest networks) in policy matrix
Assign TrustSec_Device to network devices

SGT CTS “peer authentication” between ISE and Device is done through EAP-FAST as PAC file is downloaded on the Network device, PAC which is used in case you want password less certificate like authentication without having certificates. This is called PAC bootstrapping, this is used to download policies, SGACLs and SGT tags then later SXP is used to send or download the SGT to IP mapping separately.

look at send from ISE PSN and test connection button
If there are large number of policy changes, having CLI access from ISE is much faster and better at times, for example there was a customer with 200 x 200 policy matric, it took almost 4 hours to finish the update, it was changed to CLI for all devices and all updates completed in 30 mins, if it is small incremental updates, RADIUS CoA is fine
This device ID is the hostname of the device and password corresponds to command
cts credential id DEVICE-ID password PASSWORD! this is done in non config , enable mode
device>cts credentials id <DEVICE-ID> password <PASSWORD>
show cts credentials
show cts environment-data
show cts role-based permissionsSetting long timers make sure policy is refreshed on devices annually and also only when there is an explicit change in policy

Why the pac key appears under the radius-server host command?
Even though the PAC is used for TrustSec (CTS/NDAC) and not for normal RADIUS authentication, the PAC is delivered through RADIUS using cisco’ vendor attribute, PAC exchange is not a standard RADIUS authentication — it is a special RADIUS message (Cisco-vendor attribute) used only for TrustSec device bootstrapping that is why it is configured under RADIUS server configuration block along with RADIUS shared secret.
cts authorization list <AUTHZ_List_Name> is the list of ISE RADIUS nodes that are running TrustSec
Why Cisco did it this way
Cisco chose to reuse the RADIUS channel rather than invent a new protocol:
- RADIUS is already required for 802.1X authentications
- Switches already have reachability to ISE
- The PAC exchange can ride over the same transport (UDP 1812/1645)
So the PAC bootstrap process piggybacks on RADIUS → therefore, the PAC key configuration lives inside the radius-server settings.
Full configuration of ISE RADIUS Servers with PAC
! Enable AAA
aaa new-model
! Define ISE as a RADIUS server (auth/acct) and include the PAC bootstrap secret
radius server ISE1
address ipv4 10.10.10.10 auth-port 1812 acct-port 1813
key RADIUS_SHARED_SECRET
pac key RADIUS_PAC_SECRET
!
! send vsa or vendor attributes in RADIUS authentication request
radius-server vsa send authentication
! (Optional) put servers into a group and set a source interface
aaa group server radius ISE-GRP
server name ISE1
ip radius source-interface Vlan10
! CTS/NDAC: define the authorization list used for policy download only (not tags - tags are pulled before SGACL or policy is pulled) - as clients connect with new SGT , more policy columns are pulled
cts authorization list CTS-AUTHZ
! 802.1X + CTS use the RADIUS group
aaa authentication dot1x default group ISE-GRP
aaa authorization network CTS-AUTHZ group ISE-GRP
! aaa authorization network command is usually used to allow on network or authorize audience or entity authenticated through network ports and this config says that authorized list of server (which are allowed to make CLI or COA changes) will be downloaded from ISE-GRP
! which makes it look like this
aaa authorization network ( CTS-AUTHZ ) group ISE-GRP
aaa authorization network ( cts authorization list ) group ISE-GRP
! Define credentials for EAP-FAST I-ID, these are configured under enable mode and not in config mode
cts credential id DEVICE-ID password PASSWORD
! enable 802.1x on system level
dot1x system-auth-control
! enable CTS enforcement
cts role-based enforcementSXP does not carry SGACL policies.
SXP only carries IP-to-SGT mappings
SGACL policy travels via DTLS tunnel established using PAC.
Policy matrix is translated or converted into bunch of SGACLs and then sent out to devices
Sequence and use of PAC:
1. Authenticate the switch to ISE for TrustSec
2. Receive the PAC credential
3. Establish a secure, encrypted control channel DTLS for SGACL policy download
It is sent through the PAC → NDAC → Secure DTLS Trust Tunnel that is established after the PAC is provisioned
Switch proves identity to ISE to download PAC -> RADIUS
Policy download (SGACLs and SGT tags – “TrustSec Bootstrapping”) -> PAC established DTLS (UDP)
IP-to-SGT sharing between devices -> SXP (TCP)


First thing to notice in this output is the Local Device SGT that is assigned to network device, any control plane communication from this device will be assigned SGT
Then coming below we can see 3 TrustSec ISE servers are set as servers for downloading SGT tags and SGACL policy (but not SGT to IP mappings which are downloaded over SXP)

We define more tags in ISE, in above picture we can see ACI EPGs (contracts) defined as tags and this is through automation , automatically created through API
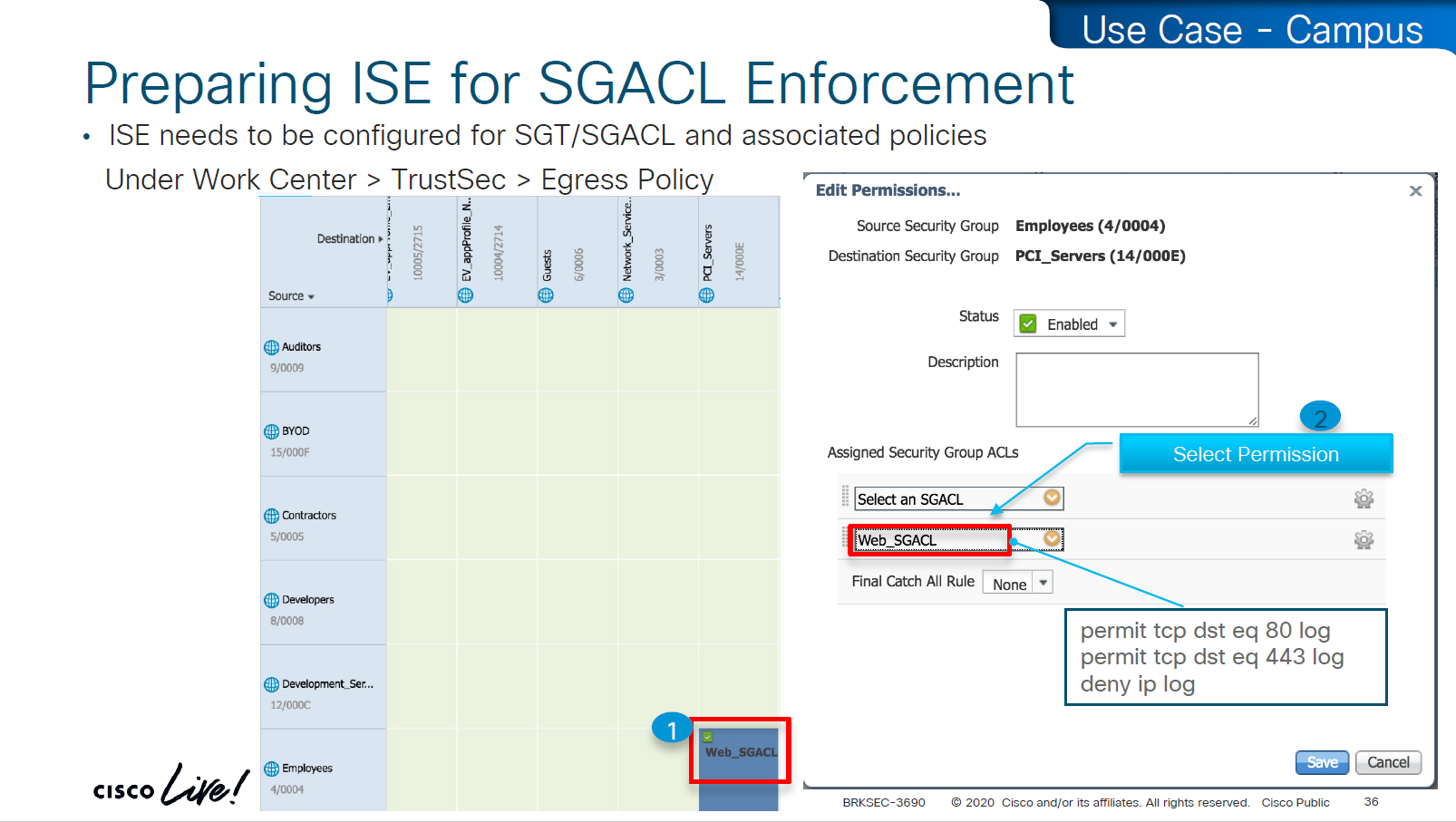
These are stateless ACLs unlike firewalls, this is exact filtering as described ACEs
but best thing about these ACEs is there are no IP addresses
One thing to notice in above screenshot is ability to define multiple ACLs in a single cell of the policy matrix but this is turned off by default as it is not supported by all devices yet because WLCs and Nexus only support single ACL for an SGT and DGT filtering
Only IOS XE switches are supporting multiple ACL per cell

above we can see manual IP to SGT map, which can also be pushed from ISE via CLI or from ISE via SXP
Even if switch has policy matrix table downloaded, and switch also has all the SGT tags, switch will not enforce on traffic unless command is “cts role-based enforcement” is defined
Second command allows us to enable on per VLAN, this is very significant because we can enable SGT enforcement incrementally on VLANs

environment data is SGT tags
policy is the policy matrix

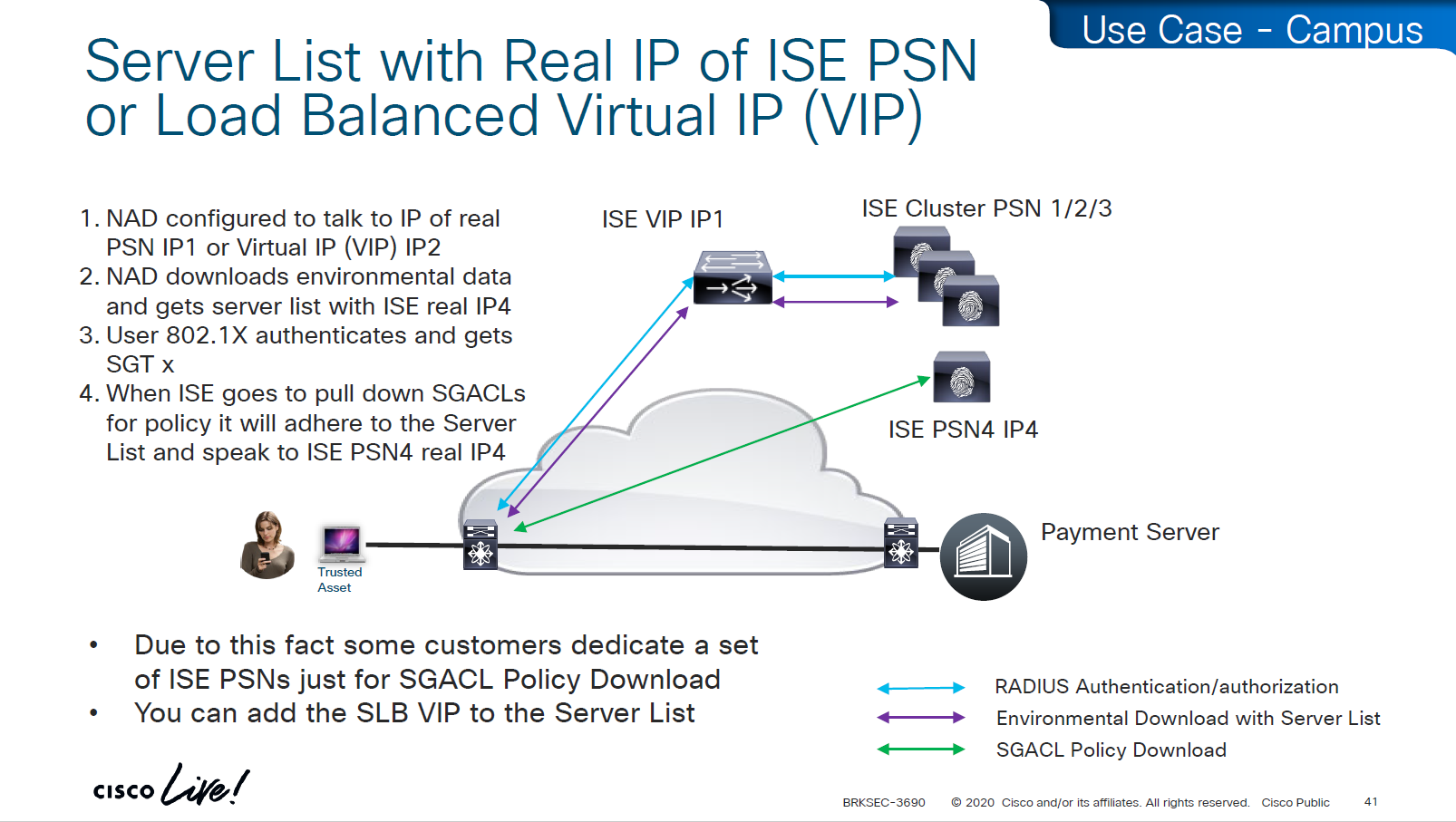
As we can see that RADIUS flow is different
“Environmental Data download + Server list” is different flow before SGACL policy is downloaded
SGACL policy download is from the server list, server list was fetched with environment data

This was done because in peak times when RADIUS servers are busy it can be too much load to download the SGACL policy over same ISE PSN nodes and it is better to download over dedicated ISE TrustSec PSN nodes

in above screen shots dynamic author (RADIUS servers allowed to do CoA) are defined
-PAN should be defined for SGT related flows
-PSNs should be configured for 802.1x / MAB
In older versions of ISE, clicking on Deploy is not enough, there is a confirmation icon on top that needs to be click and confirm, only then ISE notifies all switches that there is a change and download the new policy

There is a policy validation button that runs this command “show cts role-based permissions” and validates that ISE has same policy as devices and if there is any mismatch or issue then an Alarm is generated from ISE


SGACL denies will show as log, and you will see that logging hits are shown as well which means that if there are a lot of logs then number of hits accumulated will be reported under logging_interval_hits and log will be generated, but in some cases auditor will come in and say that they need to see a log for every drop and allow, and at that point we need to understand that this is a switch and not the firewall, with SGACL enforcement it is not possible to get log for every hit

show cts role-based counters
! shows * to * default rule
! also shows from and to columns
! SGACL is done in hardware, unless needs punting
! for example TCAM or hardware is full, log in the end of ACE , makes SW counter increment otherwise concentrate on HW-Denied and HW-Permitted columnsSoftware denies and software permits are for to the box traffic or traffic destined for the switch, including the DHCP and ARP permits will also increment the Software counters, SGACL enforcement is in hardware
One of the examples of confusion with ping is that people test access control by pinging the switch SVI and say why is the hardware counter not increasing, it will be denied in software SW-Denied, the thing with SVI ping is that it is going up through software control plane to the CPU and then responding (punted to CPU)

Wireless APs do “enforcement” with SGACLs

TrustSec implementation in wireless does follow the same principal of tagging on ingress and filtering on egress (APs)
APs do the filtering also on egress in wireless to wireless communication, that confuses people as they see SGACL download on WLC but they do not see permit or deny logs in WLC CLI, it makes sense to check the WLC but enforcement for wireless to wireless traffic is being done on AP for scaling reasons otherwise WLC will be overwhelmed as WLC can do enforcement for wireless to wired communication
Ingress AP will tag the packet and send it across the WLC over CAPWAP due to central switching and egress AP will do the lookup for SGT of the destination client using client table and perform policy enforcement based on that
Skipped Nexus 7000 SGT Considerations

Common issues


SGT trustsec relies on IP device tracking
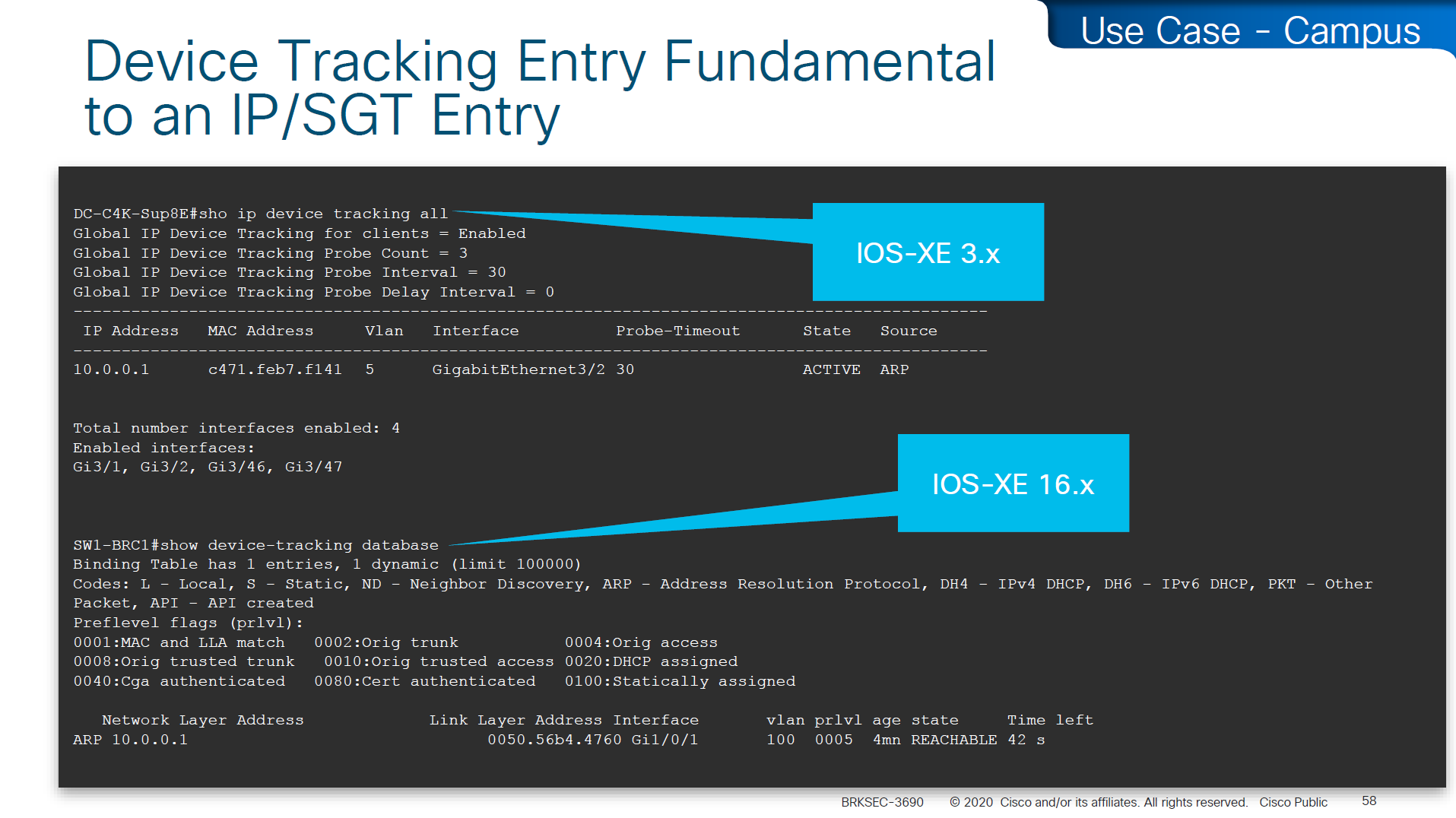

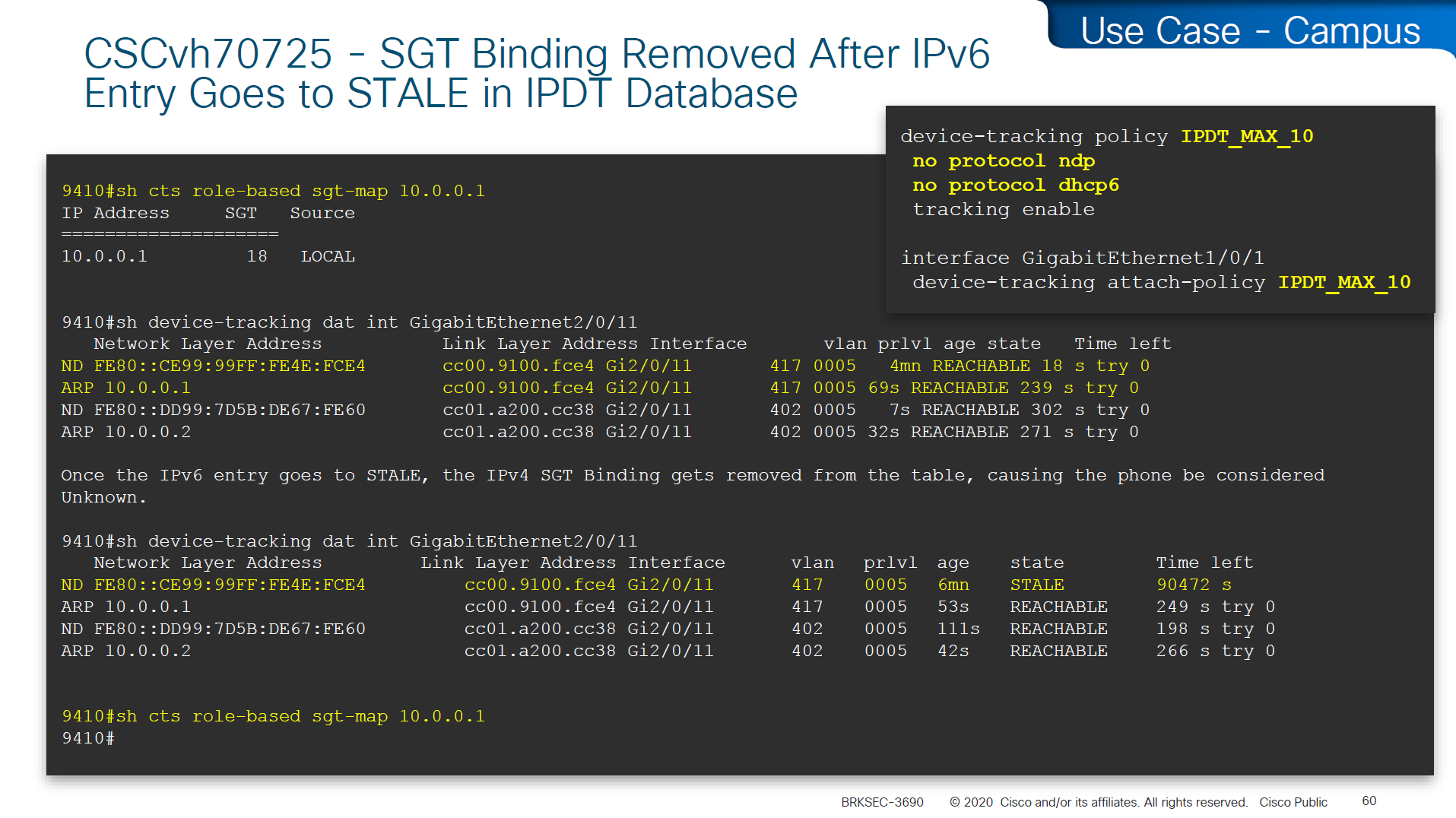
In case you have SGT disappearing from host, then check if this bug is in effect and usually happens on older unpatched code, the workaround was to turn off ndp (which is IPv6 ARP mechanism) tracking from IP device tracking and also turn off dhcpv6 tracking

in case SGACL download is not happening we need to check following:
Make sure pac is present
show cts pac allMake sure AAA servers are marked alive
show aaa servers Make sure device can reach ISE
show cts environment-dataCheck ISE to make sure SGACL is formatted properly
Make sure there are no errors in device-tracking as whole solutions rides on device-tracking to work
Sometimes bad implementation of SDWAN can cause fragmentation of large packets and sometimes that can cause ISE to device download of SGACL of DTLS (PAC based) to break for large packets causing “partial download”, that is why it is so important to first test for fragmentation over greenfield or brownfield deployment and also test large elephant connections with large packets – on the side note large elephant connections over IPSec based tunnels are heavy on platform’s ability to encrypt large traffic
So if you see partial download of SGACL, then always check for fragmentation issue, because by default for this pac based DTLS connections DF bit is set and routers from all vendors do not like DF bit
Software Defined Access (SD – Access) – SGT/VXLAN



These SDA VNs are VRFs but these are campus wide VRFs,
Macro Level segmentation is devices of different management domains go in their own VN
Micro Segmentation is used for access control within the VN

LISP is another great optimization at the access layer and it reduces or optimizes the routes by only installing /32 host routes on access layer switch to which its connected hosts are initiating connections to and from, access layer no longer needs to maintain the large routing tables, LISP installs routes in VRFed routing table of access switches
VXLAN is carried inside UDP just like an layer 7 application and VXLAN carriers the whole original ethernet frame and not just IP packet
VN and SGT are carried inside the VXLAN header
The SGT (Security Group Tag) is not added to the original inner IP packet.
It is carried only in the VXLAN header as metadata, and in order to use SGT capabilities outside of the network with Cisco gear we can use TrustSec which uses SXP and with other vendors we can use PXGrid

Policy matrix is created on DNAC and then pushed to ISE , ISE then pushes the SGT environment data (SGT Tags and Trusted Server list) over TCP, SGACL using NDAC over PAC based DTLS and then finally IP to SGT mapping on border nodes using TCP SXP


ACL or contracts are defined in badge color cells

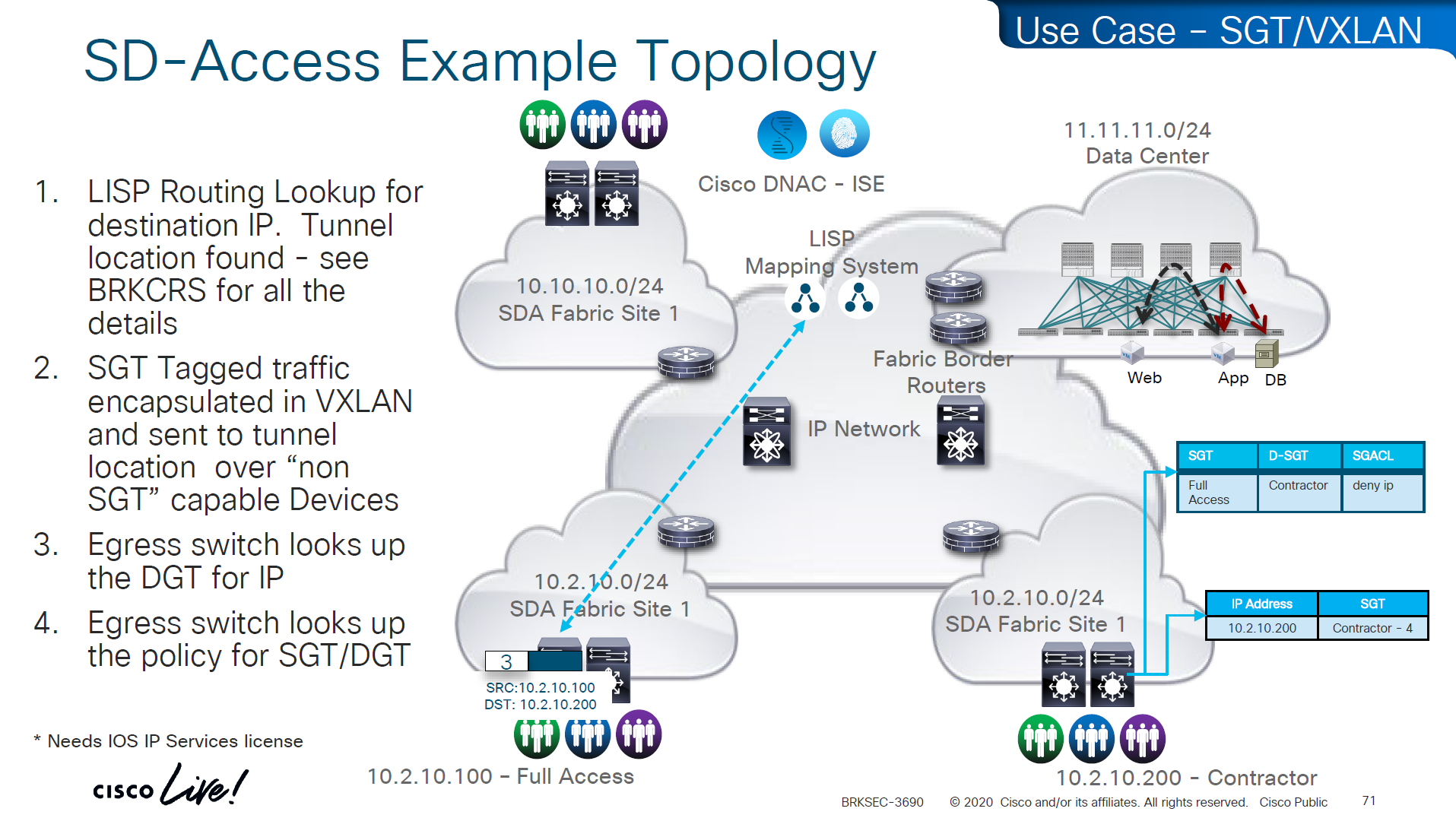

This is how it is enabled inside LISP
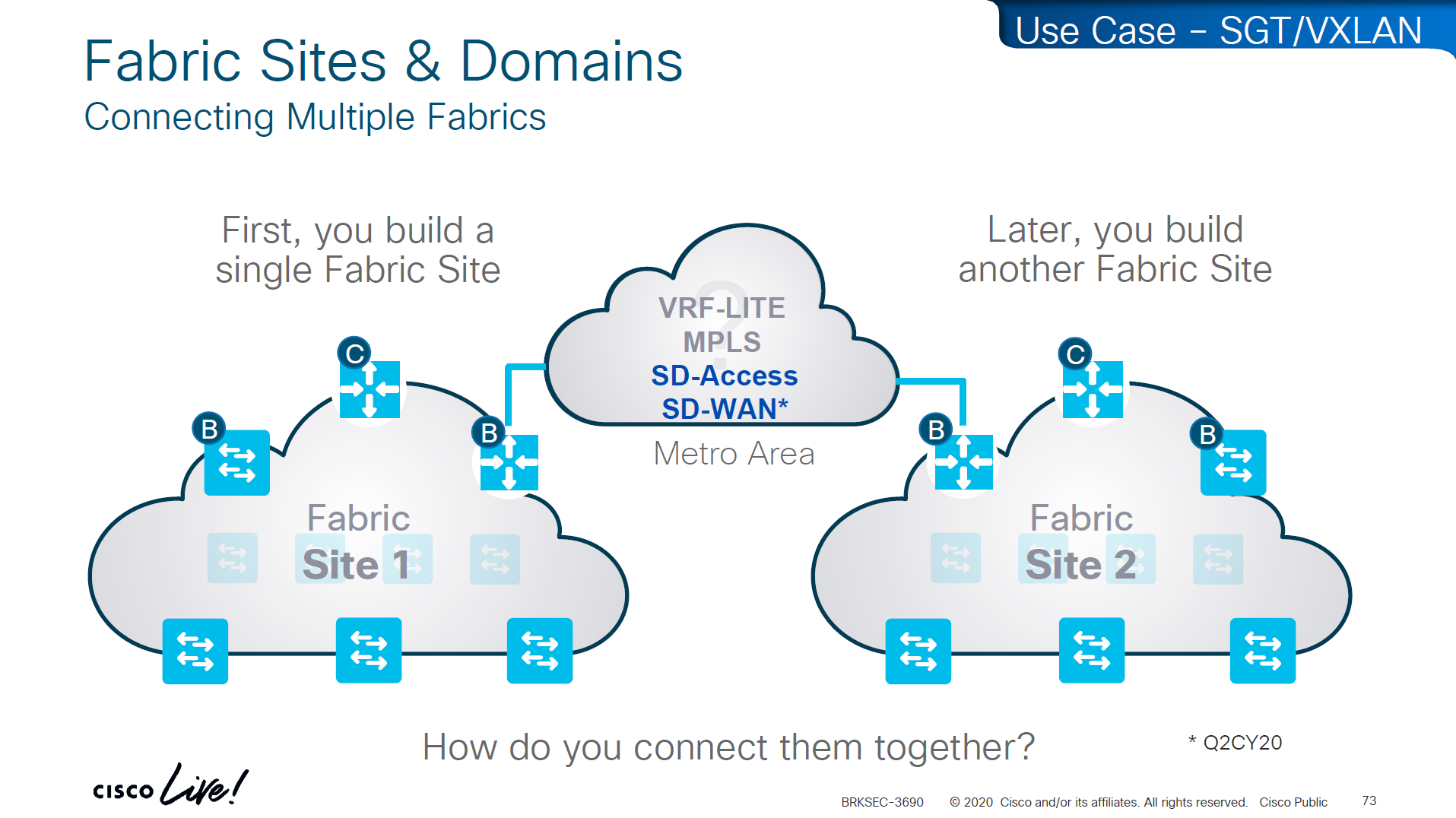
If we have SD Access transit or SDWAN, we can carry SGT to other fabric sites

SDA transit uses LISP as control plane between borders of both fabric sites
and then on data plane we have VXLAN header that crosses between fabric sites
but in order to accommodate the VXLAN header we will need 1588 or better 1600 MTU
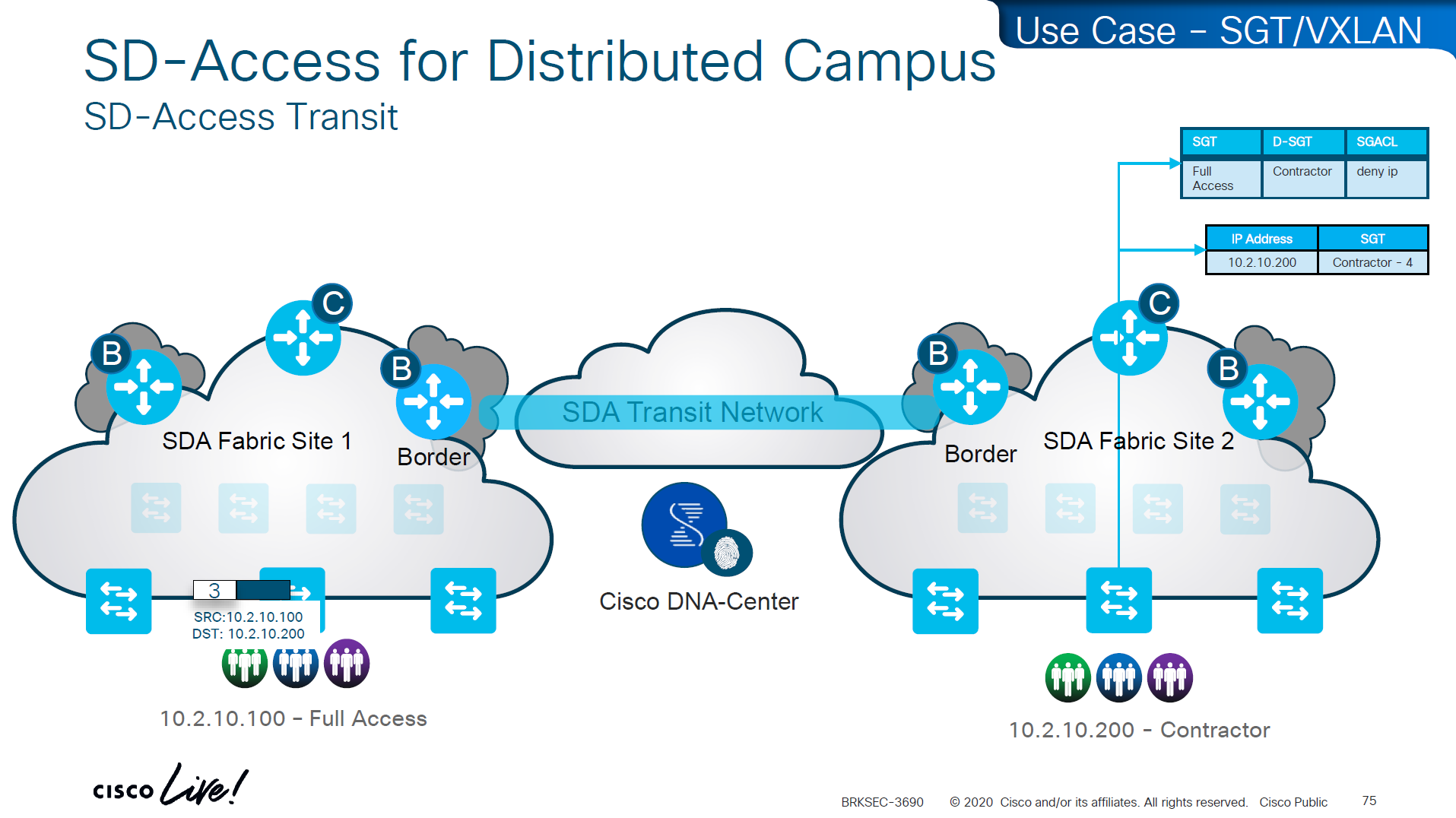
Skipped Firewall Integration with SD-Access

Skipped Meraki and 3rdParty Interop

Use Case Review -WAN



-medical devices and servers are assigned SGT and allowed to speak to one another
-Summary SGT of 10.0.0.0/8 in SXP for all users and devices in 10.0.0.0/8 space and this keeps the SGT under 12K
-Create a Policy Matrix that has Known_SGT <-> Known_SGT permit
-Create a Policy Matrix that has Known_SGT <-> Summary_SGT deny
-For Internet traffic default route is tagged as Internet_SGT
-above Internet_SGT leaves reserved tag called Unknown to handle traffic for medical devices that are not tagged
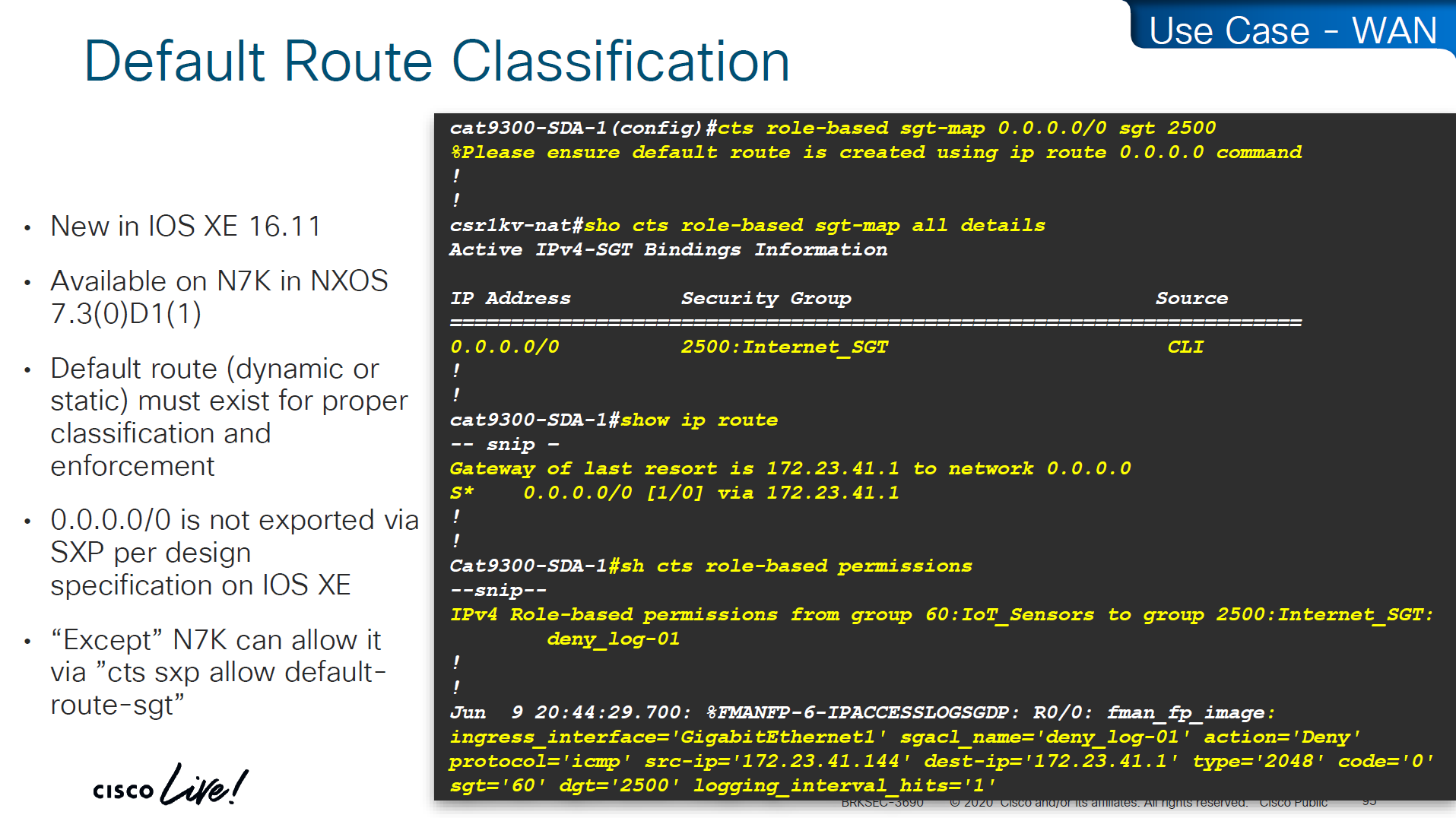
SXP Reflector Like Design

in above SXP connections, if one device speaks (has a speaker role) IP to SGT mapping then on the other end if there is a listener it will listen and learn the IP to SGT mapping and if a device listens (has a listener role) then on SXP connection it can learn IP to SGT mapping from a speaker
once a new mapping of IP to SGT is learned by aggregation Listener, it “speaks” those mapping to all the listeners

Above shows Medical_device <-> Medical_server allow
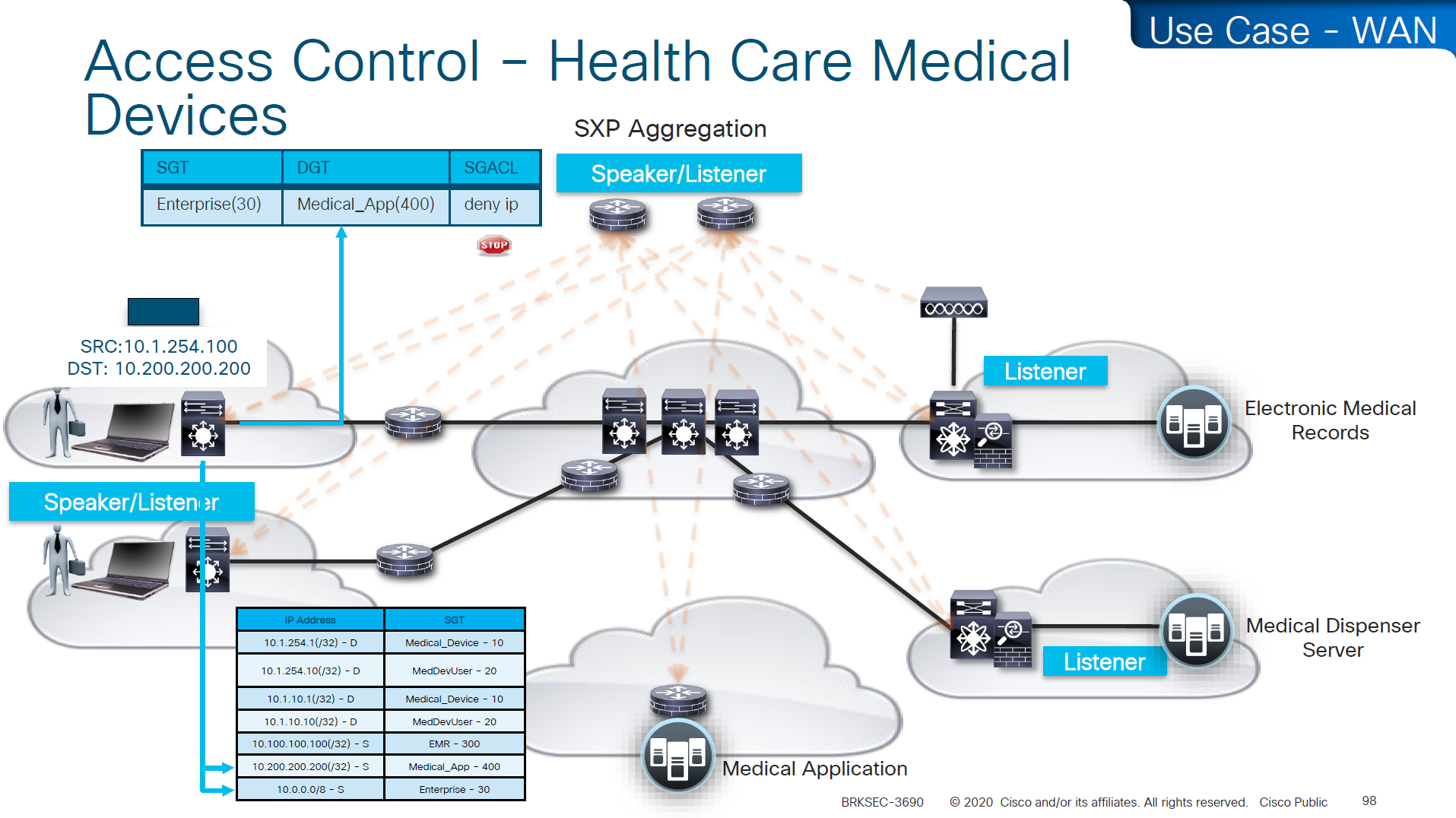
Above example is the source on 10.0.0.0 network that has fallen on 10.0.0.0/8 SGT of Enterprise and is trying to speak to Medical_device and by policy that is denied

cts manual – tells the router interface to assign sgt manually to traffic over this interface
policy static sgt 2 trusted – All traffic that enters or exits this interface is tagged with SGT = 2
“Trusted” means this interface accepts incoming SGT tags from the peer without overwriting them. If the link partner already sends SGT-tagged frames, the ASR1K trusts them instead of stripping or replacing them.
no cts role-based enforcement – on the router interface or layer 3 interfaces which are in the middle of the path, we have to turn off any kind of enforcement in order to avoid dropping any traffic , Because the ASR1K in this use case is only tagging packets, not enforcing access control. This keeps the device acting as a TrustSec transit / tagging device rather than a policy enforcement point.
cts manual
policy static sgt 2 trusted
no cts role-based enforcementso above config achieves – tag outgoing traffic, trust the tag from connected device for incoming traffic and disable enforcement because this is a transit node and not access layer policy point

show platform hardware fed switch active fwd-asic resource tcam utilization
! Max Values column
! Used Values
! first value is IP "/" second value is SGT
! "Directly or indirectly connected routes"
! for 9300 10K limit officially for both IP and SGT combined
! "Security Access Control Entries" are number of ACEs
! "SGT_DGT" is number of cells from Policy Matrix
This healthcare provider hit the scale limit of SGT on access layer so they moved the enforcement point on routers as router hardware has much more scale


If you want to know that you are tagging traffic, simply turn on netflow with cts with above commands and even if you dont export that flow anywhere, we can see local cache , great for tshoot

use this command to see the tagging info
show flow mon cts-mon cacheyou will see that in above output we see destination tag as 0, because we are running this command on ingress or access layer where there is no info about destination host or its assigned SGT

Stealthwatch has ability to specify source and destination tag




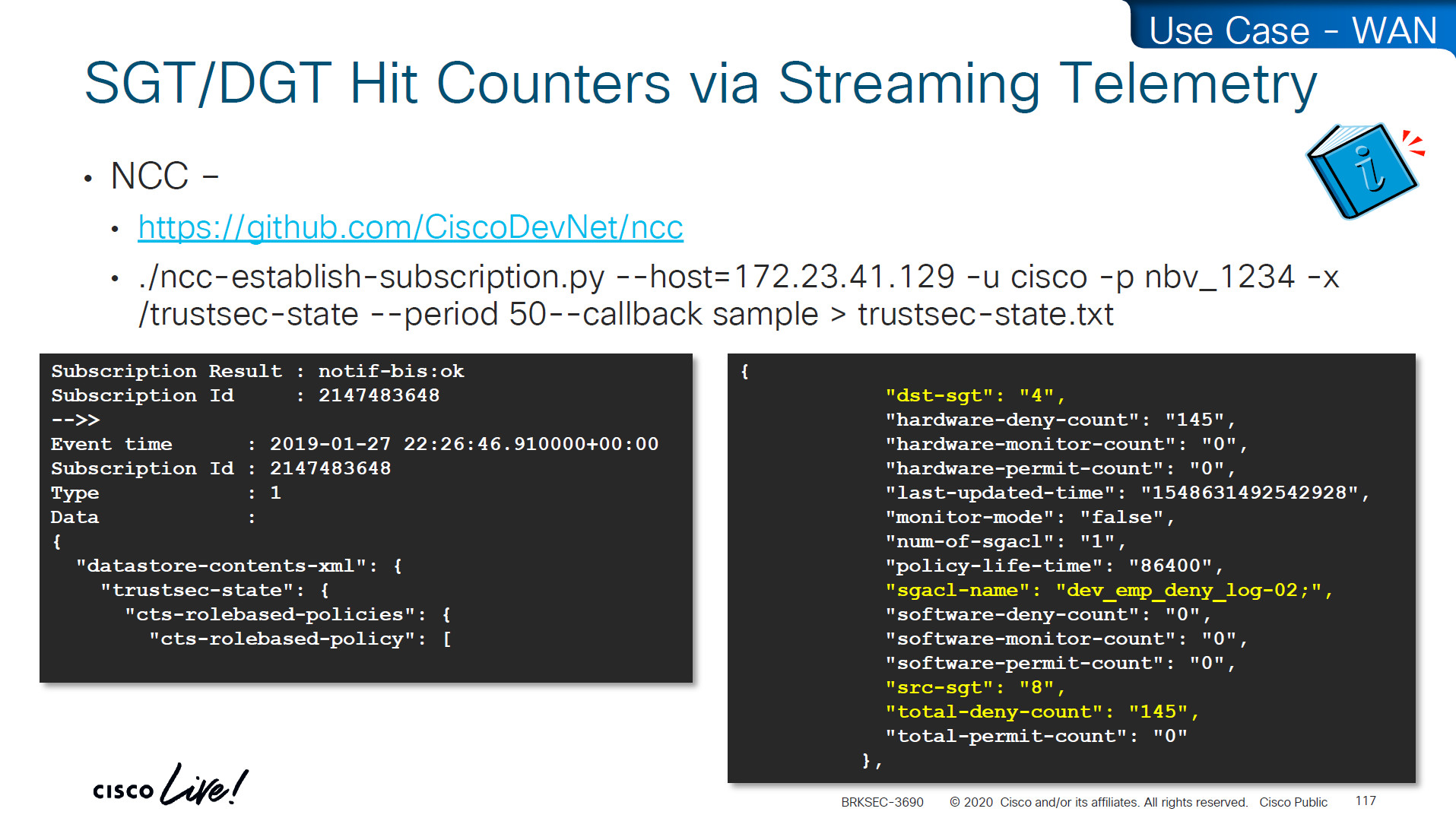

Skipped DMVPN SGT tagging
Skipped SGT/ACI
Skipped Cloud
SGT commands
! on ingress or access
cts sxp enable
cts sxp connection peer 10.1.44.1 source 10.1.11.44 password default mode local
! on core where we just learn from access as listener
cts sxp enable
cts sxp default password cisco123
! peering with Cat3K
cts sxp connection peer 10.1.11.44 source 10.1.44.1 password default mode local listener hold-time 0 0
! peering with WLC
cts sxp connection peer 10.1.33.24 source 10.1.44.1 password default mode local listener hold-time 0 0
! check IP to SGT table
show cts role-based sgt-map all details
! check SXP connection on on core
show cts sxp connections brief
----------------------------------------------
! Enable AAA
aaa new-model
! Define ISE as a RADIUS server (auth/acct) and include the PAC bootstrap secret
radius server ISE1
address ipv4 10.10.10.10 auth-port 1812 acct-port 1813
key RADIUS_SHARED_SECRET
pac key RADIUS_PAC_SECRET
!
! send vsa or vendor attributes in RADIUS authentication request
radius-server vsa send authentication
key RADIUS_SHARED_SECRET
pac key RADIUS_PAC_SECRET
!
! send vsa or vendor attributes in RADIUS authentication request
radius-server vsa send authentication
! (Optional) put servers into a group and set a source interface
aaa group server radius ISE-GRP
server name ISE1
ip radius source-interface Vlan10
! CTS/NDAC: define the authorization list used for policy download only (not tags - tags are pulled before SGACL or policy is pulled) - as clients connect with new SGT , more policy columns are pulled
cts authorization list CTS-AUTHZ
! 802.1X + CTS use the RADIUS group
aaa authentication dot1x default group ISE-GRP
aaa authorization network CTS-AUTHZ group ISE-GRP
! aaa authorization network command is usually used to allow on network or authorize audience or entity authenticated through network ports and this config says that authorized list of server (which are allowed to make CLI or COA changes) will be downloaded from ISE-GRP
! which makes it look like this
aaa authorization network ( CTS-AUTHZ ) group ISE-GRP
aaa authorization network ( cts authorization list ) group ISE-GRP
! Define credentials for EAP-FAST I-ID, these are configured under enable mode and not in config mode
cts credential id DEVICE-ID password PASSWORD
! enable 802.1x on system level
dot1x system-auth-control
! enable CTS enforcement
cts role-based enforcement
----------------------------------------------
show cts environment-data
! shows local device SGT
! shows servers that are authorized list servers
! shows downloaded SGT tags on devices
----------------------------------------------
! define SGT for local servers connected to switch
cts role-based sgt-map 192.168.31.1 sgt 100
cts role-based sgt-map 192.168.32.0/24 sgt 20
cts role-based sgt-map 10.x.x.0 sgt 30
! tag default route to Internet_SGT
! This is incase you want to use Unknown tag for something else
! for default route tag, the device must have defafult route either as a static or dynamic for this tagging to work
! this allows us to do something like Medical_devices <-> Internet_SGT deny
cts role-based sgt-map 0.0.0.0/0 sgt 2500
! enableing SGT enformcement globaly
cts role-based enforcement
! or on specific vlans for slow rollout
cts role-based enforcement vlan-list 40
----------------------------------------------
! download or refresh SGT tags
cts refresh environment-data
! download or refresh SGACLs or policy
cts refresh policy
----------------------------------------------
show cts role-based permissions
! shows SGACLs
show cts policy sgt 4
! shows SGT and its related policies in detail
show ip access-list
show cts role-based counters
! shows * to * default rule
! also shows from and to columns
! SGACL is done in hardware, unless needs punting
! for example TCAM or hardware is full, log in the end of ACE or to the box traffic such as Trust_Devices SGT, makes SW counter increment otherwise concentrate on HW-Denied and HW-Permitted columns
----------------------------------------------
show device-tracking database
show cts role-based sgt-map 10.0.0.1
show device-tracking database interface gig2/0/11
----------------------------------------------
! If SGACL download errors happen
show aaa servers
! make sure AAA servers are marked alive
show cts pac all
! make sure pac is present
show cts environment-data
! check if device can communicate with ISE
----------------------------------------------
router(config)#interface Ten1/1/1
cts manual
policy static sgt 2 trusted
no cts role-based enforcement
! tag outgoing traffic,
! trust the tag from connected device for incoming traffic
! disable enforcement because this is a transit node and not access layer policy point
show cts interface brief
----------------------------------------------
show platform hardware fed switch active fwd-asic resource tcam utilization
! Max Values column
! Used Values
! first value is IP "/" second value is SGT
! "Directly or indirectly connected routes"
! for 9300 10K limit officially for both IP and SGT combined
! "Security Access Control Entries" are number of ACEs
! "SGT_DGT" is number of cells from Policy Matrix
----------------------------------------------
flow record cts-v4
match ipv4 protocol
match ipv4 source address
match ipv4 destination address
match transport source-port
match transport destination-port
match flow direction
match flow cts source group-tag <<<<
match flow cts destination group-tag <<<<
collect counter bytes
collect counter packets
flow exporter EXP1
destination 10.1.1.1
source Gig1
flow monitor cts-mon
record cts-v4
exporter EXP1
interface vlan 10
ip flow monitor cts-mon input
ip flow monitor cts-mon output
show flow mon cts-mon cachenext post
SDWAN packet overhead for ESP
SDWAN packet overhead for ESP
IPSec-Encrypted Cisco SD-WAN Overlay (default)
IPSec ESP header: 20 bytes (can be higher depending on options)
UDP header: 8 bytes
Outer IP header (IPv4): 20 bytes
SD-WAN metadata (vSmart control, segmentation, etc.): ~28 bytes (can vary)
Total overhead: ~76 bytes